SPSS操作和实例
SPSS数据生成与数据清洗实例教程

SPSS数据生成与数据清洗实例教程Chapter 1: 引言数据生成和数据清洗是数据分析的前提,对于SPSS软件的使用者来说,掌握数据生成和数据清洗方法是非常重要的。
本章节将介绍SPSS软件的基本功能和使用方法。
1.1 SPSS简介SPSS(Statistical Package for the Social Sciences)是一款用于统计分析的软件,广泛应用于社会科学、商业、医学等领域。
SPSS提供了丰富的数据处理和分析功能,可以进行数据的输入、编辑、清洗、变换、分析等操作。
1.2 数据生成和数据清洗的意义数据生成是指根据某种规则或者设定,生成符合具体需求的样本数据。
数据清洗则是在数据生成之后,对数据进行筛选、剔除异常值、修正错误等操作,以确保数据的质量和可靠性。
数据生成和数据清洗是数据处理的前置工作,对于后续的数据分析和建模都起到至关重要的作用。
Chapter 2: 数据生成方法本章节将介绍几种常见的数据生成方法,包括随机生成、序列生成和复制生成。
2.1 随机生成数据SPSS提供了随机生成数据的功能,可以按照设定的规则生成随机的整数、小数或字符型数据。
在SPSS的"变量视图"中,可以设置变量的名称、类型、宽度和标签等属性,然后通过插入数据命令生成随机数据。
2.2 序列生成数据序列生成是指按照一定规则生成连续的数据,通常用于生成时间序列数据或者观察变量的变化趋势。
SPSS提供了序列生成的函数,可以通过指定起始值、终止值和步长等参数来生成序列数据。
2.3 复制生成数据复制生成是指根据已有的数据复制生成新的数据,通常用于扩充数据集的规模。
SPSS可以通过数据缩放和重复数据命令实现复制生成数据的功能。
Chapter 3: 数据清洗方法本章节将介绍几种常见的数据清洗方法,包括缺失值处理、异常值检测和数据修正等。
3.1 缺失值处理缺失值是指数据中的某些变量或观测值缺乏有效的数值。
缺失值会影响数据的分析结果,因此需要进行缺失值处理。
SPSS聚类分析加具体案例
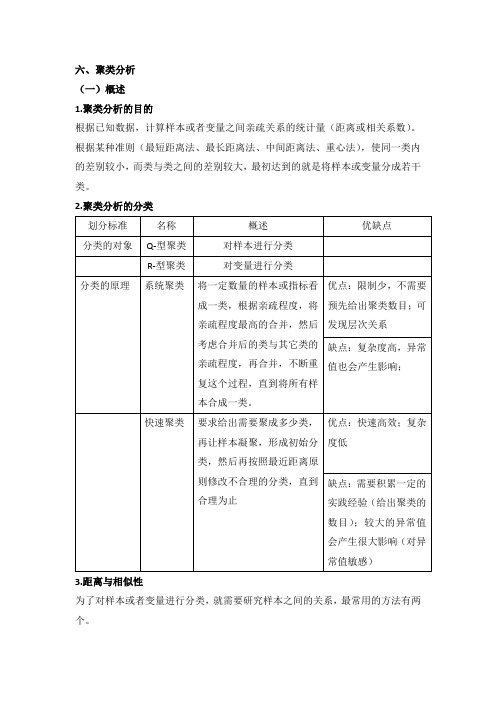
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。
SPSS教程-聚类分析-附实例操作

各地区各行业工资水平的分析(2009年数据)小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍1.研究背景及意义1.1 研究背景工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。
生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。
1.2 研究意义1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。
2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。
2.数据来源与描述2.1 数据来源——《中国劳动统计年鉴─2010》(URL:/Navi/YearBook.aspx?id=N2011010069&floor=1###)主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司出版社:中国统计出版社简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。
本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。
本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。
2.2 数据描述本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-03.分析方法及原理3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。
在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。
SPSS中多元回归分析实例解析

SPSS中多元回归分析实例解析多元回归分析是一种统计方法,用于研究一个因变量与多个自变量之间的关系。
在SPSS中,可以使用该方法来构建、估计和解释多元回归模型。
下面将以一个实例来解析SPSS中的多元回归分析。
假设我们想要研究一个教育投资项目的效果,该项目包括多个自变量,例如教育资金、教育设施、学生人数等,并且我们希望预测该项目对学生学习成绩的影响。
首先,我们需要准备好数据并导入SPSS中。
数据应包含每个教育投资项目的多个观测值,以及与之相关的自变量和因变量。
例如,可以将每个项目作为一个观测值,并将教育资金、教育设施、学生人数等作为自变量,学生学习成绩作为因变量。
在SPSS中,可以通过选择“Analyze”菜单中的“Regression”选项来打开回归分析对话框。
然后,选择“Linear”选项来进行多元回归分析。
接下来,可以将自变量和因变量添加到对话框中。
在自变量列表中,选择教育资金、教育设施、学生人数等自变量,并将它们移动到“Independent(s)”框中。
在因变量框中,选择学生学习成绩。
然后,点击“OK”按钮开始进行分析。
SPSS将输出多元回归的结果。
关键的统计指标包括回归系数、显著性水平和拟合度。
回归系数表示每个自变量对因变量的影响程度,可以根据系数的大小和正负来判断影响的方向。
显著性水平表示自变量对因变量的影响是否显著,一般以p值小于0.05为标准。
拟合度指示了回归模型对数据的拟合程度,常用的指标有R方和调整后的R方。
在多元回归分析中,可以通过检查回归系数的符号和显著性水平来判断自变量对因变量的影响。
如果回归系数为正且显著,表示该自变量对因变量有正向影响;如果回归系数为负且显著,表示该自变量对因变量有负向影响。
此外,还可以使用其他方法来进一步解释和验证回归模型,例如残差分析、模型诊断等。
需要注意的是,在进行多元回归分析时,需要满足一些前提条件,例如自变量之间应该独立、与因变量之间应该是线性关系等。
SPSS统计分析—差异分析

点击“确定”,运值等统计量,判断两组 数据是否存在显著性差异
撰写结论:根据P值判断结果, 解释两组数据之间的差异是否 具有统计学意义
05
SPSS差异分析的实例
单因素方差分析实例
目的:比较不同 组别的数据差异
步骤:选择数据→ 定义变量→选择分 析方法→设置参数 →分析结果
选择控制变量:考虑可能影响结果的其他因 素
确定样本量:根据研究目的和预期结果确定 合适的样本量
检查数据质量:确保数据完整、准确、可靠
选择合适的差异分析方法:根据研究目的和 变量类型选择合适的差异分析方法
设置差异分析选项
在弹出的窗口中,选择“独立样 本t检验”或“配对样本t检验”
选择“分析”菜单,点击“比 较平均值”选项
SPSS操作:在SPSS中输入数据,选择双因素方差分析, 得到结果
结果解读:分析不同产品类型和不同销售渠道对销售额 的影响程度和显著性水平
结论:根据分析结果,提出改进建议和策略
T检验实例
目的:比较两组数据的平均值是否存在显著性差
01 异
单击此处输入你的项正文,文字是您思想的提炼,请
尽量言简意赅的阐述观点
大数据环境下的SPSS差异分析: 利用大数据技术提高分析效率和 准确性
SPSS差异分析与人工智能技术的结 合:利用人工智能技术进行自动分 析和预测,提高分析效果和效率
添加标题
添加标题
添加标题
添加标题
云计算环境下的SPSS差异分析: 利用云计算技术实现分布式计算 和存储,提高分析速度和灵活性
SPSS差异分析在跨学科研究中的应用: 与其他领域的研究相结合,拓展SPSS 差异分析的应用范围和深度
b. 样本量的大小
c. 假设检验的设置
spss方差分析理论概念及实际操作分析

实例操作
采用“*******”数据,分析不同身份的旅游者对“政 府及相关部门的政策充分地照顾到遗产地资源开发各 利益群体的实际情况”的认同是否存在显著性差异。 D1政府及相关部门的政策充分地照顾到遗产地资源开 发各利益群体的实际情况 1不同意 2稍微不同意 3中立 4稍微同意 5同意 您的身份: A. 一般居民(旅游者) B. 学生 C. 专家、学者 D. NGO E. 媒体工作者
多因素方差分析适用案例
• 不同年龄、职业的旅游者对旅游形式的选择是否 存在显著性差异?即,年龄与职业队旅游者选择 旅游形式是否存在显著影响? • 不同教育背景、地区的旅游者对成都市内旅游满 意度是否存在显著性差异?
多因素方差分析 分析步骤
1. 提出原假设 H0:各控制变量不同水平下观测变量总体的均值 无显著性差异,控制变量各效应和交互作用效应 同时为0,即控制变量和它们的交互作用没有对观 测变量产生显著性影响
方差齐次性检验
上表为方差齐性检验表,Levene值为1.480,自由度分别为4 和612,显著性水平P值=0.207 > 0.05,可以认为不同身份的游客 对“政府及相关部门的政策充分地照顾到遗产地资源开发各利益 群体的实际情况”的认同程度具有方差齐性,即各种身份的游客 样本所在总体方差相同。
单因素方差分析结果
SPSS简明教程(X2检验和T检验)
SPSS简明教程(X2检验和T检验)SPSS最适⽤的统计学⽅法(X2检验和T检验)1.SPSS的启动(1)在windows[开始]→[程序]→[spss20],进⼊SPSS for Windows对话框,2.创建⼀个数据⽂件三个步骤:(1)选择菜单【⽂件】→【新建】→【数据】新建⼀个数据⽂件。
(2)单击左下⾓【变量视窗】标签进⼊变量视图界⾯,定义每个变量类型。
(3)单击【数据视窗】标签进⼊数据视窗界⾯,录⼊数据库单元格内。
3.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【⽂件】→【打开】→【数据】的顺序使⽤菜单命令调出打开数据对话框,在⽂件类型下拉列表中选择数据⽂件,如图所⽰。
图 Open File对话框(2)选择要打开的Excel⽂件,单击“打开”按钮,调出打开Excel数据源对话框,如图所⽰。
对话框中各选项的意义如下:⼯作表下拉列表:选择被读取数据所在的Excel⼯作表。
范围输⼊框:⽤于限制被读取数据在Excel⼯作表中的位置。
图 Open Excel Data Source对话框4.数据编辑在SPSS中,对数据进⾏基本编辑操作的功能集中在Edit和Data菜单中。
5.SPSS数据的保存SPSS数据录⼊并编辑整理完成以后应及时保存,以防数据丢失。
保存数据⽂件可以通过【⽂件】→【保存】或者【⽂件】→【另存为】菜单⽅式来执⾏。
在数据保存对话框(如图所⽰)中根据不同要求进⾏SPSS数据保存。
图 SPSS数据的保存5. 数据分析在SPSS中,数据整理的功能主要集中在【数据】和【分析】两个主菜单下6.语⾔切换:编辑(E)—选项(N)--⽤户界⾯-语⾔--简体中⽂第六章:描述性统计分析(X2检验)完成计数资料和等级资料的统计描述和⼀般的统计检验,我们常⽤的X2检验也在其中完成。
6.1.1界⾯说明界⾯如下所⽰:分析—描述统计—频率⽤于定义需要计算的其他描述统计量。
现将各部分解释如下:Percentile Values复选框组定义需要输出的百分位数,可计算1.四分位数(Quartiles)、2.每隔指定百分位输出当前百分位数(Cut points for equal groups)3.直接指定某个百分位数(Percentiles),如直接和o Central tendency复选框组⽤于定义描述集中趋势的⼀组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)。
SPSS多元回归分析实例教程
多元回归分析 在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量xj(j=1,2,3,…,n)之间的多元线性回归模型:
其中:b0是回归常数;bk(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1 x1 x2 x3 x4 y 年 蛾量 级别 卵量 级别 降水量 级别 雨日 级别 幼虫密度 级别 1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3 1976 115 1 240 2 0.6 1 2 1 7 1 1971 718 3 1460 4 18.4 4 4 2 45 4 1972 803 3 630 4 13.4 3 3 2 26 3 1973 572 2 280 2 13.2 2 4 2 16 2 1974 264 1 330 3 42.2 4 3 2 19 2 1975 198 1 165 2 71.8 4 5 3 23 3 1976 461 2 140 1 7.5 1 5 3 28 3 1977 769 3 640 4 44.7 4 3 2 44 4 1978 255 1 65 1 0 1 0 1 11 2 数据保存在“DATA6-5.SAV”文件中。 1)准备分析数据 在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后的数据显示如图2-1。
SPSS实例操作之配对t检验
豚鼠 用药 用药 号前后
1 30 46 2 38 50 3 48 52 4 48 52 5 60 58
6 46 64 7 26 56 8 58 54 9 46 54 10 48 58 11 44 36 12 46 54
.1
数据格式 定义变量
pair variable1 variable2
52.83
N Deviation
12
9.815
12
6.952
Mean 2.833
2.007
Paired Samples Test
Paired Differences
Sig. (2t df tailed)
95%
Confidence
Std.
Std. Error
Interval of the Difference
分析过程1数据格式2先计算配对的差值3对差值进行正态性检验pairttest5结果描述原始数据豚鼠号用药前用药后30463850485248526058466426565854465410485811443612465411数据格式定义变量输入数据pairvariable1variable2豚鼠号用药前用药后x1x212先计算配对的差值transformcompute13对差值进行正态性检验输出结果
Mean Deviation Mean Lower Upper
Pair 用 -8.000 10.445 3.015 -14.636 -1.364 -2.653 11 .022
1药
前-
用
药
后
软件给出的P为双尾(2-tailed),若进行单侧t检 验,p值应该为输出值的1/2。
.5பைடு நூலகம்结果描述
SPSS如何进行线性回归分析操作 精品
SPSS如何进行线性回归分析操作本节内容主要介绍如何确定并建立线性回归方程。
包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。
为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。
也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。
另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。
一、一元线性回归分析用SPSS进行回归分析,实例操作如下:1.单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。
从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。
在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。
所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。
具体如下图所示:2.请单击Statistics…按钮,可以选择需要输出的一些统计量。
如RegressionCoefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。
Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。
上述两项为默认选项,请注意保持选中。
设置如图7-10所示。
设置完成后点击Continue返回主对话框。
回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。
由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。
3.用户在进行回归分析时,还可以选择是否输出方程常数。