结构方程模型估计案例

应用案例1
第一节模型设定
结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
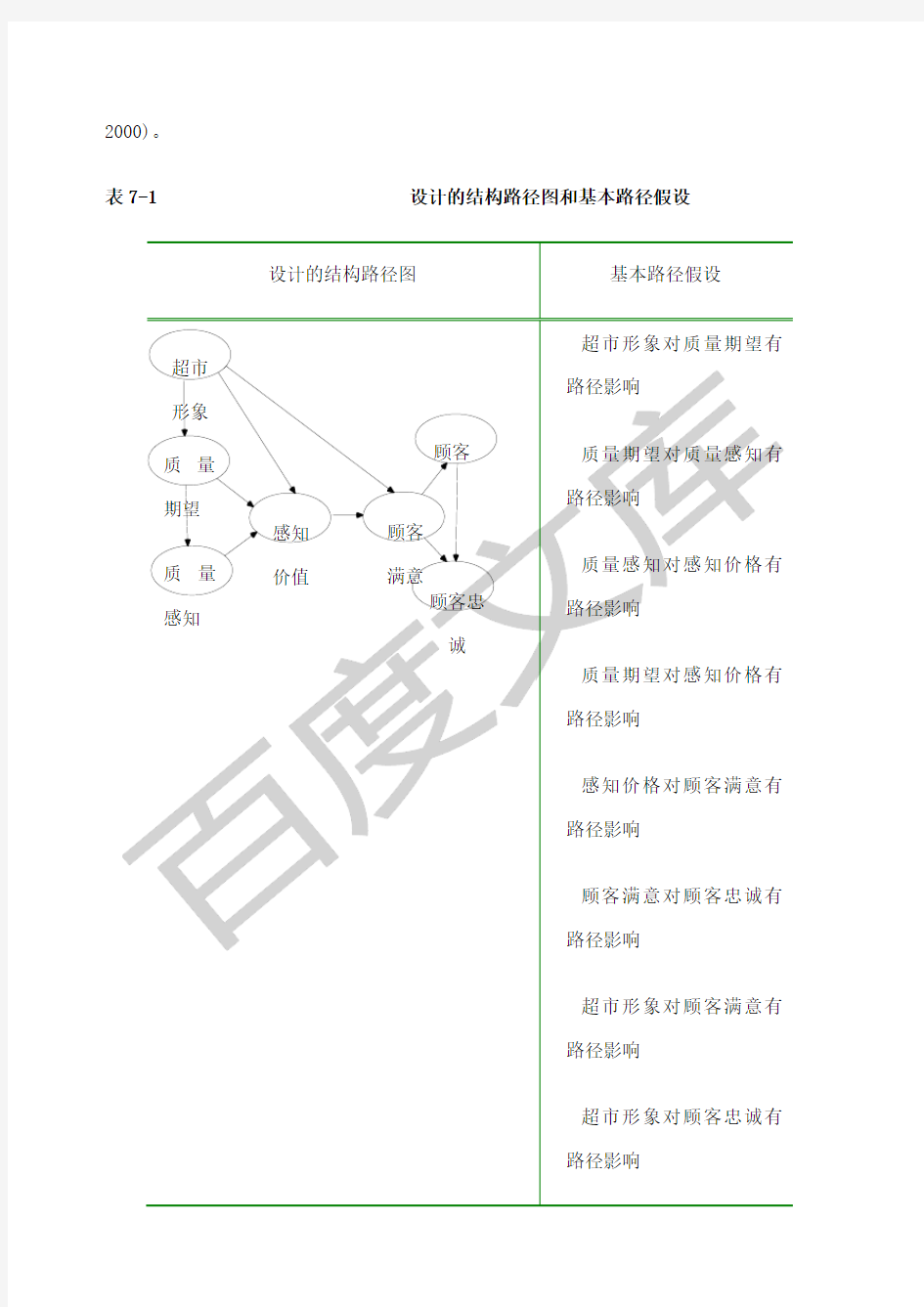
2000)。
表7-1 设计的结构路径图和基本路径假设
超市形象对质量期望有
路径影响
质量期望对质量感知有
路径影响
质量感知对感知价格有
路径影响
质量期望对感知价格有
路径影响
感知价格对顾客满意有
路径影响
顾客满意对顾客忠诚有
路径影响
超市形象对顾客满意有
路径影响
超市形象对顾客忠诚有
路径影响
2.1、顾客满意模型中各因素的具体范畴
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2 模型变量对应表
某超市总体形象的评价(a1)
与其它超市相比的形象(a2)
与其它超市相比的品牌知名度
(a3)
购物前,对某超市整体服务的期望
(a4)
购物前,期望某超市商品的新鲜程
度达到的水平(a5)
购物前,期望某超市营业时间安排
合理程度(a6)
购物前,期望某超市员工服务态度
达到的水平(a7)
购物前,期望某超市结账速度达到的水平(a8)
购物后,对某超市整体服务的满意程度(a9)
购物后,认为某超市商品的新鲜程度达到的水平(a10)
购物后,认为超市营业时间安排合理程度(a11)
购物后,认为某超市员工服务态度达到的水平(a12)
购物后,认为某超市结账速度达到的水平(a13)
您认为某超市商品的价格如何(a14)
与其他超市相比,您认为某超市商品的价格如何(a15)
对某超市的总体满意程度(a16)
和您消费前的期望比,您对某超市
的满意程度(a17)
和您心目中的超市比,您对某超市
的满意程度(a18)
您对某超市投诉的频率(包括给超
市写投诉信和直接向超市人员反
映)(a19)
您对某超市抱怨的频率(私下抱怨
并未告知超市)(a20)
您认为某超市对顾客投诉的处理
效率和效果4(a21)
4正向的,采用Likert10级量度从“非常低”到“非常高”
我会经常去某超市(a22)
我会推荐同学和朋友去某超市
(a23)
如果发现某超市的产品或服务有
问题后,能以谅解的心态主动向超
市反馈,求得解决,并且以后还会
来超市购物(a24)
级量
3
您认为与其它校内超市相比,某超市品牌
知名度如何1 2 3 4 5 6 7 8 9 10
本次调查共发放问卷500份,收回有效样本436份。
四、缺失值的处理
采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。最终得到401条数据,基于这部分数据做分析。
五、数据的的信度和效度检验
1.数据的信度检验
信度(reliability)指测量结果(数据)一致性或稳定性的程度。一致性主要反映的是测验内部题目之间的关系,考察测验的各个题目是否测量了相同的内容或特质。稳定性是指用一种测量工具(譬如同一份问卷)对同一群受试者进行不同时间上的重复测量结果间的可靠系数。如果问卷设计合理,重复测量的结果间应该高度相关。由于本案例并没有进行多次重复测量,所以主要采用反映内部一致性的指标来测量数据的信度。
折半信度(split-half reliability)是将测量工具中的条目按奇偶数或前后分成两半,采用Spearman-brown公式估计相关系数,相关系数高提示内部一致性好。然而,折半信度系数是建立在两半问题条目分数的方差相等这一假设基础上的,但实际数据并不一定满足这一假定,因此信度往往被低估。Cronbach在1951年提出了一种新的方法(Cronbach's Alpha系数),这种方法将测量工具中任一条目结果同其他所有条目作比较,对量表内部一致性估计更为慎重,因此克服了折半信度的缺点。本章采用SPSS16.0研究数据的内部一致性。在Analyze菜单中选择Scale下的Reliability Analysis(如图7-1),将数据中在左边方框中待分析的24个题目一一选中,然后点击,左边方框中待分析的24个题目进入
右边的items方框中,使用Alpha模型(默认),得到图7-2,然后点击ok即可得到如表7-3的结果,显示Cronbach's Alpha系数为0.892,说明案例所使用数据具有较好的信度。
图7-1 信度分析的选择
图7-2 信度分析变量及方法的选择
系
超市形象30.858
5操作过程同前,不同的是在图7-14中选入右边方框items中是相应潜变量对应的题目。如对超市形象潜变量,只需要把a1、a2和a3题目选入到右边方框items中即可。
质量期望
5
0.889
质量感知 5 0.862
感知价格 2 0.929
顾客满意 3 0.948
2),用其他的方式或指标与这个准则作比较,如果其他方式或指标也有效,那么这个测量即具备效标效度。例如,X 是一个变量,我们使用1
X 、2X 两种工具进行测量。如果使用1X 作为
准则,并且1X 和2X 高度相关,我们就说2X 也是具有很高的效度。当然,使用这种方法的关键在于作为准则的测量方式或指标一定要是有效的,否则越比越差。现实中,我们评价效标效度的方法是相关分析或差异显着性检验,但是在调查问卷的效度分析中,选择一个合
适的准则往往十分困难,也使这种方法的应用受到一定限制。
结构效度也称构想效度、建构效度或理论效度,是指测量工具反映概念和命题的内部结构的程度,也就是说如果问卷调查结果能够测量其理论特征,使调查结果与理论预期一致,就认为数据是具有结构效度的。它一般是通过测量结果与理论假设相比较来检验的。确定结构效度的基本步骤是,首先从某一理论出发,提出关于特质的假设,然后设计和编
效度进行考评。因此数据的效度检验就转化为结构方程模型评价中的模型拟合指数评价。对于本案例,从表7-16可知理论模型与数据拟合较好,结构效度较好。
六、结构方程模型建模
6关于标准化系数的解释见本章第五节。
构建如图7.3的初始模型。
图7-3 初始模型结构
图7-4 Amos Graphics初始界面图
第二节Amos实现7
一、Amos基本界面与工具
打开Amos Graphics,初始界面如图7-4。其中第一部分是建模区域,默认是竖版格式。如果要建立的模型在横向上占用较大空间,只需选择View菜单中的Interface Properties 选项下的Landscape(如图7.5),即可将建模区域调整为横板格式。
图7-2中的第二部分是工具栏,用于模型的设定、运算与修正。相关工具的具体功能参见书后附录二。
图7-5 建模区域的版式调整
图7-6 建立潜变量
二、Amos模型设定操作
1.模型的绘制
在使用Amos进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。相关软件操作如下:第一步,使用建模区域绘制模型中的七个潜变量(如图7-6)。为了保持图形的美观,7这部分的操作说明也可参看书上第七章第二节:Amos实现。
可以使用先绘制一个潜变量,再使用复制工具绘制其他潜变量,以保证潜变量大小一致。在潜变量上点击右键选择Object Properties,为潜变量命名(如图7-7)。绘制好的潜变量图形如图7-8。
第二步设置潜变量之间的关系。使用来设置变量间的因果关系,使用来设置变量间的相关关系。绘制好的潜变量关系图如图7-9。
图7-7 潜变量命名
图7-8 命名后的潜变量
图7-9 设定潜变量关系
第三步为潜变量设置可测变量及相应的残差变量,可以使用绘制,也可以使用
和自行绘制(绘制结果如图7-10)。在可测变量上点击右键选择Object Properties,为可测变量命名。其中Variable Name一项对应的是数据中的变量名(如图7-11),在残差变量上右键选择Object Properties为残差变量命名。最终绘制完成模型结果如图7-12。
图7-10 设定可测变量及残差变量
图7-11 可测变量指定与命名
图7-12 初始模型设置完成
2.数据文件的配置
Amos可以处理多种数据格式,如文本文档(*.txt),表格文档(*.xls、*.wk1),数据库文档(*.dbf、*.mdb),SPSS文档(*.sav)等。
为了配置数据文件,选择File菜单中的Data Files(如图7-13),出现如图7-14左
边的对话框,然后点击File name按钮,出现如图7-14右边的对话框,找到需要读入的数据文件“处理后的数据.sav”,双击文件名或点击下面的“打开”按钮,最后点击图7-14左边的对话框中“ok”按钮,这样就读入数据了。
图7-13 数据配置
图7-14 数据读入
第三节模型拟合
一、参数估计方法选择
模型运算是使用软件进行模型参数估计的过程。Amos提供了多种模型运算方法供选择8。可以通过点击View菜单在Analysis Properties(或点击工具栏
的)中的Estimation项选择相应的估计方法。
本案例使用最大似然估计(Maximum Likelihood)进行模型运算,相关设置如图7-15。
图7-15 参数估计选择
二、标准化系数
如果不做选择,输出结果默认的路径系数(或载荷系数)没有经过标准化,称作非标准化系数。非标准化系数中存在依赖于有关变量的尺度单位,所以在比
较路径系数(或载荷系数)时无法直接使用,因此需要进行标准化。在Analysis
8详细方法列表参见书后附录一。
Properties 中的Output 项中选择Standardized Estimates 项(如图7-26),即可输出测量模型的因子载荷标准化系数如表7-5最后一列。
图7.16 标准化系数计算
标准化系数是将各变量原始分数转换为Z 分数9
后得到的估计结果,用以度
量变量间的相对变化水平。
因此不同变量间的标准化路径系数(或标准化载荷系数)可以直接比较。从表7-17最后一列中可以看出:受“质量期望”潜变量影响的是“质量感知”潜变量和“感知价格”潜变量;标准化路径系数分别为0.434和0.244,这说明“质量期望”潜变量对“质量感知”潜变量的影响程度大于其对“感知价格”潜变量的影响程度。
三、
参数估计结果的展示
图7-17 模型运算完成图
使用Analyze 菜单下的Calculate Estimates 进行模型运算(或使用工具栏中的
),输出结果如图7-17。其中红框部分是模型运算基本结果信息,使用
者也可以通过点击View the output path diagram ()查看参数估计结果
图(图7-18)。
图7-18 参数估计结果图
Amos 还提供了表格形式的模型运算详细结果信息,通过点击工具栏中的
9
Z 分数转换公式为:i
i
X X Z s
-
-=。
来查看。详细信息包括分析基本情况(Analysis Summary)、变量基本情况(Variable Summary)、模型信息(Notes for Model)、估计结果(Estimates)、修正指数(Modification Indices)和模型拟合(Model Fit)六部分。在分析过程中,一般通过前三部分10了解模型,在模型评价时使用估计结果和模型拟合部分,在模型修正时使用修正指数部分。
10分析基本情况(Analysis Summary)、变量基本情况(Variable Summary)、模型信息(Notes for Model)三部分的详细介绍如书后附录三。
11潜变量与潜变量间的回归系数称为路径系数;潜变量与可测变量间的回归系数称为载荷系数。
未标准化
路径系数
估计S.E. C.R.P Label 标准化路径系数估计
质量期
望<---超市形
象0.3010.045 6.68***par_160.358
顾客满
意<---感知价
格-0.0290.028-1.0360.3par_23-0.032
顾客忠
诚<---超市形
象0.1670.101 1.6530.098par_220.183
顾客忠
诚<---顾客满
意0.50.1 4.988***par_240.569
a112<---超市形
象10.927
12凡是a+数字的变量都是代表问卷中相应测量指标的,其中数字代表的问卷第一部分中问题的序号。
a8<---质量期
望 1.0240.05817.713***par_60.816
a10<---质量感
知10.768
a15<---感知价
格10.963
a14<---
感知价0.9720.1277.67***par_120.904
格
a16<---顾客满
意 1.0090.03331.024***par_130.95
顾客忠
z40.8940.1078.352***par_29 z5 1.3730.214 6.404***par_30 e10.5840.0797.363***par_31
e20.8610.0939.288***par_32 e3 2.6750.19913.467***par_33 e5 1.5260.1311.733***par_34 e4 2.4590.18613.232***par_35
e160.420.0528.007***par_45 e170.5540.0619.103***par_46 e150.3640.5910.6160.538par_47
结构方程sem模型案例分析
结构方程SEM模型案例分析 什么是SEM模型? 结构方程模型(Structural equation modeling, SEM)是一种融合了因素分析和路径分析的多元统计技术。它的强势在于对多变量间交互关系的定量研究。在近三十年内,SEM大量的应用于社会科学及行为科学的领域里,并在近几年开始逐渐应用于市场研究中. 顾客满意度就是顾客认为产品或服务是否达到或超过他的预期的一种感受。结构方程模型(SEM)就是对顾客满意度的研究采用的模型方法之一。其目的在于探索事物间的因果关系,并将这种关系用因果模型、路径图等形式加以表述。如下图: 图: SEM模型的基本框架 在模型中包括两类变量:一类为观测变量,是可以通过访谈或其他方式调查得到的,用长方形表示;一类为结构变量,是无法直接观察的变量,又称为潜变量,用椭圆形表示。 各变量之间均存在一定的关系,这种关系是可以计算的。计算出来的值就叫参数,参数值的大小,意味着该指标对满意度的影响的大小,都是直接决定顾客购买与否的重要因素。如果能科学地测算出参数值,就可以找出影响顾客满意度的关键绩效因素,引导企业进行完善或者改进,达到快速提升顾客满意度的目的。 SEM的主要优势 第一,它可以立体、多层次的展现驱动力分析。这种多层次的因果关系更加符合真实的人类思维形式,而这是传统回归分析无法做到的。SEM根据不同属性的抽象程度将属性分成多层进行分析。 第二,SEM分析可以将无法直接测量的属性纳入分析,比方说消费者忠诚度。这样就可以将数据分析的范围加大,尤其适合一些比较抽象的归纳性的属性。 第三,SEM分析可以将各属性之间的因果关系量化,使它们能在同一个层面进行对比,同时也可以使用同一个模型对各细分市场或各竞争对手进行比较。
结构方程模型案例
结构方程模型(Structural Equation Modeling,SEM) 20世纪——主流统计方法技术:因素分析回归分析 20世纪70年代:结构方程模型时代正式来临 结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus. 结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程(LV之间关系的方程,内部关系),以ACSI模型为例,具体形式如下:
结构方程模型案例汇总-共18页
结构方程模型( Structural Equation ,SEM) Modeling 20 世纪——主流统计方法技术:因素分析回归分析 20 世纪70 年代:结构方程模型时代正式来临结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/ 因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus. 结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程
最新★结构方程模型要点资料
★结构方程模型要点 一、结构方程模型的模型构成 1、变量 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示) 内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路 中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。 内生潜在变量:潜变量作为内生变量 内生观测变量:内生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 2、参数(“未知”和“估计”) 潜在变量自身:总体的平均数或方差 变量之间关系:因素载荷,路径系数,协方差 参数类型:自由参数、固定参数 自由参数:参数大小必须通过统计程序加以估计 固定参数:模型拟合过程中无须估计 (1)为潜在变量设定的测量尺度 ①将潜在变量下的各观测变量的残差项方差设置为1 ②将潜在变量下的各观测变量的因子负荷固定为1 (2)为提高模型识别度人为设定 限定参数:多样本间比较(半自由参数) 3、路径图 (1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。 (2)常用记号: ①矩形框表示观测变量 ②圆或椭圆表示潜在变量 ③小的圆或椭圆,或无任何框,表示方程或测量的误差 单向箭头指向指标或观测变量,表示测量误差 单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差 ④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量
使用AMOS解释结构方程模型
AMOS输出解读 惠顿研究 惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。AMOS同样能处理与时间有关的自相关回归。 惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。71疏离感的处理方式相同,使用1971年对应的两个量表的得分。第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI(邓肯的社会经济指数)确定。 解读步骤 1.导入数据。 AMOS在文件ex06-a.amw中提供惠顿数据文件。使用File/Open,选择这个文件。在图形模式中,文件显示如下。虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型
2.模型识别。 潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。对误差项的处理也是一样。一旦做完这些处理,其它系数在模型中就可以被估计。在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。有了这些约束,模型就可以识别了。 注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。 3.解释模型。 模型设置完毕后,在图形模式中点击工具栏中计算估计按钮 运行分析。点击浏览文本按钮。输出如下。蓝色字体用于注解,不是AMOS输出的一部分。 Title Example6,Model A:Exploratory analysis Stability of alienation, mediated by ses.Correlations,standard deviations and means from Wheaton et al.(1977). 以上是标题,全是英文,自己翻译去吧,没有什么价值,一堆垃圾。 Notes for Group(Group number1) The model is recursive. Sample size=932
AMOS结构方程模型修正经典案例
AMOS结构方程模型修正经典案例 第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解 释四个步骤。下面以一个研究实例作为说明,使用 Amos7 软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承 ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中 增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素 (潜变量 ):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素 是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍, 2000)。 表 7-1设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象 顾客抱怨质量期望 感知价值 顾客满意 质量感知 顾客忠诚超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1 、顾客满意模型中各因素的具体范畴 1本案例是在Amos7 中完成的。 2见 spss数据文件“处理后的数据 .sav”。
结构方程模型估计案例
结构方程模型估计案例 Prepared on 22 November 2020
应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。 表7-1 设计的结构路径图和基本路径假设 、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 表7-2 模型变量对应表 1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。
结构方程Amos操作Word案例
超市形象质量期望 质量感知感知价值顾客满意 顾客抱怨 顾客忠诚 应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。 表7-1 设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。
结构方程模型(SEM)及其应用举例
结构方程模型(SEM)及其应用举例 该分公司有三类业务:无线业务、宽带业务以及综合业务。围绕着这三类业务产品的销售,该通信分公司还提供了售前、售中和售后三个环节多方面的服务。结合该通信分公司的主要产品情况,从顾客满意度着手,重点分析并找出影响顾客满意的关键因素,从而为制定有效的顾客满意度提升方案提供数据支持。 1.设计满意度模型 根据该公司的业务具体情况,设计出了顾客满意度模型,如下图: 图:某通信分公司顾客满意度SEM模型 上图显示,该公司重点要考察的是产品满意度和服务满意度对顾客满意度的影响。图中的Xn是待构建的测量指标,λ值表示各指标对上级指标的影响大小,ζn和δn表示误差,是受模型外因素影响的部分,如价格满意度等其他因素。 结构方程模型 - 结构方程模型的优点 (一)同时处理多个因变量 结构方程分析可同时考虑并处理多个因变量。在回归分析或路径分析中,就算统计结果的图表中展示多个因变量,其实在计算回归系数或路径系数时,仍是对每个因变量逐一计算。所以图表看似对多个因变量同时考虑,但在计算对某一个因变量的影响或关系时,都忽略了其他因变量的存在及其影响。
(二)容许自变量和因变量含测量误差 态度、行为等变量,往往含有误差,也不能简单地用单一指标测量。结构方程分析容许自变量和因变量均含测量误差。变量也可用多个指标测量。用传统方法计算的潜变量间相关系数,与用结构议程分析计算的潜变量间相关系数,可能相差很大。 (三)同时估计因子结构和因子关系 假设要了解潜变量之间的相关,每个潜变量者用我个指标或题目测量,一个常用的做法是对每个潜变量先用因子分析计算潜变量(即因子)与题目的关系(即因子负荷),进而得到因子得分,作为潜变量的观测值,然后再计算因子得分,作为潜变量之间的相关系数。这是两个独立的步骤。在结构方程中,这两步同时进行,即因子与题目之间的关系和因子与因子之间的关系同时考虑。 (四)容许更大弹性的测量模型 传统上,我们只容许每一题目(指标)从属于单一因子,但结构方程分析容许更加复杂的模型。例如,我们用英语书写的数学试题,去测量学生的数学能力,则测验得分(指标)既从属于数学因子,也从属于英语因子(因为得分也反映英语能力)。传统因子分析难以处理一个指标从属多个因子或者考虑高阶因子等有比较复杂的从属关系的模型。 (五)估计整个模型的拟合程度 在传统路径分析中,我们只估计每一路径(变量间关系)的强弱。在结构方程分析中,除了上述参数的估计外,我们还可以计算不同模型对同一个样本数据的整体拟合程度,从而判断哪一个模型更接近数据所呈现的关系。 结构方程模型 - 三种分析方法对比 线性相关分析 :线性相关分析指出两个随机变量之间的统计联系。两个变量地位平等,没有因变量和自变量之分。因此相关系数不能反映单指标与总体之间的因果关系。 线性回归分析 :线性回归是比线性相关更复杂的方法,它在模型中定义了因变量和自变量。但它只能提供变量间的直接效应而不能显示可能存在的间接效应。而且会因为共线性的原因,导致出现单项指标与总体出现负相关等无法解释的数据分析结果。 结构方程模型分析:结构方程模型是一种建立、估计和检验因果关系模型的方法。也可能包含无法直接观测的潜在变量。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus.
结构方程模型估计案例
应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。
2000)。 表7-1 设计的结构路径图和基本路径假设 超市形象对质量期望有 路径影响 质量期望对质量感知有 路径影响 质量感知对感知价格有 路径影响 质量期望对感知价格有 路径影响 感知价格对顾客满意有 路径影响 顾客满意对顾客忠诚有 路径影响 超市形象对顾客满意有 路径影响 超市形象对顾客忠诚有 路径影响
2.1、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 表7-2 模型变量对应表 某超市总体形象的评价(a1) 与其它超市相比的形象(a2) 与其它超市相比的品牌知名度 (a3) 购物前,对某超市整体服务的期望 (a4) 购物前,期望某超市商品的新鲜程 度达到的水平(a5) 购物前,期望某超市营业时间安排 合理程度(a6) 购物前,期望某超市员工服务态度
达到的水平(a7) 购物前,期望某超市结账速度达到的水平(a8) 购物后,对某超市整体服务的满意程度(a9) 购物后,认为某超市商品的新鲜程度达到的水平(a10) 购物后,认为超市营业时间安排合理程度(a11) 购物后,认为某超市员工服务态度达到的水平(a12) 购物后,认为某超市结账速度达到的水平(a13) 您认为某超市商品的价格如何(a14) 与其他超市相比,您认为某超市商品的价格如何(a15)
结构方程模型案例汇总
结构方程模型案例汇总 Last revised by LE LE in 2021
结构方程模型(Structural Equation Modeling,SEM) 20世纪——主流统计方法技术:因素分析回归分析 20世纪70年代:结构方程模型时代正式来临 结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显着差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus.
结构方程模型估计案例
第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释 四个步骤。下面以一个研究实例作为说明,使用Amos7软件1 2进行计算,阐述在实 际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的 模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1 o 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价 值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素 是结果变量,前提变量综合决定并影响着结果变量(Euge ne W. An derson & Claes Fornell ,2000;殷荣伍,2000)。 表7-1 设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 1关于该案例的操作也可结合书上第七章的相关内容来看。 彳本案例是在Amos7中完成的。
超市形象对质量期望有 超市 、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小 范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表 7-2 o 表7-2 模型变量对应表 形象 顾客 期望 顾客 价值 满意、 顾客 感知 忠诚 路径影响 质量期望对质量感知有 路径影响 质量感知对感知价格有 路径影响 质量期望对感知价格有 路径影响 感知价格对顾客满意有 路径影响 顾客满意对顾客忠诚有 路径影响 超市形象对顾客满意有 路径影响 超市形象对顾客忠诚有
结构方程模型案例
20世纪——主流统计方法技术:因素分析回归分析 20世纪70年代:结构方程模型时代正式来临 结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus. 结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程(LV之间关系的方程,内部关系),以ACSI模型为例,具体形式如下: 测量方程 y=Λyη+εy , x=Λxξ+εx=(1) 结构方程η=Bη+Гξ+ζ或(I-Β)η=Гξ+ζ(2)