习题答案-大数据技术与应用-微课视频版-肖政宏-清华大学出版社
清华大学出版社数据结构(C++版)(第2版)课后习题答案最全整理

清华大学出版社数据结构(C++版)(第2版)课后习题答案最全整理第1 章绪论课后习题讲解1. 填空⑴()是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
【解答】数据元素⑵()是数据的最小单位,()是讨论数据结构时涉及的最小数据单位。
【解答】数据项,数据元素【分析】数据结构指的是数据元素以及数据元素之间的关系。
⑶从逻辑关系上讲,数据结构主要分为()、()、()和()。
【解答】集合,线性结构,树结构,图结构⑷数据的存储结构主要有()和()两种基本方法,不论哪种存储结构,都要存储两方面的内容:()和()。
【解答】顺序存储结构,链接存储结构,数据元素,数据元素之间的关系⑸算法具有五个特性,分别是()、()、()、()、()。
【解答】有零个或多个输入,有一个或多个输出,有穷性,确定性,可行性⑹算法的描述方法通常有()、()、()和()四种,其中,()被称为算法语言。
【解答】自然语言,程序设计语言,流程图,伪代码,伪代码⑺在一般情况下,一个算法的时间复杂度是()的函数。
【解答】问题规模⑻设待处理问题的规模为n,若一个算法的时间复杂度为一个常数,则表示成数量级的形式为(),若为n*log25n,则表示成数量级的形式为()。
【解答】Ο(1),Ο(nlog2n)【分析】用大O记号表示算法的时间复杂度,需要将低次幂去掉,将最高次幂的系数去掉。
2. 选择题⑴顺序存储结构中数据元素之间的逻辑关系是由()表示的,链接存储结构中的数据元素之间的逻辑关系是由()表示的。
A 线性结构B 非线性结构C 存储位置D 指针【解答】C,D【分析】顺序存储结构就是用一维数组存储数据结构中的数据元素,其逻辑关系由存储位置(即元素在数组中的下标)表示;链接存储结构中一个数据元素对应链表中的一个结点,元素之间的逻辑关系由结点中的指针表示。
⑵假设有如下遗产继承规则:丈夫和妻子可以相互继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。
人工智能基础及应用(微课版) 习题及答案 第4章 机器学习

习题一、选择题1 .关于k-近邻算法说法错误的是OA是机器学习B是无监督学习Ck代表分类个数Dk的选择对分类结果没有影响2 .关于k-近邻算法说法错误的是OA一般使用投票法进行分类任务Bk-近邻算法属于懒惰学习C训练时间普遍偏长D距离计算方法不同,效果也可能显著不同3 .关于决策树算法说法错误的是OA受生物进化启发B属于归纳推理C用于分类和预测D自顶向下递推4 .利用信息增益来构造的决策树的算法是OAID3决策树B递归C归约DFIFO5 .决策树构成的顺序是()A特征选择、决策树生成、决策树剪枝B决策树剪枝、特征选择、决策树生成C决策树生成、决策树剪枝、特征选择D特征选择、决策树剪枝、决策树生成6 .朴素贝叶斯分类器属于O假设A样本分布独立B属性条件独立C后验概率已知D先验概率已知7 .支持向量机是指OA对原始数据进行采样得到的采样点B决定分类平面可以平移的范围的数据点C位于分类面上的点D能够被正确分类的数据点8 .关于支持向量机的描述错误的是OA是一种监督学习的方式B可用于多分类问题C支持非线性核函数D是一种生成式模型9 .关于k-均值算法的描述错误的是OA算法开始时,k-means算法时需要指定中心点B算法效果不受初始中心点的影响C算法需要样本与中心点之间的距离D属于无监督学习10 .k-Medoids与k-means聚类最大的区别在于()A中心点的选择规则B距离的计算法方法C应用层面D聚类效果二、简答题1 .k-近邻算的基本思想是什么?2 .决策树的叶结点和非叶结点分别表示什么?3 .朴素贝叶斯分类器为什么是“朴素”的?4 .线性可分支持向量机的基本思想是什么?5 .核技巧是如何使线性支持向量机生成非线性决策边界的?6 .什么是聚类?聚类和分类有什么区别?7 .试举例聚类分析的应用场景,参考答案一、选择题1.D2,C3.A4.A5.D6.B7.C8.D9.B 10.A二、简答题1.请简述k・近邻算法的思想答:给定一个训练样本集合D以及一个需要进行预测的样本X:对于分类问题,k-近邻算法从所有训练样本集合中找到与X最近的k个样本,然后通过投票法选择这k个样本中出现次数最多的类别作为X的预测结果;对于回归问题,k近邻算法同样找到与X最近的k个样本,然后对这k个样本的标签求平均值,得到X的预测结果。
清华大学出版社数据结构(C 版)(第2版)课后习题答案最全整理

第1 章绪论课后习题讲解1. 填空⑴()是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
【解答】数据元素⑵()是数据的最小单位,()是讨论数据结构时涉及的最小数据单位。
【解答】数据项,数据元素【分析】数据结构指的是数据元素以及数据元素之间的关系。
⑶从逻辑关系上讲,数据结构主要分为()、()、()和()。
【解答】集合,线性结构,树结构,图结构⑷数据的存储结构主要有()和()两种基本方法,不论哪种存储结构,都要存储两方面的内容:()和()。
【解答】顺序存储结构,链接存储结构,数据元素,数据元素之间的关系⑸算法具有五个特性,分别是()、()、()、()、()。
【解答】有零个或多个输入,有一个或多个输出,有穷性,确定性,可行性⑹算法的描述方法通常有()、()、()和()四种,其中,()被称为算法语言。
【解答】自然语言,程序设计语言,流程图,伪代码,伪代码⑺在一般情况下,一个算法的时间复杂度是()的函数。
【解答】问题规模⑻设待处理问题的规模为n,若一个算法的时间复杂度为一个常数,则表示成数量级的形式为(),若为n*log25n,则表示成数量级的形式为()。
【解答】Ο(1),Ο(nlog2n)【分析】用大O记号表示算法的时间复杂度,需要将低次幂去掉,将最高次幂的系数去掉。
2. 选择题⑴顺序存储结构中数据元素之间的逻辑关系是由()表示的,链接存储结构中的数据元素之间的逻辑关系是由()表示的。
A 线性结构B 非线性结构C 存储位置D 指针【解答】C,D【分析】顺序存储结构就是用一维数组存储数据结构中的数据元素,其逻辑关系由存储位置(即元素在数组中的下标)表示;链接存储结构中一个数据元素对应链表中的一个结点,元素之间的逻辑关系由结点中的指针表示。
⑵假设有如下遗产继承规则:丈夫和妻子可以相互继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。
则表示该遗产继承关系的最合适的数据结构应该是()。
2024年大数据应用及处理技术能力知识考试题库与答案

2024年大数据应用及处理技术能力知识考试题库与答案一、单选题1.当图像通过信道传输时,噪声一般与()无关。
A、信道传输的质量B、出现的图像信号C、是否有中转信道的过程D、图像在信道前后的处理参考答案:B2.在留出法、交叉验证法和自助法三种评估方法中,()更适用于数据集较小、难以划分训练集和测试集的情况。
A、留出法B、交叉验证法C、自助法D、留一法参考答案:C3.在数据科学中,通常可以采用()方法有效避免数据加工和数据备份的偏见。
A、A/B测试B、训练集和测试集的划分C、测试集和验证集的划分D、图灵测试参考答案:A4.下列不属于深度学习内容的是(_)oA、深度置信网络B、受限玻尔兹曼机C、卷积神经网络D、贝叶斯学习参考答案:D5.在大数据项目中,哪个阶段可能涉及使用数据工程师来优化数据查询性能?A、数据采集B、数据清洗C、数据存储与管理D、数据分析与可视化参考答案:C6.假定你现在训练了一个线性SVM并推断出这个模型出现了欠拟合现象,在下一次训练时,应该采取下列什么措施()A、增加数据点B、减少数据点C、增加特征D、减少特征参考答案:C7.两个变量相关,它们的相关系数r可能为0?这句话是否正确0A、正确B、错误参考答案:A8.一幅数字图像是()。
A、一个观测系统B、一个由许多像素排列而成的实体C、一个2-D数组中的元素D、一个3-D空间中的场景参考答案:C9.以下说法正确的是:()。
一个机器学习模型,如果有较高准确率,总是说明这个分类器是好的如果增加模型复杂度,那么模型的测试错误率总是会降低如果增加模型复杂度,那么模型的训练错误率总是会降低A、1B、2C、3D、land3参考答案:c10.从网络的原理上来看,结构最复杂的神经网络是0。
A、卷积神经网络B、长短时记忆神经网络C、GRUD、BP神经网络参考答案:B11.LSTM中,(_)的作用是确定哪些新的信息留在细胞状态中,并更新细胞状态。
A、输入门B、遗忘门G输出门D、更新门参考答案:A12.Matplotiib的核心是面向()。
大数据技术应用基础知识单选题99道及答案解析

大数据技术应用基础知识单选题99道及答案解析 1. 以下哪个不是大数据的特点?( ) A. 大量化 B. 结构化 C. 快速化 D. 多样化 答案:B。解析:大数据的特点包括大量化(数据量巨大)、快速化(数据产生和处理速度快)、多样化(数据类型多样),而结构化不能完全代表大数据特点,大数据中包含大量非结构化数据。
2. 大数据处理流程一般不包括以下哪个阶段?( ) A. 数据采集 B. 数据销毁 C. 数据存储 D. 数据分析 答案:B。解析:大数据处理流程通常包括数据采集(收集数据)、数据存储(保存数据)、数据分析(对数据进行分析挖掘等),数据销毁不是正常的处理流程阶段。
3. 以下哪种数据存储方式常用于存储非结构化数据?( ) A. 关系型数据库 B. 文档型数据库 C. 层次型数据库 D. 网状型数据库 答案:B。解析:关系型数据库适合存储结构化数据;文档型数据库常用于存储非结构化数据,如文档、图片等;层次型数据库和网状型数据库也是主要用于结构化数据存储。
4. Hadoop的核心组件不包括以下哪个?( ) A. HDFS B. MapReduce C. Spark D. YARN 答案:C。解析:Hadoop的核心组件包括HDFS(分布式文件系统,用于存储数据)、MapReduce(分布式计算框架)、YARN(资源管理系统),Spark是另一个大数据处理框架,不属于Hadoop核心组件。
5. 数据清洗的主要目的是( )。 A. 增加数据量 B. 提高数据质量 C. 改变数据结构 D. 加快数据处理速度 答案:B。解析:数据清洗是对数据进行清理、转换等操作,主要是为了去除噪声、错误数据等,从而提高数据质量;不是为了增加数据量、改变数据结构或者单纯加快处理速度。
6. 以下哪种数据分析方法常用于挖掘数据中的关联规则?( ) A. 分类算法 B. 聚类算法 C. 关联规则挖掘算法 D. 回归分析算法 答案:C。解析:分类算法用于将数据分类到不同类别;聚类算法用于将数据聚合成不同簇;关联规则挖掘算法专门用于挖掘数据中的关联关系;回归分析算法主要用于预测数值型变量。 7. 以下哪个不是数据可视化的工具?( ) A. Excel B. Matplotlib C. Hive D. Tableau 答案:C。解析:Excel可以进行简单的数据可视化;Matplotlib是Python中的数据可视化库;Tableau是专业的数据可视化工具;Hive是数据仓库工具,主要用于数据查询和分析,不是专门的数据可视化工具。
《大数据》试题及答案-1-大数据-李联宁-清华大学出版社

《大数据》题目一、单选题1)大数据的4V特点:Volume、Velocity、Variety、Veracity,其中他们的含义分别是( 1 )、( 2 )、( 3 )、( 4 )。
A.价值密度低B.处理速度快C.数据类型繁多D.数据体量巨大2)大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行( 5 )。
A. 数据信息B. 专业化处理C.速度处理D. 内容处理3)随着谷歌( 6 )和( 7 )的发布,大数据不再仅用来描述大量的数据,还涵盖了处理数据的( 8 )。
6: A.Map B.Docs C. YouTube D. MapReduce7: A. Google Mobile B. iGoogle C. GoogleFile System D. Google Docs8: A.质量 B. 速度 C.精度 D. 进度4)斯隆数字巡天是使用位于新墨西哥州阿帕奇山顶天文台的2.5米口径望远镜进行的红移巡天项目,2012年4月发布的关于Quasar spectra的数据为( 9 )。
A.932,891,133B. 228,468C. 1,457,002D. 668,0545)下列哪一项不属于大数据的治理:( 10 )A. 安全问题B. 成本问题C. 针对大用户D. 信息生命周期管理6)IBM的大数据战略以其在2012年5月发布智慧分析洞察“3A5步”动态路线图作为基础,指的是在( 11 )的基础上( 12 )、,进而( 13 ),优化决策策划能够救业务绩效。
A. 采取行动(Act)B. 获取洞察(Anticipate)C. 掌握信息(Align)D. 应用管理(management)7)在云生态环境中,用户需求相当于( 14 ),云数据中心相当于( 15 ),云服务相当于( 16 )。
A. 降水B. 水滴C. 水库D. 阳光8)尿布啤酒是大数据分析的( 17 )A. A/B测试B. 分类C. 关联规则挖掘D. 数据聚类9)在GAPMINDER的Wealth & Health of Nations 中,中国在什么区域( 18 )A.黄色B.红色C.绿色D. 蓝色10)舆情研判,信息科学侧重( 19 ),社会和管理科学侧重突发群体事件管理中的群体心理行为及( 20 ),新闻传播学侧重对( 21 )。
大数据技术_数据库原理及应用教程(第4版)(微课版)_[共2页]
![大数据技术_数据库原理及应用教程(第4版)(微课版)_[共2页]](https://img.taocdn.com/s3/m/105e93d7bed5b9f3f80f1c1e.png)
1.10.4 大数据技术
1.大数据技术的产生背景 IBM 前首席执行官郭士纳指出,每隔 15 年 IT 领域会迎来一次重大变革。截至到目前,共发生 了三次信息化浪潮。第一次信息化浪潮发生在 1980 年前后,其标志是个人计算机的产生,当时信息 技术所面对的主要问题是实现各类数据的处理。第二次信息化浪潮发生在 1995 年前后,其标志是互 联网的普及,当时信息技术所面对的主要问题是实现数据的互联互通。第三次信息化浪潮发生在 2010 年前后,随着硬件存储成本的持续下降、互联网技术和物联网技术的高速发展,现代社会每天正以 不可想象的速度产生各类数据,如电子商务网站的用户访问日志、微博中评论和转发信息、各类短 视频和微电影、各类商品的物流配送信息、手机通话记录等。这些数据或流入已经运行的数据库系 统,或形成具有结构化的各类文件,或形成具有非结构化特征的视频和图像文件。据统计, Google 每分钟进行 200 万次搜索,全球每分钟发送 2 亿封电子邮件,12306 网站春节期间一天的访问量为 84 亿次。总之,人们已经步入一个以各类数据为中心的全新时代——大数据时代。 从数据库的研究历程看,大数据并非一个全新的概念,它与数据库技术的研究和发展密切相关。 20 世纪 70~80 年代,数据库的研究人员就开始着手超大规模数据库(Very Large Database)的探索 工作,并于 1975 年举行了第一届 VLDB 学术会议,至今该会议仍然是数据库管理领域的顶级学术会 议之一。20 世纪 90 年代后期,随着互联网技术的发展、行业信息化建设和水平不断提高,产生了 海量数据(Massive Data),于是数据库的研究人员开始从数据管理转向数据挖掘技术,尝试在海量 数据上进行有价值数据的提取和预测工作。20 年后,数据库的研究人员发现他们所处理的数据不 仅在数量上呈现爆炸式增长,种类繁多的数据类型也不断挑战原有数据模型的计算能力和存储能 力,因此,学者纷纷使用“大数据”来表达现阶段的数据科研工作,并随之产生了一个新兴领域和 职业——数据科学和数据科学家。 2.大数据的概念 对大数据的概念,尚无明确的定义,但人们普遍采用大数据的 4V 特性来描述大数据,即“数据 量大(Volume)”“数据类型繁多(Variety)”“数据处理速度快(Velocity)”和“数据价值密度低(Value)”。
实验教案-数据库原理及应用(MySQL版)-微课视频版-李月军-清华大学出版社
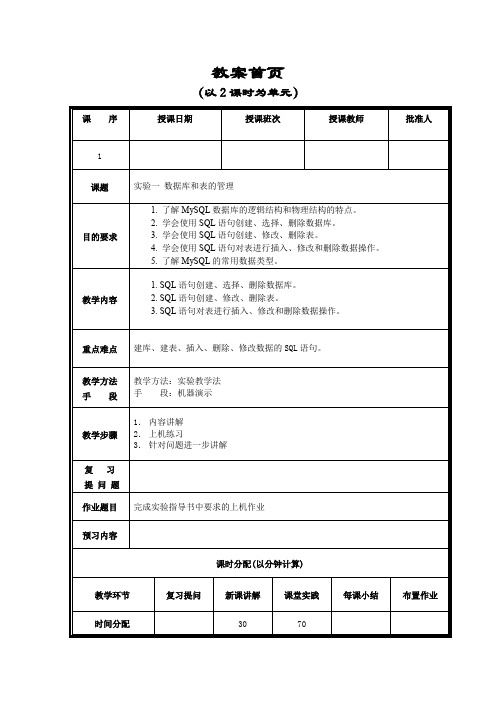
(以2课时为单元)
课 序
授课日期
授课班次
授课教师
批准人
1
课题
实验一数据库和表的管理
目的要求
1.了解MySQL数据库的逻辑结构和物理结构的特点。
2.学会使用SQL语句创建、选择、删除数据库。
3.学会使用SQL语句创建、修改、删除表。
4.学会使用SQL语句对表进行插入、修改和删除数据操作。
5.了解MySQL的常用数据类型。
教案首页
(以2课时为单元)
课 序
授课日期
授课班次
授课教师
批准人
2
课题
实验二数据查询
目的要求
1.掌握使用SQL的SELECT语句进行基本查询的方法。
2.掌握使用SELECT语句进行条件查询的方法。
3.掌握SELECT语句的GROUP BY、ORDER BY以及UNION子句的作用和使用方法。
4.掌握嵌套查询的方法。
SELECT分组、嵌套、连接查询
教学方法
手 段
教学方法:实验教学法
手 段:机器演示
教学步骤
4.内容讲解
5.上机练习
6.针对问题进一步讲解
复 习
提 问 题
作业题目
完成实验指导书中要求的上机作业
预习内容
课时分配(以分钟计算)
教学环节
复习提问
新课讲解
课堂实践
每课小结
布置作业
时间分配
30
70
教学内容
课堂组织
92
0003
0003
81
0003
0004
82
0003
0005
75
5.使用SQL语句ALTER TABLE修改curriculum表的“课程名称”列,使之为空。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题答案:第一章:1. 简述大数据的概念。
答:自2012年以来,“大数据”一词越来越引起人们的关注。
但是,目前为止,在学术研究领域和产业界中,大数据并没有一个标准的定义。
在维克托·迈尔-舍恩伯格编写的《大数据时代》一书中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。
而麦肯锡全球研究所则定义大数据为一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
通常来说,大数据是指数据量超过一定大小,无法用常规的软件在规定的时间范围内进行抓取、管理和处理的数据集合。
2. 简述大数据的基本特征。
答:大数据的主要特征可用“5V+1C”来进行概括,分别是:数据量大(Volume)、数据类型多(Variety)、数据时效性强(Velocity)、价值密度低(Value)、准确性高(Veracity)、复杂性高(Complexity),如下图所示。
图大数据特征图3.简述大数据的分析处理过程。
答:大数据的处理流程基本可划分为数据采集、数据处理与集成、数据分析和数据解释4个阶段。
即经数据源获取的数据,因为其数据结构不同(包括结构、半结构和非结构数据),用特殊方法进行数据处理和集成,将其转变为统一标准的数据格式方便以后对其进行处理;然后用合适的数据分析方法将这些数据进行处理分析,并将分析的结果利用可视化等技术展现给用户,这就是整个大数据处理的流程如下图所示。
图大数据的处理流程详细的分析处理过程参见《大数据技术与应用》第5章第2节4.简述大数据的存储方式。
答:存储系统作为数据中心最核心的数据基础,不再仅是传统分散的、单一的底层设备。
除了要具备高性能、高安全、高可靠等基于大数据应用需求,“应用定义存储”概念被提出。
主要有以下几种存储方式:1、分布式系统2、NoSQL数据库3、云数据库4、大数据存储技术路线1) 采用MPP架构的新型数据库集群2) 基于Hadoop的技术扩展和封装3) 大数据一体机5.简述大数据的商业价值和社会价值。
答:商业价值:1.对顾客群体细分,然后对每个群体量体裁衣般的采取独特的行动。
2. 运用大数据模拟实境,发掘新的需求和提高利润。
3. 提高大数据成果在各相关部门的分享程度,提高企业决策能力。
4. 进行商业模式、产品和服务的创新。
社会价值:1.大数据可以为个人提供个性化的医疗服务。
2.大数据可以提供个性化教育。
在大数据的支持下,教育将呈现另外的特征:弹性学制、个性化辅导、社区和家庭学习。
3.大数据的诞生让社会安全管理更为井然有序。
4.大数据的发展带动了社会上各行各业的发展。
6.以某一行业为例,简述大数据的应用。
答:参见《大数据技术与应用》第1章第4节第二章:1.简述大数据集群系统。
答:集群技术是指通过高速通信网络将一组相互独立的计算机联系在一起,组成一个计算机系统,该系统中每一台计算机都是一个独立的服务器,运行各自的进程,它们相互之间可以通信,既可以看作是一个个单一的系统,也能够协同起来为用户提供服务。
对网络用户来讲,后端就像是一个单一的系统,协同向用户提供系统资源、系统服务,通过网络连接组合成一个组合来共同完一个任务。
Hadoop 分布式集群是为了对海量的非结构化数据进行存储和分析而设计的一种特定的集群。
其本质上是一种计算集群。
详见《大数据技术与应用》第2章第1节2.简述集群系统的分类。
答:集群分为同构与异构两种。
而按功能和结构可以分成以下几类。
(1)高可用性集群。
(2)负载均衡集群。
(3)高性能计算集群。
(4)网格计算。
3.简述Linux操作系统的特性。
答:Linux操作系统是一个多用户,多任务,丰富的网络功能,它不仅有可靠的系统安全,而且良好的可移植性,具有标准的兼容性,良好的用户界面,出色的速度性能,最为重要的是开源,CentOS主要有以下特点:(1)主流:目前的Linux操作系统主要应用于生产环境,企业级主流Linux系统仍旧是RedHat或者CentOS。
(2)免费:RedHat 和CentOS差别不大,基于Red Hat Linux 提供的可自由使用源代码的企业CentOS是一个Linux发行版本。
(3)更新方便:CentOS独有的yum命令支持在线升级,可以即时更新系统,不像RedHat 那样需要花钱购买支持服务。
4.简述计算机虚拟化技术以及常见的虚拟化软件。
答:在计算机中,虚拟化(Virtualization)是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可分割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。
这些资源的新虚拟部分是不受现有资源的架设方式,地域或物理组态所限制。
一般所指的虚拟化资源包括计算能力和资料存储。
常见的虚拟化软件有VirtualBox、VMware Workstation、KVM。
5.简述大数据集群技术的架构。
答:一般来说,大数据集群的构架,主要分为硬件资源层、OS 层、基础设施管理层、文件系统层、大数据集群层和大数据应用层,如下图所示。
图大数据集群的架构详见《大数据技术与应用》第2章第5节6.安装Linux系统并进行网络配置。
答:Linux安装环境:CentOS 7.3, 官网/为了简化操作,使用三台服务器作为集群节点,其中一台为Master节点,两台为Slave节点。
规划集群节点IP。
对集群节点进行网络配置:(1)设置主机名(2)修改/etc/hosts文件(3)修改网络配置(4)重启网络,并查看网络IP地址(5)关闭并停止NetworkManager服务详见《大数据技术与应用》第2章第6节7.部署Linux集群、设置时间同步以及免密钥SSH配置。
答:一、集群规划二、网络配置(1)设置主机名(2)修改/etc/hosts文件(3)修改网络配置(4)重启网络,并查看网络IP地址(5)关闭并停止Network Manager服务三、安全配置(1)安全密码控制(2)设置历史记录、退出自动清空历史记录等(3)设置闲置超时时间(4)设置Selinux(5)设置并停止firewalld服务四、时间同步(1)Master节点时间同步安装设置(2)Slave节点时间同步安装设置(3)设置自动加载并重启chrony服务(4)查看master节点时间同步信息(5)查看slaver节点时间同步信息五、SSH登录(1)安装openssh,开启sshd服务(2)以root用户登录master节点,生成SSH密钥对(3)把含有公用密钥文件信息复制到节点机上(4)使用SSH登录节点机详见《大数据技术与应用》第2章第6节第三章:1.简述Hadoop系统及其优点。
答:Hadoop是一个能够让用户轻松架构和使用的分布式计算平台,它主要有以下几个优点:(1)高可靠性。
(2)高扩展性。
(3)高效性(4)高容错性。
详见《大数据技术与应用》第3章第1节2.简述Hadoop原理及运行机制。
答:Hadoop的核心由3个子项目组成:Hadoop Common、HDFS、和MapReduce。
Hadoop Common包括文件系统(File System)、远程过程调用协议(RPC)和数据串行化库(Serialization Libraries)详见《大数据技术与应用》第3章第1节3.简述Hadoop技术生态系统。
答:Hadoop生态系统主要包括:HDFS、MapReduce、Spark、Storm、HBase、Hive、Pig、ZooKeeper、 Avro 、Sqoop、Ambari、HCatalog、Chukwa 、Flume、Mahout、Phoenix、Tez、Shark等,Hadoop开源技术生态系统如下图所示。
图 Hadoop开源技术生态系统4. 学会JDK的安装和配置。
答:参见《大数据技术与应用》第3章第3节5.掌握Hadoop的安装和配置。
答:参见《大数据技术与应用》第3章第3节第四章1.简述 HDFS的体系架构。
答:Hdfs架构如下图所示:图 HDFS架构2.简述 HDFS读数据的流程。
答:详细流程如下:(1)首先HDFS的客户端通过Distributed FileSystem(HDFS中API里的一个对象);(2)通过Distributed FileSystem发送给NameNode请求,同时将用户信息及文件名的信息等发送给NameNode,并返回给DistributedFileSystem,该文件包含的block所在的DataNode位置;(3)HDFS客户端通过FSDataInputStream按顺序去读取DataNode中的block信息(它会选择负载最低的或离客户端最近的一台DataNode去读block);(4)FSDataInputStream按顺序一个一个的读,直到所有的block都读取完毕;(5)当读取完毕后会将FSDataInputStream关闭。
HDFS读数据的流程可如下图所示:图 HDFS读流程3.简述 HDFS写数据的流程。
答:详细流程如下:(1)首先HDFS的客户端通过Distributed FileSystem(HDFS中API里的一个对象);(2)通过Distributed FileSystem发送客户端的请求给NameNode(NameNode主要是接受客户端请求)并且会带着文件要保存的位置、文件名、操作的用户名等信息一起发送给NameNode;(3)NameNode会给客户端返回了一个FSDataOutputStream,同时也会返回文件要写入哪些DataNode上(负载较低的);(4)通过FSDataOutputStream进行写操作,在写之前就做文件的拆分,将文件拆分成多个Block,第一个写操作写在负载比较低的DataNode上,并将这个block复制到其他的DataNode上;(5)当所有的block副本复制完成后会反馈给FSDataOutputStream;(6)当所有的block副本全都复制完成,就可以将FSDataOutputStream流关闭;(7)通过Distributed FileSystem更新NameNode中的源数据信息。
HDFS写数据的流程可如下图所示:图 Hdfs写流程4.简述 Block副本的存放策略。
答:在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。
详细请参见《大数据技术与应用》4.1.45.编写程序实现对 HDFS文件读写等。
答:请参见《大数据技术与应用》第4章第2节第五章1.简述 MapReduce架构。