第三届泰迪杯全国大学生数据挖掘竞赛
评审教学为主型副教授综合材料一览表

国家级,百强奖
第一指导教师
22号_201803
2018美国大学生数学建模竞赛(MCM/ICM),
指导学生:朱倩楠_本,闫琳_本,余鑫怡_本
国家级,二等奖
第一指导教师
23号_201803
2018美国大学生数学建模竞赛(MCM/ICM)
指导学生:杨怡兰_本,丁国荣_本,柯胜_本
26号_201903
2019美国大学生数学建模竞赛(MCM/ICM)
指导学生:陈昕妍_本、李飞翔_本、邓双玲_本
国家级,三等奖
第一指导教师
27号_201903
2019美国大学生数学建模竞赛(MCM/ICM)
指导学生:周瑞雪_本、童梦_本、余楠_本
国家级,三等奖
第一指导教师
28号_201903
2019美国大学生数学建模竞赛(MCM/ICM)
第七届“泰迪杯”全国大学生数据挖掘挑战赛,
指导学生:李飞翔_本,沈晗_本,陈昕妍_本
国家级,三等奖
第一指导教师
省级奖项
48号_201706
第五届“泰迪杯”全国大学生数据挖掘挑战赛,
指导学生:张艳娜_研,李甜_研,田静静_研
省级,一等奖
第一指导教师
49号_201706
第五届“泰迪杯”全国大学生数据挖掘挑战赛,
2017中国高校sas数据分析大赛湖北赛区初赛,
指导学生:李杰_本,李家慧_本,曾醒_本
省级,二等奖
第一指导教师
55号_201710
2017中国高校sas数据分析大赛湖北赛区初赛,
指导学生:杨怡兰_本,陈克婷_本,张艳_本
省级,三等奖
第一指导教师
56号_201706
泰迪杯全国大学生数据挖掘竞赛试题

第三届泰迪杯全国大学生数据挖掘竞赛试题说明:1、参赛选手可从下述试题中任选一题作答,并在论文报告中标明2、论文等级会综合考虑论文质量和难度系数试题一基于电商平台家电设备的消费者需求及产品数据挖掘分析(难度系数:1.0)试题来源:背景:随着互联网与移动互联网的快速发展,截止2014年6月,我国的网民规模达6.32亿,互联网普及率为46.9%,2015年中国网民的渗透率将接近50%。
2014年天猫双十一的交易额达571亿,网上购物将成为人民生活的一部分。
网民在电商平台上浏览和购物,产生了海量的数据,如何利用好这些碎片化、非结构化的数据,将直接影响到企业产品在电商平台上的发展,也是大数据在实际企业经营中的应用。
对于用户在电商平台上留下的评论数据,运用文本分析方法,了解用户的需求、抱怨,购买原因以及产品的优点、缺点,对于改善家电设备产品及用户体验有着重要的意义。
据观研天下行业分析:近年来我国家电设备销量增长迅速,以电热水器为例,2011年电热水器市场销量比2010年增长2.29%,销售额增长5.23%;2013年热水器零售量达到2842万台,零售额达到459亿元,2014年热水器整体规模向上,但增速较2013年有所回落,零售量达到2985万台,零售额达到504亿元。
需求:1、分析用户对于热水器/净水器产品的个性化需求;2、分析现有电商热水器/净水器的产品劣势(用户抱怨点)及产品优势(用户赞点);3、分析各品牌的产品间的差异,进行差异化卖点提炼;4、分析用户购买的原因;5、对用户的购买行为进行分析挖掘(搜索关键字、购买时关注点、购买步骤、使用、评价)(此部分可选择来做)。
提示:1、在电商平台进行评论数据抓取(可用火车头采集器进行评论爬虫);2、对评论数据进行预处理(处理掉水军及随意发表的评论数据);3、可分品类进行细化分析(热水器:电热热水器、燃气热水器;净水器:净水机、纯水机);4、对评论数据进行文本分析(好评、差评、中文分词、词频统计、情感分析、语义网络);5、可利用百度指数、淘宝指数等互联网工具对热水器和净水器的消费人群及搜索关注点进行分析;6、建议在国内外相关文献的基础上尽量选择新技术手段进行挖掘,比如基于深度学习理论模型完成情感分析,参见文献:《基于深度学习的微博情感分析》、《基于深度学习的文本情感分类研究》等。
第四届泰迪杯全国数据挖掘挑战赛

基于深度学习和语言模型的印刷文字 OCR 系统
苏剑林 曾玉婷 华南师大学数学科学学院
2016 年 5 月 15 日
中文摘要
我们设计了一系列的算法,完成了文字特征提取、文字定位等工作,并基于卷积神经网络 (CNN) 建立了字符 识别模型,最后结合统计语言模型来提升效果,成功构建了一个完整的 OCR(光学字符识别) 系统. 在特征提取方面,我们抛弃了传统的“边缘检测 + 腐蚀膨胀”的方法,基于一些基本假设,通过灰度聚类、图层 分解、去噪等步骤,得到了良好的文字特征. 这部分文字特征既可以用于第二步做文字定位,又可以直接输入到第 在文字定位方面,我们通过邻近搜索的方法先整合特征碎片,得到了单行的文字特征,然后通过前后统计的方 法将单行的文字切割为单个字符. 测试表明,这种切割思路能够很好地应对中英文混排的文字切割. 在光学识别方面,我们基于 CNN 的深度学习模型建立了单字识别模型,自行生成了 140 万的样本进行训练, 能有 90% 左右的正确率. 三步的模型中进行识别,而不用做额外的特征提取工作.
迪
均匀切割 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
第三届泰迪杯全国大学生数据挖掘竞赛

第三届“泰迪杯”全国大学生数据挖掘竞赛优秀作品作品名称:城市供水处理混凝投药过程的建模与控制荣获奖项:二等奖作品单位:湖北工程学院作品成员:贾园园万爽裴幸智指导教师:张学新基于BP神经网络的最佳投药量预测摘要:混凝投药通过投加混凝剂除去原水中的杂质及其他有害物质,是城市供水过程中的重要环节之一,这一过程效果的好坏将直接影响后续处理工艺及出水水质的好坏。
该过程具有影响因素多、大滞后性和非线性等特征,实际控制难度较大。
本文基于广州南沙水厂提供的9397个投药控制数据,尝试构建一种基于BP神经网络混凝投药控制模型,来预测混凝剂的最佳投药量。
对于原数据集有缺失值情况,本文做基本预处理,用三次样条插值法对出水浊度进行插值估算,并剔除5 外的极端异常值,按照出水浊度小于1.10NTU的标准,筛选出投药合格的6143个数据,以此作为样本数据。
针对第(1)问,本文运用平流沉淀理论,求得原水混凝沉淀到出水结束的滞后时间,约为80分钟,在实际范围70min--120min内。
针对第(2)问,本文以原水浊度、原水流速、原水PH值三个因素作为BP神经网络模型的输入神经元参数,对混凝剂投加量的训练样本和测试样本进行分析,得到预测的最佳投药量;针对第(3)问,在第二问之上,增加出水浊度做为输入参数再次建立BP神经网络模型,并与第(2)问的模型进行比较。
为了比较模型性能,我们又建立多元线性回归模型,找出四个变量与投药量的回归方程,通过在训练样本与测试样本上的预测效果,对BP神经网络模型和多元回归模型进行比较,分析绝对误差等指标,发现BP神经网络具有更强的非线性逼近能力,能够对投药量进行很好的仿真和预测效果。
针对第(4)问,本文查找文献[8],引入温度数据,验证文献[9]的理论模型,通过对数变换化为线性模型,并对模型的整体显著性和温度系数的显著性作检验,但是最后结果表明系数的显著性并不强,即温度对投药量的影响并不大,并从有关化学理论角度对此结果进行解释。
2015竞赛获奖情况统计
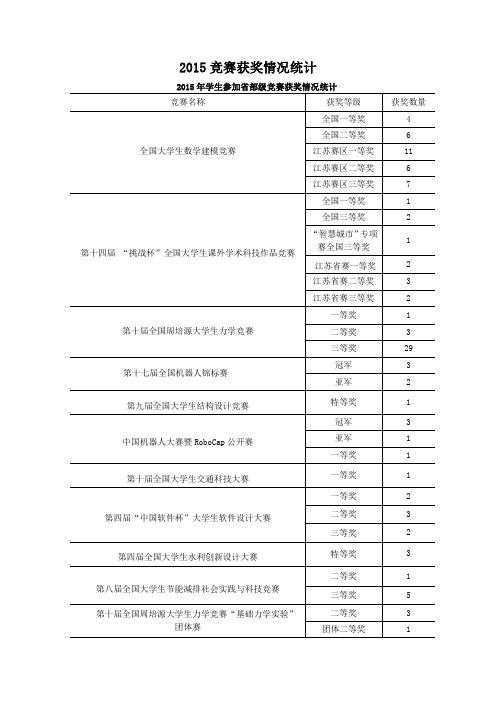
1
全国三等奖
1
华东赛区特等奖
3
华东赛区一等奖
3
“创新创业杯”全国管理决策模拟大赛
特等奖
1
二等奖
8
全国高等院校企业竞争模拟大赛
特等奖
1
一等奖
1
二等奖
2
全国大学生创业综合模拟大赛
二等奖
1
第六届全国大学生数学竞赛
全国二等奖
1
省一等奖
20
省二等奖
33
省三等奖
23
第六届中国大学生服务外包创新创业大赛
三等奖
1
全国大学生英语竞赛
全国三等奖
1
江苏赛区特等奖
2
江苏赛区一等奖
16
江苏赛区二等奖
46
江苏赛区三等奖
88
第一届全国高校云计算应用创新大赛
二等奖
2
第六届“蓝桥杯”全国软件和信息技术专业人才大赛
全国选拔赛创业团队赛一等奖
1
全国选拔赛创业团队赛二等奖
2
全国总决赛创业团队赛二等奖
1
全国二等奖
13
全国三等奖
2
江苏赛区一等奖
4
江苏赛区二等奖
6
江苏赛区三等奖
1
第七届全国大学生广告艺术设计大赛
全国三等奖
2
省一等奖
1
省二等奖
2
省三等奖
7
第九届江苏省大学生力学竞赛
特等奖
6
一等奖
56
二等奖
91
团体特等奖
1
第九届江苏省大学生力学竞赛“基础力学实验”团体赛
特等奖
2
一等奖
1
山东科技大学学生科技创新竞赛、学科专业竞赛类别等级认定名单

185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215
山东省大学生网络安全技能大赛 山东省大学生软件设计大赛 山东省大学生移动互联网创新创业大赛 “蓝盾杯”网络空间安全竞赛 “有人杯”山东省大学生单片机应用创新设计大赛 “有人杯”山东省大学生物联网创造力大赛 “小码哥杯”Java程序设计竞赛 陕西省网络空间安全技术大赛 上海国际大学生广告艺术节 山东国际大众艺术节暨创意未来·山东艺术设计大赛 齐鲁工业设计大赛 上海国际大学生广告节设计大赛 “典冀杯”山东省管乐大赛 中国·寿光文化产业博览会视觉艺术大赛 全国大学生工业设计大赛(山东赛区) 山西文化创意设计大赛 山东省大学生艺术展演活动 山东省大学生电子与信息技术应用大赛 山东省单片机应用设计大赛 山东省大学生与研究生物理教学技能大赛 “迈迪网杯”齐鲁大学生机器人大赛 全国部分地区大学生物理竞赛 “浪潮杯”山东省ACM大学生程序设计竞赛 山东省大学生物理竞赛 山东省大学生数学竞赛 APMCM亚太地区大学生数学建模竞赛 数学中国数学建模国际赛 五一数学建模竞赛 “认证杯”数学中国数学建模网络挑战赛 华中地区大学生数学建模邀请赛 山东省大学生生物化学实验技能大赛
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 90 91
全国大学生地球物理竞赛 全国大学生物联网设计竞赛 中国大学生计算机设计大赛 全国并行应用挑战赛 CCF大学生计算机系统与程序设计竞赛 信息安全铁人三项赛 世界大学生超级计算机竞赛 “华为杯”中国大学生智能设计竞赛 中国大学生程序设计竞赛 全国研究生移动终端应用设计创新大赛 全国大学生数字媒体科技作品及创意竞赛 全国大学生互联网软件设计大奖赛 中国研究生公共管理案例大赛 全国法律专业学位研究生法律文书写作大赛 全国高校秘书专业技能大赛 中国策大学生营销策划大赛 全国高等院校秘书专业知识技能大赛 全国公共管理案例分析大赛 Philip C. Jessup国际法模拟法庭辩论赛 德国威斯巴登国际钢琴比赛亚太赛区 中国创新设计红星奖 孔雀奖全国高等艺术院校声乐大赛 IADA国际艺术设计大赛(互艺奖) 全国高等学校建筑与环境设计专业学生美术作品大奖赛 中国高等院校设计艺术大赛 新加坡中新国际音乐比赛中国赛区选拔赛 意大利索利斯塔国际声乐大赛中国赛区 红点奖 中国研究生电子设计大赛 全国移动互联创新大赛 “罗麦杯”中国研究生未来飞行器创新大赛
大学生数学建模竞赛介绍

2015 OUTSTANDING WINNERS
• THE FIVE OUTSTANDING WINNERS OF THE CONTINUOUS MCM (A) PROBLEM ARE: • Northwestern Polytechnical University, China • State University of New York, University at Buffalo, NY — MAA Prize Recipient • Chongqing University, China — SIAM Prize RecipientCentral South University, China — Ben Fusaro Award • University of Adelaide, Australia — INFORMS Prize Recipient • THE FIVE OUTSTANDING WINNERS OF THE DISCRETE MCM (B) PROBLEM ARE: • University of Colorado Boulder, CO — SIAM Prize Recipient & Two Sigma Scholarship Award • Bethel University, MN — MAA Prize Recipient & Frank Giordano Award • University of Colorado Boulder, CO • Colorado College, CO — INFORMS Prize Recipient • Tsinghua University, China • THE FIVE OUTSTANDING WINNERS OF THE INTERDISCIPLINARY ICM (C) PROBLEM ARE: • Xidian University, China • Shanghai Jiao Tong University, China • Xi'an Jiaotong University, China — Leonhard Euler Award • Tsinghua University, China • National University of Defense Technology, China • Also winning as a FINALIST is: • University of Colorado Denver, CO — INFORMS Prize Recipient • THE FOUR OUTSTANDING WINNERS OF THE INTERDISCIPLINARY ICM (D) PROBLEM ARE: • NC School of Science and Mathematics, NC — INFORMS Prize Recipient • Xi'an Jiaotong University, China • Humboldt State University, CA — Rachel Carson Award & Two Sigma Scholarship Award • Zhejiang University, China
泰迪杯数模优秀论文

第四届“泰迪杯”全国数据挖掘挑战赛作品单位:北京林业大学作品成员:孙海锋郑中枢杨武岳指导老师:崔晓晖网络招聘信息的分析与挖掘摘要近年来,随着互联网的广泛应用和网络招聘的迅速发展,网络招聘信息平台已成为招聘者获取信息的主要渠道。
因此,运用网络文本分析和数据挖掘技术对网络招聘信息的研究具有重大的意义。
对于问题1,通过PositionId对招聘信息表、职位描述表进行去重,得到不重复的招聘职位信息。
利用jieba中文分词工具对岗位描述信息进行分词,并通过TF-IDF算法提取每个职位描述的前5个关键词。
再利用TF-IDF算法得到每个职位描述的TF-IDF权重向量,采用K-means对TF-IDF权重向量进行聚类,得到7个质心。
分别求出距离各个质心最近的5个职位,结合招聘信息表的PositionFirstType字段,根据KNN算法,为各个类加上行业性质标签。
再分别对各个职业类型的PositionName进行统计分析,得出各个职业类型对应的专业领域。
对于问题2,通过利用excel对去重后的招聘信息表对行业领域、工作地域、职位分类三个项目进行分类筛选,对各个项目的各类内容进行计数汇总统计,根据计数多的内容去定于热门的行业、地域、职位。
对于问题3,根据数据挖掘与分析的职位特征,将新兴的职位定义为两大类并分别筛选出来。
利用发散性思维,再分别对筛选出来的结果按照城市(city)、公司阶段(financestage)、学历要求(Education)、薪资(Salary)四个方面对其进行多方面系统地统计,结合图表进行分析预测相关职位的需求。
对于问题4,通过寻找it职位对应的id的职业描述,并对其分词和it专业语义库构建,在此基础上筛选出所有的it职位。
对附件1进行数据预处理,在预处理得到的数据上进行数据初步筛选出it行业的职位。
对筛选出的it职位对应的职业id找到职位描述表的职位描述,对该描述构建it专业语义库。
判断职业描述表中职位是否符合it职业,通过判断与专业语义库的交集长度来确定是否为it职业并统计地域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三届“泰迪杯”全国大学生数据挖掘竞赛优秀作品作品名称:基于电商平台家电设备的消费者评论数据挖掘分析荣获奖项:一等奖作品单位:华南师范大学作品成员:赵晓荣叶呈成黄佳锋指导老师:薛云基于深度学习的电热水器评论数据挖掘分析摘要:近年来,随着互联网的广泛应用和电子商务的迅速发展,网络文本及用户评论分析意义日益凸显,因此网络文本挖掘及网络文本情感分析技术应运而生,通过对文本或者用户评论的情感分析,企业能够进行更有效的管理等。
本文针对电商平台的电热水器的评论数据,利用基于半监督递归自编码(RAE)的深度学习模型,进行评论的情感分析。
为了保证评论数据挖掘分析的质量和全面性,我们重新从京东和苏宁易购平台爬取了评论数据集,对数据进行预处理——评论“去空、去重”、中文分词、停用词过滤等,再利用半监督RAE深度学习模型对这些评论进行情感分析。
之后,本文主要进行两个方面的数据挖掘分析工作:一方面是根据不同品牌电热水器的评论数据情感分析结果,提炼出各个品牌产品的差异化卖点;另一方面是根据不同电商平台的评论数据情感分析结果,进行不同电商平台的服务质量比较,进而可以使电商平台根据自身优势吸引消费者。
关键词:深度学习,情感分析,RAE,差异化卖点Data Mining on Comments of Electric water heaterBased on Deep LearningAbstract: Recently, with the wide application of Internet and the rapid development of electronic commerce, network text and user review analysis is of great significance, text mining and sentiment analysis of network text arise at the historic moment, and the emotional analysis of the text or user comments is more effective in enterprise management and so on. Electric business platform, this paper apply a deep learning method based on semi-supervised recursive encoding (RAE) on analysis of the emotion of comments which users delivered about electric water heater. In order to ensure the quality of the data mining analysis, we crawled the relevant comments data sets from Jingdong and Suning platform. Then we preprocessed comments data on wiping "empty and heavy" out, Chinese word segmentation, filtering stop words, word frequency statistics, etc. Next we analyze sentiment on these comments using a method based on semi-supervised RAE. Later, this paper analyzed mainly comments in two aspects of data mining work: on the one hand, according to sentiment analysis result of the comments of different brand electric water heater, extracting differentiation of various brand products selling point; On the other hand, according to the comments of different electric business platform data sentiment analysis results, and compare different electric business platform of service quality, and electric business platform can take measures to attract consumers according to their own advantages .Key words:deep learning; sentiment analysis; RAE; differentiation of selling point目录1.挖掘目标 (1)2.分析方法与过程 (1)2.1.总体流程 (1)2.2.具体步骤 (2)2.3.结果分析 (18)3.结论 (20)4.参考文献 (21)1.挖掘目标本次建模针对电商平台上关于电热水器的评论数据,采用基于半监督RAE 深度学习模型的数据挖掘方法,达到以下两个目标:1)利用半监督RAE模型对同一品牌电热水器的评论进行情感分析,根据分析结果得到用户针对各属性的满意度,从而提炼出该产品的优势和劣势。
分析不同品牌电热水器的评论数据,提炼出其差异化卖点。
2)对不同电商平台对应相同电热水器的评论数据进行情感分析,根据分析结果得出各个电商平台服务的优势与劣势。
2.分析方法与过程2.1.总体流程图1 总体流程图本用例主要包括以下几个步骤:步骤一:爬取网络评论数据,评论数据的获取是本次数据挖掘分析的第一步。
本文中利用火车头数据采集器,对评论文本进行抽取,最后将评论文本批量存进txt 文件中,得到实验数据。
步骤二:数据预处理,直接从网上爬取的评论数据中往往不能直接分析需要进行数据预处理。
第一步要“去空、去重”;第二步对评论数据进行中文分词,将一句评论分成多个词语进一步分析;第三步进行停用词过滤,去除掉评论中与情感判定不相关的词。
步骤三:文本矩阵转化,使用基于半监督RAE深度学习模型进行情感分析,需要将文本词语全部转换为词向量,本论文中构建了一个词表和词向量表,词表中为全部文本词语和词语的编号,词向量表中为全部词语的词向量。
步骤四:情感分析,构建基于半监督RAE的深度学习模型,利用选出的积极、消极评论各占一半左右的数据集训练情感分析模型,并进行测试,得到符合要求的模型。
利用构建的模型分析得出评论数据的情感倾向。
步骤五:属性提取并统计,将所有提及到电热水器的某些属性的评论数据从实验数据集中筛选出来,统计各个属性相关评论数据的积极评论和消极评论占该产品的积极评论和消极评论的百分比。
步骤六:结果分析,根据分析结果提取产品的差异化卖点或者每个电商平台的竞争优势和劣势,进而制定合适的营销策略。
2.2.具体步骤步骤一:爬取网络评论数据随着电子商务的迅速发展,网购的消费者越来越多,他们不再只是被动的获取网络知识,而是可以通过网络发表产品评论来分享自己的用户体验,而评论中所包含的丰富信息, 对企业管理具有重要的价值。
通过数据挖掘等技术手段实现对客户评论的智能分析,商家可以获得客户对产品的意见和态度,获取网络评论数据中的有价值的信息,做出相应的营销策略和产品改进方案等。
而网络数据挖掘分析的第一步就是爬取网络评论数据。
本次论文中采用火车头数据采集器爬取网上评论数据,将批量的URL存放进采集队列中,设置采集内容的规则,从评论网页上爬取实验需要的评论文本数据,详细步骤如下:1)采集网址规则我们首先采集美的F50-21W6的评论数据,打开它的评论页面我们要采集的评论共有6065条,分203页显示,如图2所示:图2 美的F50-21W6评论页面为采集该商品的所有评论数据,这里采用批量网址采集,将203个网址导入进行数据采集,如图3所示:图3 批量网址采集规则设置2)设置采集内容规则为了抽取出网页中有用的网络商业评论信息,还需要对采集内容规则进行设置。
首先在京东网上打开美的F50-21W6的评论页面,可以看到在京东网上评论的标签为“心得”。
接下来打开该页面的源代码,搜索到“心得”部分,可以发现它的结构如下:<dl><dt>心得:</dt><dd>不错!性价比非常高!</dd></dl>其中的“不错!性价比非常高!”就是我们想要的网络商业评论文本。
最后,根据评论在HTML文档中的结构分布,设置采集内容规则,如图4所示图4 采集内容规则设置3)结果发布为了后续研究工作的方便,本文选择将采集到的网络商业评论存储在同一个txt文件中,文件编码为”UTF-8”,最终得到一个存储全部评论文本的txt文件。
美的F50-21W6的评论示例如下:美的电热水器质量不错,价格比店里要便宜。
物流给力机子不错很好很好看也很实用,配送很快,安装师傅人也很好的。
头天下单,第二天就到货安装好了,非常满意本文实验中:从京东上选择了三个品牌的电热水器的评论数据进行抓取——美的F50-21W6、海尔EC5002-D、格兰仕G50E302T,用于提炼不同品牌产品的差异化卖点;从苏宁易购上爬取了美的F50-21W6电热水器的评论数据,用于比较和京东电商平台的服务特点。
本次实验数据见附件。
步骤二:数据预处理与数据库中的结构化数据相比,从网页上爬取的数据属于半结构化或者非结构化数据,即具有有限的结构,或者根本就没有结构,即使具有一些结构,也是着重于格式,而非文档内容,不同类型文档的结构也不一致。
此外,网页数据缺乏机器可理解的语义,而数据挖掘的对象局限于数据库中的结构化数据,并利用关系表格等存储结构来发现有价值的信息,因此有些数据挖掘技术并不适用于网络文本挖掘,即使可用也需要建立在对网络文本数据进行预处理的基础之上。
如果要对网络评论数据进行情感分析,就必须先将文本数据进行预处理,转化为结构化的数据。
该步骤中,从以下几个方面对步骤一中从网页上爬取的评论数据进行预处理。
1)“去重”、“去空”对于存储了全部网络商业评论的txt文件,每行代表了一个评论文本但是难免会出现两个完全一样的文本和一些空行。