第5章(552)均方误差准则(MSE)和LMS算法

5.5.2均方误差准则(MSE )和LMS 算法
引言:均方误差准则同时考虑ISI 及噪声的影响,使其最小化。
本节讨论问题: 1. 均方误差准则;
2. 无限长LMS 均衡器(C (z ),J min );
3. 有限长LMS 均衡器(C opt ,J min );
4. LMS 算法;
5. 均衡器的操作;
6. 递推LMS 算法收敛特性的分析。
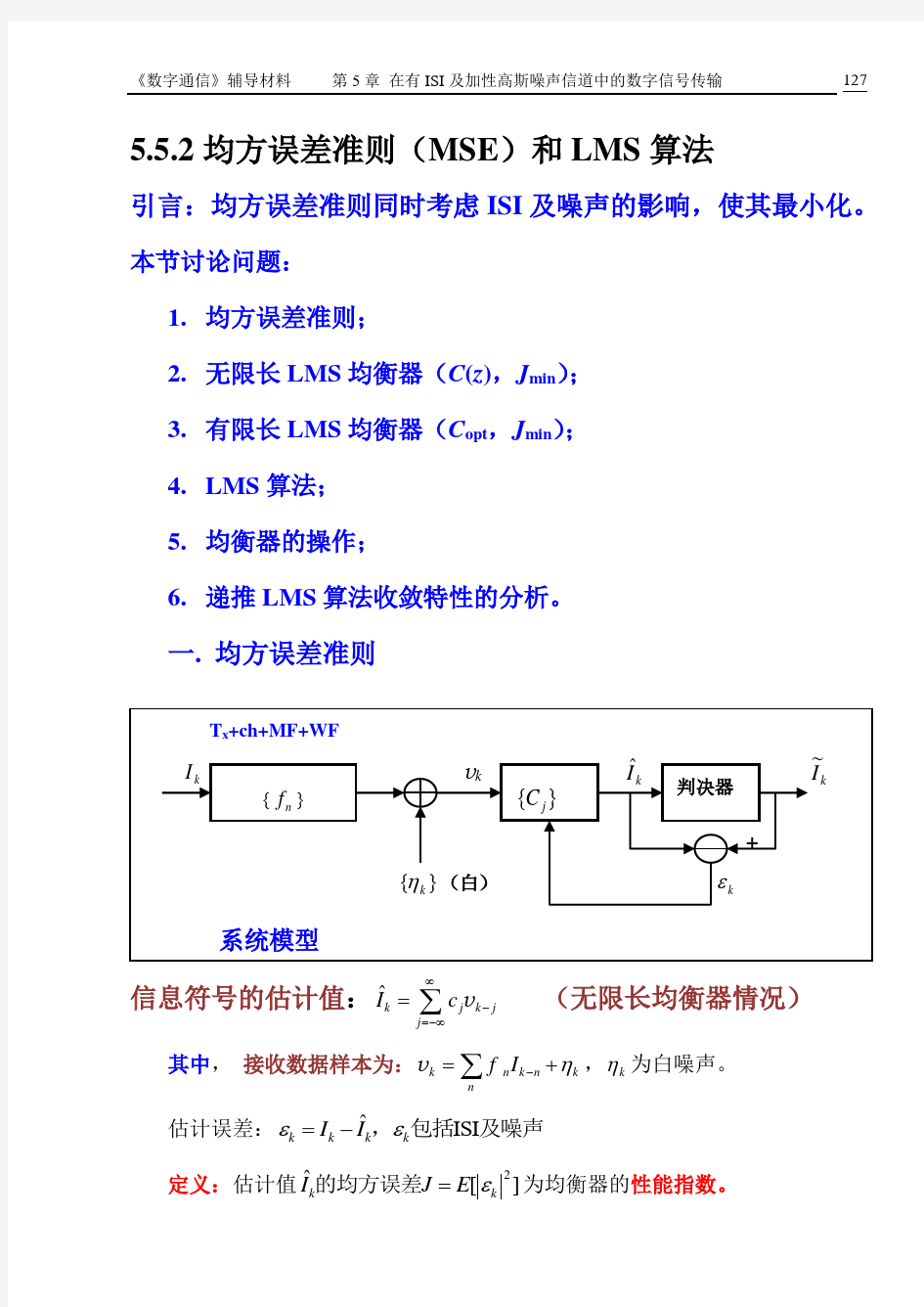
一. 均方误差准则
信息符号的估计值:?k j k j
j I c ∞
-=-∞
=
∑v (无限长均衡器情况)
其中, 接收数据样本为:k n k n k n f I η-=+∑v ,k η为白噪声。 估计误差:?ISI k k k k
I I εε=-,包括及噪声 定义:估计值2?[]k k
I J E ε=的均方误差为均衡器的性能指数。 }{k ηε
均方误差准则:使均方误差性能指数J 最小(min J ),此准则同时考虑使ISI 及噪声影响最小。
获得min J 的途径:调整{}j c ,当min J J =时,opt C C =(最佳抽头系数)
寻找opt C 的方法:1)根据正交性原理(线性均方估计):*
[]0k k l E l ε-=,所有v 。(注:与ZF 准则不同的是,这里的输入是经过两个输入滤波器的数据样本k v ,这就包含了噪声)。即*?[]0kkl E l ε-=,所有I 。
2)求函数极值方法:令
?0=→=??opt k
J
C C 2013年5月3日星期五上午讲于此处,已经是第十次矣。
这两种方法是等价的,证明如下。
证明:求导置零方法与正交性原理等价。
?l i m K
k
j
k
j j k
j
K j j K
I c c
∞
--→∞
=-∞
=-==∑
∑v v
lim T k K →∞
=V c
假如均衡器为有限长,则
?T k k
I =V c 其中
11T
k k K k K k
k K k K v v v v v ++--+-??=??V ,以及 1
1
T
K
K K K c c c c c --+-??=??c 。
()2
??[][()()]k k k k k
J E E I I I I ε**==--c *
[()]T k k k E I ε=-V c
故
{}k k J E ε*
?=-?V c
另一种方法:
()2
2
*??[][()()] {()()}
[][][][]
k k k k k k i k i k j k j i
j
k i k k i j k k j i j k i k j i
j
i
j
J E E I I I I E I c I c E I c E I c E I c c E ε*****
--****----==--=--=--+∑∑∑∑∑∑c v v v v v v
2
*[][][][]k i k k i j k k j i j k i k j i
j
i
j
E I c E I c E I c c E ****----=--+∑∑∑∑v v v v
可见,()J c 是{}j c 的平方函数(二次型)。求导置零可得:
*0k k l j k l k j j
l J E I c E c **
---?????=-+=?????∑v v v 即, ***0, k j k j k l j l J E I c l c --???????=--=-∞<<∞???????????
∑v v
()()**
00k k i k k i E E εε--∴==,或v v ,i -∞<<∞
{}k k J E ε*
?=-?V c
1
1
T
k k K
k K k
k K k K v v v v v ++--+-??=??V
结论:求导方法与正交性原理是等价的,满足正交条件,就可以获得最小MSE 。
二、无限长LMS 均衡器(()min J z C ,性能)
1. 求()z C :从正交原理出发,
()*
0k k l E ε-=v
(10-2-27)
即
*
[()]0k j k j
k l j E I c ∞
--=-∞
-
=∑v
v
即
()()
*
j
k -j
k -l k k l j c E E I ∞
-=-∞
=∑*v
v v (*) 正交条件
注: k l -v 是收数据样本,其中的噪声已经白化。
在(*)式左边可以得到:
{}********
0 k j k l n k j n k j m k l m k l n m n m k j n k l m k j k l n m n m k j n k l m lj
n
m
E E f I f I E f f I I f f E I I N ηηηηδ*------------------????????=++????????
????????=+??
??
=+∑∑∑∑∑∑v v
式中利用了[]0k n k n k k n
f I E ηη-=+=∑,v 。
注:j k jk j k kj j k ,)(δδδδδ==-==-都是Kroenecker 冲激或离散冲激的不同写法。 因此我们有:
***
,00[]k j k l n m n m l j lj m m l j lj n
m
m
E f f N f f N δδδ--+-+-=+=+∑∑∑v v
*
00
L
n n l j
lj n f f
N δ+-==+∑0 0,
l j lj x N l j L
else δ-?+-≤?=??? (A)
注:()()(1/)X z F z F z **=,()1F z **-代表了()F z 序列的共轭颠倒序列。或者说
()1F z **-代表了()F z 的MF(零时延)。
()()(1/)X z F z F z **=
()101L L f f z f z --=++
+1
1110()L L L L L z f f z f z f z **-*-+*--??++++?
?
000
L
L
L
L
L i
j
L
i j i
L j
i
L j i j i j z
f
z
f
z
z
f
f z -*
-*----======∑∑∑∑
00
L
L
L
i j i
L j i j z
f
f z *---===∑∑
00
L L
n i i n i n f f z *-===∑∑
L L
l n l n l L n f
f z
*-+=-==
∑∑(注:令l i n =-) 故
*0
L
l n n l n x f f +==∑,其支撑为:L l L -≤≤
或者说,可以得到
*
**
*
*0
L
L k
k n n
l
k l l l k n n k
n n k l
l
n n x f f
f f f f f f
f f ----+++===*====∑∑∑∑
也可以写为
j l j l L n j
l n n L
n j
l n n x f
f
f f
---=-+=-+==
∑∑)
(0
*
*
(*)式右边:
,*******
, 1
(){[]}{}{}k k l n k k l k n k l n k l n k k l n k k l n
n
c c E I E I f I f E I I E I δηη---------==+=+∑∑v
式中,,,10k k l n l n n l n l
δδ---=-?==?≠-?,当,当
由此可得
{}** , 0
l k k l
f L l E I --?-≤≤=??v (B)
将(A )、(B )两式代入(*)式:
*0[]j
l j
lj l j c x
N f δ∞
--=-∞
+=∑
上式就是: *
0l l l l c x N c f -?+=
取Z 变换: ()()110[()]()C z F z F z N F z **-**-+= (10-2-31)
则MMSE 均衡器 ()11
0()
()()F z C z F z F z N **-**-=+ (10-2-32) 等效MMSE 均衡器: ()()100
11
()()C z F z F z N X z N **-'=
=++
(10-2-33)
k
I ^
()
z C '
2. 求min J (最小均方误差) (1) 时域
2*****?[][()][][]k k k k k k k j k j
j
J E E I I E I E c εεεε-==-=-∑v 利用正交原理第二项为零,所以
2**min ?[()][][()]k k k k k j k j
j
J E I I I E I E I c -=-=-∑v *
[]j k j k j j j
j
c c E I c c f --=-=-∑∑v (利用(B)式)
令信息符号的平均功率为1,则
2
[]1k c E I ==
min 0
11j
j l l
l j J c
f c f ∞
-==-∞
=-
=-?∑
(2)频域
通过z 变换及令,T j e z ω=将min J 式的{}关系变换成n f J ~min
()
()关系ωωH e X J T j ?~min
全传输系统响应:{}()()()0
N z X z X z B b n +=? (10-2-35)
以z 反变换(留数法)求:
()112n-n c
b B z z dz j
π=
?
()()()1001122c
c
X z b B z z dz dz j
j
z X z N ππ-∴=
=
+????
?
?
(10-2-36)
j T z e T
ωπ
ω=≤
令,且,
()
()()()
()00
1
2 2j T T
j T j T j T T j T
T j T
T
X e b e e jT d j X e N X e
T
d X e
N
ωπ
ωωπωωπ
π
ωω
πω
π
---
=
??+=
+?? (10-2-37)
代入 min 01J b =-,得
()0
m i n 0
2T j T
T
N T
J d X e
N
π
π
ωωπ
-
=
+?
将()j T X e ω以信道折叠谱表示。因为
()()()
k t kT
x x kT h t h t *===?-
()()h t h t *?-的傅里叶变换为2
()H ω,故
2
12()FT
k k n n x t kT H T T πδω∞
∞=-∞
=-∞??-←?→+ ???∑∑
又
22()()()j ft j fkT k k k k k k k FT x t kT x t kT e dt x e DTFT x ππδδ∞
∞∞∞
--=-∞=-∞
=-∞-∞??-=-==????∑∑∑?
所以
()2
12 j T
n n X e H T T T ωππωω∞=-∞??=+≤ ?
??∑, (10-2-18) 所以
min
2
for ISI 0
212T T
n T T
N J d n H N T T π
π
ωπ
πω-
∞
=-∞===?
?++ ???
?∑ (10-2-38)
所以,当ISI=0时, 0
min min 0
011N J J N =
<<+, (10-2-39) 因k k k I I ?-=ε,故?k k k I I ε=+,22?[||]||k k k E I E I ε=-,利用正交原理*?[]0k k l
E ε-=I ,易证:
222?||||||k k k E I E I E ε=+,即2min ?[]1k E I J =-。 输出SNR: 2min
2
min
?[]1[]
k k E I J J E γε∞-=
=
(10-2-40)
三、有限长LMS 均衡器 (opt C ,
min J )
均方误差:()2
2
?[]K k k k j k j
j K J k E I I E I c -=-??
??=-=-????∑v {}k k J E ε*
?=-?V C
101T
K K K K c c c c c --+-??=??C 1
1T
k k K
k K k
k K k K v v v v v ++--+-??=??V
k
I =
1、求opt C :无限长均衡器
*0[]j
l j
lj l j c x
N f δ∞
--=-∞
+=∑
仿上面无限长均衡器的推导: 根据正交条件:
[]
*0l K
K
j lj j
l j
f N x
c --=-=+∑δ
令0lj l j lj x N δ-??Γ=+??
则0 0,l j lj lj x N l j L δ-?+-≤?Γ=???,
其他
(注: l x 的支撑为l L ≤。)
令 *
00 l l f L l ξ-?-≤≤?=???,
,
其他
得
∑-==Γ
K
K
j l lj
j
c ξ (10-2-43)
矩阵形式:ΓC =ξ (10-2-46)
所以, 1opt -=C Γξ (10-2-47)
说明:opt C , ξ为有)12(+K 个元素的列向量
Γ为(2K+1)×(2K+1)的Hermitian 矩阵。
因为自相关函数*k k x x -=且*lj jl δδ=,所以ij ??=Γ??
Γ中元素满足*
ij ji Γ=Γ。Γ是共轭转置阵(Hermite )阵。
2、求均衡器的性能即求最小能达到的均方差min J : 前已经证明min 1j
j j J c
f ∞
-=-∞
=-
∑
将opt C 代入()K J min 式:
1min ()111j j opt j K
J K c f **--=-''=-
=-=-∑
ξC ξΓξ (10-2-48)
注:j f 的支撑为0j L ≤≤。
工程实用方法: 采用简单的迭代过程——最速下降法。
四. LMS 算法:
内容: a)算法:k k k G C C ?-=+1 (理论算法)
b)梯度: ()k k k k
dJ E d ε*
=
=-G V C c) 工程实用算法:1??k k k k ε*++?C =C V d) 均衡器结构:图11-1-2
1、算法:LMS 算法是一种最陡下降法,其实质是一个迭代过程,而迭代过程是通过递推运算来进行的。 设{}j c 有(2K +1)个抽头
递推运算: ()()()K K j k c k c k c j j j ,,,,
0 1-=+=+δ 每次迭代变化量: ()()k G k c j j ?-∝δ 令 ()()k G k c j j ?-=δ 则 ()()()k G k c k c j j j ?-=+1 或矩阵形式: k k k G C C ?-=+1,
式中?为调节阶距(步长)注:可以看到
()()
()K K j k G k c k c j j j ,,,,0 1
1-=?-=-+,
即强制要求抽头系数向着误差下降的方向变化。 则 ()()()k G k c k c j j j ?-=+1 或矩阵形式: k k k G C C ?-=+1,
式中?为调节阶距(步长step ),其中第k 符号时间的抽头系数列矢量(即
均衡器)为:
101()()
()
()()T
k K K K K c k c k c k c k c k --+-?
?=??C
,j opt j j ()()()
曲线的梯度次迭代时,为第j j j c J k k dc k dJ k G ~=
2、梯度:
{}k k k k
dJ E d ε*
=
=-G V C
{}k k k k
dJ E d ε*
=
=-G V C 11T
k k K
k K k
k K k K v v v v v ++--+-??=??V
讨论:1)理想情况下,经过若干次迭代(时0k k =),
0min
{}0()opt k k k
E J k J ε*
=??
=-=??
=??C C G V
2)实际情况中,计算k G 困难
*[]k k k E ε=-G V 统计平均, 不实时
为克服这一困难,用估计值k
G ?取代梯度真值k G *
[]k k k E ε=-G V
对k G 的无偏估计有:?{}k k E =G G 则
k
k k V G *?ε-= k G 为梯度真值,k
G ?为真值k G 的无偏估计量。
3. 工程实用LMS 算法:
k k k G C C ???1?-=+ (11-1-9) 即 *1??k
k k k V C C ε?+=+ (11-1-11) 或 k
k k k V C C *1??ε?+=+
在商用的自适应均衡器中,为简化乘法运算次数,仅取k v 和(或)k ε的正负号进行运算,而不管大小。其优点是简单,易实现,运算次数少;缺点是收敛慢。 如:
()()()()
*
1csgn csgn j j k k j c k c k v ε-+=+? (11-1-14)
定义复符号函数:()()()()
()()()()()()()()()1 Re 0Im 01 Re 0Im 0csgn 1 Re 0Im 01 Re 0Im 0j x x j x x x j x x j x x ?+>>?
->??
--<
,
,
(11-1-15)
4. 均衡器结构
图11-1-2 基于MSE 准则的线性自适应均衡器
五. 均衡器的操作过程 1. 方框图
2. 两种工作模式(状态)
(1)训练模式(training mode ): k
k k I I ?-=ε (2
)工作模式(run mode ): k k k I I ?~-=ε, 2
10- ,即使有错判,由于?很小,由此引起的误调整影响很小。 3. 步长?选择与收敛特性 训练时:1? 1?大—加速初始调整,接近m i n J 工作时:2? 2?小—稳态误差小,m i n J J ≈ 步长?选择考虑:●稳定且收敛快 ● 稳态MSE 小 k I 六. 递推LMS 算法收敛特性的分析 1、引言 说明三个问题:要解决什么问题;分析从何入手;分析的方法。 (1) 算法表示 理论上LMS 算法: k k k G C C ?-=+1, (A ) 实用的递推算法: *1??k k k k V C C ε?+=+ (B ) 梯度向量有噪无偏估计值:*?k k k V G ε-= (2) 问题 ● 收敛特性与?的关系? ● 如何选择?,以确保收敛? 因为{} k k E G G ?=,即k G ?为真值k G 的无偏估计, 所以,?对收敛特性的影响,对(A )(B )两式是相同的。 为数学分析方便,我们只研究(A )式的收敛特性。 (3) 收敛特性的分析方法 采用反馈系统稳定性的分析方法: ● 建立以1+k C 输出的闭环系统模型,定性分析?的影响; ● 建立系统的差分方程,定量分析?的影响。 2、闭环系统模型——定性分析收敛特性 算法: 1k k k +=-?C C G (A ) 式中, ()k k k =--G =ΓC -ξξΓC (B ) Γ-接收信号自相关矩阵,由[]k j k l E v v *--确定。 ξ-互相关矩阵,由[]k k l E I v *-确定。 分析:由(A )式可看出 (1)k C 的迭代过程可以看作:每次迭代增量(k k δ=-?C G )的累积过程 —由保持器实现; (2)第k 时刻计算的增量(k -?G )应在第(k+1)时刻反映出来 —由延迟(Z -1)来实现。 结论:对闭环输出1k +C 收敛特性影响因素:, ?Γ 3、系统的差分方程——定量分析收敛特性 由(A)式 1=()k k k k k +=-?-?C C G C ΓC -ξ 得 1()k k +=-?+?C I ΓC ξ (A ') (11-1-20) 为一阶差分方程组,即 1(21)k k C I C K ξ+???????? ? ? ????????=-?Γ +?+????????????????????? ?????? 因为Γ不是对角矩阵,故,(2K+1)个一阶差分方程是相互耦合的,必须联解。所以,用解联立方程组来定量分析收敛特性是困难的。 解决方法:利用线性变换(酉变换)来解耦。 ①Γ为Hermite (厄米特)矩阵,可用U (酉矩阵)表示为 *'=ΓU ΛU (U -1) (11-1-21) 1 2 N λλλ????? ?=????? ? Λ 式中,U (酉矩阵)由Γ的特征向量确定。 Λ(对角矩阵)的对角元素为Γ的特征值,特征值{}i λ为特征方程 0λ-=ΓI 的根。 ②再利用U 矩阵的性质: *'=U U I (U -2) ③将(U -1)式代入(A ')式,两边再乘*'U ,然后利用(U -2)式,可得 1()k k +=-?+?ξΛC I C (11-1-22) 式中, 11 k k k k *++**'?=? '=??'=? C U C C U C ξU ξ 1 () () () k k k k +=-?+ ?ΛC I C ξ 信道特性反映迭代生不迭代而化的化量与与有产随变变无关关 说明:(1)因为Λ为对角矩阵,所以一阶差分方程组是线性不相关的(即解耦)。 (2) 收敛特性取决于其齐次方程组: 1()k k +=-?C I ΛC (11-1-23) 即表示成(2K+1)个一阶差分方程组: ,(1),()0,(1)0,()0 ,(1),()111K k K k K k k K k K k K C C C C C C λλλ-+--++???? -?????? ?????? ?????????=-???? ?????? ???? ??? ??-?? ????? 可见,(2K+1)个{}i λ与(2K+1)个{}i C 对应。 对第j 个抽头系数C j 的差分方程为 ,(1) ,()(1)j k j j k C C λ+=-? ,,0, ,0,1,2, j K K k =-= 其相应的闭环系统模型为: 系统函数为: 1 1 1(1)j z λ---? 令11(1)0j z λ---?=,得极点:1j z λ=-? 要使迭代过程收敛,应使极点在单位圆内,即 11j λ-?< (11-1-24) 即, 111j λ-<-?< ,() j k C ,(1) j k C + 又因为{}j λ为Γ的(2K+1)个特征值;而Γ为自相关矩阵、Hermite 型、正定 的,因此,0 ( )j all j λ>,则 2 0j λ 又因为各抽头用统一的步长?,为保证稳定收敛,以max λ确定?。 因此,若步长?满足:max 2 0λ , 则递推算法是稳定的,收敛的。 式中,max λ是Γ的最大特征值,其上界为 max ,00trace (21)(21)()K j j j j K K K x N λλ =-< ==+Γ=++∑Γ ,0,000(21)(), all j j K x N j Γ=Γ=++ 4、收敛特性的分析 (1)收敛特性~? 在满足稳定递推运算条件下(即max 2 0λ ), ??↑?↑? ?↑?? 收速度差敛稳态误矛盾解决方法:分12 ??, (一般21 /10 ??=)。 LMS 算法的优点:简单,各抽头用同一个?。 LMS 算法每次迭代时,一个抽头做两次计算(一次乘法,一次加法), 则N 个抽头(这里N=2K+1),每次迭代计算量为2N+1≈2N 。 LMS 算法的缺点:收敛慢。 因为按max λ确定?,牺牲了大多数抽头乃至整个系统的收敛速度。 (2)收敛特性~λ(max λ,min λ) 收敛速度~max min λ λ?? ??? 比值有关。 若max min 1λλ?? → ??? ,选择适当的Δ,可快速收敛。 若max min 1λλ?? >> ??? ,收敛慢。 (3) 收敛特性~信道频率响应()C f 的关系 ~~~~()j n x f C f λΓ 对有深度衰减的信道,max min 1λ λ?? >> ??? ,收敛慢。 基于最小均方误差的Tikhonov正则化参数优化研究 摘要:本文首先介绍了求解病态方程的L-曲线法、GCV法等常用的方法,然后提出了基于最小均方误差的最优Tikhonov正则化求解参数的方法。通过仿真实验表明,本文提出的基于最小均方误差的Tikhonov正则化参数优化选择方法是一种可行有效的方法。 关键字:Tikhonov正则化、均方误差、病态问题 Based on the minimum mean square error of Tikhonov regularization parameter optimization research Abstract:This paper first introduces the morbid equation of L - curve method, GCV method such as the commonly used method, and then based on the minimum mean square error of the optimal Tikhonov regularization method to solve the parameter. Through the simulation experiments show that the proposed based on the minimum mean square error of Tikhonov regularization parameter optimization selection method is a feasible and effective method. Key words: Tikhonov regularization, mean square error (mse), pathological problems 1 引言 求解线性不适定问题的正则化方法中,应用最广泛也最经典的是Tikhonov正则化方法[1]。随着各个领域中数据的处理中应用多种不适定问题的正则化方法,Tikhonov正则化方法是比较常见也是应用比较广泛的方法。该方法可以解决不同领域中不适定问题的纠正,地震中发射波长中的应用、电容层析成像图像重建、无线传感器网络实现监测和跟踪等病态问题中均可以应用Tikhonov正则化方法。本文通过对Tikhonov正则化方法中常见的L-曲线法和GCV 法进行分析Tikhonov正则化方法的特点,通过L-曲线法和GCV法进行Tikhonov正则化方法参数的确定,从而确定基于最小均方误差的Tikhonov正则化优化参数,并通过仿真实验进行验证,从而确定基于最小均方误差的Tikhonov正则化优化参数可行。从而为更深入的研究提供可靠依据。 2迭代Tikhonov正则化方法参数确定方法: 目前正则化参数的选择有先验和后验两种方法。用先验法选择正则化参数时,都需要预先对于原始数据的误差水平做出估计,但在大多数情况下这是难以做到的。后验取法可以直接应用带有噪音的原始数据对正则化参数作出估计。 2.1L-曲线法 线性分类器之 感知机算法和最小平方误差算法 1.问题描述 对所提供的的数据“data1.m ”,分别采用感知机算法、最小平方误差算法设计分类器,分别画出决策面,并比较性能,并且讨论算法中参数设置的影响 2.方法叙述 2.1感知机算法 1.假设已知一组容量为N 的样本集1y ,2y ,…,N y ,其中N y 为d 维增广样本向量,分别来自1ω和2ω类。如果有一个线性机器能把每个样本正确分类,即存在一个权向量a ,使得对于任何1ω∈y ,都有y a T >0,而对一任何2ω∈y ,都有y a T <0,则称这组样本集线性可分;否则称线性不可分。若线性可分,则必存在一个权向量a ,能将每个样本正确分类。 2.基本方法: 由上面原理可知,样本集1y ,2y ,…,N y 是线性可分,则必存在某个权向量a ,使得 ?? ???∈<∈>21 y ,0y ,0ωωj j T i i T y a y a 对一切对一切 如果我们在来自2ω类的样本j y 前面加上一个负号,即令j y =—j y ,其中2ω∈j y ,则也有 y a T >0。因此,我们令 ???∈∈='21y ,-y ,ωωj j i i n y y y 对一切对一切 那么,我们就可以不管样本原来的类型标志,只要找到一个对全部样本n y '都满足 y a T >0,N n ,,3,2,1??=的权向量a 就行了。此过程称为样本的规范化,n y '成为规范化 增广样本向量,后面我们用y 来表示它。 我们的目的是找到一个解向量* a ,使得 N n y a n T ,...,2,1,0=> 为此我们首先考虑处理线性可分问题的算法。先构造这样一个准则函数 )()(y ∑∈= k y T p y a a J γ δ 式中k γ是被权向量a 错分类的样本集合。y δ的取值保证因此()a J p 总是大于等于0。即错 第3章最小均方算法 3.1 引言 最小均方(LMS ,least-mean-square)算法是一种搜索算法,它通过对目标函数进行适当的调整[1]—[2],简化了对梯度向量的计算。由于其计算简单性,LMS 算法和其他与之相关的算法已经广泛应用于白适应滤波的各种应用中[3]-[7]。为了确定保证稳定性的收敛因子范围,本章考察了LMS 算法的收敛特征。研究表明,LMS 算法的收敛速度依赖于输入信号相关矩阵的特征值扩展[2]—[6]。在本章中,讨论了LMS 算法的几个特性,包括在乎稳和非平稳环境下的失调[2]—[9]和跟踪性能[10]-[12]。本章通过大量仿真举例对分析结果进行了证实。在附录B 的B .1节中,通过对LMS 算法中的有限字长效应进行分析,对本章内容做了补充。 LMS 算法是自适应滤波理论中应用最广泛的算法,这有多方面的原因。LMS 算法的 主要特征包括低计算复杂度、在乎稳环境中的收敛性、其均值无俯地收敛到维纳解以及利用有限精度算法实现时的稳定特性等。 3.2 LMS 算法 在第2章中,我们利用线性组合器实现自适应滤波器,并导出了其参数的最优解,这对应于多个输入信号的情形。该解导致在估计参考信号以d()k 时的最小均方误差。最优(维纳)解由下式给出: 其中,R=E[()x ()]T x k k 且p=E[d()x()] k k ,假设d()k 和x()k 联合广义平稳过程。 如果可以得到矩阵R 和向量p 的较好估计,分别记为()R k ∧ 和()p k ∧ ,则可以利用如下最陡下降算法搜索式(3.1)的维纳解: w(+1)=w()-g ()w k k k μ∧ w()(()()w())k p k R k k μ∧∧ =-+2(3.2) 其中,k =0,1,2,…,g ()w k ∧ 表示目标函数相对于滤波器系数的梯度向量估计值。 一种可能的解是通过利用R 和p 的瞬时估计值来估计梯度向量,即 1 0w R p -=(3.1) 第三章估计理论 什么是“估计”? 通俗解释:对事物做大致的判断 专业解释:通过一定的技术手段获得关于被估计事件、参数、过程的相关信息,再对这些信 息进行加工、处理获得结果的过程。 3.1引言 3.1 引言 根据研究对象的不同估计分为二种 参量估计:被估计的对象是随机变量或非随机的未知量 波形估计:被估计的对象是随机过程或非随机的未知过程 信号参量估计理论 与信号参量估计相关的理论 最佳估计 一定准则下的“最好”估计 应用领域 通信系统、雷达系统、语音、图像处理、自动控制 3.1.2 估计量的性质质 假设得到N 个观测样本数据为: 为待估计参量,[][]0,1,,1 x n w n n N θ=+=?…式中,是观测噪声。 θ[]w n 估计的任务就是利用观测样本数据构造估计量,获得估计量后,通常需要对的质量进行评价,这就需要研[]x n θ θ θ究估计量的主要性质。 估计量也是一个随机变量,具有均值和方差等统计特征,可以利用其统计特征对估计量的性质进行评价。评价 θ 指标包括:无偏性、一致性、充分性和有效性。 1、无偏性 非随机参量随机参量??θθ 无偏估计 渐进无偏估计()E θθ=()()E E θ=?lim ()N E θθ→∞=?lim ()()N E E θ θ→∞=如果上式不满足,则是一个有偏估计 θ 定义 为估计量的偏估计量的无偏性保证估计量分布在参量真值附近,是衡量()()b E θθθ=?估计量性能优劣的重要指标。然而,一个估计量是无偏的不能确保就是好的估计量,它仅能保证估值的均值近似真值。 2、一致性 可以通过增加观测样本数据来减少估计量的估计误差,具有这种性质的估计称为一致估计。 简单一致性: ?lim (||)1N P θθδ→∞?<=均方一致性:2?lim [()]0N E θ θ→∞ ?= ?定义估计误差,对无偏估计,误差的方差为 222?εθθ=?在同时满足无偏性、均方一致性的条件下,随着观测样本()()()() Var E b E εεθε==数的增加,估计误差的方差将减小并趋于零。 V ol 35No.6 Dec.2015 噪 声与振动控制NOISE AND VIBRATION CONTROL 第35卷第6期2015年12月 文章编号:1006-1355(2015)06-0152-07 次级通路估计误差偏移下的滤波-x 最小均方算法 收敛性能 玉昊昕,陈克安 (西北工业大学航海学院环境工程系,西安710072) 摘要:实现自适应有源噪声控制算法时,次级通路辨识是其关键环节。由于环境干扰等因素的存在,实际的次级通路特性不是恒定的,而是在一定范围内随机变化。次级通路传递函数建模结果与实际通路之间会存在随机偏移误差,将影响自适应有源控制算法的收敛性能,严重的可能导致系统不稳定,因此研究此种情况下的系统收敛性能十分必要。以单频噪声为例,通过建立滤波-x 最小均方算法(Fx LMS )的等效传递函数,用线性时不变(LTI )系统的稳定性判据求解算法稳定条件,求得次级通路误差存在时收敛系数的取值范围,然后通过系统极点来分析此时算法收敛特性,并研究收敛系数取值对次级通路误差的承受能力。最后,通过实验证明了分析的有效性。 关键词:振动与波;有源噪声控制;Fx LMS 算法;次级通路误差;收敛性能中图分类号:TU112.3 文献标识码:A DOI 编码:10.3969/j.issn.1006-1335.2015.06.033 Convergence Performance of Filtered-x LMS Algorithm with Shifting Secondary Path Estimation Errors YU Hao-xin ,CHEN Ke-an (School of Marine Engineering,Northwestern Polytechnical University,Xi ’an 710072,China ) Abstract :Implementation of adaptive active noise control requires an estimate model of the secondary path.In practice,the characteristics of physical secondary path are not constant but vary randomly within a specific range because of the environmental disturbance.Thus,random shifting errors,which can lead to low convergence performance or instability,will exist between the modeling results and the physical path.In this paper,the equivalent transfer function of filtered-x LMS (FxLMS)algorithm was applied to calculate the stable conditions of the algorithm according to the stability criterion of linear time invariant (LTI)system.Convergence performance of the algorithm was studied by analyzing the root locus of the equivalent transfer function.Then the effect of adaptive step on the secondary path estimation error tolerance was studied.Finally,an experiment was done to validate the analysis. Key words :vibration and wave ;active noise control ;FxLMS algorithm ;secondary path error ;convergence performance Fx LMS 算法在有源噪声控制中是最常用的前馈算法[1],特别适用于抑制周期性扰动,特别是单频信号,在此情况下,可以忽略前馈结构的因果性约束。 Fx LMS 算法形式简单,便于实现,且运算复杂度较低,有较好的稳定性,是ANC 领域最基本的算法,因此虽然已经得到了广泛运用和研究,但仍然有 收稿日期:2015-04-08 作者简介:玉昊昕(1987-),男,广西梧州市人,博士生,主要 研究方向:有源噪声控制算法研究。 通讯作者:陈克安,男,博士生导师。 E-mail:kachen@https://www.360docs.net/doc/e318694950.html, 进一步研究的必要。在Fx LMS 算法中,为了补偿次级通路(从控制器输出到误差传感器输入之间的物理通路)的影响,参考信号要先经过预估计的次级通路传递函数进行滤波。理论上讲,当估计完全精确时,必定存在使算法收敛的收敛系数。然而实际中,次级通路特性的估计误差总是存在的。对存在次级通路误差时的算法收敛性,已有一些得到广泛认同的结论。 对于宽带信号,Wang 通过常微分方程(ODE )给出了Fx LMS 算法收敛的一个充分条件[2],并将其推广到Fu LMS 算法上[3],Mosquera 也完成了类似工作[4]。他们得到的充分条件十分严格,要求次级通 5.5.2均方误差准则(MSE )和LMS 算法 引言:均方误差准则同时考虑ISI 及噪声的影响,使其最小化。 本节讨论问题: 1. 均方误差准则; 2. 无限长LMS 均衡器(C (z ),J min ); 3. 有限长LMS 均衡器(C opt ,J min ); 4. LMS 算法; 5. 均衡器的操作; 6. 递推LMS 算法收敛特性的分析。 一. 均方误差准则 其中, 接收数据样本为:k n k n k n f I η-=+∑v ,k η为白噪声。 估计误差:?ISI k k k k I I εε=-,包括及噪声 定义:估计值2?[]k k I J E ε=的均方误差为均衡器的性能指数。 均方误差准则:使均方误差性能指数J 最小(min J ),此准则同时考虑使ISI 及噪声影响最小。 获得min J 的途径:调整{}j c ,当min J J =时,opt C C =(最佳抽头系数) 寻找opt C 的方法:1)根据正交性原理(线性均方估计):* []0k k l E l ε-=,所有v 。(注:与ZF 准则不同的是,这里的输入是经过两个输入滤波器的数据样本k v ,这就包含了噪声)。 即*?[]0k k l E l ε-=,所有I 。 2)求函数极值方法:令 ?0=→=??opt k J C C 2013年5月3日星期五上午讲于此处,已经是第十次矣。 这两种方法是等价的,证明如下。 证明:求导置零方法与正交性原理等价。 ?lim K k j k j j k j K j j K I c c ∞ --→∞ =-∞ =-==∑∑v v lim T k K →∞ =V c 假如均衡器为有限长,则 ?T k k I =V c 其中 11 T k k K k K k k K k K v v v v v ++--+-??=??V ,以及 1 1T K K K K c c c c c --+-??=??c 。 基于最小均方误差(MMSE)估计的因果维纳滤波的实现 一.功能简介 基于最小均方误差(MMSE)估计的因果维纳滤波的Matlab 实现,用莱文森-德宾(Levinson-Durbin)算法求解维纳-霍夫方程(Yule-wa1ker)方程,得到滤波器系数,进行维纳滤波。 二.维纳滤波简介 信号处理的实际问题,常常是要解决在噪声中提取信号的问题,因此,我们需要寻找一种所谓有最佳线性过滤特性的滤波器,这种滤波器当信号与噪声同时输入时,在输出端能将信号尽可能精确地重现出来,而噪声却受到最大抑制。 维纳(Wiener)滤波就是用来解决这样一类从噪声中提取信号问题的一种过滤(或滤波)方法。 一个线性系统,如果它的单位样本响应为h (n ),当输入一个随机信号x (n ),且 )()()(n n s n x υ+= 其中s (n )表示信号,)(n υ表示噪声,则输出y (n )为 ∑-=m m n x m h n y )()()( 我们希望x (n )通过线性系统h (n )后得到的y (n )尽量接近于s (n ),因此称y (n )为s (n )的估计值, 用)(?n s 表示,即 )(?)(n s n y = 维纳滤波器的输入—输出关系 如上图所示。这个线性系统)(?h 称为对于s(n)的一种估计器。 如果我们以s s ?与分别表示信号的真值与估计值,而用e (n )表示它们之间的误差,即 )(?)()(n s n s n e -= 显然,e (n )可能是正的,也可能是负的,并且它是一个随机变量。因此,用它的均方值来表达误差是合理的,所谓均方误差最小即它的平方的统计平均值最小: [][] 22)?()(s s E n e E -=最小 已知希望输出为: 1 ?()()()()N m y n s n h m x n m -===-∑ 误差为: 1 ?()()()()()()N m e n s n s n s n h m x n m -==-=--∑ 均方误差为: 1 2 20()(()()())N m E e n E s n h m x n m -=????=--???? ?? ∑ 上式对() m=0,1,,N-1h m 求导得到: 1 02(()()())()0 0,1,21N opt m E s n h m x n m x n j j N -=??---==-???? ∑ 进一步得: [][] 1 ()()()()()0,1,1N opt m E s n x n j h m E x n m x n j j N -=-=--=-∑ 从而有: 1 ()()() 0,1,2,,1N xs opt xx m R j h m R j m j N -==-=-∑ 于是就得到N 个线性方程: (0)(0)(0)(1)(1)(1)(1)1(1)(0)(1)(1)(0)(1)(2)1(1)(0)(1)(1)(2)(1)(0) xs xx xx xx xs xx xx xx xs xx xx xx j R h R h R h N R N j R h R h R h N R N j N R N h R N h R N h N R ==+++--??==+++--? ? ??=--=-+-++-? 最小方差无偏估计 ?最小方差无偏估计的定义?RBLS定理 ?计算实例 1. 最小方差无偏估计的定义 对于未知常数的估计不宜采用最小均方估计,但可以约束偏差项为零的条件下,使方差最小。 定义:最小方差无偏估计定义为 约束估计是无偏的条件下,使方差 {}{} 22????()[()]()min Var E E E θ=θ-θ=θ-θ→估计的均方误差为 22????(){[]}()[()] Mse E Var E θ=θ-θ=θ+θ-θ偏差项 估计方差 在前面讨论的有效估计量是无偏的,且方差达到CRLB,所以有效估计量是最小方差无偏估计。 如果有效估计量不存在,如何求最小方差无偏估计呢?这时可利用RBLS定理求解。 2. RBLS(Rao-Blackwell-Lehmann-Scheffe)定理如果是一个无偏估计、是一个充分统计量, 那么是:(1) θ的一个可用的估计(a valid estimator); (2) 无偏; (3) 对所有的θ,方差小于等于的方差。 θ()T z ?(|())E T θ =θz θ如果充分统计量是完备的, 则是最小方差无偏估计。()T z ?(|())E T θ =θz 完备: 只存在唯一的T (z)的函数,使其无偏。 例1:高斯白噪声中未知常数的估计 0,1,...,1 i i z A w i N =+=-i w 其中是均值为零、方差为σ2高斯白噪声序列。求最小方差无偏估计。 解:首先找一个无偏估计,很显然是无偏。 1A z =其次,求A 的充分统计量,由前面的例题可知, 是A 的充分统计量。 1 ()N i i T z -==∑z 3. 计算举例 第3章最小均方(LMS)算法 最小均方算法即LMS算法是B.widrow和Hoff于1960年提出的:由于实现简单且对信号统计特性变化具有稳健件,LMS算法获得了极广泛的应用。LMS算法是基于最小均方误差准则(MMSE)的维纳滤波器和最陡下降法提出的。本章将进—步时论最小均方误差滤波器和针对这种滤波器的最陡下降法,并在此基础上详细讨论LMS算法。 LMS算法的缺点在于当输人信号的自相关关矩阵的特征值分散时,其收敛件变差。为了克服这问题并进一步简化LMs算法,学者们进行广长期研究并提出了不少改进算法,本章将对这些算法进行讨论。 最小均方误差滤波器 最小均方误差滤波器的推导 第2章2.2节已对均于图1.2的最小均力误差滤波器作了概述。本分将针对时域滤波情况进一步讨论最小均方误差滤波器。为便于讨论, I.5国内外MIMO技术研究现状 虽然MIMO无线通信技术源于天线分集技术与智能天线技术,但是MIMO系统在无需增加频谱与发射功率下就可以获得令人振奋的容量与可靠性提升,它引发了大量的理论研究与外场实验。自从1995年Telatar推导出多天线高斯信道容量['6}, 1996年Foschini提出BLAST算法[72]与1998年Tarokh等提出空时编码[(4]以来,MIMO无线通信技术的研究如雨后春笋般涌现[(73-300]。至2004年底,IEEE数据库收录该领域的研究论文己达数千篇(http://ieeexplore. ieee. org/},它们包含了MIMO无线通信技术的理论研究到实验验证以及商用化的各个方面。目前,国际上很多科研院校与商业机构都争相对MIMO通信技术进行深入研究,MIMO技术正以前所未有的速度向前发展[85]。这里列举一些国内外在研究MIMO 通信技术方面最具有代表性的机构与个人,以洞察MIMO技术的研究现状与发展动态。 A T&T Bell Lab是多天线技术研究的倡导者,其研究员I. E. Telatar ,G.J.Foschini、M.J.Gans,GD.Golden, R.A.V alenzuela, P.W.Wolniansky、D-S.Shiu,J.M.Kahn, J.Ling, J.C.Liberti,Jr.等长期从事MIMO技术研究[68,84],其第一个空时方案就是著名的BLAST结构[[74一,S,lzz],其开创性的研究包括【5,72-76,88】等]https://www.360docs.net/doc/e318694950.html,lproject/blastl] o J.H.Winters等还公布了一些研究与测试结果[ 19,64,96,180,279,282,283,285,286,306]。 斯坦福大学A.J.Paulraj教授是研究空时无线通信技术的先锋,长期从事智能天线与空时处理研究[1,11,32,41,47,91,110-111,126,139,147,152,160,255,284]{www.stanford.cdw-apaulraj}在MIMO技术研究方面具有很深的造诣,其创建的Iospan无线通信公司,主要研究MIMO 空时固定无线接入技术[80,83,305]。 奥斯汀德州大学(Univ, of Texas at Austin)电子与计算机工程系Robert W. Heath Jr教授课题组()httpa/www. ece. utexas. edu/)rheafh/)深入而系统地研究MIMO无线通信系统及其物理层、链路层与网络层方面,包括调制、编码与自适应调制、软件调度、干扰消除以及先进的多址技术等[[48,54,255]。 伯克利加州大学(University of California at Berkeley)电子工程与计算机科学系David Tse 信号处理与分析课程设计报告 项目名称:基于LMS最小均方误差法的 语音降噪 :07021102 台斯瑶 07021106 王金泊 指导教师:如玮 目录 一、课题背景和简介 (3) 二、训练目的 (3) 三、训练容 (4) 四、最小均方差LMS实现自适应滤波器的方法介绍 (4) 五、实验设计及实施过程 (6) 1、滤波器结构设计 (7) 2、高斯白噪声的实现方法 (8) 3、LMS算法的实现 (10) 六、实验结果分析 (11) 七、从实验中分析LMS算法的缺点 (14) 八、实验完整程序 (14) 九、参考文献 (18) 十、特别鸣 (18) 一、课题背景和简介 本课题是根据电子信息类本科生信号处理和分析课程的学习容和语音信号处理的实际应用相结合而设计的实践性训练。课程训练以数字信号处理为基础,在掌握基本原理的同时,理解语音信号的相关知识并结合实际应用实现对语音信号的分析和处理。 滤波是一种数字信号处理操作,其目的是为了处理某个信号,以便提取出输入信号中所包含的期望信息。在数字信号处理课程中,我们基本掌握了一些线性滤波器的设计方法,有固定的规可遵循。而在我们的实际生活中,充满了偶然和随机,时不变滤波器已不能够满足更好效果的滤波。在这种情况下,我们就需要自适应滤波器。可以看到,随着数字超大规模集成技术的发展,自适应滤波技术在很多领域得到了广泛应用。 最小均方算法是一种搜索算法,他通过对目标函数进行适当的调整,简化了对梯度相量的计算。由于其计算简单性,LMS算法以及其它一些相关算法已广泛应用于自适应滤波的各种应用中。而LMS算法是自适应滤波理论中应用最广泛的算法。这主要归因于其地计算复杂度、在平稳环境中的收敛性、其均值无偏地收敛到维纳解以及利用有限精度算法实现时的稳定特性等等。 对LMS最小均方算法的学习,将加深我们对数字信号处理课程的理解,同时对我们今后滤波技术的应用奠定了巩固的基础。 二、训练目的 1. 通过利用c程序实现数字信号处理的相关功能,巩固对信号处理原理知识的理解,提高实际编程和处理数据的综合能力,初步培养在解决信号处理实际应用问题中所应具备的基本素质和要求。 2. 培养研发能力,通过设计实现不同的信号处理问题,初步掌握在给定条件和功能的情况下,实现合理设计算法结构的能力。 用最小二乘法拟合数据并求均方偏差 摘要:数值分析是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科,是数学的一个分支,它以数字计算机求解数学问题的理论和方法为研究对象。本文通过对一组数据用origin先得到散点图,然后根据散点图来预测函数。接着用matlab软件采用最小二乘法拟合,得到两个不同的函数,并计算它们的均方偏差,以便比较这两个拟合函数的优劣。关键字:数值分析; origin ; matlab ; 最小二乘法;均方偏差 Abstraction:Numerical analysis is a computational method and its numerical computation problem is solved by computer analysis of mathematical research subject, is a branch of mathematics, it is based on the theory and methodology of digital computer to solve mathematical problems as the research object.This article through to a set of data with origin to get scatter plot, then predict function according to the scatter plot.Then using least squares fitting with the matlab software, get two different function, and the mean square deviation, they calculated to compare the advantages and disadvantages of the two fitting function. Keyword:Numerical analysis; origin; matlab ;the least square method;Mean Square Error 1、引言 数值分析主要介绍现代科学计算中常用的数值计算方法及其基本原理,研究并解决数值问题的近似解,是数学理论与计算机和实际问题的有机结合。随着科学技术的迅速发展,运用数学方法解决科学研究和工程计算领域中的实际问题,已经得到普遍重视。数学建模是数值分析联系实际的桥梁。在数学建模过程中,无论是模型的建立还是模型的求解都要用到数值分析课程中所涉及的算法,如插值方法、最小二乘法、拟合法等,那么如何在数学建模中正确的应用数值分析内容,就成了解决实际问题的关键。 其中最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。本文主要运用的数值分析算法就是最小二乘法。 2、用最小二乘法解决问题 (1) [均方误差]方差、标准差、均方差、均方误差区别总结 一、百度百科上方差是这样定义的 (variance)是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是各个数据分别与其平均数之差的平方的和的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。 看这么一段文字可能有些绕,那就先从公式入手, 对于一组随机变量或者统计数据,其期望值我们由E(X)表示,即随机变量或统计数据的均值, 然后对各个数据与均值的差的平方求和,最后对它们再求期望值就得到了方差公式。 这个公式描述了随机变量或统计数据与均值的偏离程度。 二、方差与标准差之间的关系就比较简单了 根号里的内容就是我们刚提到的 那么问题来了,既然有了方差来描述变量与均值的偏离程度,那又搞出来个标准差干什么呢? 发现没有,方差与我们要处理的数据的量纲是不一致的,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。 举个例子一个班级里有60个学生,平均成绩是70分,标准差是9,方差是81,成绩服从正态分布,那么我们通过方差不能直观的确定班级学生与均值到底偏离了多少分,通过标准差我们就很直观的得到学生成绩分布在[61,79]范围的概率为0.6826,即约等于下图中的32%*2 三、均方差、均方误差又是什么? 标准差(Standard Deviation),中文环境中又常称均方差,但不同于均方误差(mean squared error,均方误差是各数据偏离真实值的距离平方和的平均数,也即误差平方和的平均数,计算公式形式上接近方差,它的开方叫均方根误差,均方根误差才和标准差形式上接近),标准差是离均差平方和平均后的方根,用σ表示。标准差是方差的算术平方根。 从上面定义我们可以得到以下几点 MMSE检测程序 % m_sequence 程序一 function mseq=m_sequence(fbconnection) n=length(fbconnection); N=2^n-1; register=[zeros(1,n-1) 1]; mseq(1)=register(n); for i=2:N newregister(1)=mod(sum(fbconnection.*register),2); for j=2:n newregister(j)=register(j-1); end register=newregister; mseq(i)=register(n); end % %gold_seq.m (程序二) function goldseq=gold_seq(fbconnection1,fbconnection2) mseq1=m_sequence(fbconnection1); mseq2=m_sequence(fbconnection2); N=2^length(fbconnection1)-1; for shift_amount=0:N-1 shift_mseq2=[mseq2(shift_amount+1:N) mseq2(1:shift_amount)]; goldseq(shift_amount+1,:)=mod(mseq1+shift_mseq2,2); end % mmse_main (程序三) %MMSE解相关多用户检测器和CD传统多用户检测器的误码率比较(八个用户)clear all; snr_indb=1:8; for k=1:length(snr_indb) snr=10^(snr_indb(k)/10); sgma=1; eb=2*(sgma^2)*snr; LC=31; echip=eb/LC; N=10000;%number of bits transmitted %creat PN codes fbconnection=[0 1 0 0 1]; mseq=m_sequence(fbconnection); fbconnection1=[0 0 1 0 1]; fbconnection2=[0 1 1 1 1]; goldseq=gold_seq(fbconnection1,fbconnection2); %N=2^length(fbconnection)-1;基于最小均方误差的Tikhonov正则化参数优化研究
线性分类器值感知机算法和最小均方误差算法
最小均方算法
3.1-3.2.1-估计量的性质、最小方差无偏估计
次级通路估计误差偏移下的滤波-x最小均方算法收敛性能
第5章552均方误差准则MSE和LMS算法
基于最小均方误差(MMSE)估计的因果维纳滤波的实现.
最小方差无偏估计
最小均方(LMS)算法
基于LMS最小均方误差法的语音降噪北工大
用最小二乘法拟合数据并求均方偏差
均方误差范文
基于最小均方误差的-MMSE程序2