统计6-1
统计学的六个相对指标

统计学的六个相对指标
1、结构相对指标
又称结构相对数。
总体的某一部分与总体数值相对比求得的比重或比率指标。
结构相对数通常用来反映总体的结构和分布状况等。
实际经济工作中常用的恩格尔系数、贡献率、城市化程度、中间投入率、增加值率、消费率、合格率、市场占有率等都是结构相对数。
2、比较相对指标
又称比较相对数或同类相对数。
同类指标在不同空间进行静态对比形成的相对指标。
可以比较不同国家、不同地区、不同单位等经济实力、发展水平和工作优劣。
3、比例相对指标
又称比例相对数或比例指标。
反映总体中各组成部分之间数量联系程度和比例关系的相对指标。
4、强度相对指标
又称强度相对数。
有一定联系的两种性质不同的总量指标相比较形成的相对指标。
通常以复名数、百分数(%)、千分数(‰)表示。
5、动态相对指标
动态相对指标又称“动态相对数”或“时间相对指标”,就是将同—现象在不同时期的两个数值进行动态对比而得出的相对数,借以表明现象在时间上发展变动的程度。
通常以百分数(%)或倍数表示,也称为发展速度。
发展速度减1或100%为增长速度指标,计算结果大于100%为增长多少百分数或百分点,小于100%为下降多少百分数或百分点。
6、计划完成程度指标
又称计划完成百分数。
以计为比较标准,将实际完成数与计划规定数相比较,用以表明计划完成情况的相对指标,通常用百分数(%)表示。
基本统计术语

基本统计术语
1. 平均数呀,就好像是一群数字的“中心代表”。
比如说,你们班同学的考试成绩,把所有人的成绩加起来再除以人数,得到的那个数就是平均数啦。
2. 中位数呢,它可是数字队伍里的“中间力量”哟!比如找几个朋友比身高,把身高从低到高排好,最中间那个就是中位数啦。
3. 众数呀,那就是数字中的“人气王”呢!像统计大家最爱吃的水果,出现次数最多的那个水果就是众数啦。
4. 方差,就像是衡量数字们“个性差异”的指标。
好比一个团队里大家做事的风格差异有多大。
5. 标准差呢,就像是方差的“好伙伴”,它更直观地体现数字的离散程度。
例如统计同学们跑步的速度差异情况。
6. 频率啊,就像数字出现的“活跃度”。
比如统计电视节目中某个广告出现的次数。
7. 概率,这可是充满未知和期待的呀!就像抽奖,你知道自己有可能中奖,但又不确定呢。
8. 样本,不就是整体的一个“小代表”嘛!从一大筐苹果里拿出几个来看看好坏,这几个就是样本呀。
9. 总体,那就是所有的一切呀!像全校学生就是一个总体呢。
10. 统计图表,这可是让数字“活起来”的魔法呀!把数据变成直观的图形,一目了然呢。
我的观点结论:这些基本统计术语真的很重要也很有趣呀,它们能帮我们更好地理解和分析各种数据呢!。
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)

12
0 数学 书法 英语 绘画
(人) 参加兴趣班人数统计
26
种类
数学
书法
英语
绘画
24 22
20
(人人数)从统12右计6179342580面 图7的 中6 条 ,1形 你0
20
8 18
获得哪些信息?
16 14
12
10
10 8
8
76
6
4
2 0
数学 书法 英语 绘画
根据右面的条形统计图回答问题:
①右边的条形统计图中,1格代表( 2)人。 ②参加(书法)兴趣班的人数最少,有( )人7 。 ③ 参加( 数学)兴趣班和( 书)法兴趣班的人数相差最多。
短袖衬衫 长袖衬衫 牛仔外套 羽绒服
小胖服装店(
)的销售情况
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
春季
夏季 秋季
冬季
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
短袖衬衫 长袖衬衫 牛仔外套 羽绒服
小胖服装店(
)的销售情况
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
春季
夏季 秋季 冬季
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
二年级最爱的卡通人物情况
(人)
1、喜欢 喜欢
的人比 的人多。
2、喜欢 喜欢
的人是 的2倍 。
3、喜欢
的人最少。
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
二年级上册数学- 统计(条形统计图一) PPT沪教版 (22张)
2(0亿0元4)—2005年各季度GNP统计图
习题6-1分类统计字符个数(15分)

习题6-1分类统计字符个数(15分)本题要求实现⼀个函数,统计给定字符串中英⽂字母、空格或回车、数字字符和其他字符的个数。
⼩知识:c语⾔'\0' 意思:字符常量占⼀个字节的内存空间。
字du符串常量占的内存字节数zhi等于字符串中dao字节数加1。
增加的⼀个字节中存放字符"\0"(ASCII码为0)。
这是字符串结束的标志。
所以原来的这块:int n = strlen(s);for (int i = 0; i < n ; i ++ )就可以改成:for (int i = 0; s[i] != '\0' ; i ++ )code#include <stdio.h>#include <string.h>#define MAXS 15void StringCount( char s[] ){int letter = 0, blank = 0, digit = 0, other = 0;int n = strlen(s);for (int i = 0; i < n ; i ++ ){if(s[i] >= '0' && s[i] <= '9') digit += 1;else if (s[i] == ' ' || s[i] == '\n') blank += 1;else if ( (s[i] >= 'a' && s[i] <= 'z') || (s[i] >= 'a' && s[i] <= 'z')) letter += 1;else other += 1;}printf("letter = %d, blank = %d, digit = %d, other = %d", letter, blank, digit, other);}void ReadString( char s[] ); /* 由裁判实现,略去不表 */int main(){char s[MAXS];ReadString(s);StringCount(s);return 0;}/* Your function will be put here */。
应用统计学6-假设检验(1)

t 检验
(单边和双边)
χ2检验
(单边和双边)
名称 条件
H0
统计量及其分布
拒绝域 |u| >u1-α/2 u >u1-α u < - u1-α |t| >tα/2 t >tα t < -tα
2 χ 2 > χα / 2 ( n − 1)或
0 u 总体 µ ≤ µ0 2 检 方差σ 均 验 已知 µ ≥ µ 0 值 检 验 t 总体 µ = µ 0 µ ≤ µ0 2 检 方差σ 验 未知 µ ≥ µ 0
正确
α 错误和 β 错误的关系
当H0、H1给定,n固定时,无法同时使α和β变小 α和β的关系就像翘翘板,α小β就大, α大β就小
β α
使α、β 同时变小的办法就是增大样本容量。
“不能拒绝H0”
一般地说,哪一类错误所带来的后果越严重,危害越大, 在假设检验中就应当把哪一类错误作为Fra bibliotek要的控制目标。
通常β不易计算,所以通常我们 主要控制α,尽量减小β
µ ≥ µ0 µ < µ0
µ ≤ µ0 µ > µ0
双边检验
抽样分布
拒绝域 α/2
H0 :µ = µ0
H1 :µ ≠ µ0
置信水平 拒绝域 1-α α/2 接受域 H0值
临界值
临界值
左单边检验
抽样分布
拒绝域
H0 :µ ≥ µ0
H1 :µ < µ0
置信水平
α
1-α 接受域 H0值
临界值
右单边检验
由于α 事先确定,所以拒绝H0 是有说服力的, 而β通常未知,所以如果我们决定“接受H0 “,我们并不 确定这个决策的置信度,所以通常我们不采用“接受H0 “的说法,而是采用“不能拒绝H0 “的说法。
名解问答重点-卫生统计学6-(1)

第一章绪论一,名词解释1.参数:能统计计算出来描述总体的特征量,即总体的统计指标。
2.总体:根据研究目确实定的同质研究对象的全体集合。
3.同质:除了实验因素外,影响被研究指标的非试验因素相同被称为同质。
4.变异:在同质的基础上被观察个体或单位之间的差异被称为变异。
5.样本:从总体中随机抽取的部分研究对象。
6.统计量:由观察资料计算出来的量,即样本的统计指标。
7.概率:表示一个事件发生的可能性大小的数。
〔概率的统计定义:在一定条件下,重复做n次试验,nA为n次试验中事件A发生的次数,如果随着n逐渐增大,频率nA/n逐渐稳定在某一数值p附件,则数值p 称为事件A在该条件下发生的概率。
〕8.抽样误差:由抽样造成的样本均数与总体均数或各样本均数之间的差异。
二,问答题。
1.统计学的基本步骤有哪些?答:统计学是一门处理数据中变异性的科学与艺术,它包括收集数据、分析数据、解释数据,以及表达数据。
2.总体与样本的区别与关系?答:区别:样本是总体的一部分,联系:如果样本的均衡性较好,就能够代表总体的特征。
3.抽样误差产生的原因有哪些?可以防止抽样误差吗?答:一,个体差异引起;二,抽样方法引起。
抽样误差不能防止,但可以随着样本含量的增大而减小。
4.何为概率及小概率事件?答:概率是指在一定条件下,重复做n次试验,nA为n次试验中事件A发生的次数,如果随着n逐渐增大,频率nA/n逐渐稳定在某一数值p附件,则数值p称为事件A在该条件下发生的概率。
小概率事件是指习惯上将P《=0.05或P《=0.01称为小概率事件,表示某事件发生的可能性很小。
第二章定量资料的统计描述一,名词解释1.频数:对一个随机事件进行反复观察,其中某变量值出现的次数被称为频数。
2.方差:用来度量随机变量和数学期望〔即均值〕之间的偏离程度。
3.标准差:也称均方差,是各数据偏离平均数的距离的平均数。
4.中位数:是指将原始观察值从小到大或从大到小排序后,位次局中的那个数。
客户风险统计报表1-6
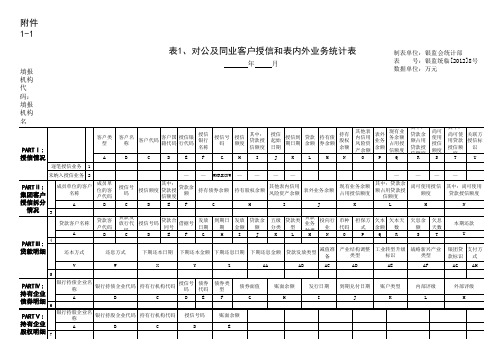
表外业务客户代码
承办银行机构代 码
表外业务类型
授信号 码
表外业务 明细
A
B
C
D
E
8
PARTⅦ: 同业客户 业务明细
9
客户名称 A
客户代 码
B
国别代 码
非现场监 管统计机
构编码
组织机 构代码
客户类 别
内部 评级
C
D
E
F
G
外部评 级
H
合同 号 F
拆放 同业
I
业务号 码 G
存放同 业 J
业务 币种代 发生 到期日 余额 码 日期 期
表外业务余额
D
E
F
G
H
I
J
授信号码
贷款合 同号
借据号
发放 日期
D
E
F
G
到期日 期 H
发放 贷款余
金额 额
I
J
五级 分类
贷款类 型
贷款 业务 种类
投向行 业
K
L
M
N
下期还本日期
下期还本金额 下期还息日期
下期还息金额
贷款发放类型
减值准 备
现有业务余额 占用授信额度
K
币种 担保方
代码 式
O
P
产业结构调整 类型
PARTⅡ: 成员单位的客户
集团客户
名称
授信拆分
A
情况 3
贷款客户名称
PARTⅢ: 4 贷款明细
A 还本方式
成员单 位的客 户代码
B
授信号 码
C
贷款客 户代码
B
贷款发 放行代
码 C
还息方式
6[1].2 统计表
![6[1].2 统计表](https://img.taocdn.com/s3/m/9ba5ff200722192e4536f6bf.png)
天?达到绿色要求了吗? 10 3 5 天数(t)
18天
4
140
1
7
ቤተ መጻሕፍቲ ባይዱ
某科学家通过一项实验来了解不同身体质量的人在进行不 同活动时所消耗的热量。下面是不同身体质量的人活动30 分所消耗的热量(单位:焦)的实验数据: (1)身体质量30千克:骑自行车252焦,打篮球504焦,看 电视88焦; 想一想:怎样确定标 (2)身体质量40千克:骑自行车323焦,打篮球689焦,看 题?标目? 电视113焦; (3)身体质量50千克:骑自行车399焦,打篮球865焦,看 电视139焦; (4)身体质量60千克:骑自行车479焦,打篮球1024焦, 看电视160焦. 请制作能反映实验情况的统计表.
一、制作统计表
标题(统计表的名称)
统计表
标目 数据
注意:不要忘了标题和数据的单位,一般还要写上制表 时间
二.利用统计表分析简单的实际问题
1.
我国陆地面积地形分布统计表
地形 面积 (万km2) 百分比
高原
山地 丘陵 盆地
249.6
316.8 96 182.4
26%
33% 10% 19%
平原
合计
115.2
打篮球 看电视
88
骑自行车
30 40 50 60
252
323 399 479
504
689 865 1024
113 139 160
根据表6-5回答下列问题:
活动类型 身体 骑自行车 质量(千克) 打篮球
表6-5
看电视
30
40
252
323
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
33.45
x 32.735
自 方差来源 由 度 配方作用 131.169 3 (A) 离差平 方和
均方 和
F值
临界值 FA0.05=3.49 FA0.01=5.95 FB0.05=3.26 FB0.01=5.41
显著 性 **
43.723 FA=20.197
加工组作 用(B)
试验误差 总和
14.3375 4
若
F F (k 1, kn k ) ,则拒绝原假设H 0 ;
若 F F (k 1, kn k ) ,则接受原假设H 0 。
(6) 一般把上述计算结果写成如下的方差分析表:
离差平 方和
方差来源 组间 (因素)
自由度
均方和
SA k 1
F值
临界值 显著性
SA
SE
k 1
MS A
k
n
2
2 Xi j X i X i X X i X
k n i
2
X i j X i
i 1 j 1 k
X
2 i 1 j 1 n k i 1 j 1 i j
X
2
n X i X
i 1
X
2
Xi
品种 田块号
1 2 3 4
1
2
3
4
5
67 67 55 42
98 96 91 66
60 69 50 35
79 64 81 70
90 70 79 88
问水稻品种对产量是否有显著影响?
在例1中,试验的指标是水稻产量,影响产量的因素是 水稻品种,不同的5个品种就是因素所处的5个水平, 这就是单因素试验问题。 例2 某车间加工生产同一种材料,有5个加工组,现在 每个加工组都采用4种不同的配方进行试验,得到材料 强度试验数据如下:
x j
1 T j n
x1
x 2 x m
1 x T mn
我们假设:X i j 是相互独立的,且 X i
j
~ N (
2 , ) i j
(i 1,2,, n; j 1,2,, m )
(1)提出原假设: H 和备择假设: (2) 构造统计量 定义4 称统计量
0
: ij ;
ST SA SB SE MST , MS A , MSB , MS E fT fA fB fE
都是
②
2 的无偏估计。
SA
2
~ ( fA) ,
2
SB
2
~ ( f B ),
2
SE
2
~ 2 ( kn k )
且相互独立。
③
FA
SA 2 fA
SE 2 fE
3.584
FB=1.656
25.9785 12 171.485 19
2.165
显 著 性 **
15 144.74
三、双因素方差分析 设影响试验指标的因素有A和B两个,因素A有n个水平 A1, A2,…, An,因素B有m个水平B1,B2,…, Bm,在 每个水平组合( A i , B k )下做一次试验,则共独立作
n×m次试验,试验数据如下表:
B
A A1 A2 … An
n
B1
2
(4)在H 0 成立时,有
2 E S ( n 1 ) ; ① E ST (mn 1) ; A
E S B (m 1) 2 ; E S E (m 1)(n 1) 2 .
记 f T mn 1, f A n 1, f B m 1, f E (m 1)(n 1) 即
加工组
配方
1
2
3
4
5
1 2 3 4
32.3 33.2 30.8 29.5
34.0 33.6 34.4 26.2
34.7 36.8 32.3 28.5
36.0 34.3 35.8 28.5
35.5 36.1 32.8 29.4
问: (1)不同加工组的工艺水平对材料强度有无显著影响? (2)同一加工组的不同配方对材料强度有无显著影响? 从以上两例可看出,试验指标的数据参差不齐,这种差异 是由以下两方面的原因造成的; (1)试验条件的不同。如种子优劣,材料配方等。 (2)偶然因素(或称随机因素)。 我们把试验条件(因素水平)不同造成的误差称为条件误 差;把偶然因素造成的误差称为试验误差(又称随机误 差)。方差分析的思想就是把条件误差与试验误差比较, 当条件误差比试验误差大得多时,就认为该因素的水平变 化对试验指标有显著的影响。
MS A ~ F( fA, fE ) MS E
FB
SB 2 fB
SE 2 fE
MS B ~ F( fB , fE ) MS E
FB
的值,
按③式分别计算 FA ,
并分别与 FA ( f A , f E ) ,
FB ( f B , f E )比较。
(5)作出判断 若 FA FA ( f A , f E ) 则认为因素A的不同水平之间有显著差异 ; 若 FA FA ( f A , f E )
H0 : 1 2 k
至少有一对 i j
1 k n X Xi j 样本总平均 nk i 1 j 1 1 n X i X i j , i 1,2,, k 第 i 组的样本平均 n j 1
(2) 构造统计量
定义1
称统计量
ST X i j X
i 1 j 1
k
n
2
为总离差平方和。
定义2
称统计量
S E X i j X i
i 1 j 1
k
n
2
为组内离差平方和。 表示了试验误差的大小。
定义3
称统计量
k n i 1 j 1
S A X i X
为组间离差平方和。
2
n X i X
i 1
F
组内 (误差)
kn k MS E S E kn 1
MS A MSE
F
kn k
总和
ST
注: 实际计算各平方和时可利用下面的公式:
T S T x , kn i j 1
2 ij
k
n
2
1 k 2 T2 S A Ti , n i 1 kn
k 1 S E x i2 j Ti 2 S T S A . n i 1 i j 1 k n
其中,Ti
x ij , i 1,2,k; T x ij .
j 1 i 1 j 1
n
k
n
例1的方差分析表:
方差来源
组间 组内 总和 离差平方 自 和 由 度 3537.68 2171.08 5708.76 4 19 均方和
F值
884.42 6.11
临界值
F0.05=3.06 F0.01=4.89
二、单因素方差分析
设因素A有k个水平A1, A2,…, Ak, 在每个水平下 独立重复做n次试验(此时称为等重复试验,实际上也可
作不等重复试验,例如,在第Ai个水 平上作n i 次试验),
每次试验的结果都是一个随机变量。同一水平下n次试验 的可能结果可视为同一总体的样本。我们记第Ai水 平的
总体为X i ,记在Ai水 平下的第j个试验结果为
B2
…
Bm
Ti x i j
j 1
m
X 11 x 12 X 21 x 22 … X n1 x n2
… x1m … x2m
T1 T2 Tn
m n
x1 x2 xn
… xnm
T j x i j T1
i 1
T2 Tm T x i j
j 1 i 1
2
SA SE
这是因为:
X
k n i 1 j 1 k
i j
Xi Xi X
Xi X
i 1
X
n j 1
i j
Xi 0
(4)在H 0 成立时,有 ①
EST (kn 1)
2 2
ES A (k 1)
2
ES E (kn k ) ST SA SE 即 MS T , MS A , MS E kn 1 k 1 kn k
4 36.0 34.3 35.8 28.5 134.6
5 35.5 36.1 32.8 29.4 133.8
Ti .
172.5 174 166.1 142.1
xi.
34.5 34.8 33.22 28.42
T. j
125.8 128.2
T =654.7
x.j
31.45 32.05
33.075
33.65
2 都是 的无偏估计。
②
SA
2
~ (k 1) ,
2
SE
2
~ 2 (kn k )
且 S A 与 S E 相互独立。
SA 2 ( k 1 ) F
③
SE 2 ( kn k )
MS A ~ F ( k 1, kn k ) MS E
(5)作出判断。
对给定的显著性水平α(通常α =0.05,或α F (k 1, kn k ) =0.01),查F分布表得上α分位点 按③式计算F的值, 并与 F (k 1, kn k ) 比较。
k