Verilog实现流水线CPU实验报告
verilog任务报告
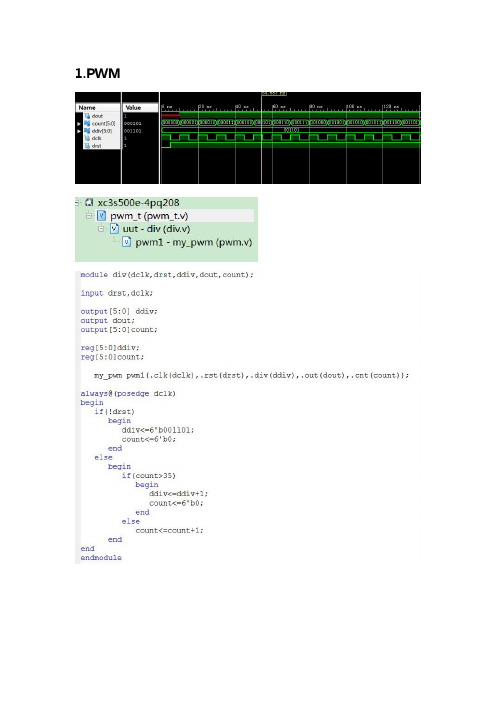
1.PWM学会了模块间参数的调用,了解了pwm的原理,可以根据需求对不同的div进行设定从而获得一个条件限制从而获得一些不同的效果。
2. 8位桶形移位器波形这里用了一个case来表示移动的位数同时也能表示几种不同的情况。
每变换一个数或者位数便重新进行判断,从而得到准确的结果。
移位在之后的任务中显得比较重要。
所以使用快速准确的移位器可以较多地节省时间。
3.FIFO4.流水线加法器波形这里采用的是两级流水。
并在其中添加了拼接从而使得结果更加准确。
这里有一个问题。
我本来设定的firsta,b是两位的,但是相加的时候发生了溢出。
所以,把它设定为三位,这样进位就可以保存在多余出的那一位中。
做完这道题让我对流水线有了更深的理解。
5.除法器I波形这是个整数除法器,用的是辗转相减,这里用了case来实现循环,这样就使得原本比较棘手的while循环更加简便。
也可以较为条理的顺序执行。
但是,这种方法似乎不是很高效,因为,结果的出现有明显的延迟,而且,随着被除数和除数的改变,延迟也会有所改变。
所以,我采用了以下方法。
6.除法器II波形这个除法器是通过移位来实现的,逻辑较为复杂,尤其是,for循环块中的逻辑,想了很长时间。
但是,它更为高效,因为是通过按位实现。
所以,我在下面的流水线除法器中,使用了这个方法。
7.流水线除法器这是流水线除法器,采用九级流水,其实,是把上面的循环,分成了九个步骤。
但是,这其中的参数处理起来比较棘手,所以我使用了很多寄存器。
九级流水也使得吞吐量大幅提高。
7个操作数由原来的9个周期变为现在的2.285个周期。
8.阵列除法器波形;。
Verilog HDL 实验报告

Verilog实验报告班级:学号:姓名:实验1 :用 Verilog HDL 程序实现直通线1 实验要求:(1) 编写一位直通线的 Veirlog HDL 程序.(2) 编写配套的测试基准.(3) 通过 QuartusII 编译下载到目标 FPGA器件中进行验证.(4) 建议用模式 52 试验程序:module wl(in,out);input in;output out;wire out;assign out=in;endmodule3 测试基准:`include “wl.v”module wl_tb;reg in_tb;wire out_tb;initialbeginin_tb =0;#100 in_tb =1;#130 in_tb =0;endendmodule4 仿真图形:实验2 :用 Verilog HDL 程序实现一位四选一多路选择器1实验要求:(1) 编写一位四选一多路选择器的 Veirlog HDL 程序.(2) 编写配套的测试基准.(3) 通过 QuartusII 编译下载到目标 FPGA器件中进行验证.(4)建议用模式 52 试验程序:module mux4_to_1 (out,i0,i1,i2,i3,s1,s0);output out;input i0,i1,i2,i3;input s1, s0;reg out;always @ (s1 or s0 or i0 or i1 or i2 or i3)begincase ({s1, s0})2'b00: out=i0;2'b01: out=i1;2'b10: out=i2;2'b11: out=i3;default: out=1'bx;endcaseendendmodule3 测试基准:`include "mux4_to_1.v"module mux4_to_1_tb1;reg ain,bin,cin,din;reg[1:0] select;reg clock;wire outw;initialbeginain=0;bin=0;cin=0;din=0;select=2'b00;clock=0;endalways #50 clock=~clock;always @(posedge clock)begin#1 ain={$random} %2;#3 bin={$random} %2;#5 cin={$random} %2;#7 din={$random} %2;endalways #1000 select[0]=!select[0];always #2000 select[1]=!select[1];mux4_to_1 m(.out(outw),.i0(ain),.i1(bin),.i2(cin),.i3(din),.s1(select[1]),.s0(select[0])); endmodule4 仿真图形:实验3:用 Verilog HDL 程序实现十进制计数器1实验要求:(1) 编写十进制计数器的 Veirlog HDL 程序. 有清零端与进位端, 进位端出在输出为 9 时为高电平.(2) 编写配套的测试基准.(3) 通过 QuartusII 编译下载到目标 FPGA器件中进行验证.(4) 自行选择合适的模式2 实验程序:module counter_10c (Q, clock, clear, ov);output [3:0] Q;output ov;input clock, clear;reg [3:0] Q;reg ov;initial Q=4'b0000;always @ (posedge clear or negedge clock)beginif (clear)Q<=4'b0;else if (Q==8)beginQ<=Q+1;ov<=1'b1;endelse if (Q==9)beginQ<=4'b0000;ov<=1'b0;endelsebeginQ<=Q+1;ov<=1'b0;endendendmodule3 测试基准:`include"./counter_10c.v"module counter_10c_tb;wire[3:0] D_out;reg clk,clr;wire c_out;reg[3:0] temp;initialbeginclk=0;clr=0;#100 clr=1;#20 clr=0;endalways #20 clk=~clk;counter_10c m_1(.Q(D_out),.clear(clr),.clock(clk),.ov(c_out)); endmodule4 仿真波形:实验4 :用 Verilog HDL 程序实现序列检测器1 实验要求:、(1) 编写序列检测器的 Veirlog HDL 程序. 检测串行输入的数据序列中是否有目标序列5'b10010, 检测到指定序列后, 用一个端口输出高电平表示.(2) 编写配套的测试基准.(3) 通过 QuartusII 编译下载到目标 FPGA器件中进行验证.(4) 自行选择合适的模式2试验程序:module e15d1_seqdet( x, z, clk, rst);input x,clk, rst;output z;reg [2:0] state;wire z;parameter IDLE = 3 'd0,A = 3'd1,B = 3'd2,C = 3'd3,D = 3'd4,E = 3'd5,F = 3'd6,G = 3'd7;assign z =(state==D && x==0)?1:0;always @(posedge clk or negedge rst)if(!rst)beginstate<=IDLE;endelsecasex(state)IDLE: if(x==1)state<=A;else state<=IDLE;A: if (x==0)state<=B;else state<=A;B: if (x==0)state<=C;else state<=F;C: if(x==1)state<=D;else state<=G;D: if(x==0)state<=E;else state<=A;E: if(x==0)state<=C;else state<=A;F: if(x==1)state<=A;else state<=B;G: if(x==1)state<=F;else state <=G;default: state<=IDLE;endcaseendmodule3测试基准:`include"e15d1_seqdet.v"`timescale 1ns/1ns`define halfperiod 20module e15d1_seqdet_tb;reg clk, rst;reg [23:0] data;wire z;reg x;initialbeginclk =0;rst =1;#2 rst =0;#30 rst =1;data= 20 'b1100_1001_0000_1001_0100;#(`halfperiod*1000) $stop;endalways #(`halfperiod) clk=~clk;always @ (posedge clk)begin#2 data={data[22:0],data[23]};x=data[23];ende15d1_seqdet m(.x(x),.z(z),.clk(clk),.rst(rst)); endmodule4仿真波形:。
流水线实验报告

流水线实验报告一、实验目的本次实验旨在探究流水线技术在计算机体系结构中的应用,并了解流水线的工作原理与效果。
通过对流水线的实验,掌握流水线操作的过程和相关概念,并通过实践了解其对计算机性能的提升作用。
二、实验器材与软件环境实验使用的器材为一台配有Intel Core i7处理器的计算机。
软件环境为Windows 10操作系统,使用C语言编译器进行代码编写和实验运行。
三、实验内容1. 流水线概述流水线是一种用于提高计算机处理器效率的技术。
它将任务划分为多个阶段,使得每个阶段都能并行地处理不同的任务。
通过将多个任务拆分并在不同的阶段同时进行,可以显著提高计算机处理速度。
2. 流水线原理流水线工作原理如下:1) 将任务划分为多个子任务,并在不同的阶段上并行执行。
2) 每个阶段的任务之间通过专门的寄存器传递数据。
3) 每个阶段的任务完成后,将结果写入寄存器,供下一个阶段使用。
4) 流水线的效果取决于各个阶段的任务执行时间,如果存在某个阶段的任务耗时较长,则可能导致整个流水线效率下降。
3. 流水线的实现实验中我们使用C语言编写一段简单的代码来模拟流水线的实现过程。
我们通过将输入的整数加1后输出,来模拟流水线的工作状态。
cinclude <stdio.h>int main() {int input[5] = {1, 2, 3, 4, 5};int output[5];int i;for (i = 0; i < 5; i++) {output[i] = input[i] + 1;}for (i = 0; i < 5; i++) {printf("%d\n", output[i]);}return 0;}上述代码将输入数组中的每个元素加1后,输出到屏幕上。
在这个过程中,我们可以将输入和输出视为流水线中的阶段,每个阶段都有固定的任务。
4. 实验结果与分析在实验中,我们输入数组为{1, 2, 3, 4, 5},运行结果如下:23456可以看到,实验结果符合我们的预期,每个输入元素都成功地加1后输出。
verilog实验报告

verilog实验报告Verilog实验报告引言:Verilog是一种硬件描述语言(HDL),用于设计和模拟数字电路。
它是一种高级语言,能够描述电路的行为和结构,方便工程师进行数字电路设计和验证。
本实验报告将介绍我在学习Verilog过程中进行的实验内容和所获得的结果。
实验一:基本门电路设计在这个实验中,我使用Verilog设计了基本的逻辑门电路,包括与门、或门和非门。
通过使用Verilog的模块化设计,我能够轻松地创建和组合这些门电路,以实现更复杂的功能。
我首先创建了一个与门电路的模块,定义了输入和输出端口,并使用逻辑运算符和条件语句实现了与门的功能。
然后,我创建了一个测试模块,用于验证与门的正确性。
通过输入不同的组合,我能够验证与门的输出是否符合预期。
接下来,我按照同样的方法设计了或门和非门电路,并进行了相应的测试。
通过这个实验,我不仅学会了使用Verilog进行基本门电路的设计,还加深了对逻辑电路的理解。
实验二:时序电路设计在这个实验中,我学习了如何使用Verilog设计时序电路,例如寄存器和计数器。
时序电路是一种具有状态和时钟输入的电路,能够根据时钟信号的变化来改变其输出。
我首先设计了一个简单的寄存器模块,使用触发器和组合逻辑电路实现了数据的存储和传输功能。
然后,我创建了一个测试模块,用于验证寄存器的正确性。
通过输入不同的数据和时钟信号,我能够观察到寄存器的输出是否正确。
接下来,我设计了一个计数器模块,使用寄存器和加法电路实现了计数功能。
我还添加了一个复位输入,用于将计数器的值重置为初始状态。
通过测试模块,我能够验证计数器在不同的时钟周期内是否正确地进行计数。
通过这个实验,我不仅学会了使用Verilog设计时序电路,还加深了对触发器、寄存器和计数器的理解。
实验三:组合电路设计在这个实验中,我学习了如何使用Verilog设计组合电路,例如多路选择器和加法器。
组合电路是一种没有状态和时钟输入的电路,其输出只取决于当前的输入。
Verilog十大基本功1(流水线设计PipelineDesign)

Verilog十大基本功1(流水线设计PipelineDesign)需求说明:Verilog设计基础内容:流水线设计来自:时间的诗流水线设计前言:本文从四部分对流水线设计进行分析,具体如下:第一部分什么是流水线第二部分什么时候用流水线设计第三部分使用流水线的优缺点第四部分流水线加法器举例第一什么是流水线流水线设计就是将组合逻辑系统地分割,并在各个部分(分级)之间插入寄存器,并暂存中间数据的方法。
目的是将一个大操作分解成若干的小操作,每一步小操作的时间较小,所以能提高频率,各小操作能并行执行,所以能提高数据吞吐率(提高处理速度)。
第二什么时候用流水线设计使用流水线一般是时序比较紧张,对电路工作频率较高的时候。
典型情况如下:1)功能模块之间的流水线,用乒乓buffer 来交互数据。
代价是增加了 memory 的数量,但是和获得的巨大性能提升相比,可以忽略不计。
2) I/O 瓶颈,比如某个运算需要输入 8 个数据,而 memroy 只能同时提供 2 个数据,如果通过适当划分运算步骤,使用流水线反而会减少面积。
3)片内 sram 的读操作,因为 sram 的读操作本身就是两极流水线,除非下一步操作依赖读结果,否则使用流水线是自然而然的事情。
4)组合逻辑太长,比如(a+b)*c,那么在加法和乘法之间插入寄存器是比较稳妥的做法。
第三使用流水线的优缺点1)优点:流水线缩短了在一个时钟周期内给的那个信号必须通过的通路长度,增加了数据吞吐量,从而可以提高时钟频率,但也导致了数据的延时。
举例如下:例如:一个 2 级组合逻辑,假定每级延迟相同为 Tpd,1.无流水线的总延迟就是2Tpd,可以在一个时钟周期完成,但是时钟周期受限制在 2Tpd;2.流水线:每一级加入寄存器(延迟为T co)后,单级的延迟为Tpd+Tco,每级消耗一个时钟周期,流水线需要 2 个时钟周期来获得第一个计算结果,称为首次延迟,它要2*(Tpd+Tco),但是执行重复操作时,只要一个时钟周期来获得最后的计算结果,称为吞吐延迟( Tpd+Tco)。
Verilog流水灯实验报告.pptx

initial begin clk = 0; rst_n = 0; #100 rst_n = 1; end
always #5 clk=~clk;
LSD LSD_inst( .clk(clk), .rst_n(rst_n),
学海无 涯
流水灯实验报告
实验二 流水灯
一、 实验目的
学会编写一个简单的流水灯程序并掌握分频的方法。熟悉 Modelsim 仿真软件的使用。
二、 实验要求
用 Quartus 编写流水灯程序,在 Modelsim 软件中进行仿真。
三、 实验仪器和设备
1、 硬件:计算机 2、 软件:Quartus、Modelsim、(UE)
四、 实验内容
1、 将时钟周期进行分频。 2、 编写 Verilog 程序实现 LED 等依次亮灭,用 Modelsim 进行仿真,绘制波形图。
五、 实验设计
(一)分频原理 已知时钟周期f 为 50MHz,周期 T 为 1/f,即 20ns。若想得到四分频计数器,即周期为 80ns 的时钟,需要把时钟进行分频。即每四个时钟周期合并为一个周期。原理图如图 1 所示。
1
学海无 涯
clk LED
LED
FPGA
cnt
图 2 设计基本框图
(四)位拼接的用法 若输入 a=4'b1010,b=3'b101,c=4'b0101,想要使输出 d=5'b10001 用位拼接,符号“{ }”:d<={b[2:1],c[1],a[2:1]} 即把 b 的低 1~2 位 10,c 的低 1 位 0,a 的低 1~2 位 01 拼接起来,得到 10 0 01。 流水灯
计算机组成CPU数据通路verilog实验报告.doc

计算机组成与系统结构实验报告院(系):计算机科学与技术学院专业班级:学号:姓名:同组者:指导教师:实验时间: 2012 年 5 月 23 日实验目的:完成处理器的单周期cpu的设计。
实验仪器:PC机(安装Altebra 公司的开发软件 QuartusII)一台实验原理:控制器分为主控制器和局部ALU控制器两部分。
主控制器的输入为指令操作码op,输出各种控制信号,并根据指令所涉及的ALU运算类型产生ALUop,同时,生成一个R-型指令的控制信号R-type,用它来控制选择将ALUop输出作为ALUctr信号,还是根据R-型指令中的func字段来产生ALUctr信号。
实验过程及实验记录:1.设计过程:第一步:分析每条指令的功能,并用RTL来表示。
第二步:根据指令的功能给出所需的元件,并考虑如何将它们互连。
第三步:确定每个元件所需控制信号的取值。
第四步:汇总各指令涉及的控制信号,生成所反映指令与控制信号之间的关系图。
第五步:根据关系表,得到每个控制信号的逻辑表达式,据此设计控制电路。
2.完成代码的编写,并调试运行。
1)controlmoduleControl(op,func,Branch,Jump,RegDst,ALUSrc,ALUctr,MemtoReg, RegWr,MemWr,ExtOp);input [5:0] op,func;output regBranch,Jump,RegDst,ALUSrc,MemtoReg,RegWr,MemWr,ExtOp; output reg [2:0] ALUctr;always @(op)case(op)6'b000000:beginBranch=0;Jump=0;RegDst=1;ALUSrc=0;MemtoReg=0;RegWr=1;MemWr =0;case(func)6'b100000:ALUctr=3'b001;6'b100010:ALUctr=3'b101;6'b100011:ALUctr=3'b100;6'b101010:ALUctr=3'b111;6'b101011:ALUctr=3'b110;endcaseend6'b001101:beginBranch=0;Jump=0;RegDst=0;ALUSrc=1;MemtoReg=0;RegWr=1;MemWr =0;ExtOp=0;ALUctr=3'b010;end6'b001001:beginBranch=0;Jump=0;RegDst=0;ALUSrc=1;MemtoReg=0;RegWr=1;MemWr =0;ExtOp=1;ALUctr=3'b000;end6'b100011:beginBranch=0;Jump=0;RegDst=0;ALUSrc=1;MemtoReg=1;RegWr=1;MemWr =0;ExtOp=1;ALUctr=3'b000;end6'b101011:beginBranch=0;Jump=0;ALUSrc=1;RegWr=0;MemWr=1;ExtOp=1;ALUctr=3' b000;end6'b000100:beginBranch=1;Jump=0;ALUSrc=0;RegWr=0;MemWr=0;ALUctr=3'b100; end6'b000010:beginBranch=0;Jump=1;RegWr=0;MemWr=0;endendcaseendmodule2)数据通路DataRoadmoduleDataRoad(Run,Clk,RegWr,MemWr,MemtoReg,RegDst,Branch,Jump,E xtOp,ALUctr,ALUSrc,busA,busB,busW,Instruction,Reg0,Reg1,Re g2,Reg3,Reg4,Mem1,Mem2,Mem3,Result,Im);inputRun,Clk,RegWr,MemWr,MemtoReg,RegDst,Branch,Jump,ExtOp,ALUS rc;input [2:0] ALUctr;output [31:0]Instruction,busA,busB,busW,Reg0,Reg1,Reg2,Reg3,Reg4,Mem1,M em2,Mem3,Result,Im;wire [31:0] busC,DataOut;wire [15:0] im;wire [4:0] Rs,Rd,Rt;wire Overflow,Zero;QZL qzl(Clk,Branch,Jump,Zero,Instruction,Run);assign Rs=Instruction[25:21];assign Rt=Instruction[20:16];assign Rd=Instruction[15:11];assign im=Instruction[15:0];Registerregister(Run,RegWr,Overflow,RegDst,Rd,Rs,Rt,busW,busA,busB ,Clk,Reg0,Reg1,Reg2,Reg3,Reg4);ALU alu(busA,busC,ALUctr,Zero,Overflow,Result);DataMem(Run,MemWr,Clk,busB,DataOut,Result,Mem1,Mem2,Mem3); MUX mux1(ALUSrc,busB,Im,busC);MUX mux2(MemtoReg,Result,DataOut,busW);Extender ext(im,Im,ExtOp);endmodule3)取指令module QZL(Clk,Branch,Jump,Zero,Instruction,Run);input Clk,Branch,Jump,Zero,Run;output [31:0] Instruction;wire [4:0] addmem;reg [29:0] PC;wire [29:0] Newpc,pc_1,pc_2,pc_3,pc_12,imm30;wire Branch_Zero;assign addmem={PC[2:0],2'b00};InsMem GetIns(addmem,Instruction);always @(negedge Clk)if(Run==1)beginPC<=Newpc;endelsebeginPC<=0;endassign pc_1=PC+1;assign imm30={{14{Instruction[15]}},Instruction[15:0]}; assign pc_2=pc_1+imm30;assign pc_3={PC[29:26],Instruction[25:0]};assign Branch_Zero=Branch&Zero;MUX m1(Branch_Zero,pc_1,pc_2,pc_12);MUX m2(Jump,pc_12,pc_3,Newpc);endmodulemodule InsMem(addmem,Instruction);input [4:0] addmem;output reg[31:0] Instruction;reg [31:0] Mem[31:0];always @(*)beginMem[0]<={6'b100011,5'b00000,5'b00001,5'b00000,5'b00000,6'b 000001};Mem[4]<={6'b100011,5'b00000,5'b00010,5'b00000,5'b00000,6'b 000010};Mem[8]<={6'b000000,5'b00001,5'b00010,5'b00011,5'b00000,6'b 100000};Mem[12]<={6'b101011,5'b00000,5'b00011,5'b00000,5'b00000,6' b000010};Mem[16]<={6'b001101,5'b00100,5'b00100,5'b11111,5'b11111,6' b111111};Mem[20]<={6'b000000,5'b00011,5'b00010,5'b00010,5'b00000,6' b100010};Mem[24]<={6'b000100,5'b00010,5'b00001,5'b00000,5'b00000,6' b001000};Mem[28]<={6'b000010,5'b00000,5'b00000,5'b00000,5'b00000,6' b000000};endalways @(*)。
verilog实验报告流水灯数码管秒表交通灯

流水灯实验目的:在basys2开发板上实现LED灯的花样流水的显示,如隔位显示,依次向左移位显示,依次向右移位显示,两边同时靠中间显示。
实验仪器:FPGA开发板一块,计算机一台。
实验原理:当一个正向的电流通过LED时,LED就会发光。
当阳极的电压高于阴极的电压时,LED就会有电流通过。
当在LED上增添一个典型值为1.5V—2.0V之间的电压时,LED就会有电流通过并发光。
实验内容:顶层模块:输入信号:clk_50MHz(主时钟信号),rst(重置信号),输出信号:[7:0] led(LED灯控制信号)。
module led_top(clkin,rst,led_out);input clkin, rst;output [7:0] led_out;wire clk_1hz;divider_1hz d0(clkin, rst, clk_1hz);led l0(clk_1hz, rst, led_out);endmodule分频模块:module divider_1hz(clkin,rst,clkout);input clkin,rst;output reg clkout;reg [24:0] cnt;always@(posedge clkin, posedge rst)beginif(rst) begincnt<=0;clkout<=0; endelse if(cnt==24999999) begincnt<=0;clkout=!clkout; endelse cnt<=cnt+1;endendmodule亮灯信号模块:module led(clkin,rst,led_out);input clkin,rst;output [7:0] led_out;reg [2:0] state;always@(posedge clkin, posedge rst)if(rst) state<=0;else state<=state+1;always@(state)case(state)3'b000:ledout<=8'b0000_0001;3'b001:ledout<=8'b0000_0010;3'b010:ledout<=8'b0000_0100;3'b011:ledout<=8'b0000_1000;3'b100:ledout<=8'b0001_0000;3'b101:ledout<=8'b0010_0000;3'b110:ledout<=8'b0100_0000;3'b111:ledout<=8'b1000_0000;endcaseendmodule实验中存在的问题:1 芯片选择问题automotive spartan3EXA3S100E XA3S250E CPG132spartan3EXC3S100E XC3S250E CP1322 时序逻辑部分,阻塞赋值和非阻塞赋值混用always@(posedge clk)begina=b+c;d<=e+f;end3 UCF文件格式错误NET “CLK” LOC = “B8”;NET “a” LOC = “N11”;NET “b” LOC = “G13”;NET “c[0]”LOC =“K11;数码管实验目的:设计一个数码管动态扫描程序,实现在四位数码管上动态循环显示“1”、“2”“3”“4”;实验仪器:FPGA开发板一块,计算机一台。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告课程名称:__ 数字系统设计实验Ⅱ__指导老师:成绩:_______实验名称:流水线MIPS微处理器设计实验类型:____设计型__ __一、实验目的和要求(必填)二、实验内容和原理(必填)三、主要仪器设备(必填)四、操作方法和实验步骤五、实验数据记录和处理六、实验结果与分析(必填)七、讨论、心得一、实验目的1.了解提高CPU性能的方法。
2.掌握流水线MIPS微处理器的工作原理。
3.理解数据冒险、控制冒险的概念以及流水线冲突的解决方法。
4.掌握流水线MIPS微处理器的测试方法。
二、实验任务设计一个32位流水线MIPS微处理器,具体要求如下:1.至少运行下列MIPS32指令。
(1)算术运算指令:ADD、ADDU、SUB、SUBU、ADDI、ADDIU。
(2)逻辑运算指令:AND、OR、NOR、XOR、ANDI、ORI、XORI、SLT、SLTU、SLTI、SLTIU。
(3)移位指令:SLL、SLLV、SRL、SRLV、SRA。
(4)条件分支指令:BEQ、BNE、BGEZ、BGTZ、BLEZ、BLTZ。
(5)无条件跳转指令:J、JR。
(6)数据传送指令:LW、SW。
(7)空指令:NOP。
2.采用5级流水线技术,对数据冒险实现转发或阻塞功能。
3.在XUP Virtex-Ⅱ Pro 开发系统中实现MIPS微处理器,要求CPU的运行速度大于25MHz。
三、实验原理1.总体设计流水线是数字系统中一种提高系统稳定性和工作速度的方法,广泛应用于高档CPU的架构中。
根据MIPS处理器的特点,将整体的处理过程分为取指令(IF)、指令译码(ID)、执行(EX)、存储器访问(MEM)和寄存器会写(WB)五级,对应多周期的五个处理阶段。
如图3.1所示,一个指令的执行需要5个时钟周期,每个时钟周期的上升沿来临时,此指令所代表的一系列数据和控制信息将转移到下一级处理。
图3.1 流水线流水作业示意图由于在流水线中,数据和控制信息将在时钟周期的上升沿转移到下一级,所以规定流水线转移变量命名遵守如下格式:名称_流水线级名称例如:在ID级指令译码电路(Decode)产生的寄存器写允许信号RegWrite在ID级、EX级、MEM级和WB级上的命名分别为RegWrite_id、RegWrite_ex、RegWrite_mem和RegWrite_wb。
在顶层文件中,类似的变量名称有近百个,这样的命名方式起到了很好的识别作用。
1)流水线中的控制信号(1)IF级:取指令级。
从ROM中读取指令,并在下一个时钟沿到来时把指令送到ID 级的指令缓冲器中。
该级控制信号决定下一个指令指针的PCSource信号、阻塞流水线的PC_IFwrite信号、清空流水线的IF_flush信号。
(2)ID级:指令译码器。
对IF级来的指令进行译码,并产生相应的控制信号。
整个CPU的控制信号基本都是在这级上产生。
该级自身不需任何控制信号。
流水线冒险检测也在该级进行,冒险检测电路需要上一条指令的MemRead,即在检测到冒险条件成立时,冒险检测电路产生stall信号清空ID/EX寄存器,插入一个流水线气泡。
(3)EX级:执行级。
该级进行算术或逻辑操作。
此外LW、SW指令所用的RAM访问地址也是在本级上实现。
控制信号有ALUCode、ALUSrcA、ALUScrB和RegDst,根据这些信号确定ALU操作、选择两个ALU操作数A、B,并确定目标寄存器。
另外,数据转发也在该级完成。
数据转发控制电路产生ForwardA和ForwardB两组控制信号。
(4)MEM级:存储器访问级。
只有在执行LW、SW指令时才对存储器进行读写,对其他指令只起到一个周期的作用。
该级只需存储器写操作允许信号MemWrite。
(5)WB级:写回级。
该级把指令执行的结果回写到寄存器文件中。
该级设置信号MemtoReg和寄存器写操作允许信号RegWrite,其中MemtoReg决定写入寄存器的数据来自于MEM级上的缓冲值或来自于MEM级上的存储器。
2)流水线冒险在流水线CPU中,多条指令通知执行,由于各种各样的原因,在下一个时钟周期中下一条指令不能执行,这种情况称为冒险。
冒险分为三类:①结构冒险:硬件不支持多条指令在同一个时钟周期内执行。
MIPS指令集专为流水线设计,因此在MIPS CPU中不存在此类冒险。
②数据冒险:在一个操作必须等待另一操作完成后才能进行时,流水线必须停顿,这种情况称为数据冒险。
数据冒险分为两类:ⅰ数据相关:流水线内部其中任何一条指令要用到任何其他指令的计算结果时,将导致数据冒险。
通常可以用数据转发(数据定向)来解决此类冒险。
ⅱ数据冒险:此类冒险发生在当定向的目标阶段在时序上早于定向的源阶段时,数据转发无效。
通常是引入流水线阻塞,即气泡(bubble)来解决。
③控制冒险:CPU需要根据分支指令的结果做出决策,而此时其他指令可能还在执行中,这时会出现控制冒险,也称为分支冒险。
解决此类冒险的常用方法是延迟分支。
2.1)数据相关与转发下面通过具体例子来阐述数据相关。
见图3.2图3.2 数据相关性问题实例图可见,后4条指令都依赖于第一条指令得到寄存器$2的结果,但sub指令要在第五周期才写回寄存器$2,但在第三、四、五个时钟周期$2分别要被and、or和add三个指令用到,所以这三个指令得到的是错误的未更新的数据,会引起错误的结果;而第六个时钟周期$2要被sw指令用到,此时得到的才是正确的已更新的数据。
这种数据之间的互相关联引起的冒险就是数据相关。
可以看出,当一条依赖关系的方向与时间轴的方向相反时,就会产生数据冒险。
(1)一阶数据相关与转发(EX冒险)首先讨论指令sub与and之间的相关问题。
sub指令在第五周期写回寄存器$2,而and指令在第四周期就对sub指令的结果$2提出申请,显然将得到错误的未更新的数据。
像这类第I条指令的源操作寄存器与第I-1条指令(即上一条指令)的目标寄存器相重,导致的数据相关称为一阶数据相关。
见图3.3中实线所示。
图3.3 一阶数据相关实例图可以发现,sub指令的结果其实在EX级结尾,即第三周期末就产生了;而and指令在第四时钟周期向sub指令结果发出请求,请求时间晚于结果产生时间,所以只需要sub指令结果产生之后直接将其转发给and指令就可以避免一阶数据相关。
如图3.3虚线所示。
转发数据为ALUResult_mem数据转发由Forwarding unit单元控制,判断转发条件是否成立。
转发机制硬件实现见图3.4图3.4 转发机制的硬件实现转发条件ForwardA、ForwardB作为数据选择器的地址信号,转发条件不成立时,ALU 操作数从ID/EX流水线寄存器中读取;转发条件成立时,ALU操作数取自数据旁路。
转发条件:①MEM级指令是写操作,即RegWrite_mem=1;②MEM级指令写回的目标寄存器不是$0,即RegWriteAddr_mem≠0;③MEM级指令写回的目标寄存器与在EX级指令的源寄存器是同一寄存器,即RegWriteAddr_mem=RsAddr_ex 或RegWriteAddr_mem=RtAddr_ex。
(2)二阶数据相关与转发(MEM冒险)接下来讨论sub指令与or指令之间的相关问题。
sub指令在第5时钟周期写回寄存器,而or指令也在第5时钟周期对sub指令的结果提出了请求,很显然or指令读取的数据是未被更新的错误内容。
这类第I条指令的源操作寄存器与第I-2条指令(即之上第二条指令)的目标寄存器相重,导致的数据相关称为二阶数据相关。
见图3.5中实线所示。
图3.5 一阶数据相关实例图如前所述,or指令在第五时钟周期向sub指令结果发出请求时,sub指令的结果已经产生。
所以,我们同样采用“转发”,即通过MEM/WB流水线寄存器,将sub指令结果转发给or指令,而不需要先写回寄存器堆。
如图3.5中虚线所示。
转发数据为RegWriteData_wb 转发条件:①WB级指令是写操作,即RegWrite_wb=1;②WB级指令写回的目标寄存器不是$0,即RegWriteAddr_wb≠0;③WB级指令写回的目标寄存器与在EX级指令的源寄存器是同一寄存器,即RegWriteAddr_wb=RsAddr_ex 或RegWriteAddr_wb=RtAddr_ex;④EX冒险不成立,即RegWriteAddr_mem≠RsAddr_ex 或RegWriteAddr_mem=RtAddr_ex。
(3)三阶数据相关与转发最后讨论sub指令与add指令之间的相关问题。
sub指令与add指令在第五时钟周期内同时读写同一个寄存器。
这类同一周期内同时读写同一个寄存器的数据相关称之为三阶数据相关。
如图3.6中实线所示。
图3.6 三阶数据相关实例图假设寄存器的写操作发生在时钟周期的上升沿,而读操作发生在时钟周期的下降沿,那么读操作将读取到最新写入的内容。
在这种假设条件下将不会发生数据冒险。
这就要求流水线中的寄存器具有“先写后读(Read After Write)”的特性。
这类“写操作发生在时钟周期的上升沿,读操作发生在时钟周期的下降沿”的寄存器虽然在理论上是可实现的,但是不适合应用于同步系统,因为它不但影响系统的运行速度,而且影响系统的稳定性,是不可取的。
因此,我们采用“转发”机制来解决三阶数据相关冒险。
该部分转发电路我们放在寄存器堆的设计中完成。
如图3.6中虚线所示。
转发数据为RegWriteData_wb。
转发条件为:①WB级指令是写操作,即RegWrite_wb=1;②WB级指令写回的目标寄存器不是$0,即RegWriteAddr_wb≠0;③WB级指令写回的目标寄存器与在ID级指令的源寄存器是同一寄存器,即RegWriteAddr_wb=RsAddr_id 或RegWriteAddr_wb=RtAddr_id。
2.2)数据冒险与阻塞当一条指令试图读取一个寄存器,而它前一条指令是lw指令,并且该lw指令写入的是同一个寄存器时,定向转发的方法就无法解决问题。
如图3.7所示注意到lw指令只能在第四时钟周期从内存中读出数据,因此它和紧随其后的and指令之间的依赖关系与时序方向是相反的,这种冒险是无法通过转发来实现的。
图3.7 数据冒险与阻塞实例图这类冒险不同于数据相关冒险,需要单独一个“冒险检测单元(Hazard Detector)”,它在ID级完成。
冒险成立的条件为:①上一条指令是lw指令,即MemRead_ex=1;②在EX级的lw指令与在ID级的指令读写的是同一个寄存器,即RegWriteAddr_ex=RsAddr_id 或RegWriteAddr_ex=RtAddr_id。
冒险的解决:为解决数据冒险,我们引入流水线阻塞。