关联规则分析及应用ppt课件
合集下载
关联规则 PPT

2. 2 挖掘过程
第一阶段 找出所有频繁项集 (Large Itemsets) 第二阶段 由频繁项集产生强关联规则(Association Rules )
3. 1 相关算法
Apriori算法 基于划分的算法 FP-Grow算法
3.2 Apriori算法
思想:
首先,找出频繁1-项集,以L1表示.L1用来寻找L2,即频繁2-项集 的集合.L2用来寻找L3,以此类推,直至没有新的频繁k-项 集被发现.每个Lk都要求对数据库作一次完全扫描.
2.1 基本概念
交易数据库(D) 交易/事务 (T)
T I
交易标识符(TID) 项集(I)
I {i1,i2,..i.m},
规则 i1 i2
支持度support: D中包含i1和 i2 的事务数与总的事务数的比值
s(A B)|{ | TD| |AD| |B|T}||
可信度 confidence: D中同时包含i1和i2的事务数与包含i1的事务数的比值
2.1 基本概念
阈值 最小支持度 – 表示规则中的所有项在事务中出现的频度 最小可信度 - 表示规则中左边的项(集)的出现暗示着右
边的项(集)出现的频度
项集 – 任意项的集合 k-项集 – 包含k个项的项集 频繁 (或大)项集 – 满足最小支持度的项集 强规则:那些满足最小支持度和最小可信度的规则.
Apriori算法
候选项集生成的示例 L3={ abc, abd, acd, ace, bcd } 自连接: L3*L3 由abc 和abd 连接得到abcd 由acd 和ace 连接得到acde 剪枝: 因为ade 不在L3中acde 被剪除
Apriori算法
挑战: 多次扫描事务数据库 巨大数量的候选项集 繁重的计算候选项集的支持度工作 改进 Apriori: 大体的思路 减少事务数据库的扫描次数 缩减候选项集的数量 使候选项集的支持度计算更加方便
关联规则及相关算法讲解幻灯片

关联规则及相关算法
1
主要内容
?关联规则概述 ?Apriori 算法 ?CARMA 算法 ?序列模式
2
关联规则概述
?数据关联是数据库中存在的一类重要的可被发现的 知识。若两个或多个变量的取值之间存在某种规律 性,就称为 关联。
?关联规则挖掘的一个典型例子是购物篮分析。
?啤酒与尿布的故事
3
啤酒与尿布的故事
?1. 算法组成 ?2. 算法中的符号定义 ?3. 算法的基本过程
?㈡ 实例说明 ?
?4. 用一个简单的例子说明算法原理。
?㈢ CARMA 算法描述 ?
?5. 用自然语言描述算法的实现过程。
27
已有的一些关联规则挖掘算法在运行之前要 求用户输入最小置信度和最小支持度。而对用户 来讲,确定合适的最小置信度和最小支持度比较 困难,需要运行算法多次判断最小置信度和最小 支持度是否过高或过低。
? 在这些原始交易数据的基础上,沃尔玛利用数据 挖掘方法对这些数据进行分析和挖掘。
5
啤酒与尿布的故事
? 一个意外的发现是:跟尿布一起购买最多的商品 竟是啤酒!
? 经过大量实际调查和分析,揭示了一个隐藏在“ 尿布与啤酒”背后的美国人的一种行为模式:
?在美国,一些年轻的父亲下班后经常要到超市去买婴 儿尿布,而他们中有30%~40%的人同时也为自己买 一些啤酒。产生这一现象的原因是:美国的太太们常 叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买 尿布后又随手带回了他们喜欢的啤酒。
在Clementine 中应用Apriori 算法
?应用Apriori 节点来对某超市的客户采购数据集进 行购物篮分析。该数据集包含有 21个属性(这些 属性包括: COD、pasta 、milk 、water 、 biscuits 、coffee 、brioches 、yoghurt 、frozen vegetables 、tunny 、beer 、tomato 、souce 、 coke 、rice 、juices 、crackers 、oil 、frozen fish 、ice cream 、mozzarella 、tinned meat 。 其中“COD”是记录编号,其它 20个属性代表 20 种商品),共 46243个记录。每个属性代表某种 商品,其取值为“ 0”或者“1”,“0”表示没有购 买该商品,“ 1”表示购买了该商品。
1
主要内容
?关联规则概述 ?Apriori 算法 ?CARMA 算法 ?序列模式
2
关联规则概述
?数据关联是数据库中存在的一类重要的可被发现的 知识。若两个或多个变量的取值之间存在某种规律 性,就称为 关联。
?关联规则挖掘的一个典型例子是购物篮分析。
?啤酒与尿布的故事
3
啤酒与尿布的故事
?1. 算法组成 ?2. 算法中的符号定义 ?3. 算法的基本过程
?㈡ 实例说明 ?
?4. 用一个简单的例子说明算法原理。
?㈢ CARMA 算法描述 ?
?5. 用自然语言描述算法的实现过程。
27
已有的一些关联规则挖掘算法在运行之前要 求用户输入最小置信度和最小支持度。而对用户 来讲,确定合适的最小置信度和最小支持度比较 困难,需要运行算法多次判断最小置信度和最小 支持度是否过高或过低。
? 在这些原始交易数据的基础上,沃尔玛利用数据 挖掘方法对这些数据进行分析和挖掘。
5
啤酒与尿布的故事
? 一个意外的发现是:跟尿布一起购买最多的商品 竟是啤酒!
? 经过大量实际调查和分析,揭示了一个隐藏在“ 尿布与啤酒”背后的美国人的一种行为模式:
?在美国,一些年轻的父亲下班后经常要到超市去买婴 儿尿布,而他们中有30%~40%的人同时也为自己买 一些啤酒。产生这一现象的原因是:美国的太太们常 叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买 尿布后又随手带回了他们喜欢的啤酒。
在Clementine 中应用Apriori 算法
?应用Apriori 节点来对某超市的客户采购数据集进 行购物篮分析。该数据集包含有 21个属性(这些 属性包括: COD、pasta 、milk 、water 、 biscuits 、coffee 、brioches 、yoghurt 、frozen vegetables 、tunny 、beer 、tomato 、souce 、 coke 、rice 、juices 、crackers 、oil 、frozen fish 、ice cream 、mozzarella 、tinned meat 。 其中“COD”是记录编号,其它 20个属性代表 20 种商品),共 46243个记录。每个属性代表某种 商品,其取值为“ 0”或者“1”,“0”表示没有购 买该商品,“ 1”表示购买了该商品。
关联规则简介与Apriori算法课件

置信度评估
评估关联规则的置信度,以确定规则是否具有可信度 。
剪枝
根据规则的置信度和支持度进行剪枝,去除低置信度 和低支持度的规则。
04 Apriori算法的优化策略
基于散列的技术
散列技术
通过散列函数将数据项映射到固定大小的桶中,具有相同散列值的数据项被分配 到同一个桶中。这种方法可以减少候选项集的数量,提高算法效率。
散列函数选择
选择合适的散列函数可以减少冲突,提高散列技术的效率。需要考虑散列函数的 均匀分布性和稳定性。
基于排序的方法
排序技术
对数据项按照某种顺序进行排序,如 按照支持度降序排序,优先处理支持 度较高的数据项,减少不必要的计算 和比较。
排序算法选择
选择高效的排序算法可以提高算法效 率,如快速排序、归并排序等。
关联规则的分类
关联规则可以根据不同的标准进行分类。
根据不同的标准,关联规则可以分为多种类型。根据规则中涉及的项的数量,可以分为单维关联规则和多维关联规则。根据 规则中项的出现顺序,可以分为无序关联规则和有序关联规则。根据规则的置信度和支持度,可以分为强关联规则和弱关联 规则。
关联规则挖掘的步骤
关联规则挖掘通常包括以下步骤:数据预处理、生成 频繁项集、生成关联规则。
关联规则简介与 Apriori算法课件
目录
• 关联规则简介 • Apriori算法简介 • Apriori算法的实现过程 • Apriori算法的优化策略 • 实例分析 • 总结与展望
01 关联规则简介
关联规则的定义
关联规则是数据挖掘中的一种重要技术,用于发现数据集中 项之间的有趣关系。
关联规则是一种在数据集中发现项之间有趣关系的方法。这 些关系通常以规则的形式表示,其中包含一个或多个项集, 这些项集在数据集中同时出现的频率超过了预先设定的阈值 。
评估关联规则的置信度,以确定规则是否具有可信度 。
剪枝
根据规则的置信度和支持度进行剪枝,去除低置信度 和低支持度的规则。
04 Apriori算法的优化策略
基于散列的技术
散列技术
通过散列函数将数据项映射到固定大小的桶中,具有相同散列值的数据项被分配 到同一个桶中。这种方法可以减少候选项集的数量,提高算法效率。
散列函数选择
选择合适的散列函数可以减少冲突,提高散列技术的效率。需要考虑散列函数的 均匀分布性和稳定性。
基于排序的方法
排序技术
对数据项按照某种顺序进行排序,如 按照支持度降序排序,优先处理支持 度较高的数据项,减少不必要的计算 和比较。
排序算法选择
选择高效的排序算法可以提高算法效 率,如快速排序、归并排序等。
关联规则的分类
关联规则可以根据不同的标准进行分类。
根据不同的标准,关联规则可以分为多种类型。根据规则中涉及的项的数量,可以分为单维关联规则和多维关联规则。根据 规则中项的出现顺序,可以分为无序关联规则和有序关联规则。根据规则的置信度和支持度,可以分为强关联规则和弱关联 规则。
关联规则挖掘的步骤
关联规则挖掘通常包括以下步骤:数据预处理、生成 频繁项集、生成关联规则。
关联规则简介与 Apriori算法课件
目录
• 关联规则简介 • Apriori算法简介 • Apriori算法的实现过程 • Apriori算法的优化策略 • 实例分析 • 总结与展望
01 关联规则简介
关联规则的定义
关联规则是数据挖掘中的一种重要技术,用于发现数据集中 项之间的有趣关系。
关联规则是一种在数据集中发现项之间有趣关系的方法。这 些关系通常以规则的形式表示,其中包含一个或多个项集, 这些项集在数据集中同时出现的频率超过了预先设定的阈值 。
关联分析基本概念与算法ppt课件
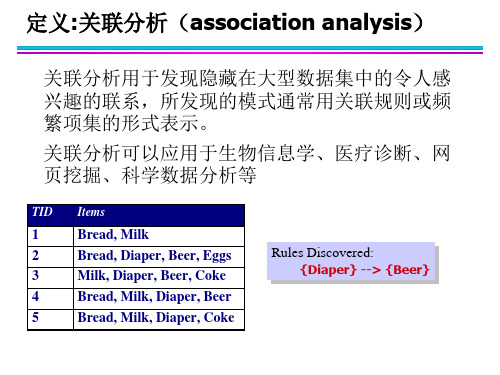
如果一个项集包含k个项 支持度计数(Support count )() – 包含特定项集的事务个数 – 例如: ({Milk, Bread,Diaper}) = 2 支持度(Support) – 包含项集的事务数与总事务数的比值 – 例如: s({Milk, Bread, Diaper}) =
2/5 频繁项集(Frequent Itemset) – 满足最小支持度阈值( minsup )的
先验原理( Apriori principle)
先验原理:
– 如果一个项集是频繁的,则它的所有子集一定也是频繁 的
相反,如果一个项集是非频繁的,则它的所有超集 也一定是非频繁的:
– 这种基于支持度度量修剪指数搜索空间的策略称为基于 支持度的剪枝(support-based pruning)
– 这种剪枝策略依赖于支持度度量的一个关键性质,即一 个项集的支持度决不会超过它的子集的支持度。这个性 质也称为支持度度量的反单调性(anti-monotone)。
4
Bread, Milk, Diaper, Beer
关联规则的强度
5
Bread, Milk, Diaper, Coke
– 支持度 Support (s) 确定项集的频繁程度
Example:
{M,iD lkia}p e Bree
– 置信度 Confidence (c) 确定Y在包含X的事 务中出现的频繁程度
Brute-force 方法:
– 把格结构中每个项集作为候选项集
– 将每个候选项集和每个事务进行比较,确定每个候选项集 的支持度计数。
Transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
2/5 频繁项集(Frequent Itemset) – 满足最小支持度阈值( minsup )的
先验原理( Apriori principle)
先验原理:
– 如果一个项集是频繁的,则它的所有子集一定也是频繁 的
相反,如果一个项集是非频繁的,则它的所有超集 也一定是非频繁的:
– 这种基于支持度度量修剪指数搜索空间的策略称为基于 支持度的剪枝(support-based pruning)
– 这种剪枝策略依赖于支持度度量的一个关键性质,即一 个项集的支持度决不会超过它的子集的支持度。这个性 质也称为支持度度量的反单调性(anti-monotone)。
4
Bread, Milk, Diaper, Beer
关联规则的强度
5
Bread, Milk, Diaper, Coke
– 支持度 Support (s) 确定项集的频繁程度
Example:
{M,iD lkia}p e Bree
– 置信度 Confidence (c) 确定Y在包含X的事 务中出现的频繁程度
Brute-force 方法:
– 把格结构中每个项集作为候选项集
– 将每个候选项集和每个事务进行比较,确定每个候选项集 的支持度计数。
Transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
关联规则概念.ppt

Ai (i∈{1, …,m}),Bj(j∈{1, …,n})是属性-值对。
关联规则X Y解释为“满足X中条件的数据库元组
多半也满足Y中条件”。
7
一、关联规则相关知识
例1:给Electionics公司的关系数据库,一个数据挖 掘系统可能发现如下形式的关联规则
age(X,“20…29”) ∧income(X,“20K…29K”)
13
二、Apriori算法及举例
1.连接步:
例: L3={abc, abd, acd, ace, bcd} Self-joining: L3 ⊕ L3
abcd from abc and abd acde from acd and ace
14
二、Apriori算法及举例
2.剪枝步:Ck是Lk的超集,它的成员可以是频繁的, 也可以不是频繁的,但所有的频繁k-项集都包含在 Ck中。
扫描数据库,确定Ck中每个候选k-项集的计数, 将计数值≥最小支持度计数的所有候选k-项集确定 到Lk中。然而,Ck可能很大,这样所涉及到的计算 量就很大。这时使用Apriori性质:如果一个候选 k-项集的(k-1)-项集不在Lk-1中,则该候选也不 可能是频繁的,从而可以从Ck中删除。
15
二、Apriori算法及举例
2.剪枝步:
例: L3={abc, abd, acd, ace, bcd}
Pruning:
acde is removed because ade is not in L3
C4={abcd}
16
二、Apriori算法及举例
例2:设有一个Electronics的事务数据库(如图1示)。 数据库中有9个事务,即|D|=9。Apriori假定事务 中的项按字典次序存放。我们使用图2解释Apriori算 法寻找D中的频繁项集。
关联规则X Y解释为“满足X中条件的数据库元组
多半也满足Y中条件”。
7
一、关联规则相关知识
例1:给Electionics公司的关系数据库,一个数据挖 掘系统可能发现如下形式的关联规则
age(X,“20…29”) ∧income(X,“20K…29K”)
13
二、Apriori算法及举例
1.连接步:
例: L3={abc, abd, acd, ace, bcd} Self-joining: L3 ⊕ L3
abcd from abc and abd acde from acd and ace
14
二、Apriori算法及举例
2.剪枝步:Ck是Lk的超集,它的成员可以是频繁的, 也可以不是频繁的,但所有的频繁k-项集都包含在 Ck中。
扫描数据库,确定Ck中每个候选k-项集的计数, 将计数值≥最小支持度计数的所有候选k-项集确定 到Lk中。然而,Ck可能很大,这样所涉及到的计算 量就很大。这时使用Apriori性质:如果一个候选 k-项集的(k-1)-项集不在Lk-1中,则该候选也不 可能是频繁的,从而可以从Ck中删除。
15
二、Apriori算法及举例
2.剪枝步:
例: L3={abc, abd, acd, ace, bcd}
Pruning:
acde is removed because ade is not in L3
C4={abcd}
16
二、Apriori算法及举例
例2:设有一个Electronics的事务数据库(如图1示)。 数据库中有9个事务,即|D|=9。Apriori假定事务 中的项按字典次序存放。我们使用图2解释Apriori算 法寻找D中的频繁项集。
关联规则算法 PPT

Apriori(先验)算法
1.连接步:为找LK,通过LK-1与自己连接产生候选K-项集的集合。该候选 K-项集的集合记为CK,CK中包含2K个可能的项集。从LK-1中取出f1和f2, fj[j]表示fj的第j项。如果两者的前(k-2)个项相同(如果 f1[1]=f2[1]∧f1[2]=f2[2]∧…∧f1[k-2] =f2[k-2]∧f1[k-1] <f2[k-1],则 LK-1的元素f1和f2是可以连接的),则进行连接f1⊕f2形成: {f1[1],f1[2],… ,f1[k-2],f1[k-1],f2[k-1]}。
关联规则算法
目录
基本概念及理论 Apriori(先验)算法 改进Apriori算法 FP-Tree算法
基本概念及理论
关联规则(Association Rule Mining) : 最早是由Agrawal、R.Srikant提出(1994) 发现事务数据库、关系数据或其它信息库中项或数据对象集合间的频 繁模式, 关联, 相关, 或因果关系结构 频繁模式: 在数据库中频繁出现的模式(项集, 序列等)
项集
{I1} {I2} {I3} {I4} {I5}
支持度计数
6 7 6 2 2
L1
比较候选支持度计数 与最小支持度计数
项集
{I1} {I2} {I3} {I4} {I5}
支持度计数
6 7 6 2 2
C2
由L1产生 候选C2
项集
{I1,I2} {I1,I3} {I1,I4} {I1,I5} {I2,I3} {I2,I4} {I2,I5} {I3,I4} {I3,I5} {I4,I5}
Apriori(先验)算法
性质 先验性质:频繁项集的所有非空子集都是频繁项集 非频繁项集的所有超集都是非频繁项集(反单调性)
关联分析计算课件

ECLAT算法
适用场景
适用于挖掘大型数据集中的复杂关联 规则。
优缺点
ECLAT算法能够处理复杂的关联规则 ,但在处理非对称关联规则时可能存 在限制。
04
关联分析工具
Weka关联分析工具
01
Weka是一款流行的机器 学习软件,提供了关联 规则挖掘功能。
02
它支持多种关联规则算 法,如Apriori和FPGrowth,并可进行参数 调整。
适用于挖掘大型数据集中的频 繁项集和关联规则。
FP-Growth算法在处理大数据 集时表现出色,但可能产生较 多的冗余规则。
ECLAT算法
总结词
基于垂直数据格式的关联规则挖掘算法
详细描述
ECLAT算法是一种基于垂直数据格式的关联规则挖掘算法。它将数据表转换为 集合形式,利用集合的对称性来挖掘关联规则。ECLAT算法能够处理复杂的关 联规则,且在处理大数据集时具有较高的效率。
关联分析的原理
关联分析基于“支持度”和“置 信度”两个基本度量来评估规则
的有趣性。
支持度衡量项集在数据集中出现 的频率,而置信度则表示规则后
件的准确性。
通过设置最小支持度和最小置信 度阈值,过滤出强关联规则。
关联分析的应用场景
购物篮分析
发现商品之间的销售关 系,优化商品摆放和促
销策略。
市场细分
根据客户购买行为将市 场划分为不同的群体, 为不同群体制定营销策
可解释性机器学习与关联分析的结合
可解释性机器学习旨在让机器学习模型的结果更容易被人 类理解。将可解释性机器学习与关联分析相结合,可以提 供更清晰的解释和可视化结果,帮助用户更好地理解数据 间的关联规则。
可解释性机器学习技术如特征重要性分析和模型解释等, 可以为关联分析提供更直观的解释和可视化结果。通过这 些技术,用户可以更清楚地了解哪些特征对关联规则的发 现具有重要影响,以及这些规则是如何得出的。
数据挖掘关联规则ppt课件

C1 1st scan
Itemset sup
{A}
2 L1
{B}
3
{C}
3
{D}
1
{E}
3
Itemset sup
{A}
2
{B}
3
{C}
3
{E}
3
40
B, E
L2 Itemset sup
{A, C}
2
{B, C}
2
{B, E}
3
{C, E}
2
C2 Itemset
{A, B}
{A, C}
sup 1 2
C2 2nd scan
19
生成频繁项集
中心思想: 由频繁(k-1)-项集构建候选k-项集 方法 找到所有的频繁1-项集 扩展频繁(k-1)-项集得到候选k-项集 剪除不满足最小支持度的候选项集
20
Apriori: 一种候选项集生成-测试方法
Apriori 剪枝原理: 若任一项集是不频繁的,则其超集 不应该被生成/测试!
果.
3
市场购物篮分析
分析事务数据库表
Perso n A B
C D
Basket
Chips, Salsa, Cookies, Crackers, Coke, Beer Lettuce, Spinach, Oranges, Celery, Apples, Grapes Chips, Salsa, Frozen Pizza, Frozen Cake Lettuce, Spinach, Milk, Butter
探寻共享多层挖掘统一支持度milksupport102milksupport6skimmilksupport4level5level5level5level3减少的支持度可伸缩的支持度约束的多层多维mlmd关联规则特殊的项和特殊的项的组合可以特别设定最小支持度以及拥有更高的优先级多维关联规则buysxmilkbuysxbread个维度或谓词predicates跨维度interdimension关联规则无重复谓词混合维度hybriddimension关联规则重复谓词buysxpopcornbuysxcoke数值的值之间有固有的排序多层关联规则
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
❖ 强关联规则:同时满足用户定义的最小支持度阈值 (min_sup)和最小置信度阈值(min_conf)的规则 称为强规则。
9
8
2012-10-12
二、关联规则挖掘过程
两个步骤: ▪ 找出所有频繁项集。 ▪ 由频繁项集生成满足最小信任度阈值的规则。
挖掘模式:
Database
产生频繁项集
min_sup
3
2012-10-12
绪论
4
2012-10-12
一、基本概念
设 I={I1,I2,…,In} 是项的集合。
❖任务相关数据D:是事务(或元组)的集合。
❖事务T:是项的集合,且每个事务具有事务标识 符TID。
❖项集A:是T 的一个子集,加上TID 即事务。
❖项集(Items):项的集合,包含k个项的项集称为 k-项集,如二项集{I1,I2}。 ❖支持度计数(Support count):一个项集的出现次
Support(A B)=P ( A ∩ B )
= support _ count(A∩B)
count (T) ❖ 频繁项集:若一个项集的支持度大于等于某个阈值。
7
2012-10-12
一、基本概念
❖ 置信度c:是包含A的事务中同时又包含B的百分比, 即条件概率。[规则准确性衡量]
confidence ( A B ) = P ( B | A) = support _ count ( A U B ) support_count ( A)
啤酒=>尿布
职业 秘书 工程师
购买物品 月工资
尿布
3000
啤酒、尿布 5000
性别=“女”=>职业=“秘书”
20
2012-10-12
四、关联规则的价值衡量
对关联规则的评价与价值衡量涉及两个层面: A.系统客观的层面 使用“支持度和信任度”框架可能会产生一 些不正确的规则。
B.用户主观的层面 ✓只有用户才能决定规则的有效性、可行性。 ✓如果把某些约束条件与算法紧密结合,既能提高数 据挖掘效率,又能明确数据挖掘的目标。
I1=苹果 I2=面包 I3=牛奶 I4=尿布 I5=啤酒
Support-count(I1)=6
6
2012-10-12
一、基本概念
❖关联规则:形如 A => B 的蕴涵式,其中A ⊂I , B⊂I,并且 A∩B =ф。
❖ 支持度:关联规则在D中的支持度(support)是D中事 务同时包含A、B的百分比,即概率。[规则代表性、 重要性衡量]
21
2012-10-12
五、关联规则的挖掘算法
Apriori算法 挖掘或识别出所有频繁项集是该算法的核心,占
整个计算量的大部分。 不足:产生大量候选频繁集、多次扫描数据库 FP-Tree算法 优点:不产生候选频繁集、只两次扫描数据库 其他算法…
22
2012-10-12
六、关联规则的应用
购物分 析
➢ 打篮球 => 喝麦片粥 [40%, 66.7%]是错误的,因为全部 学生中喝麦片粥的比率是75%,比打篮球学生的66.7%要高。
➢ 打篮球 => 不喝麦片粥 [20%, 33.3%]这个规则远比上面 那个要精确,尽管支持度和置信度都要低的多。
14
2012-10-12
二、关联规则挖掘过程
兴趣度(作用度):描述了项集A对项集B的影响力的 大小,即A与B的相关程度。
23
医疗诊 断
2012-10-12
气象预 测
…
Thank You!
2012-10-12
24
13
2012-10-12
二、关联规则挖掘过程
对强关联规则的批评:
eg:
项目 喝麦片 不喝麦片 合计
打篮球 2000 1000 3000
不打篮球 1750 250 2000
合计 3750 1250 5000
在5000个学生中,3000个打篮球,3750个喝麦片 粥,2000个学生既打篮球又喝麦片粥。
16
2012-10-12
三、关联规则的分类
基于规则中处理的变量的类别 A.布尔型:布尔型关联规则处理的值都是离散的、种
类化的,它显示了这些变量之间的关系; B. 数值型 :数值型关联规则可以和多维关联或多层
关联规则结合起来,对数值型字段进行处理。 eg: 性别=“女”=>职业=“秘书” 性别=“女”=>avg(收入)=2300
关联规则分析及应用ppt课件
目录
1
基本概念
2
关联规则挖掘过程
3
分类
4
关联规则的价值衡量
5
挖掘算法
6
关联规则的应用
2
2012-10-12
绪论
在购买铁锤的顾客当中,有70%的人同时 购买了铁钉。
年龄在40 岁以上,工作在A区的投保人当 中,有45%的人曾经向保险公司索赔过。
在超市购买面包的人有70%会购买牛奶
Hale Waihona Puke 172012-10-12
三、关联规则的分类
基于规则中数据的抽象层次: A.单层关联规则:所有的变量都没有考虑到现实的数
据是具有多个不同的层次的;
B.多层关联规则:对数据的多层性已经进行了充分的 考虑。
层:大类是否细分的问题,如上衣可以细分为 衬衣、夹克、风衣等。
eg: IBM台式机=>Sony打印机
生成强关联规则
min_conf
用户
规则评价
9
2012-10-12
二、关联规则挖掘过程
关联规则挖掘举例:
假定数据包含频繁项集
M={I1,I2,I5}。可以由M
产生哪些关联规则?
10
2012-10-12
二、关联规则挖掘过程
❖ M 的非空真子集有{I1,I2}、{I1,I5}、{I2,I5}、
{I1}、{I2}和{I5}。则结果关联规则如下,每个都
I1 I2 I5, I1 I5 I2, I2 I5 I1, I1 I2 I5, I2 I1 I5, I5 I1 I2,
confidence = 2/4 = 50 % confidence = 2/2 = 100 % confidence = 2/2 = 100 %
confidence = 2/6 = 33% confidence = 2/7 = 29% confidence = 2/2 = 100 %
P(AB) I(A B)= P(A)P(B) ✓若I(A B)=1,即P(A)P(B)=P(AB),A与B相互独立; ✓若I(A B)<1,表示A出现和B出现是负相关的。 ✓若I(A B)>1,表示A出现和B出现是正相关的。意味 着A的出 现蕴含B的出现。 小结:只有兴趣度大于1,该规则才具有实际价值。
数就是整个数据集中包含该项集的事务数。
5
2012-10-12
一、基本概念
D
TID
Items
001
I1、I2、I5
002
I2、I4
T
003
A I2、I3
004
I1、I2、I4
005
I1、I3
006
B I2、I3
007
I1、I3
008
I1、I2、I3、I5
009
I1、I2、I3
In(n=1,2,…) 指具体项目,如 购物篮分析中:
12
2012-10-12
二、关联规则挖掘过程
如果最小置信度阈值为70%,那么只有第2、3、6个规 则可以作为最终的结果输出,因为只有这些是产生的 强关联规则。
I1 I5 I2, I2 I5 I1,
I5 I1 I2,
confidence = 2/2 = 100 % confidence = 2/2 = 100% confidence = 2/2 = 100%
台式机=>Sony打印机
18
2012-10-12
三、关联规则的分类
分层示例:
19
2012-10-12
三、关联规则的分类
基于规则中数据的维数: A.单维关联规则:只涉及到数据的一个维,如用户购
买的物品;
B.多维关联规则:要处理的数据将会涉及多个维。
TID 001 002
eg:
姓名 张三 李四
性别 女 男
列出置信度。
项集
支持度计
数
项集 支持度 {I1,I2}
4
计数
{I1}
6
{I2}
7
{I3}
6
{I4}
2
{I1,I3}
4
{I1,I5}
2
{I2,I3}
4
{I2,I4}
2
项集
支持度 计数
{I1,I2,I3} 2
{I1,I2,I5} 2
{I5}
2
{I2,I5}
2
11
2012-10-12
二、关联规则挖掘过程
15
2012-10-12
三、关联规则的分类
基于规则中处理的变量的类别 A.布尔型:布尔型关联规则处理的值都是离散的、种
类化的,它显示了这些变量之间的关系; B. 数值型:数值型关联规则可以和多维关联或多层
关联规则结合起来,对数值型字段进行处理。 eg: 性别=“女”=>职业=“秘书” 性别=“女”=>avg(收入)=2300