经典分布式文件系统全介绍
Hadoop概述

Hadoop概述⼀、Hadoop概述Hadoop实现了⼀个分布式⽂件系统,简称HDFS。
Hadoop在数据提取、变形和加载(ETL)⽅⾯有着天然的优势。
Hadoop的HDFS实现了⽂件的⼤批量存储,Hadoop的MapReduce功能实现了将单个任务打碎,将碎⽚任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库⾥。
Hadoop的ETL可批量操作数据,使处理结果直接⾛向存储。
Hadoop有以下特点:1、⾼可靠性。
因为它假设计算元素和存储会失败,因此它维护多个⼯作数据副本,能够确保针对失败的节点重新分布处理。
2、⾼扩展性。
Hadoop是在可⽤的计算机集簇间分配数据并完成计算任务的,这些集簇可⽅便的扩展到数以千计的节点中。
3、⾼效性。
它以并⾏的⽅式⼯作,能够在节点之间动态移动数据,并保证各个节点动态平衡,因此处理速度⾮常快。
4、⾼容错性。
Hadoop能够⾃动保存数据的多个副本,能够⾃动将失败的任务重新分配。
5、可伸缩性。
Hadoop能够处理PB级数据。
6、低成本。
Hadoop是开源的,项⽬软件成本⼤⼤降低。
Hadoop的组成:1、最底部的是HDFS(Hadoop Distribute File System),它存储Hadoop集群中所有存储节点上的⽂件,是数据存储的主要载体。
它由Namenode和DataNode组成。
2、HDFS的上⼀层是MapReduce引擎,该引擎由JobTrackers和TaskTrackers组成。
它通过MapReduce过程实现了对数据的处理。
3、Yarn实现了任务分配和集群资源管理的任务。
它由ResourceManager、nodeManager和ApplicationMaster组成。
Hadoop由以上三个部分组成,下⾯我们就这三个组成部分详细介绍:1、HDFSHadoop HDFS 的架构是基于⼀组特定的节点构建的,(1)名称节点(NameNode仅⼀个)负责管理⽂件系统名称空间和控制外部客户机的访问。
Hadoop - 介绍

Clint
NameNode
Second NameNode
Namespace backup
Heartbeats,balancing,replication etc
DataNode
Data serving
DataNode
DataNode
DataNode
DataNode
Google 云计算
MapReduce BigTable Chubby
GFS
Hadoop可以做什么?
案例1:我想知道过去100年中每年的最高温 度分别是多少?
这是一个非常典型的代表,该问题里边包含了大量的信息数据。
针对于气象数据来说,全球会有非常多的数据采集点,每个采 集点在24小时中会以不同的频率进行采样,并且以每年持续365 天这样的过程,一直要收集 100年的数据信息。然后在这 100年 的所有数据中,抽取出每年最高的温度值,最终生成结果。该 过程会伴随着大量的数据分析工作,并且会有大量的半结构化 数据作为基础研究对象。如果使用高配大型主机( Unix环境) 计算,完成时间是以几十分钟或小时为单位的数量级,而通过 Hadoop完成,在合理的节点和架构下,只需要“秒”级。
HIVE
ODBC Command Line JDBC Thrift Server Metastore Driver (Compiler,Optimizer,Executor ) Hive 包括
元数据存储(Metastore) 驱动(Driver)
查询编译器(Query Compiler)
1. HDFS(Hadoop分布式文件系统)
HDFS:源自于Google的GFS论文,发表于2003年10月, HDFS是GFS克隆版。是Hadoop体系中数据存储管理的 基础。它是一个高度容错的系统,能检测和应对硬件 故障,用于在低成本的通用硬件上运行。HDFS简化 了文件的一致性模型,通过流式数据访问,提供高吞 吐量应用程序数据访问功能,适合带有大型数据集的 应用程序。 Client:切分文件;访问HDFS;与NameNode交互, 获取文件位置信息;与DataNode交互,读取和写入数 据。 NameNode:Master节点,在hadoop1.X中只有一个, 管理HDFS的名称空间和数据块映射信息,配置副本 策略,处理客户端请求。 DataNode:Slave节点,存储实际的数据,汇报存储信 息给NameNode。 Secondary NameNode:辅助NameNode,分担其工作 量;定期合并fsimage和fsedits,推送给NameNode;紧 急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
分布式存储技术及应用介绍

根据did you know(/)的数据,目前互联网上可访问的信息数量接近1秭= 1百万亿亿 (1024)。
毫无疑问,各个大型网站也都存储着海量的数据,这些海量的数据如何有效存储,是每个大型网站的架构师必须要解决的问题。
分布式存储技术就是为了解决这个问题而发展起来的技术,下面让将会详细介绍这个技术及应用。
分布式存储概念与目前常见的集中式存储技术不同,分布式存储技术并不是将数据存储在某个或多个特定的节点上,而是通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。
具体技术及应用:海量的数据按照结构化程度来分,可以大致分为结构化数据,非结构化数据,半结构化数据。
本文接下来将会分别介绍这三种数据如何分布式存储。
结构化数据的存储及应用所谓结构化数据是一种用户定义的数据类型,它包含了一系列的属性,每一个属性都有一个数据类型,存储在关系数据库里,可以用二维表结构来表达实现的数据。
大多数系统都有大量的结构化数据,一般存储在Oracle或MySQL的等的关系型数据库中,当系统规模大到单一节点的数据库无法支撑时,一般有两种方法:垂直扩展与水平扩展。
∙垂直扩展:垂直扩展比较好理解,简单来说就是按照功能切分数据库,将不同功能的数据,存储在不同的数据库中,这样一个大数据库就被切分成多个小数据库,从而达到了数据库的扩展。
一个架构设计良好的应用系统,其总体功能一般肯定是由很多个松耦合的功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一张或多张表。
各个功能模块之间交互越少,越统一,系统的耦合度越低,这样的系统就越容易实现垂直切分。
∙水平扩展:简单来说,可以将数据的水平切分理解为按照数据行来切分,就是将表中的某些行切分到一个数据库中,而另外的某些行又切分到其他的数据库中。
为了能够比较容易地判断各行数据切分到了哪个数据库中,切分总是需要按照某种特定的规则来进行的,如按照某个数字字段的范围,某个时间类型字段的范围,或者某个字段的hash值。
分布式文件系统MFS(moosefs)实现存储共享
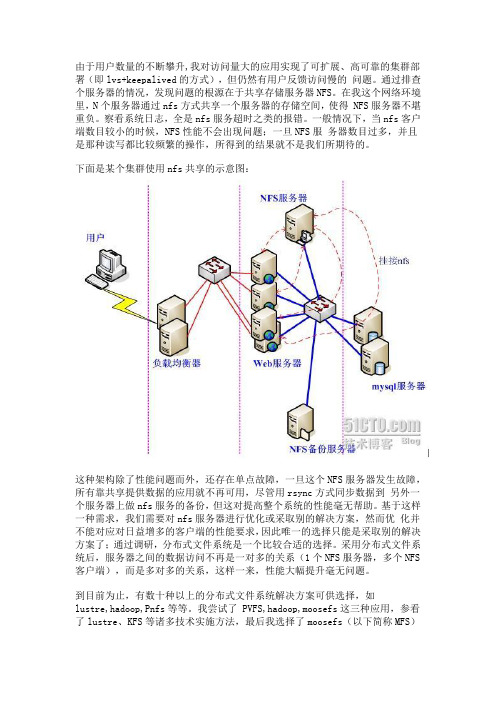
由于用户数量的不断攀升,我对访问量大的应用实现了可扩展、高可靠的集群部署(即lvs+keepalived的方式),但仍然有用户反馈访问慢的问题。
通过排查个服务器的情况,发现问题的根源在于共享存储服务器NFS。
在我这个网络环境里,N个服务器通过nfs方式共享一个服务器的存储空间,使得 NFS服务器不堪重负。
察看系统日志,全是nfs服务超时之类的报错。
一般情况下,当nfs客户端数目较小的时候,NFS性能不会出现问题;一旦NFS服务器数目过多,并且是那种读写都比较频繁的操作,所得到的结果就不是我们所期待的。
下面是某个集群使用nfs共享的示意图:这种架构除了性能问题而外,还存在单点故障,一旦这个NFS服务器发生故障,所有靠共享提供数据的应用就不再可用,尽管用rsync方式同步数据到另外一个服务器上做nfs服务的备份,但这对提高整个系统的性能毫无帮助。
基于这样一种需求,我们需要对nfs服务器进行优化或采取别的解决方案,然而优化并不能对应对日益增多的客户端的性能要求,因此唯一的选择只能是采取别的解决方案了;通过调研,分布式文件系统是一个比较合适的选择。
采用分布式文件系统后,服务器之间的数据访问不再是一对多的关系(1个NFS服务器,多个NFS 客户端),而是多对多的关系,这样一来,性能大幅提升毫无问题。
到目前为止,有数十种以上的分布式文件系统解决方案可供选择,如lustre,hadoop,Pnfs等等。
我尝试了 PVFS,hadoop,moosefs这三种应用,参看了lustre、KFS等诸多技术实施方法,最后我选择了moosefs(以下简称MFS)这种分布式文件系统来作为我的共享存储服务器。
为什么要选它呢?我来说说我的一些看法:1、实施起来简单。
MFS的安装、部署、配置相对于其他几种工具来说,要简单和容易得多。
看看lustre 700多页的pdf文档,让人头昏吧。
2、不停服务扩容。
MFS框架做好后,随时增加服务器扩充容量;扩充和减少容量皆不会影响现有的服务。
ofs的分类 -回复

ofs的分类-回复ofs是一种用于存储和处理大规模数据的技术,其提供了高可靠性、高可扩展性和高性能的数据管理能力。
现在,让我们一步一步来回答"ofs 的分类"这个主题。
第一步:什么是ofs?在开始讨论ofs的分类之前,先来了解一下ofs的基本概念。
ofs,全称为Object File System,是一种基于对象存储的分布式文件系统,旨在存储海量数据并提供高性能、高可靠性和高扩展性的数据管理能力。
与传统的文件系统不同,ofs将数据以对象的形式组织和存储,每个对象都有唯一的标识符,并可以通过该标识符进行快速访问。
ofs还提供了多种数据访问接口和数据保护机制,以满足不同应用场景的需求。
第二步:ofs的分类基于不同的特性和应用场景,ofs可以被分为以下几类:1. 分布式文件系统(Distributed File System)分布式文件系统是ofs的最基本形式,用于将数据分布式地存储在多个节点(通常是服务器)上。
每个节点都有一定的存储容量,并负责存储和管理一部分数据。
分布式文件系统通过将数据切分成多个块(chunks)并在不同节点之间进行复制来实现数据的高可靠性和高可用性。
常见的分布式文件系统包括Hadoop HDFS、Google File System(GFS)和Ceph等。
2. 对象存储(Object Storage)对象存储是ofs的一种进化形式,其将数据以对象的形式存储在分布式的存储集群中。
每个对象都有唯一的全局标识符(通常是一个URL),可以通过该标识符来进行访问和操作。
对象存储不同于传统的文件系统,不再依赖文件层次结构,而是将数据和元数据(包括文件名、文件类型、时间戳等)封装成一个完整的对象。
对象存储的优势在于其高度可扩展性、高效的数据访问速度和灵活的数据管理能力。
常见的对象存储系统包括Amazon S3、OpenStack Swift和Alibaba Cloud OSS等。
分布式文件系统在局域网中的应用

接下来就要输 入域 名了 ,域名 为 :xkd . m. jt e do
如图 1 。
个 副本 的服务器失 效 ,或 者管理员需要对 一 台服
务 器进行 脱 机维 护 ,那 么通 过使用 D S F ,用 户仍然 可 以不 问断地持续访问副本服务器 。
一
、
使用DF 的前期准备工作 S
1 .9 9j n6 — 9( 4)2 1 .20 2 03 6 /. .5 1 8 g c 1 0 00 .1
在我 们 日常工作 中 ,各部 门之 间经常需 要相互 调 阅文 件 ,例如在 “ 中央 电大人才 培养模式 改革和 开放教育 试点”项 目评 估 阶段 及 目前 我校参 与的全
21 0 0年第 2 期
NO 2 2 O . . 0l
技 术不但 可 以有 效地解决单 服务器 的性 能限制 ,而
( )确 定 域 名 三
且 可 以实 现故 障的快速转移 ,保证服 务的可用性 及
灵 活 的扩展 性 。D S 以用来把 用 户的访 问量分 配 F可 到多个含有 文件 副本 的服务 器 中。除此 之外 ,如果
了变化 。
共享 文件夹集合 到一个 逻辑名 字空 间中 ,并 以树形
目录的形式展现在用户 面前 。从用户 角度看 ,所 有
共享 文件仅存储在一个 地点 ,通过访 问一个共享 的 D S 目录 ,就能够访 问分 布在 网络 上 的共享 文件 F根 或 文件夹 ,而不必知道 这些文 件 的实 际物理位置 。 用户仅 仅需要记住一个 固定 的访 问地址 ,就可实现
DS F )是Widw 00Sre及 以上版本提供 的一项 n o s 0 evr 2
文件 服务功能 。它可以把局域 网 中不 同服务器 中的
非结构化数据存储解决方案

非结构化数据存储解决方案一、引言非结构化数据是指那些没有明确定义的数据,无法按照传统的关系型数据库模型进行存储和管理的数据。
随着大数据时代的到来,非结构化数据的规模和重要性不断增加,因此寻觅一种高效的非结构化数据存储解决方案变得尤其关键。
本文将介绍一种基于分布式文件系统和NoSQL数据库的非结构化数据存储解决方案。
二、分布式文件系统分布式文件系统是一种将文件存储在多个节点上的系统,具有高可用性、可扩展性和容错性等特点。
在非结构化数据存储解决方案中,分布式文件系统可以用来存储非结构化数据的原始文件,提供高效的读写性能和可靠的数据存储。
1. 文件存储分布式文件系统将非结构化数据的原始文件分割成多个块,并将这些块分布在不同的节点上进行存储。
这种方式可以提高数据的读写性能,同时也能够实现数据的冗余备份,提高数据的可靠性。
2. 数据索引为了方便对非结构化数据进行检索和查询,分布式文件系统需要建立相应的索引机制。
索引可以根据数据的特征和属性进行构建,以提高数据的访问效率。
常见的索引方式包括倒排索引、B树索引等。
三、NoSQL数据库NoSQL数据库是一种非关系型数据库,适合于存储和管理非结构化数据。
与传统的关系型数据库相比,NoSQL数据库具有高可扩展性、高性能和灵便的数据模型等特点,非常适合存储非结构化数据。
1. 数据模型NoSQL数据库支持多种数据模型,包括键值对、文档型、列族型和图形型等。
根据非结构化数据的特点和需求,可以选择合适的数据模型来存储和管理数据。
2. 数据查询NoSQL数据库提供了灵便的数据查询和检索方式,可以根据数据的特征和属性进行高效的查询。
同时,NoSQL数据库还支持分布式计算和并行查询,提高数据的处理性能。
四、非结构化数据存储解决方案的架构设计基于分布式文件系统和NoSQL数据库的非结构化数据存储解决方案的架构设计如下:1. 数据采集首先,需要对非结构化数据进行采集。
采集可以通过爬虫、日志采集等方式进行,将数据保存为原始文件。
大数据存储解决方案

大数据存储解决方案大数据存储解决方案引言随着信息技术的迅猛发展和互联网的普及,大数据已经成为当今社会最重要的资源之一。
然而,随着数据量的迅速增长,如何高效地存储和管理大数据成为了一个亟待解决的问题。
本文将介绍一些常用的大数据存储解决方案,包括分布式文件系统、NoSQL数据库和数据仓库。
分布式文件系统分布式文件系统是一种将大数据分散存储在多个节点上的文件系统。
它通过将大文件切割成多个小文件,并将这些小文件存储在不同的节点上,以实现数据的分布式存储和高并发访问。
其中,Hadoop分布式文件系统(HDFS)是目前应用最广泛的分布式文件系统之一。
HDFS采用了主从结构,其中有一个NameNode负责管理文件系统的元数据,而多个DataNode负责存储实际的数据。
HDFS具有高容错性和可扩展性,可以方便地处理超大规模的数据集。
此外,HDFS还提供了数据自动备份和恢复的功能,保证数据的安全性和可靠性。
NoSQL数据库传统的关系型数据库在处理大数据时面临着很多限制,如扩展性不足、读写性能不高等问题。
为了解决这些问题,产生了NoSQL(Not Only SQL)数据库。
NoSQL数据库可以存储非结构化和半结构化数据,具有高可扩展性和高性能。
在NoSQL数据库中,有几种适用于大数据存储的解决方案。
其中,列存储数据库是一种将数据按列存储的数据库。
这种存储方式可以大幅度提高查询性能,特别适合于数据分析和数据挖掘等场景。
另外,文档数据库是一种以文档为单位存储数据的数据库。
它支持复杂的数据结构,适用于存储半结构化数据。
此外,键值数据库和图数据库也是常用的NoSQL数据库解决方案。
数据仓库数据仓库是一个用于存储和管理企业数据的系统。
它采用了特定的数据模型和架构,用于支持复杂的查询和分析操作。
数据仓库通常采用多维数据模型,可以很方便地进行数据切片和切块操作。
数据仓库的存储技术发展至今已非常成熟,常用的存储方式包括关系型数据库、列存储数据库和分布式文件系统等。