基于粗糙集——信息熵的水质综合评价方法研究
基于粗糙集理论的数据挖掘方法(2006.10.16)

关于属性选择
许多学习算法处理高维数据有困难, 并且大量 无关属性的存在, 也使得数据分析受到干扰. 目的是找到满足特定标准的最小的属性子集. 搜索算法起着重要的作用. 搜索算法可以用搜 索方向(前向, 后向, 双向), 搜索方式(穷尽搜索, 启发式, 非确定式)及评价方式(精确度, 一致性, 依赖度, 信息熵等)等三个方面来分类. 约简的特点是可以保持分类/近似能力不变。
x5
x6 x7
MBA
MCE MSc
Low
Low Medium
Yes
Yes Yes
Neutral
Good Neutral
Reject
Reject Reject
x8
MCE
x1
Low
x2 x3
No
x4
Excellent
x5 x6
Reject
x7 x8
x1 x2 x3 x4 x5 x6 x7 x8 er der dr def de der e defr der der er def efr def defr der
例如,x1的决策函数 为f(x1)=(e r) (d e r) (d r) (d e f) 整个Accept类的决策 函数为f(Accept)=f(x1) f(x2) f(x3) f(x4) 化成析取范式后,各 项就是Accept类最小 决策规则
粗糙集和其他理论方法结合
和模糊集(Fuzzy set) ►模糊粗糙集(Fuzzy-Rough set) ► 应用:特征选择 聚类 ►Rough K-means ►应用: Web挖掘
粗糙集的问题
粗糙集理论应用于实际数据分析时, 会遇到 -离散化: - 噪音: 过拟合 - 数据缺失: 如何“不可区分” ? - 大数据量: 计算复杂度太高.
【国家自然科学基金】_模型评价_基金支持热词逐年推荐_【万方软件创新助手】_20140731
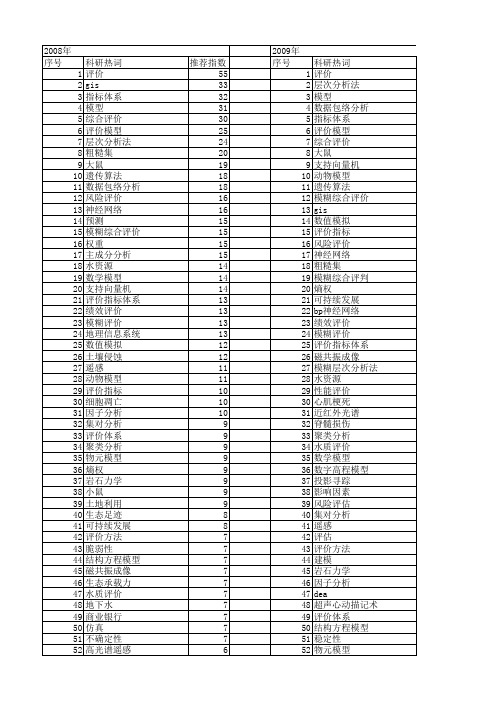
满意度 水质 气候变化 模糊理论 桥梁工程 有限元 效率评价 安全评价 地理信息系统 高光谱 风险 运筹学 血管生成 脆弱性 能源利用 综述 粒子群算法 疾病模型,动物 电子商务 生态足迹 环境影响评价 环境影响 熵 灰色系统 灰色关联分析 滑坡 权重 服务质量 最小二乘支持向量机 层次分析法(ahp) 小鼠 小波分析 定量评价 大鼠模型 多目标决策 多目标 地下水 预测 非点源污染 随机petri网 量表 道路工程 血管内皮生长因子 脑缺血 肿瘤 缺血预处理 生态承载力 生态安全 猪 物元分析 物元 深圳 海马 水资源承载力
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 1分异 稳定性 监测模型 生态安全 环境雌激素 独立作用 熵 灰色理论 湿地 湍流模型 浓度相加 模糊理论 模型,动物 有限元 数据挖掘 效率评价 振动台试验 指标 投影寻踪 实物期权 多目标优化 协调度 动脉粥样硬化 优化 黑河中游 黄河三角洲 黄土丘陵区 高血压 高管人员 高光谱 骨髓移植 风险 风-汽车-桥梁系统 顾客需求 项目管理 鞘内 隧道 重要度 道路工程 超声心动图 资源配置 质量屋 质量功能展开 质量 负荷预测 评价因子 西安市 自然崩落法 联合作用 耕地质量 耕地
科研热词 评价 层次分析法 模型 数据包络分析 指标体系 评价模型 综合评价 大鼠 支持向量机 动物模型 遗传算法 模糊综合评价 gis 数值模拟 评价指标 风险评价 神经网络 粗糙集 模糊综合评判 熵权 可持续发展 bp神经网络 绩效评价 模糊评价 评价指标体系 磁共振成像 模糊层次分析法 水资源 性能评价 心肌梗死 近红外光谱 脊髓损伤 聚类分析 水质评价 数学模型 数字高程模型 投影寻踪 影响因素 风险评估 集对分析 遥感 评估 评价方法 建模 岩石力学 因子分析 dea 超声心动描记术 评价体系 结构方程模型 稳定性 物元模型
基于粗糙集的故障诊断方法_谭天乐

第37卷第1期2003年1月浙 江 大 学 学 报(工学版)J o urnal o f Zhejiang U niv er sity (Eng ineering Science)V ol.37No.1Jan.2003收稿日期:2002-03-27.基金项目:国家自然科学基金资助项目(20076040).作者简介:谭天乐(1973-),男,湖南长沙人,博士生,从事数据挖掘、粗糙集、故障诊断技术的研究.E-mail :tltan @iipc.zju.ed 基于粗糙集的故障诊断方法谭天乐,宋执环,李 平(工业控制技术国家重点实验室;浙江大学工业控制技术研究所,浙江杭州310027)摘 要:利用粗糙集理论对决策表进行约简以自动获取过程工业生产系统中的故障知识,从信息熵的角度分析系统知识不确定性的变化,提出了一种基于粗糙集理论的故障诊断新方法,研究了粗糙集理论在故障诊断中的适用性,在前向推理和反向推理的基础上,给出了针对故障点建立决策表以及利用粗糙集约简所获得的诊断规则进行正、反向故障诊断的步骤,讨论了这种故障诊断方法的诊断性能及其在计算上的复杂度.通过这种方法能够进行故障的寻找和定位,实例分析的结果说明了利用粗糙集进行知识发现及建立智能故障诊断系统的可行性和有效性.关键词:故障诊断;粗糙集;信息熵中图分类号:T P277 文献标识码:A 文章编号:1008-973X (2003)01-0047-04Approach for fault detection and diagnosisbased on rough setT AN Tian-le,SON G Zhi-huan,LI P ing(N ational Lab oratory of Industrial Control Technology ,Institute of Industrial Process Control ,Zhejiang University ,Hangzhou 310027,China )Abstract :So me wo rk has been do ne fo r dealing with Fault Detection and Diag nosis (FDD)based o n Ro ugh Set,but in those cases Rough Set w as just reg arded as a to ol for data cleaning o r fo r assisting of other m ethods ,o r for detecting w hether a sy stem has fault but usually canno t tell w here it happened .To solv e this problem ,a new a pproach fo r FDD based on Ro ugh Set is pro po sed.The applicability and com puta-tional complexity of this approach is discussed.Know ledge abo ut a process contro l system 's faults is ob-tained auto matically by Rough Set v alue reduction ;a n entropy -based criterion is used to measure the un-certainty o f it .Methods o f forw ard and backwa rd fault diagnosis and ho w to build up decisio n tables fo r each fault source a re giv en.The feasibility of forming a kno w ledge discov ering and intellig ent decision-m aking sy stem for FDD based on Rough Set Theo ry is discussed through a case study.Key words :fault detection and diag no sis ;rough set ;informa tion entro py 基于粗糙集的故障诊断(fault detectio n a nd di-ag nosis ,FDD )技术是一种基于知识的“软诊断”技术.工业过程系统都是某种热机系统[1],当系统处于一个不随时间变化的恒定的外部条件下时,经过一段时间,系统达到一个在宏观上不随时间变化的定态.在定态下系统各个部分的熵不随时间变化.熵[1]是热力学中微观状态多样性或均匀性的一种度量,反映了系统微观状态的分布几率,将热力学几率扩展到系统各个信息源信号出现的几率就形成了信息熵[2].信息熵标志着所含信息量的多少.信息构成关于系统的知识.粗糙集理论是一种处理模糊和不确定知识的工具,它简化决策规则,提取有效的信息,能够解决知识冗余性的问题.从信息熵的角度来理解和分析粗糙集所提取的知识量,粗糙集决策表的变化表示了系统知识的变化,将这种系统知识的变化定义为故障,就可以在粗糙集的基础上对系统进行FDD.1 粗糙集简介在粗糙集理论[3]中,知识被认为是一种对现实事物进行分类的概念.用四元组S =(U ,R ,V ,f )来表述一个知识系统.其中U ={x 1,x 2,…,x n }为有限非空集合,称为论域.使用属性R j ∈R ,属性值v ij ∈V Ri V 来描述论域中的对象x j .属性构成了等价关系,也即分类方法.f :U ×R →V 是一个信息函数,它为每个对象的每个属性赋予一个信息值.U /R 表示利用R 将U 分成的等价类的集合.粗糙集中的知识系统用决策表的形式表示,其中决策表的列为属性,决策表的行为样本,决策表中的一个属性对应一个等价关系.在粗糙集理论的基础上找到决策表的属性约简,再经过属性值约简得到决策规则,这些规则表示了样本中的知识.2 系统不确定性分析——信息熵文[2]介绍了粗糙集知识系统中信息熵的概念.本文利用信息熵分析从样本约简得到的规则所推广生成的集合,根据约简后的决策表重新定义粗糙集中信息熵的概念,可以得到:设U 0为一个热机系统各个信号源所有可能状态组合所构成的集合.P (故障源)、Q (系统工况)为U 0上的两个等价关系子集,将U 0上的任一等价关系看作是一个随机变量.样本集合U U 0经过约简之后形成由知识规则集K 、条件属性集C P 、决策属性集D Q 所构成的最简决策表,这个决策表的规则K 描述了一个子集U 1,U U 1 U 0,U 1是样本集合U 的推广.求得C 、D 的等价类在U 1中的分布情况X 、Y 分别为X =(X 1,X 2,…,X m ),Y =(Y 1,Y 2,…,Y n ).知识C 的信息熵定义为:H (P )=-∑p (X i )log p (X i );其中,p (X i )=ca rd (X i )/ca rd (U 0).类似的有知识D 的信息熵H (D ).知识D 相对于知识C 的条件熵H (D |C )为H (D |C )=-∑nmi =1p (X i)∑n j =1p (Y j |X i )lo g p (Y j |X i ). 知识C 与D 的互信息I (C ,D )为I (C ,D )=H (D )-H (D |C ).如果新样本符合决策表,信号的不确定性及几率分布是确定的,信息熵不变,认为系统没有故障.当新样本与决策表相矛盾时,U 1、故障源自身的信息熵,以及它与其他信号源、系统状态之间的互信息熵将发生变化,认为系统发生了故障.3 故障诊断的步骤 步骤1:系统故障的判断利用粗糙集判断系统是否产生故障的程序为:根据实际生产情况从系统中选择相关的故障源信号和生产状况信号作为条件属性和决策属性,通过数据采样建立知识表达的决策表;剔除冗余及不相容数据,对数据进行清洗;剔除冗余属性,寻找属性约简;提取故障诊断规则并对这些规则进行评价;利用故障诊断规则对新的输入进行诊断.如果新样本符合决策表,说明关于系统的知识没有改变,信息熵没有变化,系统运行正常,否则进入故障定位.对于过程工业生产数据还需要对连续属性适当离散化,采用布尔逻辑与粗糙集相结合的方法可以比较好地解决这个问题.约简后的最简决策表可以与其他的方法结合对系统进行故障诊断,例如将最简规则表作为神经网络输入,构造神经网络结构,或者与小波、模糊集相结合等等. 步骤2:故障定位为了找到故障源的位置和原因,对样本作如下划分:设F =(f 1,f 2,…,f m )为信号源集合,P =(p 1,p 2,…,p n )为工况集合,U 为规则总结样本.①单点故障正向定位每次取一个信号源作为决策属性D i ={f i },以剩下的信号源和工况信号作为粗糙集中的条件属性C i ={f 1,f 2,…,f i -1,f i +1,…,f m ,p 1,p 2,…,p n },构成单点故障定位决策表.将数据按照以上方式构成m 个决策表,每一个决策表约简后得到一个故障点的FDD 正向规则集合.这个规则集合表示该故障点信号状态是与其他故障点及工况信号的哪些状态相对应.对于一个新的信号样本,如果样本与该点的FDD 规则不矛盾,则该点状态正常.如果与该点的某条FDD 规则相矛盾,则该点可能发生故障,并且与之矛盾的规则指出了该点发生故障的可能原因.得到的决策规则具有规则协调性,即相同的规则前部一定具有相同的规则后部,不同的规则前部允许有不同的或者相同的规则后部,相同的后部允许有相同或者不同的规则前部.②单点故障反向定位单点FDD 正向规则指正常情况下时,故障和工况之间的对应关系.这些规则相当于P →Q ,若X i ∈48浙 江 大 学 学 报(工学版) 第37卷 P 但X i ∈Q -,则系统可能出现故障.粗糙集的约简过程还保证了在样本集合中Q →P 成立,这些规则即为反向FDD 规则;若X i ∈Q 但X i ∈P -,则系统同样可能出现故障.当一个样本满足某一正向FDD 规则的后部时,如果它同时满足对该规则前部取反,则判断系统发生故障并且与之矛盾的规则指出了故障大致产生的原因.③多点故障定位当信号源之间存在耦合或同时发生多个故障时,通过单点FDD 决策表可能找不到对应的故障点.类似于单点FDD 决策表,构造多点FDD 决策表.需同时关心信号源i 和信号源j 的状况,则选择条件属性C ij ={f 1,f 2,…,f i -1,f i +1,…,f j -1,f j +1,…,f m ,p 1,p 2,…,p n },决策属性为D i ={f i ,f j }.将混合信号源D i 作为单信号源来考虑,其余的分析步骤同单点故障分析.步骤3:故障诊断的性能分析利用粗糙集获得的FDD 知识是从有限的样本中得到的.有限的样本蕴涵有限的知识,U U 0.知识的推广具有有限的可信度,U U 1.有限的知识只能对有限的情况作诊断,U 1 U 0.利用集合和概率的方法分析U 、U 1、U 0三者之间的关系就可以了解以上方法中所获得的FDD 知识的质量.这里U 0应该是一个有限集合.粗糙集知识系统S =(U ,R ,V ,f )中信息函数f 应该是确定的.即信号源可以正确分类.这实际上界定了信号源信息量的多少,这时才可以从信息熵的角度,进行基于粗糙集的故障诊断.利用精度和重要性的概念,可以定量分析信号源与其他信号源及工况的相互影响程度.令S a (W )=W (U /a )-=∪V ∈U /a ,V W V ,(W U )表示W 关于故障a 的支持子集.定义spt a (y )=|S a (W )|/|U |为W 关于故障a 的支持度或称为逼近精度[5],表示由规则约简样本所总结的关于a 点故障的知识在所有样本中的对a 点故障情况的支持度.定义a 故障点近似精度为acc a (W )=|W (U /a )-|/|W(U /a )+|,表示利用a 点故障决策表所作决策的精度,其中W (U /a )+=∪V ∈U /a ,V ∩W ≠hV .通过以上的性能指标结合粗糙集中的上、下界及边界概念,就可以对以上基于粗糙集的FDD 方法进行定性和定量的精确分析.4 计算复杂性分析粗糙集方法一个主要的局限性在于粗糙集的计算量过大.令(U ,A )为一个信息系统,U ={u 1,u 2,…,u |U |}包含|U |个样本;A =C ∪D ,C ∩D =O ,A 属性集合,C 为条件属性子集,D 为决策属性子集.对于X A ,粗糙集决策表约简过程的计算复杂度为O (2|X ||A ||U |2).对单故障源信号建立故障定位决策表需要(|U |)×(|U |-1)/2=O (|U 2|)次计算.对多故障源信号建立故障定位决策表计算的是属性划分的交集.令A ′ A 为感兴趣的故障点信号集合,则计算U /A ′的计算复杂度为O (|A ′||U |2).W (U /a )-及W (U /a )+的计算复杂性为O (|U |).单点FDD 决策支持度及精度的计算复杂度均为O (|U |).5 实 例图1为双效蒸发器带主要控制点的流程图.组分为X F 的料液注入蒸发器2蒸发,然后进入蒸发器1蒸发后将溶质组分提高为X I .图1 双效蒸发过程示意图Fig.1 Double effec t ev apor ato r对蒸发器2建立FDD 决策表.以X 2作为系统运行的工况,将W F 、W S1、W S2作为故障源,其中W S1、W S2为从蒸发器1、2顶部汽化的蒸汽流量;W F 为进入蒸发器2的料液质量流量;X 2为蒸发器2内的溶质重量分数.通过模型仿真获得系统正常运行时的各点信号数据,离散化后得到以下8种正常运行状态,如表 1.表1 工况决策表Ta b.1 Sy stem decision table编号W S1W S2W F X 21A(高)A A(高)Bb(低)1(高)2B (中)BB (中)Aa (高)1(高)3A(高)CC(低)Bb(低)2(偏高)4B (中)CC (低)Aa (高)2(偏高)5C(低)A A(高)Bb(低)3(偏低)6C (低)BB (中)Bb (低)3(偏低)7A(高)CC(低)Aa (高)4(低)49 第1期谭天乐,等:基于粗糙集的故障诊断方法 表1经过约简得到X2正向FDD规则:(A∧AA)∨(B∧BB)∨(B∧Aa)∨(BB∧Aa)→1, (CC∧Bb)∨(B∧CC)∨(B∧Bb)→2,(C∧AA)∨(C∧Bb)∨(C∧BB)∨(BB∧Bb)→3, (A∧Aa)∨(CC∧Aa)∨(C∧CC)∨(C∧Aa)→4.以上规则的前部取反,得到反向FDD规则:与1矛盾:(-A∨-AA)∧(-B∨-BB)∧(-B∨-Aa)∧(-BB∨-Aa);与2矛盾:(-CC∨-Bb)∧(-B∨-CC)∧(-B∨-Bb);与3矛盾:(-C∨-AA)∧(-C∨-Bb)∧(-C∨-BB)∧(-BB∨-Bb);与4矛盾:(-A∨-Aa)∧(-CC∨-Aa)∧(-C∨-CC)∧(-C∨-Aa).以W F、W S2、X2作为条件属性,W S1作为决策属性,构造W S1故障决策表,得到W S1正向FDD规则: (1∧Bb)∨(1∧AA)→A;(1∧Aa)→B;3∨(BB∧Bb)→C;W S1反向FDD规则:与A矛盾:(-1∨-Bb)∧(-1∨-AA);与B矛盾:-1∨-Aa;与C矛盾:-3∨-BB∨-Bb;关于W F、W S2的正向、反向FDD规则可以类似得到.通过调整模型参数模拟故障得到这样一种状态:C∧CC∧Bb∧ 2.首先采用正向规则诊断是否发生故障.发现该状态与以下诊断规则矛盾: X2正向FDD规则:(C∧Bb)→3;(C∧CC)→4;W F正向FDD规则:(C∧CC)→Aa;X2、W F可能发生故障.按照诊断规则改动X2、W F取值,结果仍然与某些正向FDD规则矛盾.用反向FDD规则诊断,该状态满足W S1=C时不会出现的情况:-3∨-BB∨-Bb.因此W S1可能出现故障.将W S1取值由低改为中或者高,由反向FDD规则找不到矛盾,同时也满足所有正向FDD规则.综上所述,该状态下W S1可能失控.6 结 语基于粗糙集的故障诊断方法是一种利用粗糙集理论对知识的获取能力,从形式上模拟人的学习能力和决策行为,对工业过程进行智能故障诊断的技术.该方法不需要先验知识,从一定程度上解决了故障诊断中关于故障知识获取的瓶颈问题.参考文献(References):[1]王彬.熵与信息[M].西安:西北工业大学出版社,1994.W AN G Bin.Entropy and information[M].Xi'an: N or thw est ern Po ly tech nica l Univ er sity Press,1994. [2]CHEN Xiang-hui,Z HU Shan-jun,JI Yin-do ng.En-t ropy based uncer tainty mea sur es fo r classification rules w ith inco nsistency to ler ance[A].IEEE International Conf erence on Systems,Man,and C ybernetics[C].N ashv ille:IEEE,2000,4:2816-2821.[3]张文修,吴伟志,梁吉业,等.粗糙集理论与方法[M].北京:科学出版社,2001.ZHAN G W en-x iu,W U Wei-zhi,LI AN G J i-y e,et al.Rough set theory and method[M].Beijing:Science Press,2001.[4]N I LSSON N J.Art if icial intelligence:A new synthesis[M].Beij ing:M achine Press,1999.[5]SHEN Li-x ia ng,T AY F E H,Q U Liang-sheng,et al.Fa ult diag nosis using ro ug h sets th eo r y[J].Computers in Industry,2000,(43):61-72.[6]SHI W en-ga ng,W ang Ri-xin,Huang Wen-hu.Applica-tio n o f r ough set theo ry to fa ult diag nosis o f check v alv es in recipr ocating pumps[A].Canadian Conf er-ence on Electrical and Computer Engineering[C].To ro nto:CCECC,2001,2:1247-1250.50浙 江 大 学 学 报(工学版) 第37卷 。
基于粗糙集和信息熵的多变量决策树的变压器故障诊断

中 图分 类 号 : P 8 T 1 文 献 标 识 码 : A
M uli ra e De ii n tva i t c so Tr e f r e o Tr n f r e Fa t a s m r o ul
Di g o i Ba e n u h e a d a n ss s d o Ro g S t n Co ndii n to En r py to
性 检 验 和 选择 , 现 多 变量 决 策树 的 建立 。 通过 实例 验 证 多变 量决 策树 诊 断模 型较 之 单 变量 决策 树诊 断模 型减 少 了故 障 实
信 息 的冗 余性 , 断效 率 高 , 果 易 于理 解 。 诊 结
基于模糊集和粗糙集理论的故障诊断方法的研究

(1 - 齐齐哈尔大学计算机系 ,齐齐哈尔 1 10 ;2齐齐哈尔大学计算 中心 ,齐齐哈尔 110 6 0 6 . 6 06)
摘 要: 概括介绍了 模糊集粗糙集的基本理论, 对基于它们的故障诊断方法进行比较, 并提出在故障诊断方法中
一
些可能的研究方向。 词 :故障诊断 ;模糊集 ;模糊推理 粗糙集 :信息熵
22 粗 糙集 _
粗糙集包括上近似集和下近似集 , 如图1 所示。 如果在一个集合 中,对象的所有条件属性都相同,那么这个集合就叫做基集。对象 集中类别y勺 甘下近似集“ 为 P 定义为 : 己 Y)
}
/ ‘ 、
、
基 集
艇类 Biblioteka L 似 集 近近 似 槊
/l
P = :, P Y Y U ,扛 ∈ 且 , j
1 模糊集理论基本概念
16 年,美国学者LAZ dh “n r a oad ot l 5 9 .. e在 If m t nn nr ”上首先提出了模糊集合的概念 ,为了便于理 a o i C o 解, 将基本概念介绍如下 : 11 模糊集合隶属 函数 .
设 域为 , 射 : -[] - 论 称映 ÷ , ÷ o 1
维普资讯
第 2 卷第 1 2 期
20 06年 1 月
齐 齐 哈 尔 大 学 学 报
J u n l f qh r ieri o r a ia v st o Qi Un y
Vo.2N . 1 . o1 2
Jn,0 6 a . 0 2
基于模糊集和粗糙 集理论的故 障诊 断方 法的研 究
了明确Pwa提出的粗糙集理论的基本 内容,这里,首先将粗集理论与基本概念介绍如下 : al k
一种基于粗糙集的决策树构造方法

给定信 息系统 S ( , , 于每个子集 = U A) 对 定义两个子集 【 :
q u, x= yE I y R X=Uf / YAX# YEURI }
知识表达 系统也称 为信息系统。 通常也用 s ( , ) = UA 来代替 s ( , = UA,
。
() 4对于 9中的每一个属性 R, . 计算使用R 进行分类时 的近似 分类 . 精度 , 择近似分类精度 最大 的 所 对应 的R 作为测试属性 , 被 选 设
兄 的不同取值分为 m个不相交 的子集 , 葺 ≤m, , 伸出 m ,号 J , 从( Q ) 个
维普资讯
S IT C F R A I N D V L P E T&E O O Y C - E H I O M TO E E O M N N CNM
文章编号:0 5 6 3 (0 6 1- 16 0 10 — 0 3 2 0 )3 0 3— 3
20 年 06
∑I I
i= l
在各种决 策树 算法中最有影 响的是 Q i ̄ 于 18 u m 96年提出的 以信息 熵 的下降速度为启发信息选取节点 的 I 3 D 算法 “ , ] 但这种算法不是最 优
的, RH n 已经证 明了求解最优决策树是一个 N — a 问题 [。 J .o g . P hr d 2 ]
() 1令决策树 的初始状态 只含有一个树根 ( Q) 中 , , 是全体训 其 练实例 的集合 , 口是条件属性 的集合 ; () 瑚 所有 叶节点 ( , 都有 如下状态 : 2若 Q) 或者第一个 分量 中 的训练实例都属于同一个类 , 或者第二个 ̄-Q为空 , - M 则停止算法 , 结果
属性取 值较 多的属性 不一定最 优 ; 3 非递增学 习算法 ; 3抗噪性 I 是 D 1 D
《2024年基于PCLake模型的乌梁素海水质突变及阈值识别研究》范文
《基于PCLake模型的乌梁素海水质突变及阈值识别研究》篇一一、引言随着工业化进程的推进,水质监测与管理逐渐成为环境保护领域的核心课题。
乌梁素海作为我国内陆重要的湖泊之一,其水质变化直接影响着生态环境的健康。
准确及时地识别水质突变现象和设定合适的阈值对于保障湖泊生态环境和提供有效的治理策略具有极其重要的意义。
本研究以PCLake模型为工具,对乌梁素海水质突变及阈值识别进行了深入研究。
二、PCLake模型简介PCLake模型是一种基于物理过程的湖泊水质模拟模型,它能够模拟湖泊水质的动态变化过程,包括水体中各种化学物质的迁移、转化和归宿等。
该模型具有较高的精度和可靠性,被广泛应用于湖泊水质的研究和预测。
三、乌梁素海水质突变研究1. 数据采集与处理:本研究首先收集了乌梁素海近几年的水质监测数据,包括pH值、溶解氧、总磷等关键指标。
通过对数据的清洗、整理和标准化处理,为后续的突变识别提供了可靠的数据基础。
2. 基于PCLake模型的水质模拟:将处理后的数据输入PCLake模型,模拟乌梁素海水质的动态变化过程。
通过模型的运行,可以获得水体中各种化学物质的浓度变化情况。
3. 突变识别方法:本研究采用基于统计的方法和基于机器学习的方法相结合的方式,对乌梁素海水质进行突变识别。
首先,通过统计方法分析水质指标的时间序列数据,找出可能的突变点;然后,利用机器学习算法对突变点进行验证和分类。
4. 突变结果分析:通过上述方法,我们成功识别出了乌梁素海的水质突变事件。
这些突变事件主要包括由人为因素(如工业排放、农业活动等)引起的水质恶化事件和由自然因素(如气候变化、水体富营养化等)引起的水质波动事件。
四、阈值识别研究1. 阈值设定原则:阈值的设定是水质突变识别的重要环节。
本研究根据乌梁素海的水质特点、生态环境需求和治理目标,设定了合理的阈值。
阈值的设定原则包括科学性、可操作性和动态性,以保证阈值的有效性和适用性。
2. 阈值识别方法:本研究采用基于数据驱动的方法进行阈值识别。
基于粗糙集的属性约简在数据挖掘中的应用研究
计
算
机
科
学
Vo 1 . 4 0 No . 8
Au g .2 0 1 3
Co mp u t e r S c i e n c e
基 于粗 糙 集 的属 性 约简 在 数 据 挖 掘 中的应 用研 究
张颖淳 苏伯 洪 曹 娟
( 重庆 交通 大 学信 息科 学 与工程 学 院 重庆 4 0 0 0 7 4 )
t h e d i s c e r n i b i l i t y ma t r i x wa s u t i l i z e d t o o b t a i n t h e c o r e a t t r i b u t e f i r s t , t h e n a n e w h e u r i s t i c a l g o r i t h m f o r a t t r i b u t e r e d u c — t i o n wa s p r o p o s e d b a s e d o n t h e i mp o r t a n c e r a t i n g s o f t h e a t t r i b u t e . Ou r a l g o r i t h m c a n g i v e p r o p e r c o mb i n a t i o n o f a t t r i -
b u t e s f o r e f f e c t i v e a t t r i b u t e r e d u c t i o n a n d t h e r e f o r e t h e c o mp l e x c o mp u t i n g i s a v o i d e d , wh i c h i s d i f f e r e n t f r o m s o me
过水性湖泊
" " " " " " " " " " " " "
过水性湖泊自净能力的动态变化 !
任瑞丽 " 刘茂松
江苏宿迁 ##$’%% )
! ! !!
" 章杰明 " 张" 明 " 许" 梅
#
$
!
任瑞丽等: 过水性湖泊自净能力的动态变化
6%%;
水体的自净能力与水体中微生物、 藻类和水生高等 %&&% ; 植物等的生物种类及数量关系密切 ( !"##"$, ’(#)"*+",, %&&- ) , 植被及相应动物群落和微生物群 落的完整性及生长状况是湿地自净功能的关键。其 中水生高等植物可促进湖水含氮、 磷物质的沉降以 及抑 制 其 再 悬 浮 和 释 放, 降 低 水 体 氮、 磷的含量 ( ."// 0 123)4$54, 6778 ; 92:2#4) !" #$% , %&&% ; 全为民 等, %&&; ; 童昌华等, %&&; ; <*4## !" #$% , %&&= ) 。湿地 生态系统植被破坏往往导致湿地自净能力的下降。 湿地生态系统的自净能力可通过一些物理、 化 学、 生物指标的变化来描述 ( >*?@2?", !" #$% , %&&% ; !2$A !" #$% , %&&% ; B2A$4##C !" #$% , %&&; ) ; 但变化程 度不仅与湿地生态系统自净能力有关, 入水水质也 影响净化效果 ( 陈桂珠和缪绅裕, 677D ) , 水质较差 时即使是自净能力较弱也可能有较显著的改变。本 文提出应用变异系数来表征系统的自净能力, 并基 于骆马湖若干年来的水质监测资料, 对过水性湖泊 骆马湖的水体自净能力及变化状况进行了研究, 从 而揭示该湿地生态系统健康状况的变化, 并为湿地 生态系统健康状况评价指标的选择提供参考。 !" 研究地区与研究方法 !# $" 研究地概况 骆马湖位于江苏省北部的黄淮平原 ( ;-E&&F— ;-E6-FG, 668E&-F—668E68FH ) , 海拔 %% +, 面积 %D&
基于MATLAB实现模糊综合指数法在水质评价中的应用研究
水质评价是环境质量评价的主要内容之一,准确的水质 评价是水资源开发利用和治理的科学依据。水污染程度和水 质分级都是模糊概念,需要以定量的方式直观地表征原水水 质总体状况。模糊综合指数评价是指对多种模糊因素所影响 的事物或现象进行总的评价,是一种定量研究多种属性事物 的工具。本文通过模糊综合指数法对某城市河道水质进行综 合评价, 确定水质类别和主要污染物,为有关部门在管理和治 理上做出决策提供科学依据。
表 1 水质标准(GB3838- 2002)
单位:mg/ L
水质标准
溶解氧≥ 化学需氧量(COD)≤ 生化需氧量(BOD5)≤
氨氮(NH3- N)≤ 总磷(以 P 计)≤ 总氮(以 N 计)≤
Ⅰ类 7.5 15 3 0.2 0.01 0.2
水质类别
Ⅱ类
Ⅲ类
6
5
15
20
3
4
0.5
1.0
0.025
0.05
3 某城市河道水质评价
取某年某城市河道原水抽样调查具有代表性的某三次的 水质数据(见表 2)。
表 2 某城市河道原水某三次的水质数据 单位:mg/ L
样本序号 溶解氧
COD
样本 1
1.3
41.1
样本 2
1.4
40.2
样本 3
1.5
41.3
BOD5 21.8 17.1 10.5
氨氮 8.1 8.4 5.8
FCI1=5.0800 水质为Ⅴ级。同理算得 FCI2=4.9950 水质 为Ⅴ级;FCI3=4.9700 水质为Ⅴ级。
从表 3 中,找出各样本权重系数中的最大值,即是水污染 最主要因素。从表 3 可看出,造成某城市河道污染的主要污染 物是总磷、总氨、氨氮。