数据分析练习题
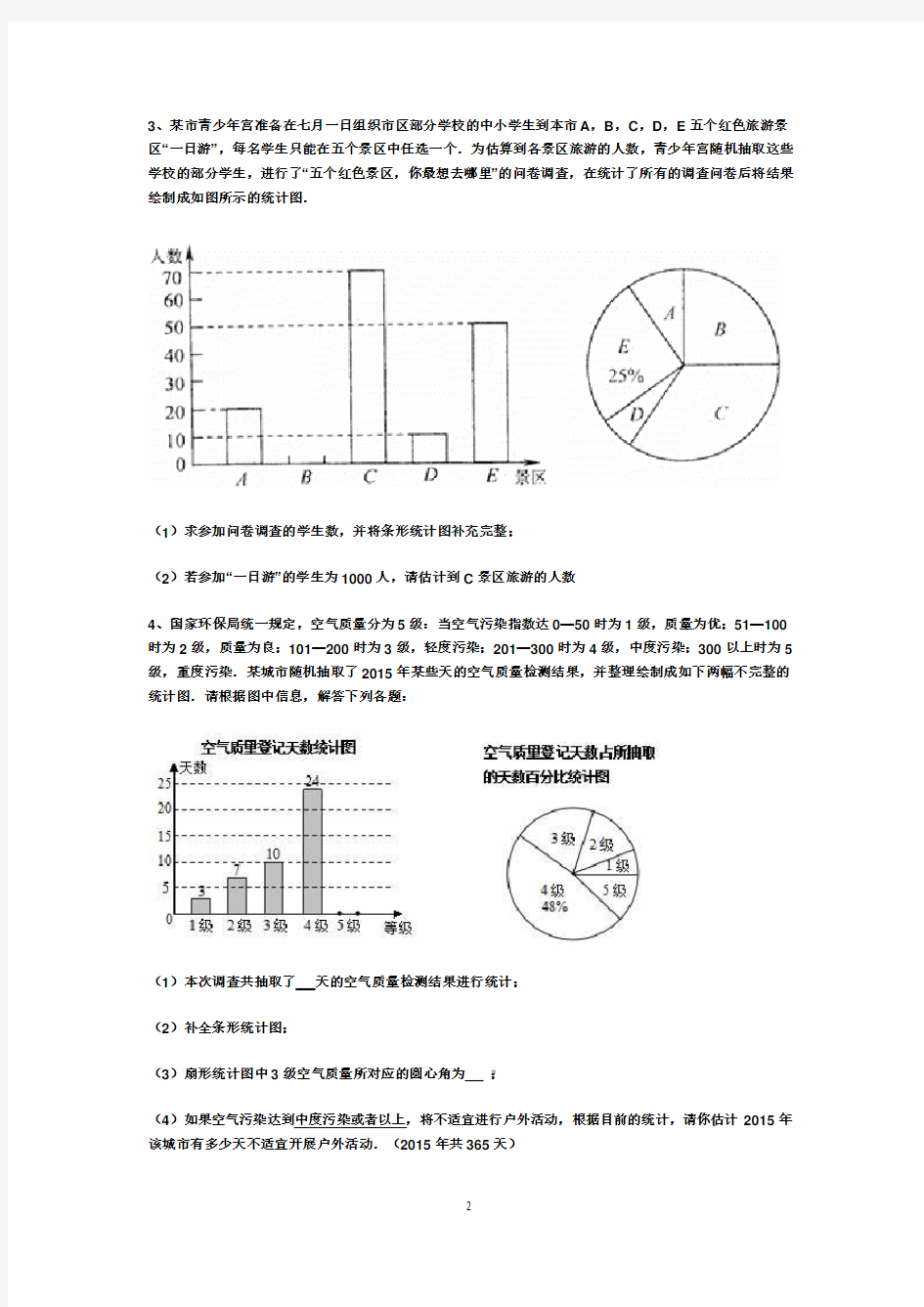
数据分析练习题 第 小组 姓名: 练习一: 1、老师在计算学期总平均分的时候按如下标准:作业占100%、测验占30%、期中占35%、期末考试占35% x 小关 = . x 小兵 = . 2、结果如下表:(单位:小时) 求这些灯泡的平均使用寿命? . x = .小时 3、在一个样本中,2出现了x 1次,3出现了x 2次,4出现了x 3次,5出现了x 4次,则这个样本的平均数为 . 4、某人打靶,有a 次打中x 环,b 次打中y 环,则这个人平均每次中靶 环。 5、某校为了了解学生作课外作业所用时间的情况,对学生作课外作业所用时间进行调查,下表是该校初二某班50名学生某一天做数学课外作业所用时间的情况统计表 (1)、第二组数据的组中值是多少? (2)、求该班学生平均每天做数学作业所用时间 答:(1)组中值为: . (2)解: 6、某公司有15名员工,他们所在的部门及相应每人所创的年利润如下表该公司每人所创年利润的平均数是多少万元?
7、为调查居民生活环境质量,环保局对所辖的50个居民区进行了噪音(单位:分贝)水平的调查,结果如下图,求每个小区噪音的平均分贝数。 8、某公司销售部有营销人员15人,销售部为了制定某种商品的销售金额,统计了这15个人的销售量如下(单位:件) 1800、510、250、250、210、250、210、210、150、210、150、120、120、210、150 求这15个销售员该月销量的中位数和众数。 假设销售部负责人把每位营销员的月销售定额定为320件,你认为合理吗?如果不合理,请你制定一个合理的销售定额并说明理由。 练习二: 1. 数据8、9、9、8、10、8、99、8、10、7、9、9、8的中位数是 ,众数是 2. 一组数据23、27、20、18、X 、12,它的中位数是21,则X 的值是 . 3. 数据92、96、98、100、X 的众数是96,则其中位数和平均数分别是( ) A.97、96 B.96、96.4 C.96、97 D.98、97 4. 如果在一组数据中,23、25、28、22出现的次数依次为2、5、3、4次,并且没有其他的数据, 则这组数据的众数和中位数分别是( ) A.24、25 B.23、24 C.25、25 D.23、25 请你根据上述数据回答问题: (1).该组数据的中位数是什么? (2).若当气温在18℃~25℃为市民“满意温度”,则我市一年中达到市民“满意温度”的大约有多少天? 60 噪音/分贝 80 70 50 40 90
人民卫生出版社第七版-误差与数据分析处理习题答案
第二章 1.属于方法误差的有:④⑦⑩;仪器误差:①②③⑨;操作误差:⑥;偶然误差:⑧; 试剂误差:⑤ 5. ① 4 2.52 4.1015.14 6.1610 ???=2.54×10-3 此题中2.52的相对误差最大,因此计算结果应修约为三位有效数字。 ② 61090.20001120 .0325 0001120.010.514.2101.3?==?? 有效位数保留原理同上。 ③ 4 51.0 4.0310 4.022.5120.002034=-??? ④ 2 0.03248.1 2.121053.01.050 =??? 此题中8.1的相对误差最大,以8.1的有效数字作为修约标准,又因为8.1的第一个有效数字为8,其相对误差的大小和三位有效数字的相对误差近似,因此可认为8.1的有效数字为三位有效数字,结果保留三位有效数字。 ⑤ 32.2856 2.51 5.42 1.89407.5010 5.738 5.420.0142 3.5462 3.546211.14 3.1413.546 -?+-??+-= == ⑥pH=2.10,求[H +]=? 由于pH 值为对数值,所以2.10的有效数字为两位有效数字,故 [H +]=7.9×10-3mol.L -1 6. 解:根据n i=1 d=-∑i x x n 和准偏差, ①第一组1d 0.24=1,S =0.28,第二组的2d 0.24=2,S =0.31。 ②两组数据的平均偏差相等但标准偏差不相等,这是因为标准偏差可以反映出数据中较大
偏差对测定结果重复性的影响。 ③由于第一组的标准偏差较小,因此这组数据的精密度更高。 7.测定碳的原子量所得数据:12.0080、12.0095、12.0099、12.0101、12.0102、12.0106、12.0111、12.0113、12.0118及12.0120。求算:(1)平均值;(2)标准偏差;(3)平均值的标准偏差;(4)平均值在99%置信水平的置信限。 解 0104.1210 12.012012.011812.011312.011112.010612.010212.010112.00992.0095112.0080=+++++++++= X (3) (4) 置信限为: 0012 .010 0012.0250.3250 .3,9,01.0,=? ===n S t t t f f αα 8. 13 .05 11 .001.0 20.014.011.005.051 .1640 .152.171.137.162.146.12 2 2 2 2 2 =+++++= =+++++=S X 7.1613 .051 .160.1=?-= t 查表得t 0.05,5=2.571 t 计<t 0.05,5 故无显著性差异。 9.解(1)计算统计量 HPLC 法:n 1=6, 1X =98.3%, s 1=1.10 化学法:n 2=5, 2X =97.5%, s 2=0.540
定量分析的误差和分析结果的数据处理习题
第五章 定量分析的误差和分析结果的数据处理习题 1.是非判断题 1-1将、、和处理成四位有效数字时,则分别为、、和。 1-2 pH=的有效数字是四位。 1-3 [HgI 4]2-的lg 4θβ=,其标准积累稳定常数4θβ为×1030 。 1-4在分析数据中,所有的“0”均为有效数字。 1-5有效数字能反映仪器的精度和测定的准确度。 1-6欲配制·L -1K 2Cr 2O 7(M=·mol -1 )溶液,所用分析天平的准确度为+,若相对误差要求为 ±%,则称取K 2Cr 2O 7时称准至。 1-7从误差的基本性质来分可以分为系统误差,偶然误差和过失误差三大类。 1-8误差的表示方法有两种,一种是准确度与误差,一种是精密度与偏差。 1-9相对误差小,即表示分析结果的准确度高。 1-10偏差是指测定值与真实值之差。 1-11精密度是指在相同条件下,多次测定值间相互接近的程度。 1-12系统误差影响测定结果的准确度。 1-13测量值的标准偏差越小,其准确度越高。 1-14精密度高不等于准确度好,这是由于可能存在系统误差。控制了偶然误差,测定的 精密度才会有保证,但同时还需要校正系统误差,才能使测定既精密又准确。 1-15随机误差影响到测定结果的精密度。 1-16对某试样进行三次平行测定,得平均含量%,而真实含量为%,则其相对误差为%。 1-17随机误差具有单向性。 1-18某学生根据置信度为95%对其分析结果进行处理后,写出报告结果为+%,该报告的结 果是合理的。 1-19置信区间是指测量值在一定范围的可能性大小,通常用百分数表示。 1-20在滴定分析时,错误判断两个样液滴定终点时指示剂的颜色的深浅属于工作过失。 2.选择题. 2-1下列计算式的计算结果(x)应取几位有效数字:x=[×× A.一位 B.二位 C.三位 D.四位
统计分析练习题
《统计分析在Excel 中的实现》练习题 1.Excel 中提供了常用的内置函数包括__________、__________、__________等。 2. 在Excel 中制作问卷,可使用________令用户选择的结果自动填入指定位置的单元格。 3. 饼图可以展示________个数据序列。 4. _________可以用于表明针对某个社会现象的观测值在一定时间、地点条件下达到的一般水平,概括总体的数量特征。 5. 抽样方法有__________、_______________两大类。 6. 根据显著性水平得到相应的检验统计量的数值称为_________。 7. 用来衡量因素在不同水平下不同样本之间的误差叫做 _________。 8 回归分析的内容主要包括确定自变量和因变量、 _________________、_____________和预测与估计。 9 . 同一现象在不同时间的相继观测值排列而成的序列称为 __________。一.填空题: 二、选择题 1. 以下关于Excel 数据处理与分析的描述,说法不正确的是( )。 A.Excel 不仅可以利用公式进行简单的代数运算,还可以用于复杂的数学模型的分析 B. 存放在记事本中的数据,无论是否有结构,可以一次性导入为Excel 数据表
C.Excel 可以通过手动、公式生成和复制生成的方式输入数据 D.Excel 绘图功能可以根据选定的统计数据绘制统计图 2. 为了调查某学校学生的上网时间,从一年级中抽取80名学生调查,从二年级学生中抽取50名学生调查,这种调查方法是( )。 A. 简单随机抽样 B. 整群抽样 C. 系统抽样 D. 分层抽样 3. 以下关于Excel 制图的描述不正确的是( )。 A.Excel 中可以制作曲面图、面积图、气泡图等多种类型图表 B. 制作图表时,往往需要对原始数据进行调整,以符合Excel 制图对数据摆放的要求 1 C. 股价图只可以用于金融股市数据的显示,无法显示其他类型数据 D. 以上都正确 4. 反映数据分布离中趋势最主要的指标值是( ) 。 A. 全距 B. 方差 C. 标准差 D. 离散系数 5. 估计量是指( ) 。 A. 用来估计总体参数的统计量名称 B. 用来估计总体参数的统计量的具体数值 C. 总体参数的名称 D. 总体参数的具体数值 6. 假设检验是检验下列哪个假设值的成立情况的?() A. 样本指标 B. 总体指标 C. 样本方差 D. 样本平均数 7. 方差分析的目的是判断()。
第2章 数据分析(梅长林)习题题答案
第2章 习 题 一、习题 (1)回归模型 15,2,1,22110 =+++=i x x y i i i i εβββ 调用proc reg : ] 由此输出得到的回归方程为: 2100920.049600.045261.3X X y ++=∧ 由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显著影响。46521.30=∧ β可以理解为该化妆品作为一种必需品每个月的销售量。当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。 p n SSE -= ∧2 σ 是2σ的无偏估计,所以2σ的估计值是. (2)调用 由此可到线性回归关系显著性检验: 0至少有一个为0:2,1:1210ββββH H ?==
的统计量/(1)/()SSR p MSR F SSE n p MSE -= =-的观测值47.56790=F ,检验的p 值 0001.0)(000<>==F F p p H 另外9989.053902 53845 2=== SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。2R 越大,表明线性关系越明显。这些结果均表明Y 与X1,X2之间的回归关系高度显著。 (3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得 到21,0,βββ的置信区间分别为: 对,0β2942.54516.343065.21781.245216.3±=?±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=?±,即)50198.0,48282.0( ) 2β:0021 .000920.00009681.01781.200920.0±=?±,即)00113.0,0071.0(- (4)首先检验X1对Y 是否有显著性影: 假设其约简模型为:15,2, 1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 3 .9012/88357.5688357 .5688137.4840=-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。 ~ 同理检验X2对Y 是否有显著性影: 假设其约简模型为:15,2, 1,110 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得: 31872)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f 由[()()]() ()/R F F SSE R SSE F f f F SSE F f --= 求得检验统计量的值为: 12/88357.5688357.56318720-= F 05.0))13,1(()(0000<>==>==F F P F F p p H 由此拒绝原假设,所以x2对Y 有显著影响。
误差和分析数据处理习题
第二章误差和分析数据处理习题 一、最佳选择题 1. 如果要求分析结果达到0.1%的准确度,使用灵敏度为0.1mg的天平称取试样时,至少应称取() A. 0.1g B. 0.2g C. 0.05g D. 0.5g 2. 定量分析结果的标准偏差代表的是()。 A. 分析结果的准确度 B. 分析结果的精密度和准确度 C. 分析结果的精密度 D. 平均值的绝对误差 3. 对某试样进行平行三次测定,得出某组分的平均含量为30.6% ,而真实含量为30.3% ,则30.6%-30.3%=0.3% 为() A. 相对误差 B. 绝对误差 C. 相对偏差 D. 绝对偏差 4. 下列论述正确的是:() A. 准确度高,一定需要精密度好; B. 进行分析时,过失误差是不可避免的; C. 精密度高,准确度一定高; D. 精密度高,系统误差一定小; 5. 下面哪一种方法不属于减小系统误差的方法() A. 做对照实验 B. 校正仪器 C. 做空白实验 D. 增加平行测定次数 6. 下列表述中,最能说明系统误差小的是( ) A. 高精密度 B. 与已知的质量分数的试样多次分析结果的平均值一致 C. 标准差大 D. 仔细校正所用砝码和容量仪器等 7. 用下列何种方法可减免分析测定中的系统误差() A. 进行仪器校正 B. 增加测定次数 C. 认真细心操作 D. 测定时保证环境的湿度一致 8. 下列有关偶然误差的论述中不正确的是() A.偶然误差是由一些不确定的偶然因素造成的; B.偶然误差出现正误差和负误差的机会均等; C.偶然误差在分析中是不可避免的; D.偶然误差具有单向性
9. 滴定分析中出现下列情况,属于系统误差的是:() A. 滴定时有溶液溅出 B. 读取滴定管读数时,最后一位估测不准 C. 试剂中含少量待测离子 D. 砝码读错 10. 某一称量结果为0.0100mg, 其有效数字为几位?() A . 1 位 B. 2 位 C. 3 位 D. 4 位 11. 测的某种新合成的有机酸pK a值为12.35,其K a值应表示为() A. 4.467×10 -13; B. 4.47×10 -13; C.4.5×10 -13; D. 4×10 -13 12. 指出下列表述中错误的表述( A ) A. 置信水平愈高,测定的可靠性愈高 B. 置信水平愈高,置信区间愈宽 C. 置信区间的大小与测定次数的平方根成反比 D. 置信区间的位置取决于测定的平均值 13. 下列有关置信区间的描述中,正确的有:( A ) A. 在一定置信度时,以测量值的平均值为中心的包括真值的范围即为置信区间 B. 真值落在某一可靠区间的几率即为置信区间 C. 其他条件不变时,给定的置信度越高,平均值的置信区间越宽 D. 平均值的数值越大,置信置信区间越宽 14. 分析测定中,使用校正的方法,可消除的误差是( )。 A. 系统误差 B. 偶然误差 C. 过失误差 D. 随即误差 15. 关于t分布曲线和正态分布曲线形状的叙述,正确的是:( ) A. 形状完全相同,无差异; B. t分布曲线随f而变化,正态分布曲线随u而变; C. 两者相似,而t分布曲线随f而改变; D. 两者相似,都随f而改变。 16. ) 457 .2 1. 17 /( ) 25751 .0 83 .2 5. 472 (+ ? ? = y的计算结果应取有效数字的位数是( ) A. 3位 B. 4位 C. 5位 D. 6位 17. 以下情况产生的误差属于系统误差的是( )。 A. 指示剂变色点与化学计量点不一致; B. 滴定管读数最后一位估测不准; C. 称样时砝码数值记错; D. 称量过程中天平零点稍有变动。 18. 下列数据中有效数字不是四位的是( )。 A. 0.2400 B. 0.0024 C. 2.004 D. 20.40 19. 在定量分析中,精密度与准确度之间的关系是( )。
第三章 误差和分析数据的处理作业及答案(1)
第三章 误差和分析数据的处理 作业及答案 一、选择题(每题只有1个正确答案) 1. 用加热挥发法测定BaCl 2·2H 2O 中结晶水的质量分数时,使用万分之一的分析天平称样0.5000g ,问测定结果应以几位有效数字报出?( D ) [ D ] A. 一位 B. 二位 C .三位 D. 四位 2. 按照有效数字修约规则25.4507保留三位有效数字应为( B )。 [ B ] A. 25.4 B. 25.5 C. 25.0 D. 25.6 3. 在定量分析中,精密度与准确度之间的关系是( C )。 [ C ] A. 精密度高,准确度必然高 B. 准确度高,精密度不一定高 C. 精密度是保证准确度的前提 D. 准确度是保证精密度的前提 4. 以下关于随机误差的叙述正确的是( B )。 [ B ] A. 大小误差出现的概率相等 B. 正负误差出现的概率相等 C. 正误差出现的概率大于负误差 D. 负误差出现的概率大于正误差 5. 可用下列何种方法减免分析测试中的随机误差( D )。 [ D ] A. 对照实验 B. 空白实验 C. 仪器校正 D. 增加平行实验的次数 6. 在进行样品称量时,由于汽车经过天平室附近引起天平震动产生的误差属于( B )。 [ B ] A. 系统误差 B. 随机误差 C. 过失误差 D. 操作误差 7. 下列表述中,最能说明随机误差小的是( A )。 [ A ] A. 高精密度 B. 与已知含量的试样多次分析结果的平均值一致 C. 标准偏差大 D. 仔细校正所用砝码和容量仪器 8. 对置信区间的正确理解是( B )。 [ B ] A. 一定置信度下以真值为中心包括测定平均值的区间 B. 一定置信度下以测定平均值为中心包括真值的范围 C. 真值落在某一可靠区间的概率 D. 一定置信度下以真值为中心的可靠范围 9. 有一组测定数据,其总体标准偏差σ未知,要检验得到这组分析数据的分析方法是否准确可靠,应该用( C )。 [ C ] A. Q 检验法 B. G(格鲁布斯)检验法 C. t 检验法 D. F 检验法 答:t 检验法用于测量平均值与标准值之间是否存在显著性差异的检验------准确度检验 F 检验法用于两组测量内部是否存在显著性差异的检验-----精密度检验 10 某组分的质量分数按下式计算:10 ???= m M V c w 样,若c =0.1020±0.0001,V=30.02±0.02, M=50.00±0.01,m =0.2020±0.0001,则对w 样的误差来说( A )。 [ A ] A. 由“c ”项引入的最大 B. 由“V ”项引入的最大
最新初中数学数据分析经典测试题附答案
最新初中数学数据分析经典测试题附答案 一、选择题 1.已知一组数据a,b,c的平均数为5,方差为4,那么数据a﹣2,b﹣2,c﹣2的平均数和方差分别是.() A.3,2 B.3,4 C.5,2 D.5,4 【答案】B 【解析】 试题分析:平均数为(a?2 + b?2 + c?2 )=(3×5-6)=3;原来的方差: ;新的方差: ,故选 B. 考点:平均数;方差. 2.已知一组数据a、b、c的平均数为5,方差为4,那么数据a+2、b+2、c+2的平均数和方差分别为() A.7,6 B.7,4 C.5,4 D.以上都不对 【答案】B 【解析】 【分析】 根据数据a,b,c的平均数为5可知a+b+c=5×3,据此可得出1 3 (-2+b-2+c-2)的值;再由 方差为4可得出数据a-2,b-2,c-2的方差. 【详解】 解:∵数据a,b,c的平均数为5,∴a+b+c=5×3=15, ∴1 3 (a-2+b-2+c-2)=3, ∴数据a-2,b-2,c-2的平均数是3;∵数据a,b,c的方差为4, ∴1 3 [(a-5)2+(b-5)2+(c-5)2]=4, ∴a-2,b-2,c-2的方差=1 3 [(a-2-3)2+(b-2-3)2+(c--2-3)2] = 1 3 [(a-5)2+(b-5)2+(c-5)2]=4, 故选B.【点睛】
本题考查了平均数、方差,熟练掌握平均数以及方差的计算公式是解题的关键. 3.对于一组统计数据:1,1,4,1,3,下列说法中错误的是() A.中位数是1 B.众数是1 C.平均数是1.5 D.方差是1.6 【答案】C 【解析】 【分析】 将数据从小到大排列,再根据中位数、众数、平均数及方差的定义依次计算可得答案.【详解】 解:将数据重新排列为:1、1、1、3、4, 则这组数据的中位数1,A选项正确; 众数是1,B选项正确; 平均数为11134 5 ++++ =2,C选项错误; 方差为1 5 ×[(1﹣2)2×3+(3﹣2)2+(4﹣2)2]=1.6,D选项正确; 故选:C. 【点睛】 本题主要考查中位数、众数、平均数及方差,解题的关键是掌握中位数、众数、平均数及方差的定义与计算公式. 4.2022年将在北京﹣﹣张家口举办冬季奥运会,很多学校为此开设了相关的课程,下表记录了某校4名同学短道速滑成绩的平均数x和方差S2,根据表中数据,要选一名成绩好又发挥稳定的运动员参加比赛,应选择() A.队员1 B.队员2 C.队员3 D.队员4 【答案】B 【解析】 【分析】 根据方差的意义先比较出4名同学短道速滑成绩的稳定性,再根据平均数的意义即可求出答案.
数据分析师常见的7道笔试题目及答案
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。以下是由小编为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map 进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP 中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP 日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含 100 个结点的最小堆),并把100
数据分析经典测试题含答案解析
数据分析经典测试题含答案解析 一、选择题 1.某校九年级数学模拟测试中,六名学生的数学成绩如下表所示,下列关于这组数据描述正确的是() A.众数是110 B.方差是16 C.平均数是109.5 D.中位数是109 【答案】A 【解析】 【分析】 根据众数、中位数的概念求出众数和中位数,根据平均数和方差的计算公式求出平均数和方差. 【详解】 解:这组数据的众数是110,A正确; 1 6 x=×(110+106+109+111+108+110)=109,C错误; 21 S 6 = [(110﹣109)2+(106﹣109)2+(109﹣109)2+(111﹣109)2+(108﹣109)2+ (110﹣109)2]=8 3 ,B错误; 中位数是109.5,D错误; 故选A. 【点睛】 本题考查的是众数、平均数、方差、中位数,掌握它们的概念和计算公式是解题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5,
则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.如图,是根据九年级某班50名同学一周的锻炼情况绘制的条形统计图,下面关于该班50名同学一周锻炼时间的说法错误的是() A.平均数是6 B.中位数是6.5 C.众数是7 D.平均每周锻炼超过6小时的人数占该班人数的一半 【答案】A 【解析】 【分析】 根据中位数、众数和平均数的概念分别求得这组数据的中位数、众数和平均数,由图可知锻炼时间超过6小时的有20+5=25人.即可判断四个选项的正确与否. 【详解】 A、平均数为1 50 ×(5×7+18×6+20×7+5×8)=6.46,故本选项错误,符合题意; B、∵一共有50个数据, ∴按从小到大排列,第25,26个数据的平均值是中位数, ∴中位数是6.5,故此选项正确,不合题意; C、因为7出现了20次,出现的次数最多,所以众数为:7,故此选项正确,不合题意; D、由图可知锻炼时间超过6小时的有20+5=25人,故平均每周锻炼超过6小时的人占总数的一半,故此选项正确,不合题意; 故选A. 【点睛】 此题考查了中位数、众数和平均数的概念等知识,中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数,如果中位数的概念掌握得不好,不把数据按要求重新排列,就会错误地将这组数据最中间的那个数当作中位数.
数据分析与处理答案
一、简答题(5×2分,共10分) 1、请解释质量控制图中三条主要控制线的意义:CL、UCL、LCL 未学,不考 2、请解释正交设计表“L934”这个符号所指代的意义。如果要做6因素4水平实验,应该选择以下哪一个正交表(不考虑交互作用):L1645,L3249 L: 正交;9:9行或9次实验;3:3个水平;4:4列或4个因素 选L3249 二、计算题(90分) 1、某分析人员分别进行4次平行测定,得铅含量分别是、、、、,试分别用3s法、Dixon法和 Grubbs检验法判断是否为离群值。(,4=,,5=)(12分) x=, s=, 3s法:∣应保留 Dixon : 70.6360.08 0.896 71.8560.08 Q - == - > ,5=, 应舍去 Grubbs: G计= 60.0868.455/5.61 -=> ,4,应舍去···2、4次测定结果为:%、%、%、%,根据这些数据估计此样品中铬的含量范围(P=95%)?
(8分) ( 2.353%903,10.0=?=t P , 3.182%9530.05=?=,t P , 5.841%9930.01=?=,t P ) x =%, s=% 1.135 3.1820.0238/ 1.1350.038μ=±?=± 3、用一种新方法测定标准试样中的氧化铁含量(%),得到以下8个数据:、、、、、、、。标准偏差为%,标准值为%问这种新方法是否可靠(P=95%,,7=) (10分) x = 34.3034.33 1.770.048 t -==< ,7,所以新方法可靠 4、某小组做加标回收试验考查方法的准确性,测得加标前1000mL 样品浓度为L ,加入浓度为1000mg/L 的标准样品后,测得样品总浓度为L ,求回收率是多少。(8分) 没讲,不考 5、两分析人员测定某试样中铁的含量,得到如下结果: 已知A 的标准偏差s 1=,B 的标准偏差s 2=,请比较两个人测定结果的精密度和准确的有无显着性差异。(12分) F (,4,4)=, t (,8)= F==< F (,4,4),故精密度无显着性差异 t=< t (,8),故准确度无显着性差异