统计SPSS数据文件的建立和管理
SPSS统计分析- 第2章 数据文件建立和管理

4.读取“*.txt”数据文件
现需将“人居收入.txt”文件中的数据读入SPSS,如图所示: (1) 打开“数据编辑器”对话框,选择“文件”|“打开文本数据”命令,打 开“打开数据”对话框。选择文本文件,单击“打开”按钮,打开“文本导入向 导”对话框,如图所示:
(2) 在“您的文本文件与 预定义的格式匹配吗? ” 选项组中选择 “ 是 ” 单选 按钮,可单击“浏览” 按 钮,选择已预定义好的 格式;单击 “ 否 ” 则需要 建立一个新格式。
2.1.1 打开定义变量视图
• 按前一章所述打开SPSS主界面,视图切换标签处单击“变 量视图”,即打开“变量视图”窗口,如图所示。在该视 图可对变量的以下属性进行定义:名称、类型、宽度、小 数、标签、值、缺失、列、对齐、度量标准和角色。
2.1.2 定义变量名称
• 在“变量视图”变量栏的“名称”栏中定义变量名称,用 户可根据数据需要或个人习惯进行定义,如果不对变量进 行定义,系统将自动默认变量名为var00001、var00002、 var00003等。一般根据变量的实质意义来命名,例如:年 龄、性别、年级等变量,可用Age,Gender,Grade命名,也 可用中文意义命名,但当出现变量数量较大时,一般使用 流水编号,即防混淆又方便。虽然变量可根据用户的需求 自行编辑,但仍有其需共同遵循的原则: • 若用英文命名,变量名首字必须为英文字母,其后方可接 数字、英文字母、@等。若用中文命名,则可直接使用。 • 不可使用空格和特殊字符(如键盘上的!、#、$、%、&、 ^、*、(、)、?等字符)。
(9) 之后进入下一步,如图所示。在“变量之间有哪些分隔符?”中,可根据 文本数据中变量间的分隔符,可选择“制表符”、 “空格”、“逗号 ”、“分号” 和“其他”复选框。在“文本限定符是什么?”中,可选择“无”、“单引号”、“ 双引号”和“其他”单选按钮,一般默认为“无”,选择完毕后单击“下一步” 。
SPSS之数据文件的建立和编辑

在上图所示的窗口中每一行表示一个变量的 定义信息,包括Name、Type、Width、 定义信息,包括 、 、 、 Decimal、Label、Values、Missing、 、 、 、 、 Columns、Align、Measure等。 、 、 等
个学生的高数、 例1、调查 个学生的高数、线代和概率论 、调查10个学生的高数 的成绩,并将数据输入到SPSS文件中。 文件中。 的成绩,并将数据输入到 文件中 定义变量; ( ⅰ )定义变量; 输入数据。 ( 接数值型的常数、变 量和函数构成算术表达式,其运算结果 为数值型常数。 2.运算优先顺序:括号、函数、乘幂、乘 除、加减;同一优先级按照从左到右的 顺序
关系表达式
1. 是比较两个量之间的关系或判断关系是否 成立。如果成立表达式的值为“真”(1), 否则为“假”(0)。 2.比较无论是数值或字符都可以。 3.符号与运算符等价。如:A>5等价于AGT5
• 输入数据前首先要定义变量。定义变量即要定 输入数据前首先要定义变量。 义变量名、变量类型、变量长度(小数位数)、 义变量名、变量类型、变量长度(小数位数)、 变量标签(或值标签)和变量的格式。 变量标签(或值标签)和变量的格式。 • 单击数据编辑窗口左下方的“Variable View” 单击数据编辑窗口左下方的“ 标签或双击列的题头( ),进入如下图所 标签或双击列的题头(Var),进入如下图所 ), 示的变量定义视图窗口, 示的变量定义视图窗口,在此窗口中即可定义 变量。 变量。
SPSS中的表达式 SPSS中的表达式
SPSS中基本运算有三种: 1、算术表达式 2、关系表达式 3、逻辑表达式
三种运算符号
数学运算符 符号 + * / ** () 意义 加 减 乘 除 幂 括号 符号 < > <= >= = ~= 关系运算符 运算符 LT GT LE GE EQ NT 意义 小于 大于 小于等于 大于等于 等于 不等于 符号 & | ~ 逻辑运算符 运算符 AND OR NOT 意义 逻辑与 逻辑或 逻辑非
SPSS数据文件的建立和管理实验报告
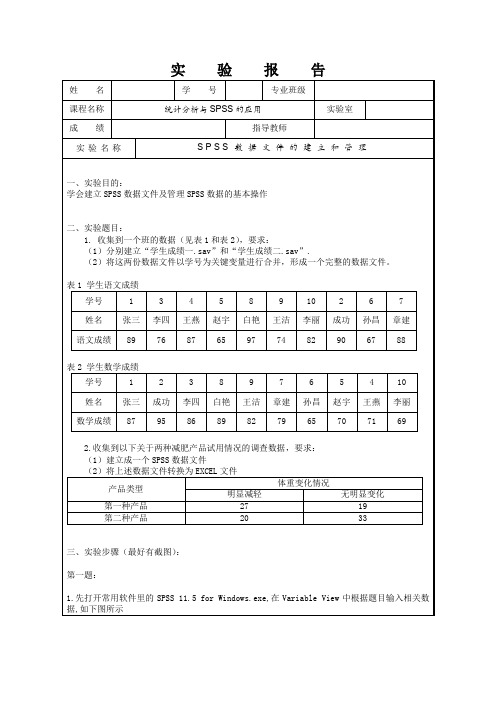
实验报告
姓名
学号
专业班级
课程名称
统计分析与SPSS的应用
实验室
成绩
四、实验结果及分析(最好有截图):
第一题:
根据题中要求,要将这两份数据文件以学号为关键变量进行合并,通过横向合并数据文件可实现.
1.在数据编辑窗口中打开需合并的SPSS数据文件
2.选择菜单:【Data】→【Merge File】→【Add Variables】,然后输入一个已存在于磁盘上的需进行横向合并处理的SPSS数据文件名
2.在Data View中先输入数据,再选中“学号”一列,选择升序排列,结果如下图所示
3.对第一个表格进行保存,并且命名为“学生成绩一.sav”
4.重新打开一个表格,在Variable View中根据题中要求输入数据,如下图所示
5.在Data View中先输入数据,再选中“学号”一列,选择升序排列,结果如下图所示
指导教师
实验名称
SPSS数据文件的建立和管理
一、实验目的:
学会建立SPSS数据文件及管理SPSS数据的基本操作
二、实验题目:
1.收集到一个班的数据(见表1和表2),要求:
(1)分别建立“学生成绩一.sav”和“学生成绩二.sav”.
(2)将这两份数据文件以学号为关键变量进行合并,形成一个完整的数据文件。
3.选中“Match cases on key variables in sorted files”,将“学号”放入“Key Variables”中,结果如下所示
实验二SPSS数据录入与编辑

实验二SPSS数据录入与编辑SPSS数据录入与编辑一、引言SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、市场调研、医学研究等领域。
在进行数据分析之前,首先需要将原始数据录入到SPSS软件中,并进行必要的数据编辑。
本文将详细介绍SPSS数据录入和编辑的标准格式。
二、数据录入1. 打开SPSS软件并创建新的数据文件。
在SPSS软件界面上方的菜单栏中,选择"File" -> "New" -> "Data",创建一个新的数据文件。
2. 定义变量名称和属性。
在数据文件中,每一列代表一个变量。
在第一行录入变量的名称,确保名称准确且易于理解。
在第二行录入变量的属性,包括变量的测量类型(如数值型、字符型、日期型等)和宽度(即变量所占的字符数)。
3. 逐行录入数据。
从第三行开始,逐行录入数据。
确保每一列的数据与对应的变量匹配,避免录入错误。
4. 保存数据文件。
在菜单栏中选择"File" -> "Save",保存数据文件。
建议将文件保存为SPSS的标准格式(.sav)。
三、数据编辑1. 缺失值处理。
在数据录入过程中,可能会出现一些数据缺失的情况。
可以使用SPSS软件提供的缺失值标记来表示缺失数据。
在数据文件中,将缺失值用特定的数值或符号表示,方便后续的数据分析。
2. 数据清洗。
数据清洗是指对数据进行筛选、排除异常值、修正错误等操作,以保证数据的质量和准确性。
可以使用SPSS软件提供的数据筛选、变量计算、数据转换等功能进行数据清洗。
3. 数据转换。
在进行数据分析之前,有时需要对数据进行转换,以满足分析的需求。
例如,可以进行数据归一化、对数变换、指标构建等操作。
SPSS软件提供了丰富的数据转换函数和操作,可以根据需求进行相应的数据转换。
第01节如何建立SPSS数据文件

第01节如何建立SPSS数据文件SPSS(Statistical Package for the Social Sciences)是一种专业的统计分析软件,被广泛应用于社会科学、市场调研以及其他领域的数据分析中。
建立SPSS数据文件是使用SPSS进行数据分析的第一步,本文将介绍如何建立SPSS数据文件的步骤。
1. 确定数据变量在建立SPSS数据文件之前,首先需要确定好需要收集和记录的各个数据变量。
数据变量包括各种观测指标或测量项目,可以是数值型、顺序型或名义型的变量。
2. 打开SPSS软件双击打开SPSS软件,进入SPSS统计分析界面。
3. 创建新数据文件在SPSS界面的主菜单栏选择"File" -> "New" -> "Data",或者直接点击工具栏上的新建数据文件图标。
弹出新建数据文件对话框。
4. 设定数据文件属性在新建数据文件对话框中,可以设置数据文件的属性,包括数据文件名、存储位置、数据文件类型等。
根据需要填写相应信息,并确定保存位置和数据文件类型。
5. 定义数据变量在数据视图窗口中,可以依次定义各个数据变量。
点击数据视图窗口中的第一个空白格,输入第一个数据变量的名称,并按下"Tab"键移动到下一个格子中。
在下一个格子中选择适当的数据类型(如数值型、字符型等)并输入数据,然后按下"Tab"键继续定义下一个数据变量。
依此类推,逐个定义好所有的数据变量。
6. 设定数据值标签在数据视图窗口中,还可以对特定的数据变量设定数据值标签。
选中某个数据变量所在的格子,点击菜单栏中的"Variable View",在弹出的对话框中输入该变量的数据值标签。
7. 保存数据文件在完成所有数据变量的定义后,点击菜单栏中的"File" -> "Save",选择保存数据文件。
数据文件的建立和管理课件

SPSS数据编辑窗口
菜单栏
编辑栏
变量名称栏
内容区
窗口切换标签栏
状态栏
数据文件的建立和管理
*
菜单栏中的选项及功能: 文件--有关文件的建立、打开、存储、显示和替换等。 编辑--有关文本内容的选择、剪切、复制、粘贴、查找和替换等。 视图--有关状态栏、工具条、网络线是否显示,以及数据显示的字体类型、大小等设置。 数据--有关数据变量定义、观察对象的选择、排序、加权、数据文件的转换、连接和汇总等。 转换--有关数值的计算、变量组段的划分、重新赋值和缺失值替代等。 分析--有关统计分析方法的应用。 图形--有关统计图表的制作。 实用程序--有关用户对软件的应用和设置等。 窗口--有关窗口的排列、选择和显示等。 帮助--有关帮助文件的调用、查找和显示等
数据文件的建立和管理
*
第2个问题涉及多个变量排序,操作和第一个问题相似,将性别,年龄,交通事故三个变量依次选入排序变量框,注意顺序不能交换(SPSS首先按第1个变量排序,变量相同时按第2个变量排序,…..),点击【升序】按钮,点击【确定】
数据文件的建立和管理
*
(1)操作简单(菜单、按钮、对话框) (2)无需编程 (3)功能强大 (4)方便的数据接口 能够读取及输出多种格式的文件,如.dbf文件、.xsl文件、.txt文件、PDF文件、word文件、Power Point 文件等。 (5)灵活的功能模块组合 SPSS for windows 软件分为若干功能模块。用户可以根据自己的分析需要和计算机的配置灵活选择。 (6)与其他程序的无缝结合 SPSS统计分析可以调用开源统计分析软件R或者开源高级程序语言python的功能模块,实现关联分析等功能。
数据文件的建立和管理
SPSS数据分析教程-2-数据文件的建立和管理
最新课件
14
数据的输入操作(2)
ID号(id) 性别(sex):1:男; 2:女
1, 2, 1, 2, 2, 1, 2, 1, 1, 1, 2, 2
身高(height)
76,59,67,65,63,72,70,68,69,74,68,63
参加活动以前的体重(before)
185 113 145 156 109 191 155 165 175 180 135 118
如果一个文件中的某个个案在另一个文件中找不到 个案来匹配,则该个案于第二个文件的变量上的取 值为缺失值。反之亦然。
如果一个文件中的某个个案在另一个文件中找到两 个或者两个以上的个案来匹配,则该个案只取第二 个文件中第一个相匹配的个案来连接。反之亦然。
最新课件
38
合并变量示意图:一对一
最新课件
39
最新课件
3
本章学习目标
理解信息、数据与数据处理的基本概念; 了解SPSS数据编辑器的特点,熟悉SPSS的变
量视图和数据视图,掌握SPSS常用的工具按 钮;
掌握数据录入SPSS软件的方法;
掌握把电子表格、数据库、文本文件等格式的 数据文件读入SPSS软件的方法;
掌握SPSS数据集的数据字典; 学习合并两个数据文件的方法; 明确分割SPSS数据文件的方法。
分析的目的是比较不同收益类型客户的概要特征。
最新课件
42
先按照关键变量“orgntype”(客户工作单 位的类型)进行合并文件。选择【数据】→ 【排序个案】 ,首先按照关键变量
“orgntype”排序。
然后选择【数据】→【合并文件】→【添加变 量】 进行合并。
最新课件
43
2.7 数据的拆分
SPSS统计软件使用指导
SPSS统计软件使用指导SPSS(统计软件包社会科学)是一个功能强大的统计分析软件,被广泛应用于社会科学领域的数据处理和统计分析。
本文将为您提供SPSS的简单使用指导。
一、数据导入与数据处理1. 数据导入:打开SPSS软件后,选择“文件”菜单中的“导入数据”,选择合适的数据类型(如Excel、CSV等),然后按照指引找到要导入的数据文件,并点击“打开”按钮导入数据。
2.数据处理:导入数据后,您可以使用SPSS进行数据清洗、数据变换和数据整合等操作。
例如,可以使用数据筛选功能去除缺失值,使用重编码功能对变量进行重新分组等。
二、数据描述统计1.频数统计:选择“分析”菜单中的“描述统计”→“频数”,将要分析的变量移至“变量列表”中,点击“统计”按钮,并选择要统计的指标(如中位数、均值等),最后点击“确定”按钮即可进行频数统计分析。
2.描述性统计:选择“分析”菜单中的“描述统计”→“描述统计”,将要分析的变量移至“变量列表”中,点击“统计”按钮,并选择要统计的指标(如均值、标准差等),最后点击“确定”按钮即可进行描述统计分析。
三、数据分析与模型建立1.相关分析:选择“分析”菜单中的“相关”→“双变量”,将要分析的变量移至“变量列表”中,点击“OK”按钮即可进行相关性分析。
2.回归分析:选择“分析”菜单中的“回归”→“线性”,将因变量和自变量移至相应的“因变量”和“自变量”框中,可以选择“统计”按钮进行相应的统计分析。
3.方差分析:选择“分析”菜单中的“比较组”→“方差分析”,将要分析的变量移至“因子”列表中以及自变量列表中,点击“OK”按钮即可进行方差分析。
四、结果输出与图表绘制1.结果输出:分析完成后,可以通过点击“结果”菜单中的“查看输出”来查看统计结果。
可以选择复制、粘贴或导出统计结果到其他软件进行进一步分析或报告。
2.图表绘制:选择“图形”菜单,其中包含了众多图表类型,如饼图、柱状图、折线图等。
实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构
实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。
spss数据文件的建立与操作
在Variable View中,定义变量的属性。
SPSS中的变量有十个属性:
变量名(Name)
变量类型(Type)
变量宽度(Width) 小数点的位数(Decimals)
变量名标签(Label) 变量值标签(Values)
1.1 数据文件的特点 1.2 定义变量 1.3 录入数据 1.4 外部数据的导入
1.1 数据文件的特点
SPSS数据文件是一种有结构的数据文件,它由数据 结构和数据内容两部分组成,其中结构部分用于定 义数据类型、宽度、缺失值等,而内容才是我们具 体要分析的数据。
SPSS数据文件的扩展名是.sav
通过一个例子理解数据文件的横向合并。
【例】将数据transform3.sav中的变量添加到 transform.sav中。
在菜单栏中选择Data | Merge Files | Add Variables命令
关于合并后的数据文件中的数据 按 哪 种 方 式 提 供 , SPSS有 三 个 选 项可供选择: 1.Both files provide cases: 是 SPSS默 认 的 方 式 , 指 合 并 后 的 数据由原来的两个数据文件共同 提供,即由原来两个数据文件中 的记录共同组成合并后的数据文 件。
在SPSS中,能使用定类尺度的数据可以是数值型,也可以是字符型变 量。必须符合穷尽和互斥的原则。穷尽的原则就是指每个个体都必须 能归为一个类别,互斥的原则是指每个个体都只能归为一个类别。
相应变量为定类变量或(无序)分类变量。
Ordinal
定序尺度是对事物之间等级或顺序差别的一种测度。 定序尺度的特点是可以测度类别差,还可以测度次序差
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第2章 SPSS数据文件的建立和管理学习目标1.明确SPSS数据的基本组织形式和数据行列的含义。
2.掌握应从哪些方面描述SPSS数据文件的结构特征。
3.熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。
4.熟练掌握在SPSS中读取Excel工作表数据的基本操作,了解读取文本和数据库数据的基本方法。
建立SPSS数据文件是利用SPSS软件进行数据分析的首要工作。
没有完整且高质质的数据,也就没有值得信赖的数据分析结论。
2.1 SPSS数据文件建立SPSS数据文件,应首先了解SPSS数据文件的特点、数据组织的基本方式和相关概念等。
只有这样才能够建立一个完整且全面的数据环境,服务于以后的数据分析工作。
2.1.1SPSS数据文件的特点SPSS数据文件是一种有别于其他文件(如Word文档、文本文件)的有特殊性的文件。
从应用角度理解,这种特殊性表现在两方面。
第一,SPSS数据文件的扩展名是.sav;第二,SPSS数据文件是一种有结构的数据文件。
它由数据的结构和内容两部分组成。
其中,数据的结构记录了数据的类型、取值说明、数据缺失情况等的必要信息,数据的内容是那些待分析的具体数据。
SPSS数据文件与一般文本数据的不同在于:一般文本文件仅有纯数据部分,而没有关于结构的描述。
正是如此,SPSS数据文件不能像一般文件那样可以直接被大多数编辑软件读取,而只能在SPSS软件中打开。
基于上述特点,建立SPSS数据文件时应完成两项任务,第一,描述SPSS数据的结构;第二,录入编辑SPSS的数据内容。
这两部分工作分别在SPSS数据编辑窗口的变量视图中完成。
2.1.2 SPSS数据的基本组织方式SPSS的数据将直观地显示在数据编辑窗口中,形成一张平面二维表格。
待分析的数据将按原始数据方式和计数数据方式组织。
一、原始数据的组织方式如果待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标,那么这些数据就可按原始数据的方式组织。
在原始数据的组织方式中,数据编辑窗口中的一行称为一个个案(case),所有个案组成完整的SPSS数据。
数据编辑窗口中的一列称为一个变量。
每个变量都有一个名字,称为变量名,它是访问和分析SPSS每个变量的唯一标识。
案例2—1为研究某地区住户的家庭住房条件和购房意向,进行问卷调查。
调查内容包括被调查者的性别、职业、年龄、家庭月收入、常住人口数、现住房面积、购房意向等问题。
现调查了2000人,得到2000份问卷数据。
具体数据在可供下载的压缩包中,文件名为“住房状况调查.sav”。
案例2—1的数据就是一份原始数据。
在SPSS数据编辑窗口中,一行存储一份问卷数据,是一个个案。
对于案例2—1,2000份问卷在SPSS中就有2000行数据,即有2000个个案。
SPSS中的一列通常应对一个问卷问题,是一个变量,每个变量都有变量名。
变量名可以与问卷题目相对应。
图2—1是该份调查数据在SPSS数据编辑窗口的数据视图中的组织样式。
二、计数数据的组织方式有时所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的计数数据。
案例2—案例2—2的数据就是一份汇总后的计数数据,而非原始数据。
在SPSS中该类数据应按计数数据的组织方式组织。
如图2—2所示。
在计数数据的组织方式中,数据编辑窗口中的一行为变量的一个分组(或多变量交叉分组下的一个分组)。
所有行囊括了该变量的所有分组情况(或多变量交叉下的所有分组情况)。
数据编辑窗口中的一列仍为一个变量,代表某个问题(或某个方面特征)以及相应的计数结果。
选择怎样的数据组织方式主要取决于收集到的数据以及今后所要进行的分析。
2.2 SPSS数据的结构和和定义方法S PSS数据的结构是对SPSS每列变量及其相关属性的描述。
它的定义是通过数据编辑窗口中的变量视图实现的。
对于案例2—1的住房调查数据,已定义好的SPSS数据结构如图2—3所示。
其中,各项内容依次变量名(Name)、列宽(Width)、小数位宽(Decimals)、变量名标签(Label)、变量值标签(Values)、缺失值(Missing)、列显示宽度(Columns)、对齐方式(Align)、计量尺度(Measure)。
其中有些内容是用户必须定义的,有些则可以忽略。
2.2.1 变量名变量名(Name)是变量访问和分析的唯一标志。
在定义SPSS数据结构时应首先给出每列变量的变量名。
SPSS数据编辑窗口中,变量名将显示在数据视图中列标题的位置上,如图2—4中所圈住的部分便是变量名。
变量的起名规则一般是:变量名的字符个数不多于8个;首字符应以英文字母开头,后面的可以跟除了!,?,*之外的字母或数字。
下划线、圆点不能为变量名的最后一个字母;变量名不区分大小写字母。
允许汉字作为变量名,汉字总数不能超过4个;变量名不能与SPSS内部特有的具有特定含义的保留字相同,如ALL,BY,AND,NOT,OR等;SPSS有默认的变量名,它以字母“VAR”开头,后面补足5位数字,如VAR00001,VAR00012等。
为方便记忆,变量名最好与其代表的数据含义相对应。
如果变量名不符合SPSS的起名规则,系统会自动给出错误提示信息。
在SPSS数据编辑窗口的变量视图中,在【Name】列下相应行的位置输入变量名即可。
如图2—5所示。
2.2.2 数据类型、列宽、小数位宽数据类型(Type)是指每个变量取值的类型。
SPSS中有三种基本数据类型,分别为数值型、字符型和日期型。
相应的类型会有默认的列宽(Width)或小数位宽(Decimals)等。
一、数值型数值型是SPSS最常用的数据类型,通常有阿拉伯数字(0-9)和其他特殊符号(如美元符号、逗号、圆点)等组成。
例如,工资、年龄、成绩等变量都可定义为数值型数据。
SPSS中数值型有以下五种不同的表现方法:1、数值型(Numeric)标准型是SPSS默认的数据类型,默认的列宽为8位,包括正负符号位、小数点和小数位在内,小数位宽默认为2位。
如果数据的实际宽度大于8位,SPSS 将自动按科学计数法显示。
需要说明的是,数据的显示并不影响真正数据的存储,也不影响数据的计算。
2.科学记数法型(Scientific Notation)科学记数法也是一种常见的数值型数据的表示方式。
例如,120用科学记数法表示为1.2E+02,其中的E表示以10为底,+02表示正的2次方。
又如,0.005用科学记数法为5.0E-03,这里—03表示负的3次方。
科学记数法的默认列宽为8,包括正负符号位、字母E和跟在其后的正负符号及两位幂次数字。
科学记法一般用来表示很大或很小的数据。
用户在输入科学记数法数据时,可以按标准型方式输入数据,SPSS会自动进行转换。
3.逗号型(Comma)逗号型数据其整数部分从个位开始每3位以一个逗号分隔,默认的列宽为8,小数位宽为2,逗号所占的位数包括在总显示宽度之内,如1,234,56。
用户在输入逗号型数据时,可以不输入逗号,SPSS将自动在相应位置上添加逗号。
4.圆点型(Dot)圆点型数据其整数部分从个位开始每3位以一个圆点分隔,以逗号作为整数和小数部分的分隔符。
它默认的列宽为8,小数位宽为2,如1.234,56。
用户在输入圆点型数据时,可以不输入圆点,SPSS将自动在相应位置上添加圆点。
5.美元符号型(Dollar)美元符号型主要用来表示货币数据,它在数据前附加美元符号$。
美元符号型数据的显示格式很多,如$###、$###,###、$#,###,##等,SPSS会以菜单方式将其显示出来供用户选择。
用户在输入美元符号型时,可以不输入美元符号,SPSS将自动在相应位置上添加美元符号。
二、字符型(String)字符型也是SPSS较常用的数据类型,它由一串字符串组成。
如职工号码、姓名、地址等变量都可定义为字符型数据。
字符型数据的默认列宽为8个字符位,它不能够进行算术运算,并区分大小写字母。
字符型数据在SPSS命令处理过程中应用一对双引号起来,但在输入数据时不应输入双引号,否则,双引号将会作为字符型数据的一部分。
三、日期型(Date)日期型用来表示日期或者时间数据,如生日、成立日期等变量可以定义为日期型。
日期型的显示格式有很多,例如,dd-mmm-yyyy,dd表示两个字符位的日期,为数据分隔符,mmm表示英文月的缩写,yyyy表示四个字符位的年份。
如25—AUG—2006表示2006年8月25日。
又例如,mm/dd/yyyy,mm表示两个字符的月份,/为数据分隔符。
dd表示两个字符位的日期,yyyy表示四个字符位的年份,如2006年8月25日也可以表示08/25/2006。
SPSS以菜单的方式将所有的日期显示格式列出来供用户选择。
在SPSS数据编辑窗口的变量视图中,在【Type】列下相应行的位置单击鼠标,并根据实际数据在弹出窗口中选择相应的数据类型,如图2--6所示。
2.2.3 变量标签变量名标签(Label)是对变量名含义的进一步解释说明,它可增强变量名的可视性和统计分析结果的可读性。
变量名标签可用中文,总长度可达120个字符,但在统计分析结果的显示中,一般不可能显示如此长的变量名标签信息。
变量名标签这个属性是可以省略的,但建议最好给出变量名的标签。
通常,如果变量名已经是中文汉字,变量名标签可以省略。
在SPSS数据编辑窗口的变量视图中,在【Label】列下相应行的位置输入变量名标签即可。
2.2.4 变量值标签变量值标签(Values)是对变量取值含义的解释说明信息,对于定类型和定序型数据尤为重要。
例如,对于性别变量,假设用数值1表示男,用数值2表示女的。
那么,人们看到的数据就仅仅是1和2这样的符号,通常很难弄清楚1代表男还是女。
但如果为性别变量附加变量值标签,并给出1和2的实际指代,则无疑会使数据含义非常清楚。
可见,变量值标签对于定序数据(如收入的高、中、低)和定类数据(如民族、性别)来说必不可少的。
它不但明确了数据的含义,也增强了最后统计分析结果的可读性。
变量值标签可以用中文。
变量值标签这个属性是可以省略的,但建议最好给出定序或定类变量的变量值标签。
在SPSS数据编辑窗口的变量视图中,在【Value】列下相应行位置单击鼠标,并根据数据在弹出窗口中指定变量值标签,如图2——7所示。
2.2.5 缺失数据缺失数据(Missing)的处理是数据分析准备过程中的一个非常重要的环节。
数据中明显错误或明显不合理的数据以及漏填的数据都可看做缺失数据。
例如,在某项客户满意度的问卷调查数据中,某个被调查者的年龄是213岁。
这个数据显然是一个不符合实际情况的失真数据。
再例如,在某项客户满意度的问卷调查中,某个被调查者的年收入没有填,是空缺的。
通常上述情况的数据都可称为缺失数据或不完全数据。