用SPSS20进行二因素设计的简单效应分析

用SPSS20进行二因素设计的简单效应分析
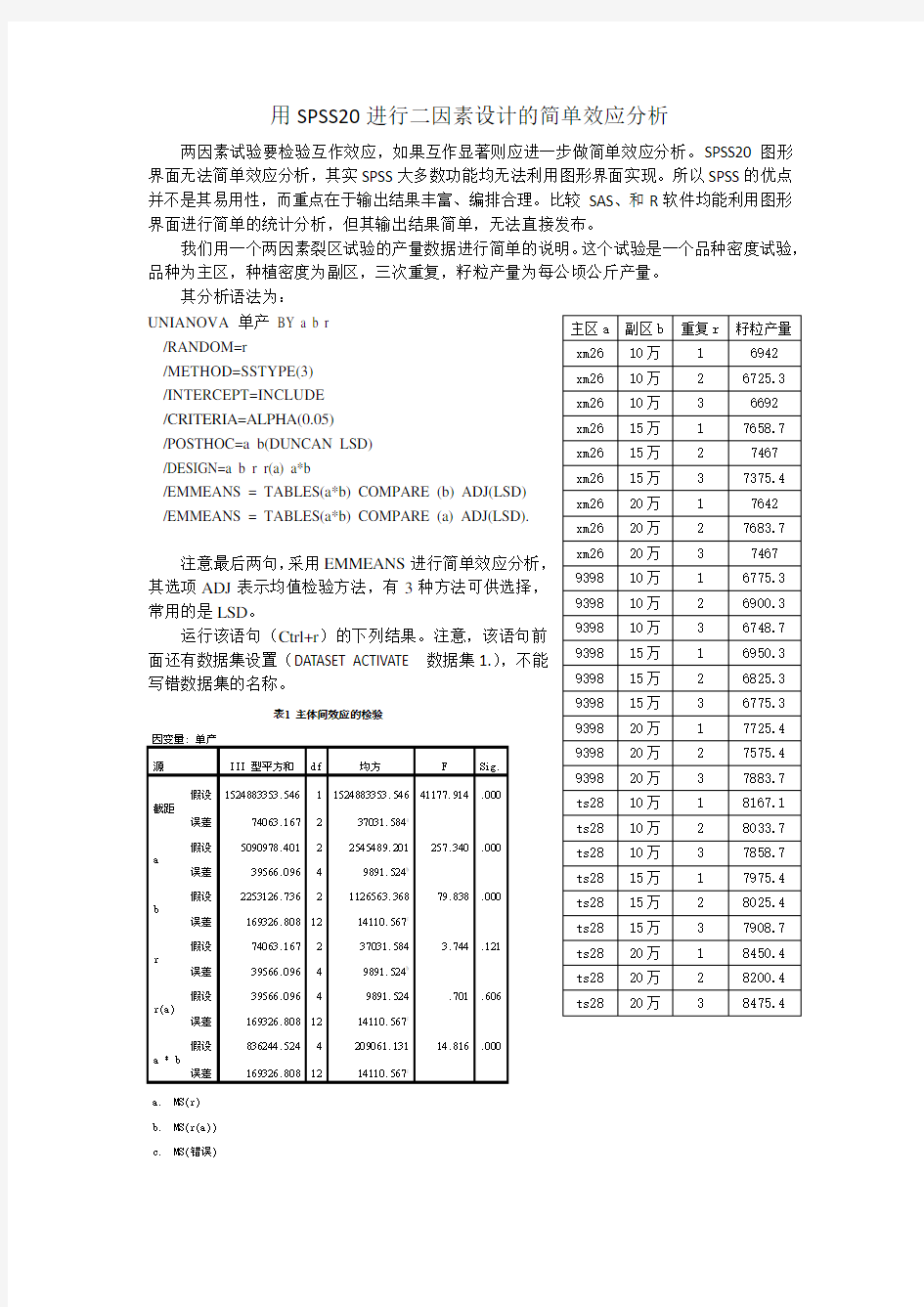
两因素试验要检验互作效应,如果互作显著则应进一步做简单效应分析。SPSS20图形
界面无法简单效应分析,其实SPSS大多数功能均无法利用图形界面实现。所以SPSS的优点
并不是其易用性,而重点在于输出结果丰富、编排合理。比较SAS、和R软件均能利用图形
界面进行简单的统计分析,但其输出结果简单,无法直接发布。
我们用一个两因素裂区试验的产量数据进行简单的说明。这个试验是一个品种密度试验,
品种为主区,种植密度为副区,三次重复,籽粒产量为每公顷公斤产量。
其分析语法为:
UNIANOVA 单产BY a b r Array /RANDOM=r
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/CRITERIA=ALPHA(0.05)
/POSTHOC=a b(DUNCAN LSD)
/DESIGN=a b r r(a) a*b
/EMMEANS = TABLES(a*b) COMPARE (b) ADJ(LSD)
/EMMEANS = TABLES(a*b) COMPARE (a) ADJ(LSD).
注意最后两句,采用EMMEANS进行简单效应分析,
其选项ADJ表示均值检验方法,有3种方法可供选择,
常用的是LSD。
运行该语句(Ctrl+r)的下列结果。注意,该语句前
面还有数据集设置(DATASET ACTIVATE 数据集1.),不能
写错数据集的名称。
表1显示互作显著,因此有必要进行简单效应分析。表2、3为主效应间的多重比较。
表4为三个品种在不同密度下产量均值及差异显著性,表5为三种密度下不同品种的差异。表4、5就是我们要进行的简单效应分析。
表4 成对比较
因变量: 单产
品种(I) 密度(J) 密度均值差值 (I-J) 标准误差Sig.b差分的 95% 置信区间b
下限上限
9398 10万
15万-42.224 96.990 .671 -253.547 169.099
20万-920.046*96.990 .000 -1131.369 -708.723 15万
10万42.224 96.990 .671 -169.099 253.547
20万-877.822*96.990 .000 -1089.145
-666.499 20万
10万920.046*96.990 .000 708.723 1131.369
15万877.822*96.990 .000 666.499 1089.145
ts28 10万
15万50.002 96.990 .616 -161.320 261.325
20万-355.573*96.990 .003 -566.896 -144.250 15万
10万-50.002 96.990 .616 -261.325 161.320
20万-405.576*96.990 .001 -616.899 -194.253 20万
10万355.573*96.990 .003 144.250 566.896
15万405.576*96.990 .001 194.253 616.899
xm26 10万
15万-713.925*96.990 .000 -925.247 -502.602
20万-811.152*96.990 .000 -1022.475 -599.829 15万
10万713.925*96.990 .000 502.602 925.247
20万-97.227 96.990 .336 -308.550 114.096 20万10万811.152*96.990 .000 599.829 1022.475
表5 成对比较
因变量: 单产
密度(I) 品种(J) 品种均值差值 (I-J) 标准误差Sig.b差分的 95% 置信区间b
下限上限
10万9398
ts28 -1211.727*96.990 .000 -1423.050 -1000.404
xm26 21.668 96.990 .827 -189.655 232.991 ts28
9398 1211.727*96.990 .000 1000.404 1423.050
xm26 1233.395*96.990 .000 1022.072 1444.718 xm26
9398 -21.668 96.990 .827 -232.991 189.655
ts28 -1233.395*96.990 .000 -1444.718 -1022.072
15万9398
ts28 -1119.500*96.990 .000 -1330.823 -908.178
xm26 -650.033*96.990 .000 -861.355 -438.710 ts28
9398 1119.500*96.990 .000 908.178 1330.823
xm26 469.468*96.990 .000 258.145 680.791 xm26
9398 650.033*96.990 .000 438.710 861.355
ts28 -469.468*96.990 .000 -680.791 -258.145
20万9398
ts28 -647.255*96.990 .000 -858.577 -435.932
xm26 130.562 96.990 .203 -80.761 341.885 ts28
9398 647.255*96.990 .000 435.932 858.577
xm26 777.817*96.990 .000 566.494 989.140 xm26
9398 -130.562 96.990 .203 -341.885 80.761
ts28 -777.817*96.990 .000 -989.140 -566.494
基于估算边际均值
*. 均值差值在 0.05 级别上较显著。
b. 对多个比较的调整:最不显著差别(相当于未作调整)。
三因素混合方差分析事后简单效应多重比较语法
概念笔记 Main effect 一个因素的独立效应,即其不同水平引起的方差变异。三因素的实验有三个主效应。把某一因素的一个水平同该因素的其他水平比较,不考虑其他因素。 Interaction 多个因素的联合效应,A因素的作用受到B因素的影响,即有交互——two-way interaction. 当一因素作用受到另外两个因素影响,即三因素交互three-way interaction. 重复测量一个因素的三因素混合设计3*2*2的混合设计 A3*B2*R2 【A, B为被试间因素】 需要分析的有—— A, B, R 各自主效应 二重交互作用,A*B, A*R, B*R 三重交互作用,A*B*C 结果发现, A, B为被试间因素,交互作用SIG 当二重交互作用SIG,需要进行simple effect检验。A因素水平在B因素某一水平上的变异。A在B1水平上的简单效应 A在B2水平上的简单效应 B在A1水平上的简单效应 B在A2水平上的简单效应 B在A3水平上的简单效应 如果三重交互作用SIG,需要进行三因素的简单简单效应分析simple simple effect. 某一因素的水平在另外两个因素的水平结合上的效应 在A1B1水平结合上,R1 与R2 差异 在A1B2水平结合上,R1 与R2 差异 在A2B1水平结合上,R1 与R2 差异 在A2B2水平结合上,R1 与R2 差异 在A3B1水平结合上,R1 与R2 差异 在A3B2水平结合上,R1 与R2 差异
重复测量方差分析之后,如果三重交互作用显著,需要编辑语法, 得出三个因素各自的简单效应 某一因素在其他两个因素的某一实验条件内的简单效应检验 三因素重复测量方差分析对应的会有3种简单效应检验结果 SPSS在输出简单效应检验结果的同时,也会报告多重比较结果,会有更直观的对比结果。 如果三重交互作用SIG,需要进行简单简单效应检验。 固定某两个因素水平组合,考察研究者最感兴趣的那个变量的效应。 MANOV A R1 R2 BY A(1,3) B(1,2) /WSFACTORS=R(2) /PRINT=CELLINFO(MEANS) /WSDESIGN /DESIGN /WSDESIGN=R /DESIGN=MWITHIN B(1) WITHIN A(1) MWITHIN B(2) WITHIN A(1) MWITHIN B(1) WITHIN A(2) MWITHIN B(2) WITHIN A(2) MWITHIN B(1) WITHIN A(3) MWITHIN B(2) WITHIN A(3) 上述语法内容是检验被试内变量R在被试间变量A, B 上的简单简单效应。 如果想检验某一被试间变量A在被试内变量R和另一个被试间变量B上的简单简单效应MANOV A R1 R2 BY A(1,3) B(1,2) /WSFACTORS=R(2) /PRINT=CELLINFO(MEANS) /WSDESIGN /DESIGN /WSDESIGN=MWITHIN C(1) MWITHIN C(2) /DESIGN=A WITHIN B(1) A WITHIN B(2)
spss的数据分析案例精选文档
s p s s的数据分析案例 精选文档 TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
SPSS重复测量的多因素方差分析报告
1、概述 重复测量数据的方差分析是对同一因变量进行重复测量的一种试验设计技术。在给予一种或多种处理后,分别在不同的时间点上通过重复测量同一个受试对象获得的指标的观察值,或者是通过重复测量同一个个体的不同部位(或组织)获得的指标的观察值。重复测量数据在科学研究中十分常见。 分析前要对重复测量数据之间是否存在相关性进行球形检验。如果该检验结果为P﹥0.05,则说明重复测量数据之间不存在相关性,测量数据符合Huynh-Feldt条件,可以用单因素方差分析的方法来处理;如果检验结果P﹤0.05,则说明重复测量数据之间是存在相关性的,所以不能用单因素方差分析的方法处理数据。在科研实际中的重复测量设计资料后者较多,应该使用重复测量设计的方差分析模型。 球形条件不满足时常有两种方法可供选择:(1)采用MANOVA(多变量方差分析方法);(2)对重复测量ANOVA检验结果中与时间有关的F值的自由度进行调整。 2、问题 新生儿胎粪吸入综合征(MAS)是由于胎儿在子宫内或着生产时吸入了混有胎粪的羊水,从而导致呼吸道和肺泡发生机械性阻塞,并伴有肺泡表面活性物质失活,而且肺组织也会发生化学性炎症,胎儿出生后出现的以呼吸窘迫为主,同时伴有其他脏器受损现象的一组综合征。血管内皮生长因子(vascular endothelial growth factor,VEGF)是一种有丝分裂原,它特异作用于血管内皮细胞时,能够调节血管内皮细胞的增殖和迁移,从而使血管通透性增加。而本实验旨在通过观察分析给予外源性肺表面活性物质治疗前后胎粪吸入综合征患儿血清中VEGF的含量变化,评价药物治疗的效果。 将收治的诊断胎粪吸入综合症的新生儿共42名。将患儿随机分为肺表面活性物质治疗组(PS组)和常规治疗组(对照组),每组各21例。PS组和对照组两组所有患儿均给予除用药外的其他相应的对症治疗。PS组患儿给予牛肺表面活性剂PS 70mg/kg治疗。采集PS 组及对照组患儿0小时,治疗后24小时和72小时静脉血2ml,离心并提取上清液后保存备用并记录血清中VEGF的含量变化情况。 结果如下: 3、统计分析
spss的数据分析案例
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够 了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Tot 474 100.0 100.0 al 上表及其 直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教
用SPSS20进行二因素设计的简单效应分析
用SPSS20进行二因素设计的简单效应分析 两因素试验要检验互作效应,如果互作显著则应进一步做简单效应分析。SPSS20图形 界面无法简单效应分析,其实SPSS大多数功能均无法利用图形界面实现。所以SPSS的优点 并不是其易用性,而重点在于输出结果丰富、编排合理。比较SAS、和R软件均能利用图形 界面进行简单的统计分析,但其输出结果简单,无法直接发布。 我们用一个两因素裂区试验的产量数据进行简单的说明。这个试验是一个品种密度试验, 品种为主区,种植密度为副区,三次重复,籽粒产量为每公顷公斤产量。 其分析语法为: UNIANOVA 单产BY a b r Array /RANDOM=r /METHOD=SSTYPE(3) /INTERCEPT=INCLUDE /CRITERIA=ALPHA(0.05) /POSTHOC=a b(DUNCAN LSD) /DESIGN=a b r r(a) a*b /EMMEANS = TABLES(a*b) COMPARE (b) ADJ(LSD) /EMMEANS = TABLES(a*b) COMPARE (a) ADJ(LSD). 注意最后两句,采用EMMEANS进行简单效应分析, 其选项ADJ表示均值检验方法,有3种方法可供选择, 常用的是LSD。 运行该语句(Ctrl+r)的下列结果。注意,该语句前 面还有数据集设置(DATASET ACTIVATE 数据集1.),不能 写错数据集的名称。
表1显示互作显著,因此有必要进行简单效应分析。表2、3为主效应间的多重比较。 表4为三个品种在不同密度下产量均值及差异显著性,表5为三种密度下不同品种的差异。表4、5就是我们要进行的简单效应分析。 表4 成对比较 因变量: 单产 品种(I) 密度(J) 密度均值差值 (I-J) 标准误差Sig.b差分的 95% 置信区间b 下限上限 9398 10万 15万-42.224 96.990 .671 -253.547 169.099 20万-920.046*96.990 .000 -1131.369 -708.723 15万 10万42.224 96.990 .671 -169.099 253.547 20万-877.822*96.990 .000 -1089.145 -666.499 20万 10万920.046*96.990 .000 708.723 1131.369 15万877.822*96.990 .000 666.499 1089.145 ts28 10万 15万50.002 96.990 .616 -161.320 261.325 20万-355.573*96.990 .003 -566.896 -144.250 15万 10万-50.002 96.990 .616 -261.325 161.320 20万-405.576*96.990 .001 -616.899 -194.253 20万 10万355.573*96.990 .003 144.250 566.896 15万405.576*96.990 .001 194.253 616.899 xm26 10万 15万-713.925*96.990 .000 -925.247 -502.602 20万-811.152*96.990 .000 -1022.475 -599.829 15万 10万713.925*96.990 .000 502.602 925.247 20万-97.227 96.990 .336 -308.550 114.096 20万10万811.152*96.990 .000 599.829 1022.475
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 第一,将EXCEL中的原始数据导入到SPSS软件中; 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。 所的结论: 标准化后的所有指标数据。 注意: SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。 factor过程对数据进行因子分析(指标之间的相关性判定略)。 【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框; 【3】设置“抽取”,勾选“碎石图”复选框; 【4】设置“旋转”,勾选“最大方差法”复选框; 【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框; 【6】查看分析结果。 所做工作: a.查看KMO和Bartlett 的检验 KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析; Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。 所的结论: 符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。 注意: 1.KMO(Kaiser-Meyer-Olkin) KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。 Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般; 0.6表示不太适合;0.5以下表示极不适合。 2.Bartlett 球度检验: 巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。 Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。 所做工作: b. 全部解释方差或者解释的总方差(Total Variance Explained)
SPSS大数据案例分析实施报告
SPSS数据案例分析 目录 _Toc438655006 一.手机APP 广告点击意愿的模型构建 (2) 1.1构建研究模型 (2) 1.2研究变量及定义 (2) 1.3研究假设 (2) 1.4变量操作化定义 (2) 1.5问卷设计 (2) 二.实证研究 (2) 2.1基础数据分析 (2) 2.2频数分布及相关统计量 (2) 2.3相关分析 (2) 2.4回归分析 (2) 2.5假设检验 (2)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显著影响
SPSS概览--数据分析实例详解
第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下:
1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、
简单效应
简单效应(simple effect)分析通常是在作方差分析时存在交互效应的情况下的进一步分析。你需要在SPSS 中编写syntax实现 一、完全随机因素实验中简单效应得分析程序 假如一个两因素随机实验中,A因素有两个水平、B因素有三个水平,因变量是Y,检验B因素在A因素的两个水平上的简单效应分析。 TWO-FACTOR RANDOMIZED EXPERIMENT SIMPLE EFFECTS DATA LIST FREE /A B Y. BEGIN DATA 1 3 4 1 1 2 1 1 3 2 2 5 2 1 6 1 2 8 2 1 9 1 2 8 2 3 10 2 3 11 2 3 9 2 3 8 END DATA. MANOVA y BY A(1,2) B(1,3) /DESIGN /DESIGN=A WITHIN B(1) A WITHIN B(2) A WITHIN B(3). 若A与B存在交互作用而进行的进一步分析(即简单效应分析)。同时你可以再加一个design: /DESIGN=B WITHIN A(1) B WITHIN A(2). 另外,三因素完全随机实验中的简单效应和简单简单效应的分析。 当实验设计中的因素多于两个时,做简单效应检验的前提仍然是,方差分析中发现了显著的两次交互作用。而当三因素完全随机实验中发现了显著的三次交互作用时,可以进一步作简单简单效应检验。也是DESIGN。 /DESIGN=A WITHIN B(1)WITHIN C(1) A WITHIN B(2)WITHIN C(2). 例如: THREE-FACTOR RANDOMIZED EXPERIMENT SIMPLE EFFECTS. SIMPLE SIMPLE EFFECTS. DATA LIST FREE /A B C Y. BEGIN DATA
【精品管理学】spss因子分析案例 共(13页)
[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
图 ???对话框(图框。 图 钮返回 图11.3?描述性指标选择对话框 ???点击Extraction...钮,弹出FactorAnalysis:Extraction对话框(图11.4),系统提供如下因子提取方法: 图11.4?因子提取方法选择对话框 ???Principalcomponents:主成分分析法;
???Unweightedleastsquares:未加权最小平方法; ???Generalizedleastsquares:综合最小平方法; ???Maximumlikelihood:极大似然估计法; ???Principalaxisfactoring:主轴因子法; ???Alphafactoring:α因子法; ???对话框。 ???5种因图 ???旋转的目的是为了获得简单结构,以帮助我们解释因子。本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。 ???点击Scores...钮,弹出弹出FactorAnalysis:Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。
图11.6?估计因子分方法对话框? ?11.2.3?结果解释 ??在输出结果窗口中将看到如下统计数据: ??系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。 好。今KMO值 NumberofCases?=?????25 CorrelationMatrix: X1???????X2???????X3???????X4???????X5???????X6???????X7 X1????????1.00000 X2?????????.58026??1.00000
多因素方差分析
多因素方差分析 多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因 [例子] 研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著 表5-7 不同温度与不同湿度粘虫发育历期表 数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。
1)准备分析数据 在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。 图5-6 数据输入格式 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因素方差分析设置窗口如图5-7。
图5-7 多因素方差分析窗口 3)设置分析变量 设置因变量:在左边变量列表中选“历期”,用向右拉按钮选入到“Dependent Variable:”框中。 设置因素变量:在左边变量列表中选“a”和“b”变量,用向右拉按钮移到“Fixed Factor(s):”框中。可以选择多个因素变量存容量的限制,选择的因素水平组合数(单元数)应该尽量少。 设置随机因素变量:在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量 设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到“Covariate(s)”框中。 设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。 4)选择分析模型 在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。 图5-8 “Univariate Model” 定义分析模型对话框
SPSS多因素方差分析
体育统计与SPSS读书笔记(八)—多因素方差分析(1) 具有两个或两个以上因素的方差分析称为多因素方差分析。 多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。 下面用例子的形式来说说多因素方差分析的运用。还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级和不同教学法班级双因素。 分析: 1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据), 年级 不同教学方法的班级 定性班 定量班 定性定量班 五年级 页脚内容1
(班级每个人) (班级每个人) (班级每个人) 初中二年级 (班级每个人) (班级每个人) (班级每个人) 高中二年级 (班级每个人) (班级每个人) (班级每个人) 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里假设他们之间有交互作用。 页脚内容2
简单效应分析语法
3*3*4被试内反复测量的简单效应分析语法: GLM a1b1c1ACC a1b1c2ACC a1b1c3ACC a1b1c4ACC a1b2c1ACC a1b2c2ACC a1b2c3ACC a1b2c4ACC a1b3c1ACC a1b3c2ACC a1b3c3ACC a1b3c4ACC a2b1c1ACC a2b1c2ACC a2b1c3ACC a2b1c4ACC a2b2c1ACC a2b2c2ACC a2b2c3ACC a2b2c4ACC a2b3c1ACC a2b3c2ACC a2b3c3ACC a2b3c4ACC a3b1c1ACC a3b1c2ACC a3b1c3ACC a3b1c4ACC a3b2c1ACC a3b2c2ACC a3b2c3ACC a3b2c4ACC a3b3c1ACC a3b3c2ACC a3b3c3ACC a3b3c4ACC /WSFACTOR=ISI 3 Polynomial 情绪类型3 Polynomial 缺少部位4 Polynomial /METHOD =SSTYPE(3) /EMMEANS=TABLES(ISI*缺少部位) COMPARE(ISI) ADJ(LSD) /PLOT=PROFILE(ISI*缺少部位) /EMMEANS=TABLES(情绪类型*缺少部位) COMPARE(情绪类型) ADJ(LSD) /PLOT=PROFILE(情绪类型*缺少部位) /PRINT = DESCRIPTIVE /CRITERIA=ALPHA(.05) /WSDESIGN=ISI 情绪类型缺少部位ISI*情绪类型ISI*缺少部位情绪类型*缺少部位ISI*情绪类型*缺少部位.
27多因素试验结果的统计分析讲解
小题教学计划
2.7 多因素试验结果统计分析 一、两因素随机区组试验结果的统计分析 设试验有A 、B 两个因素,A 因素有a 个水平,B 因素有b 个水平,则试验有a ×b 个处理组合,重复r 次,随机区组试验设计,则试验有abr 个观察值。 例题:有A 1、A 2、A 3三个苹果新品种,氮肥用量有4个水平B 1(不施氮)、B 2(低氮)、B 3(中氮)、B 4(高氮)的品种和氮肥用量的二因素试验,共12个处理,采用随机区组试验设计,重复4次,其小区产量列于下表。 表1 苹果新品种和氮肥用量试验区组与处理两项表 11A 1B 2 43 44 42 129 43.00 A 1B 3 46 47 44 137 45.67 A 1B 4 43 42 46 131 43.67 A 2B 1 36 36 38 110 36.67 A 2B 2 48 44 42 134 44.67 A 2B 3 44 49 49 142 47.33 A 2B 4 46 41 40 127 42.33 A 3B 1 30 34 38 102 34.00 A 3B 2 40 42 50 132 44.00 A 3B 3 64 52 60 176 58.67 A 3B 4 44 44 36 124 41.33 T r 524 516 524 T=1564 43.44 1、资料整理 将试验结果资料整理成表1,计算出各区组总和T r ,各处理总和T t 及平均数 t x 。然后再整理成表2。 表2 品种(A )和施氮量(B )两向表
2、平方和与自由度的分解 C=kn T 2=4 3315642??67947.11 SS T =C x -∑2 =402+412+…+362=1500.89 SS r =C ab T r -∑2=435245165242 22?++-C=3.56 SS t ==++=-∑3 1241291202 222C r T t 1219.56 SS e =SS T -SS r -SS t =1500.89-3.56—1219.56=277.77 对SS t =1219.56进行分解 =C C rb T A -?++=-∑4 35345135172 222=20.72 SS B =C C ra T B -?+++=-∑3 33824553953322 2222=852.67 SS A ×B = SS t - SS A -SS B =1219.56-20.72-852.67=346.17 将以上结果填如下表中。 3、F 测验 列方差分析表,进行F 测验 表3 苹果品种与施氮量二因素试验的方差分析 变异来源 DF SS S 2 F F 0.05 F 0.01 区组间 2 3.56 1.78 <1 处理间 11 1219.56 110.87 8.78** 3.26 3.18 品 种 2 20.72 10.36 <1 3.44 5.72 施氮量 3 852.67 284.22 22.50** 3.00 4.82 品种×施氮量 6 346.17 57.70 4.57** 2.55 3.75 误 差 22 277.77 12.63 总变异 35 1500.89 F 测验结果表明:区组间、品种间差异不显著,而处理间、施氮量间、品种×施氮量间的差异极显著。由此说明:不同的施氮量对苹果产量影响不同,而不同苹果品种对施氮量有不同要求,需作氮肥用量间及品种×施氮量间的多重比较。 4、多重比较 (1)施氮量之间的比较 以各小区平均数进行最小显著极差法(LSR )测验
简单效应SPSS编程
被试内、被试间、混合实验设计简单效应分析 简单效应(simple effect)分析 简单效应(simple effect)分析通常是在作方差分析时存在交互效应的情况下的进一步分析。你需要在SPSS中编写syntax实现。 一、完全随机因素实验中简单效应得分析程序 假如一个两因素随机实验中,A因素有两个水平、B因素有三个水平,因变量是Y,检验B因素在A因素的两个水平上的简单效应分析。 TWO-FACTOR RANDOMIZED EXPERIMENT SIMPLE EFFECTS. DATA LIST FREE /A B Y. BEGIN DATA 1 3 4 1 1 2 1 1 3 2 2 5 2 1 6 1 2 8 2 1 9 1 2 8 2 3 10 2 3 11 2 3 9
2 3 8 END DATA. MANOVA y BY A(1,2) B(1,3) /DESIGN /DESIGN=A WITHIN B(1) A WITHIN B(2) A WITHIN B(3). 若A与B存在交互作用而进行的进一步分析(即简单效应分析)。同时你可以再加一个design: /DESIGN=B WITHIN A(1) B WITHIN A(2). 自编数据试试 y A B 4.00 1.00 3.00 2.00 1.00 1.00 3.00 1.00 1.00 5.00 2.00 2.00 6.00 2.00 1.00 8.00 1.00 2.00 9.00 2.00 1.00 8.00 1.00 2.00 10.00 2.00 3.00 11.00 2.00 3.00
SPSS相关分析案例讲解
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 第九章两因素及多因素方差分析 9.1双菊饮具有很好的治疗上呼吸道感染的功效,为便于饮用,制成泡袋剂。研究不同浸泡时间和不同的浸泡温度对浸泡效果的影响,设计了一个两因素交叉分组实验,实验结果(浸出率)见下表[52]: 浸泡温度 /℃ 浸泡时间/min 101520 6023.7225.4223.58 8024.8428.3229.55 9530.6431.5832.21 对以上结果做方差分析及Duncan检验。该设计已经能充分说明问题了吗?是否还有更能说明问题的设计方案? 答:无重复二因素方差分析程序及结果如下: options linesize=76 nodate; data hermed; do temp=1 to 3; do time=1 to 3; input effect @@; output; end; end; cards; 23.72 25.42 23.58 24.84 28.32 29.55 30.64 31.58 32.21 ; run; proc anova; class temp time; model effect=temp time; means temp time/duncan alpha=0.05; run; The SAS System Analysis of Variance Procedure Class Level Information Class Levels Values TEMP 3 1 2 3 TIME 3 1 2 3 Number of observations in data set = 9 The SAS System Analysis of Variance Procedure Dependent Variable: EFFECT Sum of Mean Source DF Squares Square F Value Pr > F 被试、被试间、混合实验设计简单效应分析 简单效应(simple effect)分析 简单效应(simple effect)分析通常是在作方差分析时存在交互效应的情况下的进一步分析。你需要在SPSS中编写syntax实现。 一、完全随机因素实验中简单效应得分析程序 假如一个两因素随机实验中,A因素有两个水平、B因素有三个水平,因变量是Y,检验B因素在A因素的两个水平上的简单效应分析。 TWO-FACTOR RANDOMIZED EXPERIMENT SIMPLE EFFECTS. DATA LIST FREE /A B Y. BEGIN DATA 1 3 4 1 1 2 1 1 3 2 2 5 2 1 6 1 2 8 2 1 9 1 2 8 2 3 10 2 3 11 2 3 9 2 3 8 END DATA. MANOVA y BY A(1,2) B(1,3) /DESIGN /DESIGN=A WITHIN B(1) A WITHIN B(2) A WITHIN B(3). 若A与B存在交互作用而进行的进一步分析(即简单效应分析)。同时你可以再加一个design: /DESIGN=B WITHIN A(1) B WITHIN A(2). 自编数据试试 y A B 4.00 1.00 3.00 2.00 1.00 1.00 3.00 1.00 1.00 5.00 2.00 2.00 6.00 2.00 1.00 8.00 1.00 2.00 9.00 2.00 1.00 8.00 1.00 2.00 10.00 2.00 3.00 11.00 2.00 3.00 9.00 2.00 3.00 8.00 1.00 2.00 当然,你可也直接贴下述语句至syntax编辑框: 应会输出下述结果: The default error term in MANOVA has been changed from WITHIN CELLS to WITHIN+RESIDUAL. Note that these are the same for all full factorial designs. * * * * * * A n a l y s i s o f V a r i a n c e * * * * * * 12 cases accepted. 0 cases rejected because of out-of-range factor values. 0 cases rejected because of missing data. 6 non-empty cells. 3 designs will be processed.两因素及多因素方差分析
简单效应SPSS编程