计量经济学作业,DOC
计量经济学作业

计量经济学作业7.下列为一个完备的联立方程计量经济学模型:011210132t t t t t t t t t Y M C I M Y P ββγγμααγμ=++++=+++其中,M 为货币供给量,Y 为国生产总值,P 为价格总指数。
,C I 分别为居民消费与投资。
(1) 指出模型的生变量、外生变量、先决变量;(2) 写出简化式模型,并导出结构式参数与简化式参数之间的关系; (3) 用结构式条件确定模型的识别状态; (4) 指出间接最小二乘法、工具变量法、二阶段最小二乘法中哪些可用于原模型第1,2个方程的参数估计。
解:(1) 生变量:t Y 、t M外生变量:t I 、t C 、t P 先决变量:t I 、t C 、t P (2) 简化式模型:101112131202122232=++++=++++t t t t t t t t t t Y C I P M C I P ππππεππππε结构式参数与简化式参数之间的关系:001131210111213111111111111βαββγγγππππαβαβαβαβ+====----0103111220212223111111111111ααβγαγαγππππαβαβαβαβ+====----(3) 模型中包含g =2个生变量,k =3个先决变量;第1个方程包含1g =2个生变量,1k =2个先决变量; 第2个方程包含2g =2个生变量,2k =1个先决变量;结构参数矩阵为101210310100B ββγγααγ----⎛⎫Γ= ⎪---⎝⎭首先判断第1个结构方程的识别状态。
对于第1个方程,有()003B γΓ=-,()0011R B g Γ==-,即方程可以识别,又因为111k k g -=-,所以第1个结构方程恰好识别。
对于第2个结构方程,有()0012B γγΓ=--,()0011R B g Γ==-,即方程可以识别,又因为221k k g ->-,所以第2个结构方程过度识别。
计量经济学作业

计量经济学作业计量经济学作业(5-7)一、作业五1. 在存在异方差情况下,普通最小二乘法(OLS )估计量是有偏的和无效的。
()2. 当存在自相关时,OLS 估计量是有偏的并且也是无效的。
()3. 如果在多元回归模型中,根据通常的t 检验,全部回归系数分别都是统计上不显著的,那么该模型不会有一个高的R 2值。
()4. 在时间序列模型中,遗漏重要解释变量既有可能导致异方差问题,又有可能导致自相关问题。
()5. 变量是非线性的回归模型在计量经济学上不被称作线性回归模型。
()6. 随机误差项μi 与残差e i 是一回事。
()7. 给定显著性水平α及自由度,若计算得到的t 值超过临界的t 值,则接受原假设。
8. 蛛网现象可能会带来计量经济模型的自相关问题。
()9. 无论模型中包括多少个解释变量,总离差平方和(TSS )的自由度总为(n-1)。
()10. 在多元线性回归模型中,方差膨胀因子(VIF )一定是不小于1。
()11. 在存在异方差情况下,常用的OLS 法总是高估了估计量的标准差。
()12. 若假定自相关系数等于1,那么一阶差分变换能够消除自相关。
()13. 存在多重共线时,模型参数无法估计。
()14. 如果在多元回归模型中,根据通常的t 检验,全部回归系数分别都是统计上不显著的,那么该模型不会有一个高的R 2值。
()15. 当我们得到参数区间估计的上下限的具体数值后,就可以说参数的真实值落入这个区间的概率为1-α. ()16. p 值和显著性水平α是一回事。
()17. 只有当μi 服从正态分布时,OLS 估计量才服从正态分布。
()18. 多元回归模型的总体显著性意味着模型中任何一个变量都是统计显著的。
()19. 戈德菲尔德-夸特检验(GQ 检验)可以检验复杂性的异方差。
()20. 残差平方和除以自由度(n-k )始终是随机误差项μi 方差(2σ)的无偏估计量。
()21. 用一阶差分法消除自相关时,我们假定自相关系数等于-1。
最新计量经济学大作业(1)

2010-2011第二学期计量经济学大作业大作业名称:2008年12月我国税收多因素分析组长:学号:00 姓名:专业:财政学成员:学号:00 姓名:专业:财政学学号:00 姓名:专业:财政学选课班级:A01 任课教师:徐晔成绩:评语:__________________________________________________ 教师签名:批阅日期:计量经济大作业要求如下:目的要求:1.熟练掌握计量经济学的主要理论与方法;2.能够理论联系实际;3.能够运用计量经济学软件Eviews进行计算和分析;4.要求:word文档格式,内容四千字左右,并附数据。
内容:1.确立问题:选择一个经济预测问题或经济分析问题,根据一定的经济理论和实际经验分析所涉及的经济领域或经济系统中某一经济变量与其它一些(至少二个)经济变量之间的因果关系。
2.建立模型:初步建立其多元线性回归模型,利用软件求解回归方程;进行经济意义检验、统计与经济计量检验,解决可能出现的违反基本假设的问题,最后确定回归方程。
3.提供图表:给出说明该回归方程建立效果较好的必要的图表,如通过被解释变量的观察值曲线与拟合值曲线来比较其拟合效果。
4.实证分析:利用回归方程的结果进行一定的经济预测或经济分析。
江西财经大学信息管理学院计量经济学课程组2011/2/192008年12月我国税收多因素分析【摘要】:本文主要分析税收收入与国民生产总值及进出口的关系,通过数据拟合模型,将几者之间的关系量化。
一、研究背景税收是国家为了实现其职能,按照法定标准,无偿取得财政收入的一种手段,是国家凭借政治权力参与国民收入分配和再分配而形成的一种特定分配关系。
是我们国财政收入的基本因素,也影响着我国经济的发展。
税收收入的影响因素是来自于多方面的,如居民消费水平、城乡储蓄存款年末余额、财政支出总量以及国内生产总值等等。
近年来,我国的税收增长远远快于GDP的增长速度,通过对税收增长的两个影响因素进行分析,从中找出对我国的税收增长影响最大的影响因素。
计量经济学作业1-4

作业一1、双对数模型01ln ln Y X u ββ=++中,参数β1的含义是( )A .X 的相对变化,引起Y 的期望值绝对量变化B .Y 关于X 的边际变化C .X 的绝对量发生一定变动时,引起因变量Y 的相对变化率D .Y 关于X 的弹性2、设OLS 法得到的样本回归直线为12i i i Y X e ββ=++,以下说法不正确的是 ( ) A .0i e =∑ B .(,)X Y 在回归直线上 C .Y Y = D .(,)0i i COV X e ≠3、下列说法正确的有( )A .时序数据和横截面数据没有差异B. 对总体回归模型的显著性检验没有必要C. 总体回归方程与样本回归方程是有区别的D. 判定系数R 2不可以用于衡量拟合优度4、在回归分析中,下列有关解释变量和被解释变量的说法正确的有( )A .被解释变量和解释变量均为随机变量B .被解释变量和解释变量均为非随机变量C .被解释变量为随机变量,解释变量为非随机变量D .被解释变量为非随机变量,解释变量为随机变量5、一元线性回归分析中的回归平方和ESS 的自由度是( )A 、nB 、n-1C 、n-kD 、16、对样本的相关系数γ,以下结论错误的是( )A .γ越接近1,X 与Y 之间线性相关程度高B .γ越接近0,X 与Y 之间线性相关程度高C .01γ≤≤D . X 与Y 相互独立,则γ=0,7、同一时间,不同单位相同指标组成的观测数据称为( )A .原始数据B .横截面数据C .时间序列数据D .修匀数据8、根据样本资料估计得出人均消费支出Y 对人均收入X 的回归模型为ln i Y =2.00+0.75lnXi ,这表明人均收入每增加1%,人均消费支出将增加( )A 、0.2%B 、0.75%C 、2%D 、7.5%9、利用OLS 估计得到的样本回归直线12i i Y X ββ=+ 必然通过点 ( )A 、(,)X YB 、(,0)XC 、(0,)YD 、(0,0)10、多元线性回归分析中的 RSS 反映了( )A .应变量观测值总变差的大小B .应变量回归估计值总变差的大小C .应变量观测值与估计值之间的总变差D .Y 关于X 的边际变化11、将内生变量的前期值作解释变量,这样的变量称为( )A 、虚拟变量B 、控制变量C 、政策变量D 、滞后变量12、回归分析中使用的距离是点到直线的垂直坐标距离。
计量经济学实证练习作业.docx
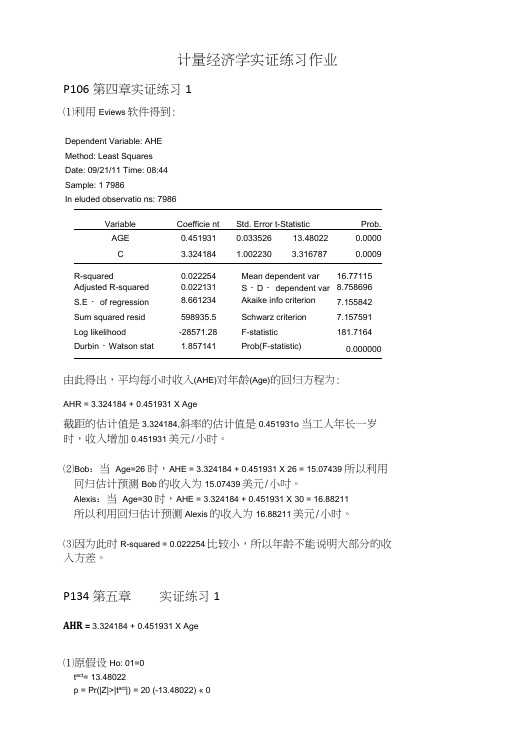
计量经济学实证练习作业P106第四章实证练习1⑴利用Eviews软件得到:Dependent Variable: AHEMethod: Least SquaresDate: 09/21/11 Time: 08:44Sample: 1 7986In eluded observatio ns: 7986Variable Coefficie nt Std. Error t-Statistic Prob.AGE 0.451931 0.033526 13.48022 0.0000C 3.324184 1.002230 3.316787 0.0009R-squared 0.022254 Mean dependent var 16.77115 Adjusted R-squared 0.022131 S・D・ dependent var 8.758696 S.E・ of regression 8.661234 Akaike info criterion 7.155842 Sum squared resid 598935.5 Schwarz criterion 7.157591 Log likelihood -28571.28 F-statistic 181.7164 Durbin・Watson stat 1.857141 Prob(F-statistic) 0.000000由此得出,平均每小时收入(AHE)对年龄(Age)的回归方程为:AHR = 3.324184 + 0.451931 X Age截距的估计值是3.324184,斜率的估计值是0.451931o 当工人年长一岁时,收入增加0.451931美元/小时。
⑵Bob:当Age=26 时,AHE = 3.324184 + 0.451931 X 26 = 15.07439 所以利用冋归估计预测Bob的收入为15.07439美元/小吋。
Alexis:当Age=30 时,AHE = 3.324184 + 0.451931 X 30 = 16.88211所以利用回归估计预测Alexis的收入为16.88211美元/小时。
计量经济学案例分析作业.doc

计量案例分析学院:国际贸易学院班级:贸易经济2班姓名:___________学号:_______2013年12月16日□ Equati on: UNTITLED Workfile: UNTITLED::Untitled、View | Proc | Object | Print〔Name〔Freeze] Estimate | Forecast | Stats | Resids |Dependent Variable: YMethod: Least SquaresDate: 12/21/13 Time: 19:06Sample: 1994 2007Included observations: 14VariableCoefficientStd.Errort-Statistic Prob.C•1471.9561137.046-1.294544 0.2316X2 0.042510.0046139.216082 0.0000X3 4.4324781.0633414.168445 0.0031X4 2.9222731.0936652.6720010.0283X5 1.4267861.4175551.006512 0.3436X6 -354.9821244.8486-1.449802 0.1852R-squared0.997311Mean dependent var3527.783Adjusted R-squared 0.995630 S.D. dependent var 1927.495S.E. of regression 127.4135 Akaike info criterion 12.83028Sum squared resid 129873.5 Schwarz criterion 13.10416Log likelihood -83.81195 Hannan-Quinn criter. 12.80493F-statistic 593.4168 Durbin-Watson stat 1.558415Prob(F-statistic) 0.0000019941997年中国旅游收入及相关数据¥=-1471.96+0.0425X2+4.432X3+2.922X4+1.427X5-354.98X6R2 =0.997 -R=0.996经济意义:说明假定其他变量不变的情况下,各每增加1万人次的国内旅游人数、1元的城镇居民人均旅游花费、1元的农村居民人均旅游花费、1万公里的公路里程和1万公里的铁路里程,国内旅游收入就会相应的增加0. 0425亿元、4. 432亿元、2.922亿元、1.427亿元和减少354. 98亿元。
(完整word版)计量经济学基本点练习题及答案

(完整word版)计量经济学基本点练习题及答案Chap1—31、在同⼀时间不同统计单位的相同统计指标组成的数据组合,是()A、原始数据B、时点数据C、时间序列数据D、截⾯数据2、回归分析中定义的( )A、解释变量和被解释变量都是随机变量B、解释变量为⾮随机变量,被解释变量为随机变量C、解释变量和被解释变量都为⾮随机变量D、解释变量为随机变量,被解释变量为⾮随机变量3、在⼀元线性回归模型中,样本回归⽅程可表⽰为:()4、⽤模型描述现实经济系统的原则是( )A、以理论分析作先导,解释变量应包括所有解释变量B、以理论分析作先导,模型规模⼤⼩要适度C、模型规模越⼤越好;这样更切合实际情况D、模型规模⼤⼩要适度,结构尽可能复杂5、回归分析中使⽤的距离是点到直线的垂直坐标距离。
最⼩⼆乘准则是指()6、设OLS法得到的样本回归直线为A、⼀定不在回归直线上B、⼀定在回归直线上C、不⼀定在回归直线上D、在回归直线上⽅7、下图中“{”所指的距离是A.随机误差项B.残差C.因变量观测值的离差D.因变量估计值的离差8、下⾯哪⼀个必定是错误的9、线性回归模型的OLS估计量是随机变量Y的函数,所以OLS估计量是()。
A.随机变量B.⾮随机变量C.确定性变量D.常量10、为了对回归模型中的参数进⾏假设检验,必须在古典线性回归模型基本假定之外,再增加以下哪⼀个假定:A.解释变量与随机误差项不相关B.随机误差项服从正态分布C.随机误差项的⽅差为常数D.两个误差项之间不相关D B C B D B B C A BChap41、⽤OLS估计总体回归模型,以下说法不正确的是:2、包含有截距项的⼆元线性回归模型中的回归平⽅和ESS的⾃由度是()A、nB、n-2C、n-3D、23、对多元线性回归⽅程的显著性检验,,k代表回归模型中待估参数的个数,所⽤的F统计量可表⽰为:4、已知三元线性回归模型估计的残差平⽅和为800,样本容量为24,则随机误差项的⽅差估计量为( )A 、33.33B 、 40C 、 38.09D 、36.365、在多元回归中,调整后的判定系数与判定系数的关系为6、下⾯哪⼀表述是正确的:A.线性回归模型的零均值假设是指B.对模型进⾏⽅程总体显著性检验(即F 检验),检验的零假设是C.相关系数较⼤意味着两个变量存在较强的因果关系D.当随机误差项的⽅差估计量等于零时,说明被解释变量与解释变量之间为函数关系7、在模型的回归分析结果报告中,有F=263489,p=0.000,则表明()A 、解释变量X1对Y 的影响是显著的B 、解释变量X2对Y 的影响是显著的C 、解释变量X1, X2对的Y 联合影响是显著的D 、解释变量X1, X2对的Y 的影响是均不显著8、关于判定系数,以下说法中错误的是()A 、判定系数是因变量的总变异中能由回归⽅程解释的⽐例;B 、判定系数的取值范围为0到1;C 、判定系数反映了样本回归线对样本观测值拟合优劣程度的⼀种描述;D 、判定系数的⼤⼩不受到回归模型中所包含的解释变量个数的影响。
计量经济学作业

计量经济学作业一.一元线性回归:居民消费模式和消费规模分析研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均*****元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
2002年中国各地区城市居民人均年消费支出和可支配收入数据含义如下:城市居民家庭平均每人每年消费支出(元)Y城市居民人均年可支配收入(元) X根据数据在Eviews初步做出散点图,如上图示:通过观察散点图,可以大致确定变量Y、X之间存在线性关系。
(1).拟建立如下一元线性回归模型:Y= 0+ 1Χ+由Eviews对数据进行分析,得下表一般可写出如下回归分析结果:=282.24+0.759常数C值得标准误差为287.2649,T=0.9825;标准误差为0.0*****,T=20.*****。
2=0.*****;F=421.9023简单统计量:城市居民家庭平均每人每年消费支出平均值是5982.476元,中位数5459.64元,最大值是*****元,最小值4462.08元,标准差1601.762,偏度1.*****,表明序列分布有长长的右拖尾,峰度为4.*****,表明序列分布的突起程度大于正态分布,城市居民家庭平均每人每年消费支出总额为*****.8元,观察数为31。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学作业
第二章
为了初步分析城镇居民家庭平均每百户计算机用户有量(Y)与城镇居民平均每人全年家庭总收入(X)的关系,可以作以X为横坐
所估计的参数,
总收入每增加1元,平均说来城镇居民每百户计算机拥有量将增加0.002873台,这与预期的经济意义相符。
拟合优度和统计检验
拟合优度的度量:本例中可决系数为0.8320,说明所建模型整体上对样本数据拟合较好,即解释变量“各地区城镇居民家庭人均总
收入”对被解释变量“各地区城镇居民每百户计算机拥有量”的绝大部分差异做出了解释。
对回归系数的t检验:针对和,估计的回归系数的标准误差和t值分别为:,;
的标准误差和t值分别为:,。
因为,
绝;因
,所以应拒绝。
城镇居民人均总收入对城镇居民每百
取,平均置信度
已经得到、、、n=31,可计算出。
当时,将相关数据代入计算得到83.7846 3.1627,即是说当地区城镇居民人均总收入达到25000元时,城镇居民每百户计算机拥有量平均值置信度95%的预测区间为(80.6219,86.9473)台。
个别置信度95%的预测区间为
当时,将相关数据代入计算得到83.784616.7190
是说,当地区城镇居民人均总收入达到元时,城镇居民每百户计算机拥有量
化,选择“教育支出在地方财政支出中的比重”作为其代表。
探索将模型设定为线性回归模型形式:
根据图中的数据,模型估计的结果写为
(935.8816)(0.0018)(0.0080)(0.0517)(9.0867)(470.3214)
t=(-2.5820)(6.3167)(4.9643)(2.8267)(2.5109)(1.8422)
=0.9732F=181.7539n=31
模型检验
1.经济意义检验
模型估计结果说明,在嘉定齐天然变量不变的情况下,地区生产1
2
中数据可以得到:=0.9732
可决系数为=0.9679
:,
性水平,在分布表中查出自由度为k-1=5何n-k=25
界值.由表3.4得到F=181.7539,由于F=181.7539>
,应拒绝原假设:,说明回归方程显著,即“地区生产总值”,“年末人口数”,“居民平均每人教育现金消费”,“居民教育消费价格指数”,“教育支出在地方财政支出中的比重”等变量联合起来确实对“地方财政教育支出”有显
著影响。
(3)t检验:分别针对,
给定显著水平,查t分布表得自由度为。
由表中数据可得,除了
以外,与、、、、对应的t统计量分别为
,这说明在显著水平
,也就是说,当在其他解释
()
()()
(
响。
当给定显著性水平时,由于与
,小于,不能拒绝
的显著性水平下,“教育支出在地方财政支出中的比重”
,表明在α
在地方财政支出中的比重”()对“地方财政教育支出”(Y)有显著的影响。
这样的结论从表中的P值也可以判断,与、、、
、估计值对应的P值均小于,表明在的显著
性水平下,对应解释标量对被解释变量影响显著。
与估计值对应的P值为0.0773,小于,表明在的显著性水平下,
“教育支出在地方财政支出中的比重”()对“地方财政教育支出”(Y)的影响是显著的。
利用所估计的地方财政教育支出模型,可以通过某地区相应的“地区生产总值”()、“年末人口数”()、“居民平均每人现金教育消费”()、“居民教育消费价格指数”()、“教育支出在地方财政支出
该模型,可决系数很高,
,不仅
实确实存在一定的多重共线性。
将各变量进行对数变换,再对以下模型进行估计。
利用EViews软件,对、X2、X3、X4、X5分别取对数,分别生
型,
,所有系数估计值高度显著。
对系数估计值的解释如下:在其他变量保持不变的情况下,如果旅游人数每增加1%,则国内旅游收入平均增加0.921%;如果城镇居民旅游支出每增加1%,则国内旅游收入平均增加0.41%;如果农村居民旅游支出每增加1%,则国内旅游收入平均增加0.29%;如果铁路里程每增加1%,则国内旅游收入平均增加1%。
所有解释变量的符号都与先验预期相一致,即旅游人数、城乡居民旅游支出和铁路里程都与国内旅游收入正相关。
在这个例子中,经过数据变换后,尽管解释变量之间高度相关,但相关的统计检验指标,如回归方程检验的F统计量、各回归系数的t统计量都高度显著,且所有系数都具有正确的符号,这表明所有这
残差平方
大致看出残差平方随
趋势。
因此,模型很可能存在异方差。
但是是否确实存在异方差还应
样本区间1~8的回归结果:
样本区间14~21的回归结果:
1.求F统计量值。
基于以上两图中残差平方和的数据,即Sumsquaredresid的值。
由样本区间1~8的回归结果图中得到残差平
方和为=144958.9,由样本区间14~21的回归结果图得到残差平
方和为=734355.8,根据Goldfeld-Quandt检验,F统计量为
2.判断:
在下,上式分子、分母的自由度均为6,查F分布表得临
辅助函数为
经估计出现White检验结果,见下图
,,在
查分布表,得临界值,同时和
也显计算的统计量值
,所以拒绝原假设,不拒绝
上图为加权最小二乘估计结果。
可以看出,运用加权最小二乘法消除了异方差性后,参数的t检验均为显著,F检验也显著,即估计结果为
这说明人口数量每增加1万人,平均说来将增加2.7236个卫生医疗机构,而不是引子中得出的需要增加5.3735个医疗机构。
虽然这个模型可能还存在某些其他需要进一步解决的问题,但这一估计结果或许比引子中的结论更为接近真实情况。
图中显示,
表明存在自相关。
可见,模型中t统计量和F统计量的结论并不可信,
的回归可得残差序列,为估计自相关系数,用进行滞后一期的自回归,在EWiews命令栏中输入“lsee(-1)”可得回归方程:
由式可知,,对原模型进行广义差分回归:
在EWiews中操作得到广义差分回归的输出结果,如图:
由图可得回归方程为
Se=(6.4927)(0.0234)
式中,.
由于使用了广义差分数据,样本容量减少了1个,为26个。
查
统计表可知.461
相关。
可决系数统计量也均达到理想水平。
由差分方程由
们得到最终的中国农
由图DW=1.7813可以判断,,说明在5%显著性水平下广义差分后模型中已无自相关。
由中国农村居民消费的广义差分模型可知,中国农村居民的编辑消费倾向为0.7162,即中国农民人均实际纯收入每增加1元,平均说来人均实际消费支出将增加0.7162元。
第七章
7.4为了研究1955~1974年美国制造业库存量Y和销售额X的关系,下面用阿尔蒙法估计如下有限分布滞后模型:
在实际应用中,Eviews提供了多项式分布滞后指令“PDL”用于估计
行研究。
为了考察货币供应量的变化对物价的影响,我们用广义货币M2的月增长量M2Z作为解释变量,以居民消费价格月度同比指数TBZS为被解释变量进行研究。
首先估计如下回归模型:
得到的回归结果见下图:
从回归结果来看,M2Z的t统计量值显著,表明当期货币供应量的变化对当期物价水平的影响在统计意义上有一定影响,但没有显现出这种影响的滞后性。
为了分析货币供应量变化影响物价的滞后性,作滞后6个月的分布滞后模型的估计,在Eviews工作文档的方程设
结果表明,从滞后12个月开始t统计量值显著,一直到滞后15个月位置,从滞后第16个月开始t值变得不再显著;再从回归系数来看,从滞后11个月开始,货币供应量变化对物价水平的影响明显增加,在滞后13个月时达到最大然后逐步下降。
通过上述一系列分析,我们可以做出这样的判断:在我国,货币
供应量变化对物价水平的影响具有明显的滞后性,滞后期大约为三个季度,而且滞后影响具有持续性,持续的长度大约为半年,其影响力度先递增然后递减,滞后结构为∧型。
当然,从上述回归结果也可以看出,回归方程不高,DW值也偏低,表明除了货币供应量以外,还有其他因素影响物价变化;同时,
阶段性特征。
为了分析居民储蓄行为在1996~2011年不同时期的数量关系,以1996年、2000年、2005年、2007年和2009年的五个转折点为依据,分别引入虚拟变量、,这五个年度所对应的GNI分别为701420.5亿元、98000.5元、184088.6亿元、251483.2亿元、
340320亿元。
据此我们设定了如下以加法和乘法两种方式同时引入虚拟变量的模型:
;。
对上式进行回归,结果如下图所示。
se=(0.056512)(0.069078)(0.056164)
t=(-4.9543)(8.0005)(-9.1692)
由于的参数估计量的t值大于临界值(30-6)=1.711,其余各个斜率系数的t值均大于临界值(30-6)=2.064,表明各解释变量的斜率系数在显著性水平
下显著地不等于0,居民人民币储蓄存款年增加额的回归模型分别为
运用虚拟变量的规则和方法,没有考虑通货膨胀等因素,也没有考虑时间序列数据的特殊问题。
而在实证分析中,储蓄函数还应考虑如通货膨胀、消费行为变动等其他因素。