fluent并行计算的方法
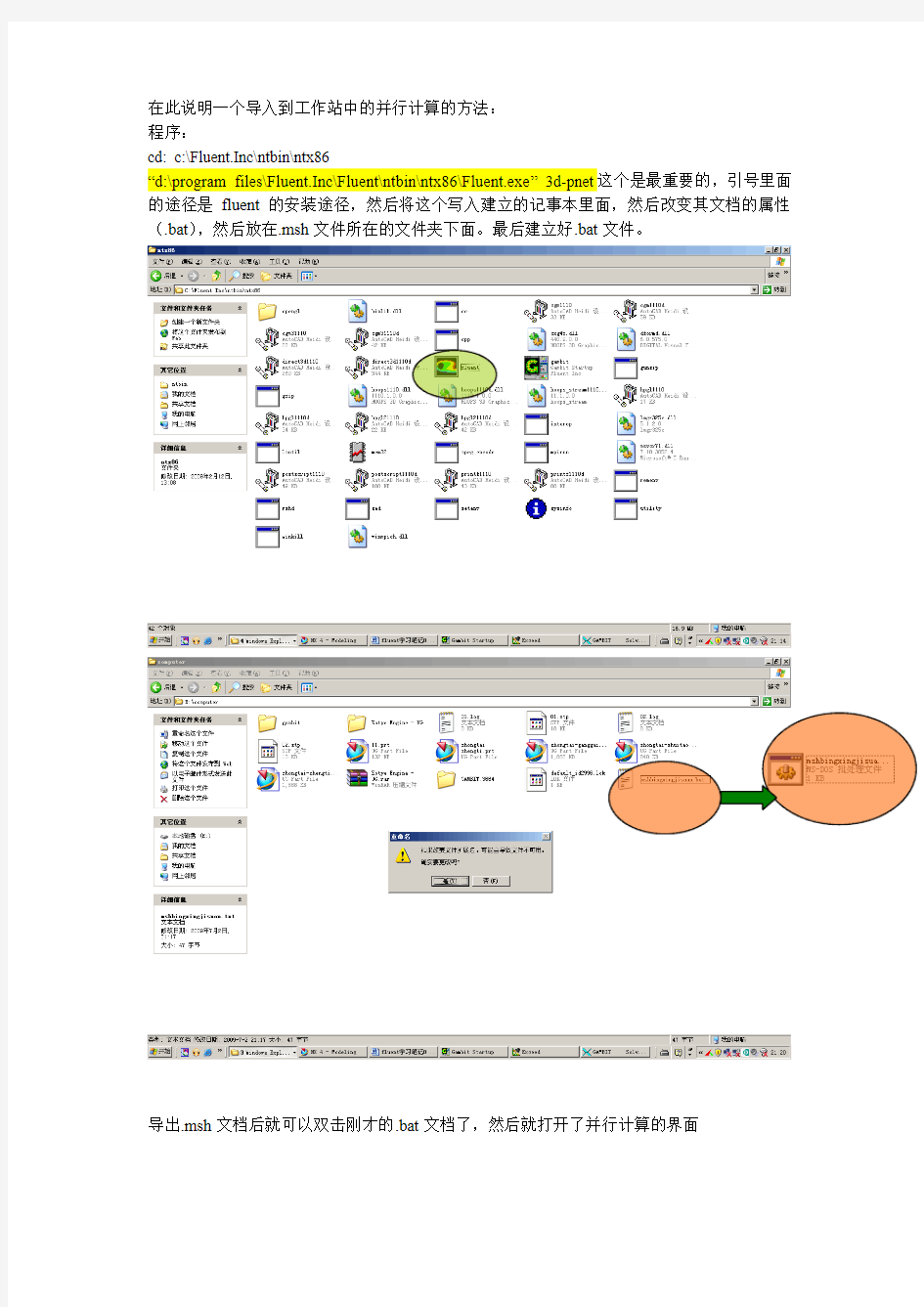
在此说明一个导入到工作站中的并行计算的方法:
程序:
cd: c:\Fluent.Inc\ntbin\ntx86
“d:\program files\Fluent.Inc\Fluent\ntbin\ntx86\Fluent.exe” 3d-pnet这个是最重要的,引号里面的途径是fluent的安装途径,然后将这个写入建立的记事本里面,然后改变其文档的属性(.bat),然后放在.msh文件所在的文件夹下面。最后建立好.bat文件。
导出.msh文档后就可以双击刚才的.bat文档了,然后就打开了并行计算的界面
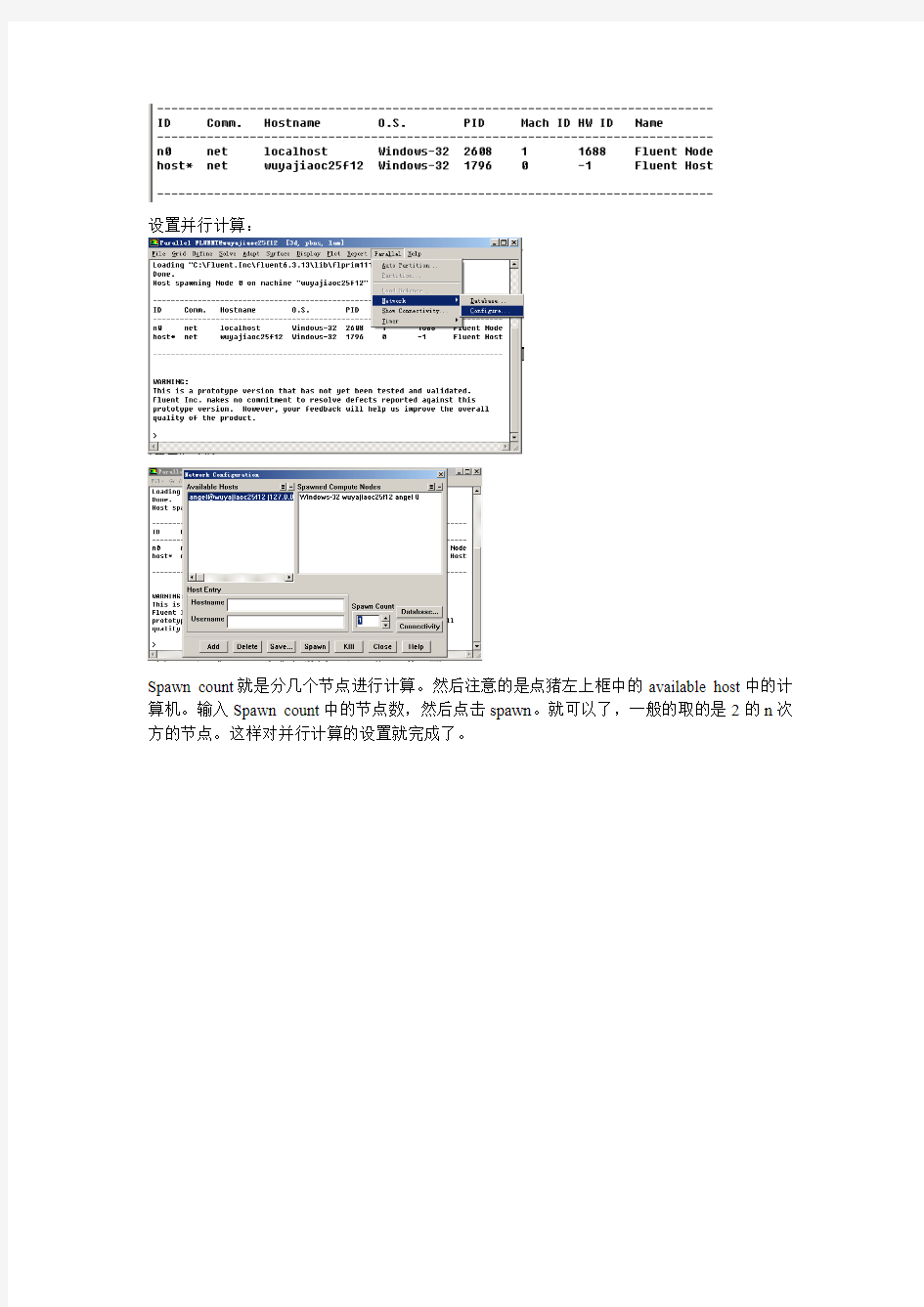
设置并行计算:
Spawn count就是分几个节点进行计算。然后注意的是点猪左上框中的available host中的计算机。输入Spawn count中的节点数,然后点击spawn。就可以了,一般的取的是2的n次方的节点。这样对并行计算的设置就完成了。
并行计算综述
并行计算综述 姓名:尹航学号:S131020012 专业:计算机科学与技术摘要:本文对并行计算的基本概念和基本理论进行了分析和研究。主要内容有:并行计算提出的背景,目前国内外的研究现状,并行计算概念和并行计算机类型,并行计算的性能评价,并行计算模型,并行编程环境与并行编程语言。 关键词:并行计算;性能评价;并行计算模型;并行编程 1. 前言 网络并行计算是近几年国际上并行计算新出现的一个重要研究方向,也是热门课题。网络并行计算就是利用互联网上的计算机资源实现其它问题的计算,这种并行计算环境的显著优点是投资少、见效快、灵活性强等。由于科学计算的要求,越来越多的用户希望能具有并行计算的环境,但除了少数计算机大户(石油、天气预报等)外,很多用户由于工业资金的不足而不能使用并行计算机。一旦实现并行计算,就可以通过网络实现超级计算。这样,就不必要购买昂贵的并行计算机。 目前,国内一般的应用单位都具有局域网或广域网的结点,基本上具备网络计算的硬件环境。其次,网络并行计算的系统软件PVM是当前国际上公认的一种消息传递标准软件系统。有了该软件系统,可以在不具备并行机的情况下进行并行计算。该软件是美国国家基金资助的开放软件,没有版权问题。可以从国际互联网上获得其源代码及其相应的辅助工具程序。这无疑给人们对计算大问题带来了良好的机遇。这种计算环境特别适合我国国情。 近几年国内一些高校和科研院所投入了一些力量来进行并行计算软件的应用理论和方法的研究,并取得了可喜的成绩。到目前为止,网络并行计算已经在勘探地球物理、机械制造、计算数学、石油资源、数字模拟等许多应用领域开展研究。这将在计算机的应用的各应用领域科学开创一个崭新的环境。 2. 并行计算简介[1] 2.1并行计算与科学计算 并行计算(Parallel Computing),简单地讲,就是在并行计算机上所作的计算,它和常说的高性能计算(High Performance Computing)、超级计算(Super Computing)是同义词,因为任何高性能计算和超级计算都离不开并行技术。
学习fluent(流体常识及软件计算参数设置)
luent 中一些问题 ( 目录 ) 离散化的目的 计算区域的离散及通常使用的网格 控制方程的离散及其方法 各种离散化方法的区别 8 9 10在GAMBIT 中显示的“check 主要通过哪几种来判断其网格的质量?及其在做网格时大 致注意到哪些细节? 11 在两个面的交界线上如果出现网格间距不同的情况时,即两块网格不连续时,怎么样克 服这种情况呢? 12在设置GAMBIT 边界层类型时需要注意的几个问题: a 、没有定义的边界线如何处理? b 、计算域内的内部边界如何处理( 2D )? 13 为何在划分网格后,还要指定边界类型和区域类型?常用的边界类型和区域类型有哪 些? 14 20 何为流体区域( fluid zone )和固体区域( solid zone )?为什么要使用区域的概念? FLUENT 是怎样使用区域的? 15 21 如何监视 FLUENT 的计算结果?如何判断计算是否收敛?在 FLUENT 中收敛准则是 如何定义的?分析计算收敛性的各控制参数,并说明如何选择和设置这些 参数?解决不收1 如何入门 2 CFD 2.1 2.2 2. 3 2.4 2.5 2.6 计算中涉及到的流体及流动的基本概念和术语 理想流体( Ideal Fluid )和粘性流体( Viscous Fluid ) 牛顿流体( Newtonian Fluid )和非牛顿流体( non-Newtonian Fluid ) 可压缩流体 ( Compressible Fluid )和不可压缩流体( Incompressible Fluid ) 层流( Laminar Flow )和湍流( Turbulent Flow ) 定常流动( Steady Flow )和非定常流动( Unsteady Flow ) 亚音 速流动 (Subsonic) 与超音速流动( Supersonic ) 热传导( Heat Transfer )及扩散 ( Diffusion ) 2.7 3 在数值模拟过程中,离散化的目的是什么?如何对计算区域进行离散化?离散化时通常 使用哪些网格?如何对控制方程进行离散?离散化常用的方法有哪些?它们有 什么不 同? 3.1 3.2 3.3 3.4 4 常见离散格式的性能的对比(稳定性、精度和经济性) 5 流场数值计算的目的是什么?主要方法有哪些?其基本思路是什么?各自的适用范围是 什 么? 6 可压缩流动和不可压缩流动,在数值解法上各有何特点?为何不可压缩流动在求解时反 而比 可压缩流动有更多的困难? 6.1 可压缩 Euler 及 Navier-Stokes 方程数值解 6.2 不可压缩 Navier-Stokes 方程求解 什么叫边界条件?有何物理意义?它与初始条件有什么关系? 在数值计算中,偏微分方程的 双曲型方程、椭圆型方程、抛物型方程有什么区别? 在网格生成技术中,什么叫贴体坐标 系?什么叫网格独立解?
学习fluent (流体常识及软件计算参数设置)
luent中一些问题----(目录) 1 如何入门 2 CFD计算中涉及到的流体及流动的基本概念和术语 2.1 理想流体(Ideal Fluid)和粘性流体(Viscous Fluid) 2.2 牛顿流体(Newtonian Fluid)和非牛顿流体(non-Newtonian Fluid) 2.3 可压缩流体(Compressible Fluid)和不可压缩流体(Incompressible Fluid) 2.4 层流(Laminar Flow)和湍流(Turbulent Flow) 2.5 定常流动(Steady Flow)和非定常流动(Unsteady Flow) 2.6 亚音速流动(Subsonic)与超音速流动(Supersonic) 2.7 热传导(Heat Transfer)及扩散(Diffusion) 3 在数值模拟过程中,离散化的目的是什么?如何对计算区域进行离散化?离散化时通常使用哪些网格?如何对控制方程进行离散?离散化常用的方法有哪些?它们有什么不 同? 3.1 离散化的目的 3.2 计算区域的离散及通常使用的网格 3.3 控制方程的离散及其方法 3.4 各种离散化方法的区别 4 常见离散格式的性能的对比(稳定性、精度和经济性) 5 流场数值计算的目的是什么?主要方法有哪些?其基本思路是什么?各自的适用范围是什么? 6 可压缩流动和不可压缩流动,在数值解法上各有何特点?为何不可压缩流动在求解时反而比可压缩流动有更多的困难? 6.1 可压缩Euler及Navier-Stokes方程数值解 6.2 不可压缩Navier-Stokes方程求解 7 什么叫边界条件?有何物理意义?它与初始条件有什么关系? 8 在数值计算中,偏微分方程的双曲型方程、椭圆型方程、抛物型方程有什么区别? 9 在网格生成技术中,什么叫贴体坐标系?什么叫网格独立解? 10 在GAMBIT中显示的“check”主要通过哪几种来判断其网格的质量?及其在做网格时大致注意到哪些细节? 11 在两个面的交界线上如果出现网格间距不同的情况时,即两块网格不连续时,怎么样克服这种情况呢? 12 在设置GAMBIT边界层类型时需要注意的几个问题:a、没有定义的边界线如何处理? b、计算域内的内部边界如何处理(2D)? 13 为何在划分网格后,还要指定边界类型和区域类型?常用的边界类型和区域类型有哪些? 14 20 何为流体区域(fluid zone)和固体区域(solid zone)?为什么要使用区域的概念?FLUENT是怎样使用区域的? 15 21 如何监视FLUENT的计算结果?如何判断计算是否收敛?在FLUENT中收敛准则是如何定义的?分析计算收敛性的各控制参数,并说明如何选择和设置这些参数?解决不收
蒙特卡罗方法并行计算
Monte Carlo Methods in Parallel Computing Chuanyi Ding ding@https://www.360docs.net/doc/72407214.html, Eric Haskin haskin@https://www.360docs.net/doc/72407214.html, Copyright by UNM/ARC November 1995 Outline What Is Monte Carlo? Example 1 - Monte Carlo Integration To Estimate Pi Example 2 - Monte Carlo solutions of Poisson's Equation Example 3 - Monte Carlo Estimates of Thermodynamic Properties General Remarks on Parallel Monte Carlo What is Monte Carlo? ? A powerful method that can be applied to otherwise intractable problems ? A game of chance devised so that the outcome from a large number of plays is the value of the quantity sought ?On computers random number generators let us play the game ?The game of chance can be a direct analog of the process being studied or artificial ?Different games can often be devised to solve the same problem ?The art of Monte Carlo is in devising a suitably efficient game.
辐射和对流模型Fluent参数设置
辐射和对流模型Fluent参数设置 1.读入***.mesh文件,并对网格文件进行进行检查,Grid→cheek,主要看最小体积和最小面积不能为负,之后进行刻度转换,Grid→scale,在Gmbit 里面建模默认尺寸为米,与实际尺寸之间要进行转化,如下图: 2.选择求解器,Define→Models→sover……根据情况选择,如上图:接着选择辐射模型,Define→Models→Radiation,如下图,当Radiation Model面板上 点击ok时,会出现一个信息提示框,告诉你新 的材料物性被添加了,你将在后面设置物性参 数,因此现在只需单击ok确认这个信息即可, 如下图: 注意:当你激活辐射模型后,Fluent会自动打开能量求解器,如下图: 不用再Define→Models→Energy……
3.设置流体粘性,由于模型中空气流速比较大,设成双方程模型:如下图: 4.设置操作条件,此模型此有流体,属有重力情况,Define→Operating Conditions,选中 Gravity.Y方向加速度设置为-9.8 2 m,击OK确定。 /s 设置工作温度,在后面要激活的Boussinesq model要用到,(Boussinesq model:
考虑温度变化而忽略压强变化引起的密度变化叫做Boussinesq 假设) 5. 定义材料并设置其物理属性 Define →Material …… 先定义空气物性,要定义成有浮力的,取Boussinesq 选项。 Density=1.1653/m kg ,()k kg j C p ?=/1005 Thermal Conductivity=0.0267()k m w ?/,Material Type :fluid ; Thermal Expansion Coefficient =0.0033()k /1。 通过滚动条使先前面板中不可见的物性显示出来。在Scattering Coefficient 和Scattering Phase Function 中保持默认值,在要解决的问题中不涉及到散射问题;设定热扩散系数(用boussinesq 模型时)为1e-5K -1。单击Change/Create ,关闭Materials 面板。 6.设置边界条件Define → Boundary Conditions ……
Fluent求解参数设置
求解参数设置(Solution Methods/Solution Controls): 在设置完计算模型和边界条件后,即可开始求解计算了,因为常会出现求解不收敛或者收敛速度很慢的情况,所以就要根据具体的模型制定具体的求解策略,主要通过修改求解参数来完成。在求解参数中主要设置求解的控制方程、选择压力速度耦合方法、松弛因子、离散格式等。 在VOF模型中,PISO比较适合于不复杂的流体,SIMPLE和SIMPLEC适合于可压缩的流体或者处于封闭域中的流体。 ? 求解的控制方程: 在求解参数设置中,可以选择所需要求 解的控制方程。可选择的方程包括Flow(流动方 程)、Turbulence(湍流方程)、Energy(能量方 程)、Volume Fraction(体积分数方程)等。在 求解过程中,有时为了得到收敛的解,先关闭 一些方程,等一些简单的方程收敛后,再开启 复杂的方程一起计算。 ? 选择压力速度耦合方法: 在基于压力求解器中,FLUENT提供了压 力速度耦合的4种方法,即SIMPLE、 SIMPLEC(SIMPLE.Consistent)、PISO以及 Coupled。定常状态计算一般使用SIMPLE或者 SIMPLEC方法,对于过渡计算推荐使用PISO方 法。PISO方法还可以用于高度倾斜网格的定常 状态计算和过渡计算。需要注意的是压力速度 耦合只用于分离求解器,在耦合求解器中不可 以使用。 在FLUENT中,可以使用标准SIMPLE算法和SIMPLEC算法,默认是SIMPLE算法,但对于许多问题如果使用SIMPLEC可能会得到更好的结果,尤其是可以应用增加的亚松弛迭代时。 对于相对简单的问题(如没有附加模型激活的层流流动),其收敛性可以被压力速度耦合所限制,用户通常可以使用SIMPLEC算法很快得到收敛解。在SIMPLEC算法中,压力校正亚松弛因子通常设为1.0,它有助于收敛,但是,在有些问题中,将压力校正松弛因子增加到1.0可能会导致流动不稳定,对于这种情况,则需要使用更为保守的亚松弛或者使用SIMPLE算法。对于包含湍流或附加物理模型的复杂流动,只要用压力速度耦合做限制,SIMPLEC就会提高收敛性,它通常是一种限制收敛性的附加模拟参数,在这种情况下,SIMPLE和SIMPLEC 会给出相似的收敛速度。 对于所有的过渡流动计算,推荐使用PISO算法邻近校正。它允许用户使用大的时间步,而且对于动量和压力都可以使用亚松弛因子1.0。对于定常状态问题,具有邻近校正的PISO并不会比具有较好的亚松弛因子的SIMPLE或SIMPLEC好。对于具有较大扭曲网格上的定常状态和过渡计算推荐使用PISO倾斜校正。 当使用PISO邻近校正时,对所有方程都推荐使用亚松弛因子为1.0或者接近1.0。如果只对高度扭曲的网格使用PISO倾斜校正,则要设定动量和压力的亚松弛因子之和为1.0(例如,压力亚松弛因子0.3,动量亚松弛因子0.7)。
传统并行计算框架与MR的区别
现在MapReduce/Hadoop以及相关的数据处理技术非常热,因此我想在这里将MapReduce的优势汇总一下,将MapReduce与传统基于HPC集群的并行计算模型做一个简要比较,也算是对前一阵子所学的MapReduce知识做一个总结和梳理。 随着互联网数据量的不断增长,对处理数据能力的要求也变得越来越高。当计算量超出单机的处理能力极限时,采取并行计算是一种自然而然的解决之道。在MapReduce出现之前,已经有像MPI这样非常成熟的并行计算框架了,那么为什么Google还需要MapReduce,MapReduce相较于传统的并行计算框架有什么优势,这是本文关注的问题。 文章之初先给出一个传统并行计算框架与MapReduce的对比表格,然后一项项对其进行剖析。 MapReduce和HPC集群并行计算优劣对比 ▲ 在传统的并行计算中,计算资源通常展示为一台逻辑上统一的计算机。对于一个由多个刀片、SAN构成的HPC集群来说,展现给程序员的仍旧是一台计算机,只不过这台计算拥有为数众多的CPU,以及容量巨大的主存与磁盘。在物理上,计算资源与存储资源是两个相对分离的部分,数据从数据节点通过数据总线或者高速网络传输到达计算节点。对于数据量较小的计算密集型处理,这并不是问题。而对于数据密集型处理,计算节点与存储节点之间的I/O将成为整个系统的性能瓶颈。共享式架构造成数据集中放置,从而造成I/O传输瓶颈。此外,由于集群组件间耦合、依赖较紧密,集群容错性较差。 而实际上,当数据规模大的时候,数据会体现出一定的局部性特征,因此将数据统一存放、统一读出的做法并不是最佳的。 MapReduce致力于解决大规模数据处理的问题,因此在设计之初就考虑了数据的局部性原理,利用局部性原理将整个问题分而治之。MapReduce集群由普通PC机构成,为无共享式架构。在处理之前,将数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map),将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至reduce节点),避免了大量数据的传输,提高了处理效率。无共享式架构的另一个好处是配合复制(replication)策略,集群可以具有良好的容错性,一部分节点的down机对集群的正常工作不会造成影响。 硬件/价格/扩展性 传统的HPC集群由高级硬件构成,十分昂贵,若想提高HPC集群的性能,通常采取纵向扩展的方式:即换用更快的CPU、增加刀片、增加内存、扩展磁盘等。但这种扩展方式不能支撑长期的计算扩展(很容易就到顶了)且升级费用昂贵。因此相对于MapReduce集群,HPC集群的扩展性较差。 MapReduce集群由普通PC机构成,普通PC机拥有更高的性价比,因此同等计算能力的集群,MapReduce集群的价格要低得多。不仅如此,MapReduce集群
20100428第三章 并行计算模型和任务分解策略
第三章并行计算模型和任务分解策略 首先,我们将研究不同类型的并行计算机,为了不严格限定于某个指定机型,我们通过模型把并行计算机抽象为几个特定属性。为了说明并行程序中处理器之间的通信概念模型我们讨论了不同的程序模型,另外为了分析和评估我们算法的性能,我们讨论了多计算机架构下评估并行算法复杂度的代价模型。在介绍并分析的各种代价模型的基础上给出了改进型的代价模型。 其次我们定义这样几个指标如负载均衡和网络半径等用来研究图分解问题的主要特性。并把图分解问题归纳为一般类型和空间映射图类型。我们重点研究的是后者,因为多尺度配置真实感光照渲染算法可以很方便的描述成空间映射图形式。 3.1 并行计算机模型 以下给出并行计算机的模型的概述,根据其结构并行计算机大致可分为以下几类。 多计算机(Multicomputer):一个von Neumann计算机由一个中央处理器(CPU)和一个存储单元组成。一个多计算机则由很多von Neumann计算机通过互联网络连接而成的计算机系统。见图3.1。每个计算机(节点)执行自己的计算并只能访问本地的存储。通过消息实现各计算机之间的互相通讯。在理想的网络中,两个计算节点之间的信息传送代价与本地的计算节点和它的网络阻塞无关,只和消息的长度相关。以上多计算机和分布式存储的MIMD机器之间的主要区别在于后者的两个节点间的信息传输不依赖于本地计算和其它网络阻塞。 分布式存储的MIMD类型的机器主要有IBM的SP, Intel的Paragon, 曙光4000系列, Cray 的T3E, Meiko的CS-2, NEC的Cenju 3, 和nCUBE等。通过本地网络的连接的集群系统可以认为是分布式存储的MIMD型计算机。 多处理器(Multiprocessor):一个多处理器型并行计算机(共享存储的MIMD计算机)由大量处理器组成,所有的处理器都访问一个共同的存储。理论上理想的模型就是PRAM模型(并行的随机访问系统),即任何一个处理器访问任一存储单元都是等效的(见图3.2)。并发存储访问是否允许取决于所使用的真正的模型【34】。 混合模型:分布式共享存储(DMS)计算机,提供了一个统一的存储访问地址空间但是分布式物理存储模块。编译器和运行时系统负责具体的并行化应用。这种系统软件比较复杂。 图3.1 多计算机模型图3.2 PRAM 模型 SIMD计算机:在一个SIMD(单指令流多数据流)计算机中在不同数据流阶段所有的处理器执行同样的指令流。典型的机型有MasPar的MP, 和联想机器CM2。 多计算机系统具有良好的可扩展性,价格低廉的集群式并行计算机就属于这种模型,本文中的算法主要基于多计算机体系结构。 3.2 程序模型 并行程序的编程语言如C或Fortan。并行结构以某种类库的形式直接整合进这些编程语言中。编程模型确定了并行程序的风格。一般可分为数据并行、共享存储和消息传递等模型[35]。 数据并行编程:数据并行模型开始于编写同步SIMD并行计算机程序。程序员需要在每个处理器上独立执行一个程序,每个处理器均有其自己的存储器。程序员需要定义数据如何分配到每个局部存储中。实际应用中大量的条件分支的需要使得其很难高效的运行在SIMD型的机器上。 共享存储编程:共享存储模型是一个简单的模型,因为程序员写并行程序就像写串行程序一样。一个程序的执行与几个处理器独立,也不需要同步。一个处理器的执行状态独立于其它处理器的运
详细FLUENT实例讲座翼型计算
详细FLUENT实例讲座翼型计算 部门: xxx 时间: xxx 整理范文,仅供参考,可下载自行编辑
CAE联盟论坛精品讲座系列 详细FLUENT实例讲座-翼型计算 主讲人:流沙 CAE联盟论坛总版主 1.1 问题描述 翼型升阻力计算是CFD最常规的应用之一。本例计算的翼型为 RAE2822,其几何参数可以查看翼型数据库。本例计算在来流速度0.75马赫,攻角3.19°情况下,翼型的升阻系数及流场分布,并将计算结果与实验数据进行对比。模型示意图如图1所示。 b5E2RGbCAP 1.p ng(12.13 K>2018/7/29 23:41:251.2 FLUENT前处理设置Step 1:导入计算模型 以3D,双精度方式启动FLUENT14.5。 利用菜单【File】>【Read】>【Mesh…】,在弹出的文件选择对话框中选择网格文件rae2822_coarse.msh,点击OK按钮选择文件。如图2所示。p1EanqFDPw
点击FLUENT模型树按钮General,在右侧设置面板中点击按钮Display…,在弹出的设置对话框中保持默认设置,点击Display按钮,显示网格。如图3所示。DXDiTa9E3d 2.png(11.51 K>2018/7/29 23:41:25
3.png(33.41 K>2018/7/29 23:41:253-2.png(52.04 K>2018/7/29 23:41:25Step 2:检查网格 采用如图4所示步骤进行网格的检查与显示。点击FLUENT模型树节点General节点,在右侧面板中通过按钮Scale…、Check及 Report Quality实现网格检查。 4.png(12. 10 K>RTCrpUDGiT2018/7/29 23:41:25点击按钮Check,在命令输出按钮出现如图5所示网格统计信息。从图中可以看出,网格尺寸分布: x轴:-48.97~50m
蒙特卡罗方法的计算程序
关于蒙特卡罗方法的计算程序已经有很多,如:EGS4、FLUKA、ETRAN、ITS、MCNP、GEANT 等。这些程序大多经过了多年的发展,花费了几百人年的工作量。除欧洲核子研究中心(CERN)发行的GEANT主要用于高能物理探测器响应和粒子径迹的模拟外,其它程序都深入到低能领域,并被广泛应用。就电子和光子输运的模拟而言,这些程序可被分为两个系列:1.EGS4、FLUKA、GRANT 2.ETRAN、ITS、MCNP 这两个系列的区别在于:对于电子输运过程的模拟根据不同的理论采用了不同的算法。EGS4和ETRAN分别为两个系列的基础,其它程序都采用了它们的核心算法。 ETRAN(for Electron Transport)由美国国家标准局辐射研究中心开发,主要模拟光子和电子,能量范围可从1KeV到1GeV。 ITS(The integrated TIGER Series of Coupled Electron/Photon Monte Carlo Transport Codes )是由美国圣地亚哥(Sandia)国家实验室在ETRAN的基础上开发的一系列模拟计算程序,包括TIGER 、CYLTRAN 、ACCEPT等,它们的主要差别在于几何模型的不同。TIGER研究的是一维多层的问题,CYLTRAN研究的是粒子在圆柱形介质中的输运问题,ACCEPT是解决粒子在三维空间输运的通用程序。 NCNP(Monte Carlo Neutron and Photo Transport Code)由美国橡树林国家实验室(Oak Ridge National Laboratory)开发的一套模拟中子、光子和电子在物质中输运过程的通用MC 计算程序,在它早期的版本中并不包含对电子输运过程的模拟,只模拟中子和光子,较新的版本(如MCNP4A)则引进了ETRAN,加入了对电子的模拟。 FLUKA 是一个可以模拟包括中子、电子、光子和质子等30余种粒子的大型MC计算程序,它把EGS4容纳进来以完成对光子和电子输运过程的模拟,并且对低能电子的输运算法进行了改进。
ECLIPSE 并行运算实现方法_JiangSu
Schlumberger Private ECLIPSE 并行运算实现方法 1. 在MODEL_NAME.DATA 文件中的RUNSPEC 部分添加下列关键字: PARALLEL 4 / 2. 在并行机上自己的数据文件夹中创建一个新的文件,如名为:hosts. 若想用4个CPU 计算模型,则此模型内容可作如下设置,从而制定运算所用的节点及CPU : js031 js031 js032 js032 等。 其中js031, js032为并行机中各计算节点的名字。 3. 在此文件夹内执行并行运算,所用命令如下: @mpieclipse –hostfile hosts MODEL_NAME (黑油模型) 或 @mpie300 –hostfile hosts MODEL_NAME (组分模型) 4. 然后会出现如下状态信息,提示选择并行链接方式: [ecl@gri01 e100]$ @mpieclipse -hostfile hosts PARALLEL Specify Parallel InterConnect required ? 1 - Ethernet / Gigabit 2 - Myrinet 3 - Scali Select 1-3 [default 1 - Ethernet / Gigabit] : 1 5. 此时,选择1,出现如下信息: Running version 2006.1 Running Parallel Eclipse 100 on Machine type linux_x86_64 Local config file ECL.CFG exists, OK to use ('n' deletes local file) (Y/n)?: y 5. 选择Y ,出现如下信息,模拟运算即可正常运行: Using local config file ECL.CFG Running MPICH software from /apps/ecl/tools/linux_x86_64/mpich_x86_64 Number of processors required is = 4 Running Parallel Eclipse 100 on Machine type linux_x86_64 version 2006.1 …… 1 READING RUNSPEC 2 READING TITLE
FLUENT操作过程及全参数选择
振动流化床仿真操作过程及参数选择 1创建流化床模型。 根据靳海波论文提供的试验机参数,创建流化床模型。流化床直148mm 高1m开孔率9%孔径2mm在筛板上铺两层帆布保证气流均布。 因为实验机为一个圆形的流化床,所以可简化为仅二维模型。而实际实验中流化高度远小于1m甚至500mm所以为提高计算时间,可将模型高度缩为500mm由于筛板上铺设两层帆布以达到气流均分的目的,所以认为沿整个筛板的进口风速为均匀的。最终简化模型如下图所示: 上图为流化后的流化床模型,可以看出流化床下端的网格相对上端较密,因为流化行为主要发生的流化床下端,为了加快计算时间,所以采用这种下密上疏的划分方式。其中进口设置为velocity inlet ;出口设置为outflow ;左右两边分为设置为wall。在GAMBIT中设置完毕后,输出二维模型vfb.msh。 outflow 边界条件不需要给定任何入口的物理条件,但是应用也会有限制,大致为以下四点: 1.只能用于不可压缩流动
2.出口处流动充分发展 3.不能与任何压力边界条件搭配使用(压力入口、压力出口) 4.不能用于计算流量分配问题(比如有多个出口的问题) 2 打开FLUENT 6326,导入模型vfb.msh 点击GRID—CHECK检查网格信息及模型中设置的信息,核对是否正确,尤其查看是否出现负体积和负面积,如出现马上修改。核对完毕后,点击GRID-SCAL弹出SCALEGRID窗口,设置单位为mm 并点击change length unit 按钮。具体设置如下: 3设置求解器 保持其他设置为默认,更改TIME为unsteady,因为实际流化的过程是随时间变化的。 (1)pressure based 求解方法在求解不可压流体时,如果我们联立求解 从动量方程和连续性方程离散得到的代数方程组,可以直接得到各速
并行计算的基本概念
并行计算的基本概念 [转贴2008-02-25 09:57:26] 1、并行计算:并行计算是指同时对多个任务或多条指令、或对多个数据项进行处理。完成此项处理的计算机系统称为并行计算机系统,它是将多个处理器通过网络连接以一定的方式有序地组织起来。 2、指令流:机器执行的指令序列; 3、数据流:由指令流调用的数据序列,包括输入数据和中间结果。 4、SIMD计算机:有一个控制部件和许多处理单元,所有的处理单元在控制部件的统一控制下工作。控制部件向所有的处理单元广播同一条指令,所有的处理单元同时执行这条指令,但是每个处理单元操作的数据不同。 5、MIMD计算机没有统一的控制部件,含有多个处理器,各处理器可以独立地执行不同的指令,每个处理器都有控制部件,各处理器通过互连网络进行通信。 6、并行向量处理机(PVP)在并行向量处理机中有少量专门定制的向量处理器。每个向量处理器有很高的处理能力。并行向量处理机通过向量处理和多个向量处理器并行处理两条途径来提高处理能力。 7、大规模并行处理机(MPP)大规模并行处理机一般指规模非常大的并行计算机系统,含有成千上万个处理器。它一般采用分布的存储器,存储器一般为处理器私有,各处理器之间用消息传递的方式通信。大规模并行处理机的互连网络一般是专门设计定制的。 8、分布式共享存储器多处理机(DSM)分布式共享存储器多处理机的主要特点是它的存储器在物理上是分布在各个结点中的,但是通过硬件和软件为用户提供一个单一地址的编程空间,即形成一个虚拟的共享存储器。它通过高速缓存目录支持分布高速缓存的一致性。 9、机群(COW或NOW) 是由高档商品微机(包括工作站)用高速商品互连网络(有的商用机群也使用定制的网络)连接而成,每个结点都是一台完整的计算机(可能没有鼠标、显示器等外设)。 10、对称多处理机(SMP)对称多处理机的最大特点是其中的各处理器完全平等,无主从之分。所有的处理器都可以访问任何存储单元和I/O设备。存储器一般使用共享存储器,只有一个地址空间。因为使用共享存储器,通信可用共享变量(读写同一内存单元)来实现。 11、UMA UMA是Uniform Memory Access(均匀存储访问)模型的缩写。在这种并行机中所有的处理器均匀共享物理存储器。所有处理器访问任何存储字需要相同的时间(此即为均匀存储访问名称的来源)。每台处理器可以有私有高速缓存。UMA结构适用于通用或分时应用。 12、NUMA NUMA是Nonuniform Memory Access(非均匀存储访问)模型的缩写。在NUMA中,共享存储器在物理上是分布的,所有的本地存储器构成了全局地址空间。NUMA与UMA的区别在于处理器访问本地存储器和群内共享存储器比访问远程存储器或全局共享存储器快。 13、COMA COMA是Cache-Only Memory Architecture(全高速缓存存储结构)模型的缩写。COMA 实际是NUMA的一种特例,将NUMA中的分布存储器换成高速缓存就得到了COMA。在COMA 中,每个结点上没有存储层次结构,所有的高速缓存构成了全局地址空间。访问远程高速缓存要借助分布的高速缓存目录。 14、CC-NUMA CC-NUMA是Cache-Coherent Nonuniform Memory Access(高速缓存一致性非均匀存储访问)模型的缩写。CC-NUMA结构的并行机实际上是将一些SMP机作为结点互连起来而构成的并行机,绝大多数商用CC-NUMA多处理机系统使用基于目录的高速缓存一致性协议;它的存储器在物理上是分布的,所有的局部存储器构成了共享的全局地址空间。 15、NORMA NORMA是No-Remote Memory Access(非远程存储访问)模型的缩写。在NORMA 中,所有的存储器都是处理器私有的,仅能由其处理器访问。各处理器之间通过消息传递方式通信。 16、静态网络(Static Networks)静态网络是指结点间有着固定连接通路且在程序执行期间,这种连接保持不变的网络 17、动态网络(Dynamic Networks)动态网络是用开关单元构成的,可按应用程序的要求动态地
学习fluent(流体常识及软件计算参数设置)
luent 中一些问题( 目录) 1 如何入门 2 CFD 计算中涉及到的流体及流动的基本概念和术语 2.1 理想流体( Ideal Fluid )和粘性流体( Viscous Fluid ) 2.2 牛顿流体( Newtonian Fluid )和非牛顿流体( non-Newtonian Fluid ) 2.3 可压缩流体( Compressible Fluid )和不可压缩流体( Incompressible Fluid ) 2.4 层流( Laminar Flow )和湍流( Turbulent Flow ) 2.5 定常流动( Steady Flow )和非定常流动( Unsteady Flow ) 2.6 亚音速流动(Subsonic) 与超音速流动( Supersonic ) 2.7 热传导( Heat Transfer )及扩散( Diffusion ) 3 在数值模拟过程中,离散化的目的是什么?如何对计算区域进行离散化?离散化时通常使用哪些网格?如何对控制方程进行离散?离散化常用的方法有哪些?它们有什么不同? 3.1 离散化的目的 3.2 计算区域的离散及通常使用的网格 3.3 控制方程的离散及其方法 3.4 各种离散化方法的区别 4 常见离散格式的性能的对比(稳定性、精度和经济性) 5 流场数值计算的目的是什么?主要方法有哪些?其基本思路是什么?各自的适用范围是什么? 6 可压缩流动和不可压缩流动,在数值解法上各有何特点?为何不可压缩流动在求解时反而比可压缩流动有更多的困难? 6.1 可压缩Euler 及Navier-Stokes 方程数值解 6.2 不可压缩Navier-Stokes 方程求解 7 什么叫边界条件?有何物理意义?它与初始条件有什么关系? 8 在数值计算中,偏微分方程的双曲型方程、椭圆型方程、抛物型方程有什么区别? 9 在网格生成技术中,什么叫贴体坐标系?什么叫网格独立解? 10在GAMBIT中显示的“check主要通过哪几种来判断其网格的质量?及其在做网格时大致注意到哪些细节? 11 在两个面的交界线上如果出现网格间距不同的情况时,即两块网格不连续时,怎么样克服这种情况呢? 12 在设置GAMBIT 边界层类型时需要注意的几个问题:a 、没有定义的边界线如何处理? b、计算域内的内部边界如何处理( 2D)? 13 为何在划分网格后,还要指定边界类型和区域类型?常用的边界类型和区域类型有哪 些? 14 20 何为流体区域( fluid zone )和固体区域( solid zone )?为什么要使用区域的概念?FLUENT 是怎样使用区域的? 15 21 如何监视FLUENT 的计算结果?如何判断计算是否收敛?在FLUENT 中收敛准则是 如何定义的?分析计算收敛性的各控制参数,并说明如何选择和设置这些参数?解决不收
第7章 蒙特卡罗方法 (附录)
第7章附录 7.2.1 均匀分布随机数 例题7.2.1计算程序 ! rand1.for program rand1 implicit none real r integer n,c,x,i open(5,file='rand1.txt') n = 32768 c = 889 x = 13 do i = 1,1000 x = c*x-n*int(c*x/n) r = real(x)/(n-1) write(5,'(f8.5)') r end do end !!!!!!rand2.for!!!!! program rand2 implicit none integer, parameter :: n=1000 integer ix,i real r open(5,file='rand2.txt') ix=32765 do i=1,n call rand(ix,r) write(5,'(f8.6)') r end do end program rand2 subroutine rand(ix,r) i=ix*259 ix=i-i/32768*32768 r=float(ix)/32768 return end
7.2.3 随机抽样 例题7.2.2计算程序 % 例题7_2_2.m figure(1); set(gca,'FontSize',16); t = rand(1000,1); y = -log(t); z = exp(-y); plot(y,z,'.'); xlabel('图7.2-2 例题7.2.2-指数分布抽样') ==================================================== 例题7.2.5计算程序 ! 例题7.2.5 program scores parameter(nmax=10,mmax=13) real(8) x(nmax),y(nmax),l(0:nmax),z(mmax),ys(mmax),r integer i,j,k data x/5.0,15.0,25.0,35.0,45.0,55.0,65.0,75.0,85.0,95.0/ data y/0,0,0,0,0.08,0.19,0.31,0.27,0.11,0.04/ open(2,file='scores_old.txt') open(5,file='scores_new.txt') ! mmax个抽样学生成绩 open(7,file='scores_sample.txt') write(2,'(2f15.5)') (x(i),y(i),i=1,nmax) ix=32765 l(0)=0 do i=1,nmax l(i)=l(i-1)+y(i) end do do j=1,mmax call rand(ix,r) do k=1,nmax if(r.le.l(k)) goto 11 end do 11 z(j)=x(k) end do write(5,*) (z(i),i=1,mmax) ys=0 do i=1,mmax k=z(i)/float(nmax) ! 确定抽样学生所在的分数段
第2章 fluent的计算步骤
FLUENT6.1全攻略 第二章 FLUENT的计算步骤 本章通过一个稍微复杂一些的算例再次演示FLUENT的求解过程。这个算例的内容是计算一个二维弯管中的湍流流动和热传导过程,在这个算例中可以看到FLUENT计算的标准流程,其中包括: (1)如何读入网格文件。 (2)如何使用混合的单位制定义几何模型和物质属性。 (3)如何设定边界条件和和物质属性。 (4)如何初始化计算并用残差曲线监视计算进程。 (5)如何用分离求解器计算流场。 (6)如何用FLUENT的图形显示功能检查流场。 (7)如何用二阶精度离散格式获得更高精度的流场。 (8)以温度梯度为基准调整网格以提高对温度场的计算精度。 2.1 问题概述 图2-1 弯管流动图示 如图2-1所示,温度为26℃的冷流体流过弯管,温度为40℃的热流体从转弯处流入, 1
FLUENT6.1全攻略 并与主流中的冷流体混合。管道的尺寸如图2-1所示,单位为英寸,而边界条件和流体材料性质则采用国际单位制。入口处的雷诺数为2.03 x 105,因此必须使用湍流模型。 2.2 处理网格 网格处理包括网格的输入、检查、光顺、比例转换和显示等操作,下面分别进行介绍。 2.2.1读入网格文件 首先启动FLUENT的2D版,然后读入网格文件: File -> Read -> Case... 这个算例的网格文件可以在FLUENT6.1为用户提供的文档光盘中找到,路径是: cdrom:\fluent6.1\help\tutfiles\elbow\elbow.msh 2.2.2检查网格 执行下列菜单操作,进行网格检查: Grid -> Check 此时控制台窗口中会显示与网格有关的信息,包括网格空间范围、体积信息、表面积信息、节点信息等等。网格中存在的任何错误都会出现在这个信息报告中,其中最需要检查的是网格单元的体积不能为负值,否则计算将无法继续下去。 图2-2 Smooth/Swap Grid(光顺/转换网格)面板 2
FLUENT全参数设置(新手)
4月1日 写给Fluent新手(续) 31数值模拟过程中,什么情况下出现伪扩散的情况?以及对于伪扩散在数值模拟过程中如何避免? 假扩散(false diffusion)的含义: 基本含义:由于对流—扩散方程中一阶导数项的离散格式的截断误差小于二阶而引起较大数值计算误差的现象。有的文献中将人工粘性(artificial viscosity)或数值粘性(numerical viscosity)视为它的同义词。 拓宽含义:现在通常把以下三种原因引起的数值计算误差都归在假扩散的名称下 1.非稳态项或对流项采用一阶截差的格式; 2.流动方向与网格线呈倾斜交叉(多维问题); 3.建立差分格式时没有考虑到非常数的源项的影响。 克服或减轻假扩散的格式或方法, 为克服或减轻数值计算中的假扩散(包括流向扩散及交叉扩散)误差,应当: 1. 采用截差阶数较高的格式; 2. 减轻流线与网格线之间的倾斜交叉现象或在构造格式时考虑到来流方向的影响。 3. 至于非常数源项的问题,目前文献中,还没有为克服这种影响而专门构造的格式,但是高阶格式显然对减轻其影响是有利的。 32 FLUENT轮廓(contour)显示过程中,有时候标准轮廓线显示通常不能精确地显示其细节,特别是对于封闭的3D物体(如柱体),其原因是什么?如何解决? FLUENT等高线(contour)显示过程中,可以通过调节显示的水平等级来调节其显示细节,Levels...最大值允许设置为100.对于封闭的3D物体,可以通过建立Surface,监视Surface上的量来显示计算结果。或者计算之后将结果导入到Tecplot中,作切片图显示。