蚁群算法简介
蚁群算法
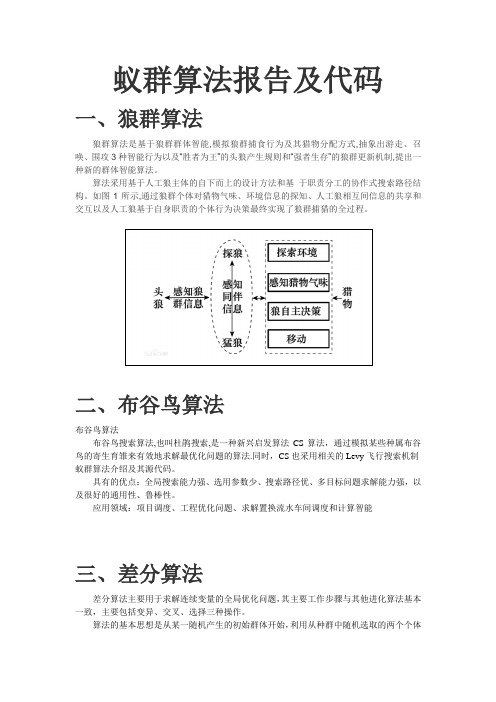
蚁群算法报告及代码一、狼群算法狼群算法是基于狼群群体智能,模拟狼群捕食行为及其猎物分配方式,抽象出游走、召唤、围攻3种智能行为以及“胜者为王”的头狼产生规则和“强者生存”的狼群更新机制,提出一种新的群体智能算法。
算法采用基于人工狼主体的自下而上的设计方法和基于职责分工的协作式搜索路径结构。
如图1所示,通过狼群个体对猎物气味、环境信息的探知、人工狼相互间信息的共享和交互以及人工狼基于自身职责的个体行为决策最终实现了狼群捕猎的全过程。
二、布谷鸟算法布谷鸟算法布谷鸟搜索算法,也叫杜鹃搜索,是一种新兴启发算法CS算法,通过模拟某些种属布谷鸟的寄生育雏来有效地求解最优化问题的算法.同时,CS也采用相关的Levy飞行搜索机制蚁群算法介绍及其源代码。
具有的优点:全局搜索能力强、选用参数少、搜索路径优、多目标问题求解能力强,以及很好的通用性、鲁棒性。
应用领域:项目调度、工程优化问题、求解置换流水车间调度和计算智能三、差分算法差分算法主要用于求解连续变量的全局优化问题,其主要工作步骤与其他进化算法基本一致,主要包括变异、交叉、选择三种操作。
算法的基本思想是从某一随机产生的初始群体开始,利用从种群中随机选取的两个个体的差向量作为第三个个体的随机变化源,将差向量加权后按照一定的规则与第三个个体求和而产生变异个体,该操作称为变异。
然后,变异个体与某个预先决定的目标个体进行参数混合,生成试验个体,这一过程称之为交叉。
如果试验个体的适应度值优于目标个体的适应度值,则在下一代中试验个体取代目标个体,否则目标个体仍保存下来,该操作称为选择。
在每一代的进化过程中,每一个体矢量作为目标个体一次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局最优解逼近。
四、免疫算法免疫算法是一种具有生成+检测的迭代过程的搜索算法。
从理论上分析,迭代过程中,在保留上一代最佳个体的前提下,遗传算法是全局收敛的。
五、人工蜂群算法人工蜂群算法是模仿蜜蜂行为提出的一种优化方法,是集群智能思想的一个具体应用,它的主要特点是不需要了解问题的特殊信息,只需要对问题进行优劣的比较,通过各人工蜂个体的局部寻优行为,最终在群体中使全局最优值突现出来,有着较快的收敛速度。
简要叙述蚁群算法及其优缺点

简要叙述蚁群算法及其优缺点蚁群算法,说白了,就是从蚂蚁们的“工作方式”中汲取灵感,来解决一些复杂的问题。
你想啊,蚂蚁虽然个头小,脑袋也没啥大智慧,可它们集体合作的时候,可真是让人瞠目结舌。
就拿找食物这事儿来说,蚂蚁们通过一种叫做“信息素”的东西,能把食物的方向告诉其他蚂蚁。
你想,成群结队的蚂蚁在地上爬来爬去,气氛可热闹了。
而这些蚂蚁在寻找最短路径的过程中,就是利用这种“信息素”来引导彼此。
哦对,信息素就是一种化学物质,它能吸引其他蚂蚁走自己走过的路,时间久了,大家都能找到最短最优的路线。
这就是蚁群算法的核心,大家通过简单的规则合作起来,居然能找到很复杂问题的解决方案。
听起来是不是有点神奇?但这就是大自然的魅力,真是让人不得不佩服!蚁群算法的好处,简直是数不胜数。
它特别适合处理那些“大而复杂”的问题。
像是找最短路径、优化调度这些问题,用蚁群算法解决起来特别靠谱。
更妙的是,它不需要预先知道问题的具体情况。
就像蚂蚁不需要知道前方有什么危险,只要它们不断地试探,最终总能找到正确的路。
蚁群算法特别“顽强”,它可以通过不断地调整来适应环境变化。
假设前方的路突然有个障碍,蚂蚁们马上就能改变路线,去找另一条更合适的道路。
这种动态适应能力,在现实世界中有着广泛的应用,像物流配送、网络路由、甚至是金融分析等,蚁群算法都能大显身手。
不过话说回来,世上没有十全十美的事儿,蚁群算法也有它的缺点。
首先吧,虽然它能找到“可行的”解,但并不总能找到“最优”的解。
你要知道,这个算法是基于概率的,蚂蚁们在探索路径时是随机的,所以它有可能会走冤枉路,最终找到一个不错但不是最好的答案。
就像你找餐厅,可能你最后选了个味道还不错的地方,但走了好多冤枉路,吃完饭才发现旁边就有个更好吃的店。
所以,有时候蚁群算法可能不是最理想的选择,特别是当问题特别复杂,解空间又大到让你头晕眼花的时候。
再者呢,蚁群算法的计算量也挺大的。
每次要让大量的“蚂蚁”在问题空间中四处乱窜,寻找最佳路径。
蚁群算法简介

,
钒 :
{
一…
其 中,lw d=N t ul表示蚂蚁 k下一 al e k{—a k o b 步允许选择的城市, t u 表示第 k 而 a k b 个蚂蚁 的 禁忌 表,b ) t u(表示禁忌 表中第 s a s 个元 素; 表 , 示 由城市 i 转移到城市 i 的期望程度f 又称可见 度) 可根据某种启发式算法具体确定, , 当 .O > 时, 表示邻域 i 处蚂蚁按概率 P移 至邻域 j 。 的概 率; - ≤0时, 当q 。 邻域 i 的蚂 蚁做邻域搜索, 其搜 索半径 ( 或步长) rtB 为 ;、 分别 表示蚂蚁在 运动 c 过程 中所积累的信息及启发式 因子在蚂蚁选择 路径 中所起的不同作用, 它们是控制 信息激素 强度与可见度 的相对重要性 的参数 。 可见, 转移 概率是可见度 和 t 时刻信息激素强度的权衡 。 与真实蚂蚁系统不同,人工蚁群系统具有 定 的记忆功 能, t u(: ,, m 记 录蚂 蚁 用 a l …,) b k 2 k目前 已走过 的城市。随着时间 的推移, 以前留 下的信息激素逐渐消逝。设信息激素的保留系 数为 p < < ) ( p 1 它体现 了信息激 素强度的持 久 0 , 性; 1 p 而 - 表示信息激素的消逝程度( 信息激素 蒸发) 。经过 △ 时段, t 蚂蚁完成一 次循环, 各路径 e 信 息激素量需按式( 刷新: 2 )
一 一
3蚁群算法模型 为模 拟蚂蚁 的行 为,以求解 N个城 市 的 T P问题为例 。已知有 N个城市, S 寻找一条访 问 两个城市之间的最短路径。设 蚁群 中蚂蚁数量 为 m, : ,, N表示城市 i j d 12…,) 和 之间的路径 长度, 此处选用的是无 向图 G NE, d= j ( ,) 。d. 即 . N是 城市个数, E是城市 的连通的边的集合 。 Bm 设 . 表 示t 时刻位于城市 i 的蚂蚁个数, 则有
蚁群算法——精选推荐

蚁群算法⼀、蚁群算法蚁群算法是在20世纪90年代由澳⼤利亚学者Marco Dorigo等⼈通过观察蚁群觅⾷的过程,发现众多蚂蚁在寻找⾷物的过程中,总能找到⼀条从蚂蚁巢⽳到⾷物源之间的最短路径。
随后他们在蚂蚁巢⽳到⾷物源之间设置了⼀个障碍,⼀段时间以后发现蚂蚁⼜重新⾛出了⼀条到⾷物源最短的路径。
通过对这种现象的不断研究,最后提出了蚁群算法。
蚁群算法在解决(即TSP问题)时,取得了⽐较理想的结果。
⼆、基本⼈⼯蚁群算法原理运⽤⼈⼯蚁群算法求解TSP问题时的基本原理是:将m个蚂蚁随机地放在多个城市,让这些蚂蚁从所在的城市出发,n步(⼀个蚂蚁从⼀个城市到另外⼀个城市为1步)之后返回到出发的城市。
如果m个蚂蚁所⾛出的m条路经对应的中最短者不是TSP问题的最短路程,则重复这⼀过程,直⾄寻找到满意的TSP问题的最短路径为⽌。
为了说明这⼀个算法下⾯⽤⼀个算法流程图来表⽰⼀下:三、蚁群算法中涉及到的参数及其符号::蚂蚁数量,约为城市数量的1.5倍。
如果蚂蚁数量过⼤,则每条路径上的信息素浓度趋于平均,正反馈作⽤减弱,从⽽导致收敛速度减慢;如果过⼩,则可能导致⼀些从未搜索过的路径信息素浓度减⼩为0,导致过早收敛,解的全局最优性降低:信息素因⼦,反映了蚂蚁运动过程中积累的信息量在指导蚁群搜索中的相对重要程度,取值范围通常在[1, 4]之间。
如果信息素因⼦值设置过⼤,则容易使随机搜索性减弱;其值过⼩容易过早陷⼊局部最优:启发函数因⼦,反映了启发式信息在指导蚁群搜索中的相对重要程度,取值范围在[3, 4.5]之间。
如果值设置过⼤,虽然收敛速度加快,但是易陷⼊局部最优;其值过⼩,蚁群易陷⼊纯粹的随机搜索,很难找到最优解:信息素挥发因⼦,反映了信息素的消失⽔平,相反的反映了信息素的保持⽔平,取值范围通常在[0.2, 0.5]之间。
当取值过⼤时,容易影响随机性和全局最优性;反之,收敛速度降低:信息素常数,表⽰蚂蚁遍历⼀次所有城市所释放的信息素总量。
04蚁群算法ACA

导言蚁群算法是20世纪90年代发展起来一种模仿蚂蚁群体行为的新的智能优化算法。
意大利学者Dorigo M等人提出一种模拟昆虫王国蚂蚁群体觅食行为方式的仿生优化算法——蚁群算法(Ant Colony Algorithm,ACA)。
该算法引入正反馈并行机制,具有较强的鲁棒性、优良的分布式计算机制、易于与其他方法结合等优点。
目前蚁群算法已经渗透到各个应用领域,从一维静态优化问题到多维动态优化问题,从离散问题到连续问题。
蚁群算法解决了许多复杂优化和经典NP-C问题,展现出优异的性能和广阔的发展前景。
基本蚁群算法的原理基本蚁群算法(Ant System,AS)是采用人工蚂蚁的行走路线来表示待求问题可行解得一种方法。
每只人工蚂蚁在解空间中独立的搜索可行解,当它们碰到一个还没有走过的路口时,就随机挑选一条路径前行,同时释放出与路径长度有关的信息素(pheromone) 。
路径越短信息素的浓度就越大。
当后继的人工蚂蚁再次碰到这个路口的时候,以相对较大的概率选择信息素较多的路径,并在“行走路径”上留下更多的信息素,影响后来的蚂蚁,形成正反馈机制。
随着算法的推进,代表最优解路线上的信息素逐渐增多,选择它的蚂蚁也逐渐增多,其他路径上的信息素却会随着时间的流逝而逐渐消减,最终整个蚂蚁在正反馈机制的作用下集中到代表最优解的路线上,也就找到了最优解。
在整个寻优过程中,单只蚂蚁的选择能力有限,但蚁群具有高度的自组织性,通过信息素交换路径信息,形成集体自催化行为,找到最优路径。
蚁群优化算法中,每个优化问题的解都是搜索空间的一只蚂蚁,蚂蚁都有一个由优化的目标函数决定的适应度函数值(与释放的信息素成正比) ,蚂蚁根据周围信息素的多少决定搜索方向,并在搜索过的路径上释放信息素以影响别的蚂蚁。
优缺点分析ACA 具有如下优点:(1)ACA 是一种正反馈算法,这是蚁群算法最显著的特点;(2)ACA 本质上一种分布式并行算法。
(3)ACA 具有较好的全局寻优特性。
遗传算法与蚁群算法简介

实数编码的GA通常采用算术交叉: 双个体算术交叉:x1、x2为父代个体,α ∈(0, 1)为随机数 x1' = αx1 + (1 - α)x2 x2' = αx2 + (1 - α)x1 多个体算术交叉: x1, …, x2为父代个体; αi ∈(0, 1)且∑αi = 1 x' = α1x1 + α2x2 + … + αnxn 组合优化中的置换编码GA通常采用 部分映射交叉(partially mapping crossover, PMX):随机选择两个交叉点,交换交叉点之间的片段;对于其他基因,若它不与换过来的片段冲突则保留,若冲突则通过部分映射来确定最后的基因 p1 = [2 6 4 | 7 3 5 8 | 9 1] p1' = [2 3 4 | 1 8 7 6 | 9 5] p2 = [4 5 2 | 1 8 7 6 | 9 3] p2' = [4 1 2 | 7 3 5 8 | 9 6]
北京交通大学计算机与信息技术学院
*
智能优化算法简介
*பைடு நூலகம்
20世纪80年代以来,一些优化算法得到发展 GA、EP、ACO、PSO、SA、TS、ANN及混合的优化策略等 基本思想:模拟或揭示某些自然现象或过程 为用传统的优化方法难以解决的NP-完全问题提供了有效的解决途径 由于算法构造的直观性与自然机理,因而通常被称作智能优化算法(intelligent optimization algorithms),或现代启发式算法(meta-heuristic algorithms) [智能优化算法及其应用,王凌,清华大学出版社,2001]
线性次序交叉(LOX)
单位置次序交叉(C1)
类似于OX。选择一个交叉位置,保留父代个体p1交叉位置前的基因,并在另一父代个体p2中删除p1中保留的基因,将剩余基因填入p1的交叉位置后来产生后代个体p1'。如父代个体同前,交叉位置为4,则后代个体为p1' =[2 6 4 7 | 5 1 8 9 3],p2' =[4 5 2 1 | 6 7 3 8 9]
蚁群算法——精选推荐
蚁群算法蚁群算法⽬录1 蚁群算法基本思想 (1)1.1蚁群算法简介 (1)1.2蚁群⾏为分析 (1)1.3蚁群算法解决优化问题的基本思想 (2)1.4蚁群算法的特点 (2)2 蚁群算法解决TSP问题 (3)2.1关于TSP (3)2.2蚁群算法解决TSP问题基本原理 (3)2.3蚁群算法解决TSP问题基本步骤 (5)3 案例 (6)3.1问题描述 (6)3.2解题思路及步骤 (6)3.3MATLB程序实现 (7)3.1.1 清空环境 (7)3.2.2 导⼊数据 (7)3.3.3 计算城市间相互距离 (7)3.3.4 初始化参数 (7)3.3.5 迭代寻找最佳路径 (7)3.3.6 结果显⽰ (7)3.3.7 绘图 (7)1 蚁群算法基本思想1.1 蚁群算法简介蚁群算法(ant colony algrothrim,ACA)是由意⼤利学者多⾥⼽(Dorigo M)、马聂佐(Maniezzo V )等⼈于20世纪90初从⽣物进化的机制中受到启发,通过模拟⾃然界蚂蚁搜索路径的⾏为,提出来的⼀种新型的模拟进化算法。
该算法⽤蚁群在搜索⾷物源的过程中所体现出来的寻优能⼒来解决⼀些系统优化中的困难问题,其算法的基本思想是模仿蚂蚁依赖信息素,通过蚂蚁间正反馈的⽅法来引导每个蚂蚁的⾏动。
蚁群算法能够被⽤于解决⼤多数优化问题或者能够转化为优化求解的问题,现在其应⽤领域已扩展到多⽬标优化、数据分类、数据聚类、模式识别、电信QoS管理、⽣物系统建模、流程规划、信号处理、机器⼈控制、决策⽀持以及仿真和系统辩识等⽅⾯。
蚁群算法是群智能理论研究领域的⼀种主要算法。
1.2 蚁群⾏为分析Bm=20t=0 m=10m=10t=11.3 蚁群算法解决优化问题的基本思想⽤蚂蚁的⾏⾛路径表⽰待优化问题的可⾏解,整个蚂蚁群体的所有路径构成待优化问题的解空间。
路径较短的蚂蚁释放的信息量较多,随着时间的推进,较短路径上积累的信息浓度逐渐增⾼,选择该路径的蚂蚁个数愈来愈多。
蚁群算法(ACO)简要介绍
城市之间距离
目标函数为 其中 w
(d ij ) nn
f ( w) d il 1i, l
l 1 n
(i1 , i2 ,, in )
为城市1,2,…n的一个排列,
in1 i1
算法示例
蚂蚁k(k=1,2,…,m)根据各个城市间连接路径上的信 息素浓度决定其下一个访问城市,设 Pijk (t )表示t时刻蚂蚁k 从城市i转移到城市j的概率,其计算公式为:
is (t )is (t ) , s allowk Pijk (t ) is (t )is (t ) xallowk 0, s allowk
信息更新公式为:
ij (t 1) (1 ) ij (t ) ij n ,0 1 k ij ii k 1
算法原理
算法原理
基于以上蚁群寻找食物时的最优路径选择问题, 可以构造人工蚁群,来解决最优化问题。 人工蚁群中把具有简单功能的工作单元看作蚂蚁。 二者的相似之处在于都是优先选择信息素浓度大的路径。 较短路径的信息素浓度高,所以能够最终被所有蚂蚁选 择,也就是最终的优化结果。 两者的区别在于人工蚁群有一定的记忆能力,能 够记忆已经访问过的节点。同时,人工蚁群再选择下一 条路径的时候是按一定算法规律有意识地寻找最短路径, 而不是盲目的。例如在TSP问题中,可以预先知道当前 城市到下一个目的地的距离。
蚁群算法(ACO)介绍
李杰林
ACO算法起源
20世纪90年代意大利学者M.Dorigo, V.Maniezzo,A.Colorni等从生物进化的机制中 受到启发,通过模拟自然界蚂蚁搜索路径的行为, 提出来一种新型的模拟进化算法——蚁群算法, 是群智能理论研究领域的一种主要算法。用该方 法求解TSP问题、分配问题、job-shop调度问题, 取得了较好的试验结果。虽然研究时间不长,但 是现在的研究显示出,蚁群算法在求解复杂优化 问题(特别是离散优化问题)方面有一定优势, 表明它是一种有发展前景的算法。
蚁群算法ppt课件
2 简化旳蚂蚁寻食过程
假设蚂蚁每经过一处所留下旳信息素为一种单位,则经过36个时间单位 后,全部开始一起出发旳蚂蚁都经过不同途径从D点取得了食物,此时ABD 旳路线来回了2趟,每一处旳信息素为4个单位,而 ACD旳路线来回了一趟, 每一处旳信息素为2个单位,其比值为2:1。
寻找食物旳过程继续进行,则按信息素旳指导,蚁群在ABD路线上增派一 只蚂蚁(共2只),而ACD路线上依然为一只蚂蚁。再经过36个时间单位后, 两条线路上旳信息素单位积累为12和4,比值为3:1。
8
2 简化旳蚂蚁寻食过程
蚂蚁从A点出发,速度相同,食物在D点,可能随机选择路线 ABD或ACD。假设初始时每条分配路线一只蚂蚁,每个时间单位 行走一步,本图为经过9个时间单位时旳情形:走ABD旳蚂蚁到 达终点,而走ACD旳蚂蚁刚好走到C点,为二分之一旅程。
9
2 简化旳蚂蚁寻食过程
本图为从开始算起,经过18个时间单位时旳情形:走ABD旳蚂 蚁到达终点后得到食物又返回了起点A,而走ACD旳蚂蚁刚好走 到D点。
若按以上规则继续,蚁群在ABD路线上再增派一只蚂蚁(共3只),而 ACD路线上依然为一只蚂蚁。再经过36个时间单位后,两条线路上旳信息素 单位积累为24和6,比值为4:1。
若继续进行,则按信息素旳指导,最终全部旳蚂蚁会放弃ACD路线,而都 选择ABD路线。这也就是前面所提到旳正反馈效应。
11
3 自然蚁群与人工蚁群算法
15
5 初始旳蚁群优化算法—基于图旳蚁群 系统(GBAS)
初始旳蚁群算法是基于图旳蚁群算法,graph-based
ant system,简称为GBAS,是由Gutjahr W J在2023年
旳Future Generation Computing Systems提出旳.
《蚁群算法介绍》课件
输出最优解和相关性能指标。
详细描述
这一步是将最优解和相关性能指标输出,以 便于对算法的性能进行分析和评估。
04
蚁群算法的性能分析
收敛性分析
收敛速度
蚁群算法在优化问题中的收敛速度取决于初始信息素分布、蚂蚁数量、迭代次数等因素 。
最优解质量
蚁群算法在某些问题上可能找到全局最优解,但在其他问题上可能只能找到近似最优解 。
VS
详细描述
这一步是生成初始解的过程,需要按照设 定的规则,将蚂蚁随机放置在解空间中, 并初始化每条路径上的信息素。
迭代优化
总结词
通过蚂蚁的移动和信息素的更新,不断优化 解的质量。
详细描述
这一步是蚁群算法的核心部分,通过模拟蚂 蚁的移动和信息素的更新机制,不断迭代优 化解的质量,最终找到最优解。
结果
多目标优化问题的蚁群算法
针对多目标优化问题,蚁群算法需要 进行相应的改进。
VS
多目标优化问题要求算法在满足多个 冲突目标的同时找到最优解。这需要 对蚁群算法进行相应的调整,以适应 多目标优化的特性。例如,可以通过 引入权重因子来平衡各个目标之间的 矛盾,或者采用非支配排序方法对解 进行分层处理,以便更好地处理多目 标优化问题。
蚁群算法的优化目标
寻找最短路径
蚁群算法的主要目标是找到起点到终 点之间的最短路径,这在实际应用中 可用于解决如旅行商问题、车辆路径 问题等优化问题。
平衡搜索与探索
蚁群算法需要在搜索和探索之间取得 平衡,以避免陷入局部最优解,提高 算法的全局搜索能力。
03
蚁群算法的实现步骤
问题建模
总结词
将实际问题抽象为蚁群算法能够解决的问题模型。
蚂蚁根据局部信息素浓度选择移动方向,倾向于选择信息素浓度较高的路径。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 蚁群算法简介蚁群算法(Ant Clony Optimization,ACO)是一种群智能算法,它是由一群无智能或有轻微智能的个体(Agent)通过相互协作而表现出智能行为,从而为求解复杂问题提供了一个新的可能性。
蚁群算法最早是由意大利学者Colorni A., Dorigo M. 等于1991年提出。
经过20多年的发展,蚁群算法在理论以及应用研究上已经得到巨大的进步。
蚁群算法是一种仿生学算法,是由自然界中蚂蚁觅食的行为而启发的。
在自然界中,蚂蚁觅食过程中,蚁群总能够按照寻找到一条从蚁巢和食物源的最优路径。
图(1)显示了这样一个觅食的过程。
图(1)蚂蚁觅食在图1(a)中,有一群蚂蚁,假如A是蚁巢,E是食物源(反之亦然)。
这群蚂蚁将沿着蚁巢和食物源之间的直线路径行驶。
假如在A和E之间突然出现了一个障碍物(图1(b)),那么,在B点(或D点)的蚂蚁将要做出决策,到底是向左行驶还是向右行驶?由于一开始路上没有前面蚂蚁留下的信息素(pheromone),蚂蚁朝着两个方向行进的概率是相等的。
但是当有蚂蚁走过时,它将会在它行进的路上释放出信息素,并且这种信息素会议一定的速率散发掉。
信息素是蚂蚁之间交流的工具之一。
它后面的蚂蚁通过路上信息素的浓度,做出决策,往左还是往右。
很明显,沿着短边的的路径上信息素将会越来越浓(图1(c)),从而吸引了越来越多的蚂蚁沿着这条路径行驶。
2. TSP问题描述蚁群算法最早用来求解TSP问题,并且表现出了很大的优越性,因为它分布式特性,鲁棒性强并且容易与其它算法结合,但是同时也存在这收敛速度慢,容易陷入局部最优(local optimal)等缺点。
TSP问题(Travel Salesperson Problem,即旅行商问题或者称为中国邮递员问题),是一种,是一种NP-hard问题,此类问题用一般的算法是很大得到最优解的,所以一般需要借助一些启发式算法求解,例如遗传算法(GA),蚁群算法(ACO),微粒群算法(PSO)等等。
TSP问题可以分为两类,一类是对称TSP问题(Symmetric TSP),另一类是非对称问题(Asymmetric TSP)。
所有的TSP问题都可以用一个图(Graph)来描述:令V={c1, c2, …, c i, …, c n},i = 1,2, …, n,是所有城市的集合. c i表示第i个城市, n为城市的数目;E={(r, s): r,s∈V}是所有城市之间连接的集合;C = {c rs: r,s∈V}是所有城市之间连接的成本度量(一般为城市之间的距离);如果c rs = c sr, 那么该TSP问题为对称的,否则为非对称的。
一个TSP问题可以表达为:求解遍历图G = (V, E, C),所有的节点一次并且回到起始节点,使得连接这些节点的路径成本最低。
3. 蚁群算法原理假如蚁群中所有蚂蚁的数量为m,所有城市之间的信息素用矩阵pheromone表示,最短路径为bestLength,最佳路径为bestTour。
每只蚂蚁都有自己的内存,内存中用一个禁忌表(Tabu)来存储该蚂蚁已经访问过的城市,表示其在以后的搜索中将不能访问这些城市;还有用另外一个允许访问的城市表(Allowed)来存储它还可以访问的城市;另外还用一个矩阵(Delta)来存储它在一个循环(或者迭代)中给所经过的路径释放的信息素;还有另外一些数据,例如一些控制参数(,,,Q),该蚂蚁行走玩全程的总成本或距离(tourLength),等等。
假定算法总共运行MAX_GEN次,运行时间为t。
蚁群算法计算过程如下:(1)初始化设t=0,初始化bestLength为一个非常大的数(正无穷),bestTour为空。
初始化所有的蚂蚁的Delt矩阵所有元素初始化为0,Tabu表清空,Allowed表中加入所有的城市节点。
随机选择它们的起始位置(也可以人工指定)。
在Tabu中加入起始节点,Allowed中去掉该起始节点。
(2)为每只蚂蚁选择下一个节点。
为每只蚂蚁选择下一个节点,该节点只能从Allowed中以某种概率(公式1)搜索到,每搜到一个,就将该节点加入到Tabu中,并且从Allowed中删除该节点。
该过程重复n-1次,直到所有的城市都遍历过一次。
遍历完所有节点后,将起始节点加入到Tabu中。
此时Tabu表元素数量为n+1(n为城市数量),Allowed元素数量为0。
接下来按照(公式2)计算每个蚂蚁的Delta矩阵值。
最后计算最佳路径,比较每个蚂蚁的路径成本,然后和bestLength比较,若它的路径成本比bestLength小,则将该值赋予bestLength,并且将其Tabu赋予BestTour。
(公式1)(公式2)其中表示选择城市j的概率,k表示第k个蚂蚁,表示城市i,j在第t时刻的信息素浓度,表示从城市i到城市j的可见度,,表示城市i,j之间的成本(或距离)。
由此可见越小,越大,也就是从城市i到j的可见性就越大。
表示蚂蚁k在城市i与j之间留下的信息素。
表示蚂蚁k经过一个循环(或迭代)锁经过路径的总成本(或距离),即tourLength. ,,Q均为控制参数。
(3)更新信息素矩阵令t = t + n,按照(公式3)更新信息素矩阵phermone。
(公式3)为t+n时刻城市i与j之间的信息素浓度。
为控制参数,为城市i与j之间信息素经过一个迭代后的增量。
并且有(公式4)其中由公式计算得到。
(4)检查终止条件如果达到最大代数MAX_GEN,算法终止,转到第(5)步;否则,重新初始化所有的蚂蚁的Delt矩阵所有元素初始化为0,Tabu表清空,Allowed表中加入所有的城市节点。
随机选择它们的起始位置(也可以人工指定)。
在Tabu中加入起始节点,Allowed中去掉该起始节点,重复执行(2),(3),(4)步。
(5)输出最优值// AO.cpp : 定义控制台应用程序的入口点。
#pragma once#include <iostream>#include <math.h>#include <time.h>const double ALPHA=1.0; //启发因子,信息素的重要程度const double BETA=2.0; //期望因子,城市间距离的重要程度const double ROU=0.5; //信息素残留参数const int N_ANT_COUNT=34; //蚂蚁数量const int N_IT_COUNT=1000; //迭代次数const int N_CITY_COUNT=51; //城市数量const double DBQ=100.0; //总的信息素const double DB_MAX=10e9; //一个标志数,10的9次方double g_Trial[N_CITY_COUNT][N_CITY_COUNT]; //两两城市间信息素,就是环境信息素double g_Distance[N_CITY_COUNT][N_CITY_COUNT]; //两两城市间距离//eil51.tsp城市坐标数据double x_Ary[N_CITY_COUNT]={37,49,52,20,40,21,17,31,52,51,42,31,5,12,36,52,27,17,13,57,62,42,16,8,7,27,30,43,58,58,37,38,46,61,62,63,32,45,59,5,10,21,5,30,39,32,25,25,48,56,30};double y_Ary[N_CITY_COUNT]={52,49,64,26,30,47,63,62,33,21,41,32,25,42,16,41,23,33,13,58,42,57,57,52,38,68,48,67,48,27,69,46,10,33,63,69,22,35,15,6,17,10,64,15,10,39,32,55,28,37,40};//返回指定范围内的随机整数int rnd(int nLow,int nUpper){return nLow+(nUpper-nLow)*rand()/(RAND_MAX+1);}//返回指定范围内的随机浮点数double rnd(double dbLow,double dbUpper){double dbTemp=rand()/((double)RAND_MAX+1.0);return dbLow+dbTemp*(dbUpper-dbLow);}//返回浮点数四舍五入取整后的浮点数double ROUND(double dbA){return (double)((int)(dbA+0.5));}//定义蚂蚁类class CAnt{public:CAnt(void);~CAnt(void);public:int m_nPath[N_CITY_COUNT]; //蚂蚁走的路径double m_dbPathLength; //蚂蚁走过的路径长度int m_nAllowedCity[N_CITY_COUNT]; //没去过的城市 int m_nCurCityNo; //当前所在城市编号int m_nMovedCityCount; //已经去过的城市数量public:int ChooseNextCity(); //选择下一个城市void Init(); //初始化void Move(); //蚂蚁在城市间移动void Search(); //搜索路径void CalPathLength(); //计算蚂蚁走过的路径长度};//构造函数CAnt::CAnt(void){}//析构函数CAnt::~CAnt(void){}//初始化函数,蚂蚁搜索前调用void CAnt::Init(){for (int i=0;i<N_CITY_COUNT;i++){m_nAllowedCity[i]=1; //设置全部城市为没有去过m_nPath[i]=0; //蚂蚁走的路径全部设置为0}//蚂蚁走过的路径长度设置为0m_dbPathLength=0.0;//随机选择一个出发城市m_nCurCityNo=rnd(0,N_CITY_COUNT);//把出发城市保存入路径数组中m_nPath[0]=m_nCurCityNo;//标识出发城市为已经去过了m_nAllowedCity[m_nCurCityNo]=0;//已经去过的城市数量设置为1m_nMovedCityCount=1;}//选择下一个城市//返回值为城市编号int CAnt::ChooseNextCity(){int nSelectedCity=-1; //返回结果,先暂时把其设置为-1//=================================================================== ===========//计算当前城市和没去过的城市之间的信息素总和double dbTotal=0.0;double prob[N_CITY_COUNT]; //保存各个城市被选中的概率for (int i=0;i<N_CITY_COUNT;i++){if (m_nAllowedCity[i] == 1) //城市没去过{prob[i]=pow(g_Trial[m_nCurCityNo][i],ALPHA)*pow(1.0/g_Distance[m_nCurCityNo][i] ,BETA); //该城市和当前城市间的信息素dbTotal=dbTotal+prob[i]; //累加信息素,得到总和}else //如果城市去过了,则其被选中的概率值为0{prob[i]=0.0;}}//=================================================================== ===========//进行轮盘选择double dbTemp=0.0;if (dbTotal > 0.0) //总的信息素值大于0{dbTemp=rnd(0.0,dbTotal); //取一个随机数for (int i=0;i<N_CITY_COUNT;i++){if (m_nAllowedCity[i] == 1) //城市没去过{dbTemp=dbTemp-prob[i]; //这个操作相当于转动轮盘,如果对轮盘选择不熟悉,仔细考虑一下if (dbTemp < 0.0) //轮盘停止转动,记下城市编号,直接跳出循环{nSelectedCity=i;break;}}}}//=================================================================== ===========//如果城市间的信息素非常小( 小到比double能够表示的最小的数字还要小)//那么由于浮点运算的误差原因,上面计算的概率总和可能为0//会出现经过上述操作,没有城市被选择出来//出现这种情况,就把第一个没去过的城市作为返回结果//题外话:刚开始看的时候,下面这段代码困惑了我很长时间,想不通为何要有这段代码,后来才搞清楚。