常用的正则
linux awk正则表达式

linux awk正则表达式正则表达式是在文本处理中常用的一种工具,它可以用来匹配、搜索和替换文本中的特定模式。
在Linux系统中,awk是一种流程控制语言,也可以使用正则表达式来处理文本。
以下是一些常用的正则表达式及其含义:1. ^(脱字符号):匹配字符串的开始位置。
例如,^abc表示以字符串“abc”为开头的字符串。
2. $(美元符号):匹配字符串的结束位置。
例如,abc$表示以字符串“abc”为结尾的字符串。
3. .(句号):匹配任意单个字符,但不包括换行符。
例如,a.b可以匹配“aab”、“acb”、“adb”等字符串。
4. *(星号):匹配前面的字符出现零次或多次。
例如,a*b可以匹配“ab”、“aab”、“abb”等字符串。
5. +(加号):匹配前面的字符出现一次或多次。
例如,a+b可以匹配“ab”、“aab”、“abb”等字符串。
6. ?(问号):匹配前面的字符出现零次或一次。
例如,a?b可以匹配“b”、“ab”等字符串。
7. [](方括号):匹配方括号内的任意一个字符。
例如,[abc]可以匹配“a”、“b”、“c”中的任意一个字符。
8. [^](脱字符号和方括号):不匹配方括号内的任意一个字符。
例如,[^abc]可以匹配不含a、b、c字符的任意一个字符。
9. ()(圆括号):捕获匹配的内容。
例如,(ab)+可以匹配“ab”、“abab”、“ababab”等字符串,并会将匹配的内容保存在分组中。
以上只是部分常用的正则表达式,实际使用时还需根据具体场景进行调整。
在awk中,可以使用-F选项来指定分隔符,并使用$1、$2等符号来代表从左往右数的第一、二个字段等。
可以结合正则表达式来解决一些文本处理问题。
例如,下面的命令可以将文件中的所有单词转换成大写字母:awk '{for(i=1;i<=NF;i++) $i=toupper($i)}1' file.txt其中,NF表示当前行的字段数,toupper函数用于将字符串转换成大写字母。
爬虫常用正则、re.findall使用

爬⾍常⽤正则、re.findall使⽤爬⾍常⽤正则爬⾍经常⽤到的⼀些正则,这可以帮助我们更好地处理字符。
正则符单字符. : 除换⾏以外所有字符[] :[aoe] [a-w] 匹配集合中任意⼀个字符\d :数字 [0-9]\D : ⾮数字\w :数字、字母、下划线、中⽂\W : ⾮\w\s :所有的空⽩字符包,括空格、制表符、换页符等等。
等价于 [ \f\n\r\t\v]\S : ⾮空⽩数量修饰* : 任意多次 >=0+ : ⾄少1次 >=1: 可有可⽆ 0次或者1次{m} :固定m次 hello{3,}{m,} :⾄少m次{m,n} :m-n次边界$ : 以某某结尾^ : 以某某开头分组(ab)贪婪模式.*⾮贪婪惰性模式.*?# 1 提取出python'''key = 'javapythonc++php're.findall('python',key)re.findall('python',key)[0]'''# 2 提取出 hello word'''key = '<html><h1>hello word</h1></html>'print(re.findall('<h1>.*</h1>', key))print(re.findall('<h1>(.*)</h1>', key))print(re.findall('<h1>(.*)</h1>', key)[0])'''# 3 提取170'''key = '这个⼥孩⾝⾼170厘⽶'print(re.findall('\d+', key)[0])'''# 4 提取出http://和https://'''key = ' and https://'print(re.findall('https?://', key))'''# 5 提取出 hello'''key = 'lalala<hTml>hello</HtMl>hahaha' # 输出的结果<hTml>hello</HtMl>print(re.findall('<[hH][tT][mM][lL]>.*[/hH][tT][mM][lL]>',key))'''# 6 提取hit. 贪婪模式;尽可能多的匹配数据'''key = 'qiang@' # 加?是贪婪匹配,不加?是⾮贪婪匹配print(re.findall('h.*?\.', key))'''# 7 匹配出所有的saas和sas'''key = 'saas and sas and saaas'print(re.findall('sa{1,2}s',key))'''# 8 匹配出 i 开头的⾏'''key = """fall in love with youi love you very muchi love shei love her"""print(re.findall('^i.*', key, re.M))'''# 9 匹配全部⾏'''key = """<div>细思极恐你的队友在看书,你的闺蜜在减肥,你的敌⼈在磨⼑,隔壁⽼王在练腰.</div>"""print(re.findall('.*', key, re.S))'''案例题re.findall 使⽤1、re.findall 可以对多⾏进⾏匹配,并依据参数作出不同结果。
js常用的正则表达式

js常用的正则表达式前言JavaScript中的正则表达式被广泛用于字符串的匹配和替换,可以让代码更加优雅和高效。
本文将介绍JS中常用的正则表达式及其用法,希望能对初学者有所帮助。
一、基本语法正则表达式由字面值和特殊字符两种类型组成。
字母、数字、空格等都表示字面值,而特殊符号则表示特定含义,例如/d代表数字,/s代表空格等。
正则表达式用斜杠“/”将其包裹起来。
二、常用正则表达式1. 匹配IP地址/^(\d{1,3}\.){3}\d{1,3}$/使用说明: \d表明是数字,{1,3}表明可以是一个到三个数字,\.表示点,^表示字符串开始,$表示字符串结束。
2. 匹配邮箱/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/使用说明: \w表示字母数字下划线,[-+.]表示这些特殊字符中的一个,*表示出现零次或多次。
3. 匹配电话号码/^[1][3,4,5,7,8][0-9]{9}$/使用说明: [1]表示以1开头,[3,4,5,7,8]表示第二个数字只能是这些中的一个,[0-9]{9}表示后面必须跟九个数字。
4. 匹配URL地址/^(http|https):\/\/[a-zA-Z0-9]+[\.a-zA-Z0-9_-]*[a-zA-Z0-9]+(\/\S*)?$/使用说明: (http|https)表示http或https,\/\/表示两个斜杠,[a-zA-Z0-9]表示字母数字任意一个,+表示一个或多个,[\.a-zA-Z0-9_-]*表示出现零次或多次,\/表示斜杠,\S表示任意一个非空白字符。
5. 匹配HTML标签/<\/?[^>]+>/gi使用说明: \?表示出现零次或一次,[^>]表示不是大于号的字符,+表示一个或多个,/i使匹配忽略大小写,/g表示全局匹配。
6. 匹配中文字符/[\u4e00-\u9fa5]/使用说明: [\u4e00-\u9fa5]表示从\u4e00到\u9fa5这个区间的所有字符。
python常用的正则表达式大全
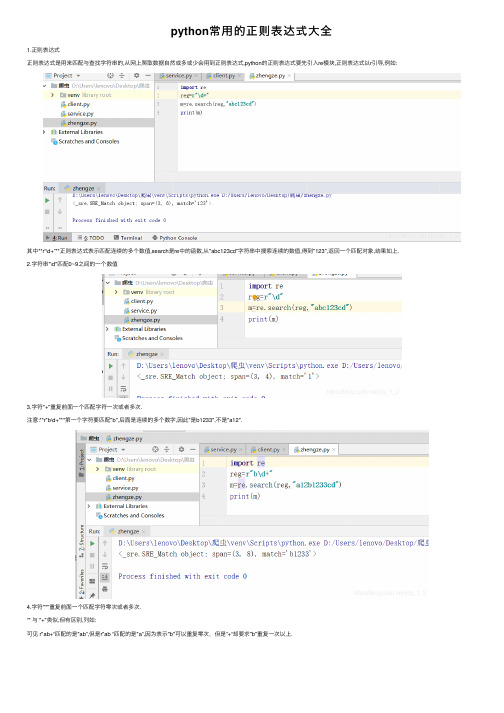
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
flutter 常用正则

flutter 常用正则在Flutter中,你可以使用Dart语言的正则表达式库,通常是dart:core库中的RegExp类。
以下是一些在Flutter中常用的正则表达式示例:匹配邮箱地址:RegExp emailRegex = RegExp(r'^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$');匹配手机号码:RegExp phoneRegex = RegExp(r'^[1-9][0-9]{10}$');匹配URL:RegExp urlRegex = RegExp(r'^(http|https):\/\/[\w-]+(\.[\w-]+)+([\w.,@?^=%&:/~ +#-]*[\w@?^=%&/~+#-])?$');匹配数字:RegExp numberRegex = RegExp(r'^\d+$');匹配日期(yyyy-mm-dd):RegExp dateRegex = RegExp(r'^\d{4}-\d{2}-\d{2}$');匹配用户名(由字母、数字、下划线组成,长度在3到16位之间):RegExp usernameRegex = RegExp(r'^[a-zA-Z0-9_]{3,16}$');匹配密码(至少包含一个大写字母、一个小写字母、一个数字,长度在8到16位之间):RegExp passwordRegex = RegExp(r'^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,16}$');以上只是一些常见的正则表达式示例。
具体的正则表达式应根据你的具体需求进行调整。
在Flutter中使用这些正则表达式时,你可以使用RegExp类的hasMatch方法来检查一个字符串是否匹配某个正则表达式。
常用正则表达式,手机号、固话号、身份证号等

常⽤正则表达式,⼿机号、固话号、⾝份证号等⼿机号码正则表达式验证function checkPhone(){var phone = document.getElementById('phone').value;if(!(/^1[34578]\d{9}$/.test(phone))){alert("⼿机号码有误,请重填");return false;}}或者是function checkPhone(){var phone = document.getElementById('phone').value;if(!(/^1(3|4|5|7|8)\d{9}$/.test(phone))){alert("⼿机号码有误,请重填");return false;}}注:⼩括号就是括号内看成⼀个整体 ,中括号就是匹配括号内的其中⼀个正则⾥⾯的中括号[]只能匹配其中⼀个,如果要匹配特定⼏组字符串的话,那就必须使⽤⼩括号()加或|,我还以为在中括号中也能使⽤或|符号,原来|在中括号⾥⾯也是⼀个字符,并不代表或。
[3457]匹配3或者4或者5或者7,⽽(3457)只匹配3457,若要跟前⾯⼀样可以加或(3|4|5|7)。
[34|57]匹配3或者4或者|或者5或者7.⽽(34|57)能匹配34或者57。
固定电话号码正则表达式:function checkTel(){var tel = document.getElementById('tel').value;if(!/^(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}$/.test(tel)){alert('固定电话有误,请重填');return false;}}⾝份证校验//⾝份证正则表达式(15位)isIDCard1=/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/;//⾝份证正则表达式(18位)isIDCard2=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$/;⾝份证正则合并:(^\d{15}$)|(^\d{17}([0-9]|X)$)提取信息中的⽹络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*提取信息中的图⽚链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}提取信息中的中国邮政编码:[1-9]{1}(\d+){5}提取信息中的中国⾝份证号码:\d{18}|\d{15}提取信息中的整数:\d+提取信息中的浮点数(即⼩数):(-?\d*)\.?\d+提取信息中的任何数字:(-?\d*)(\.\d+)?提取信息中的中⽂字符串:[\u4e00-\u9fa5]*提取信息中的双字节字符串 (汉字):[^\x00-\xff]*使⽤⽅法:test()⽅法在字符串中查找是否存在指定的正则表达式,并返回布尔值,如果存在则返回true,否则返回false。
实用正则表达式匹配和替换大全
实⽤正则表达式匹配和替换⼤全正则表达式⾮常有⽤,查找、匹配、处理字符串、替换和转换字符串,输⼊输出等。
⽽且各种语⾔都⽀持,例如.NET正则库,JDK正则包, Perl, JavaScript等各种脚本语⾔都⽀持正则表达式。
下⾯整理⼀些常⽤的正则表达式。
字符描述\将下⼀个字符标记为⼀个特殊字符、或⼀个原义字符、或⼀个向后引⽤、或⼀个⼋进制转义符。
例如,'n' 匹配字符 "n"。
'\n' 匹配⼀个换⾏符。
序列 '\\' 匹配 "\" ⽽ "\(" 则匹配 "("。
^匹配输⼊字符串的开始位置。
如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
$匹配输⼊字符串的结束位置。
如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
*匹配前⾯的⼦表达式零次或多次。
例如,zo* 能匹配 "z" 以及 "zoo"。
*等价于{0,}。
+匹配前⾯的⼦表达式⼀次或多次。
例如,'zo+' 能匹配 "zo" 以及"zoo",但不能匹配 "z"。
+ 等价于 {1,}。
匹配前⾯的⼦表达式零次或⼀次。
例如,"do(es)?" 可以匹配 "do" 或"does" 中的"do" 。
? 等价于 {0,1}。
{n}n是⼀个⾮负整数。
匹配确定的n次。
例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。
python常用正则表达式
python常用正则表达式
正则表达式是一种用于匹配文本模式的工具,是Python中的一项重要功能。
以下是Python中常用的正则表达式:
1. 匹配任意字符:使用“.”符号表示任意一个字符(除了换行符)
2. 匹配特定字符:使用方括号“[]”表示需要匹配的字符集合,如[abc]表示匹配a、b、c三个字符中的任意一个。
3. 匹配某个范围内的字符:使用“-”符号表示要匹配的字符范围,如[a-z]表示匹配小写字母a到z中的任意一个。
4. 匹配重复字符:使用“*”符号表示前面的字符可以重复出现任意次数,如a*表示匹配0个或多个a字符。
5. 匹配固定数量的字符:使用“{n}”表示前面的字符必须出现n次,如a{3}表示匹配3个a字符。
6. 匹配至少n次、至多m次的字符:使用“{n,m}”表示前面的字符必须出现至少n次、至多m次,如a{1,3}表示匹配1到3个a 字符。
7. 匹配任意多个字符:使用“+”符号表示前面的字符可以出现1次或多次,如a+表示匹配至少一个a字符。
8. 匹配开头或结尾的字符:使用“^”符号表示以指定字符开头,使用“$”符号表示以指定字符结尾,如^a表示以a字符开头,a$表示以a字符结尾。
以上是Python中常用的正则表达式,掌握这些基本规则可以帮
助开发者更快、更准确地匹配文本模式。
java常用正则表达式
java常用正则表达式在Java编程语言中,正则表达式是一种优秀的字符串匹配工具,可以用于搜索、替换和分割字符串。
Java标准库中提供了强大的正则表达式类库,让我们可以轻松地进行复杂的字符串操作。
下面我们将以分步骤的方式介绍Java中常用的正则表达式。
1. 字符组字符组用于匹配一组字符中的任意一个字符。
在正则表达式中,字符组以中括号“[]”表示。
例如,正则表达式“[abc]”可以匹配字符“a”、“b”或“c”。
2. 范围字符组范围字符组用于匹配一组连续的字符。
在正则表达式中,范围字符组以中括号“[]”表示,并在其中用短横线“-”表示范围。
例如,正则表达式“[a-z]”可以匹配任何小写字母;正则表达式“[0-9]”可以匹配任何数字。
3. 非字符组非字符组用于匹配不在一组字符中的任意一个字符。
在正则表达式中,非字符组以中括号“[]”表示,并在其中用排除符号“^”表示非。
例如,正则表达式“[^abc]”可以匹配任何不是字符“a”、“b”或“c”的字符。
4. 点字符点字符用于匹配任意一个字符(除了换行符)。
在正则表达式中,点字符以英文句点“.”表示。
例如,正则表达式“a..b”可以匹配任何以字符“a”开头、以字符“b”结尾、中间有两个任意字符的字符串。
5. 匹配次数匹配次数用于限定一个字符或字符组重复出现的次数。
在正则表达式中,常用的匹配次数包括:- *:匹配0次或多次;- +:匹配1次或多次;- ?:匹配0次或1次;- {n}:匹配n次;- {n,}:匹配至少n次;- {n,m}:匹配n至m次。
例如,正则表达式“ab*c”可以匹配任何以字符“a”开头、以字符“c”结尾、中间有0个或多个字符“b”的字符串。
6. 锚点锚点用于限制匹配的位置。
在正则表达式中,常用的锚点包括:- ^:匹配字符串的开头;- $:匹配字符串的结尾;- \b:匹配单词边界;- \B:匹配非单词边界。
例如,正则表达式“^hello”可以匹配以“hello”开头的字符串。
只能输入正整数的正则表达式及常用的正则表达式
只能输⼊正整数的正则表达式及常⽤的正则表达式<input type='text' id='SYS_PAGE_JumpPage' name='SYS_PAGE_JumpPage' size='3' maxlength='5' onkeyup='this.value=this.value.replace(/[^1-9]/D*$/,"")' ondragenter="return false" onpaste="return !clipboardData.getData('text').match(//D/)"" style="ime-mode 1.只能输⼊数字和英⽂的:<input onkeyup="value=value.replace(/[/W]/g,'') " onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))" ID="Text1" NAME="Text1">2.只能输⼊数字的:<input onkeyup="value=value.replace(/[^/d]/g,'') " onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))" ID="Text2" NAME="Text2">3.只能输⼊全⾓的:<input onkeyup="value=value.replace(/[^/uFF00-/uFFFF]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/uFF00-/uFFFF]/g,''))" ID="Text3" NAME="Text3">4.只能输⼊汉字的:<input onkeyup="value=value.replace(/[^/u4E00-/u9FA5]/g,'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/u4E00-/u9FA5]/g,''))" ID="Text4" NAME="Text4">5.邮件地址验证:var regu = "^(([0-9a-zA-Z]+)|([0-9a-zA-Z]+[_.0-9a-zA-Z-]*[0-9a-zA-Z]+))@([a-zA-Z0-9-]+[.])+([a-zA-Z]{2}|net|NET|com|COM|gov|GOV|mil|MIL|org|ORG|edu|EDU|int|INT)$"var re = new RegExp(regu);if (s.search(re) != -1) {return true;} else {window.alert ("请输⼊有效合法的E-mail地址!")return false;}6.⾝份证:"^//d{17}(//d|x)$"7.17种正则表达式"^//d+$" //⾮负整数(正整数 + 0)"^[0-9]*[1-9][0-9]*$" //正整数"^((-//d+)|(0+))$" //⾮正整数(负整数 + 0)"^-[0-9]*[1-9][0-9]*$" //负整数"^-?//d+$" //整数"^//d+(//.//d+)?$" //⾮负浮点数(正浮点数 + 0)"^(([0-9]+//.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*//.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数"^((-//d+(//.//d+)?)|(0+(//.0+)?))$" //⾮正浮点数(负浮点数 + 0)"^(-(([0-9]+//.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*//.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数"^(-?//d+)(//.//d+)?$" //浮点数"^[A-Za-z]+$" //由26个英⽂字母组成的字符串"^[A-Z]+$" //由26个英⽂字母的⼤写组成的字符串"^[a-z]+$" //由26个英⽂字母的⼩写组成的字符串"^[A-Za-z0-9]+$" //由数字和26个英⽂字母组成的字符串"^//w+$" //由数字、26个英⽂字母或者下划线组成的字符串"^[//w-]+(//.[//w-]+)*@[//w-]+(//.[//w-]+)+$" //email地址"^[a-zA-z]+://(//w+(-//w+)*)(//.(//w+(-//w+)*))*(//?//S*)?$" //url=============================================1.取消按钮按下时的虚线框 在input⾥添加属性值 hideFocus 或者 HideFocus=true2.只读⽂本框内容在input⾥添加属性值 readonly3.防⽌退后清空的TEXT⽂档(可把style内容做做为类引⽤) <INPUT style=behavior:url(#default#savehistory); type=text id=oPersistInput>4.ENTER键可以让光标移到下⼀个输⼊框 <input onkeydown="if(event.keyCode==13)event.keyCode=9" >5.只能为中⽂(有闪动) <input onkeyup="value="/value.replace(/[" -~]/g,'')" onkeydown="if(event.keyCode==13)event.keyCode=9">6.只能为数字(有闪动) <input onkeyup="value="/value.replace(/["^/d]/g,'') "onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))">7.只能为数字(⽆闪动)<input ime-mode:disabled" onkeydown="if(event.keyCode==13)event.keyCode=9" onKeyPress="if ((event.keyCode<48 || event.keyCode>57)) event.returnValue=false">8.只能输⼊英⽂和数字(有闪动) <input onkeyup="value="/value.replace(/[/W]/g,"'')" onbeforepaste="clipboardData.setData('text',clipboardData.getData('text').replace(/[^/d]/g,''))">9.屏蔽输⼊法<input type="text" name="url" ime-mode:disabled" onkeydown="if(event.keyCode==13)event.keyCode=9">10. 只能输⼊数字,⼩数点,减号(-)字符(⽆闪动) <input onKeyPress="if (event.keyCode!=46 && event.keyCode!=45 && (event.keyCode<48 || event.keyCode>57)) event.returnValue=false">11. 只能输⼊两位⼩数,三位⼩数(有闪动) <input maxlength=9 onkeyup="if(value.match(/^/d{3}$/))value="/value.replace(value,parseInt(value/10))" ;value="/value.replace(//./d*/./g,'."')" onKeyPress="if((event.keyCode<48 || event.keyCode>57) && event.keyCode!=46 && event.keyCode!=45 || value.m 总结以上所述是⼩编给⼤家介绍的只能输⼊正整数的代码及常⽤的正则表达式,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
常用的正则
正则表达式是一种强大的工具,用来对文本进行匹
配、查找、替换、提取等操作。它在计算机编程、文本处
理、数据分析等领域广泛应用。本文将介绍一些常用的正
则表达式,包括字符、量词、组合等方面的内容。
一、字符
1.元字符. :匹配除了换行符(\n)之外的任何单个
字符。
2.元字符^ :以某个字符串开头。在中括号内表示取
反操作。例如[^abc]表示除了a、b、c之外的任意字符。
3.元字符$ :以某个字符串结尾。
4.元字符* :前一个字符出现0次或多次。例如ab*c
可以匹配ac、abc、abbc等。
5.元字符+ :前一个字符出现一次或多次。
6.元字符? :前一个字符出现0次或1次。
7.字符类[...]:用方括号括起来的任何字符都可以匹
配。例如[abc]可以匹配a、b或c。
8.字符范围[-...]:用连字符将字符范围连接起来,
表示匹配该范围内的任何字符。例如[a-z]可以匹配任何小
写字母。
9.元字符\ :用来转义特殊字符。例如\.表示匹配小
数点。
二、量词
1.元字符{n} :前一个字符出现n次。
2.元字符{n,} :前一个字符出现至少n次。
3.元字符{n,m} :前一个字符出现n到m次。
4.元字符? :前一个字符出现0次或1次。
5.元字符* :前一个字符出现0次或多次。
6.元字符+ :前一个字符出现一次或多次。
例如,\d{3}-\d{4}表示匹配美国的邮政编码格式。
三、分组
1.使用小括号()将一组字符括起来,表示一个整体。
2.可以在小括号前加一个元字符,表示对整个分组的
操作。
3.可以使用|表示或操作。
4.可以使用(?:...)表示非捕获分组,即匹配但不捕
获。
例如,(ab)+可以匹配连续的ab字符串,(a|b)+可以
匹配由a和b组成的字符串。
四、零宽断言
1.元字符(?=...)表示正向预查,即后面必须跟着某个
模式。
2.元字符(?!...)表示负向预查,即后面不应该跟着某
个模式。
3.元字符(?<=...)表示正向回顾后发,即前面必须跟
着某个模式。
4.元字符(?跟着某个模式。
例如,\b\w+(?=ing)\b可以匹配以ing结尾的单词。
(?<=\d{2})\d{2}可以匹配前面是两个数字的两个数字。
五、常用匹配
1.匹配数字:\d,等价于[0-9]。
2.匹配非数字:\D,等价于[^0-9]。
3.匹配空白字符:\s,可以匹配空格、制表符、换行
符等任何空白字符。
4.匹配非空白字符:\S。
5.匹配任意字符:.,等价于[^\n]。
6.匹配边界:\b,可以匹配单词边界或字符串边界。
以上是一些常用的正则表达式,每个正则表达式都可
以实现特定的匹配功能。在使用正则表达式时,一定要注
意语法的正确性,避免不必要的错误和漏洞。同时,在实
际应用中,也要根据具体情况选择合适的正则表达式,以
达到最大的匹配效果。