A Comparative Analysis of James Legge and Ku Hung-
A Review of An Introduction to Discourse Analysis: Theory and Method by James Paul Gee

A Review of An Introduction to Discourse Analysis:Theory andMethod by James Paul GeeAbstract:Discourse Analysis is an important aspect in the linguistic study. The present paper introduces an important book An Introduction to Discourse Analysis:Theory and Method by James Paul Gee. Brief contents and comments are presented in the study.Key words:introduction;contents;comment1 IntroductionAn Introduction to Discourse Analysis:Theory and Method (2000)is one of the 54 books in A collection of Modern Linguistics and Applied Linguistics published by Foreign Language Teaching and Research Press. James Paul Gee,author of this book is a Tashia Morgridge Professor of Reading at the University of Wisconsin at Madison. He had once taught linguistics at Hampshire College in Massachusetts,Boston University and the University of California.As the title suggests,this book contributes to gain insight into the nature of discourse analysis,both from a theoretical view and in application. Ron Scollon,Professor of Georgetown University speaks highly of this book:“If you only read one book on discourse analysis,this is the one to read”. It’s an easily accessible and useful book for teachers and postgraduates of linguistics.2 Main ContentsThis book?mainly discusses two aspects:the research method and the nature of discourse. It consists of seven chapters and an appendix.Chapter One is an introduction to the whole book. The author makes clear his basic viewpoints on language,theory and methods used in his book. Gee attaches importance on the two following functions of language:to scaffold the performance of social activities and to scaffold human affiliation within cultures and social groups and institutions. The approach to discourse analysis is social and cognitive.Chapter Two discusses “Discourse”(with a big D)and social language. Gee holds that when people speak or write something,they are in fact constructing six things or six areas of“reality”:the meaning and value of aspects of the material world,activities,identities and relationships,politics,connections and semiotics. Social languages reflect people’s social identity and activity. He later offers a concrete definition of“Discourse” and shows that Discourses always involve more than language.Chapter Three introduces two primary tools of inquiry:situated meanings and cultural models,both of which involve ways of looking at how speakers and writers give specific meanings within specific situations. Gee contends that the meanings of words are not stable and general,and they integrally linked to social and cultural groups in ways that transcend in individual minds.Chapter Four adopts several examples to further explain “cultural model”,an important notion in this book. The author claims th at cultural models are our “first thought” or taken-for-granted assumptions about what is “typical’or normal;they are political and closely related to social culture and social groups. Based on how they are put to use and the effects they have,cultural models are divided into three sorts:espoused models,evaluative modes and models-in-(inter)action models. He further indicates that metaphors are a rich source of cultural models.Chapter Five,with the title of “Discourse Analysis”,is the most important part in this book. In this chapter,Gee integrates the tools of inquiry he has discussed in the earlier chapters into an overall model of discourse analysis that stresses the six building tasks introduced in chapter 2. He also discusses the role of transcripts,what might constitute an “ideal” discourse analysis and the nature of validity in discourse analysis. He argues that the validity of an analysis is not a matter of how one’s detailed transcript is but a matter of how the transcript works together with all the other elements of the analysis to create a “trustworthy” analysis.Gee thinks the validity for the discourse analysis is based on convergence,agreement,coverage and linguistic details. In this chapter,Gee also discusses an important and related property of language —“reflexivity”.Chapter Six deals with some aspects of how speech is planned and produced and what has to do with the sorts of meanings the speakers hope to carry and the hearers try to recover. Gee exhaustively presents a few details about the structure of sentences and of discourses in terms of function words & content words,information,stress& intonation,lines,stanzas,macrostructure and macro-lines. He concludes that these details are not important in and of themselves;the importance is that discourse analyst looks for patterns and links within and across utterance in order to form hypotheses about how meaning is being construed and organized.Chapter Seven is an example of discourse analysis. It deals with data in an attempt to exemplify some of the tools of inquiry discussed in this book. The data comes from extended interviews with middle-school teenagers and try to analyze how these teenagers make sense of their selves,lives and society.Following the above chapters,the last part is an appendix which gives a quick overview of the in communication. It is vital for the beginners to master grammar. To study grammar,Gee recommends M.A.K Halliday’s An Introduction to FunctionalGrammar.3 Brief CommentThis book is an introduction to the analysis of language as it is used to enact activities,perspectives and identities. Gee adopts a unique approach which is a little social and cognitive to some degree I think to discourse analysis in this book. He takes both written and spoken language as his source of analysis and his perspectives involve in a variety of disciplines,including psychology,anthropology,communication and education. The whole book clearly reflects Gee’s compatible attitude towards discourse analysis. He cont ends that “there are many approaches to discourse,none of them,including this one is uniquely right”. He also encourages readers to formulate their own views on discourse and use different tools of inquiry in their own discourse analysis.The overall structure is accessible and conforms to readers’learning procedure. This book presents the theory of language-in-use alongside tools of inquiry first (Chapter Two—Four);then these tools of inquiry are placed in the framework of an overall approach to discourse analysis (Chapter Five);finally an example of discourse analysis is presented the last Chapter. Besides,the author introduces theories or tools of inquiry with many concrete or everyday examples to explain them,thus make it easier for the readers to understand.The only slightest dissatisfaction I find in this book is the arrangement of some topics. For instances,the notion of “Discourse” is discussed both in the first two chapters. Some of the content of Chapter Three (situated meanings and cultural models)and Chapter Four (cultural models)are overlapping. If the content is better organized,I believe it’ll be more beneficial to readers.Reference:[1]Gee J. P. An Introduction to Discourse Analysis:Theory and Method[M].Beijing:Foreign Language Teaching and Researching Press,2000.。
专题05 阅读理解D篇(2024年新课标I卷) (专家评价+三年真题+满分策略+多维变式) 原卷版

《2024年高考英语新课标卷真题深度解析与考后提升》专题05阅读理解D篇(新课标I卷)原卷版(专家评价+全文翻译+三年真题+词汇变式+满分策略+话题变式)目录一、原题呈现P2二、答案解析P3三、专家评价P3四、全文翻译P3五、词汇变式P4(一)考纲词汇词形转换P4(二)考纲词汇识词知意P4(三)高频短语积少成多P5(四)阅读理解单句填空变式P5(五)长难句分析P6六、三年真题P7(一)2023年新课标I卷阅读理解D篇P7(二)2022年新课标I卷阅读理解D篇P8(三)2021年新课标I卷阅读理解D篇P9七、满分策略(阅读理解说明文)P10八、阅读理解变式P12 变式一:生物多样性研究、发现、进展6篇P12变式二:阅读理解D篇35题变式(科普研究建议类)6篇P20一原题呈现阅读理解D篇关键词: 说明文;人与社会;社会科学研究方法研究;生物多样性; 科学探究精神;科学素养In the race to document the species on Earth before they go extinct, researchers and citizen scientists have collected billions of records. Today, most records of biodiversity are often in the form of photos, videos, and other digital records. Though they are useful for detecting shifts in the number and variety of species in an area, a new Stanford study has found that this type of record is not perfect.“With the rise of technology it is easy for people to make observation s of different species with the aid of a mobile application,” said Barnabas Daru, who is lead author of the study and assistant professor of biology in the Stanford School of Humanities and Sciences. “These observations now outnumber the primary data that comes from physical specimens(标本), and since we are increasingly using observational data to investigate how species are responding to global change, I wanted to know: Are they usable?”Using a global dataset of 1.9 billion records of plants, insects, birds, and animals, Daru and his team tested how well these data represent actual global biodiversity patterns.“We were particularly interested in exploring the aspects of sampling that tend to bias (使有偏差) data, like the greater likelihood of a citizen scientist to take a picture of a flowering plant instead of the grass right next to it,” said Daru.Their study revealed that the large number of observation-only records did not lead to better global coverage. Moreover, these data are biased and favor certain regions, time periods, and species. This makes sense because the people who get observational biodiversity data on mobile devices are often citizen scientists recording their encounters with species in areas nearby. These data are also biased toward certain species with attractive or eye-catching features.What can we do with the imperfect datasets of biodiversity?“Quite a lot,” Daru explained. “Biodiversity apps can use our study results to inform users of oversampled areas and lead them to places – and even species – that are not w ell-sampled. To improve the quality of observational data, biodiversity apps can also encourage users to have an expert confirm the identification of their uploaded image.”32. What do we know about the records of species collected now?A. They are becoming outdated.B. They are mostly in electronic form.C. They are limited in number.D. They are used for public exhibition.33. What does Daru’s study focus on?A. Threatened species.B. Physical specimens.C. Observational data.D. Mobile applications.34. What has led to the biases according to the study?A. Mistakes in data analysis.B. Poor quality of uploaded pictures.C. Improper way of sampling.D. Unreliable data collection devices.35. What is Daru’s suggestion for biodiversity apps?A. Review data from certain areas.B. Hire experts to check the records.C. Confirm the identity of the users.D. Give guidance to citizen scientists.二答案解析三专家评价考查关键能力,促进思维品质发展2024年高考英语全国卷继续加强内容和形式创新,优化试题设问角度和方式,增强试题的开放性和灵活性,引导学生进行独立思考和判断,培养逻辑思维能力、批判思维能力和创新思维能力。
诗经英译 理雅各

Annotating style
• The style of arrangement of annotationsis roughly consistent with the traditional Chinese annotating style
Interpretation of poetry theme
Three times The first translation began in 1863. It was in blank form. The second was the translation of The Book of Songs into a rhymed version in 1876. The third was a collection of selected poems in 1879, which was published in the Oriental Canon.
From 1861 to 1886, he translated all the major Chinese classics, including the Four Books and The Five Classics, in 28 volumes. When he left China, he was an accomplished writer. He, along with French scholar Louis de Gaulseffin and German scholar William Willewise, is regarded as one of the three Masters of Chinese Translation in Europe. He is also the first winner of the Ru Lian Translation Prize.
《荀子》英译对比研究_翻译方法

《荀子》英译对比研究_翻译方法Title: A Comparative-Translation Study on Xunzi: Translation MethodAbstract:This paper presents a comparative-translation study on the translation method of Xunzi, an important Confucian scholar in ancient China. Firstly, it reviews the original Chinese text of Xunzi and its relevant contexts. Secondly, it compares the translations of Xunzi's text by two major translators, James Legge and John Knoblock. Then, it points out the strengths and weaknesses of their translation methods, followed by discussion of the implications for future translation studies. Finally, the paper concludes that both translators have successfully produced translations that capture the original meaning of Xunzi's text and highlights the importance of understanding the culture, style, and context of a text before translating it.Keywords: Xunzi, Translation Method, Comparative-Translation Study, James Legge, John Knoblock.Introduction: The Chinese philosopher Xunzi (荀子) is one of the most influential Confucian scholars in ancient China. His meticulous interpretation of the fundamentals of Confucianism has created an intellectual tradition that lasts to this day. To better understand and appreciate Xunzi's teachings, it is essential to first understand the original Chinese text, as well as its cultural and historical context. This paper compares the translations of Xunzi's text by two major translators, James Legge and John Knoblock. It will assess the strengths and weaknesses of their translation methods and discuss the implications for future translation studies.Body:Legge's Method: James Legge (1815-1897) was a British sinologist who devoted his life to the translation of important Chinese works into English. He studied Buddhist and Taoist scriptures before expanding his interest to the Confucian writings of the classic era. In his translation of Xunzi, Legge relied on his classical Chinese language knowledge to give accurate and detailed translations. For example, he carefully distinguished between the original characters and the context of the texts in order to present the most literal version of Xunzi's philosophical thoughts. Legge also adopted a range of different approaches throughout the text, such as using idiomatic expressions to bring out the poetic beauty of the prose.Knoblock's Method: John Knoblock (1947-present), is an American professor best known for his three-volume translation of Xunzi. He drew on his expertise in classical Chinese to create a more modern and accessible translation for a wider audience. Unlike Legge, Knoblock adopted a ‘contextualization’ approach in his translations. This means that he puts a greater emphasis on understanding the meanings of the passages in relation to the overall context of Xunzi's work. He also takes a ‘less literal’ approach and often paraphrases passages to make them easier to understand.Conclusion: Through their various approaches, both Legge and Knoblock successfully produced translations that capture the original meaning of Xunzi's text. The analysis of their translation methods highlights the importance of understanding the culture,style and context of a text before attempting to translate it. The paper believes that future translators can benefit from further exploring both translators’ methods to develop more accurate and elegant translations.When it comes to applying the translation methods of James Legge and John Knoblock, this paper suggests that understanding the culture, style, and context of a text are essential. Translators should first determine the original meaning of a text before attempting to translate it. For example, Legge relied on his classical Chinese language knowledge to provide a literal version of the text, while Knoblock adopted a contextualization approach to put more emphasis on understanding the meanings of the passages. Additionally, Legge used idiomatic expressions to bring out the poetic beauty of the prose, whereas Knoblock often paraphrased passages to make them easier to understand.Overall, understanding the cultural and historical context of a text can help translators to produce accurate and elegant translations, just like both Legge and Knoblock. Future translators can benefit from further exploring both translators’ methods in order to gain a deeper insight into the nuances and subtleties of Xunzi's work and create translations that capture the essence of his teachings. By following these methods, translators can ensure that their translations accurately convey the true meaning behind Xunzi's texts.In addition to understanding the context of a text, one of the most important aspects of translation is the ability to capture the tone and style of the original. This can be especially challenging when translating ancient texts. Fortunately, both Legge and Knoblock managed to successfully do so by using a combination of modern and classical language.Legge's choice of idiomatic expressions was essential to bringing out the poetic beauty of Xunzi's prose, while Knoblock's use of well-crafted metaphors created an accurate yet accessible translation. Additionally, they both paid great attention to detail when translating the characters, ensuring accuracy and consistency throughout their translations.It is important to note that translating ancient texts is a complex process that requires both linguistic and literary skills. While there is no single right or wrong way to translate a text, Legge and Knoblock have provided great insight into how translators should approach such a task. By utilizing their combined knowledge and experience, future generations can continue to produce accurate and elegant translations of classic Chinese texts.Although Legge and Knoblock both used different methods to translate Xunzi’s texts, they both respected the original intention and meaning behind the text. This shows us that translation is not simply a matter of transferring words from one language to another; rather, it involves an understanding of the cultural, historical and literary context of the text in order to ensure accuracy and clarity.Legge and Knoblock's translations of Xunzi's texts serve as a reminder that translation should strive for a balance between accuracy and elegance. Both translators' works demonstrate the importance of understanding the original intent and content of a text before beginning the translation process.By taking into account their respective approaches, future translators can continue to create translations that capture theessence of classic Chinese texts. In doing so, they will help ensure that these ancient texts remain accessible and informative to generations to come.The translations of Xunzi's texts by Legge and Knoblock provide valuable insight into the complexities of translating ancient Chinese texts. Although their approaches were different, both translators managed to successfully capture the nuances and subtleties of the original text while ensuring accuracy and clarity in their respective translations.Legge's literal approach combined with Knoblock's contextualization technique make for a comprehensive understanding of Xunzi's writings. Their combined methods highlight the need for translators to take into account the cultural, historical, and literary context of a text when attempting to translate it. This is especially important for ancient texts, as these texts often contain references to philosophies and concepts that may not be immediately recognizable to modern readers.By combining the approaches of both Legge and Knoblock, future translators can ensure that their translations are accurate, elegant, and informative. In doing so, they will help ensure that the wisdom and teachings of Xunzi remain accessible and relevant to generations to come.This paper has looked at the approaches of both James Legge and John Knoblock in translating Xunzi's texts. Although their methods differ, they both managed to capture the essence of Xunzi's teachings with their respective translations. Through their combined efforts, we can gain a better understanding of the complexities of translating ancient Chinese texts.It is clear that understanding the culture, style, and context of a textare essential when attempting to translate it. Translators should be aware of the nuances and subtleties of the text when interpreting it, as well as its relevance in the modern context. Additionally, they should strive to achieve a balance between accuracy and elegance, while taking into account the different interpretations of the text by various scholars.By using a combination of the approaches used by Legge and Knoblock, future translators can ensure that their translations accurately convey the intent and meaning behind Xunzi's texts. In doing so, they will help make ancient Chinese texts more accessible and relevant to a wider audience.Translating Xunzi's texts requires an understanding of the original context and intention of the text as well as a mastery of both classical and modern Chinese. Both Legge and Knoblock demonstrated this through their translation methods, which emphasize the importance of accuracy and elegance. Their work serves as a reminder that translation is a complex and challenging process that should not be taken lightly.In order to successfully translate ancient Chinese texts, current and future translators must not only understand the cultural and historical context of the text, but also the nuances and subtleties of the language itself. They must also ensure that their translations accurately convey the true meanings behind the text while maintaining its original poetic beauty and musicality.By combining the approaches used by both Legge and Knoblock, future generations of translators will be able to effectively convey the wisdom and teachings of Xunzi to a wider audience. Throughtheir combined efforts, Xunzi's teachings will remain accessible and relevant for years to come.。
2024届高考英语阅读理解专练(含答案)
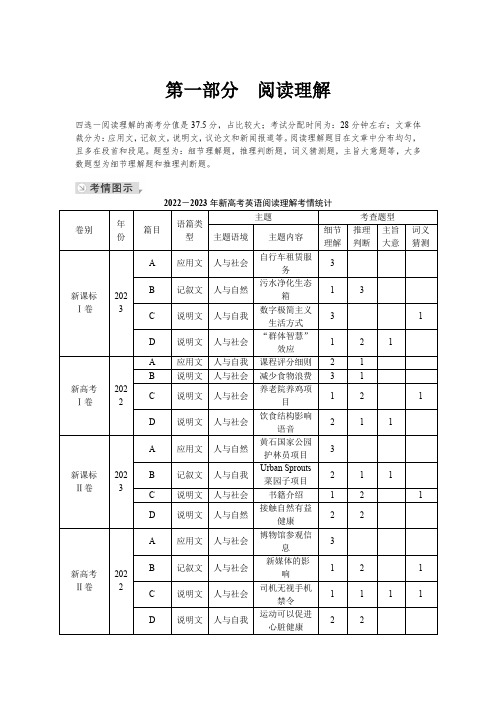
第一部分阅读理解四选一阅读理解的高考分值是37.5分,占比较大;考试分配时间为:28分钟左右;文章体裁分为:应用文,记叙文,说明文,议论文和新闻报道等。
阅读理解题目在文章中分布均匀,且多在段首和段尾。
题型为:细节理解题,推理判断题,词义猜测题,主旨大意题等,大多数题型为细节理解题和推理判断题。
卷别年份篇目语篇类型主题考查题型主题语境主题内容细节理解推理判断主旨大意词义猜测新课标Ⅰ卷2023A应用文人与社会自行车租赁服务3B记叙文人与自然污水净化生态箱13C说明文人与自我数字极简主义生活方式31 D说明文人与社会“群体智慧”效应121新高考Ⅰ卷2022A应用文人与自我课程评分细则21B说明文人与社会减少食物浪费31C说明文人与社会养老院养鸡项目121 D说明文人与社会饮食结构影响语音211新课标Ⅱ卷2023A应用文人与自然黄石国家公园护林员项目3B记叙文人与自我Urban Sprouts菜园子项目211 C说明文人与社会书籍介绍121D说明文人与自然接触自然有益健康22新高考Ⅱ卷2022A应用文人与社会博物馆参观信息3B记叙文人与社会新媒体的影响121 C说明文人与社会司机无视手机禁令1111 D说明文人与自我运动可以促进心脏健康22(细节理解题+推理判断题+词义猜测题+段落大意题)【典例印证】【破题关键点】(2023·新课标Ⅰ卷)The goal of this book is to make the case for digital minimalism,including a detailed exploration of what it asks and why itworks, and then to teach you how to adopt this philosophy if you decide it’s right for you.To do so, I divided the book into two parts. In part one, I describe the philosophical foundations of digital minimalism, starting with an examination of the forces that are making so many people’s digital lives increasingly intolerable, before moving on to a detailed discussion of the digital minimalism philosophy.Part one concludes by introducing my suggested method for adopting this philosophy: the digital declutter. This process requires you to step away from optional online activities for thirty days. At the end of the thirty days, you will then add back a small number of carefully chosen online activities that you believe will provide massive benefits to the things you value. In the final chapter of part one, I’ll guide you through carrying out your own digital declutter. In doing so, I’ll draw on an experiment I ran in 2018 in which over 1,600 people agreed to perform a digital declutter. You’ll hear these participants’ stories and learn what strategies worked well for them, and what traps they encountered that you should avoid.The second part of this book takes a closer look at some ideas that will help you cultivate (培养) a sustainable digital minimalism lifestyle. In these chapters, I examine issues such as the importance of solitude (独处) and the necessity of cultivating high-quality leisure to replace the time most now spend on mindless device use. Each chapter concludes with a collection of practices, which are designed to help you act on the big ideas of the chapter. You can view these practices as a toolbox meant to aid your efforts to build a minimalist lifestyle that words for your particular circumstances.1. What is the book aimed at?A. Teaching critical thinking skills.B. Advocating a simple digital lifestyle.C. Solving philosophical problems.D. Promoting the use of a digital device.2. What does the underlined word “declutter”in paragraph3 mean?A. Clear-up.B. Add-on.1. 先读第1题的题干,标出关键词________→根据关键词,从第一段开始浏览,寻找和题干关键词意思相近的________,确定此处内容是本题根据→根据本句中的“to make the case for digital minimalism(为数字极简主义辩护)”,确定第1题的答案________2. 再读第2题的题干,关键词是画线词________→根据关键词,从第1段后浏览,在第三段找到画线词→找到关键词后把此处内容和四个选项进行比对,确定第2题的答案________3. 然后读第3题的题干,标出关键词________→根据关键词,从第2题关键词后面浏览,寻找题干中的关键词→找到关键词后把此处内容和四个选项进行比对,确定第3题的答案________4. 最后读第4题的题干,标出关键词________→根据关键词,从第3题关键词后面浏览,寻找题干中的关键词→找到关键词后把此处内容和四个选项进行比对,确定第4题的答案________答案 1. aimed; goal; B2. declutter; A3. the final chapter of part one; C4. practices; AC. Check-in.D. Take-over.3. What is presented in the final chapter of part one?A. Theoretical models.B. Statistical methods.C. Practical examples.D. Historical analyses.4. What does the author suggest readers do with the practicesoffered in part two?A. Use them as needed.B. Recommend them to friends.C. Evaluate their effects.D. Identify the ideas behind them.题型微解题型微解1:细节理解题细节理解题是高考题型中考查较多的题型,也是容易得分的题型,该题型分为:直接细节题,间接细节题,数字计算题和归纳概括题。
高三英语文学批评标准应用单选题30题

高三英语文学批评标准应用单选题30题1. In "Pride and Prejudice", which of the following is not a key element of literary criticism?A. Character developmentB. Plot structureC. Author's backgroundD. Publishing date答案:D。
本题主要考查文学批评的基本概念。
选项A 人物发展是文学作品分析的重要方面;选项B 情节结构对于理解作品的整体性很关键;选项C 作者的背景会影响作品的创作和解读。
而选项D 出版日期并非文学批评的关键元素。
2. When analyzing "Romeo and Juliet", which aspect is most crucial in literary criticism?A. The number of charactersB. The language styleC. The historical backgroundD. The sales volume of the book答案:B。
文学批评中,对于《罗密欧与朱丽叶》的分析,选项A 人物数量并非最关键;选项C 历史背景有一定作用,但不是最核心的;选项D 书籍的销量与文学批评无关。
而语言风格是理解和评价这部作品的关键所在。
3. In the literary criticism of "To Kill a Mockingbird", what should begiven priority?A. The film adaptationB. The moral themesC. The book cover designD. The printing quality答案:B。
对于《《杀死一只知更鸟》的文学批评,选项A 电影改编不是首要考虑的;选项 C 书的封面设计和选项 D 印刷质量都不属于文学批评的重点。
说卦传-中英文对照(英文byjameslegge)

Treatise of Remarks on the TrigramsChapter I. 1. Anciently, when the sages made the Yî, in order to give mysterious assistance to the spiritual Intelligences, they produced (the rules for the use of) the divining plant.2. The number 3 was assigned to heaven, 2 to earth, and from these came the (other) numbers.3. They contemplated the changes in the divided and undivided lines (by the process of manipulating the stalks), and formed the trigrams; from the movements that took place in the strong and weak lines, they produced (their teaching about) the separate lines. There ensued a harmonious conformity to the course (of duty) and to virtue, with a discrimination of what was right (in each particular case). They (thus) made an exhaustive discrimination of what was right, and effected the complete development of (every) nature, till they arrived (in the Yî) at what was appointed for it (by Heaven).昔者,圣人之作易也,幽赞神明而生蓍。
A CHRG Analysis of ambiguity in Biological Texts (Extended Abstract)

A CHRG Analysis of ambiguity inBiological Texts(Extended Abstract)Veronica Dahl and Baohua GuLogic and Functional Programming Group,School of Computing Science,Simon Fraser University,Burnaby,B.C.V5A1S6Canada{veronica,bgu}@cs.sfu.caAbstract.We propose a methodology for analyzing human languagesentences which can efficiently choose between alternative readings spring-ing from the interaction between coordination and preposition phraseattachment.We present a proof-of-concept in terms of an extremelysuccinct CHRG[3]analyzer for interpreting biological text titles.Ourmethod uses expert knowledge on semantic types and compatibilitiesamong them,as well as contextual facilities of CHRG to gain an overallview of the sentence components involved in disambiguation.1IntroductionThis work was inspired by our efforts to automatically extract concepts from biological text,where one of the main challenges faced is the amount of infor-mation succinctly packed into titles.Typically,biological named entities appear as acronyms or in condensed versions,and the amount of information is max-imized by heavy use of coordination within noun phrases.As well,they have a tendency to contain several prepositional phrases with no clear indication of what antecedent they should attach to.For example,given the title sentence of a Medline abstract:“IL-2gene expression and NF-kappa B activation through CD28requires reactive oxygen production by5-lipoxygenase”,it is hard to see whether the activation through CD28refers only to NF-kappa B or to both IL-2 gene and NF-kappa B.The ambiguity involved in titles containing even one instance of coordination or preposition phrase attachment is a challenge,and when two or more coexist in the same title,the number of possible interpretations explodes,making it extremely difficult for a naive automated system to cope with.However,it is not unusual tofind,within the text or in related knowledge bases such as biological dictionaries and ontologies(e.g.,the GENIA Ontology [8]),short descriptions of what the entities’names refer to,or at the very least their semantic types(e.g.,protein molecule,DNA family or group).The short descriptions are often contained in simple constructs named appositions(e.g.,asin“Grf40,a novel Grb2family member””),and their semantic types can very often be found directly in available taxonomies(e.g.,the GENIA corpus[7]),or inferred from other related knowledge bases(e.g.,[8]).We have found that by extracting the semantic class to which each named entity refers,and by considering the relationships the sentence involves it in,wecan discard many of the ambiguities that originate in the coordination construc-tions where they intervene.In this paper we propose an analysis of ambiguity in compact text in general,while focusing on biological texts’titles in particularfor ease of demonstration and exemplification.2Analysis of the Ambiguities Most Commonly Present in Biological Titles2.1An ExampleThe typical features of titles and similar corpora are:a)the entities are referred to through abbreviations or acronyms;b)coordination is quite common;c)prepositional phrase attachment ambiguities are very common too;The following sentence,taken from the GENIA corpus[7],illustrates: IL-2gene expression and NF-kappa B activation through CD28requires re-active oxygen production by5-lipoxygenase.In this sentence,coordination interacts with preposition phrase attachment with highly ambiguous results:the sentence could mean either(note that each readingis the conjunction of two simpler sentences,noted with a)and b)below):–Reading(1):1a.IL-2gene expression through CD28requires reactive oxygen production by5-lipoxygenase.1b.NF-kappa B activation through CD28requires reactive oxygen produc-tion by5-lipoxygenase.–Reading(2):2a.IL-2gene expression requires reactive oxygen production by5-lipoxygenase.2b.NF-kappa B activation through CD28requires reactive oxygen produc-tion by5-lipoxygenase.Atfirst glance,deciding among these possible readings appears an un-surmountable task.However,if we simply retrieve the semantic types or classes to which each entity belongs,and note whether such classes can meaningfully appear as ar-guments of the relationships in which they are involved,many of the possible readings fade away.Any remaining ones will in general be those that are also ambiguous for a human expert in the biological notions involved.2.2Our methodologyTo analyze sentences such as the above,wefirst consult the GENIA corpus, a repository of annotations for every biological named entity in biological text in order to attach each abbreviation or acronym to a)its full name and b)its semantic type.In those cases where this information is not present,we look for an apposition either in the text that accompanies the title we are analyzing,or in related texts.In the previous section’s example,a lookup for IL-2gene in the GENIA corpus yields the name IL-2gene and the semantic type DNA domain or region. On the other hand,it could be that an entity is not annotated as a biological entity in the GENIA corpus,but wefind it within the text or within some other corpus,in an apposition which can point us to the type.Even when an entity is found in the GENIA corpus,consultation of the appositions which further define it may be useful.For instance,from“Grf40,A novel Grb2family member,is involved in T cell signaling through interaction with SLP-76and LAT.”,we can infer that the protein molecule GRf40further belongs to the subfamily Grb2.Our problem now reduces to encode which semantic types make sense in each argument of each of the biological relationships we most commonly encounter in biological texts.This information has to be constructed from an expert’s knowledge.The Appendix shows a prototype implementation of our methodology as afirst step in demonstrating its usefulness.3Exploiting ontological informationOne of thefiles we consult in our system is the GENIA ontology,which expresses subtype relationships in the format exemplified by:subtype("Natural_source","Source").In anotherfile we have the expert knowledge about compatibility between biomedical concepts,expressed in our system as constants or as types,e.g. compatible(IL-2_gene_expression’,’Protein_molecule’).Such information will be consulted from our grammar rules for disambigua-tion.For instance,the example in2.1is easily taken care of by just one CHRG rule,namelynp(A),prep(P),np(B)/-(verb(_);prep(_);eos(_))<:> subtype(A,’BioProcess’),subtype(B,’BioEntity’),compatible(A,B) |np(A+P+B).This rule will create a noun phrase from two noun phrases(represented A and B)joined by a preposition(P),provided that the second np isflanked by either a verb,another preposition,or and end of sentence character,and provided that A’s type and B’s type are compatible(as well as being a subtype of, respectively,’BioProcess’and’BioEntity’).The ontology is consulted,of course, when checking the desired subtype relationships.4Criticality of CHRG for our methodologyThe use of CHRG is crucial to our approach,sincea)it allows us to work bottom-up,thereby heading more directly to the right analysis.b)it allows us to put together into the same rule information coming from heterogeneous sources.For instance,we mine ontology information from the Genia Ontology[8],and can consult or effect transformations of that information that suit disambiguation purposes.Left hand sides of CHRG rules do not care from whichfile(among the ones having been read)the information that needs to be put together comes from,so this gives a great degree of modularity and allows us to incorporate information from heterogenous sources.c)in the case of the text,or even of some titles containing appositions that define a given term.If we consider for instance the sentence:”Overexpression of DR-nm23,a protein encoded by a member of the nm23gene family,inhibits granulocyte differentiation and induces apoptosis in32Dc13myeloid cells”,we can glean some definitional information for DR-nm23.The level of granularity with which we want to take advantage of this feature will vary according to our purposes.We might be content for instance with noting only that it is a protein,in which case the rest of the sentence can be ignored(CHRG includes a facility for disregarding intermediate strings which will not be analyzed)or that it is a protein and is encoded by a member of the nm23gene family,or that it is a protein,is encoded by a member of the nm23gene family,and induces apoptosis,and so on.Likewise,the information that nm23is a gene can be gleaned from the same sentence.In other words,we can implement a specialized CHRG which only looks at appositions within a text,disregards the rest of the text,and decides how to usefully exploit the information in the apposition:will it be used to consult the type hierarchy,to expand it,or just to add a definition into the database we are working with?d)the use of CHRGs allows for a straightforward coexistence with CHR[6] rules,and even for the same symbols to be considered both as grammar symbols or as constraints.This is exemplified by the coexistence of the grammar rule described in Section3with the CHR rule:np(X),np(Y),compatible(A,B)==>subtype(X,A),subtype(Y,B)|compatible(X,Y).which extends the user’s definitions of compatibility by considering that if the user has described A and B as being compatible,and the parser has discovered X and Y as noun phrases,where X is a subtype of A and Y is a subtype of B,X and Y are also compatible.This inferred compatibility information can then be used by the grammar rule in Section3,since it is now in the constraint store.We do not know of any other system which so seamlessly would allow us to combine grammar and program rules for similar interactions needed.As well,the facility of CHRG for looking at context allows us to implement the above described methodology with extreme conciseness.The full prototype program takes only one page and is included in full in the Appendix.It is to be noted that as a side effect of disambiguation,our implementation completes the meaning of coordinated sentences which do not overtly contain all the conjuncts.Previous work for reconstructing elided meanings within co-ordinated phrases in natural language typically take more machinery for their implementation,puting parallelism in discourse,or further tools such as assumptions and Datalog grammars[4][5].Let us exemplify with the same sample sentence,taken from a real life title, which we showed in Section1.Semantic types are described through binary pred-icates of the form type(Entity,Class),e.g.from the program in the Appendix we can see that the semantic type of“IL-2gene-expression”is“bioprocess”.As well,our expert knowledge base includes information on compatibilities,from which we can know for instance that“IL-2gene-expression is compatible with CD28.The rules that analyze conjoined noun phrases consult such information and take appropriate action by conjoining only those components that are compatible in type,and likewise appropriately attaching any prepositional phrases.Thus,in the above example,the second reading is simply not accessible from the grammar rules given,since they fail to satisfy the compatibility condition.5DiscussionWe have proposed a CHRG methodology to disambiguate multiple readings of sentences in biological text,on the basis of compatibilities between semantic types,which are calculated on thefly by consulting the GENIA ontology and dynamically extending user defined,basic relationships on compatibilities.Our parsing technique integrates semantics at the lexical level,exploiting an ontology for the application domain(biological texts).We mix grammar rules and CHR proper rules to allow productive interac-tion between domain constraints and grammatical constraints.As explained in Section4,this makes it easier to express our problem in directly executable terms.Our approach uses includes expert knowledge on semantic types of named entities and on compatibility between entities based on their semantic types. Appositions can provide further information about an entity of interest,as we also saw.Some appositions may even throw light upon relationships between two entities.We have shown that this approach allows us to very succinctly express within the grammar rules the conditions under which alternative readings originating in preposition attachment plus coordinating ambiguities should be chosen.We have exemplified our methodology for the particular problem of PP-attachment in coordinate constructions,and tested it with afirst running proto-type which is shown in the Appendix.Thesefirst results show that much simpler machinery can be arrived at within our methodology than was previously the case in related work on coordination,including our own work with Datalog gram-mars and assumptions[4]and even CHR[5].Part of this is due to the restrictionof our domain to a well-investigated domain for which online corpora and on-tologies exist,namely the biological domain,but as also pointed out,a bigger part is due to the use of CHRG rules which focus on the relevant context seen overall,checks on types and their compatibilities,and uses this information to decide how to form meaning from the meanings of the involved parts.However,we yet have to combine the advantages obtained in the present work with other long distance dependency work around CHR[6],for a uniform, more encompassing treatment,perhaps along the lines suggested in citeDahl-2004.Our present focus on titles allows us to get away with”just”allowing coordination among the possible long-distance dependency phenomena.With this work we hope to stimulate further research into the subject. Acknowledgements This work is supported by the CONTROL project,funded by Danish Natural Science Research Council,and by Veronica Dahl’s NSERC Discovery Grant.References[1]Aguilar Solis,D.and Dahl,V.:Coordination revisited:a CHR approach.In Proc.Iberamia’04,Mexico.[2]CHRG User Manual.http://akira.ruc.dk/henning/chrg/[3]Henning Christiansen:CHR grammars.Theory and Practice of Logic Programming,5(4-5):467-501(2005)[4]Dahl,V.:On Implicit Meanings.In:Computational Logic:From Logic Program-ming into the Future.F.Sadri and T.Kakas(eds).(invited contribution),volume in honour of Bob Kowalski,Springer-Verlag,2002.[5]Dahl,V.:Treating Long-Distance Dependencies through Constraint Reasoning.InProc.of the3rd International Workshop on Multiparadigm Constraint Programming Languages,2004.[6]Frhwirth,T.:Theory and Practice of Constraint Handling Rules,Special Issue onConstraint Logic Programming(P.Stuckey and K.Marriot,Eds.),Journal of Logic Programming,Vol37(1-3),pp95-138,October1998.[7]GENIA Corpus:http://www-tsujii.is.s.u-tokyo.ac.jp/genia/topics/Corpus/[8]GENIA Ontology:http://www-tsujii.is.s.u-tokyo.ac.jp/genia/topics/Corpus/genia-ontology.htmlAppendix A:the prototype CHRG implementation fortitle disambiguation%the CHR rules and CHR grammar rules used for disambiguation:-compile(’chrg.txt’).handler simple_coordination_solver.constraints np/1,compatible/2,subtype/2.grammar_symbols sentence/1,subj/1,verb/1,obj/1,np/1,conj/1,prep/1,eos/1,compatible/2,subtype/2.%to induce new subtype relationsnp(A),subtype(A,B),subtype(B,C)==>subtype(A,C).%to induce new compatible relationsnp(X),np(Y),compatible(A,B)==>subtype(X,A),subtype(Y,B)|compatible(X,Y).np(X),compatible(A,B)==>subtype(X,A)|compatible(X,B).np(Y),compatible(A,B)==>subtype(Y,B)|compatible(A,Y).%%grammar rules to group a np with a following preposition phrasenp(A),prep(P),np(B),conj(K),np(C)<:>np(A+P+B),conj(K),np(A+P+C).np(A),prep(P),np(B)/-(verb(_);prep(_);eos(_))<:>subtype(A,’BioProcess’),subtype(B,’BioEntity’),compatible(A,B) |np(A+P+B).np(A),conj(K),np(B+P+C)<:>subtype(A,’BioProcess’),subtype(C,’BioEntity’),compatible(A,C) |np(A+P+C),conj(K),np(B+P+C).%%rules to classify noun phrases as subjects or objects of verbsnp(A)/-verb(_)::>subj(A).verb(_)-\np(A)::>obj(A).%%rules to handle coordinationsnp(A),conj(_),subj(B)::>subj(A),subj(B).obj(A),conj(_),np(B)::>obj(A),obj(B).%%to identify a complete sentencesubj(A),verb(V),obj(B)::>sentence(s(A,V,B)).sentence(A),conj(_),sentence(B)<:>sentence(A+B).%%to solve incomplete sentencessubj(A),verb(V)/-conj(_),sentence(s(_,_,B))::>sentence(s(A,V,B)).sentence(s(A,_,_))-\conj(_),verb(V),obj(B)::>sentence(s(A,V,B)).subj(A)-\conj(_),sentence(s(_,V,B))::>sentence(s(A,V,B)).sentence(s(A,V,_))-\conj(_),obj(B)::>sentence(s(A,V,B)).subj(A),verb(V1),conj(_),verb(V2),obj(B)::>sentence(s(A,V1,B)),sentence(s(A,V2,B)).%include example sentence,ontology,concepts,and domain knowledge:-include(’test_example.txt’).%sentences for testing:-include(’genia_ontology.txt’).%the GENIA Ontology:-include(’genia_concepts.txt’).%annotations from GENIA corpus:-include(’compatibility.txt’).%compatibility between concepts end_of_CHRG_source.(N.B.for the referees:you can download the example1.txt and other title phrases or title sentences of the GENIA corpus we are considering here from www.cs.sfu.ca/bgu/personal/CSLP2007)Appendix B:the Auxiliary Files%the content of file"genia_ontology.txt"subtype(’BioEntity’,’BioConcept’).subtype(’BioProcess’,’BioConcept’).subtype(’Source’,’BioEntity’).subtype(’Substance’,’BioEntity’).subtype(’Natural_source’,’Source’).subtype(’Artificial_source’,’Source’).subtype(’Organism’,’Natural_source’).subtype(’Body_part’,’Natural_source’).subtype(’Tissue’,’Natural_source’).subtype(’Cell_type’,’Natural_source’).subtype(’Cell_component’,’Natural_source’).subtype(’Other_artificial_source’,’Artificial_source’). subtype(’Cell_line’,’Artificial_source’).subtype(’Multi_cell’,’Organism’).subtype(’Mono_cell’,’Organism’).subtype(’Virus’,’Organism’).subtype(’Compound’,’Substance’).subtype(’Atom’,’Substance’).subtype(’Organic’,’Compound’).subtype(’Inorganic’,’Compound’).subtype(’Amino_acid’,’Organic’).subtype(’Nucleic_acid’,’Organic’).subtype(’Lipid’,’Organic’).subtype(’Carbohydrate’,’Organic’).subtype(’Other_organic_compound’,’Organic’).subtype(’Protein’,’Amino_acid’).subtype(’Peptide’,’Amino_acid’).subtype(’Amino_acid_monomer’,’Amino_acid’).subtype(’DNA’,’Nucleic_acid’).subtype(’RNA’,’Nucleic_acid’).subtype(’Nucleotide’,’Nucleic_acid’).subtype(’Polynucleotide’,’Nucleic_acid’).subtype(’Protein_family_or_group’,’Protein’).subtype(’Protein_complex’,’Protein’).subtype(’Protein_molecule’,’Protein’).subtype(’Protein_subunit’,’Protein’).subtype(’Protein_substructure’,’Protein’).subtype(’Protein_domain_or_region’,’Protein’).subtype(’Protein_ETC’,’Protein’).subtype(’DNA_family_or_group’,’DNA’).subtype(’DNA_molecule’,’DNA’).subtype(’DNA_domain_or_region’,’DNA’).subtype(’DNA_substructure’,’DNA’).subtype(’DNA_ETC’,’DNA’).subtype(’RNA_family_or_group’,’RNA’).subtype(’RNA_molecule’,’RNA’).subtype(’RNA_domain_or_region’,’RNA’).subtype(’RNA_substructure’,’RNA’).subtype(’RNA_ETC’,’RNA’).%the content of file"genia_concepts.txt"%sample domain knowledge about the types of bioconceptssubtype(’IL-2_gene_expression’,’BioProcess’).subtype(’NF-kappa-B_activation’,’BioProcess’).subtype(’reactive_oxygen_production’,’BioProcess’).subtype(’CD28’,’Protein_molecule’).subtype(’5-lipoxygenase’,’Protein_molecule’).%the content of file"compatibility.txt"%sample domain knowledge about compatibility between bioconceptscompatible(’IL-2_gene_expression’,’Protein_molecule’). compatible(’NF-kappa-B_activation’,’Protein’).compatible(’reactive_oxygen_production’,’Protein_molecule’).%the content of file"test_example.txt"%a sample sentence to disambiguate%we assume that base NPs have been identified beforehands1:-X=[’IL-2_gene_expression’,and,’NF-kappa-B_activation’,\ through,’CD28’,requires,’reactive_oxygen_production’,\by,’5-lipoxygenase’,’.’],parse(X).[’IL-2_gene_expression’]<:>np(’IL-2_gene_expression’).[and]<:>conj(and).[’NF-kappa-B_activation’]<:>np(’NF-kappa-B_activation’). [through]<:>prep(through).[’CD28’]<:>np(’CD28’).[requires]<:>verb(require).[’reactive_oxygen_production’]<:>np(’reactive_oxygen_production’). [by]<:>prep(by).[’5-lipoxygenase’]<:>np(’5-lipoxygenase’).[’.’]<:>eos(’.’).Appendix C:the Execution of Testing Sentences%the execution results of the testing sentence on SICSTUS 3.8.4|?-s1.<0>IL-2_gene_expression<1>and<2>NF-kappa-B_activation\<3>through<4>CD28<5>requires<6>reactive_oxygen_production\ <7>by<8>5-lipoxygenase<9>.<10>all(0,10),begin(-1,0),end(10,11),subtype(’NF-kappa-B_activation’,’BioProcess’),subtype(’CD28’,’BioEntity’),compatible(’NF-kappa-B_activation’,’CD28’),subtype(’IL-2_gene_expression’,’BioProcess’),subtype(’CD28’,’BioEntity’),compatible(’IL-2_gene_expression’,’CD28’),subtype(reactive_oxygen_production,’BioProcess’),subtype(’5-lipoxygenase’,’BioEntity’),compatible(reactive_oxygen_production,’5-lipoxygenase’),verb(5,6,require),np(0,5,’IL-2_gene_expression’+through+’CD28’),subj(0,5,’IL-2_gene_expression’+through+’CD28’),conj(0,5,and),np(0,5,’NF-kappa-B_activation’+through+’CD28’),subj(0,5,’NF-kappa-B_activation’+through+’CD28’),obj(6,7,reactive_oxygen_production),sentence(0,7,s(’NF-kappa-B_activation’+through+’CD28’,require,\reactive_oxygen_production)),sentence(0,7,s(’IL-2_gene_expression’+through+’CD28’,require,\reactive_oxygen_production)),eos(9,10,’.’),np(6,9,reactive_oxygen_production+by+’5-lipoxygenase’),obj(6,9,reactive_oxygen_production+by+’5-lipoxygenase’),sentence(0,9,s(’NF-kappa-B_activation’+through+’CD28’,require,\reactive_oxygen_production+by+’5-lipoxygenase’)), sentence(0,9,s(’IL-2_gene_expression’+through+’CD28’,require,\reactive_oxygen_production+by+’5-lipoxygenase’))?yes|?-。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2018年19期总第407期翻译研究ENGLISH ON CAMPUSA Comparative Analysis of James Legge and Ku Hung-ming’s English Versions in Xue Er from the Perspective of Cultural Filter文/孙艳【Abstract】As one of the most representative works of China, Lun Yü has been playing a very important part bothat home and abroad. James Legge and Ku Hung-ming ’s English versions both are popular among foreign readers and made great contributions to the transmission of Chinese culture. This thesis uses a comparative study on Ku’s and Legge’s versions of “Zi” and “君子” in Xue Er which is the first chapter of Lun Yü, from the perspective of cultural filter to simply analyze the characteristic of the two English versions. Through the analysis, this study finds that cultural filter occurs due to the cultural differences and the translator’s consideration of cultural elements both within and beyond the text.【Key words】Comparative Analysis; Cultural Filter; English Versions;Xue Er【作者简介】孙艳(1991.5.11- ),女,汉族,现就读于西安外国语大学英文学院2016级翻译学专业,主要研究方向:翻译理论与实践研究。
1. IntroductionLun Yü is said to be written by Confucius’s disciples, is mainly about the words and acts of the central Chinese thinker and philosopher Confucius and his disciples. By studying the two English versions translated by James Legge and Ku Hung-ming from the perspective of cultural filter, we found out that Ku Hung-ming’s version stresses the moral demands of Chinese Confucianism. He tends to use more liberal translation.(赵倩慧,p22-p23). James Legge’s translation is one of the most classical one among many foreign translation. In his translation, we can find more literal translation and more sameness in thinking patterns and syntactic structures. His wording is very simplified and concise. However, they all filter some Chinese ancient cultural words.2. Cultural FilterBy studying translation together with text and context, House interprets cultural filter from a sociological perspective. In his bookTranslation Quality Assessment : Past and present(p68), he explains cultural filter is a means of capturing socio-cultural differences in expectation norms and stylistic conventions between the source and target linguistic-cultural communities. The concept was used to emphasize the need for empirical bases for any ‘manipulations’ on the original undertaken by the translator.3. Comparison Analysis of the Two Versions from the Perspective of Cultural Filter3.1.1 The translation of “Zi”From the whole Xue Er, we can find “Zi” which especially refers to Confucius is used for ten times. Ku Hung-ming translates them as “Confucius”, while Legge translates them into “The Master”.On the translation of the two English versions, Ku’s version is literal translation which is specific and conveys the meaning of the source text comparatively accurate. While Legge’s translation on this word is free translation, the reference is relatively broad. “子” has the specific Chinese meaning especially referring to Confucius who is a Chinese teacher, politician, and philosopher of the Spring and Autumn period of Chinese history. Legge’s version filters the specific Chinese meaning.3.1.2 The translation of “君子”In the whole Xue Er, “君子” appears four times. Ku translates it as “A wise and good man and “a wise man”. While Legge translates it into “a man of complete virtue”, “the superior man ” and “the scholar”.What kind of people can be called “君子” at Confucius’s time? It is explained in the dictionary(《古汉语常用字字典》,p225):“ 1. 对统治者和贵族男子的尊称;2. 指有道德或学问修养的人;3. 对对方的尊称;4. 妻子称丈夫;5. 称自己的父亲。
” According to these translations, the strategy of Legge’s version is domestication which entails translating in a transparent, fluent, ‘invisible’ style in order to minimize the foreignness of the TT. And it is easy for the English readers to understand and accept. As is well-known, “君子” in Chinese ancient time also has its specific meaning. Ku and Legge all filter the Chinese meaning and don’t convey the Chinese special meaning specifically. 4. ConclusionIn conclusion, Cultural Filter is receivers’ conscious or unconscious choice, transformation, disguise, etc, of the communicated information because of their different cultural tradition, historical background, aesthetic habits, etc, which changes the original information in content and form. Generally speaking, the larger the cultural gap between two cultures, the more original culture will be filtered. References:[1]Juliane House(2015).Translation Quality Assessment:Past and pre-sent,Routledge.239。