计量经济学小组作业
计量经济学作业

计量经济学作业7.下列为一个完备的联立方程计量经济学模型:011210132t t t t t t t t t Y M C I M Y P ββγγμααγμ=++++=+++其中,M 为货币供给量,Y 为国生产总值,P 为价格总指数。
,C I 分别为居民消费与投资。
(1) 指出模型的生变量、外生变量、先决变量;(2) 写出简化式模型,并导出结构式参数与简化式参数之间的关系; (3) 用结构式条件确定模型的识别状态; (4) 指出间接最小二乘法、工具变量法、二阶段最小二乘法中哪些可用于原模型第1,2个方程的参数估计。
解:(1) 生变量:t Y 、t M外生变量:t I 、t C 、t P 先决变量:t I 、t C 、t P (2) 简化式模型:101112131202122232=++++=++++t t t t t t t t t t Y C I P M C I P ππππεππππε结构式参数与简化式参数之间的关系:001131210111213111111111111βαββγγγππππαβαβαβαβ+====----0103111220212223111111111111ααβγαγαγππππαβαβαβαβ+====----(3) 模型中包含g =2个生变量,k =3个先决变量;第1个方程包含1g =2个生变量,1k =2个先决变量; 第2个方程包含2g =2个生变量,2k =1个先决变量;结构参数矩阵为101210310100B ββγγααγ----⎛⎫Γ= ⎪---⎝⎭首先判断第1个结构方程的识别状态。
对于第1个方程,有()003B γΓ=-,()0011R B g Γ==-,即方程可以识别,又因为111k k g -=-,所以第1个结构方程恰好识别。
对于第2个结构方程,有()0012B γγΓ=--,()0011R B g Γ==-,即方程可以识别,又因为221k k g ->-,所以第2个结构方程过度识别。
计量经济学小组作业
一、理论依据回归分析是在对线性分析模型提出若干假设的条件下,应用普通最小二乘法得到了无偏的、有效的参数估计量。
但是,在实际的计量经济学问题中,完全满足这些基本假设的情况并不多见。
如果违背了某一项基本假设,那么应用最小二乘法估计模型就不能得到无偏的、有效的参数估计量,OLS法失效,这就需要发展新的方法估计模型.二、建立建立GDP的CD生产函数模型1984—2014年GDP、就业人数、资本形成总额统计表(数据来源于国家统计年鉴)利用EViews软件估计结果得:LnYˆ=—4,3705+0。
5841lnL+0。
8851lnKt = (—1.4306)(2。
0309)(33.7808)R2=0.9991 R2=0。
9990 F=6995.2170 DW=1.7909即:在资本投入保持不变的条件下,劳动投入每增加1%,产出将平均增加0。
5841%在劳动投入保持不变的条件下,资本投入每增加1%,产出将平均增加0。
8511%。
三、自相关性自相关性的检验由残差图估计得残差et呈线性回归,表明随机项ut存在。
DW检验:DW=0.56918给定显著性水平α=0.05 n=31 k=2查表得得下限临界值d L=1.36和上限临界值d U=1。
50由W=0.56918<d L=1。
36,这时随机误差项存在一阶正自相关。
回归检验法建立残差项e t与e t—1、e t—2的回归模型.由结果可得随机误差项存在一阶自相关。
相关图和Q统计量检验明显可得我国gdp模型存在着一阶自相关性各阶滞后的Q统计量的p值都小于0.05说明在5%的显著性水平下,拒绝原假设,残差序列存在自相关。
自相关性的修正迭代估计法在命令窗口中键入“LS lnGDP C lnLlnK AR(1) AR(2)”得到表3。
2.1回归结果。
键入文本由上图得DW=1.790932 n=29 k=2 α=0.05查表得d L=1.34,d U=1。
48<DW=1。
790932<4—d U=2。
计量经济学作业HW2

Homework2for Econometrics(due April10,2013)Spring2013Instructor:Jihai YuTA:Kunyuan Qiao1.The data in WAGE2.RAW on working men was used to estimate the following equation:d educ=10:36 0:094sibs+0:131meduc+0:210feducn=722;R2=0:214where educ is years of schooling,sibs is number of siblings,meduc is mother’s years of schooling,and feduc is father’s years of schooling.(i)Does sibs have the expected e¤ect?Explain.Holding meduc and feduc…xed,by how much does sibs have to increase to reduce predicted years of education by one year?(A noninteger answer is acceptable here.) (ii)Discuss the interpretation of the coe¢cient on meduc.(iii)Suppose that Man A has no siblings,and his mother and father each have12years of education.Man B has no siblings,and his mother and father each have16years of education.What is the predicted di¤erence in years of education between B and A?2.In a study relating college grade point average to time spent in various activities,you distribute a survey to several students.The students are asked how many hours they spend each week in four activities:studying, sleeping,working,and leisure.Any activity is put into one of the four categories,so that for each student, the sum of hours in the four activities must be168.(i)In the modelGP A= 0+ 1study+ 2sleep+ 3work+ 4leisure+u;does it make sense to hold sleep,work,and leisure…xed,while changing study?(ii)Explain why this model violates Assumption MLR.3.(iii)How could you reformulate the model so that its parameters have a useful interpretation and it satis…es Assumption MLR.3?3.The following equation describes the median housing price in a community in terms of amount of pollution (nox for nitrous oxide)and the average number of rooms in houses in the community(rooms):log(price)= 0+ 1log(nox)+ 2rooms+u:(i)What are the probable signs of 1and 2?What is the interpretation of 1?Explain.(ii)Why might nox[or more precisely,log(nox)]and rooms be negatively correlated?If this is the case,does the simple regression of log(price)on log(nox)produce an upward or a downward biased estimator of 1? (iii)Using the data in HPRICE2.RAW,the following equations were estimated:\log(price)=11:71 1:043log(nox);n=506;R2=0:264\log(price)=9:23 0:718log(nox)+0:306rooms;n=506;R2=0:514:Is the relationship between the simple and multiple regression estimates of the elasticity of price with respect to nox what you would have predicted,given your answer in part(ii)?Does this mean that 0:718is de…nitely closer to the true elasticity than 1:043?4.(i)Consider the simple regression model y01x u under the…rst four Gauss-Markov assumptions.For some function g(x),for example g(x)=x2or g(x)=log(1+x2),de…ne z i=g(x i).De…ne a slope estimator as~ 1=P n i=1(z i z)y i P n i=1(z i z)x iShow that~ 1is linear and unbiased.Remember,because E(u j x)=0,you can treat both x i and z i as nonrandom in your derivation.(ii)Add the homoskedasticity assumption,MLR.5.Show thatV ar(~ 1)= 2P n i=1(z i z)2(P i=1(z i z)x i)2(iii)Show directly that,under the Gauss-Markov assumptions,V ar(^ 1) V ar(~ 1),where^ 1is the OLS estimator.[Hint:The Cauchy-Schwartz inequality implies that1n P n i=1(z i z)(x i x) 2 1n P n i=1(z i z)2 1n P n i=1(x i x)2notice that we can drop x from the sample covariance.]5.A problem of interest to health o¢cials(and others)is to determine the e¤ects of smoking during pregnancy on infant health.One measure of infant health is birth weight;a birth weight that is too low can put an infant at risk for contracting various illnesses.Since factors other than cigarette smoking that a¤ect birth weight are likely to be correlated with smoking,we should take those factors into account.Forexample,higher income generally results in access to better prenatal care,as well as better nutrition for the mother.An equation that recognizes this isbwght= 0+ 1cigs+ 2faminc+u(i)What is the most likely sign for 2?(ii)Do you think cigs and faminc are likely to be correlated?Explain why the correlation might be positive or negative.(iii)Now,estimate the equation with and without faminc,using the data in BWGHT.DTA.Report the results in equation form,including the sample size and R-squared.Discuss your results,focusing on whether adding faminc substantially changes the estimated e¤ect of cigs on bwght.e the data set in WAGE2.DTA for this problem.As usual,be sure all of the following regressions contain an intercept.(i)Run a simple regression of IQ on educ to obtain the slope coe¢cient,say,~ 1.(ii)Run the simple regression of log(wage)on educ,and obtain the slope coe¢cient,~ 1.(iii)Run the multiple regression of log(wage)on educ and IQ,and obtain the slope coe¢cients,^ 1and^ 2, respectively.(iv)Verify that~ 1=^ 1+^ 2~ 1.。
计量经济学作业 第四小组

计量经济学小组作业论文题目:浙江省三次产业对该地区生产总值的影响组别:第四组组员姓名:杨纯妮P100210129张远平P100210130张滕P100210133黄晨晖P100210134何丽芳P100210135吴垠P100210136分析浙江省三大产业对浙江省经济增长的影响摘要:地区生产总值是衡量一个地区经济增长的重要的指标,它是一个国家或者地区在一定时期内生产的所有的商品或劳务的增加量的总和。
三大产业是地区生产总值的重要组成部分,用生产法通过三大产业的增加值可以计算地区生产总值。
本次作业就是要通过三大产业分析其对地区生产总值的影响。
浙江省是我国沿海地区经济发达的省份,其三次产业结构分布比较合理,研究其经济结构有助于实现研究的目的,这是本次作业选为研究对象的原因,并且对于地区经济增长有重要的意义。
关键字:地区生产总值三大产业影响产业结构引言:地区生产总值的计算方法有生产法、分配法、使用法三种方法。
本次作业就是要运用生产法的原理来验证三大产业对地区生产总值的影响。
生产法的原理是:地区生产总值=∑(各产业的总产出-改产业的中间消耗)(公式一)=∑各个产业的增加值=∑(第一产业的增加值+第二产业的增加值+第三产业的增加值)=∑(第一产业的生产总值+第二产业的生产总值+地三产业的生产总值)(公式二)运用生产法知道了三次产业与地区生产总值之间的关系,我们就可以对它们进行相关的分析。
但是它们之间的关系的相关性如何?他们之间的回归线性方程会是怎样的呢?通过下面的过程我们就可以推算出该回归线性方程。
一.进行模型的建立。
通过对浙江省1978年到2010年的数据的观察和分析,我们进行了以下假设:Y=c+β1X1+β2X2+β3X3 (方程一)其中:Y代表地区生产总值c 代表常数项β1代表第一产业的相关系数β2代表第二产业的相关系数β3代表第三产业的相关系数X1代表第一产业的地区生产总值X2代表第二产业的地区生产总值X3代表第三产业的地区生产总值因为地区生产总值=第一产业生产总值+第二产业生产总值+第三产业生产总值,所以通过求三大产业各自的系数来达到此次作业的目的。
计量经济学作业,DOC

计量经济学作业第二章为了初步分析城镇居民家庭平均每百户计算机用户有量(Y)与城镇居民平均每人全年家庭总收入(X)的关系,可以作以X为横坐所估计的参数,总收入每增加1元,平均说来城镇居民每百户计算机拥有量将增加0.002873台,这与预期的经济意义相符。
拟合优度和统计检验拟合优度的度量:本例中可决系数为0.8320,说明所建模型整体上对样本数据拟合较好,即解释变量“各地区城镇居民家庭人均总收入”对被解释变量“各地区城镇居民每百户计算机拥有量”的绝大部分差异做出了解释。
对回归系数的t检验:针对和,估计的回归系数的标准误差和t值分别为:,;的标准误差和t值分别为:,。
因为,绝;因,所以应拒绝。
城镇居民人均总收入对城镇居民每百取,平均置信度已经得到、、、n=31,可计算出。
当时,将相关数据代入计算得到83.7846 3.1627,即是说当地区城镇居民人均总收入达到25000元时,城镇居民每百户计算机拥有量平均值置信度95%的预测区间为(80.6219,86.9473)台。
个别置信度95%的预测区间为当时,将相关数据代入计算得到83.784616.7190是说,当地区城镇居民人均总收入达到元时,城镇居民每百户计算机拥有量化,选择“教育支出在地方财政支出中的比重”作为其代表。
探索将模型设定为线性回归模型形式:根据图中的数据,模型估计的结果写为(935.8816)(0.0018)(0.0080)(0.0517)(9.0867)(470.3214)t=(-2.5820)(6.3167)(4.9643)(2.8267)(2.5109)(1.8422)=0.9732F=181.7539n=31模型检验1.经济意义检验模型估计结果说明,在嘉定齐天然变量不变的情况下,地区生产12中数据可以得到:=0.9732可决系数为=0.9679:,性水平,在分布表中查出自由度为k-1=5何n-k=25界值.由表3.4得到F=181.7539,由于F=181.7539>,应拒绝原假设:,说明回归方程显著,即“地区生产总值”,“年末人口数”,“居民平均每人教育现金消费”,“居民教育消费价格指数”,“教育支出在地方财政支出中的比重”等变量联合起来确实对“地方财政教育支出”有显著影响。
计量经济学课程作业
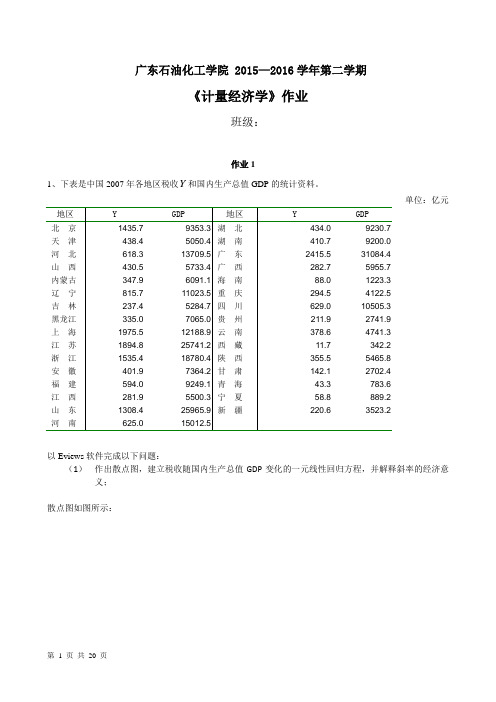
广东石油化工学院 2015—2016学年第二学期《计量经济学》作业班级:作业11、下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:亿元以Eviews软件完成以下问题:(1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;散点图如图所示:建立如下的回归模型根据Eviews软件对表中数据进行回归分析的计算结果知:R^2 = 0.760315 F=91.99198斜率的经济意义:国内生产总值GDP每增加1亿元,国内税收增加0.071亿元。
(2)对所建立的方程进行检验;从回归估计的结果看,模型拟合较好。
可决系数R2=0.760315,表明国内税收变化的76.03%可由国内生产总值GDP的变化来解释。
从斜率项的t检验值看,大于10%显著性水平下自由度为n-2=29的临界值t0.05(29)=1.699,且该斜率值满足0<0.071<1,符合经济理论中税收乘数在0与1之间的说法,表明2007年,国内生产总值GDP每增加1亿元,国内税收增加0.071亿元。
(3)若2008年某地区国内生产总值为8500亿元,求该地区税收收入的预测值和预测区间。
由上图可得知该地区国内生产总值的预测值:Y i= -10.63+0.071*8500=592.87(亿元)下面给出国内生产总值90%置信度的预测区间E(GDP)=8891.126Var(GDP)=57823127.64在90%的置信度下,某地区E(Y0)的预测区间为(60.3,1125.5)。
2、已知某市货物运输总量Y(万吨),国内生产总值GDP(亿元,1980不变价)1985年-1998年的样本观测值见下表。
年份Y GDP 年份Y GDP1985 18249 161.69 1992 17522 246.921986 18525 171.07 1993 21640 276.81987 18400 184.07 1994 23783 316.381988 16693 194.75 1995 24040 363.521989 15543 197.86 1996 24133 415.511990 15929 208.55 1997 25090 465.781991 18308 221.06 1998 24505 509.1资料来源:《天津统计年鉴》,1999年。
计量经济学作业实验四、五(1)
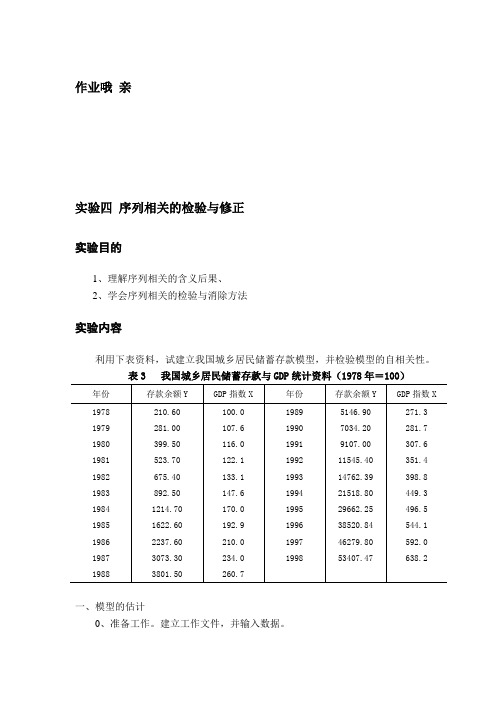
作业哦亲实验四序列相关的检验与修正实验目的1、理解序列相关的含义后果、2、学会序列相关的检验与消除方法实验内容利用下表资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。
表3 我国城乡居民储蓄存款与GDP统计资料(1978年=100)一、模型的估计0、准备工作。
建立工作文件,并输入数据。
1、相关图分析 SCAT X Y相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。
现将函数初步设定为线性、双对数等不同形式,进而加以比较分析。
2、估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C Xx y5075.9284.14984ˆ+-= =t (-6.706) (13.862)2R =0.9100 F =192.145 S.E =5030.809⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNXx yln 9588.20753.8ˆln +-= =t (-31.604) (64.189)2R =0.9954 F =4120.223 S.E =0.12213、选择模型比较以上模型,可见各模型回归系数的符号及数值较为合理。
各解释变量及常数项都通过了t 检验,模型都较为显著。
比较各模型的残差分布表。
线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这种函数形式设置是不当的。
而且,这个模型的拟合优度也较双对数模型低,所以又可舍弃线性模型。
双对数模型具有很高的拟合优度,因而初步选定回归模型为双对数回归模型。
二、模型自相关的检验1.图示法其一,残差序列e t 的变动趋势图。
菜单:Quick→Graph→line ,在对话框中输入resid ;或者用命令操作,直接在命令行输入:line X 。
其二,作e t-1和e t 之间的散点图。
菜单:Quick→Graph→Scatter ,在对话框中输入resid(-1) resid ;或者用命令操作,直接在命令行输入:scat resid(-1) resid 。
第五次计量经济学小组作业

6.11
a.
应用Eviews对模型进行回归,得到结果如下:
则估计的回归方程为:
b.
B1为截距项,表示第一季度的平均销量。
B2、B3、B4均为差别截距系数,其中
B2表示在其他条件不变的情况下,第二季度和其他季度销量平均相差58.6667百万美元;
B3表示在其他条件不变的情况下,第三季度和其他季度销量平均相差57.6090百万美元;
B4表示在其他条件不变的情况下,第四季度和其他季度销量平均相差1338.109百万美元。
c.
由于圣诞节在第四季度,圣诞节期间人们对饰品、玩具和游戏的需求要高于其他季度,因此第四季度饰品、玩具和游戏的销售量要明显多于其他季度。
前三季度中,无重大节日庆典,人们对饰品、玩具和游戏的需求较前三季度中的其他季度相比,无太大差异。
d.
应用实际的销量减去模型估计出的销量值再加上销量值的均值得到的结果即为消除季节影响的序列。
6.12
应用Eviews对模型进行回归,得到结果如下:
则估计的回归方程为:
a.
此模型较上模型多一定性变量,且无截距项。
b.
需要略去截距项。
在此模型形式中,无截距项,因此要忽略截距项,即做过原点回归。
c.
选用6.11中的模型。
在第一次估计中,得到的截距项在统计上显著非零,不能忽略;且在本次回归中,每增加一个定性变量都要损失一个单位的自由度,在本问题中,共有四个季节,因此能够采用的最多定性变量为n-4,即3个。
因此应选用6.11中估计出的回归模型,即在此问题中,不能选用过原点的回归模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、理论依据回归分析是在对线性分析模型提出若干假设的条件下,应用普通最小二乘法得到了无偏的、有效的参数估计量。
但是,在实际的计量经济学问题中,完全满足这些基本假设的情况并不多见。
如果违背了某一项基本假设,那么应用最小二乘法估计模型就不能得到无偏的、有效的参数估计量,OLS法失效,这就需要发展新的方法估计模型。
二、建立建立GDP的CD生产函数模型1984-2014年GDP、就业人数、资本形成总额统计表(数据来源于国家统计年鉴)利用EViews软件估计结果得:LnYˆ=-4,3705+0.5841lnL+0.8851lnKt = (-1.4306)(2.0309)(33.7808)R2=0.9991 R2=0.9990 F=6995.2170 DW=1.7909即:在资本投入保持不变的条件下,劳动投入每增加1%,产出将平均增加0.5841%在劳动投入保持不变的条件下,资本投入每增加1%,产出将平均增加0.8511%.三、自相关性自相关性的检验由残差图估计得残差et呈线性回归,表明随机项ut存在。
DW检验:DW=0.56918给定显著性水平α=0.05 n=31k=2查表得得下限临界值d L=1.36和上限临界值d U=1.50由W=0.56918<d L=1.36,这时随机误差项存在一阶正自相关。
回归检验法建立残差项e t与e t-1、e t-2的回归模型。
由结果可得随机误差项存在一阶自相关。
相关图和Q统计量检验明显可得我国gdp模型存在着一阶自相关性各阶滞后的Q统计量的p值都小于0.05说明在5%的显著性水平下,拒绝原假设,残差序列存在自相关。
自相关性的修正迭代估计法在命令窗口中键入“LS lnGDP C lnLlnK AR(1) AR(2)”得到表3.2.1回归结果。
键入文本由上图得DW=1.790932n=29k=2α=0.05查表得d L=1.34,d U=1.48<DW=1.790932<4-d U=2.52 所以模型已不存在自相关。
此时,回归方程为:LnYˆ=-4,3705+0.5841lnL+0.8851lnKt = (-1.4306)(2.0309)(33.7808)R2=0.9991 R2=0.9990 F=6995.2170 DW=1.7909四、异方差性异方差性的检验图示法假设国内生产总值的差别主要来源于就业人数,所以是L引起了异方差性。
模型得到的残差平方与lnL、lnK的散点图表明存在复杂的异方差性。
图4.1.1 异方差性检验图德菲尔德—匡特检验将原始数据按lnL排成升序,去掉中间7个数据,得到两个容量为12的子样,对两个子样分别做OLS回归,求各自残差平方和和。
求得=0.003751,=0.023462。
计算出F=/=0.023462/0.003751=6.2549,取α=0.05时,查F分布表得(9,9)=3.18,而F=6.2549>(9,9)=3.18,所以存在递增的异方差性。
4.1.3 戈里瑟和帕克检验4.1.3.1 戈里瑟检验利用Eviews进行戈里瑟检验。
生成序列,再分别建立与这些序列的回归方程。
由上述各回归结果可知,的回归模型中解释变量的系数估计值显著不为0且均能通过显著性检验。
所以认为存在异方差性。
4.1.4 ARCH检验样本资料是时间序列数据,所以继续用ARCH方法检验异方差。
利用Eviews软件得到ARCH检验结果如表4.1.4所示。
表4.1.4 ARCH检验结果取显著水平α=0.05,LM(p)=(n-p)=4.96236>(p)=(1)=3.841,则拒绝,表明模型中存在异方差性,即存在异方差效应。
异方差性的修正加权最小二乘法下面采用加权最小二乘法对原模型进行回归。
取L的倒数1/L为权数进行加权最小二乘法,回归结果如表4.2.1所示。
表4.2.1 加权最小二乘法估计结果表4.2.2 WLS估计模型后的怀特检验结果Ln=-4.9591+0.6289lnL+0.8928lnKt =(-2.8086) (3.5882) (46.1733)=0.9982, DW=0.6687, F=7935.028为了分析异方差性的校正情况,利用WLS估计出每个模型之后,还需要利用怀特检验再次判断模型是否存在着异方差性,检验结果如表3.2.2所示。
给定显著水平α=0.05,由于=6.602925<(5)=11.07,所以加权最小二乘法回归结果不存在异方差性。
由p=0.2519可知,亦不存在异方差。
回归结果表明,中国国内生产总值与就业人数、资本形成总额正相关。
就业人数的对数每增长1万人,国内生产总值的对数将增长0.6289亿元;资本形成总额的对数每增长1亿元,国内生产总值的对数将增长0.8928亿元。
五、多重共线性的检验与修正5.1多重共线性的检验5.1.1相关系数检验表5.1.1 相关系数矩阵如上表所示,解释变量间的相关系数r>0.9,认为lnl与lnk之间高度相关。
5.1.2辅助回归模型检验首先建立解释变量的辅助回归模型,结果如下:Lnk=-90.15836+9.038250lnlt=(-10.16917) (11.34073)R2=0.816004 =0.809659 DW=0.216612 F=128.6122Lnl=10.18539+0.090273lnkt=(122.165) (11.3473)R2=0.816004 =0.809659 DW=0.249538 F=128.6122从以上辅助回归模型的R2、F统计量的数值可以看出,解释变量lnk、lnl之间存在严重的多重共线性。
5.1.3方差膨胀因子检验从以上辅助回归模型可知,VIF1=VIF25.4349>5,可以认为模型存在较严重的多重共线性。
5.2多重共线性的修正----逐步回归法分别做lnY对lnk,lnl的一元回归,结果如下表所示:表5.2.1一元回归结果(被解释变量为lny)从上表的回归结果可知,lnk,lnl对lny均由显著性影响。
但lnk的影响更显著。
利用EViews软件,分别进行有进有出回归和单项回归,其回归结果相同,如下表所示:表5.2.2有进有出逐步回归结果表5.2.3单项逐步回归结果因此得到修正后的回归方程为:Lny=-5.731598+0.886599lnk+0.704186lnlt =(-3.024193) (47.72504) (3.788089)=0.9982, DW=0.6687, F=7935.028六、结论在经过检验与修正,认为已经消除回归模型的自相关性、多重共线性以及异方差性,修正后的模型可用CD生产函数进行分析,以CD生产函数为理论基础,结合多元线性回归模型的知识,实证分析资本和劳动对我国总产出的影响,并分析我国属于资本密集型还是劳动密集型。
从修正后的模型可以看出,我国资本形成总额每增加1%,GDP上涨0.886599%;就业人数没上涨1%,GDP 上涨0.74186%。
如果将两个弹性系数相加,我们得到一个重要的经济参数——规模报酬,它反映了产出对要素投入的比例变动。
如果两个弹性系数之和为1,则称规模报酬不变;如果两个弹性系数之和大于1则称规模报酬递增;如果两个弹性系数之和小于1,则称规模报酬递减。
在本案例中,两个弹性系数之和为1.590785,表明中国经济的特征是规模报酬递增的。
七.中国经济规模报酬递增的影响因素分析7.1专业化程度分工一直被认为是引致报酬递增的首要因素。
中国经济多年的高速增长,首先在于渐进式改革解除了对分工与交易发展的束缚。
随着技术的进步,生产过程越来越细分,产品以及生产工艺专业化都有了突破式发展,企业内部和企业间的迂回生产方式和产品多样化程度加深,最终使得分工链条加长和专业化程度加深并带来产品生产效率的提高;另一方面,随着分工的深化,地区间、行业间的分工和交易障碍进一步被打破,特别是各地区、行业间市场分割和贸易封锁的瓦解,通过比较优势在产业和地区间实现了合理分工,专业化分工使各经济主体的活动集中在自己的核心优势上做大做强,分工的网络效应凸显。
可以说,地区行业的专业化是生产专业化的表现形式,也是劳动地域分工不断深化的结果,会引致报酬递增7.2技术创新熊彼特认为,经济发展的核心不是均衡,报酬递增就产生于创新过程中的“产业突变”和“创造性破坏”。
技术创新,特别是知识性因素具有溢出效应,这是影响报酬递增的直接因素。
在中国多年经济发展的微观层面上,随着现代企业制度普遍建立,以市场为导向的企业技术创新动力和能力越来越强。
企业的发展更多地依靠技术创新和知识管理,生产经营活动明显转向高技能、高技术的领域;企业为了自身长期的发展必然会依靠高新技术以及不断革新的技术确保自己获得市场优势,从而在企业内部形成报酬递增。
在宏观层面上,首先,不断创造的新技术、新工艺使原有的技术装备和工艺水平不断提高,导致原有固定资产结构的优化,促使产业结构升级;其次,技术创新成果的扩散引导投资结构向更合理的方向发展;再次,技术创新的良好收益引导资金从效益差、成长性弱的产业转向效益好、成长性强的产业,使各种资源配置趋向合理。
除此之外,近年来中国对知识产权保护的水平越来高,技术创新的动力机制日益形成,使得技术创新成为形成报酬递增最为直接的因素。
7.3政府政策在中国,政府长期扮演的是经济增长推动者和改革开放推动者的双重角色,形成了政府主导的典型“中国式”发展模式,转轨时期中国经济主要特色之一是诸多经济发展机制与政府政策相关。
同样,公共部门服务或政府政策与报酬递增息息相关。
政府支持政策对报酬递增影响的途径主要有二:一是政府政策能够为企业提供生产性服务,政府对高技术产业等的投入加大会提高此类部门的生产率,同时政府政策具有导向作用,会引导社会和私人资本迅速流入,使报酬递增成为可能;二是政府财政支出如教育支出、科学研究开发支出也会对各产业乃至整个经济的发展有积极的正向作用,为报酬递增提供良好的外在环境。
7.4市场结构在劳动分工方面,自从斯密定理提出后,关于市场结构与报酬递增的难题一直困扰着新古典主流经济学家。
一般来说,企业进行创新的目的在于获得创新利润,而在完全竞争市场上,完全的信息会迅速使技术创新扩散到所有的企业,对创新企业而言,创新投入的巨大成本并不能得到应有的回报,因此必将缺乏创新动力,所以需要一定程度的垄断和知识产权的保护来使得报酬递增持续下去。
八.政策建议长期以来,中国经济呈现出粗放型增长的特点,主要表现为增长由大量资本、能源和原材料以及劳动力投入推动,而技术进步对经济增长的贡献比较低。
中国在未来十年或者更长的时间要保持经济的持续强劲增长,从要素投入型增长转向效率提高型增长是关键,即中国经济增长的驱动机制应完全转向报酬递增的内生驱动机制。