InfiniBand高速网络互连技术
1.高速网络InfiniBand加速大数据应用介绍

高速网络InfiniBand加速大数据应用刘通Mellanox亚太市场开发总监Mellanox公司概况股票代码: MLNX ▪连接服务器、存储器的高带宽与低延迟网络的领导厂商•FDR 56Gb/s InfiniBand 与万兆/4万兆以太网•降低应用等待数据时间•大幅提升数据中心投资回报率▪公司总部:•美国加州以及以色列双总部•全球范围内约~1432名员工▪良好财务状况•2013年销售近3.9亿美元•现金与投资达3.4亿美元截至2013年9月世界领先的端到端网络互连设备提供商Virtual Protocol Interconnect存储前端 / 后端服务器交换机/ 网关56G IB & FCoIB 56G InfiniBand10/40/56GbE & FCoE 10/40/56GbEVirtual Protocol Interconnect芯片交换机、网关网卡网线、模块Metro / WAN完整的InfiniBand与以太网产品线▪InfiniBand 是高性能应用的首选网络▪采用Mellanox FDR InfiniBand 的系统同比增长1.8倍•加速63% 的InfiniBand系统是基于FDR (141 systems out of 225)超级计算机TOP500中最高占有率InfiniBand提供不可超越的系统效率▪InfiniBand是实现最高系统效率的关键,平均高于万兆以太网30% ▪Mellanox InfiniBand 实现最高效率99.8% 平均效率•InfiniBand: 87% •Cray: 79%•10GbE: 67% •GigE: 40%InfiniBand技术优势InfiniBand 技术的优势和特点▪InfiniBand Trade Association (IBTA) 协会制定规范•开放标准的高带宽、低延迟网络互连技术▪串行高带宽连接•SDR: 10Gb/s HCA连接•DDR: 20Gb/s HCA连接•QDR: 40Gb/s HCA连接–现在•FDR: 56Gb/s HCA连接– 2011年底•EDR: 100Gb/s HCA连接– 2014年▪极低的延迟•低于1 微妙的应用级延迟▪可靠、无损、自主管理的网络•基于链路层的流控机制•先进的拥塞控制机制可以防止阻塞▪完全的CPU卸载功能•基于硬件的传输协议•可靠的传输•内核旁路技术▪远端内存直接访问•RDMA-读和RDMA-写▪服务质量控制(QoS)•在适配器卡级提供多个独立的I/O通道•在链路层提供多条虚拟通道▪集群可扩展性和灵活性•一个子网可支持48,000个节点,一个网络可支持2128个节点•提供多种集群拓扑方式▪简化集群管理•集中路由管理•支持带内网络诊断和升级RDMA (远端内存直接访问技术) – 如何工作RDMA 运行于InfiniBand 或Ethernet内核硬件用户机架1OSNICBuffer 1 应用程序1应用程序2OSBuffer 1NICBuffer 1TCP/IP机架2HCAHCABuffer 1Buffer 1 Buffer 1Buffer 1Buffer 1Mellanox RDMA 远端内存直接访问技术零拷贝远程数据传输低延迟, 高速数据传输InfiniBand - 56Gb/sRoCE* – 40Gb/s内核旁路 通讯协议卸载* RDMA over Converged Ethernet应用程序应用程序用户层内核 硬件缓存缓存加速分布式数据库迈络思网络加速主流数据库▪Oracle 数据仓库•提供4倍闪存•写性能提升20倍•数据吞吐量提高33%•降低能耗10% 到 40%▪IBM DB2 Purescale 数据库:•需要低延迟高带宽的网络,同时满足高可靠性•RDMA 大大降低CPU负荷•实现DB2 Purescale 接近线性的可扩展性▪微软 SQL Server 数据仓库•更高性能,更低成本▪Teradata 数据仓库•相较以太网,跨机柜SQL查询速度提升2倍•数据加载性能提升4倍大幅提升性能与可扩展性,降低成本河南移动Oracle RAC数据库解决方案▪采用Mellanox InfiniBand交换机作为心跳网络连接设备;▪全线速无阻塞网络;▪采用高可用的冗余连接方式,避免单点故障;▪40Gb/s高通讯带宽、100纳秒超低延迟,全面加速Oracle RAC性能InfiniBand+PCI-e SSD新架构加速Oracle数据库生产环境:处理器:16 CPU Itanium21.6GHZ(双核)内存:192G数量:3新架构 RAC节点:AMD Quad-Core 83802.5GHZ 4 CPU (4核)内存:64G数量:2 分钟网络层40/10GbE 交换机应用及存储融合Oracle RAC Node 1 SDC PC Serverw/ ECSLSI NytroSDSOracle RAC Node 2 SDC PC Server w/ ECS LSI NytroSDSOracle RAC Node n SDC PC Server w/ ECS LSI NytroSDSSDC: ScaleIO 数据客户端SDS: ScaleIO 数据访问服务端 40/10 GbEMellanox 网络交换机Mellanox 40GbE 交换机+40GbE 网卡实现最佳Oracle 性能与扩展性Oracle RAC 数据库Oracle RAC 数据库SDC: ScaleIO 数据客户端SDS: ScaleIO 数据访问服务端 40/10 GbE EthernetSDSSDCSDCSDSSDS 网络层 40 GbE 互联PC Server w/ ECS LSI NytroPC Server w/ ECS LSI NytroPC Server w/ ECS LSI Nytro数据库应用层存储层Mellanox 网络交换机Mellanox 40GbE 交换机+40GbE 网卡实现最佳Oracle 性能与扩展性Mellanox加速分布式Oracle RAC性能Mellanox 40GbE 交换机+40GbE网卡实现最佳Oracle性能与扩展性加速大数据Data Intensive Applications Require Fast, Smart InterconnectHost/Fabric SoftwareICs Switches/GatewaysAdapter Cards Cables/Modules End-to-End & Virtual Network Ready InfiniBand and Ethernet PortfolioMetro / WANCertified Networking Gear河南移动大数据部署实例▪任意服务器之间进行40Gb/s无阻塞通信,消除节点间I/O瓶颈▪网络采用36口交换机堆叠的Fat-tree架构,最大幅度地降低网络开销,随着节点数量的增加,整体性能线性增加,提供最佳的线性扩展能力▪集群任意节点均与两个交换机互联,实现系统的高可靠性;▪全省上网行为数据每天8TB,大数据处理平台(90台)40秒完成忙时数据装载、5小时内完成日报表处理TCO大幅降低高达79.6%Hadoop缺陷调查•管理工具•性能•可靠性•SQL支持•备份与恢复451 Research 2013 Hadoop调查Hadoop 性能提升挑战•HDFS 本事的数据延迟问题 •不能支持大量小文件•Map Reduce, Hbase, Hive, 等等的效率.HDFS™(Hadoop Distributed File System)HBaseHivePigMap ReduceSQL(e.g. Impala)•性能提升需求 –实时操作–更快执行速度Map Reduce 工作进程▪开源插件▪支持Hadoop版本•Apache 3.0, Apache 2.2.x, Apache 1.3•Cloudera Distribution Hadoop 4.4内嵌支持Hadoop MapReduce RDMA优化HDFS™(Hadoop Distributed File System)Map Reduce HBaseDISK DISK DISK DISK DISK DISKHive Pig速度翻倍HDFS 操作ClientNameNodeDataNode1 48 DataNode48DataNode142 WriteReadReplicationReplicationHDFS FederationNameNode•HDFS Federation •更快硬盘•更快CPU 和内存IO 成为瓶颈▪HDFS 基于RDMA进行移植▪支持CDH5 和 HDP2.1 Hadoop HDFS RDMA优化HDFS ClientJXIO JXIO JXIO JXIOHDFS ClusterHadoop存储架构的限制•Hadoop 使用本地硬盘保持数据本地性和低延迟–很多高价值数据存在于外置存储–拷贝数据到HDFS, 运行分析, 然后将结果发到另外系统–浪费存储空间–随着数据源的增多,数据管理变成噩梦•直接访问外部数据,无需拷贝?–需要解决性能问题存储: 从Scale-Up 向 Scale-Out 演进 Scale-out 存储系统采用分布计算架构•可扩展,灵活,高性价比1000020000300004000050000600001Gb iSCSI 10Gb iSCSI 8Gb FC 16Gb FC40Gb iSCSITCP 40Gb iSER RoCEFDR IBWire speed Mb/sActual Single-Thread Throughput Mb/s顺序文件读性能 (单端口)iSER : iSCSI over RDMAiSER 实现最快的存储访问iSCSI (TCP/IP)1 x FC 8 Gb port4 x FC 8 Gb portiSER 1 x 40GbE/IBPort iSER 2 x 40GbE/IB Port (+Acceleration)KIOPs130200800110023005001000150020002500K I O P s @ 4K I O S i z e▪使用高性能网络和RDMA•避免性能瓶颈▪避免单点失败– HDFS Name Node▪节省33%磁盘空间!方案1: 使用并行文件系统替换HDFSLustre 作为文件系统方案Mellanox网络与RDMA技术实现最高 Lustre 性能Hadoop over Cloud?▪通常满负荷运转,而不是多虚机配置 ▪云存储慢且贵顾虑: •降低成本•弹性获得大量资源•与数据源更近•简化Hadoop 操作好处:?Performance?▪利用OpenStack 内置组件与管理功能•RDMA 已经内置在OpenStack▪RDMA 实现最快性能, 占用更低CPU 负荷最快的OpenStack 存储速度Hypervisor (KVM)OSVM OS VM OS VMAdapter Open-iSCSI w iSERCompute ServersRDMA Capable InterconnectiSCSI/iSER Target (tgt) Adapter Local DisksRDMA Cache Storage Servers OpenStack (Cinder)Using RDMA toaccelerate iSCSIstorage支持RDMA的高速网络大幅提升大数据应用性能4倍性能!Benchmark: TestDFSIO (1TeraByte, 100 files)2倍性能!Benchmark: 1M Records Workload (4M Operations)2X faster run time and 2X higher throughput2倍性能!Benchmark: MemCacheD Operations3倍性能!Benchmark: Redis Operations步入100G网络时代通过更快移动数据实现更大数据价值 20Gbs 40Gbs 56Gbs 100Gbs 2000 2020 2010 2005 2015 200Gbs10Gbs Gbs – Gigabit per secondMellanox 网络速度路线图引领网络速度的发展迈向更高网速进入100G时代36 EDR (100Gb/s) 端口, <90ns 延迟吞吐量7.2Tb/s100Gb/s 网卡, 0.7us 延迟1.5亿消息/秒(10 / 25 / 40 / 50 / 56 / 100Gb/s)Mellanox引领高速网络技术不止于InfiniBand端到端高速以太网Thank You。
InfiniBand 连接现在和未来

InfiniBand 连接现在和未来InfiniBand是致力于服务器端的高性能互联技术,它的使命是:使处理器级的带宽,从处理器到系统I/O、到存储网络,穿越整个数据中心,形成一张统一的、包括服务器互连、服务器与存储互连、存储网络在内的神经网络。
InfiniBand技术是一种开放标准的高带宽、高速网络互联技术。
目前,它的发展速度非常快,而且越来越多的大厂商正在加入或者重返到它的阵营中来,包括Cisco、IBM、HP、Sun、NEC、Intel等。
可以说,InfiniBand已经成为目前主流的高性能计算机互连技术之一。
而且,目前基于InfiniBand技术的网络卡的单端口带宽最大可达到20Gbps,基于InfiniBand的交换机的单端口带宽最大可达60Gbps,单交换机芯片可以支持达480Gbps的带宽,为目前和未来对于网络带宽要求非常苛刻的应用提供解决方案。
InfiniBand体系结构InfiniBand技术通过一种交换式通信组织(Switched Communications Fabric)提供了较局部总线技术更高的性能,它通过硬件提供了可靠的传输层级的点到点连接,并在线路上支持消息传递和内存映像技术。
InfiniBand技术通过连接HCA(Host Channel Adapters)、TCA(Target Channel Adapters)、交换机以及路由器来工作,其体系结构如图1所示。
目前,集群计算、存储区域网(SAN)、网格、内部处理器通信(IPC)等高端领域对高带宽、高扩展性、高QoS以及高RAS(Reliability、A vailability and Serviceability)等有迫切需求,InfiniBand技术可以为实现这些高端需求提供可靠的保障。
在I/O技术层面,InfiniBand 具有两个非常关键的特性:一是物理层设备低功耗,二是“箱外带宽”(Bandwidth Out of the Box)。
200G QSFP DD AOC在InfiniBand网络中的应用
200G QSFP DD AOC在InfiniBand网络中的应用随着数据中心的不断深入与高需求,人们对于此领域的拓展研究也在不断更迭最新技术与开发最优性能产品及解决方案。
前段时间易飞扬(Gigalight)发布了200G QSFP DD PSM8光模块,标志着基于NRZ调制的200G低成本数据中心内部平行光互连方案基本完成,也象征着公司在200G解决方案上的领先地位。
不同于业界主张的400G方案,易飞扬(Gigalight)坚持200G的数据中心解决方案,可为客户提供一站式的服务和解答。
本文主要根据现阶段超算中心的发展进程,来分析当前交换机之间InfiniBand技术的特征以及应用领域,其中以200G QSFP DD AOC为例,说明了超算中心互连技术的端口封装形式朝着更高工作带宽发展的现状。
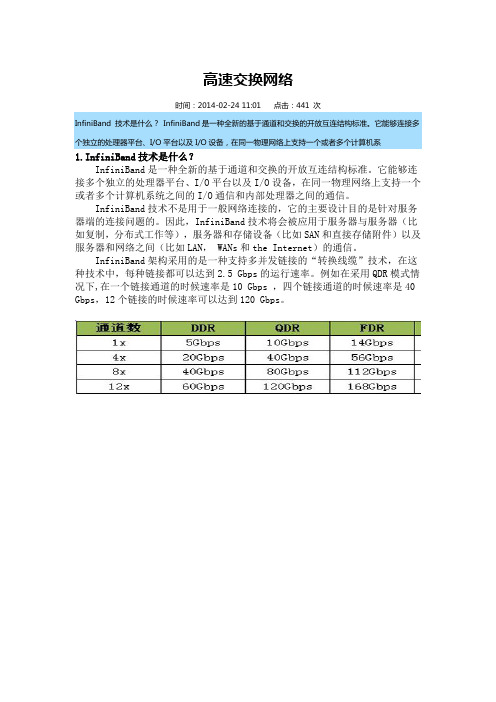
超算系统里的InfiniBand技术根据2017年全球超级计算机500强榜单公布情况,我国无锡“神威--太湖之光”超级计算机以每秒125,435.9TFlop/s的峰值计算能力再次蝉联世界第一名,广州“天河二号”超算系统以每秒54,902.4TFlop/s的峰值计算能力位居世界第二名。
值得注意的是这些超算中心的交换互连技术均采用来自以色列InfiniBand的交换机和网络适配卡。
当前在超算中心互连技术阵营中有以色列的InfiniBand,高性能Ethernet,IBM的BlueGene,Cray和后起之秀Intel的OmniPath,这五大技术占据市场的重要份额,其中InfiniBand和高性能Ethernet占绝对领导地位。
超算中心的互连技术朝着更高带宽、更低延迟、更低功耗和更密的互联端口在发展,而InfiniBand互连技术在当前成为高性能存储互连方案的首选,正是因为其满足了大带宽和低时延的需求。
InfiniBand是一个统一的互连结构,既可以处理存储I/O、网络I/O,也能够处理进程间通信。
它可以将磁盘阵列、SANs、LANs、服务器和集群服务器进行互联,在相对短的距离内提供高带宽、低延迟的传输,而且在单个或多个互联网络中支持冗余的I/O通道,让数据中心在局部故障时仍能运转。
mellanox infiniband技术原理

Mellanox Infiniband是一种高速计算机网络技术,主要用于数据中心的互连。
其设计目的是为了提高数据传输的速度和效率,降低延迟,并提供更高的带宽。
Infiniband技术使用点对点通信,可以在服务器、存储设备和网络设备之间提供高带宽、低延迟的数据传输。
Infiniband技术的工作原理如下:
1. 基于通道化:Infiniband使用通道化技术,将数据传输划分为多个通道,每个通道可以独立进行数据传输。
这种方式可以提高带宽利用率,降低冲突和延迟。
2. 基于信用机制:Infiniband使用信用机制来管理数据传输。
发送方在发送数据之前,先发送一个请求,接收方收到请求后,返回一个信用。
发送方在收到信用后,才开始发送数据。
这种方式可以确保数据传输的顺序性和可靠性。
3. 具有流量控制:Infiniband技术具有流量控制功能,可以根据网络状况和接收方的能力来调整数据传输的速度和大小,避免网络拥塞和数据丢失。
4. 支持虚拟化:Infiniband支持虚拟化技术,可以在不同的虚拟机和应用程序之间提供高效的数据传输。
总之,Mellanox Infiniband技术通过通道化、信用机制、流量控制和支持虚拟化等技术,提供了高性能、高可靠性和高带宽的网络连接,适用于数据中心和云计算环境。
InfiniBand技术的研究

InfiniBand技术的研究1.介绍随着CPU和通讯处理速度的不断加快,10Gbps、100Gbps的逐步普及,传统的I/O标准和系统,例如PCI、Ethernet、Fibre Channel可能已经无法跟上脚步。
因此如何将旧有的设备或产品升级为高速的通讯系统,正是IT从业者目前普遍苦恼的问题。
InfiniBand标准(简称IB)的出现就是为了解决PCI等传统I/O架构的通讯传输瓶颈。
该标准采用点对点架构,提高容错性和扩展性,在硬件上实现10Gbps的数据传输(每个独立的链路基于四针的2.5Gbps双向连接),采用虚拟通道(Virtual Lane)实现QoS,同时借由CRC技术来保证信号的完整性。
本文将介绍InfiniBand这一技术标准,以及它的主要组成部分。
InfiniBand架构:InfiniBand采用双队列程序提取技术,使应用程序直接将数据从适配器送入到应用内存(称为远程直接存储器存取或RDMA),反之依然。
在TCP/IP协议中,来自网卡的数据先拷贝到核心内存,然后再拷贝到应用存储空间,或从应用空间将数据拷贝到核心内存,再经由网卡发送到Internet。
这种I/O操作方式,始终需要经过核心内存的转换,它不仅增加了数据流传输路径的长度,而且大大降低了I/O的访问速度,增加了CPU的负担。
而SDP则是将来自网卡的数据直接拷贝到用户的应用空间,从而避免了核心内存参与。
这种方式就称为零拷贝,它可以在进行大量数据处理时,达到该协议所能达到的最大的吞吐量。
InfiniBand的协议采用分层结构,各个层次之间相互独立,下层为上层提供服务。
其中物理层定义了在线路上如何将比特信号组成符号,然后再组成帧、数据符号以及包之间的数据填充等,详细说明了构建有效包的信令协议等;链路层定义了数据包的格式以及数据包操作的协议,如流控、路由选择、编码、解码等;网络层通过在数据包上添加一个40字节的全局的路由报头(Global Route Header, GRH)来进行路由的选择,对数据进行转发。
Infiniband介绍与使用

万兆以太网与Infiniband网络
万兆以太网 说明 优点 缺点 Infiniband 说明 优点 缺点 用于互联服务器和交换机的半专有技术 极低的延迟(不到100ns)和高吞吐量(高达120Gbps),使它成为数据 中心最强健的互联技术之一 在服务器硬件上需要昂贵的专有互联设备,并且在与数据中心或集群外 部进行通信时,需要交换设备在以太网和Infiniband之间进行转换 目前市场上最快的以太网技术,具有极低的延迟(不到500ns)的新适配 器和交换机正在进入市场 通常使用标准的以太网LAN设备、线缆和PC接口卡 延迟问题依然存在,因而可能把这种技术排斥在像集群和网格等对延迟 极其敏感的应用之外,速度仍落后于其它的一些互联技术
InfiniBand体系架构
InfiniBand标准定义了一套 用于系统通信的多种设备, 包括信道适配器、交换机和 路由器 信道适配器用于同其它设备 的连接,包括主机信道适配 器(HCA)和目标信道适配 器(TCA) 交换机是 InfiniBand结构中 的基本组件 点到点的交换结构:解决了 共享总线、容错性和可扩展 性问题 具有物理层低功耗特点和箱 外带宽连接能力
在管理节点启动子网管理服务
chkconfig opensmd on service opensmd restart
在所有的节点启动openibd服务
chkconfig ipenibd on service openibd restart
查看IP
ipconfig ib0
谢谢!
Infiniband驱动安装与配置
#tar xvfz OFED-1.5.2.tgz #cd OFED-1.5.2 #./install.pl
选择2
对于一个集群来说,在管理节点选择3,其他计算节点选择2安装,出现的余下选项,一路 Enter则可,即使在操作系统完全安装的情况下,通常至少会提示tcl-devel等依赖组件未 安装,到安装光盘里查找缺少的rpm包,在每节点都安装缺少的rpm包
InfiniBand
高速交换网络时间:2014-02-24 11:01 点击:441 次InfiniBand 技术是什么?InfiniBand是一种全新的基于通道和交换的开放互连结构标准。
它能够连接多个独立的处理器平台、I/O平台以及I/O设备,在同一物理网络上支持一个或者多个计算机系1.InfiniBand技术是什么?InfiniBand是一种全新的基于通道和交换的开放互连结构标准。
它能够连接多个独立的处理器平台、I/O平台以及I/O设备,在同一物理网络上支持一个或者多个计算机系统之间的I/O通信和内部处理器之间的通信。
InfiniBand技术不是用于一般网络连接的,它的主要设计目的是针对服务器端的连接问题的。
因此,InfiniBand技术将会被应用于服务器与服务器(比如复制,分布式工作等),服务器和存储设备(比如SAN和直接存储附件)以及服务器和网络之间(比如LAN, WANs和the Internet)的通信。
InfiniBand架构采用的是一种支持多并发链接的“转换线缆”技术,在这种技术中,每种链接都可以达到2.5 Gbps的运行速率。
例如在采用QDR模式情况下,在一个链接通道的时候速率是10 Gbps ,四个链接通道的时候速率是40 Gbps,12个链接的时候速率可以达到120 Gbps。
2.为什么需要InfiniBand?采用Intel架构的处理器的输入/输出性能会受到总线的限制。
总线的吞吐能力是由总线时钟和总线的宽度决定的。
这种速度上的限制制约了服务器和存储设备、网络节点以及其他服务器通讯的能力。
而在InfiniBand的技术中,InfiniBand直接集成到系统板内,并且直接和CPU以及内存子系统互动,在传输层上,它提供了可靠的点对点连接,不同于PCI,Infiniband允许多个I/O外设无延迟、无拥塞地同时向处理器发出数据请求。
Infiniband技术与其他网络协议(如TCP/IP)相比,InfiniBand具有更高的传输效率。
一种新型的高速互连网络

基金项目:教育部留学回国人员专项基金资助作者简介:贾志国,硕士研究生,主要研究领域为计算机系统结构。
赵青苹,副教授,主要研究领域为计算机组成原理。
董小社,副教授,主要研究领域为计算机体系结构与光互连网络,并行计算。
1引言由于并行处理是提高服务处理能力、满足应用需求不断增长的有效途径。
目前采用高速网络连接结点机的集群服务器系统将成为未来高性能服务器发展的主流技术。
网络互连技术是服务器集群系统关键技术之一,它决定了服务器的体系结构,直接影响了服务器系统的各项性能指标。
是影响整个系统的实用性能、扩展性、可靠性等特性的主要因素之一。
随着计算能力向数据中心的集中,消除性能瓶颈和改进系统管理变得比以往更加至关重要。
开发研制新型互连技术并将其引入到服务器系统的互连以及服务器系统和外部网络、海量存储设备的互连中来,根本改变现有网络服务器系统的整体构造,使外部海量存储设备、外部网络以及服务器之间的连接可以通过中央高速交换网络系统完成,才能满足从以服务器结点为连接核心向以服务器结点和外部存储结点为连接核心转变的发展趋势。
同时,交换技术的引入可以使服务器、外部存储、外围I /O 设备成为相互独立的物理单元,使网络服务器系统逐渐向模块化的方向发展,在这种结构框架下,I /O 带宽问题、高速数据交换问题、I /O 扩展问题等都可以迎刃而解。
而千兆位以太网、Myrinet 、SCI 互连网络络等不论是带宽、总线利用率,都达不到处理结点互连、处理结点和存储设备互连的需要。
因此,需要一种高性能、高带宽、高扩展性的高速互连网络。
In-finiBand 正是为此而提出的一种新的体系结构。
它简化了处理结点、存储结点之间的连接方式,提高了连接带宽,并能与其他外围设备连接。
2I /O 的历史及现状在I /O 总线的历史中曾经有两种总线占据过统治地位,这就是ISA 和PCI 。
ISA(Industry Standard Architecture ,工业标准架构)是一个有相当历史的产品,现在的BX 主板还在使用这种插槽。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
•
• •
近3年来的TOP5超级计算机系统
2009年 Rank1
美洲虎 Cray XT5-HE
2010年
2011年
NUDT TH-1A
K computer
Rank2 IBM BladeCenter Rank3 Cray XT5-HE
Rank4 IBM蓝色基因 Rank5 NUDT TH-1
12000000 峰值性能(Gflops) 10000000 8000000
• K Computer:
– 10.51 Petaflop/s on Linpack – 705024 SPARC64 cores (8 per die; 45 nm) (Fujitsu design) – Tofu interconnect (6-D torus) – 12.7 MegaWatt
Roadrunner Architecture
Part 2: Cell Blades
Roadrunner Architecture
Part 3: Nodes(Triblade= 1*Opteron +2*cell)
HT x16 6.4 GB/s HT2100 HT2100 IB 2 GB/s PCIe x8 2 GB/s
三大突破
• “天河一号”除了使用了英特尔处理器,还 首次在超级计算机中使用了2048个我国自 主设计的处理器。这款名为“飞腾-1000”的 64位CPU。它利用65纳米技术设计生产,共 有8个核心。 • 中国首创了CPU和GPU融合并行的体系结构。
• 制造了先进的通信芯片,设计了先进的互 联结构。160Gb/s,是国际上的商用IB的两 倍。
神威蓝光拥有四大特点:
• 全部采用国产的CPU • Linpack效率高达74.4%,而一般的千万亿次 机都在50%左右 • 采用液冷技术,节能
• 高密度,在一个机仓(机柜)里可以装入 1024颗CPU,千万亿次规模仅需要9个这样 的机仓。
计算机节点,在1U高的机箱中可以放入4个 CPU板,每个板上可以装两颗16核的CPU。
13
TH-1A互连架构
• 超级胖树结构
NO.3 Jaguar美洲虎,2.331Pflops
Cray XT5-HE Opteron Six Core 2.6 GHz,近25万个内核
美洲虎的3D-Torus
CRAY 超级计算机的Roadmap
Future system: 1 EF Cray XT5: 1+ PF Leadership-class system for science
Part 4: Scaling Out
Compute Unit (CU)
Total cores: Total flop/s: Total cores: Total flop/s:
7,200 80,928,000,000,000
• 日本理化研究所(RIKEN)高级计算科学研究院(AICS)和富士通共同研制 • 每秒运算速度超越1亿亿次大关。Linpack测试的最大计算性能达到了 10.51PFlops,也就是每秒钟1.051亿亿次浮点计算,这也是人类首次跨越1 亿亿次计算大关。 • 采用的处理器是富士通制造的SPARC64 VIIIfx,八核心,主频2.0GHz,二级 缓存6MB,热设计功耗58W,峰值浮点性能128GFlops。为了获得更高性 能,富士通还在其中加入了一系列高性能集群计算扩展,可以有效管理 其共享二级缓存,并支持SIMD、每核心256位浮点寄存器、高级核心间硬 件同步等等。 • 处理器数量是88128颗,核心数量为705024个,占据864个机柜。这些处 理器通过名为“豆腐”(Tofu)的特殊6-D mesh/torus网络连接在一起,带宽 5GB/s。同时,“京”的峰值计算性能也达到了11.28PFlops,执行效率为 惊人的93.2%
FY 2009
DARPA HPCS: 20 PF Leadership-class system
FY 2011
100–250 PF
FY 2015
FY 2018
美洲虎
NO.4 曙光“星云”, 2.9843Pflops
• Infiniband互连
No14: 神威蓝光:全国产化的超级计算 机问世
• 该机器获得科技部863计划支持,由国家并行计算机工程 技术研究中心制造,于2011年9月安装于国家超算济南中 心,全部采用自主设计生产的CPU(ShenWei processor SW1600),系统共8704个CPU,峰值1.07016PFlops,持续 性能795.9TFlops, Linpack效率74.37%,总功耗1074KW。 • 国家超级计算济南中心是科技部批准成立的全国3个千万 亿次超级计算中心之一,由山东省科学院计算中心负责建 设、管理和运营。 • 是国内首台全部采用国产中央处理器(CPU)和系统软件 构建的千万亿次计算机系统,标志着我国成为继美国、日 本之后第三个能够采用自主CPU构建千万亿次计算机的国 家。
国际超级计算机500强排名(TOP500)
• 是美国田纳西大学、伯克利NERSC实验室和德 国曼海姆大学一些专家为评价世界超级计算机 性能而搞的民间学术活动,每年2次排出世界上 实际运行速度最快的前500台计算机。(6月、11 月) • 排名的依据是线性代数软件包Linpack的实际测 试数据,而峰值浮点运算速度作为参考值列出。 • Linpack基准测试程序
这就是神威蓝光的“心脏”:申威1600实物照
在计算节点中采用液冷(据说是使用500元1吨的纯 净水)设计也是神威蓝光的一大技术特色,中间是 铝制液冷散热板。
国内三大系统比较
Roadrunner(走鹃)
Part 1: Opteron Blades
Opteron socket
Opteron core Opteron core
– 是一个可以分解和解答线性方程和线性最小平方问 题的Fortran子程序集. – 于20世纪70年代到80年代初为超级计算机而设计 – 测试出的最高性能指标作为衡量机器性能的标准
4
TOP500分析
• • • • • • 中国TOP100总Linpack性能达到11.85 Pflops (2010年6.3PFlops),是2010年的1.88倍; 跟全球TOP500相比,2011年6月全球TOP500排行榜第一名被日本的K-Computer夺 得,2010年11月TOP500第一名的天河1A降为世界第二,但中国的机器份额首次取 得第二名,仅次于美国; 国家超级计算天津中心以国防科大天河1A再次蝉联中国TOP100第一名,Linpack性 能2.57PFlops,峰值4.7PFlops; 国家超级计算济南中心以国家并行计算机工程技术研究中心全国产神威蓝光力夺 得中国TOP100第二名,Linpack性能795.9TFlops,峰值1.07PFlops,神威蓝光是我 国历史上首台全国产的千万亿次超级计算机; 国家超级计算长沙中心以国防科大天河1A-HN力夺中国TOP100第三名,Linpack性 能771.7TFlops,峰值1.34PFlops。 全部机器的Linpack性能超过22.1Tflops是2010年9.6TFlops的2.3倍,比去年的1.41倍 大幅提升。 全部系统的峰值超过25.6TFlops,是2010年11TFlops的2.33倍,比去年的1.36倍大 幅提升; 排名前三的机器两套是CPU+GPU异构MPP; 97个(2010年98个)系统都是机群架构,机群继续占据主导地位,在前10名里4台是 CPU+GPU体系架构,在TOP100中共有13套CPU+GPU异构机群。
1.8 GHz 3.6 Gflop/s 64+64 KB L1 cache 2 MB L2 cache
Total cores:
Total flop/s:
2 1 0
7,200,000,000 0 3,600,000,000
Roadrunner(走鹃)
Part 1: Opteron Blades
LS21 Blade Opteron socket Opteron core Opteron core HyperTransport 6.4+6.4 GB/s Opteron socket Opteron core Opteron core
InfiniBand高速网络互连技术
2012年5月
内容提要
1. 超级计算机系统及其互连结构 2. Infiniband互连网络的体系结构
Lecture 1
3. 在HPC中的典型互连架构及应用 4. IB网络优化技术 5. 未来展望
Lecture 2
内容提要
1. 2. 3. 4. 5. 超级计算机系统及其互连结构 Infiniband互连网络的体系结构 在HPC中的典型互连架构及应用 IB网络优化技术 未来展望
ASCI Springschool 2012
Henk Corporaal
(8)
K Computer的互连架构
• 6D-mesh/urs
No 2:天河-1A,国防科技大学
• 这是超过美国橡树岭国家实验室产品高达40%的系统。达到每秒47 00万亿次的峰值性能和每秒2507万亿次的实测性能。 • 14336颗英特尔六核至强X5670 2.93GHz CPU、7168颗Nvidia Tesla M2050 GPU,以及2048颗自主研发的八核飞腾FT-1000处理器 • 天河一号A将大规模并行GPU与多核CPU相结合,在性能、尺寸以及功 耗等方面均取得了巨大进步,是当代异构计算的典型代表。 该系统采 用了7168颗英伟达™(NVIDIA®)Tesla™ M2050 GPU以及14,336颗 CPU。如果单纯只使用CPU的话,要实现同等性能则需要50,000颗以上 的CPU以及两倍的占地面积。 • 更重要的是,如果完全采用CPU打造,可实现2.507 Petaflops(千万亿 次)性能的系统将消耗1200万瓦特的电力。 多亏在异构计算环境中运 用了GPU,天河一号A仅消耗404万瓦特的电力,节能效果高达3倍。 二者之间的功耗之差足够满足5000多户居民一年的电力所需。