基于片上多核的H.264编码的并行加速性研究
合肥工业大学2010-2011学年学生创新基金资助项目一览表
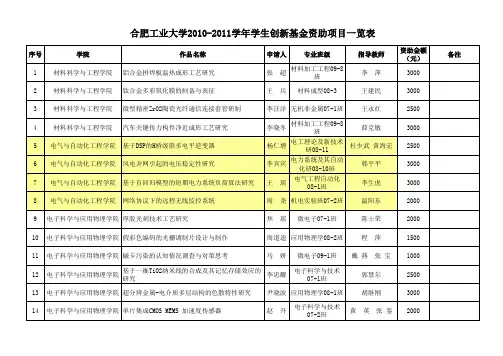
隆 冰
交通工程08-1 载运工具运用工程 07-1 载运工具运用工程 08-1 思政08-1 经济学08-1班 经济学09-1班 思想政治教育系 08-1班 社会工作07-2班 思政09-38研 思政研09-39班 生物技术08-1 生技08-1 生物技术07-1 生物工程07-1 食品08-1班 生物工程08-1 生物工程08-2
电子科学与应用物理学院 超分辨金属-电介质多层结构的色散特性研究 电子科学与应用物理学院 单片集成CMOS MEMS 加速度传感器
尹晓波 应用物理学08-1班 赵 升 电子科学与技术 07-2班
15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
电子科学与应用物理学院 氧化物半导体异质结器件的制备及特性研究 电子科学与应用物理学院 电子竞技的管理和发展前景以及社会影响 电子科学与应用物理学院 基于矩阵初等变换和遗传算法的量子电路综合 电子科学与应用物理学院 从挂科角度看大学生教育管理思路研究 电子科学与应用物理学院 碳纳米管中晶格波的研究 电子科学与应用物理学院 电流模式控制的非理想DC-DC开关变换器建模与 仿真研究
曹建中 曹建中 陈 奇 朱衍飞 陈 奇 朱衍飞 李洪涛 汪洪波 王 雁 殷晓晨 张 宝 张 良 朱立红 杨 静 陈 田 程克勤 候整风 胡东辉 蒋建国 罗月童
2000 1500 2000 1500 2000 2500 2500 1000 1000 1500 2500 2500 2000 2000 2500 2000 2000
基于车载无线定位的高速公路交通事件检测系统 宁学荣 研究 缓解城市停车难的关键性措施 高速公路动静态交通管理资源配置方法研究 小型纯电动汽车动力传动系统性能匹配 杨路路 章 洵 王 方
《基于FPGA的多核处理器系统的研究与设计》范文

《基于FPGA的多核处理器系统的研究与设计》篇一一、引言随着科技的快速发展,处理器性能的需求不断提升,传统单核处理器已经难以满足日益增长的计算需求。
因此,多核处理器系统成为了研究的热点。
本文以基于FPGA(现场可编程门阵列)的多核处理器系统为研究对象,对其进行了详细的研究与设计。
二、研究背景及意义FPGA作为一种可编程的硬件设备,具有高度的并行性、灵活性和可定制性,因此被广泛应用于高性能计算、信号处理等领域。
而多核处理器系统则通过集成多个处理器核心,实现了更高的计算性能和更快的处理速度。
将FPGA和多核处理器系统相结合,可以构建出高性能、高灵活性的多核处理器系统,对于提高计算性能、降低功耗、增强系统稳定性等方面具有重要的意义。
三、FPGA多核处理器系统的设计(一)系统架构设计基于FPGA的多核处理器系统主要由多个FPGA芯片组成,每个FPGA芯片上集成了多个处理器核心。
系统采用共享内存的方式,实现了各个处理器核心之间的数据交换和通信。
此外,系统还包含了控制模块、接口模块等部分,以实现系统的整体控制和外部接口的连接。
(二)处理器核心设计处理器核心是FPGA多核处理器系统的核心部分,其设计直接影响到整个系统的性能。
在处理器核心设计中,需要考虑指令集设计、数据通路设计、控制单元设计等方面。
指令集设计需要考虑到指令的兼容性、可扩展性和执行效率;数据通路设计需要考虑到数据的传输速度和带宽;控制单元设计则需要考虑到处理器的控制流程和时序。
(三)系统通信设计系统通信是FPGA多核处理器系统中非常重要的一部分,它涉及到各个处理器核心之间的数据交换和通信。
在系统通信设计中,需要考虑到通信协议的设计、通信接口的选择、通信速度和带宽等方面。
常用的通信协议包括总线协议、消息传递协议等,需要根据具体的应用场景进行选择和设计。
四、系统实现与测试(一)硬件实现在硬件实现阶段,需要根据设计要求选择合适的FPGA芯片和开发工具,完成电路设计和布局布线等工作。
基于异构多核处理器的H.264并行编码算法

H. 4的编码 算法 。针对 多 sc 编码并 行效率低 下 ,D P 2 6 le i S
基 金项 目:国家 自然科学基金 资助项 目( 9 7 0 ) 4 2 0 1;国家科技支撑计划基金 资助项 目 2 ( B F 9 0 ) 0 (【 9 A 3B 3 ;浙江省级重点科技创新 团队基金资助 ) 】
( iil inl rcso D P更适合进行视频处理的优势 D g aSga Poesr S ) t ,
所在 。 内部 有 7 针对 多种 视频编 解码 标准而设 计 的加 它 个 速 引擎 , 括边界 强度 计算 引擎 、变换 量化 引擎 、熵编码 包
引擎、帧 内预测 估计 引擎 、环路滤 波 引擎、运动 补偿 引擎 、
( stt o Ad acdDii l eh oo yadIsu n, h agUnv ri , a gh u3 0 2 , hn) I tue f vn e gt c n lg n t me tZ  ̄i iesy H n zo 10 7C ia ni aT nr n t
[ s a t 2 4 ie o igs n ad a ihcmp t gc mpe i ,n i c lt e e ihdf io ie a—me n o ig I Ab t c]H.6 d ocdn a dr s g o ui o l t adi df utometh g —e nt nvdoi r l i cdn .n r v t h h n xy s i t h i i ne t e
3 6
计
算
机
工
程
21 0 2年 8 2 月 0日
和 A M 双核任 务分 配不 均衡 的问题 提 出优化方 案 。 R
建 宏块 ,再经 环路滤波 后得 到参考 图像 。。 为 释放 C U,让 共有 效地 进行 数 据准 备 以及逻 辑 控 P 制 , M66 D 4 7中加入 7 H V C 硬 件加速 引擎 , 个 D IP 它们 与
基于多核处理器的多任务并行处理技术研究

能主要有 : 降低 单个 问题求解 的时间 ; 加问题求解 规模 、 增 提高 问题求解精度 ; 容错 、 高的可用性 、 高吞吐率 。并行 计算 面 更 提
实验结果表 明, 改进后的算法可 以充分利用 多核处理器并行处理数据的特点, 提高并行加速 比, 大大提高数:处理效率。 活
关键词
中图分类号
多核 多任务 并行算法 任务并行库 V . E SN T
T 31 P0 文献标识码 A
RE SEARCH ON ULTI CoRE. M . BAS ED II M 7
G s f n提 出了和阿 姆尔达 定律 不 同的假 设 来证 实加 速 ut s ao 系数是能超越 阿姆 尔达定律 的限制的 , ut sn认为软件 中的 G sf ao 串行部分是 固定 的, 不会随规模 的增大 而增 大 , 假设并行 处理 并 部 分的执行 时间是固定 的。G s f n定律用公式描述为 : ut s ao
间和计算节 点都 扩大 P倍时 , 程序 中并行工作负载增加的倍数 。
Sp ( )= ( f+C( ) 1一 ) f+G p ( / ) p ( /( ( ) 1一 p 在 加速 比模 型中考虑 了 cce与主 存之 间 的调 度开 销 , ah 对 加 速 比的分 析更加准确 , 在一定 程度上可 以解释实 验 中出现的
个 相对独立 的数 据区 , 由不 同的处 理器分别 处理 。并行算 法 的
处理器 的性能 , 随着芯片制程工艺 的不断进步 , 单个 芯片上集 成 的晶体管数 已超过数亿 , 传统处理器体 系结构技术面临瓶颈 , 很
多核学习中的并行计算与加速技术(九)

在当今科技迅猛发展的时代,人工智能、大数据、深度学习等领域的发展势不可挡。
在这些领域中,计算能力的需求也在不断增加。
为了满足这种需求,多核计算和并行计算技术成为了不可或缺的一部分。
本文将从多核学习的角度,探讨并行计算与加速技术在其中的应用。
多核学习作为一种新兴的学习方式,旨在通过同时运行多个学习任务来提高整体的学习效率。
在多核学习中,需要同时处理大量的数据,而传统的单核计算已经无法满足这种需求。
因此,并行计算技术成为了多核学习中的重要组成部分。
并行计算技术是指通过同时执行多个计算任务来提高计算效率的一种技术。
在多核学习中,通过并行计算技术可以充分利用多个核心的计算能力,从而加快学习的速度。
并行计算技术可以分为任务并行和数据并行两种方式。
任务并行是指将不同的学习任务分配给不同的核心进行处理。
每个核心负责执行一个独立的学习任务,通过这种方式可以充分利用多核处理器的计算能力,从而加速学习过程。
而数据并行则是将同一个学习任务的数据分配给不同的核心进行处理。
每个核心负责处理部分数据,最后将结果进行合并。
这种方式可以有效地提高整体的计算效率。
除了并行计算技术外,加速技术也是多核学习中的关键所在。
加速技术是指通过硬件或软件的优化来提高计算速度的一种技术。
在多核学习中,加速技术可以通过优化算法、使用高性能计算设备等方式来提高计算效率。
其中,GPU加速技术是目前应用较为广泛的一种加速技术。
GPU(Graphics Processing Unit)是一种专门用于图形处理的处理器,但是由于其高并行计算能力,目前被广泛应用于各种科学计算和深度学习任务中。
通过使用GPU加速技术,可以大大提高多核学习中的计算速度,从而加快学习过程。
不仅如此,还有一些新兴的加速技术也开始在多核学习中得到应用。
比如,FPGA(Field-Programmable Gate Array)是一种灵活可编程的硬件加速器,可以通过编程实现各种不同的计算任务。
基于H.264视频解码器DDR2存储器接口的设计与验证的开题报告

基于H.264视频解码器DDR2存储器接口的设计与验证的开题报告一、研究背景和意义随着图像和视频传输技术的飞速发展,视频解码器已经成为移动终端、便携式媒体播放器等众多电子设备的必备组件。
而基于H.264视频解码器的电子设备则因其高质量的视频解码功能而备受关注。
在H.264视频解码器中,DDR2存储器接口是关键的组成部分。
在此基础上,通过对嵌入式H.264视频解码器的DDR2存储器接口的设计和验证,可以实现视频解码器的高效工作,并有效提高视频输出质量。
因此,本研究的意义在于:深入分析H.264视频解码器的DDR2存储器接口,研究其工作原理和特点,设计并验证嵌入式H.264视频解码器DDR2存储器接口的性能,进而提高视频解码器的性能和质量。
二、研究目标和内容(一)研究目标本研究旨在设计和验证基于H.264视频解码器DDR2存储器接口的嵌入式视频解码器,具体研究目标包括:1. 深入研究H.264视频解码器的DDR2存储器接口的工作原理和特点;2. 设计基于DDR2存储器接口的嵌入式视频解码器;3. 对嵌入式视频解码器进行性能测试,并分析其性能指标;4. 对嵌入式视频解码器进行功能验证,并测试其视频输出质量。
(二)研究内容1. H.264视频解码器DDR2存储器接口的原理分析;2. 基于DDR2存储器接口设计嵌入式视频解码器的硬件架构;3. DDR2存储器接口的驱动程序设计;4. 嵌入式视频解码器的性能测试和结果分析;5. 嵌入式视频解码器的功能验证和视频质量测试。
三、研究方法和技术路线(一)研究方法1. 文献研究法:阅读相关文献,深入了解H.264视频解码器的DDR2存储器接口的特点和性能指标;2. 设计方法:采用硬件设计方法进行嵌入式视频解码器的设计;3. 测试方法:采用性能测试和功能验证法测试嵌入式视频解码器的性能和视频输出质量。
(二)技术路线1. 理论研究:深入研究H.264视频解码器DDR2存储器接口的工作原理和特点;2. 硬件设计:根据DDR2存储器接口的特点,设计基于DDR2存储器接口的嵌入式视频解码器的硬件架构;3. 驱动程序设计:编写DDR2存储器接口的驱动程序,实现与嵌入式视频解码器的通信和控制;4. 性能测试和功能验证:测试嵌入式视频解码器的性能指标和功能,并对其视频输出质量进行分析和测试。
HEVC关键技术2
HEVC关键技术摘要:随着人们视觉感受要求的提高,视频的分辨率和应用场合发生了重大变化。
但是现有的视频压缩标准已经不能满足需求,这就要求研究人员提出新的视频压缩标准,进一步提高视频的压缩效率,高效视频编码标准应运而生。
高效视频编码标准主要目标是在现有的H.264/A VC high profile的基础上,压缩效率提高一倍,可以允许适当提高编码端的复杂度。
本文主要从高效视频编码标准的关键技术入手,比较全面地介绍了基于四叉树结构的分割技术、细粒度slice分块边界、预测编码技术、环路滤波、熵编码、并行化设计等技术。
同时,对高效视频编码标准的发展前景进行了预测。
关键词:高效视频编码标准,预测编码技术,环路滤波、熵编码、并行化设计1 HEVC的背景H.264是当前普遍的视频编码标准,它将视频压缩效率提高到一个更高的水平。
由于其高效的压缩效率,以及良好的网络亲和性,使得该标准在较短的时间内得到广泛普及。
然而,随着网络技术和终端处理能力的不断提高和发展,人们提出了更高的要求,希望能够提供高清、3D、移动无线,以满足新的家庭影院、远程监控、数字广播、移动流媒体、便携摄像、医学成像等新领域的应用。
如果继续采用H.264编码就会出现如下一些局限性[1]:1.宏块个数的爆发式增长,会导致用于编码宏块的预测模式、运动矢量、参考帧索引和量化级等宏块级参数信息所占用的码字过多,用于编码残差部分的码字明显减少。
2.由于分辨率的大大增加,单个宏块所表示的图像内容的信息大大减少,这将导致相邻的4×4或8×8块变换后的低频系数相似程度也大大提高,导致出现大量的冗余。
3.由于分辨率的大大增加,表示同一个运动的运动矢量的幅值将大大增加,H.264中采用一个运动矢量预测值,对运动矢量差编码使用的是哥伦布指数编码,该编码方式的特点是数值越小使用的比特数越少。
因此,随着运动矢量幅值的大幅增加,H.264中用来对运动矢量进行预测以及编码的方法压缩率将逐渐降低。
NoC_MPSim:基于片上网络通信架构多核仿真平台
Absr c : A o fg r besmu ai np afr - No MPS m sp o o e h sp p r o x lrn sg p c ta t c n u a l i l t l t m- i o o C i i r p s d i t i a e re p o gt de in s a e n f i he
N C M Sm o — P i。该平 台包含处 理器工具链 、 台 自动化 配置脚 本以及 一个 包含 处理器 、 平 网络适 配 器以及 多
种路 由器的 R L 型库 , T模 可根据 用户输 入 的 系统 配置信 息 自动生 成周期精 确 的多核 仿真 系统 。针 对 片 上 网络 通信 架构 的特 征 , 定义 了基 于该 通信 架构 的 多核 系统 的 高层 次通 信抽 象模 型 , 并借鉴 并行机 中
的 消息传递机 制 , 出了一种可有 效 隐藏 网络乱序 的并行 编程模 型 及其 通信原 语 , 完成 其所 需要 的 提 并
软\ 硬件 建模 。 用提 出的编程模 型 , 应 实现 了 MSC算法基 于四核 仿真 系统 的分布式 并行计 算 , UI 并经 实 验得到 该并行 M SC算 法在 该 系统 中加速 比可达 2 6 UI .。 关键字 : 片上 多处理器 ; 片上 网络 ; 编程 模型 ; 通信抽 象
— —
o C— a e li o es se f No b s d Mu t -c r y t m. Th l t r whih c n an h r c s o o lc i , a c n g ain s rp n ep af m c o ti st ep o e s rto han o o f urto c i ta d a i RTL mo e ir r n l d n r c s e s newo k a p o sa d r u e s i b et e e aeac ce a c r t l —c r d ll a yi cu i gp o e s r , t r da tr n o tr , sa l og n r t y l c u aemu t o e b i smu ai n s se a c r i o i p tp r mee s A g e e o i lto y t m c o dng t n u a a tr . hih lv lc mmu ia in mo e s as e n d b s d o h s n c t d li lo d f e a e n t i o i c mmu ia in a c ie tr , nd b s d o t a al l r ga o n c t r h tcu e a a e n i,ap l o r mmi g mo e nd i o o r ep n d la t c mmu ia in p i tv s s n c t rmi e ,wh c o i ih c n efc iey s le t e o t o-o d rp o l m, a e r aie t o wae h d r n r sr cu e Ba e n t i a fe t l ov h u — f r e r b e v r e lz d wih s f r / a wa e i fa tu t r . t r s d o h s po a rg mmi gmo e, e ie p al l r n d l wer a z a l l r e MUS C a t me i n a4 o es se a dp o et es e s2. I r h t i -c r y tm, n r v h pe dupi 6. i c Ke r s: li r c s o y tm- n— p; t r —o — i ; o a y wo d Mu t -P o e s rS se o — Chi Newo k —n— Ch p Pr g mmi gmo e; mmu iai na src r n d l Co n c to b ta t
H.264并行编码算法的研究
JANG Xig c a g,ZHOU u I n — hn J n, LUO Ch a —fi u n e
0h ntnin o mae C mm nct na d Sg T e Isi t }I g o u iai n i t n o md
p r l l m.On n e u l c r lt r a al i es I tl d a - o e p af m.t e s e d p s a mo t n o - e ] t o i g a p iai n .a d . n e l t o — o h p e u i l s 2 i n n r a 一 i me c d n p l t s n 15 ra - i c o i me c d
流 (I SMD) 令 ; 一 种 是 基 于 线 程 级 的 并 行 ( L ) 这 指 另 TP, 种 方 法 需 要 和 多 核 技 术 相 互 配 合 来 实 现 。 验 证 明 , 纯 试 单 使用 任 何 …种 方 法 都 不 能 实 现 编 码 的最 大 并 行 化 l 一 _ I 。
・ 分・ 技 析 术
( 海 交通 大 学 图像 通 信 与 信 息 处 理 研 究所 电 子 工 程 系 ;上 海数 字 媒 体 处 理 与 传 输 重 点 实验 室 ,上 海 2 0 4 上 0 2 0)
【 摘 要 】 以 x 6 24编 码 器 作 为研 究 对 象 , 指 令 集 并 行 的 基 础 上 对 其 进 行 线 程 级 并 行 优 化 , It 双 核 处 理 器 平 台 上 , 对 非 实 在 在 nl e 针
HEVC若干关键技术研究
HEVC若干关键技术研究HEVC(High Efficiency Video Coding)是一种高效视频编码技术,也是当前最先进的视频压缩标准之一。
这项技术的研究包含了众多关键技术,其中几个核心技术包括多桢并行编码、色度处理和变形滤波等。
本文将就HEVC若干关键技术进行探讨,以便更好地理解和应用这一先进的视频编码标准。
多桢并行编码是HEVC中的一项重要技术,它利用多桢的并行处理,在增加编码复杂度的同时,提高了编码效果。
传统的视频编码标准如H.264/MPEG-4 AVC使用的是基于单个桢的编码技术,而HEVC进行了创新性设计,引入多桢并行编码的概念。
这样一来,编码器可以将多个桢一起进行压缩编码,并且在解码端同样可以并行解码,从而实现更高的编解码效率。
色度处理是HEVC中的另一个关键技术,它主要涉及到对色度信息(Cb和Cr)的处理方式。
在传统的视频编码标准中,色度信息通常以相对较低的分辨率进行采样和编码,这样虽然节约了编码的复杂度,但也导致了色彩细节的损失。
而HEVC则改进了这一问题,通过色度推测方法和高精度的运动补偿技术,在更高的色度分辨率下进行编码,从而提高了视频的色彩还原效果。
变形滤波是HEVC中的重要技术之一,它主要用于减小视频编解码过程中产生的伪影和图像模糊现象。
视频编解码过程中会由于帧间差分和运动矢量引起图像的失真,而变形滤波技术通过计算变形像素和滤波参数来对图像进行补偿,从而减小了失真的程度。
HEVC中采用了一种自适应的滤波算法,根据不同的情况选择合适的滤波强度,使得图像达到更好的视觉效果。
除了上述关键技术外,HEVC还包含了其他一些重要的研究内容。
例如,运动估计算法的优化,通过提高运动矢量的精度和准确度,减小了运动估计误差,从而提高了编码的效率。
此外,比特率控制算法和码率分配技术也是HEVC中的重要研究方向,通过合理地控制压缩比特率,使得视频在满足不同场景需求的同时,保持更高的视觉质量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
为进一 步提高 H.6 实 时编解码 的性能 , 24 本文提 出了基于 多核结构 的 H24 行化方案 , 硬件结 构与软 件算法协 同 . 并 6 通过 图 1 数据分层结构
子宏块
优化 的方式 , 实现多核结构上 的高速编码 。
因为 以序列 为调度单 元 , 其并 行粒度较 大 , 易造 成各处理 器负载 不平衡 , 对各个处 理器要 求有较 大的缓 存空间 , 且 不适 于嵌入式平 台。序列 中的一帧 图像 要用到前面 已编 码图像帧 ,
Absr c : Ai ig a te c n it b t e te g o n vie p o e sn r q rme t o p ra l e upme t a d hg ta t m n t h o f c ewe n h r wig l do r c sig e uie ns n o tbe q i n s n ih c mp tto l o o uaina c mplx t o 2 4 c d c aall P C・ s d H.6 tae y i p o osd o e lt e e c dn .T kn GA ei y f H.6 o e ,a p r le M So bae 2 4 srtg s rp e fr ra—i n o ig a ig FP m a v rfc t n ltom , i c iv s aall lc -a e H. 4 e c dn o a sn l bu d a—o e s e i ai p af r i o t a h e e p l sieb s d r e 26 n o ig n ige s u lc r M PS C b c l b rtv l o y ol o ai ey a o tmiig ad re tu  ̄ p i zn h r wa sr c a d of r lo i m .Th e p rme tr s ls h w ha a o d a c lrto fe t a e m a e y n s t wa e ag rt h e x e i n e ut s o t t g o c eeain e c C n b d b
1 2 4 码标 准及 并行 化分 析 H.6 编
会造 成任 务之 间的相 互等待 , 并 H24 . 定义 了基本 、 6 主要 、 展三种支持不 同类 型应用的档 如果 以图像为 独立编 码单元 , 扩 次 (rfe 。其 中 , po l) i 基本 档 次通过 I 片和 P片的帧 内和 帧 间编 且增加处理器之间的通信开销 。 码, 支持基 于上下文 自适应变长熵 编码 (A L )较 其他档次 C VC, 更适合便携式视频通信 设备的需求 。 在 以宏块和 比宏块更细粒度上进 行并 行编码 , 处理器之 间 的通信次数会 大幅度增加 , 因为宏块 以及 子宏块的预测编码会
多 明显 优 势将 成 为视 频 压缩 的未 来主 流标 准 , 是 , 但 其较 高 的 计算 复 杂度 与 当前 便 携设 备 较 低 的计 算能 力 的矛 盾 相 当
突 出。
视频序 列
针对这一问题 , 我们以提高硬件计算能力为手段, 改善了 片上多核 平 台等 的计算 能力[ 同时 在编解码 算法优化 等方 面 1 J ;
u ig sn mut—o e tc n o y orp r l lH.6 nc dng n mbe d d e vr n n . li r e h olg f a al 2 4 e o i i e c e d e n io me t
K e r s H. 6 y wo d : 2 4; M PS C; FP o GA ; si e; p a l l e c d n lc r e a l n o ig
计算机 时 4 . 编码的并行加速性研究 6
宋 阳’ ,章 晓燕
( 天津工业大学计算机与软件学院,天津 30 6 ;2 1 . 0 10 .中国农业银行)
摘 要 :针对便携设备 上不断增强的视频 处理要 求和H.6 编 解码 算法相对较 高的计算复杂度之 间的矛盾 , 出了基 于 24 提 片上 多核 结构 的H.6 并行化 方案 , 24 以达到 实时编码 的效 果。该方 案以 F G P A为验证 平台 , 通过硬件 结构与软件 算法协 同优化 的方式 , 在单 总线双核 结构的 MP o S C上 实现 了基 于片的H.6 并行编码 。实验 结果表明 , 24 在嵌入 式环境 下利用 多
0 引言
H24 数 据结 构 分 为 序 列 、 . 的 6 图像 、 、 块 、 宏 块 五个 层 片 宏 子
如图 l 示 , 层次 可 以被 选择作 为并 行算 法的基本 调 所 这些 随着对便携设备高画质视频处理等需求的 1益增长 , 3 高 次 ,
。 性 能编解 码 等相关 技术 已成为研 究热 点 。H. 4 2 协议 以其 诸 度 单元 6
核技术 实现 H. 4 2 并行编码可 以取得 良好的加速效果 。 6 关键词 :H.6 ;片上 多核 ;F G 24 P A;片;并行 编码
R e e r h n r le c e e a i n f M PS s a c o Pa a ll A c lr to o oC- s d ba e H . 4 26 En o ng c di
S ONG n ZHANG a - a 2 Ya g , Xi o y n
(. col f C m u rSi c Sho o o p t c ne& S w r E g er g T n n P l e n n e i,T n n 3 0 6 ,C i ; . gi l rl , o hn ) e e o ae n i e n , i f o t h i U i r t i j 0 10 hn 2 A r u u f C /a t f n i ai y c c v sy a i a cta