多元统计分析上机作业

多远统计上机作业
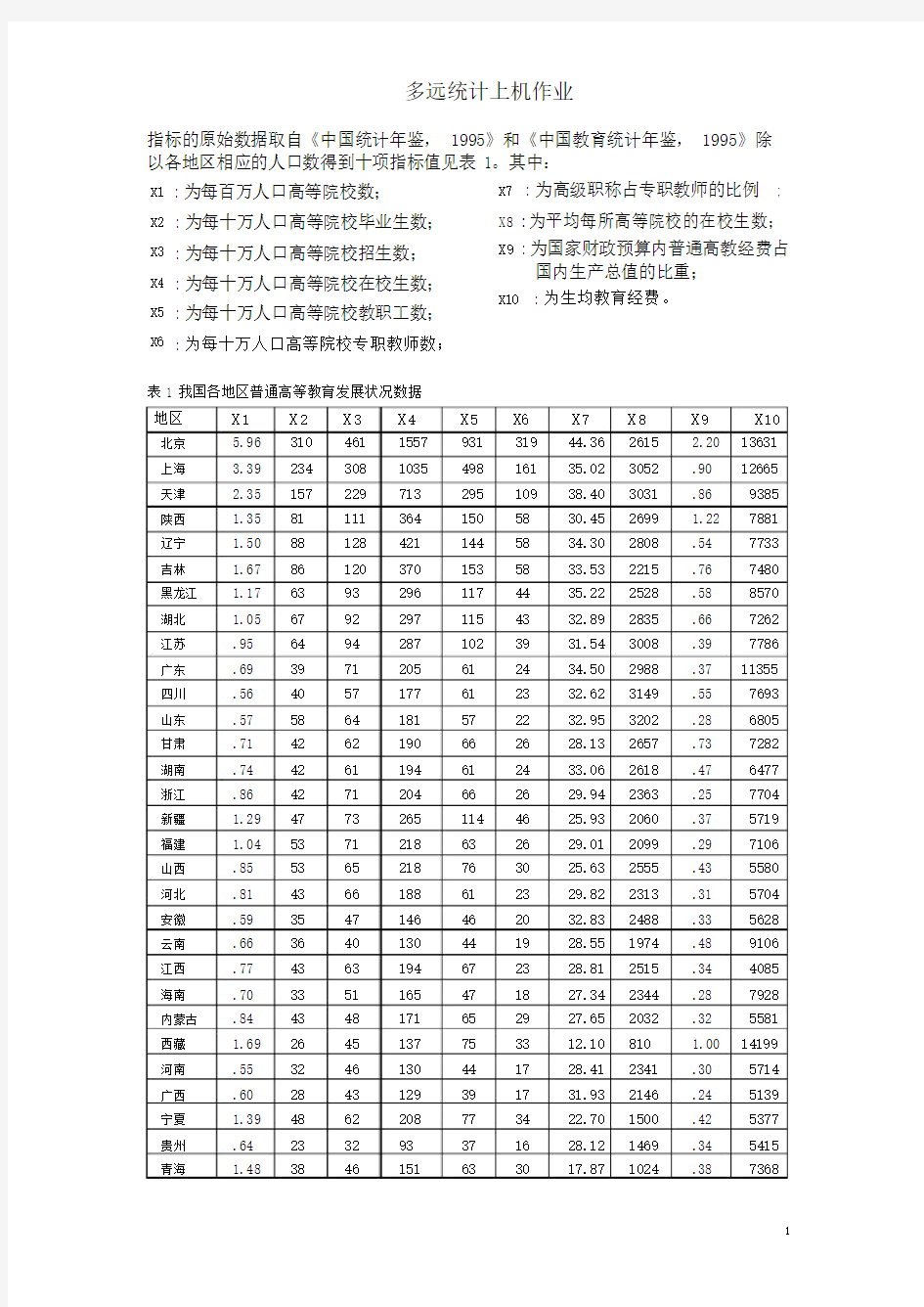
指标的原始数据取自《中国统计年鉴, 1995》和《中国教育统计年鉴, 1995》除以各地区相应的人口数得到十项指标值见表 1。其中:
X1 X2 X3 X4 X5 X6:为每百万人口高等院校数;
:为每十万人口高等院校毕业生数;
:为每十万人口高等院校招生数;
:为每十万人口高等院校在校生数;
:为每十万人口高等院校教职工数;
:为每十万人口高等院校专职教师数;
X7: 为高级职称占专职教师的比例;
X8 :为平均每所高等院校的在校生数;
X9 :为国家财政预算内普通高教经费占
国内生产总值的比重;
X10: 为生均教育经费。
表 1 我国各地区普通高等教育发展状况数据
地区X1X2X3X4X5X6X7X8X9X10北京 5.96310461155793131944.362615 2.2013631上海 3.39234308103549816135.023052.9012665天津 2.3515722971329510938.403031.869385陕西 1.35811113641505830.452699 1.227881辽宁 1.50881284211445834.302808.547733吉林 1.67861203701535833.532215.767480黑龙江 1.1763932961174435.222528.588570湖北 1.0567922971154332.892835.667262江苏.9564942871023931.543008.397786广东.693971205612434.502988.3711355四川.564057177612332.623149.557693山东.575864181572232.953202.286805甘肃.714262190662628.132657.737282湖南.744261194612433.062618.476477浙江.864271204662629.942363.257704新疆 1.2947732651144625.932060.375719福建 1.045371218632629.012099.297106山西.855365218763025.632555.435580河北.814366188612329.822313.315704安徽.593547146462032.832488.335628云南.663640130441928.551974.489106江西.774363194672328.812515.344085海南.703351165471827.342344.287928内蒙古.844348171652927.652032.325581西藏 1.692645137753312.10810 1.0014199河南.553246130441728.412341.305714广西.602843129391731.932146.245139宁夏 1.394862208773422.701500.425377贵州.64233293371628.121469.345415青海 1.483846151633017.871024.387368
根据上面数据回答以下问题:
(一) 计算10个变量的相关系数矩阵,并找出相关性最强的 5 组变量;
1.利用 SPSS 软件,依次选中 Analysis---correlate---bivariable ,得结果整理得
1.000.940.950.960.970.980.410.070.870.66
0.94 1.000.990.990.970.970.610.350.800.60
0.950.99 1.00 1.000.980.980.630.340.820.62
0.960.99 1.00 1.000.990.990.610.330.830.61
0.970.970.980.99 1.00 1.000.560.240.860.62
r
xy
0.970.980.99 1.00 1.000.550.220.870.62
0.98
0.410.610.630.610.560.55 1.000.780.370.15
0.070.350.340.330.240.220.78 1.000.110.05
0.870.800.820.830.860.870.370.11 1.000.68
0.660.600.620.610.620.620.150.050.68 1.00
2
5组变量:X 2和,X2和X4,和X4,X4和及和。
.其中:变量最强的X 3X 3X 5X 5X 6
[注: SPSS运行结果见附件(一 )] (二) 对上面数据进行主成分分析,要求写出:
a)方差分解表(特征值,累积贡献率);
解答:
7.50275.02275.022
1.57715.77090.791
.536 5.36296.154
.206 2.06498.217
.145 1.45099.667
Initial Eigenvalue s
.22299.889
.022
.007.07199.960
.003.02799.987
.001.00799.994
.001.006100.000
b)要求累积贡献率大于等于85%,选取主成分个数,并用原始的10 个变量表示每个主成分;
解答: n=2 时,贡献率达到90.791%;原始的 10个变量表示每个主成
分F1和F2:
F 10.349766X 10.358893X 20.362179X 30.362179 X 40.360353 X 5
0.359988 X 6 0.224171X 7 0.120118 X 8 0.319097X 9 0.245347 X 10
F 2-0.19749X 10.034241X 20.029464X 30.013537X 40.05096 X 5
0.0645X 60.582902X 70.702349X 80.1943X 90.28667 X 10
c)计算每个省份相应的主成分值,并对主成分值进行标准化。
北京上海天津陕西辽宁吉林黑龙江湖北江苏广东
11.70 5.94 3.50 1.010.830.800.240.12-0.16-0.31
-0.890.10 1.030.030.88-0.020.580.85 1.020.93
四川山东甘肃湖南浙江新疆福建山西河北安徽
-0.70-0.86-0.74-0.86 -0.98-0.82-0.96-1.07 -1.22-1.35
1.29 1.640.200.850.19-0.51-0.190.150.330.87
云南江西海南内蒙古西藏河南广西宁夏贵州青海
-1.18-1.36-1.35-1.40-0.67-1.64-1.68-1.27-1.97-1.60
-0.650.65-0.10-0.23-4.720.270.47-1.48-0.80-2.75
【注: SPSS 运行结果见附录二】
(三) 利用2)中的标准化后主成分值对30 个省市进行聚类分析,要求,a)分别用系统聚类
和快速聚类把30 个省市分成 3 类,并比较这两种聚类结果异同(系统聚类给出你选择
的聚类方法及谱系图)
Rescaled Distance Cluster Combine
CASE 0510152025
Label Num +---------+---------+---------+---------+---------+
15─┐
18─┤
19─┤
13─┤
23─┤
24─┤
16─┤
17─┤
21─┤
26─┤
27─┤
20─┤
22─┤
14─┤
11─┤
12─┼─┐
9─┤│
10─┤│
7─┤│
8─┤├─────┐
4─┤││
6─┤││
5─┘│├─┐
28─┐││ │
29─┼─┘│ ├─────────────────────────────────────┐30─┘│ ││
25─────────┘││
2───┬───────┘│
3───┘│
1─────────────────────────────────────────────────┘聚类情况:第一类:北京
第二类:上海、天津
第三类:其他
快速聚类法:
Initial Cluster Centers
Cluster
123 VAR0001211.70 5.94-.67 VAR00013-.89.10-4.72
Iteration History a
Iterati Change in Cluster Centers
on123
1.000 3.147 4.677
2.000.674.076
3.000 1.249.069
4.000.000.000
a. Convergence achieved due to
no or small change in cluster
centers. The maximum absolute
coordinate change for any center
is .000. The current iteration is 4.
The minimum distance between
initial centers is 5.843.
Cluster Membership Cluster Membership
Case Case Case
Number Number Cluster Distance Number Cluster 11.000 163.498 22 1.307 173.255 32 1.307 183.324 43 1.795 193.551 53 1.843 203 1.046 63 1.585 213.757 73 1.181 223.871 83 1.247 233.574 93 1.199 243.654 103 1.055 253 4.709 113 1.305 263.902 123 1.647 273 1.020 133.209 283 1.546 143.867 293 1.428 153.276 303 2.860
(四) 利用3)中快速聚类的结果及2)标准化后主成分值进行判别分析,要求:a)检验 3
类间的均值是否相等; b)检验 3 类间的自协方差阵是否相等(a,b 的结果要求给出原假设和检验结果);c)写出 fisher 和典型判别准则;d)分别利用 c)的检验准则检验青海属于哪一类; e)给出检验判别准则的优劣。
a)建立检验假设为:H0 :三类均值相等 vs H 1 :三类均值不相等
Between-Subjects Factors
N
Cluster Number of Case11
22
327
Multivariate Tests c
Effect Value F Hypothesis df Error df Sig. Intercept Pillai's Trace.894 1.092E2a 2.00026.000.000 Wilks' Lambda.106 1.092E2a 2.00026.000.000
Hotelling' s Trace8.404 1.092E2a 2.00026.000.000
Roy's Largest Root8.404 1.092E2a 2.00026.000.000 QCL_1Pillai's Trace.94212.012 4.00054.000.000 Wilks' Lambda.08531.675 a 4.00052.000.000
Hotelling' s Trace10.49965.616 4.00050.000.000
Roy's Largest Root10.469 1.413E2b 2.00027.000.000
a. Exact statistic
b. The statistic is an upper bound on F that yields a lower bound on the significance level.
c. Design: Intercept + QCL_1
【 SPSS运行结果】由Sig.值可以看到,无论从哪个统计量来看,三类都是与显著差异的,故拒绝原假设,
认为三类均值不相等。
b)建立检验假设为:H 0:三类自协方差阵相等vs H 1 :三类自协方差阵不相等
Warnings
Box's Test of Equality of Covariance Matrices is not computed because there are
fewer than two nonsingular cell covariance matrices.
c)fisher 判别准则:设Yi ( X ) 为第i个线性判别函数,(i=1,2,,m),
m d ( x , G k )
2 ( y i ( x ) y i ( x k ))
i1
则 d ( x , G t )m i nd ( x , G k ) , x G t
1 j k
典型判别准则:
d)
Canonical Discriminant Function Classification Function Coefficients
Coefficients
Cluster Number of Case
Function
123
12 VAR0001216.748 6.612-1.110
VAR00012 1.191.020 VAR00013-2.376-.377.116
VAR00013-.143.778 (Constant)-100.121-16.594-1.533
(Constant).000.000 Fisher's linear discriminant functions
Unstandardized coefficients
(五)对10个变量使用主轴因子法进行因子分析,要求:a)写出因子载荷矩阵,并给出变量
X1 和因子间的关系; b)计算每个变量的共同度,并给出变量 1 被选取因子解释的比例;
c)对因子进行方差最大化旋转,给出旋转后的因子载荷矩阵,并利用该矩阵对原始的
10 个变量进行分类,而且出没类变量的实际意义;d)计算青海省的因子得分。
a)因子载荷矩阵CM(Component Matrixa)b)变量的共同度
.958.248X10.979268
.983.043X20.968138
.992.037X30.985433
.992.017X40.984353
.987.064X50.978265
CM
.081X60.978757
.986
0.91282
.614.732X7
X80.886165
.329.882
X90.823412
.874.244
X100.581184
.672.360
由上表【变量共同度】结果,变量 X1 和因子间的关系可表示为:X 1= 0.958 F 10.248 F 2,X 2 = 0.983 F 1 0.043 F 2 ,其余以次类推。
变量 1被选取因子解释的比例为97.9%.
有旋转后的因子载荷矩阵可以看出,公共因子F1 在Xi(i=1,2,3,4,5,6,9,10)上的载荷值都很大。
通过变量的含义得出, F1 反映高校教育规模及教育发展水平和教育经费的公
共因子。公共因子 F2 在通过变量的含义得出, F1 反映高校教育规模及教育发展水平和教育经费的公共因子。公共因子F2在X 7,X 8上的载荷较大,是反映高校高级职称占专职教师的比例和平均每所高等院校的在校生数的公共因子,
有了对各个公共因子合理的解释,结合各个城市在两个公共因子上的得分和综合
得分,就可以对各中心城市的教育发展水平进行评价了。
d)青海省的因子得分-0.585,-2.188.【SPSS运行结果参见附录三】
附录一:
Total Variance Explained
Initial Eigenvalues Extraction Sums of Squared Loadings Compo
nent Total% of Variance Cumulative %Total% of Variance Cumulative % 17.50275.02275.0227.50275.02275.022
2 1.57715.77090.791 1.57715.77090.791
3.536 5.36296.15
4.536
5.3629
6.154
4.206 2.06498.217.206 2.06498.217
5.145 1.45099.667.145 1.45099.667
6.022.22299.889
7.007.07199.960
8.003.02799.987
9.001.00799.994
10.001.006100.000
Extraction Method: Principal Component Analysis.
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
应用多元统计分析课后答案
应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 2 1/21 (2)()p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
03第三篇 多元统计分析作业题
第三篇 多元统计分析作业题 1 证明题 1)已知ψ==A X E X Z T T T ,这里用到关系1-ψ=E A 。以二变量为例证明: 12*-Λ=ψ=A X A X Z T T T 1)(-=T T A X 。 式中X 为标准化原始变量矩阵,A 为载荷矩阵,Z 为非标准化主成分得分,Z *为标准化的因子得分,E 为单位化特征向量构成的矩阵即正交矩阵,Ψ为特征根的平方根的倒数构成的对角阵,Λ为特征根构成的对角阵,对于二变量有 ?????? ??=ψ21 /10 /1λλ, ?? ? ???=Λ21 00λλ. 2)对于二变量因子模型,我们有 ?? ?++=++=222221122 112211111εεu f a f a x u f a f a x . 试以 x 1为例证明1 2 22==+j x j j u h σ ,这里∑== p k kj j a h 1 2 22 21 211a a +=。 2 计算题 1)现有一组古生物腕足动物贝壳标本的两个变量:长度x 1和宽度x 2。所测数据如下(表2.1)。 要求: ① 利用Excel 对数据进行主成分分析。 ② 借助SPSS 对该数据进行主成分分析,并计算结果与Excel 的计算结果进行对比,理解各个表格所给参数的含义。 ③ 用本例数据验证证明题?的推导结果。 表2.1 古生物腕足动物贝壳标本数据 样品编号 长度x 1 宽度x 2 样品编号 长度x 1 宽度x 2 1 3 2 14 12 10 2 4 10 15 12 11 3 6 5 16 13 6 4 6 8 17 13 14 5 6 10 18 13 15 6 7 2 19 13 17 7 7 13 20 14 7 8 8 9 21 15 13 9 9 5 22 17 13
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
多元统计分析期末复习试题
第一章: 多元统计分析研究的容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X均值向量: 随机向量X与Y的协方差矩阵: 当X=Y时Cov(X,Y)=D(X);当Cov(X,Y)=0 ,称X,Y不相关。 随机向量X与Y的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X,Y为随机向量,A,B 为常数矩阵 E(AX)=AE(X); E(AXB)=AE(X)B; D(AX)=AD(X)A’; )' ,..., , ( ) , , , ( 2 1 2 1P p EX EX EX EXμ μ μ = ' = )' )( ( ) , cov(EY Y EX X E Y X- - = q p ij r Y X ? =) ( ) , (ρ
Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变量之间的比较。 4、对数变换:对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。它将具有指数特征的数据结构变换为线性数据结构。 三、样品间相近性的度量 研究样品或变量的亲疏程度的数量指标有两种:距离,它是将每一个样品看作p 维空),(~∑μP N X μ∑μp X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ)()1(,,n X X X )',,,(21p X X X )')(()()(1X X X X i i n i --∑=n 1X μ ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
matlab与应用多元统计分析
多元统计分析中的应用研究 , 摘要:许多实际问题往往需要对数据进行统计分析,建立合适的统计模型,过去一般采用SAS 、SPSS软件分析,本文给出 Matlab软件在多元统计分析上的应用, 主要介绍Matlab 在聚类分析、判别分析、主成份分析上的应用,文中均给以实例, 结果令人满意。 关键词:Matlab软件;聚类分析;主成份分析 Research for application of Multivariate Statistical Analysis Abstract:Many practice question sometimes need Statistical Analysis to data.,and establish appropriate Statistical model SAS and SPSS software were commonly used in foretime ,this paper give the application of Matlab software in Multivariate Statistical Analysis,mostly introduce the application of Matlab software in priciple component analysis and cluster analysis and differentiate analysis.The example are given in writing and the result are satisfaction. Key words: Matlab software; cluster analysis; priciple component analysis 0 引言 许多实际问题往往需要对数据进行多元统计分析, 建立合适的模型, 在多元统计分析方面, 常用的软件有SAS 、SPSS 、S-PLUS等。我们在这里给出Matlab在多元统计分析上的应用, 在较早的版本中, 统计功能不那么强大, 而在Matlab6.x版本中, 仅在统计工具中的功能函数就达200多个, 功能已足以赶超任何其他专用的统计软件,在应用上Matlab具有其他软件不可比拟的操作简单,接口方便, 扩充能力强等优势, 再加上Matlab的应用范围广泛, 因此可以预见其在统计应用上越来越占有极其重要的地位,下面用实例给出Matlab 在聚类分析、主成份分析上的应用。 1 聚类分析 聚类分析法是一门多元统计分类法,其目的是把分类对象按一定规则分成若干类,所分成的类是根据数据本身的特征确定的。聚类分析法根据变量(或样品或指标)的属性或特征的相似性,用数学方法把他们逐步地划类,最后得到一个能反映样品之间或指标之间亲疏关系的客观分类系统图,称为谱系聚类图。 聚类分析的步骤有:数据变换,计算n个样品的两两间的距离,先分为一类,在剩下的n-1个样品计算距离,按照不同距离最小的原则,增加分类的个数,减少所需要分类的样品的个数,循环进行下去,直到类的总个数为1时止。根
应用多元统计分析SAS作业第六章资料
6-10 今有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据(见表1)。 (1) 试用多种系统聚类法对6个弹头进行分类;并比较分类结果; (2) 试用多种方法对7种微量元素进行分类。 问题求解 1对6个弹头进行分类 对数据进行标准化变换,样品间距离定义为欧式距离,系统聚类的方法分别使用类平均法(A VE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录1)。 1.1类平均法 图1 类平均聚类法相关矩阵特征值图 图2 类平均聚类分析法聚类历史图 由图2可知,NCL=1时半偏R 2最大且伪F 统计量在NCL=2,5时和伪t 方统计量在NCL=1,4时较大。因此,将6个弹头分为两类{}{}(2) (2) 121,2,4,6,3,5G G ==。SAS 绘制的谱系聚类图如图 3所示。
图3 类平均聚类分析法谱系聚类图 1.2中间距离法 图4 中间距离聚类法相关矩阵特征值图 图5 中间距离聚类法聚类历史图 由图5可知,中间距离法与类平均法结果一致。因此,也将6个弹头分为两类 {}{}(2)(2) 121,2,4,6,3,5G G ==。 SAS 绘制的谱系聚类图如图6所示。
图6中间距离聚类法谱系聚类图 1.3可变类平均法 图7可变类平均聚类法分析结果图 图8 可变类平均聚类法聚类历史图 由图8可知,可变类平均法(=0.25 β-)输出结果与前两种方法稍有不同,NCL=1时半偏R2最大且伪F统计量在NCL=2时次大,NCL=5时最大;而伪t方统计量在NCL=1时最大。因此,分
多元统计分析期末考试考点整理
二名词解释 1、 多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理 论和方法,是一元统计学的推广 2、 聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方 法。将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。 使类内对象的同质性最大化和类间对象的异质性最大化 3、 随机变量:是指变量的值无法预先确定仅以一定的可能性 (概率)取值的量。它是由于随 机而获得的非确定值,是概率中的一个基本概念。即每个分量都是随机变量的向量为随机向 量。类 似地,所有元素都是随机变量的矩阵称为随机矩阵。 4、统计量:多元统计研究的是多指标问题 ,为了了解总体的特征,通过对总体抽样得到代表 总体的样本,但因为信息是分散在每个样本上的 ,就需要对样本进行加工,把样本的信息浓缩 到不包含未知量的样本函数中,这个函数称为统计量 二、计算题 ^16 -4 2 k 设H = 其中启= (1Q —纣眉=-4 4-1 [― 试判断叼+ 2吟与 「花一? [是否独立? 解: "10 -6 -15 -6 1 a 2U -16 20 40 故不独立口 -r o 2丿 按用片的联合分帚再I -6 lti 20 -1G 20 ) -1V16 -4 0 -4 A 2 丿"-1
2.对某地区农村的百名2周宙男翌的身高、胸圉、上半骨圉进行测虽,得相关数据如下』根据汶往资料,该地区城市2周岁男婴的遠三个指标的均值血二(90Q乩16庆现欲在多元正态性的假定下检验该地区农村男娶是否与城市男婴有相同的均值?伽厂43107-14.62108.946^1 ]丼中乂=60.2x^)-1=(115.6924)-1-14.6210 3.172-37 3760 、8.9464-37 376035.S936」= 0.01, (3,2) = 99.2, 03) =293 隔亠4) =16.7) 答: 2、假设检验问题:比、# =险用‘//H地 r-8.o> 经计算可得:X-^A 22 厂 「3107 -14.6210 ST1=(23J3848)-1 -14.6210 3.172 8 9464 -37 3760 E9464 -37.3760 35.5936 构造检验统计量:尸=旳(丟-間)〃丿(巫-角) = 6x70.0741=420.445 由题目已知热“(3,)= 295由是 ^I =^W3,3)^147.5 所以在显著性水平ff=0.01下,拒绝原设尽即认 为农村和城市的2周岁男婴上述三个指标的均 值有显著性差异 (] 4、设盂=(耳兀.昂工/ ~M((XE),协方差阵龙=P P (1)试从匸出发求X的第一总体主成分; 答: (2)试|可当卩取多大时才链主成分册贡蕭率达阳滋以上.
多元统计分析上机作业
多远统计上机作业 指标的原始数据取自《中国统计年鉴, 1995》和《中国教育统计年鉴, 1995》除以各地区相应的人口数得到十项指标值见表 1。其中: X1 X2 X3 X4 X5 X6:为每百万人口高等院校数; :为每十万人口高等院校毕业生数; :为每十万人口高等院校招生数; :为每十万人口高等院校在校生数; :为每十万人口高等院校教职工数; :为每十万人口高等院校专职教师数; X7: 为高级职称占专职教师的比例; X8 :为平均每所高等院校的在校生数; X9 :为国家财政预算内普通高教经费占 国内生产总值的比重; X10: 为生均教育经费。 表 1 我国各地区普通高等教育发展状况数据 地区X1X2X3X4X5X6X7X8X9X10北京 5.96310461155793131944.362615 2.2013631上海 3.39234308103549816135.023052.9012665天津 2.3515722971329510938.403031.869385陕西 1.35811113641505830.452699 1.227881辽宁 1.50881284211445834.302808.547733吉林 1.67861203701535833.532215.767480黑龙江 1.1763932961174435.222528.588570湖北 1.0567922971154332.892835.667262江苏.9564942871023931.543008.397786广东.693971205612434.502988.3711355四川.564057177612332.623149.557693山东.575864181572232.953202.286805甘肃.714262190662628.132657.737282湖南.744261194612433.062618.476477浙江.864271204662629.942363.257704新疆 1.2947732651144625.932060.375719福建 1.045371218632629.012099.297106山西.855365218763025.632555.435580河北.814366188612329.822313.315704安徽.593547146462032.832488.335628云南.663640130441928.551974.489106江西.774363194672328.812515.344085海南.703351165471827.342344.287928内蒙古.844348171652927.652032.325581西藏 1.692645137753312.10810 1.0014199河南.553246130441728.412341.305714广西.602843129391731.932146.245139宁夏 1.394862208773422.701500.425377贵州.64233293371628.121469.345415青海 1.483846151633017.871024.387368
多元统计分析期末试题汇编
一、填空题(20分) 1、若),2,1(),,(~)(n N X p =∑αμα 且相互独立,则样本均值向量X 2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。 3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。 4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。 5、设样品),2,1(,),,('21n i X X X X ip i i i ==,总体),(~∑μp N X ,对样品进行分类常用的距离有:明氏距 离,马氏距离2 ()ij d M =)()(1j i j i x x x x -∑'--,兰氏距离()ij d L = 6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。 7、一元回归的数学模型是:εββ++=x y 10,多元回归的数学模型是: εββββ++++=p p x x x y 22110。 8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。 9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。 二、计算题(60分) 1、设三维随机向量),(~3∑μN X ,其中??? ? ? ??=∑200031014,问1X 与2X 是否独立?),(21'X X 和3X 是否 独立?为什么? 解: 因为1),cov(21=X X ,所以1X 与2X 不独立。 把协差矩阵写成分块矩阵??? ? ??∑∑∑∑=∑22211211,),(21'X X 的协差矩阵为11∑因为12321),),cov((∑='X X X ,而012=∑,所以),(21'X X 和3X 是不相关的,而正态分布不相关与相互独 立是等价的,所以),(21'X X 和3X 是独立的。
多元统计分析重点归纳.归纳.docx
多元统计分析重点宿舍版 第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用 选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析 多元统计分析方法 选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量 3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型 第二讲:计算均值、协差阵、相关阵;相互独立性 第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤 主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。 主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序 主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。依次类推,原来有P 个变量,就可以转换出P 个主
数学建模多元统计分析
实验报告 一、实验名称 多元统计分析作业题。 二、实验目的 (一)了解并掌握主成分分析与因子分析的基本原理和简单解法。 (二)学会使用matlab编写程序进行因子分析,求得特征值、特征向量、载荷矩阵等值。(三)学会使用排序、元胞数组、图像表示最后的结果,使结果更加直观。 三、实验内容与要求
四、实验原理与步骤 (一)第一题: 1、实验原理: 因子分析简介: (1) 1.1 基本因子分析模型 设p维总体x=(x1,x2,....,xp)'的均值为u=(u1,u2,....,u3)',因子分析的一般模型为 x1=u1+a11f1+a12f2+........+a1mfm+ε 1 x2=u2+a21f1+a22f2+........+a2mfm+ε 2 ......... xp=up+ap1f1+fp2f2+..........+apmfm+εp 其中,f1,f2,.....,fm为m个公共因子;εi是变量xi(i=1,2,.....,p)所独有的特殊因子,他们都是不可观测的隐变量。称aij(i=1,2,.....,p;j=1,2,.....,m)为变量xi的公共因子fi上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。上式可以写为矩阵形式 x=u+Af+ε
其中A=(aij)pxm 称为因子载荷矩阵;f=(f1,f2,....,fm)'为公共因子向量;ε=(ε1,ε2,.....εp)称为特殊因子向量 (2) 1.2 共性方差与特殊方差 xi的方差var(xi)由两部分组成,一个是公共因子对xi方差的贡献,称为共性方差;一个是特殊因子对xi方差的贡献,称为特殊方差。每个原始变量的方差都被分成了共性方差和特殊方差两部分。 (3) 1.3 因子旋转 因子分析的主要目的是对公共因子给出符合实际意义的合理解释,解释的依据就是因子载荷阵的个列元素的取值。当因子载荷阵某一列上各元素的绝对值差距较大时,并且绝对值大的元素较少时,则该公共因子就易于解释,反之,公共因子的解释就比较困难。此时可以考虑对因子和因子载荷进行旋转(例如正交旋转),使得旋转后的因子载荷阵的各列元素的绝对值尽可能量两极分化,这样就使得因子的解释变得容易。 因子旋转方法有正交旋转和斜交旋转两种,这里只介绍一种普遍使用的正交旋转法:最大方差旋转。这种旋转方法的目的是使因子载荷阵每列上的各元素的绝对值(或平方值)尽可能地向两极分化,即少数元素的绝对值(或平方值)取尽可能大的值,而其他元素尽量接近于0. (4) 1.4 因子得分 在对公共因子做出合理解释后,有时还需要求出各观测所对应的各个公共因子的得分,就比如我们知道某个女孩是一个美女,可能很多人更关心该给她的脸蛋、身材等各打多少分,常用的求因子得分的方法有加权最小二乘法和回归法。 注意:因子载荷矩阵和得分矩阵的区别: 因子载荷矩阵是各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。因子得分矩阵表示各项指标变量与提取的公因子之间的关系,在某一公因子上得分高,表明该指标与该公因子之间关系越密切。简单说,通过因子载荷矩阵可以得到原始指标变量的线性组合,如X1=a11*F1+a12*F2+a13*F3,其中X1为指标变量1,a11、a12、a13分别为与变量X1在同一行的因子载荷,F1、F2、F3分别为提取的公因子;通过因子得分矩阵可以得到公因子的线性组合,如F1=a11*X1+a21*X2+a31*X3,字母代表的意义同上。 (5) 1.5 因子分析中的Heywood(海伍德)现象 如果x的各个分量都已经标准化了,则其方差=1。即共性方差与特殊方差的和为1。也就是说共性方差与特殊方差均大于0,并且小于1。但在实际进行参数估计的时候,共性方差
应用多元统计分析习题解答-主成分分析
主成分分析 6.1 试述主成分分析的基本思想。 答:我们处理的问题多是多指标变量问题,由于多个变量之间往往存在着一定程度的相关性,人们希望能通过线性组合的方式从这些指标中尽可能快的提取信息。当第一个组合不能提取止。这就是主成分分析的基本思想。 6.2 主成分分析的作用体现在何处? 答:一般说来,在主成分分析适用的场合,用较少的主成分就可以得到较多的信息量。以各个主成分为分量,就得到一个更低维的随机向量;主成分分析的作用就是在降低数据“维数” 6.3 简述主成分分析中累积贡献率的具体含义。 答:主成分分析把p 个原始变量12,, ,p X X X 的总方差()tr Σ分解成了p 个相互独立的变量p 个主成分的,忽略 一些带有较小方差的主成分将不会给总方差带来太大的影响。这里我们()m p <个主成分,则称1 1 p m m k k k k ψλλ ===∑∑ 为主成分1, ,m Y Y 的累计贡献率,累计贡献率表明1,,m Y Y 综合12,, ,p X X X 的能力。通常取m ,使得累计贡 献率达到一个较高的百分数(如85%以上)。 答:这个说法是正确的。 即原变量方差之和等于新的变量的方差之和 6.5 试述根据协差阵进行主成分分析和根据相关阵进行主成分分析的区别。 答:从相关阵求得的主成分与协差阵求得的主成分一般情况是不相同的。从协方差矩阵出发的,其结果受变量单位的影响。主成分倾向于多归纳方差大的变量的信息,对于方差小的变量就可能体现得不够,也存在“大数吃小数”的问题。实际表明,这种差异有时很大。我 6.6 已知X =()’的协差阵为 试进行主成分分析。 解:=0 计算得 当 时 ,
多元统计分析作业一(第四题)
课程名称:多元统计回归分析 实验项目:多元方差分析 实验类型:验证性 学生学号: 学生姓名: 学生班级: 课程教师: 实验日期: 2016-04-18
.995 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 距跟踪 Wilks 的 .005 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 Lambda Hotelling 215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 的跟踪 Roy 的最 215.561 1832.265(b) 2.000 17.000 .000 .995 3664.530 1.000 大根 A Pillai 的 .901 7.378 4.000 36.000 .000 .450 29.511 .991 跟踪 Wilks 的 .101 18.305(b) 4.000 34.000 .000 .683 73.221 1.000 Lambda Hotelling 8.930 35.720 4.000 32.000 .000 .817 142.882 1.000 的跟踪 Roy 的最 8.928 80.356(c) 2.000 18.000 .000 .899 160.712 1.000 大根 B Pillai 的 .205 2.198(b) 2.000 17.000 .142 .205 4.397 .386 跟踪 Wilks 的 .795 2.198(b) 2.000 17.000 .142 .205 4.397 .386 Lambda Hotelling .259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 的跟踪 Roy 的最 .259 2.198(b) 2.000 17.000 .142 .205 4.397 .386 大根
多元统计分析期末考试考点
多元统计分析期末考试考 点 The following text is amended on 12 November 2020.
二名词解释 1、多元统计分析:多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广 2、聚类分析:是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。将个体或对象分类,使得同一类中的对象之间的相似性比与其他类的对象的相似性更强。使类内对象的同质性最大化和类间对象的异质性最大化 3、随机变量:是指的值无法预先确定仅以一定的可能性(概率)取值的量。它是由于随机而获得的非确定值,是概率中的一个基本概念。即每个分量都是随机变量的向量为随机向量。类似地,所有元素都是随机变量的矩阵称为随机矩阵。 4、统计量:多元统计研究的是多指标问题,为了了解总体的特征,通过对总体抽样得到代表总体的样本,但因为信息是分散在每个样本上的,就需要对样本进行加工,把样本的信息浓缩到不包含未知量的样本函数中,这个函数称为统计量 三、计算题 解: 答: 答: 题型三解答题
1、简述多元统计分析中协差阵检验的步骤 答: 第一,提出待检验的假设和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域;第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 2、简述一下聚类分析的思想 答:聚类分析的基本思想,是根据一批样品的多个观测指标,具体地找出一些能够度量样品或指标之间相似程度的统计量,然后利用统计量将样品或指标进行归类。把相似的样品或指标归为一类,把不相似的归为其他类。直到把所有的样品(或指标)聚合完毕. 3、多元统计分析的内容和方法 答:1、简化数据结构,将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。(1)主成分分析(2)因子分析(3)对应分析等
几种多元统计分析方法及其在生活中的应用[1]
第2章聚类分析及其应用实例 2. 1聚类分析简介 聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统 计分析方法,它们讨论的对象是大量的样品,要求能合理地按各自的特性來进行合理的分类,没有任何模式可供参考或依循,即是在没有先验知识的情况下进行的[']。 聚类分析方法有很多,按不同的分类方式,有不同的分类。按聚类方法的不 同可分为以下几种: (1)系统聚类法:对所在的指标进行分类,每一次将最相似的两个数据合并 成一类,合并之后和其他数据的距离会重新计算,这个步骤会不断重复下去直至所有指标合并成一类,并类的过程可用一张谱系聚类图描述. (2)调优法(动态聚类法):所谓调优法,从表面意思就可以看出是在对n 个对象初步分类后,根据分类后的信息损失尽可能小的原则对分类进行择优调整,直到分类合理为止. (3)有序样品聚类法:在很多实际问题中,所谓的样品都是相互独立的个体, 因此可以平等的划分。但是有序样品聚类法的存在就是因为在另外一些实际问题中,样品之间是存在着某种联系而在分类中是不允许打乱顺序的。有序样品聚类法开始时将所有样品归为一类,然后根据某种分类准则将其分为二类等等,一直往下分类下去直至满足分类要求。它的思想正好与系统聚类法的相反。 (4)模糊聚类法:利用模糊聚集理论来处理分类问题,它对经济领域中具有 模糊特征的两态数据或多态数据具有明显的分类效果. (5)图论聚类法:在处理分类问题中独创性的引入了图论中最小支撑树的概
念。 (6)聚类预报法:顾名思义,就是用聚类分析的方法来在各个领域中进行预 报。在多元统计分析中,判别分析、回归分析等方法都可以用来做预报,但是在 一些异常数据面前,这些方法做的预报都不是很准确,方法也不好准确的实施, 而聚类预报则很好的解决了这一点。可以预见,聚类预报法经过更深入的研究后,一定会得到更加广泛的应用。 按聚类对象的不同,聚类分析可分为2型[对样品(CASES)聚类]与型[对 变量(V ARIABLE)聚类],两种聚类在方法和步骤上都基本相同. 2. 2聚类分析方法介绍 数学方法在实际应用中是否受欢迎,最主要的一点就是它能不能适用于大型 6 第2章聚类分析及.11;应用实例 计算的问题。图论聚类法、基于等价关系的聚类方法和谱系聚类法在大型问题中 难以快速有效处理数据而应用甚少。基于目标函数的聚类方法因其设计简单,在 实际生活中被广泛运用,其主要思想是将问题转换为带约束条件的非线性优化, 这样就可以运用完备的线性最优化知识解决问题,而且这种方法也易于在计算机 上实现。而伴随着计算机技术的突飞猛进,基于目标函数的聚类方法必定会成为 研究的热点。 2. 2. 1谱系聚类方法 在待分析样本数较小时,通常采用谱系聚类方法(系统聚类法)。谱系聚类法 是按距离准则来对样本进行分类的,例如我们要将样本集X中的《个样本划分为C
最新多元统计分析作业
多元统计分析作业
海洋地球化学多元统计分析作业 一、预备工作:数据的输出管理 首先设置File output manager output manager中,选中individual wind。 Also send to Report wind中,选中single report。 二、数据的导入 数据表(data.xls)为一个深海沉积物柱中30个样品分析结果。第1列为样品编号,第2列为样品的采样深度(单位),第三列起为分析的各元素含量。将data.xls 数据导入Statistica worksheet中 (操作步骤为菜单File open …data.xls) 三、数据(图表)的输出 统计分析过程中生成的结果都可以输出到Word文档中(菜单 as …或PrtSc,粘贴到word中)。 对生成的图表,还可先菜单File Add to report,再粘贴到word中。 本项上机实习需完成以下统计分析 一、相关及回归分析(Correlation matrices) 1、分析两组分Co-Ni, CaO-Sr,Fe2O3-MnO,的相关关系,做出相关关系 图,拟合出回归方程。
图1 Co-Ni 相关关系图 图2 CaO-Sr 相关关系图
图3 Fe2O3-MnO 相关关系图 2、做出三组分Cu-Pb-Zn;Sr-Cu-CaO之间的散点图 (scatterplot) 。
图4 Cu-Co-Ni 散点图 图5 Sr-Cu-CaO 散点图
3、计算CaO、Co、Cu、Fe2O3、MnO、Ni、Sr之间的相关关系矩阵。 表1 沉积物中元素相关关系矩阵 (n=30,p<0.05) CaO Fe2O3MnO Co Cu Ni Sr CaO 1.00 Fe2O3-0.23 1.00 MnO 0.18 0.18 1.00 Co -0.21 0.85 0.41 1.00 Cu -0.02 -0.01 0.36 0.26 1.00 Ni -0.10 0.96 0.24 0.88 -0.03 1.00 Sr 0.97 -0.25 0.23 -0.20 0.09 -0.13 1.00 二、聚类分析(Cluster analysis) 1、首先将数据进行标准化(分别进行和列的标准化),得到标准化的数据集。 2、采用Tree clustering 方式,Single linkage法,对CaO、Co、Cu、Fe2O 3、 MnO、Ni、Sr 进行R型聚类分析,进行统计分析。 图6 R型聚类分析图 注:采用Tree clustering 方式, Single linkage ,1-Pearson r 法。