大数据结构实验-互联网域名查询实验报告材料
数据结构实验报告八-快速排序

实验8 快速排序1.需求分析(1)输入的形式和输入值的范围:第一行是一个整数n,代表任务的件数。
接下来一行,有n个正整数,代表每件任务所用的时间。
中间用空格或者回车隔开。
不对非法输入做处理,及假设用户输入都是合法的。
(2)输出的形式:输出有n行,每行一个正整数,从第一行到最后一行依次代表着操作系统要处理的任务所用的时间。
按此顺序进行,则使得所有任务等待时间最小。
(3)程序所能达到的功能:在操作系统中,当有n 件任务同时来临时,每件任务需要用时ni,输出所有任务等待的时间和最小的任务处理顺序。
(4)测试数据:输入请输入任务个数:9请输入任务用时:5 3 4 2 6 1 5 7 3输出任务执行的顺序:1 2 3 3 4 5 5 6 72.概要设计(1)抽象数据类型的定义:为实现上述程序的功能,应以整数存储用户的第一个输入。
并将随后输入的一组数据储存在整数数组中。
(2)算法的基本思想:如果将任务按完成时间从小到大排序,则在完成前一项任务时后面任务等待的时间总和最小,即得到最小的任务处理顺序。
采取对输入的任务时间进行快速排序的方法可以在相对较小的时间复杂度下得到从小到大的顺序序列。
3.详细设计(1)实现概要设计中定义的所有数据类型:第一次输入的正整数要求大于零,为了能够存储,采用int型定义变量。
接下来输入的一组整数,数据范围大于零,为了排序需要,采用线性结构存储,即int类型的数组。
(2)实现程序的具体步骤:一.程序主要采取快速排序的方法处理无序数列:1.在序列中根据随机数确定轴值,根据轴值将序列划分为比轴值小和比轴值大的两个子序列。
2.对每个子序列采取从左右两边向中间搜索的方式,不断将值与轴值比较,如果左边的值大于轴值而右边的小于轴值则将二者交换,直到左右交叉。
3.分别对处理完毕的两个子序列递归地采取1,2步的操作,直到子序列中只有一个元素。
二.程序各模块的伪代码:1、主函数int main(){int n;cout<<"请输入任务个数:";cin>>n;int a[n];cout<<"请输入任务用时:";for(int i=0;i<n;i++) cin>>a[i];qsort(a,0,n-1); //调用“快排函数”cout<<"任务执行的顺序:";for(int i=0;i<n;i++) cout<<a[i]<<" "; //输出排序结果}2、快速排序算法:void qsort(int a[],int i,int j){if(j<=i)return; //只有一个元素int pivotindex=findpivot(a,i,j); //调用“轴值寻找函数”确定轴值swap(a,pivotindex,j); //调用“交换函数”将轴值置末int k=partition(a,i-1,j,a[j]); //调用“分割函数”根据轴值分割序列swap(a,k,j);qsort(a,i,k-1); //递归调用,实现子序列的调序qsort(a,k+1,j);}3、轴值寻找算法://为了保证轴值的“随机性”,采用时间初始化种子。
icmp协议分组结构实验报告

icmp协议分组结构实验报告icmp协议是互联网协议族中的一员,它是Internet控制消息协议(Internet Control Message Protocol)的缩写。
icmp协议为IP协议提供了差错检测和报告的功能,它的主要作用就是在IP网络间中传递“控制信息”。
那么icmp协议的分组结构是怎样的呢?下面我们一起来探索一下。
icmp协议的分组结构可以分为以下几个部分:1.ICMP报文类型(Type)和代码(Code):ICMP报文类型表示此类报文的作用,而代码定义这个报文类型下具体的操作和错误信息。
2.校验和(Checksum):icmp协议使用校验和来检测报文传输过程中的错误。
3.其他数据字段:icmp协议还会在报文中加入其他的数据信息,如时间戳、TTL等等。
下面我们来分别看一下这几个部分。
1.ICMP报文类型(Type)和代码(Code)ICMP协议中一共有13种类型和29种代码。
其中,13种类型可以分为两大类:一类是差错报告(Error-report-message),用于报告网络运行过程中的错误;另一类是询问报文(Query-message),用于查询网络状态。
差错报告中最常见的包括:Type0:Echo Reply(回显应答报文)Type3:Destination Unreachable(目的地不可达报文)Type4:Source Quench(源端抑制报文)询问报文中常用的有:Type8:Echo Request(回显请求报文)Type11:Time Exceeded for a Datagram(数据包过期报文)2.校验和(Checksum)ICMP协议中的校验和用于检测数据包传输过程中的错误。
在发送端,ICMP会计算出报文中的所有数据的总和,并将结果存储在报文的校验和字段中。
在接收端,同样会对报文中的所有数据进行计算,并与发送端所计算的校验和进行比较,如果校验和相同,则说明数据传输过程中没有出现错误,否则就会报告错误信息。
数据库管理系统实验报告doc

数据库管理系统实验报告篇一:数据库_图书馆管理系统实验报告数据库课程设计报告专业:计算机科学与技术班级: 03 组长:张云60 组员:王冉28指导教师:袁道华成绩:XX年12月16日一、课程设计概述1. 课程设计背景课程需要开发一个图书管理系统,要求在读者登记处可以将读者的信息添加,信息系统中保存,当读者信息发生变化,对计算机内容进行修改,当读者办理退卡手续要删除此读者信息,图书管理负责图书和出版社的管理,读书借还处进行借书管理,还书管理,库存查询,图书排行榜,生成超期未还书的读者,进行通知.给不同用户设置不同权限,供用户访问数据库。
2. 编写目的熟练掌握mysql中的创建数据库、创建表、显示、查询、select语句、视图、存储过程、创建检索、对表的添加、删除、修改和用户权限的设置等基本运用,并通过编写这个图书管理系统来实际演练。
3. 软件定义Mysql是目前最流行的开源的中小型关系数据管理系统,目前被广泛的应用于internet上得中小型网站中,它由mysql AB公司开发、发布并支持。
本实验用的是mysql 5.1版本4. 开发环境本实验用的是mysql 5.1版本,windowsXX二、需求分析1. 问题的提出1:怎么通过mysql和信息之间的关系来创建图书管理系统的数据库及表? 2:怎样来实现对插入读者信息并保存、修改及删除? 3:怎么来实现对图书的管理?4:怎样实现对借书后在读书借还处添加读者借书信息和还书后删除读者借还处中的借书信息且更新图书管理处的图书数量?5:怎么实现对超期读者进行罚款操作和生成这些读者的名单,以方便通知? 6:怎样实现图书的借书排行榜和查看库存书量?7:怎么样来根据不同用户对数据库的等级的不同来设置这些用户的权限?2. 需要完成的功能及各部分功能概述1:读者登记建卡处的功能是对读者基本信息进行登记,读者信息发生变化对读者基本信息进行修改,读者要求退还借书卡时对读者信息进行删除等操作。
数据库应用实验报告创建数据库和表以及表操作
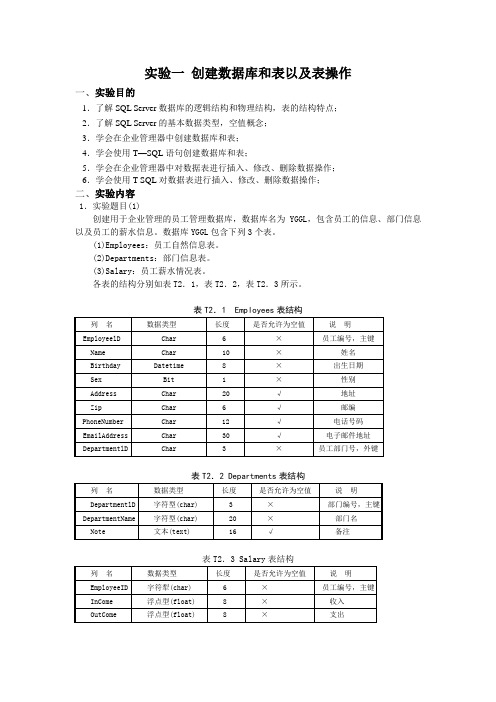
实验一创建数据库和表以及表操作一、实验目的1.了解SQL Server数据库的逻辑结构和物理结构,表的结构特点;2.了解SQL Server的基本数据类型,空值概念;3.学会在企业管理器中创建数据库和表;4.学会使用T—SQL语句创建数据库和表;5.学会在企业管理器中对数据表进行插入、修改、删除数据操作;6.学会使用T-SQL对数据表进行插入、修改、删除数据操作;二、实验内容1.实验题目(1)创建用于企业管理的员工管理数据库,数据库名为YGGL,包含员工的信息、部门信息以及员工的薪水信息。
数据库YGGL包含下列3个表。
(1)Employees:员工自然信息表。
(2)Departments:部门信息表。
(3)Salary:员工薪水情况表。
各表的结构分别如表T2.1,表T2.2,表T2.3所示。
表T2.1 Employees表结构表T2.2 Departments表结构实验步骤1.在企业管理器中创建数据库YGGL要求:数据库YGGL初始大小为10MB,最大大小为50MB,数据库自动增长,增长方式是按5%比例增长;日志文件初始为2MB,最大可增长到5MB(默认为不限制),按1MB增长(默认是按5%比例增长)。
数据库的逻辑文件名和物理文件名均采用默认值,分别为 YGGL_data 和e:\sql\data\MSSQL\Data\YGGL.mdf,其中e:\sql\data\MSSQL为SQL Server 的系统安装目录;事务日志的逻辑文件名和物理文件名也均采用默认值分别为YGGL—LOG 和 e:\sql\data\MSSQL\Data\YGGL_Log.1df。
以系统管理员Administrator是被授权使用CREATE DATABASE语句的用户登录SQL Server服务器,启动企业管理器一>在服务器上单击鼠标右键一>新建数据库一>输入数据库名“YGGL”一>选择“数据文件”选项卡一>设置增长方式和增长比例一>选择“事务口志”选项卡一设置增长方式和增长比例。
物联网大实验报告(3篇)

第1篇一、实验背景随着信息技术的飞速发展,物联网技术逐渐成为我国新一代信息技术的重要组成部分。
物联网(Internet of Things,简称IoT)是指通过信息传感设备,将各种物品连接到网络上进行信息交换和通信,以实现智能化识别、定位、追踪、监控和管理的一种网络技术。
本实验旨在让学生深入了解物联网的基本原理、关键技术及其实际应用,培养学生的实践能力和创新意识。
二、实验目的1. 理解物联网的基本概念、发展历程和未来趋势;2. 掌握物联网关键技术,如传感器技术、通信技术、数据处理技术等;3. 熟悉物联网系统开发流程,包括需求分析、系统设计、实现和测试;4. 培养学生的实践能力和创新意识,提高学生的综合素质。
三、实验内容1. 物联网感知层实验:通过搭建一个简单的传感器网络,实现温度、湿度等环境参数的采集和传输。
(1)实验原理:利用DS18B20数字温度传感器采集环境温度,通过单总线通信协议将数据传输到单片机,单片机再将数据发送到上位机。
(2)实验步骤:1)搭建传感器网络,包括DS18B20传感器、单总线通信模块、单片机等;2)编写单片机程序,实现传感器数据采集和通信;3)使用上位机软件(如LabVIEW)接收传感器数据,并实时显示。
2. 物联网网络层实验:利用ZigBee无线通信技术实现节点间的数据传输。
(1)实验原理:ZigBee是一种低功耗、低成本、低速率的无线通信技术,适用于短距离、低速率的数据传输。
(2)实验步骤:1)搭建ZigBee网络,包括协调器、路由器和终端节点;2)编写节点程序,实现数据采集、传输和接收;3)测试网络性能,如传输速率、通信距离等。
3. 物联网应用层实验:开发一个基于物联网的智能家居控制系统。
(1)实验原理:利用物联网技术实现家居设备的远程控制、实时监测等功能。
(2)实验步骤:1)选择智能家居设备,如智能灯泡、智能插座等;2)搭建智能家居控制系统,包括控制器、传感器、执行器等;3)编写控制器程序,实现家居设备的远程控制、实时监测等功能;4)测试系统性能,如设备响应速度、数据准确性等。
数据结构(C语言版)实验报告 (内部排序算法比较)

《数据结构与算法》实验报告一、需求分析问题描述:在教科书中,各种内部排序算法的时间复杂度分析结果只给出了算法执行时间的阶,或大概执行时间。
试通过随机数据比较各算法的关键字比较次数和关键字移动次数,以取得直观感受。
基本要求:(l)对以下6种常用的内部排序算法进行比较:起泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、堆排序。
(2)待排序表的表长不小于100000;其中的数据要用伪随机数程序产生;至少要用5组不同的输入数据作比较;比较的指标为有关键字参加的比较次数和关键字的移动次数(关键字交换计为3次移动)。
(3)最后要对结果作简单分析,包括对各组数据得出结果波动大小的解释。
数据测试:二.概要设计1.程序所需的抽象数据类型的定义:typedef int BOOL; //说明BOOL是int的别名typedef struct StudentData { int num; //存放关键字}Data; typedef struct LinkList { int Length; //数组长度Data Record[MAXSIZE]; //用数组存放所有的随机数} LinkList int RandArray[MAXSIZE]; //定义长度为MAXSIZE的随机数组void RandomNum() //随机生成函数void InitLinkList(LinkList* L) //初始化链表BOOL LT(int i, int j,int* CmpNum) //比较i和j 的大小void Display(LinkList* L) //显示输出函数void ShellSort(LinkList* L, int dlta[], int t,int* CmpNum, int* ChgNum) //希尔排序void QuickSort (LinkList* L, int* CmpNum, int* ChgNum) //快速排序void HeapSort (LinkList* L, int* CmpNum, int* ChgNum) //堆排序void BubbleSort(LinkList* L, int* CmpNum, int* ChgNum) //冒泡排序void SelSort(LinkList* L, int* CmpNum, int* ChgNum) //选择排序void Compare(LinkList* L,int* CmpNum, int* ChgNum) //比较所有排序2 .各程序模块之间的层次(调用)关系:二、详细设计typedef int BOOL; //定义标识符关键字BOOL别名为int typedef struct StudentData //记录数据类型{int num; //定义关键字类型}Data; //排序的记录数据类型定义typedef struct LinkList //记录线性表{int Length; //定义表长Data Record[MAXSIZE]; //表长记录最大值}LinkList; //排序的记录线性表类型定义int RandArray[MAXSIZE]; //定义随机数组类型及最大值/******************随机生成函数********************/void RandomNum(){int i; srand((int)time(NULL)); //用伪随机数程序产生伪随机数for(i=0; i小于MAXSIZE; i++) RandArray[i]<=(int)rand(); 返回;}/*****************初始化链表**********************/void InitLinkList(LinkList* L) //初始化链表{int i;memset(L,0,sizeof(LinkList));RandomNum();for(i=0; i小于<MAXSIZE; i++)L->Record[i].num<=RandArray[i]; L->Length<=i;}BOOL LT(int i, int j,int* CmpNum){(*CmpNum)++; 若i<j) 则返回TRUE; 否则返回FALSE;}void Display(LinkList* L){FILE* f; //定义一个文件指针f int i;若打开文件的指令不为空则//通过文件指针f打开文件为条件判断{ //是否应该打开文件输出“can't open file”;exit(0); }for (i=0; i小于L->Length; i++)fprintf(f,"%d\n",L->Record[i].num);通过文件指针f关闭文件;三、调试分析1.调试过程中遇到的问题及经验体会:在本次程序的编写和调试过程中,我曾多次修改代码,并根据调试显示的界面一次次调整代码。
大二材料力学实验报告答案,大二材料力学实验报告答案和数据
大二材料力学实验报告答案,大二材料力学实验报告答案和数据大二材料力学实验报告答案,大二材料力学实验报告答案和数据1实验原理:材料的力学性质是衡量材料性能的重要指标,材料力学实验是通过对材料的受力反应、形变及破坏等进行测试,以获得材料的各项力学性能参数。
本次材料力学实验主要涉及杆件弯曲和杆件拉伸两个方面,包括杆件的应力、应变、杨氏模量、屈服强度、断裂强度等指标的测量和计算。
实验仪器与材料:1.微机控制电子材料实验机(电液伺服型)2.应变片3.夹具4.长度计等实验过程:1.杆件弯曲实验(1)测量杆件初始长度L0(2)在微机控制下,向杆件中心施加弯曲力,同时记录在悬挂点上观测到的弯曲挠度δ(3)杆件应力计算,根据应变片测得的应变ε和杆件截面形状和尺寸计算得出杆件所受应力σ(4)杆件截面形变计算,根据杆件的截面形变计算出它所受到的剪切力(5)杆件杨氏模量计算,根据应力-应变的线性关系,可以求得杆件的杨氏模数E2.杆件拉伸实验(1)测量杆件初始长度L0(2)夹紧杆件两端的夹具,向杆件下端施加垂直拉力,并在微机控制下,使拉伸速率恒定(3)杆件的应变计算,根据应变片测量到的杆件应变,以及杆件的初始长度和截面形状和尺寸计算杆件所受应力σ(4)杆件的屈服强度试验,记录实验过程中,杆件所受力的变化趋势,在杆件承受正常应力下,杆件开始产生塑性变形的应力值被称为其屈服强度(5)杆件的断裂试验,记录实验过程中,杆件承载的极限力以及断裂后的形态,求得其断裂强度实验结果:1.杆件弯曲实验:得到杆件的.应力、应变、杨氏模量等参数数据,并通过图表反映2.杆件拉伸实验:得到杆件的应力、应变、屈服强度、断裂强度等参数数据,并通过图表反映实验分析:根据实验结果可以得出,杆件在弯曲和拉伸的过程中,其受力反应、形变和破坏等产生了相应记录,并通过计算得到了杆件的各项力学性能参数。
通过对杆件行驶弯曲实验,可以计算出杆件的杨氏模量,通过对杆件进行拉伸实验,可以计算出杆件的屈服强度和断裂强度等参数,这些参数对于材料选用、工程设计等具有重要的参考意义。
分布式实验报告
分布式实验报告在当今数字化和信息化的时代,分布式系统的应用越来越广泛,其在处理大规模数据、提供高可用性服务等方面发挥着重要作用。
本次分布式实验旨在深入研究分布式系统的工作原理、性能特点以及面临的挑战,并通过实际操作和测试来验证相关理论和技术。
一、实验背景随着互联网的快速发展,用户数量和数据量呈爆炸式增长,传统的集中式系统在处理能力、可扩展性和可靠性等方面逐渐难以满足需求。
分布式系统通过将任务分布在多个节点上协同工作,能够有效地解决这些问题。
然而,分布式系统也带来了一系列新的技术挑战,如数据一致性、网络延迟、节点故障等。
二、实验目的本次实验的主要目的包括:1、深入理解分布式系统的架构和工作原理。
2、掌握分布式系统中的数据分布、副本管理和一致性算法。
3、评估分布式系统在不同负载情况下的性能表现。
4、分析分布式系统在面对节点故障时的容错能力和恢复机制。
三、实验环境为了进行本次实验,我们搭建了一个由多台服务器组成的分布式集群环境。
具体配置如下:服务器数量:5 台操作系统:CentOS 7CPU:Intel Xeon E5-2620 v4 @ 210GHz内存:32GB存储:1TB SATA 硬盘网络:千兆以太网在每台服务器上,我们安装了所需的软件和依赖,包括分布式系统框架(如 Hadoop、Zookeeper 等)、数据库(如 MySQL)、监控工具(如 Nagios)等。
四、实验内容1、数据分布策略实验我们首先研究了不同的数据分布策略,如哈希分布、范围分布和随机分布。
通过在分布式系统中插入和查询大量数据,比较了不同策略下的数据均衡性、查询效率和数据迁移成本。
实验结果表明,哈希分布在数据均衡性方面表现较好,但在处理范围查询时效率较低;范围分布适用于范围查询,但容易导致数据倾斜;随机分布的性能较为不稳定。
2、副本管理实验接着,我们对副本管理进行了实验。
设置了不同的副本数量(如 1 个副本、2 个副本和 3 个副本),并模拟了节点故障的情况,观察系统在数据可用性和恢复时间方面的表现。
数据库实验报告
数据库实验报告《数据库系统概论》实验指导书2012-8-30⽬录实验⼀数据库服务器的连接及数据库的建⽴ (1)实验⼆简单SQL查询及数据库多表查询 (12)实验三视图、索引、存储过程和触发器的使⽤ .. 22实验四 E-R模型与关系模型的转换 (30)实验五维护数据的完整性(选做)错误!未定义书签。
实验六事务管理(课后选做)错误!未定义书签。
实验七数据库的备份与恢复(课后选做)错误!未定义书签。
实验⼀数据库服务器的连接及数据库的建⽴⼀、实验⽬的:了解连接数据库服务器的⾝份验证模式,熟悉样例数据库。
掌握DBMS中利⽤界⾯进⾏建库建表操作。
⼆、实验准备:数据模型由三个要素组成:数据结构、数据操作和完整性约束。
1、数据结构数据结构⽤于描述系统的静态特性,是所研究的对象类型的集合。
数据模型按其数据结构分为层次模型、⽹状模型和关系模型。
2、数据操作数据操作⽤于描述系统的动态特性,是指对数据库中各种对象的实例允许执⾏的操作的集合,包括操作及有关的操作集合。
3、数据的约束条件数据的约束条件是⼀组完整性规则的集合。
完整性规则是给定的数据及其联系所具有的制约和存储规则,⽤以限定符合数据库状态以及状态的变化,以保证数据的正确、有效和相容。
数据库系统的三级模式结构数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三级组成。
1、外模式。
外模式也称⼦模式或⽤户模式,它是数据库⽤户(包括应⽤程序员和最终⽤户)看见和使⽤的局部数据的逻辑结构和特征的描述,是数据库⽤户的数据视图,是与某⼀应⽤有关的数据的逻辑表⽰。
⼀个数据库可以有多个外模式。
2、模式。
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有⽤户的公⽤数据视图。
⼀个数据库只有⼀个模式。
3、内模式。
内模式也称存储模式,它是数据物理和存储结构的描述,是数据在数据库内部的表⽰⽅式。
⼀个数据库只有⼀个内模式。
DBMS的功能1、数据定义数据定义包括定义构成数据库结构的外模式、模式和内模式,定义各个外模式与模式之间的映射,定义模式与内模式之间的映射,定义有关的约束条件(例如,为保证数据库中数据具有正确语义⽽定义的完整性规则,为保证数据库安全⽽定义的⽤户⼝令和存取权限等)。
数据库原理实验报告
计算机与信息学院数据库原理实验报告专业:计算机科学与技术班级:2012级本科班学号:07173姓名:指导教师:2014年06月18 日实验项目列表计算机与信息学院实验报告纸实验一数据库创建与管理一、实验目的与要求1、熟练掌握SSMS中界面方式创建和管理数据库。
2、熟练掌握SSMS查询编辑器T-SQL语句创建和管理数据库。
3、熟练掌握备份和还原数据库。
二、实验内容1、界面方式创建和管理数据库(1)创建数据库(2)修改数据库(3)删除数据库2、利用企业管理器备份和还原数据库(1)备份数据库(2)还原数据库3、T-SQL语句方式创建和管理数据库(1)创建SPJ数据库:在SSMS中“新建查询”,输入以下语句并运行CREATE DATABASE SPJON(NAME=’SPJ_Data’,FELENAME='C:\Program Files\Microsoft SQL Server\MSSQL\data\SPJ_Data.MDF' ,SIZE = 3,MAXSIZE = 10,FILEGROWTH = 10%)LOG ON(NAME = 'SPJ_Log', FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL\data\SPJ_Log.LDF' ,SIZE = 1,FILEGROWTH = 10%)(2)修改SPJ数据库:在查询分析器中输入以下语句并运行ALTER DATABASE SPJMODIFY FILE(NAME='SPJ_Data',SIZE=4,ALTER DATABASE SPJADD FILE(NAME='SPJ_Data_2', FILENAME='C:\Program Files\Microsoft SQL Server\MSSQL\Data\SPJ_Date_2.ndf',SIZE=1,MAXSIZE=10,FILEGROWTH=10%)(3)删除SPJ数据库:DROP DATABASE SPJ4、界面方式创建数据库XSBOOK,写出操作过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
标准 文案 实 验 报 告
实验课程:数 据 结 构 实验项目:实验三互联网域名查询 专 业:计算机科学与技术 班 级: 姓 名: 学 号: 指导教师: 标准
文案 目 录 一、问题定义及需求分析 (1)问题描述 (2)实验任务 (3)需求分析
二、概要设计: (1)抽象数据类型定义 (2)主程序流程 (3) 模块关系
三、详细设计 (1)数据类型及存储结构 (2)模块设计
四、调试分析 (1)调试分析 (2)算法时空分析 (3)经验体会
五、使用说明 (1)程序使用说明 六、测试结果 (1)运行测试结果截图 七、附录 (1)源代码 标准
文案 一、问题定义及需求分析 (1)实验目的 互联网域名查询 互联网域名系统是一个典型的树形层次结构。从根节点往下的第一层是顶层域,如cn、com等,最底层(第四层)是叶子结点,如www等。因此,域名搜索可以看成是树的遍历问题。 (2)实验任务 设计搜索互联网域名的程序。 (3)需求分析: 1)采用树的孩子兄弟链表等存储结构。 2)创建树形结构。 3)通过深度优先遍历搜索。 4)通过层次优先遍历搜索。
二、概要设计: 采用孩子兄弟链表存储结构完成二叉树的创建; 主程序流程: 创建根节点 域名输入 域名拆分 根据孩子兄弟链表表示的树进行插入 调用层次优先遍历 输出遍历结果 调用深度优先遍历 输出遍历结果 结束程序 模块关系: 输入域名
创建孩子兄弟树 层次优先遍历输出结果 深度优先遍历输出结果 结束 三、详细设计 孩子兄弟链表结构: typedef struct CSNode{ ElemType data[10]; struct CSNode *firstchild, *nextsibling; }*CSTree; 标准 文案 模块一深度优先遍历 算法如下 void DFS(CSNode *root) { if (!root) return;//递归结束条件 printf("%s\n", root->data); DFS(root->firstchild);//递归遍历孩子节点 DFS(root->nextsibling);//递归遍历兄弟节点 } 模块二层次优先遍历 算法如下 void BFS(CSNode *root) { printf("层次优先搜索遍历结果为:\n"); Queue que; que.Clear(); que.push(root);//根节点入队列 while (!que.empty()) {//队列不空的时候执行循环 CSNode *xx = que.front(); //取队首元素 que.pop();//出队列 printf("%s\n", xx->data); if (xx->nextsibling) {//出队节点的孩子节点若不空则入队列 que.push(xx->nextsibling); } if (xx->firstchild) {//同样若孩子节点不空则入队列 que.push(xx->firstchild); } } }
四、调试分析 问题解决: 在编写层次优先遍历算法的时候遍历结果总是不正确,原因是取完队首元素后没有将出队列,经过改正,在取队首元素后加上出队列函数将队首元素出队;这样便解决了问题; 时空分析:经过孩子兄弟链表表示的树创建后便得到一棵二叉树;对于两个遍历函数,深度优先遍历是递归算法,在时间上,递归算法效率较低,尤其是运算次数较大的时候;层次优先遍历函数借助到队列,所以在存占用上较多;而深度优先遍历算法的空间占用上更优于层次优先遍历; 经验体会: 孩子兄弟链表表示的树与二叉树可以相互转化;它的深度优先遍历递归算法虽较为简单但相比非递归算法而言效率不高。
五、使用说明 第一步:输入域名 第二步:完成创建 标准 文案 第三步:输出层次优先遍历结果 第四步:输出深度有限遍历结果
六、测试截屏
七、附录 #include #include #include #define ElemType char #define QueueSize 50 #define push Push #define empty Empty #define pop Pop #define front Front typedef struct CSNode{ ElemType data[10]; struct CSNode *firstchild, *nextsibling; }*CSTree;//节点结构
void InitTree(CSNode *A) { //构造一个空树 A = (CSTree)malloc(sizeof(CSNode)); 标准 文案 A->firstchild = A->nextsibling = NULL; } int Search_(CSNode *X, char *a) { //查找待插入的节点在树中是否存在 CSNode *B; B = X;//B指向根节点 while (B->data) { if (strcmp(B->data, a) == 0) { X = B; //若存在相等的则返回1 return 1; } else { B = B->nextsibling; //否则B指向它的兄弟节点 } } return 0; }
void hanshu1(CSNode *A, ElemType *s) {//将节点插入到树中 CSNode *B, *X; char *str; int i; X = A; //X指向根节点 B = (CSTree)malloc(sizeof(CSNode)); B->firstchild = B->nextsibling = NULL; char ZhongZhuan[15]; //中转数组
for (; s != '\0';) { //zhongzhuan接受s中xxx.部分或取完翻转zhongzhuan str = strchr(s, '.');//返回字符串s中第一次出现点的位置 if (str) { i = str - s; ZhongZhuan[i + 1] = '\0'; for (; i >= 0; i--, s++) { ZhongZhuan[i] = s[0];//将拆分后的节点传入中转数组中 } } 标准 文案 else {//字符串中不含点符号 _strrev(s); i = strlen(s); ZhongZhuan[i + 1] = '\0'; for (; i >= 0; i--) { ZhongZhuan[i] = s[i];//将字符串存入中转数组里 } s = '\0'; }
if (Search_(X, ZhongZhuan)) {//若要插入的字符串已存在该层面上 X = X->firstchild;//x指向孩子节点 continue; } if (X->data[0] == '0') { strcpy(X->data, ZhongZhuan);//将中转数组的信息复制给待插入节点 B = (CSTree)malloc(sizeof(CSNode)); B->firstchild = B->nextsibling = NULL; } else { if (X->firstchild) { strcpy(B->data, ZhongZhuan); X->nextsibling = B;//将B作为X的兄弟节点 B = (CSTree)malloc(sizeof(CSNode)); B->firstchild = B->nextsibling = NULL; X = X->nextsibling; //x指向它的兄弟节点 } else { strcpy(B->data, ZhongZhuan); X->firstchild = B; B = (CSTree)malloc(sizeof(CSNode)); B->firstchild = B->nextsibling = NULL; X = X->firstchild; } } } } 标准 文案 struct Queue { int Top, Tail; CSNode *a[1000]; void Clear(); void Push(CSNode *e); void Pop(); CSNode *Front(); bool Empty(); };//队列封装为结构体
void Queue::Clear() { Top = Tail = 0; return; }//清空队列
void Queue::Push(CSNode *e) { a[Tail++] = e; return; }//入队列
void Queue::Pop() { Top++; return; }//出队列
CSNode *Queue::Front() { return a[Top]; }//取队首元素
bool Queue::Empty() { return Top == Tail; }//判空
void BFS(CSNode *root) { printf("层次优先搜索遍历结果为:\n"); Queue que; que.Clear(); que.push(root);//根节点入队列 while (!que.empty()) {//队列不空的时候执行循环 CSNode *xx = que.front(); //取队首元素 que.pop();//出队列 printf("%s\n", xx->data); if (xx->nextsibling) {//出队节点的孩子节点若不空则入队列 que.push(xx->nextsibling);