典型相关分析(1)

武夷学院实验报告
课程名称:多元统计分析项目名称:典型相关分析
:专业:14信计班级:1班学号:同组成员:无
一、实验目的
1.对典型相关分析问题的思路、理论和方法认识;
2.SPSS软件相应计算结果确认与应用;
3.SPSS软件相应过程命令。
二、实验容
这里通过典型相关分析来反映我国财政收入与财政支出之间的关系。第一组反映财政收入的指标有国增值税、营业税、企业所得税、个人所得税、专项收入及行政事业性收费收入等,分别用X1-X6来表示。第二组反映财政支出的指标有一般公共服务、国防、公共安全、教育、科学技术、社会保障和就业、医疗卫生与计划生育及节能环保等,分别用Y1-Y8来表示。原始数据如下:
三、实验步骤
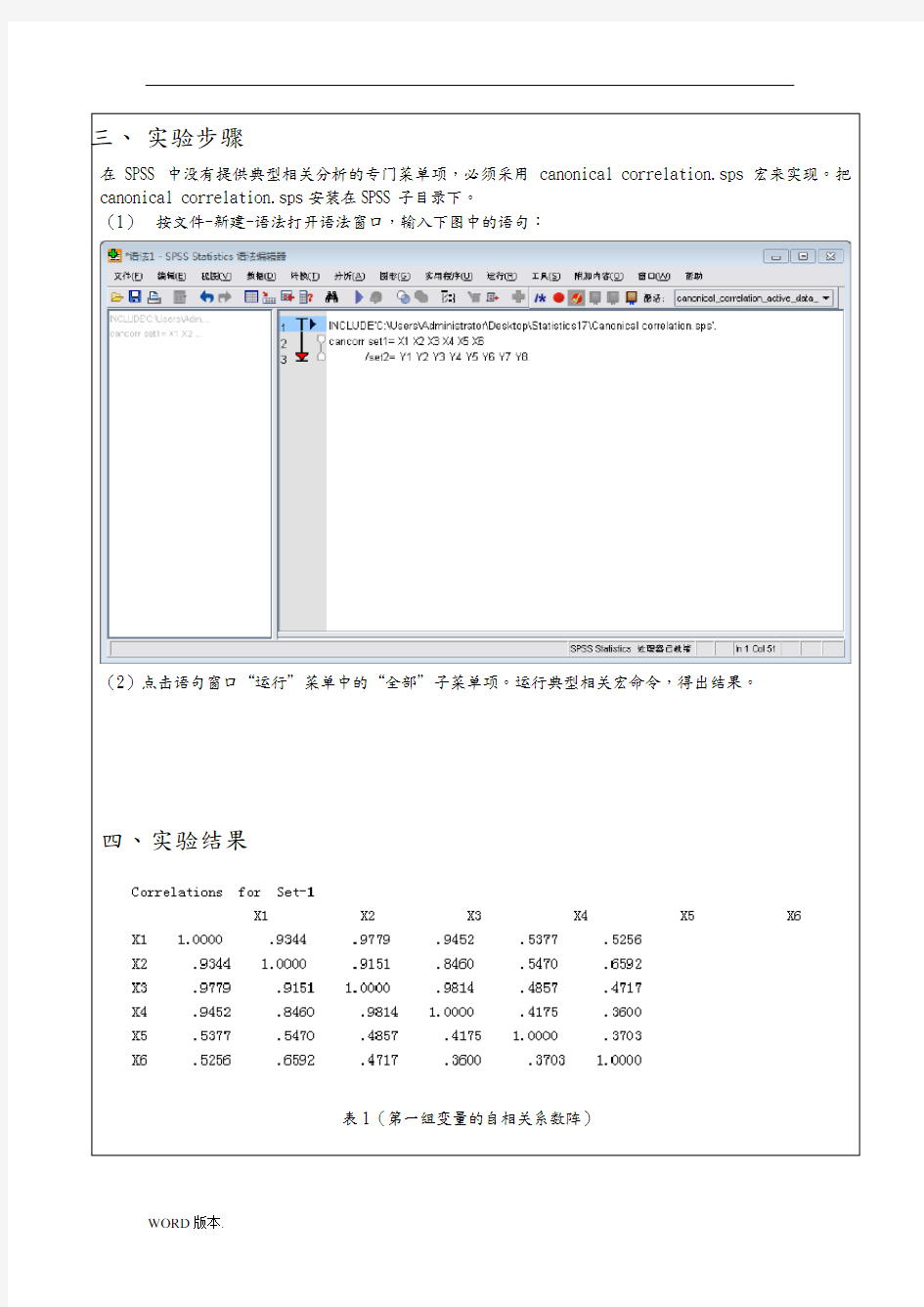
在SPSS中没有提供典型相关分析的专门菜单项,必须采用canonical correlation.sps宏来实现。把canonical correlation.sps安装在SPSS子目录下。
(1)按文件-新建-语法打开语法窗口,输入下图中的语句:
(2)点击语句窗口“运行”菜单中的“全部”子菜单项。运行典型相关宏命令,得出结果。
四、实验结果
表1(第一组变量的自相关系数阵)
表2(第二组变量的自相关系数阵)
表1和表2分别为两组变量的自相关系数阵。反映了各组变量间的相关系数。
表3(两组变量间的相关系数阵)
表3为两组变量间的相关系数。从表中可以看出,第一组变量中的X1,X2,X3与第二组变量中的Y3,Y4,Y5之间相关系数较高,这进一步说明需要提取典型变量来代表这种相关性。
值得注意的是,由于变量间的交互作用,这个简单相关系数阵只能作为参考,不能真正反映两组变量间的实质联系。
表4(典型相关系数)
表4为典型相关系数。从表中可以看出,第一对典型变量相关系数为0.991,第二对典型变量相关系数为0.838,以此类推共有6对典型变量的典型相关系数。由于此处的典型相关系数是从样本数据算得的,和简单相关系数一样,有必要进行总体系数是否为0的检验(见表5)。
表5(典型相关系数的显著性检验)
表5为典型相关系数的显著性检验。该表从左至右分别为Wilks统计量、卡方统计量、自由度和伴随概率。从表中伴随概率可以看出,第一对和第二对典型变量的典型相关系数显著不为0;从第三对典型变量开始,典型相关系数的p值都比较大,均相关性不显著。因此需要第一对和第二对典型变量。
表6(第一组典型变量的标准化系数)
表7(第一组典型变量的为标准化系数)
表8(第二组典型变量的标准系数)
表9(第二组典型变量的未标准系数)
表6-表9为各典型变量标准化与未标准化的系数列表。从表6和表8中第一列和第二列数据可以得到第一对典型变量的线性函数,分别为
表10(第一组的典型载荷系数)
表11(第一组的交叉载荷系数)
表12(第二组的典型载荷系数)
表13(第二组的交叉载荷系数)
表10-表13为典型载荷系数与交叉载荷系数的输出结果。其中,典型载荷系数是典型变量与本组观测变量之间的两两简单相关系数。交叉载荷系数是指某一典型变量与另外一组中的观测量之间的两两简单相关。
表14
表15
表16
表17
典型相关分析(CCA)附算法应用及程序演示教学
典型相关分析(C C A)附算法应用及程序
典型相关分析
摘要 利用典型相关分析的思想,提出了解决了当两组特征矢量构成的总体协方差矩阵奇异时,典型投影矢量集的求解问题,使之适合于高维小样本的情形,推广了典型相关分析的适用范围.首先,探讨了将典型分析用于模式识别的理论构架,给出了其合理的描述.即先抽取同一模式的两组特征矢量,建立描述两组特征矢量之间相关性的判据准则函数,然后依此准则求取两组典型投影矢量集,通过给定的特征融合策略抽取组合的典型相关特征并用于分类.最后,从理论上进一步剖析了该方法之所以能有效地用于识别的内在本质.该方法巧妙地将两组特征矢量之间的相关性特征作为有效判别信息,既达到了信息融合之目的,又消除了特征之间的信息冗余,为两组特征融合用于分类识别提出了新的思路.
一、典型相关分析发展的背景 随着计算机技术的发展,信息融合技术已成为一种新兴的数据处理技术,并已取得了可喜的进展.信息融合的3个层次像素级、特征级、决策级。 特征融合,对同一模式所抽取的不同特征矢量总是反映模式的不同特征的有效鉴别信息,抽取同一模式的两组特征矢量,这在一定程度上消除了由于主客观因素带来的冗余信息,对分类识别无疑具有重要的意义 典型相关分析(CanoniealComponentAnalysis:CCA)是一种处理两组随机变量之间相互关系的统计方法。它的意义在于:用典型相关变量之间的关系来刻画原来两组变量之间的关系!实现数据的融合和降维!降低计算复杂程度。 二、典型相关分析的基本思像 CCA 的目的是寻找两组投影方向,使两个随机向量投影后的相关性达到最大。具体讲,设有两组零均值随机变量 () T c ...c c p 21x ,,= 和 () T d ...d d q 21y ,,= CCA 首先要找到一对投影方向1α和1β,使得投影y v 11T β= 和x u 11 T α=之间具有最大的相关性,1u 和1v 为第一对典型变量;同 理,寻找第二对投影方向2α和2β,得到第二对典型变量2u 和2v ,使其与第一对典型变量不相关,且2u 和2v 之间又具有最大相关性。这样下去,直到x 与y 的典型变量提取完毕为止。从而x 与y 之
2018年社区工作30 个最新经典案例分析题
2018年社区工作30 个最新经典案例分析题 说明:本文主要包含了社区工作(社工)各个方面的内容,以30个经典案例为依托,详细分析问题、设计方案、实施方案、解决问题以及触类旁通的关键启示。 案例1、社区安全--安装防盗门问题 某居民小区位于本市城乡结合部,小区内有住户1840户,长住居民5300多人,基本上都是由农民回城的人员、动迁人员和外地入住人员组成。 小区人员有三大特点:一是无业和生活困难的居民多;二是六十岁以上的老人多;三是外来人员多。 小区接上级综合治理部门的通知,要求在小区各楼道内安装电子防盗门。然而有的居民认为,外来人员多的楼道,安装防盗门的 实际意义和效果不大;有的居民觉得经济困难,拿不出钱来安装;还有人顾虑,防盗门质量不一定有保障,等等。面对不少居民都拒 绝安装电子防盗门的情况,社工如何将该项工作顺利推进。 主要问题: 1.上述案例属于社区社会工作的哪个范畴? 2.试分析部分居民拒绝安装电子防盗门的深层原因是什么。 3.社工应采取什么样的介入方法,帮助社区有效推进工作开展? 答题要点: 1.本案例属于社区治安工作: (1)社区内生活困难人员多,难以支付安装费用; (2)社区居民结构复杂,难以统一思想;
(3)对防盗门的产品功能及质量不信任等。 2.工作方法和策略: (1)听取各居民住户的意见和建议,必要时还可以召开小区党员领导会义; (2)召开楼组长代表会议,传达工作精神,统一他们的思想; (3)对于防盗门质量问题,可以与生产厂商沟通,在小区内现场展示防盗门的样品; (4)加大宣传力度,对社区反对居民进行个案心理安抚和调适。 案例2、社区康复—-智障人问题 某市街道D社区,拥有居民3万多人。假设你是该社区的一名社工,并且主要负责社区内智障人士的康复工作,请针对智障人士设计一套社区康复计划。 答题要点: 1.方案设计: 康复方案的目标主要包括以下4个方面: (1)智障人士在行为及社会功能上的改变; (2)智障人士家庭对生活满意程度的提高; (3)智障人士与邻里之间关系得到改善; (4)社区对智障人士的接受程度增加。 2.实施策略: (1)个人训练:为智障人士提供简单的自我照顾技巧及康复技巧训练,协助其发展个人才能。
多元统计分析模拟考题及答案.docx
一、判断题 ( 对 ) 1 X ( X 1 , X 2 ,L , X p ) 的协差阵一定是对称的半正定阵 ( 对 ( ) 2 标准化随机向量的协差阵与原变量的相关系数阵相同。 对) 3 典型相关分析是识别并量化两组变量间的关系,将两组变量的相关关系 的研究转化为一组变量的线性组合与另一组变量的线性组合间的相关关系的研究。 ( 对 )4 多维标度法是以空间分布的形式在低维空间中再现研究对象间关系的数据 分析方法。 ( 错)5 X (X 1 , X 2 , , X p ) ~ N p ( , ) , X , S 分别是样本均值和样本离 差阵,则 X , S 分别是 , 的无偏估计。 n ( 对) 6 X ( X 1 , X 2 , , X p ) ~ N p ( , ) , X 作为样本均值 的估计,是 无偏的、有效的、一致的。 ( 错) 7 因子载荷经正交旋转后,各变量的共性方差和各因子的贡献都发生了变化 ( 对) 8 因子载荷阵 A ( ij ) ij 表示第 i 个变量在第 j 个公因子上 a 中的 a 的相对重要性。 ( 对 )9 判别分析中, 若两个总体的协差阵相等, 则 Fisher 判别与距离判别等价。 (对) 10 距离判别法要求两总体分布的协差阵相等, Fisher 判别法对总体的分布无特 定的要求。 二、填空题 1、多元统计中常用的统计量有:样本均值向量、样本协差阵、样本离差阵、 样本相关系数矩阵. 2、 设 是总体 的协方差阵, 的特征根 ( 1, , ) 与相应的单 X ( X 1,L , X m ) i i L m 位 正 交 化 特 征 向 量 i ( a i1, a i 2 ,L ,a im ) , 则 第 一 主 成 分 的 表 达 式 是 y 1 a 11 X 1 a 12 X 2 L a 1m X m ,方差为 1 。 3 设 是总体 X ( X 1, X 2 , X 3, X 4 ) 的协方差阵, 的特征根和标准正交特征向量分别 为: 1 2.920 U 1' (0.1485, 0.5735, 0.5577, 0.5814) 2 1.024 U 2' (0.9544, 0.0984,0.2695,0.0824) 3 0.049 U 3' (0.2516,0.7733, 0.5589, 0.1624) 4 0.007 U 4' ( 0.0612,0.2519,0.5513, 0.7930) ,则其第二个主成分的表达式是
管理沟通 经典案例分析
2011-2012第一学期管理沟通期中考试试题: 案例: 韩鹏的竞聘 韩鹏,2001年7月,毕业于辽宁工业大学电子工程专业,应聘到了大连MV商业集团公司工作。由于在三个月的试用期内,韩鹏工作富有激情,并且具有较强的交际能力,很快便得到集团领导的赏识。2001年10月,新入职员工的岗位分配时,按照韩鹏个人的第一志愿,他竞聘到了集团营销部工作,负责集团内部报刊和广告方面的工作。 进入营销部后,韩鹏一如既往地努力工作,善于钻研,经常向部门内部的前辈和其他科室的领导请教工作方法以及业务方面的问题,从而使其业务能力不断提升,工作开展得有声有色,业绩也很突出,受到了营销部主管领导的好评。 随着工作时间的延续,韩鹏觉得目前的机关工作不利于自己以后的职业发展,于是他协调各方面关系,终于得到了集团下属公司领导的认可,也得到了一次工作调动的机会。 2005年2月,韩鹏调至集团下属最大的分公司营业部大连A区营业部担任服务经理助理职务。韩鹏在这个职务上如鱼得水,很快便成为营业部的骨干。2005年10月,韩鹏被任命为营业部服务经理,全面负责营业部的顾客服务工作。一直积极要求上进的他工作更加努力,希望自己能够得到更大的提升。 正在韩鹏希望自己能够有更大的发展空间时,2007年3月,MV集团公司决定拓宽业务领域,成立国际名品经营公司,面向集团内部招聘一名总经理和两名业务经理。韩鹏认为自己的工作能力和经验能够适合国际名品公司业务经理的要求,决定再一次挑战自己,便报名参加竞聘业务经理。 2007年3月20日,MV集团国际名品公司岗位竞聘大会在集团总部大楼会议室举行,集团总裁、总部机关各部门的领导和集团各分公司总经理出席了会议。参加业务经理竞聘的除了韩鹏外,还有MV集团大连B营业部的业务经理徐志强和2004年刚刚加入MV集团的国内某名牌大学毕业生王嘉实。由于认真准备了讲稿,加之对自己的沟通能力、应变能力以及工作经验充满自信,韩鹏认为此次竞聘成功的概率很大,至少自己比入职不满三年的王嘉实的工作经验丰富很多,胜算也大得多。 由于竞聘的顺序是按照姓名的拼音排序,所以韩鹏第一个走上了讲台。整个演讲过程都很顺利,下一个环节是答辩。 为了给自己原来的部下鼓劲,营销部孟总第一个提问:“韩鹏,你在刚才的演讲中提到自己工作能力很强,能讲一讲你是如何提升自己的工作能力的吗?” “作为入职集团近五年的大学生,我对领导安排的每一项工作都仔细思考,认真执行,同时经常到图书馆借阅各种与工作相关的业务书籍,时常向老领导和经验丰富的员工请教工作方法,从理论和实践两个方面不断提升自己的业务能力,所以即使我不是业务能力最强的一个,但我一定是进步最快的一个!”韩鹏满怀信心地答道。 “你刚才提到零售企业的顾客服务工作十分重要,甚至对公司的经营业绩起到举足轻重的作用,能深入地说一说服务的主要作用吗?”为进一步考察韩鹏的工作能力,集团总裁继续提问。 “我从2005年2月到现在一直从事服务工作,处理的棘手问题很多,我认为服务工作开展的好坏将直接影响公司的经营效益,同时对公司的持续发展起着很重要的作用。就拿我工作的大连A营业部来说吧,两年内我处理的顾客投诉问题我自己都不知道有多少起了,客服部的工作很重要,工作开展也很难,有些顾客如不给予经济补偿就百般纠缠。我们营业
应用多元统计分析习题解答典型相关分析Word版
第九章 典型相关分析 9.1 什么是典型相关分析?简述其基本思想。 答: 典型相关分析是研究两组变量之间相关关系的一种多元统计方法。用于揭示两组变量之间的内在联系。典型相关分析的目的是识别并量化两组变量之间的联系。将两组变量相关关系的分析转化为一组变量的线性组合与另一组变量线性组合之间的相关关系。 基本思想: (1)在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。即: 若设(1) (1)(1) (1)12(,, ,)p X X X =X 、(2)(2)(2) (2) 12(,, ,)q X X X =X 是两组相互关联的随机变量, 分别在两组变量中选取若干有代表性的综合变量Ui 、Vi ,使是原变量的线性组合。 在(1)(1)(1)(2)()()1D D ''==a X b X 的条件下,使得(1)(1)(1)(2)(,)ρ''a X b X 达到最大。(2)选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对。 (3)如此继续下去,直到两组变量之间的相关性被提取完毕为此。 9.2 什么是典型变量?它具有哪些性质? 答:在典型相关分析中,在一定条件下选取系列线性组合以反映两组变量之间的线性关系,这被选出的线性组合配对被称为典型变量。具体来说, ()(1)()(1) ()(1) ()(1)1122i i i i i P P U a X a X a X '=++ +a X ()(2)()(2) ()(2) ()(2)1122i i i i i q q V b X b X b X '=+++b X 在(1)(1)(1)(2)()()1D D ''==a X b X 的条件下,使得(1)(1)(1)(2)(,)ρ''a X b X 达到最大,则称 (1)(1)'a X 、(1)(2)'b X 是(1)X 、(2)X 的第一对典型相关变量。 典型变量性质: 典型相关量化了两组变量之间的联系,反映了两组变量的相关程度。 1. ()1,()1 (1,2,,)k k D U D V k r === (,)0,(,)0()i j i j Cov U U Cov V V i j ==≠ 2. 0(,1,2,,) (,)0 ()0() i i j i j i r Cov U V i j j r λ≠==?? =≠??>? 9.3 试分析一组变量的典型变量与其主成分的联系与区别。 答:一组变量的典型变量和其主成分都是经过线性变换计算矩阵特征值与特征向量得出的。主成分分析只涉及一组变量的相互依赖关系而典型相关则扩展到两组变量之间的相互依赖关系之中 ()(1)()(1)()(1)()(1) 1122i i i i i P P U a X a X a X '=+++a X ()(2)()(2)()(2)()(2)1122i i i i i q q V b X b X b X '=+++b X (1)(1)(1)(1)1 2 (,,,)p X X X =X 、(2)(2)(2)(2)1 2 (,,,)q X X X =X
关于小学生计算错误典型实例、原因分析与改进办法
关于小学生计算错误典型实例、原因分析与改进办法 计算在小学数学教学中占据着十分重要的地位,是小学数学教学内容的重要组成部分,是学习数学的基础。培养学生准确、迅速、灵活的计算能力是小学数学教学的一项重要任务。但我们往往发现学生在实际学习中,计算错误多,正确率低,部分家长和教师认为学生计算错误的原因是由于计算时不细心造成的。难道学生的计算错误仅仅是因为粗心大意吗?他们计算出错的原因究竟有哪些呢?为了真正了解学生在计算中产生错误的原因,找到解决问题的办法和措施,我校开展了一次对学生计算错误典型实例、原因分析与改进办法的问卷调查活动,现将调查情况整理汇报如下: 一、活动参与情况 全校数学教师31人,发出调查表31份,收回调查表18份,参与率58%。参与度较低,从而说明教师对此项工作在思想上没有高度重视。教师们在平时教学中做了大量工作,但没有及时反思总结,自己的好经验好方法没有得到推广交流,达不到资源共享的目的。 二、学生计算错误的原因及实例 在计算练习中,学生的计算错误经常发生:不是看错数字,就是写错数字;不是抄错数字,就是漏写符号;或是加法忘了进位,减法忘了退位,加法当减法做,乘法当成了除法,小数点忘了点或点错了位,商中间不够商“1”而忘了用
“0”占位,分数加法中分子加分子、分母加分母,还有四则运算中不按运算顺序计算,而是怎样好算就怎样算,有时甚至会出现一些无法理解的错误等等。原因是多方面的,根据收集到的调查材料显示,学生计算错误大致可以归纳为知识性错误和非知识性错误两大类。知识性错误是指学生对于计算法则概念或运算顺序的不理解,或者没有很好的掌握所学知识导致的错误。非知识性错误是指学生不是不懂得运算,而是由于不良的学习习惯所导致的错误;如抄错数字、不认真审题、注意力不集中、易受负迁移干扰等。 (一)知识性错误 1、基础知识不扎实。 有些学生对于简单的20以内加减法不熟练,表内乘法出现三七二十七、六九四十五等错误,在混合运算中对一些常用数据如25×4,125×8,分数与小数互化等不熟练,质数表记不准,简便算法不能“为己所用”,这些都有可能使学生计算出错。 2、概念、法则理解不清 概念和法则是学生思维的基本形式,又是学生进行计算的重要依据。只有正确理解和掌握基本概念和计算法则才能正确地进行计算。 (1)退位减法算理不清
典型案例分析
铁山乡干部作风整治典型案例分析会 会议记录整理 时间:2012年4月24日 地点:乡便民服务中心五楼会议室 主持:彭联军(纪检书记) 4月24日上午,铁山乡党委政府在乡便民服务中心五楼会议室召开“集中整治干部作风突出问题活动”典型案例剖析专题会议,出席会议的有全体乡村干部、乡属乡办各单位的负责人。会议由乡纪委书记、集中整治影响发展环境的干部作风突出问题活动领导小组副组长彭联军同志主持。乡党委书记、集中整治影响发展环境的干部作风突出问题活动领导小组组长洪海出席会议并讲话。 一、典型案例分析 1、江西省赣州市石城县通报一起干部作风问题典型案件。 该县屏山镇长江村新村点近百户建房户2007年申请办证,至今年3月调查时仍未办结,对该镇政府、规划所、国土所相关人员办事拖拉、服务意识不强、不把群众利益放在首位的行为和驻村挂点的县体育局“送政策、送温暖、送服务”工作队员作风不实问题进行效能责任追究,给予3人口头效能告诫,扣发一个月津补贴的50%;给予4人书面效能告诫,扣发一个月津补贴,且当年度考核不能评为优秀等次;对建房办证中乱收费行为进行立案调查,给予1人党内严重警告、2人党内警告、2人行政警告处分。目前,该村建房户土地使用
证正在按程序办理中,违规收取的费用已全部退还给了建房户。 分析:江西省赣州市石城县屏山镇长江村新村点农民建房办证过程中有关部门单位存在的问题,暴露出乡政府及职能部门存在着政策宣传不力、惠民政策执行不到位、干部作风飘浮、办事效率不高等问题,它直接侵害了群众的利益,造成了不良社会影响。各部门、各单位尤其是各级领导干部一定要从中汲取教训,引以为戒。要切实维护群众合法权益,坚决制止农民建房乱收费行为。要以当前全县正在开展集中整治影响发展环境的干部作风突出问题活动为契机,不断加强干部作风建设。要积极开展“送政策、送温暖、送服务”工作,深入群众,切实解决群众的合理诉求。 2、河北兴隆县部分县直部门和乡镇党员干部严重违纪违法被查处。 2009年5月,河北省审计厅到兴隆县对该县2006至2008年财政决算情况进行审计,审计中发现兴隆县部分县直部门和乡镇存在较严重的违反财经纪律问题,省审计组陆续向承德市委移送案件线索83件。市委决定组成联合调查组进行调查核实。经过省审计组审计和市委调查组调查,发现被审单位存在三个方面的突出问题:一是监督查处工作不到位。二是资金、账户管理不严。三是资金支出随意性大,违规使用资金现象比较严重。该县挂兰峪镇原党委书记王庆国、原镇长司铁军采用收入不入账、虚打收条截留款项、虚开发票套取资金等方式,将该镇应收的承包费、县直部门拨付的项目款等合计364万元留作账外资金,并采取报销虚假单据的方式,从“小金库”中套取现
典型相关分析SPSS例析
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。 典型相关与主成分相关有类似,不过主成分考虑的是一组变量,而典型相关考虑的是两组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设:两组变量间是线性关系,每对典型变量之间是线性关系,每个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因变量。 典型相关会找出一组变量的线性组合**=i i j j X a x Y b y =∑∑与 ,称 为典型变量;以使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。i a 和j b 称为典型系数。如果对变量进 行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关;原来所有变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变量之间的相关,不能代
表两个变量组的相关;各对典型变量构成的多维典型相关,共同代表两组变量间的整体相关。 典型负荷系数和交叉负荷系数 典型负荷系数也称结构相关系数,指的是一个典型变量与本组所有变量的简单相关系数,交叉负荷系数指的是一个典型变量与另一组变量组各个变量的简单相关系数。典型系数隐含着偏相关的意思,而典型负荷系数代表的是典型变量与变量间的简单相关,两者有很大区别。 重叠指数 如果一组变量的部分方差可以又另一个变量的方差来解释和预测,就可以说这部分方差与另一个变量的方差之间相重叠,或可由另一变量所解释。将重叠应用到典型相关时,只要简单地将典型相关系数平方(2 CR),就得到这对典型变量方差的共同比例,代表一个典型变量的方差可有另一个典型变量解释的比例,如果将此比例再乘以典型变量所能解释的本组变量总方差的比例,得到的就是一组变量的方差所能够被另一组变量的典型变量所能解释的比例,即为重叠系数。 例1:CRM(Customer Relationship Management)即客户关系管理案例,有三组变量,分别是公司规模变量两个(资本额,销售额),六个CRM实施程度变量(WEB网站,电子邮件,客服中心,DM 快讯广告Direct mail缩写,无线上网,简讯服务),三个CRM绩效维度(行销绩效,销售绩效,服务绩效)。试对三组变量做典型相关分析。
典型相关分析及其应用实例
摘要 典型相关分析是多元统计分析的一个重要研究课题.它是研究两组变量之间相关的一种统计分析方法,能够有效地揭示两组变量之间的相互线性依赖关系.它借助主成分分析降维的思想,用少数几对综合变量来反映两组变量间的线性相关性质.目前它已经在众多领域的相关分析和预测分析中得到广泛应用. 本文首先描述了典型相关分析的统计思想,定义了总体典型相关变量及典型 相关系数,并简要概述了它们的求解思路,然后深入对样本典型相关分析的几种算法做了比较全面的论述.根据典型相关分析的推理,归纳总结了它的一些重要性质并给出了证明,接着推导了典型相关系数的显著性检验.最后通过理论与实例分析两个层面论证了典型相关分析的应用于实际生活中的可行性与优越性. 【关键词】典型相关分析,样本典型相关,性质,实际应用 ABSTRACT The Canonical Correlation Analysis is an important studying topic of the Multivariate Statistical Analysis. It is the statistical analysis method which studies the correlation between two sets of variables. It can work to reveal the mutual line dependence relation availably between two sets of variables. With the help of the thought about the Principal Components, we can use a few comprehensive variables to reflect the linear relationship between two sets of variables. Nowadays It has already been used widely in the correlation analysis and forecasted analysis. This text describes the statistical thought of the Canonical Correlation Analysis firstly, and then defines the total canonical correlation variables and canonical correlation coefficient, and sum up
如何在SPSS中实现典型相关分析
如何在SPSS中实现典型相关分析? SPSS 11.0 15.1 典型相关分析 15.1.1方法简介 在相关分析一章中,我们主要研究的是两个变量间的相关,顶多调整其他因素的作用而已;如果要研究一个变量和一组变量间的相关,则可以使用多元线性回归,方程的复相关系数就是我们要的东西,同时偏相关系数还可以描述固定其他因素时某个自变量和应变量间的关系。但如果要研究两组变量的相关关系时,这些统计方法就无能为力了。比如要研究居民生活环境与健康状况的关系,生活环境和健康状况都有一大堆变量,如何来做?难道说做出两两相关系数?显然并不现实,我们需要寻找到更加综合,更具有代表性的指标,典型相 关(CanonicalCorrelation)分析就可以解决这个问题。 典型相关分析方法由Hotelling提出,他的基本思想和主成分分析非常相似,也是降维。即根据变量间的相关关系,寻找一个或少数几个综合变量(实际观察变量的线性组合)对来替代原变量,从而将二组变量的关系集中到少数几对综合变量的关系上,提取时要求第一对综合变量间的相关性最大,第二对次之,依此类推。这些综合变量被称为典型变量,或典则变量,第1对典型变量间的相关系数则被称为第1典型相关系数。一般来说,只需要提取1~2对典型变量即可较为充分的概括样本信息。 可以证明,当两个变量组均只有一个变量时,典型相关系数即为简单相关系数;当一组变量只有一个变量时,典型相关系数即为复相关系数。故可以认为典型相关系数是简单相关系数、复相关系数的推广,或者说简单相关系数、复相关系数是典型相关系数的特例。 15.1.2引例及语法说明 在SPSS中可以有两种方法来拟合典型相关分析,第一种是采用Manova过程来拟合,第二种是采用专门提供的宏程序来拟合,第二种方法在使用上非常简单,而输出的结果又非常详细,因此这里只对它进行介绍。该程序名为Canonical correlation.sps,就放在SPSS的 安装路径之中,调用方式如下: INCLUDE 'SPSS所在路径\Canonical correlation.sps'. CANCORR SETl=第一组变量的列表 /SET2=第二组变量的列表. 在程序中首先应当使用include命令读入典型相关分析的宏程序,然后使用cancorr名称调用,注意最后的“.”表示整个语句结束, 不能遗漏。 这里的分析实例来自曹素华教授所著《实用医学多因素统计分析方法》第176页:为了研究兄长的头型与弟弟的头型间的关系,研究者随机抽查了25个家庭的两兄弟的头长和头宽,资料见文件canoncor.sav,希望求得两组变量的典型变量及典型相关系数。显然,代表兄长头形的变量为第一组变量,代表弟弟头形的变量为第二组变量,这里希望求得的是两组变量间的相关性,在语法窗口中键入的程 序如下: INCLUDE 'D:\SpssWin\Canonical correlation.sps'. 请使用时改为各自相应的安装目录 CANCORR SETl=longlwidthl 列出第一组变量 /SET2=long2width2. 列出第二组变量 选择菜单Run->All,运行上述程序,结果窗口中就会给出典型相关分析的结果。 15.1.3 结果解释 NOTE:ALL OUTPUT INCLUDING ERROR MESSAGES HAVE BEEN TEMPORARILY SUPPRESSED.IF YOU EXPERIENCE UNUSUAL BEHAVIOR THEN RERUN THIS
SPSS典型相关分析
SPSS数据统计分析与实践 第二十二章:典型相关分析 (Canonical Correlation) 主讲:周涛副教授 北京师范大学资源学院 教学网站:https://www.360docs.net/doc/c218764925.html,/Courses/SPSS
典型相关分析(Canonical Correlation)本章内容: 一、典型相关分析的基本思想 二、典型相关分析的数学描述 三、SPSS实例 四、小节
典型相关分析的基本思想 z典型相关分析是研究两组变量之间相关关系的一种多元统计方法。 z简单相关系数;复相关系数;典型相关系数 z典型相关分析首先在每组变量中找出变量的线性组合,使其具有最大相关性; z然后再在每组变量中找出第二对线性组合,使其与第一对线性组合不相关,而第二对本身具有最大相关性; z如此继续下去,直到两组变量之间的相关性被提取完毕为止; z这些综合变量被称为典型变量(canonical variates);第I对典型变量间的相关系数则被称为第I 典型相关系数(一般来说,只需提取1~2对典型变量即可较为充分的概括样本信息)。
典型相关分析的目的 T q T p Y Y Y Y X X X X ),,,() ,,,(2121K K ==设两组分别为p 与q 维 (p ≤q)的变量X ,Y :设p + q 维随机向量协方差阵,????????=Y X Z ??? ?????ΣΣΣΣ=Σ222112 11其中Σ11是X 的协方差阵,Σ22是Y 的协方差阵,Σ12=ΣT 21是X ,Y 的协方差阵 典型相关分析用X 和Y 的线性组合U =a T X , V =b T Y 之间的相关来研究X 和Y 之间的相关性。其目的就是希望找到向量a 和b ,使ρ(U ,V )最大,从而找到替代原始变量的典型变量U 和V 。
典型问题分析
典型问题分析 阅读下面的文字,完成后面题目。 中华民族文化遗产宝藏中,传统节日有着其他文化遗产所不具备的特殊性,值得我们在建设和谐社会的过程中给予特别关注。 在古代社会的早期,人与自然的和谐是传统节日最根本、最重要的主题;中古以后,传统节日促进人际和谐的内容才逐渐占据更重要的位置。中国传统节日大都是岁时节日。所谓岁时节日,就是与天时、物候的周期性转移相适应,有固定的节期和特定民俗活动的时日。它们是先人将自然时间进程与社会活动节律有机结合的产物,体现着传统文化天人合一的观念。我国历史上的传统节日数量很多,它们产生于不同的历史时期,有各自的形成、发展、兴盛、衰弱以至消失的过程。 节日就是时间历程的重要节点,它的形成当然是有了基本的时间观念之后的事。古人最早产生的时间观念是日出日落、寒来暑往。由此,开始分为寒暑两季,接着有了四季的划分和最早的节气。先秦古籍《逸周书·时训》记载了二十四节气。流传至今的节气名称全部是以简洁朴素的词汇感性地描述天象气候物候的变化。古人认识到这些日子是天象气候转变的关键节点,以为这些划分都是神灵的意志使然,便在这些日子施行巫术、占卜,祭拜日月星辰、五谷诸神,祈求神灵保佑风调雨顺、五谷丰登、人们健康平安等。每年如此,便形成了在特定时日周期性重复的民俗活动,形成了最初的节日。月亮的晦朔圆缺之日也让古人感到神秘并加以崇拜,也会产生萌芽状态的节日。这些早期的节日产生于古人以其感性、原始的方式认识自然、适应自然的过程,源于古人在特定时日用以解释、控制自然进程的超自然力崇拜。所以说,岁时节日的产生,最初完全是人追求与自然和谐的结果。确定节气之后,又有了年月日的划分,便形成了历法。 传统节日都有贵人伦、重亲情的特点,显著体现着中华民族传统伦理和礼俗,有浓厚的人情味,几千年来已经成为维系中国社会人际关系的重要感情纽带,故传统节日的保护,有利于保持和有效促进人际关系的和谐。 一些较大的传统节日,已不仅仅是汉族的节日,也成为许多少数民族的节日。如春节已成为我国境内四十多个民族的共同节日。同时,少数民族的节日数量众多,也是中华民族文化遗产的重要组成部分,也必须给予充分的尊重,采取切实的保护措施,维护中华文化一体化格局中的各民族文化多样化;其节日文化中的优秀成分,也可被吸收到汉族的节日传统中来。 包括节日文化在内的民俗文化是民族文化的基础部分,是为中华民族全体成员共享的文化。在同一个日子过同样的节日,使我们体会到属于同一个族群的文化认同感。尤其是在异文化环境,一个族群同样的节日习俗就更成为文化认同的显著标志。文化的认同往往比政治
典型相关分析
武夷学院实验报告 课程名称:多元统计分析项目名称:典型相关分析 姓名:专业:14信计班级:1班学号:同组成员:无 -、实验目的 1.对典型相关分析问题的思路、理论和方法认识; 2.SPSS软件相应计算结果确认与应用; 3.SPSS软件相应过程命令。 二、实验内容 这里通过典型相关分析来反映我国财政收入与财政支出之间的关系。第一组反映财政收入的指标有国内增值税、营业税、企业所得税、个人所得税、专项收入及行政事业性收费收入等,分别用X1-X6来表示。第二 组反映财政支出的指标有一般公共服务、国防、公共安全、教育、科学技术、社会保障和就业、医疗卫生与计划生育及节能环保等,分别用Y1-Y8来表示。原始数据如下: jts 10^ ?96K! 1?痼8496.6641 H929? 129.06M.820H W234 8? 225.0B425.1 '2W.39tU.31 一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα∑ :=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B 的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A 和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0 ΣΣ 中学生心理问题典型案例及分析 一、性意识发展咨询案例 案例介绍 一名初一女生喜欢并希望一高二男生保护她。她自己也知道并非是交男朋友。但她仍然想知道这名高二男生的电话号码,却又害羞说不出口。同时,她不知道男女生之间的交往是否是正常现象。因此,很害怕别的同学知道了自己的想法而被笑话。她很迷茫,又不知道应该怎么做。请老师为她解答。 案例分析 首先给她介绍并讲解有关的科学知识。 我国青少年儿童性意识萌发成熟的平均年龄在11、12——16、17岁,近几年来还有提前的趋势,身高体重的迅速增长以及性器官的成熟促使青少年对异性产生了浓厚的兴趣,但是又因为对两性知识的缺乏而有一种强烈的神秘感。他们能很清楚的意识到自己身体上的变化,逐渐认识到自己在慢慢长大,但在异性面前却显得很拘谨腼腆。到后期出现一种表面回避而内心憧憬的背反现象。一些男女同学虽然感情很好,在学习上互相帮助,但却害怕它会招来大部分同学的议论,对他们的学习产生不好的影响。 在咨询时我为她仔细分析,并且给了她许多参考性的意见,最终让她自己决定该怎么做。 1.树立正确的思想观念。喜欢一个人包括异性并没有错,这都是人很正常的想法。 2.当你对一个人有强烈的喜爱念头时,就应该从多方面去了解他的优点和不足,然后他在你心中的神秘感会逐渐消失的。 3.直接对他说自己很崇拜他并且希望能得到他的关心和保护,如果不敢面对面的说也可以间接接触,例如可以采用写信或者让自己信赖的老师和同学转告的方式等等。 4.表达不愿意影响他,希望能共同进步的想法。 5.当有人评论时,要理直气壮的接受这一切,因为大多数人都因为不了解而进行各种猜测。这些都是人之常情,也不要因此而气愤。 6.为了双方都有一个美好的未来则应该做好每天该做的事。作为一名学生应该首先把自己的成绩搞好,从而回到正常的学习生活轨道中来。 二、社会性发展咨询案例 案例介绍 一名初二女生来询问,她和她的一个很要好的朋友经常吵架,她不知道两人还是不是好朋友?为了保住友谊,他们不敢相互指出对方的对与错,甚至在她的好友有偷盗自己东西的行为时,也不敢多说,近来,好友还被一群品行不良的人恐吓威胁着让陪着他们玩玩,而且让好友去干坏事,她们两个都害怕不服从会招到报复,而服从了又害怕自己变坏。因此,徘徊不定,也不知道怎么办。 案例分析 首先给她介绍并讲解有关的科学知识。 少年由于缺乏辨证而全面的看事物的经验,往往会把朋友之间的友谊神圣化。他们会把小集团中的一些人的行为准则作为自己的行动标准。常常为了所谓的“义气”而包庇同伴,或者为对方打抱不平,也不管是否符合社会道德规范就很冲动的做出一些造成较大不良后果的行动。 第一章: 多元统计分析研究的容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X均值向量: 随机向量X与Y的协方差矩阵: 当X=Y时Cov(X,Y)=D(X);当Cov(X,Y)=0 ,称X,Y不相关。 随机向量X与Y的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X,Y为随机向量,A,B 为常数矩阵 E(AX)=AE(X); E(AXB)=AE(X)B; D(AX)=AD(X)A’; )' ,..., , ( ) , , , ( 2 1 2 1P p EX EX EX EXμ μ μ = ' = )' )( ( ) , cov(EY Y EX X E Y X- - = q p ij r Y X ? =) ( ) , (ρ Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变量之间的比较。 4、对数变换:对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。它将具有指数特征的数据结构变换为线性数据结构。 三、样品间相近性的度量 研究样品或变量的亲疏程度的数量指标有两种:距离,它是将每一个样品看作p 维空),(~∑μP N X μ∑μp X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ)()1(,,n X X X )',,,(21p X X X )')(()()(1X X X X i i n i --∑=n 1X μ ∑μX )1,(~∑n N X P μ),1(∑-n W p X X应用多元统计分析试题及答案
中学生心理问题典型案例及分析1.
多元统计分析期末复习试题