Wu-Manber algorithm
基于CUDA的Wu-Manber多模式匹配算法

N D A 公司推 出的一种全 新的软件和硬件架构 ,它 VI I 将 G U视为一个并行数据 计算的设备, P 对所进行 的任 务进行 分配和 计算。C DA编程模型【 】 U 5 将执行 的程序 , 6 分为两部分: s端与 D vc 端 。 ot 是指在 C U Hot ei e H s端 P 上执行 的部分 ,Dei vc e端则是在 G U上执行 的部分 , P
的编程 模 型 以及 WuMab r算法 ,第 3 节 是 关于 . ne
WuMa br . n e 算法在 C DA下的实现 与优化 , 4节是 U 第 实验 结果与分 析,最后 是结 束语 。
角,其 已经应用在 图形动画 、科学计算 、生物 、物理
2 相关技术介绍
21 D .CU A编程模型 C D C m ueU ie e i rh etr)J U A( o p t nf dD vc A ci c e[ i e t u 5 是
_
C DA 中包含 多种存储空 间,合理使用这些存储 U 空间能够提高 数据访 问速度 ,节省带宽,提升程 序的
性能 。
行完全 匹配 ,若有完全 匹配则报告结果 。T :T+1,
转() 1。
2 - n e 算法 介绍 . WuMa b r 2
3 Wu n e算法在C D . br Ma U A中的实现
()计算该窗 口T的前缀 即 … 的哈希值 ,记 3
为 tx p e x。 et r f i
_
()对于符合 H S h】 <H H【 1所有 4 A H【 P AS h+ 】 C DA程序流程 U p ,若 P FX【 t tpe x E R I P】 x rf ,则 把 文本 和模 式 串进 e i
一种改进的Wu—Manber多模式串匹配算法

第3 4卷第 l 0期 20 0 7年 l 0月
应
用
科
技
Vo . 4. o.1 13 N 0
0c_ 0o t2 7
Appi d S e c a Te h o o y le cin e nd 0 7 1 0 3 0 10 6 1 2 0 ) 0— 0 2— 4
网络 的高速 化 发 展 , 以及 由此 引起 的 网络 入 侵
手 段 的多样 化对 入 侵 检测 系统 提 出 了严 峻 考 验. 对
的模式 串进 行 配 的算 法 . 多 是单 模 式 串匹 配算 大 法的推 广 , 主要 有 A C算法 和 wuMab r 法 等 . — n e算 A C算 法 是一 种 采 用 有 限 状 态 自动 机 的 算 法 , 由于
A dl gr v rg h ia c a c urd WM a d Wu M n e lo tm w r cmp r nep r ns n a e eaesi d tnew sa q i .Q n - a b ra rh ee o ae i x e me t r a t f s e gi d i .
g a n x e o t e c re twi d w,t e ma i r m e td t h u r n n o h x mum h f d sa c ft e a g rt m e c e 4 B r m —B 1 s i itn e o h lo h r a h d m - fo m t i - 4 .
H aq at f n 5 1 , hncu 3 0 1 C ia edu r r i6 3 6 C agh n10 0 , hn ) eoU t
A s at B sdo ea a s f - n e l rh n h e f Sa o tm, ni poe ut l p t bt c: ae nt n l i o Mab r gi m a dtei ao l rh a m rvd m lpe a- r h y s Wu a ot d Q gi i t n a hn l rh a rsne , a e WM( uc - a b r .C nie n eif m t no eB e sm t igagi m w speetd n m dQ r c ot Q ikWu M n e) o s r gt o ai f h — di h n r o t
基于分解算法的动态大规模合乘匹配-路径规划

基于分解算法的动态大规模合乘匹配-路径规划
孙芮;吴文祥
【期刊名称】《科学技术与工程》
【年(卷),期】2022(22)4
【摘要】动态合乘是出行路线相似的出行者共用一辆车的交通方式,能够有效利用现有资源,最大化社会效益。
当前合乘研究存在司机-乘客匹配质量不高,算法实时性差等局限。
提出了考虑订单匹配数量、司机旅行时间、乘客等待时间与乘客延误时间的司机-乘客合乘匹配模型。
针对模型特点,设计了基于分解方法的司机-乘客合乘匹配与路径规划算法。
通过选择贪心随机自适应搜索算法、粒子群算法与本文的算法对比,成都市网约车数据验证,结果表明:分解算法下司机与乘客不方便成本低于贪心与粒子群算法;分解算法订单匹配率在90%以上,高于贪心与粒子群算法的80%~90%匹配率。
通过对比证明,所提出的模型与算法,能够在保证高匹配率的前提下,降低出行不方便成本,提高算法实时性,在实际工程中有较好的应用效果。
【总页数】7页(P1662-1668)
【作者】孙芮;吴文祥
【作者单位】北方工业大学电气与控制工程学院
【正文语种】中文
【中图分类】U491.1
【相关文献】
1.基于Wu-Manber算法的大规模URL模式串匹配算法
2.基于Wu-Manber算法的大规模URL模式串匹配算法
3.基于A*算法与自适应分片的大规模最优路径规划
4.基于结构分解的动态图增量匹配算法
5.基于改进粒子群算法的大规模自动导引车系统路径规划优化
因版权原因,仅展示原文概要,查看原文内容请购买。
Wu-Manber算法的一种综合改进

3 在 T 中 向后 移动 S F X] ) HI TE 个字符 , 即取 T 中前 T+S F X3 字符 中 的后 B 个 , 查 S F 3 F HI TE 个 / 再 HI TE
4如果 S F X3 , 明 T 中当前 位置 是一 个可 能 的匹 配入 口, ) m T ̄ 一O表 执行 相互 的匹配 过程 . 后 T 的后 然
算法 的 匹配过程 如下 所述 :
1取 T 文 本 的前 T 个 字符 中的后 B个 , 为 x, S F ] , ) F / 设 查 HI T[ 表
链表 结点, 为指向 P 模式串
图 1 A H表的数据结构 H S
然后 根据 S V X3 HI TE 值进行 相应 的动 作.
移 动 1个字符 , 继续 执行 2 步骤 . )
收 稿 日期 : 0 8 0 — 7 2 0— 30
Vo. No 2 17 . J n. 2 0 u 08
Wu Ma b r — n e 算法的一种综合改进
莫 德 敏 刘 耀 军
( . 原科 技 大 学 计 算 机 科 学技 术 学 院 , 1太 山西 太 原 0 0 2 ; . 原 师 范 学 院 计 算 机 系 , 西 太 原 0 0 1 ) 3042太 山 3 0 2
较 等 领域 . 典 的多关 键 字 匹 配包 括 Ah — o ai 经 oC rs k算 法 口 , o c ]C mme t— l r 法 [ , e Ho so l 法 , n zWat 算 e 1 S t rp o 算 ] Wu S n A . n e . u  ̄ ima b r的 wu Ma b r 法n 和各种 并行 算 法_等 . 中 Wu Ma b r 法采 用 了 B 算 法l — ne 算 】 其 — ne 算 M _ 2 ] 的跳跃 思想 和 HAS 散列 的方法 , H 在许 多相 关 领域 中得 到 了应 用. 献 E ] Wu Ma b r 法 的跳跃距 离 文 3对 — ne 算
Wu-Manber算法性能分析及其改进

Wu-Manber算法性能分析及其改进
陈瑜;陈国龙
【期刊名称】《计算机科学》
【年(卷),期】2006(33)6
【摘要】在模式匹配中,多模式匹配算法越来越受到人们的关注.本文首先介绍了一些著名的多模式匹配算法,重点介绍了Wu-Manber算法的基本概念及其实现原理,此算法在实践应用中是最有效的.然后提出了对Wu-Manber算法的改进,以解决多模式串长度很短时出现的性能问题.最后,实验数据表明,改进后的Wu-Manber算法,其性能远远优于传统的Wu-Manber算法.
【总页数】4页(P203-205,209)
【作者】陈瑜;陈国龙
【作者单位】福州大学数学与计算机科学学院,福州350002;福州大学数学与计算机科学学院,福州350002
【正文语种】中文
【中图分类】TP3
【相关文献】
1.改进的Wu-Manber多模式串匹配算法的设计与实现 [J], 姚永安
2.Wu-Manber算法在大规模模式串下的改进 [J], 莫德敏;刘耀军
3.Wu-Manber算法的改进研究 [J], 王佳星;陈华辉
4.一种改进的Wu-Manber多模式串匹配算法 [J], 刘征宇;刘学生
5.一种改进的Wu-Manber多关键字匹配算法 [J], 莫德敏;刘耀军
因版权原因,仅展示原文概要,查看原文内容请购买。
【计算机应用与软件】_移动应用_期刊发文热词逐年推荐_20140723
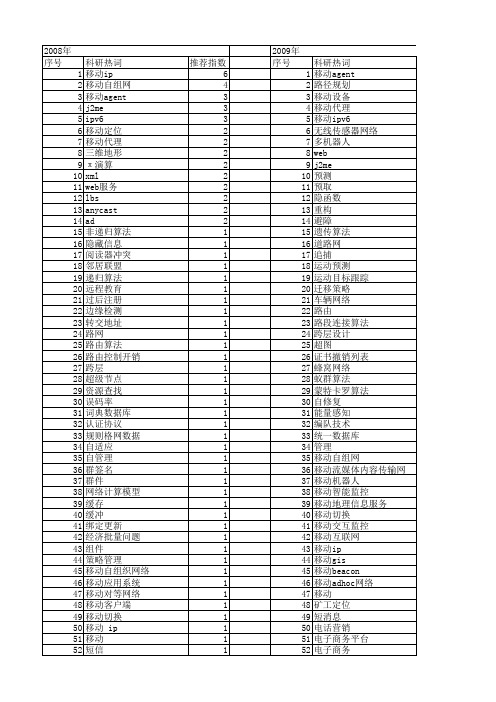
科研热词 移动ip 移动自组网 移动agent j2me ipv6 移动定位 移动代理 三维地形 π 演算 xml web服务 lbs anycast ad 非递归算法 隐藏信息 阅读器冲突 邻居联盟 递归算法 远程教育 过后注册 边缘检测 转交地址 路网 路由算法 路由控制开销 跨层 超级节点 资源查找 误码率 词典数据库 认证协议 规则格网数据 自适应 自管理 群签名 群件 网络计算模型 缓存 缓冲 绑定更新 经济批量问题 组件 策略管理 移动自组织网络 移动应用系统 移动对等网络 移动客户端 移动切换 移动 ip 移动 短信
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
科研热词 移动agent 路径规划 移动设备 移动代理 移动ipv6 无线传感器网络 多机器人 web j2me 预测 预取 隐函数 重构 避障 遗传算法 道路网 追捕 运动预测 运动目标跟踪 迁移策略 车辆网络 路由 路段连接算法 跨层设计 超图 证书撤销列表 蜂窝网络 蚁群算法 蒙特卡罗算法 自修复 能量感知 编队技术 统一数据库 管理 移动自组网 移动流媒体内容传输网络 移动机器人 移动智能监控 移动地理信息服务 移动切换 移动交互监控 移动互联网 移动ip 移动gis 移动beacon 移动adhoc网络 移动 矿工定位 短消息 电话营销 电子商务平台 电子商务
盲检测 盲多用户检测 电子白板 游戏编程 混合路由 汉诺塔 模板 检测和过滤 树 有保质期产品 最短路径 最大独立集 智能移动终端 智能化学习 智能agent 无线门户网站 无线应用协议 无线传感网络 无线传感反应网络 无线会话协议 数据转换 数据查询 数据同步 数字高程模型 数字水印 改进 ike 握手协议 拥塞控制 手机游戏 恶意主机 性能优化 快速切换 彩信协议栈 异种网络 异常入侵检测 库存约束 并发控制 工作流建模 嵌入式移动数据库 嵌入式 层次细节模型 层次型fa 层次化ip 小尺度衰落 射频识别技术 对等网络 容量约束 定位网关 定位中心 安全漏洞 安全对策 安全关联增强 学习petri网 大尺度路径损耗
Wu—Manber算法性能分析及其改进

如果对于 1 ≤ n存在 丁[+1 ] I 1 ・ ] ≤ , … +m =尸 [.m , .
其中 1 ≤ ≤五 则模式 串 尸 在 文本 丁 的位 置 i 出 现, , I 处 即模 式串与文本匹配 。字符 串的多模式匹配 问题就是要寻找多个 P在 T 中是否 出现 , 以及 出现的位置 。 目前已出现多种多模 式匹 配算法 。早在 1 7 9 5年 , V. 八 Ah o和 M.. oai J C rs k就提 出解 决 多模 式 匹配 问题 的 A c h
介绍 了 wu n e 算法的基 本概 念及 其实现原理 , 算法在 实践应 用 中是 最有效 的。然后提 出 了对 WuMabr — br Ma 此 - ne 算 法的改进 , 以解决多模 式 串长度很 短时 出现的性能 问题 。最后 , 实验 数据表 明, 改进 后 的 WuMa b r 法, ne算 其性 能远
。
注 的一 个 算 法 。S nWu和 Ud Ma b r] u i n eI 的实 验 表 明, s 在 S nS ac0上 , u prl 他们 的算 法可 以于 1 内完 成在 1 . M 的 O秒 58 文 本 中搜 索 1 0 0个模 式 的工 作 。在 wM 算 法 的 基础 上 , 00 S nWu和 Ud Mab r实 现 了一 个 用 于 模 糊 匹 配 的 工 具 u i ne a rp。 geE 和一个文本检索 的工 具 l s ̄ 在实 际的应 用 中都 ] i e mp , 获得 了 良好 的效 率。但是 , 我们 通过测试 实验 发现 WuMa —  ̄ n br e 算法在某些特 定情 况下 性能 并 不是 很好 , 对这 一 问题 针
远优 于传统的 WuMab r 多模 式 匹配 , 能分析 性
算法的论文

算法的论文以下是一些著名的算法论文:1. "A Fast Algorithm for Particle Simulations" - Leslie Greengard, Vladimir Rokhlin(1987)该论文提出了快速多极子方法(Fast Multipole Method, FMM),广泛应用于粒子模拟和计算机图形学中。
2. "An Efficient Parallel Algorithm for Convex Hulls in Two Dimensions" - Timothy Chan(1996)该论文提出了线性时间复杂度的二维凸包算法,对于计算凸包非常高效。
3. "A Fast Algorithm for Approximate String Matching" - Wu, S.M.; Manber, U.(1992)该论文提出了经典的字符串匹配算法——Wu-Manber算法,通过利用位运算技术,实现了高效的近似匹配。
4. "PageRank: Bringing Order to the Web" - Sergey Brin, Lawrence Page(1998)该论文介绍了PageRank算法,用于评估网页的重要性,为谷歌搜索引擎的核心算法。
5. "An O(n log n) Algorithm for Implicit Dual Graph Enumeration" - Jonathan Shewchuk(1997)该论文提出了计算三维内隐图的线性对数时间复杂度算法,为计算机图形学中的几何建模和网格生成提供了重要基础。
6. "A Fast Algorithm for the Belief Propagation" - Yair Weiss (2001)该论文提出了信念传播算法(Belief Propagation),在概率图模型和机器学习中得到广泛应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A FAST ALGORITHM FOR MULTI-PATTERN SEARCHINGSun WuDepartment of Computer ScienceChung-Cheng UniversityChia-Yi,Taiwansw@.twUdi Manber1Department of Computer ScienceUniversity of ArizonaTucson,AZ85721udi@May1994SUMMARYA new algorithm to search for multiple patterns at the same time is presented.The algorithm is faster than previous algorithms and can support a very large number—tens of thousands—of patterns.Several applications of the multi-pattern matching problem are discussed.We argue that,in addition to previous applications that required such search,multi-pattern matching can be used in lieu of indexed or sorted data in some applications involving small to medium size datasets.Its advantage,of course,is that no additional search structure is needed.Keywords:algorithms,merging,multiple patterns,searching,string matching.1Supported in part by a National Science Foundation grants CCR-9002351and CCR-9301129,and by the Advanced Research Pro-jects Agency under contract number DABT63-93-C-0052.The information contained in this paper does not necessarily reflect the position or the policy of the ernment or other spon-sors of this research.No official endorsement should be inferred.1.IntroductionWe solve the following multi-pattern matching problem in this paper:Let P={p1,p2,...,p k}be a set of patterns,which are strings of characters from afixed alphabet.Let T=t 1,t2,...,t N be a large text,again consisting of characters from.The problem is tofind all occurrences of all the patterns of P in T.For example,the UNIX fgrep and egrep programs support multi-pattern matching through the-f option.The multi-pattern matching problem has many applications.It is used in datafiltering(also called data mining)tofind selected patterns,for example,from a stream of newsfeed;it is used in security appli-cations to detect certain suspicious keywords;it is used in searching for patterns that can have several forms such as dates;it is used in glimpse[MW94]to support Boolean queries by searching for all terms at the same time and then intersecting the results;and it is used in DNA searching by translating an approxi-mate search to a search for a large number of exact patterns[AG+90].There are,of course,many other applications.Aho and Corasick[AC75]presented a linear-time algorithm for this problem,based on an automata approach.This algorithm serves as the basis for the UNIX tool fgrep.A linear-time algorithm is optimal in the worst case,but as the regular string-searching algorithm by Boyer and Moore[BM77]demonstrated, it is possible to actually skip a large portion of the text while searching,leading to faster than linear algo-rithms in the average mentz-Walter[CW79]presented an algorithm for the multi-pattern match-ing problem that combines the Boyer-Moore technique with the Aho-Corasick algorithm.The Commentz-Walter algorithm is substantially faster than the Aho-Corasick algorithm in practice.Hume[Hu91] designed a tool called gre based on this algorithm,and version2.0of fgrep by the GNU project[Ha93]is using it.Baeza-Yates[Ba89]also gave an algorithm that combines the Boyer-Moore-Horspool algorithm [Ho80](which is a slight variation of the classical Boyer-Moore algorithm)with the Aho-Corasick algo-rithm.We present a different approach that also uses the ideas of Boyer and Moore.Our algorithm is quite simple,and the main engine of it is given later in the paper.An earlier version of this algorithm was part of the second version of agrep[WM92a,WM92b],although the algorithm has not been discussed in [WM92b]and only briefly in[WM92a].The current version is used in glimpse[MW94].The design of the algorithm concentrates on typical searches rather than on worst-case behavior.This allows us to make some engineering decisions that we believe are crucial to making the algorithm significantly faster than other algorithms in practice.We start by describing the algorithm in detail.Section3contains a rough analysis of the expected running time,and experimental results comparing our algorithm to three others.The last section discusses applications of multi-pattern matching.2.The Algorithm2.1.Outline of the AlgorithmThe basic idea of the Boyer-Moore string-matching algorithm[BM77]is as follows.Suppose that the pat-tern is of length m.We start by comparing the last character of the pattern against t m,the m’th character of the text.If there is a mismatch(and in most texts the likelihood of a mismatch is much greater than the likelihood of a match),then we determine the rightmost occurrence of t m in the pattern and shift accord-ingly.For example,if t m does not appear in the pattern at all,then we can safely shift by m characters and look next at t2m;if t m matches only the4th character of the pattern,then we can shift by m4,and so on. In natural language texts,shifts of size m or close to it will occur most of the time,leading to a very fast algorithm.We want to use the same idea for the multi-pattern matching problem.However,if there are many patterns,and we would like to support tens of thousands of patterns,chances are that most characters in the text match the last character of some pattern,so there would be few if any such shifts.We will show how to overcome this problem and keep the essence(and speed)of the Boyer-Moore algorithm.Thefirst stage is a preprocessing of the set of patterns.Applications that use afixed set of patterns for many searches may benefit from saving the preprocessing results in afile(or even in memory).This step is quite efficient,however,and for most cases it can be done on thefly.Three tables are built in the preprocessing stage,a SHIFT table,a HASH table,and a PREFIX table.The SHIFT table is similar,but not exactly the same,to the regular shift table in a Boyer-Moore type algorithm.It is used to determine how many characters in the text can be shifted(skipped)when the text is scanned.The HASH and PRE-FIX tables are used when the shift value is0.They are used to determine which pattern is a candidate for the match and to verify the match.Exact details are given next.2.2.The Preprocessing StageThefirst thing we do is compute the minimum length of a pattern,call it m,and consider only the first m characters of each pattern.In other words,we impose a requirement that all patterns have the same length.It turns out that this requirement is crucial to the efficiency of the algorithm.Notice that if one of the patterns is very short,say of length2,then we can never shift by more than2,so having short patterns inherently makes this approach less efficient.Instead of looking at characters from the text one by one,we consider them in blocks of size B.Let M be the total size of all patterns,M=k*m,and let c be the size of the alphabet.As we show in Section 3.1,a good value of B is in the order of log c2M;in practice,we use either B=2or B=3.The SHIFT table plays the same role as in the regular Boyer-Moore algorithm,except that it determines the shift based on the last B characters rather than just one character.For example,if the string of B characters in the text do not appear in any of the patterns,then we can shift by m B+1.Let’s assume for now that the SHIFT table contains an entry for each possible string of size B,so its size is||B.(We will actually use a compressedtable with several strings mapped into the same entry to save space.)Each string of size B is mapped (using a hash function discussed later)to an integer used as an index to the SHIFT table.The values in the SHIFT table determine how far we can shift forward(skip)while we scan the text.Let X=x1...x B bethe B characters in the text that we are currently scanning,and assume that X is mapped into the i’th entry of SHIFT.There are two cases:1.X does not appear as a substring in any pattern of PIn this case,we can clearly shift m B+1characters in the text.Any smaller shift will put the last B characters of the text against a substring of one of the patterns which is a mismatch.We store in SHIFT[i]the number m B+1.2.X appears in some patternsIn this case,wefind the rightmost occurrence of X in any of the patterns;let’s assume that X ends at position q of P j and that X does not end at any position greater than q in any other pattern.We store m q in SHIFT[i].To compute the values of the SHIFT table,we consider each pattern p i=a1a2...a m separately. We map each substring of p i of size B a j B+1...a j into SHIFT,and set the corresponding value to the minimum of its current value(the initial value for all of them is m B+1)and m j(the amount of shifting required to get to this substring).The values in the SHIFT table are the largest possible safe values for shifts.Replacing any of the entries in the SHIFT table with a smaller value will make less shifts and will take more time,but it will still be safe:no match will be missed.So we can use a compressed table for SHIFT,mapping several different strings into the same entry as long as we set the minimal shift of all of them as the value.In agrep,we actually do both.When the number of patterns is small,we select B=2,and use an exact table for SHIFT; otherwise,we select B=3and use a compressed table for SHIFT.In either case,the algorithm is oblivious to whether or not the SHIFT table is exact.As long as the shift value is greater than0,we can safely shift and continue the scan.This is what happens most of the time.(In a typical example,the shift value was zero5%of the time for100patterns, 27%for1000patterns,and53%for5000patterns.)Otherwise,it is possible that the current substring in the text matches some pattern in the pattern list.But which pattern?To avoid comparing the substring to every pattern in the pattern list,we use a hashing technique to minimize the number of patterns to be com-pared.We already computed a mapping of the B characters into an integer that is used as an index to the SHIFT table.We use the exact same integer to index into another table,called HASH.The i’th entry of the HASH table,HASH[i],contains a pointer to a list of patterns whose last B characters hash into i.The HASH table will typically be quite sparse,because it holds only the patterns whereas the SHIFT table holds all possible strings of size B.This is an inefficient use of memory,but it allows us to reuse the hash func-tion(the mapping),thus saving a lot of time.(It is also possible to make the hash table a power of2frac-tion of the SHIFT table and take just the last bits of the hash function.)Let h be the hash value of the current suffix in the text and assume that SHIFT[h]=0.The value of HASH[h]is a pointer p that points into two separate tables at the same time:We keep a list of pointers to the patterns,PAT_POINT,sorted by the hash values of the last B characters of each pattern.The pointer p points to the beginning of the list of patterns whose hash value is h.Tofind the end of this list,we keep incrementing this pointer until it is equal to the value in HASH[h+1](because the whole list is sortedaccording to the hash values).So,for example,if SHIFT[h]0,then HASH[h]=HASH[h+1](becauseno pattern has a suffix that hash to h).In addition,we keep a table called PREFIX,which will be described shortly.Natural language texts are not random.For example,the suffixes‘ion’or‘ing’are very common in English texts.These suffixes will not only appear quite often in the text,but they are also likely to appear in several of the patterns.They will cause collisions in the HASH table;that is,all patterns with the same suffix will be mapped to the same entry in the HASH table.When we encounter such a suffix in the text, we willfind that its SHIFT value is0(assuming it is a suffix of some patterns),and we will have to exam-ine separately all the patterns with this suffix to see if they match the text.To speed up this process,we introduce yet another table,called PREFIX.In addition to mapping the last B characters of all patterns,we also map thefirst B characters of all patterns into the PREFIX table.(We found that B=2is a good value.)When wefind a SHIFT value of0 and we go to the HASH table to determine if there is a match,we check the values in the PREFIX table. The HASH table not only contains,for each suffix,the list of all patterns with this suffix,but it also con-tains(hash values of)their prefixes.We compute the corresponding prefix in the text(by shifting m B characters to the left)and use it tofilter patterns whose suffix is the same but whose prefix is different. This is an effectivefiltering method because it is much less common to have different patterns that share the same prefix and the same suffix.It is also a good‘balancing act’in the sense that the extra work involved in computing the hash function of the prefixes is significant only if the SHIFT value is often0, which occurs when there are many patterns and a higher likelihood of collisions.The preprocessing stage may seem quite involved,but in practice it is done very quickly.In our implementation,we set the size of the3tables to215=32768.Running the match algorithm on a near empty textfile,which is a measure of the time it takes to do the preprocessing,took only0.16seconds for 10,000patterns.2.3.The Scanning StageWe now describe the scanning stage in more detail and give a partial code for it.The main loop of the algorithm consists of the following steps:pute a hash value h based on the current B characters from the text(starting with t m B+1...t m).2.check the value of SHIFT[h]:if it is>0,shift the text and go back to1;otherwise,go to3.pute the hash value of the prefix of the text(starting m characters to the left of the current posi-tion);call it text_prefix.4.Check for each p,HASH[h]p<HASH[h+1]whether PREFIX[p]=text_prefix.When they areequal,check the actual pattern(given by PAT_POINT[p])against the text directly.A partial C code for the main loop is given in Figure1.The complete code is available by anonymous ftp from as part of the glimpse code(check thefile mgrep.c in directory agrep).while(text<=textend){h=(*text<<Hbits)+(*(text-1));/*The hash function(we use Hbits=5)*/if(Long)h=(h<<Hbits)+(*(text-2));/*Long=1when the number of patterns warrants B=3*/shift=SHIFT[h];/*we use a SHIFT table of size215=32768*/if(shift==0){/*‘‘h=h&mask_hash’’can be used here if HASH is smaller then SHIFT*/text_prefix=(*(text-m+1)<<8)+*(text-m+2);p=HASH[h];p_end=HASH[h+1];while(p++<p_end){/*loop through all patterns that hash to the same value(h)*/if(text_prefix!=PREFIX[p])continue;px=PAT_POINT[p];qx=text-m+1;while(*(px++)==*(qx++));/*check the text against the pattern directly*/if(*(px-1)==0){/*0indicates the end of a string*/report a match}shift=1;}text+=shift;}Figure1:Partial code for the main loop.3.Performance3.1.A Rough Analysis of the Running TimeWe present an estimate for the running time of this algorithm assuming that both the text and the patterns are random strings with uniform distribution.In practice,texts and patterns are not random,but this esti-mate gives a rough idea about the performance of the algorithm.We show that the expected running time is less than linear in the size of the text(but not by much).Let N be the size of the text,P the number of patterns,m the size of one pattern,M=mP the total size of all patterns,and assume that N M.Let c be the size of the alphabet.We define the size of theblock used to address the SHIFT table as B=log c2M.The SHIFT table contains all possible strings of size b,so there are c b=c log c2M2Mc entries in the SHIFT table.The SHIFT table is constructed in timeO(M)because each substring of size B of any pattern is considered once and it takes constant time on the average to consider it.We divide the scanning time into two cases.Thefirst case if when the SHIFT valueis non-zero;in this case a shift is applied and no more work needs to be done at that position in the text. The second,and more complicated,case is when the SHIFT value is0;in this case we need to read more of the pattern and the text and consult the HASH table.Lemma1:The probability that a random string of size B leads to a shift value of i,0i m B+1,is1/2m.Proof:At most P=M/m strings lead to a SHIFT value of i for0i m B+1.But the number of allpossible strings of size B is at least2M.So the probability of one random string to lead to a SHIFT value of i is1/2m.Notice that this is true for SHIFT value0as well.Lemma1implies that the expected value of a shift is m/2.Since it takes O(B)to compute onehash function,the total amount of work in the cases of non-zero shifts is O(BN/m).The extrafiltering by the prefixes makes the probability of false hits extremely small.More precisely,let’s assume that B=B. The probability that a given pattern has the same prefix and suffix as another pattern is<1/M,which is insignificant.Therefore,the amount of work for the case of shift value0is also O(B)unless there is actu-ally a match(in which case we need to check the whole pattern taking time O(m)).Since shift value0 occurs<1/2m of the time(by lemma1),the expected total amount for this step is also O(BN/m).4.ExperimentsIn this section we present several experiments comparing our algorithm to existing algorithms and evaluat-ing the effects of the number and size of patterns on the performance.Unless the patterns are very small or there are very few of them,our algorithm is significantly faster.All experiments were conducted on a Sun SparcStation10model510,running Solaris.All times are elapsed times(on a lightly loaded system get-ting more than90%of the CPU)given in seconds;each experiment was performed10times and the aver-ages are given(the deviations were very small).The textfile we used for all experiments was a collection of articles from the Wall Street Journal totaling15.8MB.The patterns were words from thefile(all pat-terns appeared in the text).Table1compares our algorithm,labeled agrep,against four other search routines:the original egrep and fgrep,GNU-grep version2.0[Ha93],and gre,an older program written by Andrew Hume(which at the time was the only program that could handle large number of patterns).The patterns were words of sizes ranging from5to15with average size slightly above6.The original egrep and fgrep could not han-dle(or took too long for)more than few hundreds patterns.In the second experiment,we measured the running times of agrep for different number of patterns ranging from1000to10,000.The running time is indeed improved once the number of patterns exceeds about8,000.The reason for that is very simple;it is related more to the way greps work rather than to the specific algorithm.Agrep(and every other grep)outputs the lines that match the query.Once it is esta-blished that a line should be output,there is no need to search further in that line.Above8,000,the number of patterns becomes so large,most lines are matched and matched early on.So less work is needed to match the rest of the lines.We present this as an example of misleading performance measures;we prob-ably would not have thought about this effect if the numbers had not actually gone down.#of patternsegrep fgrep GNU-grep gre agrep 106.5413.57 2.83 5.66 2.22508.2212.95 5.639.67 2.9310016.6913.27 6.6911.88 3.3120042.6213.518.1214.38 3.871000--12.1823.14 5.792000--15.8028.367.445000--21.8238.0911.61Table 1:A comparison of different search routines on a 15.8MB text.024681012140200040006000800010000S e c o n d s Number of Paterns Running time Figure 2:A comparison of running times for different number of patterns.In the third experiment,we measured the effect of the sizes of the minimum pattern (denoted by m in the discussion on the algorithm).The larger m is the more chances of shifting there are,leading to less work.We used 100patterns for each case,with the average size being typically 1more than the minimal size.The graph matches quite well the curve of the function 1/(m c ),where c is a small constant such that m c is the average shift value.We also measured the time used for preprocessing a large set of patterns (by running agrep and GNU-grep on an empty text).The preprocessing for both programs are very fast up to 1000patterns,02468102345678910S e c o n d s Minimum Pattern Size Running timeFigure 3:The effect of the minimum pattern length on the running time.taking on the order of 0.1second (once the patterns are in the cache).For more patterns,GNU-grep becomes slower (because of the added complexity of building tries);for 10,000patterns,agrep takes about 0.17seconds whereas GNU-grep requires about 0.90seconds.5.Additional ApplicationsIn another project,to find all similar files in a large file system [Ma94],we needed a data structure to han-dle the following type of searches.We had a large set of (typically 100,000to 500,000)small records,each identified by a unique integer.The main operation was to retrieve several records (typically 50-100,but sometimes as high as 1000)given their identifiers.The data structure needed to be stored on disk,and the operation above was triggered by the user.Searching for unique keywords is one of the most basic data structure problems and there are many options to handle it;the most common techniques use hashing or tree structures.But since we have to search many keywords at the same time,even with efficient hashing,most of the pages will be fetched anyway.And if the data is fetched from disk anyway,multi-pattern matching provides a very effective and simple solution.We stored the records as we obtained them without sorting them or providing any other structure,putting one record together with its identifier per line.Then we used agrep with the multi-pattern capabilities.The benefits of this approach are 1)no need for any additional space for the data structure,2)no need for preprocessing or organizing the data structure (e.g.,sorting),and 3)more flexible search;for example,the keywords can be any strings,Of course,if thetotal number of pages far exceeds the number of keywords that need to be searched,then other data struc-tures will be better.But for small to medium size applications,this is a surprisingly good solution.We believe that it can be used in a variety of similar situations.Another example is intersection problems.The common method forfinding all common records to twofiles is to sort bothfiles and merge.With this approach,there is no need to sort,and the preprocessing is done only on the smallfile.Another applications is a general‘‘match-and-replace’’utility,called mar.2Each pattern is associ-ated with a replacement pattern.When a pattern is discovered it is replaced in the output by its replace-ment.One subtle detail in the algorithm is that we now must shift by the length of the matched pattern after it is discovered(instead of by1)to avoid overlapping replacements.For example,if‘war’is replaced by‘peace’and‘art’is replaced by‘science’,and we shift by1after seeing‘war’,we will replace‘wart’by ‘peacescience’.(Of course,there is also an option to require that only complete words are replaced.) Since we can support thousands of patterns,mar can be used for wholesale translations(e.g.,from English to American)very fast.References[AC75]Aho,A.V.,and M.J.Corasick,‘‘Efficient string matching:an aid to bibliographic search,’’Communications of the ACM18(June1975),pp.333340.[AG+90]Altschul S.F.,W.Gish,ler,E.W.Myers,and D.J.Lipman,‘‘Basic local alignment search tool,’’J.Molecular Biology15(1990),pp.403410.[Ba89]Baeza-Yates R.A.,‘‘Improved string searching,’’Software—Practice and Experience19 (1989),pp.257271.[BM77]Boyer R.S.,and J.S.Moore,‘‘A fast string searching algorithm,’’Communications of the ACM20(October1977),pp.762772.[CW79]Commentz-Walter,B,‘‘A string matching algorithm fast on the average,’’Proc.6th Interna-tional Colloquium on Automata,Languages,and Programming(1979),pp.118132.[Ha93]Haertel,M.,‘‘Gnugrep-2.0,’’Usenet archive comp.sources.reviewed,Volume3(July,1993). [Ho80]Horspool,N.,‘‘Practical Fast Searching in Strings,’’Software—Practice and Experience,10 (1980).[Hu91]Hume A.,personal communication(1991).[Ma94]U.Manber,‘‘Finding Similar Files in a Large File System,’’Usenix Winter1994Technical Conference,San Francisco(January1994),pp.110.[MW94]U.Manber and S.Wu,‘‘GLIMPSE:A Tool to Search Through Entire File Systems,’’Usenix Winter1994Technical Conference,San Francisco(January1994),pp.2332.2We expect to make mar available by anonymous ftp in a few weeks.11[WM92a]Wu S.,and U.Manber,‘‘Agrep—A Fast Approximate Pattern-Matching Tool,’’Usenix Winter1992Technical Conference,San Francisco(January1992),pp.153162.[WM92b]Wu S.,and U.Manber,‘‘Fast Text Searching Allowing Errors,’’Communications of the ACM 35(October1992),pp.8391.。