搭建eclipse的hadoop开发环境知识点
Hadoop家族以及环境搭建(附图解)

Hadoop家族以及环境搭建(附图解)来源:ITSTAR回顾上次课内容,上一次课首先我们就给大家介绍了项目如何去安装Linuxp环境,这个步骤我们写得非常的清楚和详细,建议大家下来以后一定要按照我们的文档一步一步的进行操作,所以我们提供了一个word的文档,这个文档大家可以从我们这个实验介质当中可以找到这个文档,那这里实际上就列出来了你在安装这个Linux的时候需要注意哪些具体的问题。
前面的这些步骤都比较简单,咱们就看一看就可以了。
前面的这些都是比较简单,我们把重点的几个步骤给大家再说一下,我们往下看其中一个非常重要的步骤就是,你要选择你的网卡类型,我们在这里推荐大家去选择这个仅主机模式的这X网卡,它就能够保证我们的本机和虚拟机能够进行通信,这样我们在本机上通过Putty就能连接到虚拟机Linux上,但是你选择仅主机模式的时候,在安装Linux的时候就需要设置它的ip地址,而这个ip地址咱们的笔记上面是写得很清楚的,那么我们可以看到当你设置ip地址的时候,你需要跟你本机上VMware net1的这个网卡在同一个网段上,这个咱们可以来确定下,因为我们抓好了这个VMware以后我们可以打开我们的这个命令行的窗口,我们可以执行ip这个config -all列出来所有的ip的地址,我们应该看这个就是VMware net1的这个网卡,他锁定的ip地址是192.168.157注意,这个地址是网关地址,网关就是windows,然后在安Linux的时候,你指的ip地址需要跟这个ip地址在一个网段也就是说在这个157的这个上所以呢我们一共会安装5台的Linux,那么ip地址大家设置的时候要设是192.168.157.111,192.168.157.112,192.168.157.113和192.168.157.114和192.168.157.115这样,通过这些ip地址就可以从windows 上连接到Linux上,这个问题大家一定不要设置错了。
elasticsearch-hadoop参数

elasticsearch-hadoop参数概述:elasticsearch-hadoop是一款用于连接Hadoop和Elasticsearch 的开源软件,它提供了对Elasticsearch中数据的读写操作。
在连接和使用elasticsearch-hadoop时,需要了解并正确配置相关参数,以确保数据传输和处理的效率和稳定性。
本文将介绍elasticsearch-hadoop的主要参数及其含义和设置方法。
参数详解:1. hosts:Elasticsearch集群的地址列表,可以是一个IP地址或主机名,多个地址之间用逗号分隔。
默认为一个IP地址。
2. index:要连接的Elasticsearch索引名称。
3. type:要连接的Elasticsearch数据类型,通常为文档类型。
4. port:Elasticsearch服务器端口号,默认为9200。
5. authentication:是否启用身份验证,如果启用,需要提供用户名和密码。
6. username/password:身份验证的用户名和密码。
7. retry_on_failure:是否重试失败的操作,默认为true。
8. max_retries:失败操作的最大重试次数。
9. request_timeout:请求超时时间。
10. bulk_size:批量操作的大小。
11. bulk_interval:批量操作的间隔时间。
12. read_timeout:Elasticsearch读取超时时间。
13. connect_timeout:Elasticsearch连接超时时间。
14. transport_timeout:Elasticsearch传输超时时间。
15. transport_compress:是否压缩传输数据,默认为false。
16. transport_no_compress_list:避免传输压缩的列名列表。
17. yml/properties:elasticsearch-hadoop的配置文件格式,默认为yml。
《Hadoop大数据技术与应用》-熟悉基于Eclipse+

《Hadoop大数据技术与应用》实验报告实验3:熟悉基于Eclipse+ Maven的JAVA开发环境一、实验目的1.了解如何使用Eclipse进行创建Maven工程、运行Maven工程。
2.了解Maven的一些基本命令,如打包命令二、实验环境Ubuntu16.04 desktop三、实验内容与实验过程及分析(写出详细的实验步骤,并分析实验结果)实验内容:实验3:使用Eclipse+Maven环境,开发”Hello World”程序,并运行实验步骤:(1)选择Eclipse工作空间目录(2)设置Maven环境:点击Eclipse菜单【Window】-->【Preferences】在左侧目录中找到【Maven】-->【Installations】,默认的内嵌的Maven,则点击【Add】按钮,点击【Directory】,选择目录:/opt/maven/apache-maven-3.5.0点击【Finish】.点击【Finish】后,可以看到下图所示增加了maven,点击前面的选择框,将它选中。
后面Eclipse的Maven将采用此apache-maven-3.5.0点击【Maven】-->【User Settings】,点击【Browse】,选择文件/opt/maven/apache-maven-3.5.0/conf/settings.xml 最后点击【OK】关闭(3)创建Maven工程:点击菜单【New】->【New】->【Project】,选择【Maven】 ->【Maven Project】,点击【Next】,工程所在目录默认为工作空间即可,点击【Next】,项目类型,默认即可。
输入组织名和项目名,点击【Finish】。
(4))修改pom.xml,指定工程的主类:选择pom.xml,并编辑修改pom.xml,在</project>前增加下面内容<mainClass>与</mainClass> 之间的内容表示主类,注意修改为实际工程的主类(5)pom.xml修改后,刷新工程(刷新工程的目的是重新刷新依赖等).(6) 在Eclipse中运行工程(7) 获取工程所在目录(8)在命令行中构建(打包)工程打开命令行,并切换到工程所在目录,该目录即是上一步复制的路径,如:cd /home/ua15/eclipse_hadoop/cddmvn clean package(9) 在命令行中运行查看生成的jar包:ls target运行jar包:java -jar target/cdd-0.0.1-SNAPSHOT.jar实验结果图为:四、实验总结(每项不少于20字)存在问题:运行时一直出错,一直找不到原因,网络找解决方案时也不知道从哪点入手。
apache-hadoop环境搭建基本hadoop指令介绍

apache-hadoop环境搭建基本hadoop指令介绍hadoop环境搭建预先准备:软件兼容性调查:在安装hadoop时应该考虑到将来使⽤得情况,⼀般我们除了安装hadoop之外,还会安装hbase,hive,zookeeper等,这些软件之间会存在兼容性问题,再安装前,需要调研完整后选择合适的版本hadoop硬件安装需求:通常,安装hadoop⾄少需要三台主机,这是因为分布式存储的备份逻辑要求,⼀份⽂件需要有三个副本,这就导致⾄少要有三台node data主机。
由于namenode主机可以与node data主机共存再⼀台机器上,这样⽤户就可以在三台主机上搭建⼀个hadoop分布式存储环境。
在这⾥,我们采⽤四台主机的⽅式来搭建hadoop分布式存储环境,使⽤户能够更好,更快的理解分布式存储的概念和模块功能。
安装拓扑结构图:数据流hadoop账户配置IP192.168.10.110192.168.10.111192.168.10.112192.168.10.113hostname namenode node1node2node3user hadoop hadoop hadoop hadoopssh√√√√ntp√√√√通⽤环境准备:java编译环境准备:防⽕墙关闭systemctl stop firewalld.servicesystemctl disable firewalld.service结点时间同步准备:ntp服务器ssh⽆密码访问准备:为普通结点创建管理账户以下操作需要通过ssh登录相应主机后,在结点上执⾏,默认username和passwd均为hadoop,在下⾯的参数中也使⽤hadoop新建账户:sudo useradd -d /home/{username} -m {username}为账户创建密码:sudo passwd {username}给账户提升root权限:echo "{username} ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/{username}sudo chmod 0440 /etc/sudoers.d/{username}为namenode结点创建⽅便的管理⽅法注:以下操作都是针对name-node结点,hadoop⽤户。
eclipse开发hadoop程序
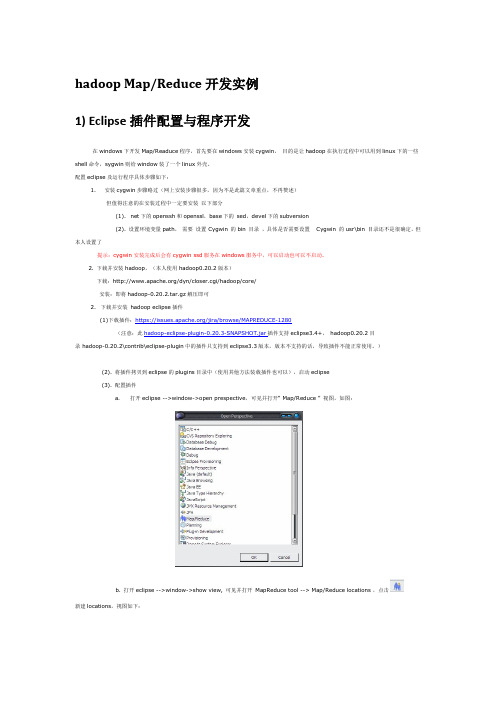
hadoop Map/Reduce开发实例1) Eclipse插件配置与程序开发在windows下开发Map/Readuce程序,首先要在windows安装cygwin,目的是让hadoop在执行过程中可以用到linux下的一些shell命令,sygwin则给window装了一个linux外壳。
配置eclipse及运行程序具体步骤如下:1. 安装cygwin步骤略过(网上安装步骤很多,因为不是此篇文章重点,不再赘述)但值得注意的在安装过程中一定要安装以下部分(1). net下的openssh和openssl,base下的sed,devel下的subversion(2). 设置环境变量path,需要设置 Cygwin 的bin 目录,具体是否需要设置 Cygwin 的usr\bin 目录还不是很确定,但本人设置了提示:cygwin安装完成后会有cygwin ssd服务在windows服务中,可以启动也可以不启动。
2. 下载并安装hadoop,(本人使用hadoop0.20.2版本)下载:/dyn/closer.cgi/hadoop/core/安装:即将hadoop-0.20.2.tar.gz解压即可2. 下载并安装hadoop eclipse插件(1)下载插件:https:///jira/browse/MAPREDUCE-1280(注意:此hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar插件支持eclipse3.4+,hadoop0.20.2目录 hadoop-0.20.2\contrib\eclipse-plugin中的插件只支持到eclipse3.3版本,版本不支持的话,导致插件不能正常使用。
)(2). 将插件拷贝到eclipse的plugins目录中(使用其他方法装载插件也可以),启动eclipse(3). 配置插件a.打开eclipse -->window->open prespective,可见并打开“ Map/Reduce ” 视图,如图:b. 打开eclipse -->window->show view, 可见并打开MapReduce tool --> Map/Reduce locations ,点击新建locations,视图如下:General选项卡各个参数说明:Location name:本地视图的location名称,自己自定义一个名称即可Map/Reduce Master组内host和port: 为Map/Reduce Master的地址与端口号,此地址端口与hadoop服务器安装配置过程中conf/mapred-site.xml文件中mapred.job.tracker节点值一致。
HADOOP(4)eclipse开发整合
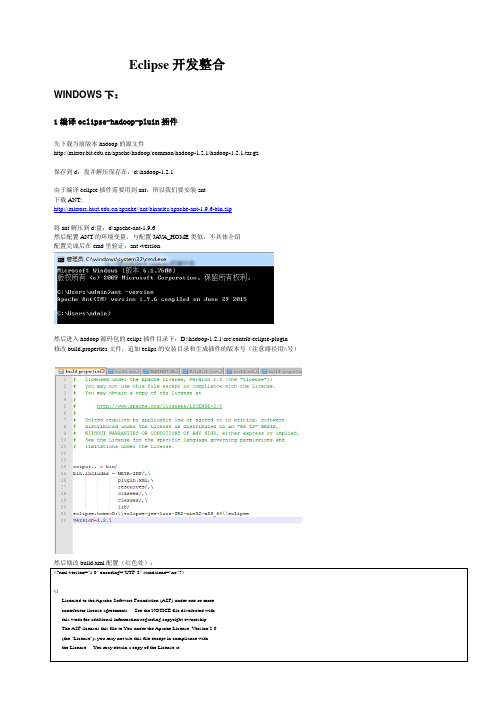
Eclipse开发整合WINDOWS下:1编译eclipse-hadoop-pluin插件先下载当前版本hadoop的源文件/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz保存到d:盘并解压保存在:d:\hadoop-1.2.1由于编译eclipse插件需要用到ant,所以我们要安装ant下载ANT:/apache//ant/binaries/apache-ant-1.9.6-bin.zip将ant解压到d:盘:d\apache-ant-1.9.6然后配置ANT的环境变量,与配置JA V A_HOME类似,不具体介绍配置完成后在cmd里验证:ant -version然后进入hadoop源码包的eclips插件目录下:D:\hadoop-1.2.1\src\contrib\eclipse-plugin修改build.properties文件,追加eclips的安装目录和生成插件的版本号(注意路径用\\号)然后修改build.xml配置(红色处):<?xml version="1.0" encoding="UTF-8" standalone="no"?><!--Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.--><project default="jar" name="eclipse-plugin"><import file="../build-contrib.xml"/><path id="eclipse-sdk-jars"><fileset dir="${eclipse.home}/plugins/"><include name="org.eclipse.ui*.jar"/><include name="org.eclipse.jdt*.jar"/><include name="org.eclipse.core*.jar"/><include name="org.eclipse.equinox*.jar"/><include name="org.eclipse.debug*.jar"/><include name="org.eclipse.osgi*.jar"/><include name="org.eclipse.swt*.jar"/><include name="org.eclipse.jface*.jar"/><include name="org.eclipse.team.cvs.ssh2*.jar"/><include name="com.jcraft.jsch*.jar"/></fileset><fileset dir="D:/hadoop-1.2.1"><include name="hadoop*.jar"/></fileset></path><!-- Override classpath to include Eclipse SDK jars --><path id="classpath"><pathelement location="${build.classes}"/><pathelement location="${hadoop.root}/build/classes"/><path refid="eclipse-sdk-jars"/></path><!-- Skip building if eclipse.home is unset. --><target name="check-contrib" unless="eclipse.home"><property name="skip.contrib" value="yes"/><echo message="eclipse.home unset: skipping eclipse plugin"/></target><target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib"><echo message="contrib: ${name}"/><javacencoding="${build.encoding}"srcdir="${src.dir}"includes="**/*.java"destdir="${build.classes}"debug="${javac.debug}"deprecation="${javac.deprecation}"><classpath refid="classpath"/></javac></target><!-- Override jar target to specify manifest --><target name="jar" depends="compile" unless="skip.contrib"><mkdir dir="${build.dir}/lib"/><copy file="D:/hadoop-1.2.1/hadoop-core-${version}.jar" tofile="${build.dir}/lib/hadoop-core.jar" verbose="true"/> <copy file="D:/hadoop-1.2.1/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="D:/hadoop-1.2.1/lib/commons-configuration-1.6.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/commons-httpclient-3.0.1.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/commons-lang-2.4.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/jackson-core-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/jackson-mapper-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/><jarjarfile="${build.dir}/hadoop-${name}-${version}.jar"manifest="${root}/META-INF/MANIFEST.MF"><fileset dir="${build.dir}" includes="classes/ lib/"/><fileset dir="${root}" includes="resources/ plugin.xml"/></jar></target></project>修改D:\hadoop-1.2.1\src\contrib\eclipse-plugin\META-INF文件夹下的MANIFEST.MF文件(红色部分):Manifest-Version: 1.0Bundle-ManifestVersion: 2Bundle-Name: MapReduce Tools for EclipseBundle-SymbolicName: org.apache.hadoop.eclipse;singleton:=trueBundle-Version: 0.18Bundle-Activator: org.apache.hadoop.eclipse.ActivatorBundle-Localization: pluginRequire-Bundle: org.eclipse.ui,org.eclipse.core.runtime,unching,org.eclipse.debug.core,org.eclipse.jdt,org.eclipse.jdt.core,org.eclipse.core.resources,org.eclipse.ui.ide,org.eclipse.jdt.ui,org.eclipse.debug.ui,org.eclipse.jdt.debug.ui,org.eclipse.core.expressions,org.eclipse.ui.cheatsheets,org.eclipse.ui.console,org.eclipse.ui.navigator,org.eclipse.core.filesystem,mons.loggingEclipse-LazyStart: trueBundle-ClassPath: classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-configuration-1.6.jar,lib/commons-httpclient-3.0.1.jar,lib/commons-lang-2.4.jar,lib/jackson-core-asl-1.8.8.jar,lib/jackson-mapper-asl-1.8.8.jarBundle-Vendor: Apache Hadoop然后在cmd下进入到D:\hadoop-1.2.1\src\contrib\eclipse-plugin目录,运行ant:cd D:\hadoop-1.2.1\src\contrib\eclipse-pluginant jar完成后提示:然后在D:\hadoop-1.2.1\build\contrib\eclipse-plugin下会看到生成了文件hadoop-eclipse-plugin-1.2.1.jar,将其拷贝到eclipse安装目录下的plugins 的文件夹下(D:\eclipse-jee-luna-SR2-win32-x86_64\eclipse\plugins)然后启动eclipse可以看到插件已经有了然后配置我们的hadoop:Window-->Preferences-->Hadoop Map/Reduce填入hadoop本机上hadoop源码包解压所放的目录配置Hdfs位置:Windows -->Show View -->Other-->MapReduce Tools-->Map/Reduce Location然后在在Map/Reduce Location视图下New Hadoop Location填入hdfs地址及jobTracker端口和NameNode端口(很可惜的是这里的User name填hadoop或者其他说明值如果是window系统都不起作用,很是坑爹。
Hadoop2.7.0环境搭建详细笔记

Hadoop安装说明 所需软件: VMware Workstation 10.0 用于创建虚拟机 CentOS-6.4-x86_64-bin-DVD1.iso 操作系统 jdk-8u45-linux-x64.tar java运行库 hadoop-2.7.0.tar.gz Hadoop安装包 xshell_4.0.0131.1397032097 Xshell工具
一、安装操作系统
用VMware Workstation 10.0创建三个虚拟机,分别为master、slaves1、slaves2,操作系统为CentOS-6.4
二、配置IP地址
以root用户执行,所有节点都需要执行。配置IP地址一共有两种方式: A、使用NAT模式 虚拟机网络连接使用NAT模式,物理机网络连接使用Vmnet8。 虚拟机设置里面——网络适配器,网络连接选择NAT模式。()
虚拟机菜单栏—编辑—虚拟网络编辑器,选择Vmnet8 NAT模式, 1.在最下面子网设置ip为192.168.30.0 子网掩码255.255.255.0 2.NAT设置里面网关IP为192.168.30.1 3.使用本地DHCP服务将IP地址分配给虚拟机不勾选 设置完成后点击应用退出。 设置虚拟机的ip,虚拟机ip必须和Vmnet8在同一网段 #vi /etc/sysconfig/network-scripts/ifcfg-eth0 输入上述命令后回车,打开配置文件,使用方向键移动光标到最后一行,按字母键“O”,进入编辑模式,输入
完成后,按一下键盘左上角ESC键,输入:wq 在屏幕的左下方可以看到,输入回车保存配置文件。
设置DNS地址,运行命令#vi /etc/resolv.conf 光标移动到空行,按“O”键,输入 nameserver 192.168.30.2 退出按ESC键,输入:wq 回车保存配置文件。
重启网络服务 #service network restart 重启之后#ifconfig 查看配置的ip地址,物理机ping这个地址测试是否能通。
hadoop集群eclipse安装配置

第二步: 选择"Window"菜单下的"Preference", 然后弹出一个窗体, 在窗体的左侧, 有一列选项, 里面会多出"Hadoop Map/Reduce"选项, 点击此选项, 选择 Hadoop 的安装目录 (如我的 Hadoop 目录: E:\HadoopWorkPlat\hadoop-1.0.0) 。 结果如下图:
"中的"
",点击"Other"选项,也可以弹出上图,从中选
7 / 30
第四步:建立与 Hadoop 集群的连接,在 Eclipse 软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选 择"New Hadoop Location",然后弹出一个窗体。
8 / 30
注意上图中的红色标注的地方,是需要我们关注的地方。
hadoop fs -ls
Байду номын сангаас
12 / 30
到此为止,我们的 Hadoop Eclipse 开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到 HDFS 分布式文件上, 可以互相对比意见文件是否已经上传成功。 3、Eclipse 运行 WordCount 程序 配置 Eclipse 的 JDK 如果电脑上不仅仅安装的 JDK6.0,那么要确定一下 Eclipse 的平台的默认 JDK 是否 6.0。从"Window"菜单下选择 "Preference",弹出一个窗体,从窗体的左侧找见"Java",选择"Installed JREs",然后添加 JDK6.0。下面是我的默认选择 JRE。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
搭建eclipse的hadoop开发环境知识点
一、概述
在大数据领域,Hadoop是一个非常重要的框架,它提供了分布式存储和处理海量数据的能力。
而Eclipse作为一款强大的集成开发环境,为我们提供了便利的开发工具和调试环境。
搭建Eclipse的Hadoop 开发环境对于开发人员来说是必不可少的。
本文将从安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等方面来详细介绍搭建Eclipse的Hadoop开发环境的知识点。
二、安装Hadoop插件
1. 下载并安装Eclipse
我们需要在全球信息湾上下载最新版本的Eclipse,并按照提示进行安装。
2. 下载Hadoop插件
在Eclipse安装完成后,我们需要下载Hadoop插件。
可以在Eclipse 的Marketplace中搜索Hadoop,并进行安装。
3. 配置Hadoop插件
安装完成后,在Eclipse的偏好设置中找到Hadoop插件,并按照提示进行配置。
在配置过程中,需要指定Hadoop的安装目录,并设置一些基本的环境变量。
三、配置Hadoop环境
1. 配置Hadoop安装目录
在Eclipse中配置Hadoop的安装目录非常重要,因为Eclipse需要
通过这个路径来找到Hadoop的相关文件和库。
2. 配置Hadoop环境变量
除了配置安装目录,还需要在Eclipse中配置Hadoop的环境变量。
这些环境变量包括HADOOP_HOME、HADOOP_COMMON_HOME、HADOOP_HDFS_HOME等,它们指向了Hadoop的各个组件所在的目录。
3. 配置Hadoop项目
在Eclipse中创建一个新的Java项目,然后在项目的属性中配置Hadoop库,以及其它一些必要的依赖。
四、创建Hadoop项目
1. 导入Hadoop库
在新建的Java项目中,我们需要导入Hadoop的相关库,比如hadoopmon、hadoop-hdfs、hadoop-mapreduce等。
2. 编写Hadoop程序
在项目中编写Hadoop程序,可以通过MapReduce、Hive、Pig等
方式来处理Hadoop中的数据。
3. 调试Hadoop程序
在Eclipse中可以很方便地调试Hadoop程序,通过设置断点和观察
变量来分析程序的执行过程。
五、总结与展望
通过本文的介绍,我们了解了如何搭建Eclipse的Hadoop开发环境,包括安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等
知识点。
搭建好开发环境后,我们可以方便地进行Hadoop程序的开发和调试。
未来,随着大数据技术的不断发展,我们也需要不断地学
习和更新知识,以适应发展的需求。
个人观点与理解
搭建Eclipse的Hadoop开发环境是学习和应用大数据技术的基础,
只有搭建好了开发环境,我们才能更好地进行Hadoop程序的开发和
调试。
随着大数据技术的发展,我们也需要不断地更新知识,学习新
的技术和工具,以适应行业的发展需求。
在搭建开发环境的过程中,我们也需要注重细节,确保每一步都正确
无误。
只有这样,才能保证后续的开发工作顺利进行。
我们也可以通
过搭建开发环境的过程来加深对Hadoop框架的理解,从而更好地应用和创新。
在未来,我会继续深入学习和应用大数据技术,不仅限于搭建开发环境,还会深入研究Hadoop的原理和应用,为行业的发展贡献自己的力量。
在这篇文章中,我们详细介绍了搭建Eclipse的Hadoop开发环境的知识点,包括安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等。
通过深入的研究和实践,我们可以更好地理解和应用Hadoop技术,为大数据领域的发展贡献自己的力量。
在大数据领域中,Hadoop是一个非常重要的框架,用于存储和处理海量数据。
与此Eclipse作为一款强大的集成开发环境,为开发人员提供了便捷的开发工具和调试环境。
搭建Eclipse的Hadoop开发环境对于从事大数据开发的工程师来说是至关重要的。
本文将继续介绍搭建Eclipse的Hadoop开发环境的知识点和具体步骤。
六、Hadoop环境搭建
1. 安装JDK
在搭建Hadoop开发环境之前,首先需要安装Java Development Kit (JDK)。
JDK是用于编写和运行Java程序的软件开发工具包,是使用Java编程语言的必需工具。
在安装JDK后,需要配置
JAVA_HOME环境变量,指向JDK安装的路径。
2. 下载和配置Hadoop
接下来,需要下载Hadoop的安装包,并解压到本地。
在配置Hadoop环境变量时,需要设置HADOOP_HOME环境变量,指向Hadoop安装的路径。
还需要添加Hadoop的bin目录到系统的Path环境变量中,以便在命令行中能够直接调用Hadoop命令。
3. 配置Hadoop集群
如果需要搭建一个Hadoop集群来进行开发和测试,需要对Hadoop 的配置文件进行相应的修改。
Hadoop的主要配置文件包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等,需要根据实际情况进行配置。
4. 启动Hadoop集群
在配置好Hadoop集群后,需要启动Hadoop集群。
可以使用start-dfs.sh命令来启动Hadoop分布式文件系统(HDFS),使用start-yarn.sh命令来启动YARN资源管理器。
启动成功后,可以通过浏览器访问Hadoop的Web界面,查看集群的状态和资源使用情况。
七、创建Hadoop项目
1. 在Eclipse中创建Hadoop项目
在安装了Hadoop插件和配置好Hadoop环境后,可以在Eclipse中创建一个新的Java项目。
在创建项目时,需要添加Hadoop的Jar包
到项目的构建路径中,以便在项目中使用Hadoop的API。
2. 编写MapReduce程序
Hadoop的核心功能是MapReduce,因此在Hadoop项目中,通常会编写MapReduce程序来处理数据。
MapReduce程序包括Mapper和Reducer两个阶段,需要在项目中编写相应的Mapper和Reducer类,并进行数据处理和计算。
3. 调试Hadoop程序
在Eclipse中可以方便地调试Hadoop程序。
可以通过设置断点和监视变量来分析程序的执行过程,帮助定位和解决程序中的问题。
八、总结
通过本文的介绍,我们了解了如何在Eclipse中搭建Hadoop开发环境,包括安装Hadoop插件、配置Hadoop环境、创建Hadoop项目等知识点。
搭建好了开发环境后,可以方便地进行Hadoop程序的开发和调试。
在实际开发中,还需要不断地深入学习和积累经验,提升自己在大数据领域的技术水平。
在未来,随着大数据技术的不断发展,我们还需要不断地更新知识,学习新的技术和工具,以适应行业的发展需求。
只有不断地学习和实践,才能更好地适应大数据领域的发展,并做出更大的贡献。
希望通
过本文的介绍,读者能够对搭建Eclipse的Hadoop开发环境有更深入的了解,并能够在实际工作中应用到相关的技术和方法。