粗糙集与决策树的分类器设计与对比
分类方法

2
分类方法的类型
从使用的主要技术上看,可以把分类方法归结为 四种类型:
基于距离的分类方法 决策树分类方法 贝叶斯分类方法 规则归纳方法。
3
分类问题的描述
2.使用模型进行分类
首先评估模型(分类法)的预测准确率。 如果认为模型的准确率可以接受,就可以用它对类标号 未知的数据元组或对象进行分类。
5
四 分类方法
分类的基本概念与步骤 基于距离的分类算法 决策树分类方法 贝叶斯分类 规则归纳
6
基于距离的分类算法的思路
定义4 定义4-2 给定一个数据库 D={t1,t2,…,tn}和一 , 组类C={C1,…,Cm}。假定每个元组包括一些数 , 值型的属性值: 值型的属性值:ti={ti1,ti2,…,tik},每个类也包 , 含数值性属性值: 含数值性属性值:Cj={Cj1,Cj2,…,Cjk},则分 , 类问题是要分配每个t 类问题是要分配每个ti到满足如下条件的类Cj:
P( X | C i ) = ∏ P( xk | C i )
k =1 n
14
朴素贝叶斯分类(续)
可以由训练样本估值。 其中概率P(x1|Ci),P(x2|Ci),……,P(xn|Ci)可以由训练样本估值。 ,
是离散属性, 如果Ak是离散属性,则P(xk|Ci)=sik|si,其中sik是在属性Ak上具有值xk的 的训练样本数, 类Ci的训练样本数,而si是Ci中的训练样本数。 中的训练样本数。 如果Ak是连续值属性,则通常假定该属性服从高斯分布。因而, 是连续值属性,则通常假定该属性服从高斯分布。因而,
基于粗糙集和信息熵的多变量决策树的变压器故障诊断

中 图分 类 号 : P 8 T 1 文 献 标 识 码 : A
M uli ra e De ii n tva i t c so Tr e f r e o Tr n f r e Fa t a s m r o ul
Di g o i Ba e n u h e a d a n ss s d o Ro g S t n Co ndii n to En r py to
性 检 验 和 选择 , 现 多 变量 决 策树 的 建立 。 通过 实例 验 证 多变 量决 策树 诊 断模 型较 之 单 变量 决策 树诊 断模 型减 少 了故 障 实
信 息 的冗 余性 , 断效 率 高 , 果 易 于理 解 。 诊 结
【国家自然科学基金】_粗糙集(rs)_基金支持热词逐年推荐_【万方软件创新助手】_20140731
科研热词 粗糙集 神经网络 支持向量机 高速公路 频率规划 铁路数字移动通信 选择 识别 融资模式 约简 矿井环境监测 知识约简 相对核 相容关系矩阵 电子商务 煤层厚度预测 灰色聚类 灰色关联分析 火灾识别 汽轮机组 模糊神经网络 最小二乘支持向量机 断层预测 数据融合 敏捷定制设计 故障诊断 成组数据处理 属性约简 客户流失预测 多变量决策树 基础设施项目 噪声数据 变精度粗糙集 单变量决策树 信息融合 人工神经网络 交通事件 不完备决策表 smc rbf神经网络 d-s证据理论
2013年 序号 1 2 3 4 5 6 7 8 9 1焊 离散化 知识发现 母线负荷预测 旋转电弧 数据挖掘 支持向量机 属性约简 单病种成本 偏差识别
推荐指数 3 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
科研热词 推荐指数 粗糙集 9 支持向量机 3 未确知测度 2 预测 1 采空区 1 遥感影像 1 遗传算法 1 逼近理想解的排序法(topsis) 1 贴近度 1 质量特性 1 质量功能配置 1 置信度 1 结构尺寸效应 1 经济效益 1 精度设计 1 粗糙集理论(rs) 1 突出危险性评价 1 神经网络 1 特征加权 1 煤与瓦斯突出 1 灰色关联分析 1 概率神经网络 1 无线传感器网络 1 数控机床 1 效果评估 1 故障诊断 1 影响因素 1 定制企业 1 安全测评 1 培训 1 受训人员 1 危险度 1 危机预警 1 制粉系统 1 分类 1 分布式数据挖掘 1 克隆选择算法 1 信息系统安全保障评估模型 1 供应链质量 1 优选指标 1
基于免疫算法的分类器设计

CH E Yu -a g W ANG - h a N n f n Ru c u n
( o ue p rme tNaj gUnvri f ot n eeo mu i t n Na n 1 0 3Chn ) C mp tr De at n , ni iest o s a dT lcm nc i , mig2 0 0 , ia n y P ao
两个模式识别问题 , 讨论 了其信 息处理与学 习机制 。2 0 年 00 D su t ̄] ag pa 等人 比较 了应 用于模 式识 别 中的人 工免 疫否定 ”
选择算法和肯定选择算法 , 并用 于检测所监 控数据 的异常行 为 。20 0 2年 d at e sr C o和 Tmmi” 提出 了模式 识别 中人工 i s] [
算法[ 粗糙集[ 和支持 向量机[ 、 ] 。Lm 等人 l 从预 测准确 i g ] 度、 模型复杂性以及模型训练时间对 3 种分类算法进行 了比 3 较。 目前普遍认为不存 在某种方 法能适 合各种 特点 的数据 , 实际问题 的复杂性 以及分类方法 的本原缺 陷都使得无论 哪一 种方法都 只能解决某一类 问题 。人工免疫 系统是一种 由生物
wi lb l x l r t n c p b l y Ac o d n h rn i l fg n e o u i n n g t es lc i n a d co a e e t n,h t g o a p o a i a a i t . c r i g t e p i cp e o e e r v l t , e a i ee t n l n l l c i t e h e o i o v o s o ma h m a ia d l fca sf a i n a g rt m s g v n a d a ca sf r b s d o mmu e a g rt m s d sg e . i te t l c mo e ls i c t l o i o i o h wa ie n ls i e a e n i i n lo i h wa e i n d F — n l , h l o ih p o o e st s e n h n wrte i i r c g iin p o lm , n h o a io t t e l s al t ea g rt m r p s d wa e t d o a d i n d g t e o n to r b e a d t e c mp rs n wi o h rc a — y t h sfc to l o i m s id c t d t a th sa g e tc mp t i e e s o e o n t n r t n e o n t n c p b l y i a i n ag rt i h n ia e h t i a r a o e i v n s n r c g i o a e a d r c g i o a a i t . t i i i Ke wo d Cls i c t n, t iili y rs a sf a i Ar i ca mmu e s se , n wrte i i r c g iin i o f n y t m Ha d i n d g t e o n t t o
基于Rough Sets-C4.5的故障征兆提取与判别

第2 卷 第 1 期 7 0 20 0 6年 1 0月
东 北 大 学 学 报 ( 自 然 科 学 版 )
J un l f otes r ies y Naua S ine o ra o rhat nUnvri ( trl c c ) N e t e
Vo .7, . 0 12 No 1
Oc . 2 0 0 6 t
文 章 编号 : 10 —0 6 2 0 )013 —4 0 53 2 (0 6 1—180
基 于 R u hS t —C . o g es 4 5的 故 障征 兆提 取 与 判 别
王 庆 ,巴德 纯 ,孟 祥志
传感器用于监测温度 的变化, 压力传感器用于监 测压力的变化)以传感器代表的被测量作为条件 . 属性( 字段 , 它反映了设备的状态)设备状态作为 , 决策属性 , 建立初始决策表 , 如表 1 所示.
表 1 初始决策表
T b e 1 l ia e iin t be a l n t l c so a l i d
实现对新样本的快速诊断 . 但神经元 网络学习速
度 慢且其 网络输 出不 便 于解 释 ( 般要 加 上 解 释
器)本文研究粗糙集和决策树[ 1 C . 算法相 . 90 4 5 ,]
融合的故障诊断. 决策树【C . 是 I3的扩展算 5 45 D ]
法, 它克 服 了 I D3不 能对 连 续 属 性 进 行 处 理 , 对
终的故障诊断器 , 否则要重新调整树 的结构 . 一个 完整 的基于 R u hS t—C 5模型 的故障诊 断 o g s A. e
过程 如 图 1所示 .
原 始 信 息 系l ( 离散决策) l 1 分明函数 约简集 I
基于数据集决策树分类器研究

在 建树 阶段 ,某一 节 点 的计算 量主 要 为数据 集上 统 计信 息的 获 取 、分割 标准 的确 定 以及 对分 割后 数 据 的标示 。其 中 ,数据 集 上属 性 一 类别 表 阵列 的构 建是 算法 运行 的基 础 , 也是影 响算 法运 行 效率 的主要 部分 。 测试 结 果说 明 ,一 次扫 描与 多次 扫描 的运 行 时间相 比,前者 效果 明显优 于后 者 。其 次 , 由于 改进 算法 可 以实 现如 文献 Ⅲ中介 绍 的在节 点分 割 时生成 子 节 点的属 性一 别 表组 , 以有 效地 减少 类 所 了对 外存 的访 问 。
一
数据 记录数 。
为 D节点的子节点。然后递归地对各个节点进行分割,直至分割
终止。
实现决策树算法的主要过程有两个 :一是所需统计信息的计 算 ,二 是按照 设定 的分割 规则 对数 据集 进行 分割 。 即代 之 于数据 的 重 新 组 合 , 另 外 设 置 标 识 信 息 对 数 据 的划 分 加 以标 记 。 以 数 据集 的相应 统计 信息 即可 ,据此提 出 了 A C二维表 。如 图 i V 所 S I 、 P IT LQ S RN 为代表 , 多算法 的 改进都 是基于 这 两个过 程进 示。该思路的关键在于,对节点的每一属性分别建立相应的 AC 许 r 行 的。 表— — 即为 A Cg op后 ,求解 该节点 的分 割标准 时只 需访 问其 V-r u 二、决策树构建算法分析 对应 的 A Cgo p V —r u ,而不 必再访 问数据 集 。 SI LQ和 S RN P IT的改 进是 引入 了属性 表 、类 别 分布表 。其 基 \ h“ cBs cas 1sl 1s2 e8s 1sK a t tr i \ 本 思路如 下 : B t l[ 。 ] t r 8 i 1 ( )初始 设置 时 ,为每个 属性 建立 一个 属性表 一 属性表 的一条记 录对应 数据 集 中 的一条记 录 。属性 表 由三部 a t v l[ , 】 t r a i 2 分 构成 : 据记 录号 ,相应 的属性 值和 记录类 别 。 于连 续属 性 , 数 对 属性表 预先 按属性 值 的给定 顺序 进行 排序 。 ( )节 点分 割标准 的求 解 二 将决策树 中除叶节 点外 的任意 节点称作 内部节 点。 建树 阶段包 a t v 1 jm tr a [,] 含三个 主要步骤 :首先 ,对每 一个 内部 节点 , 取每个 属性所对应 读 图 1 Ac v 二维 表
常用的三种分类算法及其比较分析
第22卷第5期重庆科技学院学报(自然科学版)2020年10月常用的三种分类算法及其比较分析肖铮(四川工商职业技术学院,成都611830)摘要:做好数据分析处理工作,必需掌握几种分类算法。
介绍了决策树算法、朴素贝叶斯算法和最近邻算法的基本思想和分类流程,给出了应用实例,比较分析了它们各自具有的优势和存在的局限。
采用数据挖掘技术进行大数据分析要选择最合适的算法,才能获得更有效的结果(关键词:数据挖掘%决策树算法;朴素贝叶斯算法%最近邻算法中图分类号:TP301文献标识码:A文章编号:1673-1980(2020)05-0101-06数据挖掘就是通过算法从海量数据中搜索获取有用知识和信息的过程。
数据挖掘的任务主要表现为预测和描述:预测性任务就是根据其他属性的值来预测特定属性的值;描述性任务就是概括数据中潜在的联系模式(如相关性、趋势、聚类、轨迹和异常等)。
分类属于预测任务。
分类算法的目的就是构造一个分类函数或者分类模型,然后由这个模型把数据库中的数据映射到某一个给定的类别中⑷(决策法、素法最邻法的分类算法。
下面,我们将结合实例对这3种算法进行比较分析。
1决策树算法决策树算法是数据挖掘中常见且实用的分类方法,经常被用于规则提取和分类预测等领域。
J.R. Quinlan于1979年提出并在之后逐渐修正完善的ID3算法[2],是经典的决策树算法。
后来有学者在ID3的基础之上推出了效率更高、适用范围更广的C4.5算法,它既适用于分类问题,又适用于回归问题。
近几年,有南京大学周志华教授提出的“选择性集成”[3]概念被学术界所接受,并有基于遗传算法的选择性集成算法GASEN-b用于集成C4.5决策树⑷(1.〔基本思想和分类过程决策树算法在决策分类时整个过程都非常清晰。
在判断类别时,首先通过计算选择一个属性,把它放在决策树的顶端,称它为根节点;接下来从这个点分出若干个分支,任何一个分支都代表一个不同的分类特征,每个分支的另一端都连接一个新的点,称为决策点。
第3章 数据挖掘技术
YEARS TENURED 3 7 2 7 6 3 no yes yes yes no no
Classifier (Model)
IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’
数据仓库与数据挖掘
分类的实现—利用模型预测
Classifier Testing Data
数据仓库与数据挖掘
3.1.2.1 决策树算法
决策树构造的条件
构造好的决策树的关键是:如何选择好的逻辑判断 或属性。 对于同样一组样本,可以有很多决策树能符合这组 样本。 研究表明,一般情况下,树越小则树的预测能力越 强。要构造尽可能小的决策树,关键在于选择恰当 的逻辑判断或属性。 由于构造最小的树是NP问题,因此只能采用启发式 策略选择好的逻辑判断或属性。
基本的决策树构造算法没有考虑噪声,生成的决策树 完全与训练样本拟合。在有噪声的情况下,完全拟合 将导致过分拟合(overfitting),即对训练数据的 完全拟合反而不具有很好的预测性能。
数据仓库与数据挖掘
3.1.2.1 决策树算法
剪枝技术 是一种克服噪声的技术,同时它也能使树得到简化 而变得更容易理解。 剪枝的类型 向前剪枝(forward pruning)在生成树的同时决 定是继续对不纯的训练子集进行划分还是停机。 向后剪枝(backward pruning)是一种两阶段法: 拟合-化简(fitting-and-simplifying),首先 生成与训练数据完全拟合的一棵决策树,然后从树 的叶子开始剪枝,逐步向根的方向剪。
数据仓库与数据挖掘
3.1.2.1 决策树算法
剪枝的局限性
剪枝并不是对所有的数据集都好,就象最小树并不 是最好(具有最大的预测率)的树。当数据稀疏时, 要防止过分剪枝(over-pruning)。从某种意义上 而言,剪枝也是一种偏向(bias),对有些数据效 果好而有些数据则效果差。
决策树论文20篇050122
收稿日期:!""#$"#$"%基金项目:教育部博士启动基金资助项目(!""""&#%!")・作者简介:王庆(&’(")),男,辽宁沈阳人,东北大学博士研究生,讲师;巴德纯(&’%#)),男,辽宁沈阳人,东北大学教授,博士生导师・第!*卷第&期!""%年&月东北大学学报(自然科学版)+,-./01,23,.4560746./8/9:6.794;(304-.01<=96/=6)>,1?!*,3,@&!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!+0/@!""%文章编号:&""%$A "!*(!""%)"&$""B "$"#智能故障诊断的粗糙决策模型王庆,巴德纯,王晓冬(东北大学机械工程与自动化学院,辽宁沈阳&&"""#)摘要:为了提高故障诊断的精度和降低误报率,提出了粗糙决策智能故障诊断模型・该模型可以对决策表进行无教师的规则提取;通过自学习,用较少的样本即可对故障进行分类・将复杂系统的原始样本集转化成了决策表,利用粗糙集具有较强的处理不确定和不完备信息的能力,对原始样本集的条件属性进行了约简处理;同时,利用决策树具有快速学习及分类的优势对约简后的决策表进行规则提取,提高了故障诊断的鲁棒性・给出了基于该模型的故障诊断步骤・以实例介绍了利用该模型进行故障诊断的全过程・关键词:粗糙集;约简;决策树;规则;故障诊断中图分类号:C D&B !;C D&B A文献标识码:E如何从不完备及冗余数据中准确提取征兆,以提高故障诊断的鲁棒性,是近年来故障诊断的研究热点[&]・同时建立高效的故障诊断器,以提高诊断的精度和速度也受到学者的广泛关注[!]・粗糙集理论[A ]作为一种处理不确定和不精确问题的工具广泛应用于数据挖掘和模式识别领域[#!B ],近年来也被用于智能故障诊断・在故障模式的识别中,粗糙集能在保证信息不丢失的前提下,对决策系统进行有效约简,去除多余信息,减轻故障分类器的压力;同时也能进行规则提取与规则约简・但其对规则的处理多基于知识库逻辑理论,效率不高;特别是它没有给出规则间的关系,得到的规则对故障状态的推理为产生式的推理,诊断速度不高・郝丽娜等[’]提出了基于粗糙集和神经元网络的故障诊断模型,利用粗糙集对决策表进行约简,同时发挥神经元网络并行计算的优点,对故障快速分类・但神经元网络学习速度慢是实时快速故障诊断的瓶颈,并且用神经元网络的故障分类结果不便于解释,往往要加入解释器・本文研究粗糙集与决策树融合的故障诊断方法・决策树[&",&&]具有对无次序的实例进行快速分类并记忆的能力,其产生的规则是树状结构,规则间关系清晰,使得推理的结果便于解释;利用粗糙集对决策表进行离散化及约简,并用决策树提取规则产生故障分类器,达到了对故障进行快速诊断的目的,并以实例验证了该模型的有效性・&理论基础定义!!F 〈",#,$,%〉为信息系统,其中"F {&&,&!,…,&’}为全体样本集(论域)・#F (")为全部属性集,(为条件属性集,)为决策属性集,(#)F !・$为全部属性的值域,设*是任一属性,&+是任一个对象,则%(&+,*)表示&+在*属性的取值・定义"设任一属性子集,$#,-(,)F {(&+,&.)%"!&’*%,,%(&+,*)F %(&.,*)},二元关系-(,)称为不可分辨关系・属性子集,将全部样本"划分成若干等价类,称为,基本元素・,基本元素中的任意两个对象&,/关于,是不可区分的,称&,/在属性集合,上不可分辨・决策表可以看作是"的一族等价关系,即知识库・定义#,$#,0$";,0F "{1%"/23)(,):1$0};,0F ";{1%"/23)(,):1#0(!}分别称为下近似和上近似・定义$"((,))为近似质量・如果(4是(去掉某些条件属性后的条件属性集合,并能保持近似质量不变,即:"((4,))F "((,))则(4为(的一个)约简,其中"((,))5)0%"/)6(066"6・万方数据定义!令!"#($)为$所有约简的集合,%&!"($)!!!"#($)为$的属性约简的核・!!(%’())")为信息系统*的分明矩阵,%’(!{+"%#+(,’)$+(,()},’,(!#,$,…,);-(%)!!{%.’(:#&(&’&);.’($%}为分明函数・定义"设/!(0#,0$,…,0’,…,01)为信源发出的信息;2!(3#,3$,…,3’,…,34)为信宿收到的信息・5(0’)为0’发生的概率;5(3(/0’)为收到3(后判定为0’的概率・6(/)78’5(0’)&’($5(0’)为信息/所能提供的信息量(熵)・6/()27’(5(3()’’50’3()(&’($50’3()(为信宿收到全部信息2后对信源发出的信息/的不确信性・定义#收到2后获得关于/的信息量为9!6(:))6(:/;),为平均互信息量或熵降量,它表示2能提供的关于/的信息量的大小・$基于粗糙决策模型故障诊断步骤故障诊断中的条件属性多为连续值,为了对其进行约简和规则提取要对其进行离散化处理・即在连续的属性域上寻找若干个断点,用断点将连续的属性值划分为离散的区间・最后用离散的决策表代替了原来的连续的决策表・然后根据定义求取决策表分明矩阵,根据分明矩阵求取其分明函数,并将分明函数化简成若干合取的析取式形式,则析取式中每个合取对应一个条件属性约简的结果・所谓规则的提取就是从约简决策表中得到推理规则集,该规则集是用来对一个新对象(新设备状态)进行分类的故障诊断器・本文采用决策树*+,算法对约简表进行规则提取・*+,算法是利用信息论中的信息熵降作为评判函数・它在决策表(属性集)上寻找一个最佳的分类条件属性,该属性作为决策树的一个分支节点(该节点上条件属性的熵降最大)・然后再根据该节点上条件属性的值进行分支,选取其中一个分支再根据最大熵降从其他条件属性中搜索最佳属性作为下一级的新节点,直到形成一个完整的决策树・该决策树即为故障诊断的规则集・该规则集作为故障分类器对故障进行诊断・最后给定一个测试集,用上述粗糙决策故障诊断模型对测试集中的各个对象进行分类,得到每一个对象对应的设备状态・,基于粗糙决策模型故障诊断算例以上海宝钢-./012设备为对象,对其进行了状态量的获取,分别提取了各种过程量(如水蒸气、冷凝水及各种压力)的原始数据信息・并建立如下信息系统,*!(/,$%#),/为对象集,即-./012设备状态集;$!{+#,+$,…,+#3}代表条件属性,即代表-./012各个参量域集・其中,+’,’!#,$,…,#4分别代表系统真空度<%,一级泵入口压力<#,二级泵入口压力<$,三级泵入口压力<,,四级泵入口压力<4,水池压力<3,系统入口温度=%,冷凝器#回水温度=#,冷凝器$回水温度=$,水蒸气流量4(,冷凝水流量45,水蒸气温度=(,冷凝水温度=5,水蒸气压力<(,冷凝水压力<5・#!{>}为决策属性,>!’,’!#,$,…,#$分别代表设备的状态(水蒸气压力、流量太低;四级泵故障;冷凝器$回水温度太高;冷凝水温度太高;冷凝水压力、流量太低;水蒸气温度过高;水蒸气压力、流量太低;三级泵抽气故障;冷凝器#回水温度过高;冷凝器#故障;一级泵故障;系统状态正常)・对决策表进行离散化处理,并用符号代表离散决策表中各个条件属性的分段值(自然数#,%,$分别代表偏大,中间,偏低的分段),得离散化的决策表并用矩阵"表示,阵中’!#,$,…,#4代表对象集;(!#表示为对象域,(!$,,,…,#6表示条件属性;(!#7表示决策属性・根据离散化的决策表首先求取决策表的分明矩阵并根据分明函数-的定义对分明矩阵进行约简计算,即计算分明函数-的最小析取范式・其中,每一个析取分量对应一个约简・从中任选一个约简,该约简对应的决策表用矩阵"(表示・"7#%%%%#%%%%$%%%$%#$%%%%#%%%%%%%%%%$,%%%#%%%%#%%%%%%,4%%%#%%%%%%%%#%%43%%%#%%%%%%$%%%$36%%%#%%%%%%%$%%%67%%%#%%%%%$%%%$%78%%%#%%%%%%%%%%%89%%#%%%%#%%%%%%%9#%%%#%%%%%%%%%%%%#%####%%%%%%%%%$%%%6#$##%%%%%%%%%%%%%###,##%%%%%%%$%%%$%#)*+,#4%%%%%%%%%%%%%%%#$#8第#期王庆等:智能故障诊断的粗糙决策模型万方数据!!!!"""!""""""!#"""!""#"""#$""!""!""""$%""!""""""!%&""!""""#""&’""!"""""#"’(""!"""#"""()""!""""""")*"!""!"""""*!""!""""""""!"!!!"""""""#"’!#!"""""""""!!!$!"""""#"""!"#$%!%""""""""""!#由矩阵!和!!可见经过了属性的约简,去除了信息系统的多余属性,使决策表得到了简化・用属性"","#,"$,"%,#!,##,$+,$,,#+,#,所包含的信息可完全代表原来决策表中的信息,达到了约简的目的・约简!!对应的决策表中有!#种不同的决策属性,即有!#种故障类型,其中有!%个样本・根据决策树-.$算法,首先计算决策表的初始熵:%(&)!’#!%/0+##!%’#!%/0+##!%’!"!%/0+#!"!%!$(&#・计算属性""的条件熵:%(&/"")!$!%’$$/0+#()!$)!!!%’!!!!/0+#!()!!!$("&((・同理计算其他属性的条件熵・经计算得知"$的条件熵最小说明其熵降最大,所以选择"$为第一级结点・"$有两个分支,"$1"和"$1!・分别以这两个分支为起点计算・以"$1"分支计算其对应的初始熵和条件熵・经计算得知"#和$+的条件熵最小说明其熵降最大,所以任选"$为第二级结点・"#有两个分支,"#1"和"#1!・分别再以这两个分支为起点计算・"#1!分支计算得#!为其下级结点,同理计算#!的两个分支的初始熵为"说明它不能再分,都为最终接点(叶接点),分别对应于故障*和故障!"・以次类推・逐步计算各级结点和叶结点,最后得到决策树如图!所示・从图!可见利用决策树-.$算法形成了以下!$条规则:"$1!&##1"’*1$;"$1!&##1!&#+1#’*1’;"$1!&##1!&#+1"&$,1#’*1&;"$1!&##1!&#+1"&$,1"&#,1!’*1%;"$1!&##1!&#+1"&$,1"&#,1"&$+1"’*1’;"$1!&##1!&#+1"&$,1"&#,1"&$+1"’*1(;"$1"&"#1!&#!1"’*1!";"$1"&"#1!&#!1!’*1*;"$1"&"#1"&$+1#’*1!;"$1"&"#1"&$+1"&""1!&#+1"’*1!!;"$1"&"#1"&$+1"&""1!&#+1#’*1’;"$1"&"#1"&$+1"&""1"&"%1"’*1!#;"$1"&"#1"&$+1"&""1"&"%1!’*1#・图!"#$%&’决策树图()*+!,-.)/)0123--04"#$%&’234567粗糙决策故障诊断的故障分类器(诊断器)就由上述!$条规则组成・由!!可见,*1)对应的条件属性集包含于*1$,*1%,*1&,*1’,*1(的条件属性集,所以上述规则中没有对故障类型*1)进行推理,即由决策树-.$算法自动形成的决策树中不包含故障类型*1)的叶结点・看来决策树-.$算法也能够对一些特例进行排除,说明具有规则的过滤能力・给定包含!$对象的测试集",应用该模型对其诊断,结果见表!・"!!""""!""""#"""#"#""!""""""""""""$!!"""""""""#"""%"""!""""""""!""&!!"""""""""""""’"""!""""""#"""#("""!"""""""#""")"""""""""#"""#"*"""""""""""""""!"""""!""""""""""!!"""!""""!""""""!#!!"""""""#"""#""#$%!$""!""""!"""""""・#)东北大学学报(自然科学版)第#’卷万方数据表!故障诊断结果"#$%&!’&()%*+,,#)%*-.#/0+(.(样本对象诊断结果!!"!#$%&&’!!%’(%样本对象诊断结果)(*!"!#"!!$!"!!$*与训练集比较表明,上述分类结果完全正确,这说明该粗糙决策故障诊断模型能够对+,-./0的故障进行正确的诊断・&结论复杂系统故障诊断中,数据样本集中有大量重复样本和冗余属性,甚至干扰信息;粗糙集能够对包含干扰和冗余信息的决策表进行约简处理并提取征兆,表现出较强的鲁棒性・决策树可以对决策表进行快速无教师的规则提取,得到树状规则集,诊断时它用较少的属性即可对故障进行分类,适用于快速故障分类・因此基于粗糙集和决策树理论相融合的故障诊断技术对复杂系统的快速鲁棒故障诊断具有现实意义・参考文献:[!]1234,/5678,,9:14;75:<=>25?@A B 2B :B 2@?C A :?D BE =B =D E A C 6[F ];!"#$%&’()*+,+-%)&(.,"###,&$($):%!G (";["]陶志,许宝栋,汪定伟・基于决策属性支持度的知识约简方法[F ]・东北大学学报(自然科学版),"##","$(!!):!#"’G !#")・(/5A H ,3:0I ,J 5@?I J;.@A K <E >?EC E >:L =2A @5M M C A 5L DN 5B E >A @>E L 2B 2A @5==C 2N :=EB :M M A C =>E ?C E E [F ];/"%(+01"23"(&4’0)&’(+5+*6’()*&.(30&%(0178*’+8’),"##","$(!!):!#"’G !#");)[$]O 5K <5P H ;+A :?D B E =B [F ];,+&’(+0&*"+01/"%(+01"2!"#$%&’(0+-,+2"(#0&*"+78*’+8’),!*)",!!(’):$&!G $’%;[&]F E <A @E PF ;+A :?DB E =BC E >:L =2A @A Q5==C 2N :=E B5@>=D E 2C >A R 52@B Q A C @E :C 5<@E =K A C P B [F ];!"#$%&*"+01,+&’11*9’+8’,!**’,!!("):$$*G $&(;[’]黎明,张化光・基于粗糙集的神经网络建模方法研究[F ]・自动化学报,"##",")(!):"(G $$・(12S ,H D 5@?,T ;+E B E 5C L DA @=D E R E =D A >A Q@E :C 5<@E =K A C PR A >E <2@?N 5B E >A @C A :?DB E =B=D E A C 6[F ];:8&0:%&"#0&*807*+*80,"##",")(!):"(G $$;)[%]O 5K <5PH ;+A :?D B E =5M M C A 5L D =AP @A K <E >?E -N 5B E >>E L 2B 2A @B :M M A C =[F ];;%("$’0+/"%(+01"2<$’(0&*"+01=’)’0(84,!**(,**(%):&)G ’(;[(]U D 2E @UU ;V C A :?D B E =5M M C A 5L D =A 5==C 2N :=E ?E @E C 5<2W 5=2A @2@>5=5R 2@2@?[F ];/"%(+01"2,+2"(#0&*"+78*’+8’),!**),!#((&):!%*G !(%;[)].C 6B W P 2E K 2L W S;+A :?D B E =5M M C A 5L D =A 2@L A R M<E =E 2@Q A C R 5=2A @B 6B =E R B [F ];,+2"(#0&*"+78*’+8’),!**),!!"("):$*G &*;[*]郝丽娜,王伟,吴光宇,等・粗糙集-神经网络故障诊断方法研究[F ]・东北大学学报(自然科学版),"##$,"&($):"’"G "’’・(,5A 1X ,J 5@?J ,J :TY ,’&01;+E B E 5C L D A @C A :?D BE =-@E :C 5<@E =K A C P Q 5:<=>25?@A B 2B R E =D A >[F ];/"%(+01"23"(&4’0)&’(+5+*6’()*&.(30&%(0178*’+8’),"##$,"&($):"’"G "’’;)[!#]9:2@<5@F +;Z @>:L =2A @A Q>E L 2B 2A @=C E E B [F ];>084*+’?’0(+*+9,!*)%,!(!):)!G !#%;[!!]9:2@<5@F+;42R M <2Q 62@?>E L 2B 2A @=C E E B [F ];,+&’(+0&*"+01/"%(+01"2>0+@>084*+’7&%-*’),!*)(,"((!):""!G "$&;Z @=E <<2?E @=75:<=I 25?@A B 2B S A >E <05B E >A @+A :?D4E =B5@>I E L 2B 2A @/C E E/D E A C 6A :3BC *+9,D :E ’@84%+,A :3BF *0"@-"+9(4L D A A <A Q S E L D 5@2L 5<8@?2@E E C 2@?[V :=A R 5=2A @,X A C =D E 5B =EC @\@2]E C B 2=6,4DE @65@?!!###&,U D 2@5;U A C C E B MA @>E @=:J V X T92@?,8-R 52<:K 5@?^2@?@E :!B A D :;L A R )!"#$%&’$:+A :?D B E =B 5@>>E L 2B 2A @=C E E =DE A C 65C E 2@=C A >:L E >2@L A R M <2L 5=E >2@=E <<2?E @=Q 5:<=>25?@A B 2B B 6B =E R (U Z 7I 4);VC A :?D ->E L 2B 2A @Q 5:<=>25?@A B 2BR A >E <2B =D :B >E ]E <A M E >=A E @B :C E >25?@A B 2B M C E L 2B 2A @5@>B M E E >:M =D E 2R M <E R E @=5=2A @A Q U Z 7I 4;/D ER A >E <L 5@E _=C 5L =C :<E B >2C E L =<6Q C A RC E >:L E >>E L 2B 2A @=5N <E ;+A :?D B E =B =D E A C 65B 5@E KR 5=D E R 5=2L 5<=A A <2B :B E >=A >E 5<K 2=D 2@E _5L =5@>:@L E C =52@P @A K <E >?E Q A C M 5==E C @C E L A ?@2=2A @;/D E =5C ?E =2BR 52@<6=A C E R A ]E C E >:@>5@=2@Q A C R 5=2A @5@>B E E P Q A C C E >:L E >>E L 2B 2A @=5N <E B ;V B 5^:2L P <6<E 5C @2@?=D E A C 65@>L <5B B 2Q 2L 5=2A @=A A <,>E L 2B 2A @=C E E 2B :B E >=A E _=C 5L =C :<E B >2C E L =<6Q C A R C E >:L E >>E L 2B 2A @=5N <E B A5B =A5L ^:2C E B 5=2B Q 5L =A C 6C E B :<=;V @E _5R M <E 2B ?2]E @=AB D A K D A K=A5M M <6=D E 2@=E <<2?E @=Q 5:<=>25?@A B 2B =A +,-./0]5L ::R R E =5<<:C ?2L 5<B 6B =E R ;/D EE Q Q E L =2]E @E B BA Q=D E5<?A C 2=D R2B=D E C E Q A C E M C A ]E >=D C A :?D=D E E _E R M<2Q 2L 5=2A @;()*+,%-#:C A :?D B E =B ;C E >:L =2A @;>E L 2B 2A @=C E E ;C :<E ;Q 5:<=>25?@A B 2B (=’8’*6’-:$(*1’,"##&)$)第!期王庆等:智能故障诊断的粗糙决策模型万方数据。
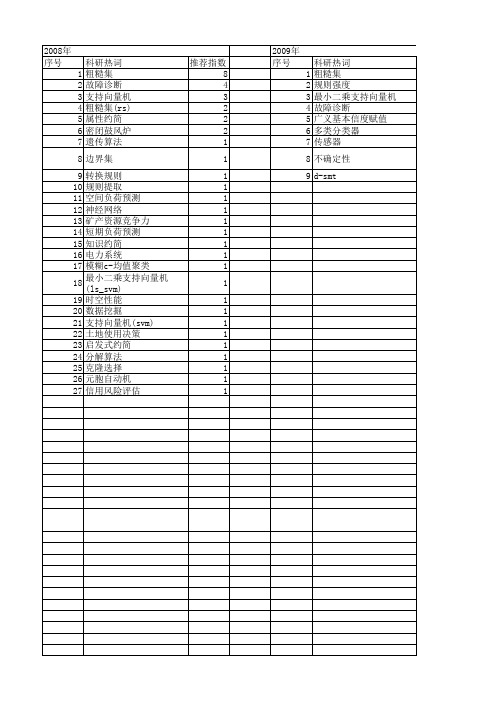
【计算机工程与设计】_rough set_期刊发文热词逐年推荐_20140726
推荐指数 12 6 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10
2011年 科研热词 风险评估 计算机免疫 粗糙集权重计算 粗糙概念格 粗糙形式概念 模型 抗体浓度 形式背景 形式概念抽取 属性集合幂集 推荐指数 1 1 1 1 1 1 1 1 1 1
科研热词 粗糙集 属性约简 粗糙集理论 相似粗糙集 权值 故障诊断 属性依赖度 启发式信息 决策规则 遗传算法 适应度函数 规则提取 航空发动机 网络安全 约简 粗集理论 粗集 粒度化 算法 等价类 离散化 知识量 相关系数 相关度 熵 模糊认知图 概念格 树 条件熵 条件属性 断点核 文本分类 数据挖掘 数据库安全 数字水印 推理 属性重要性 层次聚类 层次分析法 小生境 安全评价 图像分割 变精度粗糙集 分类 分明矩阵 分布约简 决策表 决策树 决策数据库 冗余项集 关联规则 关系数据
科研热词 粗糙集 属性约简 遗传算法 属性重要度 区分矩阵 齿轮箱 饱和度 质量管理 规则相容度 规则提取 规则准确度 神经网络 相对可辨识矩阵 特征降维 渗透率 模糊聚类 模糊划分 核 数据挖掘 故障诊断 故障识别 支持向量回归 广义重要度 广义欧氏距离 差别矩阵 属性 孔隙度 启发式算法 启发式信息 同被引 变电站 动态聚类法 动态划分 分辨矩阵 关联规则 关联度 值约简 信息熵 专利文献 gis fcm聚类
推荐指数 6 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41