第4章 队列
第四章 队列研究1
第二节 研究设计与实施
确定研究因素
确定研究结局
选择研究现场
研究对象 确定样本量 资料收集与随防 质量控制
确定研究因素和结局
文献资料
(描述性研究和病例对照研究) 个人既往研究结果
暴露因素
性质 定性(quality) 定量(quantity) 方法 访谈 实验室 检查 查阅记录 测量 统一标准 发病或死亡
历史性队列研究 (Historical cohort study)
也称为回顾性队列研究(retrospective cohort
study) 双向性队列研究(Ambispective cohort study)
历史性队列
双向性队列
暴露 因 素 非暴露
结 局
前瞻性队列
暴露 因 素 非暴露 结 局
暴露组(exposure population):
包括不同暴露水平的亚组。
对照组(control population) : 根据研究目的和研究条件选择不同 的对照人群。
可比性
暴露组的选择
职业人群:如石棉作业工人等 特殊暴露人群:如接受放射线治疗的人 一般人群:Framingham研究 有组织的人群:如医学会会员、工会会员等
对照组的选择
内对照:与暴露组来自同一人群 外对照:与暴露组来自不同人群 总人口对照:全人口为对照。如全国或某省 /市、县的统计资料
多重对照:同时选用上述两种或以上的对照
样本含量的估计
计算样本量时需考虑的问题 抽样方法 暴露组与非暴露组的比例 失访率
影响样本量的因素
全人群(对照人群)中所研究疾病的发病率P0
3例研究对象的出生日期与进出研究时间
编号
第四章栈和队列

}
if(k==1){
BS.top1++;
Bs.stack[BS.top1]=item;
}
else if(k==2){
BS.top1--;
ElemType peek(BothStack& BS,int k)
{
if(k==1){
if(BS.top1==-1){
cerr<<"Stack 1 is empty!"<<end1;
exit(1);
当向栈2插入元素时,则使top2减1才能够得到新的栈顶位置。当top1等于top2-1或者top2等
于top1+1时,存储空间用完,无法再向任一栈插入元素。用于双栈操作的顺序存储类型可定
义为:
struct Bothstack{
ElemType stack[stackMaxSize];
int top1,top2;
};
双栈操作的抽象数据类型可定义为:
DAT BSTACK is
Data:采用顺序结构存储的双栈,其存储类型为Bothstack
operations:
void InitStack(Bothstack& BS,int k);
2.在一个数组空间stack[StackMaxSize]中可以同时存放两个顺序栈,栈底分别在数组的两端
,当第一个栈的栈顶指针top1等于-1时则栈1为空,当第二个栈的栈顶指针top2等于StackMax
Size时栈2为空。两个栈均向中间增长,当向栈1插入元素时,使top1增1得到新的栈顶位置,
BS.stack[BS.top2]=item;
习题-第四章队列研究

第四章队列研究名词解释1.cohort study2.Cumulative incidence3.Relative risk4.Attributable risk5.selection bias6.lost to follow-up bias7.standardized ratio8.end point选择题1.队列研究的最大优点是A.控制混淆因子的作用易实现B.发生偏倚的机会少C.对较多的人进行较长时间的随访D.较直接验证病因与疾病的因果关系E.研究的结果常能代表全人群2.评价某致病因素对人群危害程度使用A.PARB.SMRC.AR%D.RRE.AR3.在队列研究中A.不能计算特异危险度B.不能计算相对危险度C.只能计算比值比来估计相对危险度D.能计算相对危险度,不能计算特异危险度E.既可计算相对危险度,又可计算特异危险度4.某因素和某疾病间联系强度的最好测量可借助于A.整个人群的发病率B.传染期C.相对危险度D.潜伏期E.以上都不是5.下列关于相对危险度(RR)的叙述,正确的是A.不能应用于试验流行病学中B.在估计公共卫生措施的影响时比特异危险度更有用C.也可以应用到生态学研究中D.无效假设值为零E.在调查特定疾病的病因时比归因危险度更有用6.在进行队列研究时,队列必须A.有相同的遗传史B.居住在共同地区C.经过相同的观察期限D.暴露于同种疾病E.有共同的疾病史7.在队列研究中,累积发病率指的是A.某动态人群在一定时期内某病新发病例数与同期平均人数之比B. 某动态人群在一定时期内某病新发病例数与时期开始时总人数之比C.某流动人群在一定时期内某病现患病例数与时期开始时总人数之比D.某固定的研究人群在一定时期内新发病例数与开始时总人数之比E.某动态的人群在一定观察期内某病新发病例数与同期暴露人数之比8.以人年为单位计算的率为A.标化死亡比B.发病密度C.发病率D.现患率E.死亡率9.前瞻性队列研究与流行病学实验的根本区别是A.是否进行了随访观察B.是否设立对照组C.是否应用了先进的仪器、设备D.是否在现场人群中进行E.是否人为控制研究条件10.队列研究最大的优点是A.较直接地验证病因与疾病的因果关系B.发生偏倚的机会少C.对较多的人进行较长期的随访D.较易控制混杂因子E.研究的结果常能代表全人群11.下述哪项不是前瞻性调查的特点A.可同时研究多个因素B.多数情况下要计算人年发病(死亡)率C.每次调查能同时研究几种疾病D.可直接计算发病率E.因素可分为几个等级,以便计算剂量反应关系12.在队列研究中,率差是指:A.病例组的发病率或死亡率与对照组同种率之差B.暴露组的发病率或死亡率与对照组同种率之差C.暴露组的暴露率与对照组的暴露率之差D.病例组的暴露率与对照组的暴露率之差E.以上都不是13.关于相对危险度,下列叙述哪项不正确的是A.相对危险度小于1,说明存在负联系B.相对危险度等于1,说明暴露与疾病关联很强C.是暴露组危险度与对照组危险度之比D.相对危险度的取值范围在O-∞之间E.相对危险度大于l,说明存在正联系14.关于分析性研究的叙述,下列哪项是错误的A.队列研究中,相对危险度等于暴露组发病率除以对照组发病率B.特异危险度等于暴露组死亡(发病)率减去非暴露组死亡(发病)率C.病例对照研究中,可用比值比估计相对危险度D.病例对照研究中,相对危险度等于病例组发病率除以对照组发病率E.病例对照研究中,成组资料与匹配资料的效应测量值的计算公式不同15.下列哪项不是影响病例对照研究样本大小的主要因素A.人群中暴露者的比例B.要求研究的变量的性质C.要求的显著性水平D.要求的把握度E.假定暴露造成的相对危险度填空题1.队列研究中,根据研究的方便与可能,暴露人群通常有下列4种选择:、、和。
第四章队列研究(cohortstudy)

4 2 3 2 7 8 3 5 2 1 0 37
30 11 8 19 25 29 73 74 467 819 57
1425.5 1464.0 1504.5 1521.0 1502.0 1481.5 1440.5 1375.5 1112.0 473.5 36.5 1333.6
第一年暴露人年数为: L1=I1+1/2(N1-D1-W1)=1403+1/2(79-4-30)=1425.5 I2=I1+N1-D1-W1=1403+79-4-30=1448 L2=1448+1/2(45-2-11)=1464 以此类推,合计得13336.5人年
六、质量控制 1、调查员的选择 2、调查员的培训 3、制定调查手册 4、监督
重复调查;数值检查或逻辑检错;定期观察调查员的工作; 对不同调查员的数据进行分布比较;变量的时间趋势分析;使 用录音机
第四节 资料的整理与分析
一、队列研究资料整理表
组别 病例 非病例 合计 发病率
暴露组 a b a +b =n 1 a / n 1 = Ie 非暴露组 c d c +d =n 0 c / n 0 = Io 合计 a+c=m1 b+d=m0 a+b+c+d=t m1/ t= It
第四章 队列研究 (cohort study)
前瞻性研究(Prospective study);发生率研究(incidence study); 随访研究(follow-up study);纵向研究(longitudinal study)
1. 2. 3. 4. 6. 7.
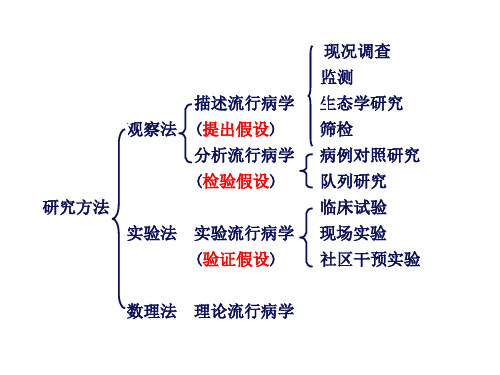
概述 研究实例 研究设计与实施 资料整理与分析 常见偏倚及其控制 优点与局限性
第4章.队列研究(谭红专)

第四章队列研究队列研究(cohort study)是分析流行病学(analytical epidemiology)研究中的重要方法之一,它通过直接观察危险因素暴露状况不同的人群的结局来探讨危险因素与所观察结局的关系。
与之类似的名称还有前瞻性研究(prospective study)、发生率研究(incidence study)、随访研究(follow-up study)及纵向研究(longitudinal study)等。
队列研究与病例对照研究相比,其检验病因假设的效能优于病例对照研究。
因此,队列研究在流行病学病因研究中应用广泛。
第一节概述一、概念队列研究是将人群按是否暴露于某可疑因素及其暴露程度分为不同的亚组,追踪其各自的结局,比较不同亚组之间结局频率的差异,从而判定暴露因子与结局之间有无因果关联及关联大小的一种观察性研究(observational study)方法。
这里观察的结局主要是与暴露因子可能有关的结局。
暴露(exposure)是指研究对象接触过某种待研究的物质(如重金属)、具备某种待研究的特征(如年龄、性别及遗传等)或行为(如吸烟)。
暴露在不同的研究中有不同的含意,暴露可以是有害的,也可以是有益的,但都是需要研究的。
队列(cohort)原意是指古罗马军团中的一个分队,流行病学家加以借用,表示一个特定的研究人群组。
根据特定条件的不同,流行病学中的队列一般有两种情况:一是指特定时期内出生的一组人群,叫出生队列(birth cohort);另一种是泛指具有某种共同暴露或特征的一组人群,一般即称之为队列或暴露队列(exposure cohort),如某个时期进入某工厂工作的一组人群。
根据人群进出队列的时间不同,队列又可分为两种:一种叫固定队列(人群)(fixed cohort),是指人群都在某一固定时间或一个短时期之内进入队列,之后对他们进行随访观察,直至观察期终止,成员没有因为结局事件以外的其他原因退出,也不再加入新的成员,即在观察期内保持队列的相对固定。
数据结构专项精讲课程讲义-第三部分-第4章 队列

一 选择题1. 假设以数组A[m]存放循环队列的元素,其头尾指针分别为front和rear,则当前队列中的元素个数为( A )。
A.(rear-front+m)%m B.rear-front+1 C.(front-rear+m)%m D.(rear-front)%m 2. 循环队列A[0..m-1]存放其元素值,用front和rear分别表示队头和队尾,则当前队列中的元素是( A )。
A. (rear-front+m)%mB. rear-front+1C. rear-front-1D. rear-front3. 循环队列存储在数组A[0..m]中,则入队时的操作为(D )。
A. rear=rear+1B. rear=(rear+1) mod (m-1)C. rear=(rear+1) mod mD. rear=(rear+1)mod(m+1)4. 若用一个大小为6的数组来实现循环队列,且当前rear和front的值分别为0和3,当从队列中删除一个元素,再加入两个元素后,rear和front的值分别为多少?( B )A. 1和 5B. 2和4C. 4和2D. 5和15. 用单链表表示的链式队列的队头在链表的( A )位置。
A.链头 B.链尾 C.链中二 判断题1. 队列是一种插入与删除操作分别在表的两端进行的线性表,是一种先进后出型结构。
( × )2. 通常使用队列来处理函数或过程的调用。
( × )3. 队列逻辑上是一个下端和上端既能增加又能减少的线性表。
( √ )4. 循环队列通常用指针来实现队列的头尾相接。
( × )5. 循环队列也存在空间溢出问题。
(√ )6. 队列和栈都是运算受限的线性表,只允许在表的两端进行运算。
(× )7. 栈和队列都是线性表,只是在插入和删除时受到了一些限制。
( √ )三 应用题1. 简要叙述循环队列的数据结构,并写出其初始状态、队列空、队列满时的队首指针与队尾指针的值。
流行病学第四章 队列研究

yes
暴露组
目标人群 代表 未患某研究 性样 疾病
No Yes 非暴露组 No
队列研究的结构模式图
本
固定队列
出现结局 未出现结局
研究开始
研究结束
动态队列
出现结局
失访
研究开始
研究结束
队列研究的特点
属于观察性研究
设立对照组 由因及果
能计算发病率,确证暴露与疾病的因果联系
质量控制
培训调查员
制定相应的规章制度 盲法
资料分析
计算各组的发病或死亡率
对组间率的差异进行统计学显著性检验 对差异有统计学显著性的进一步计算关联强
度
累计发病率:观察人群比较稳定
观察期内发病(或死亡 )人数 CI 观察开始时的人口数
发病密度:观察期间人群人数产生了较大的
直接获得暴露组和非暴露组的发病率或死亡率
直接估计危险度
符合时间顺序,验证病因的能力较强 获得一种暴露与多种结局的关系 收集的资料完整可靠,不存在回忆偏倚 可研究疾病的自然史
不适于发病率很低的疾病的病因研究 易发生失访偏倚 耗时,耗人力、物力、财力
设计要求严密,资料的收集和分析难度较大
队列研究的实施—确定研究结局
结局:指研究者预期的结果事件。是队列研
究观察的自然终点。 结局不仅限于发病、死亡还可以是中间变量。
队列研究的实施—确定研究对象
暴露人群的选择: 职业人群 特殊暴露人群 一般人群 有组织的人群团体 对照人群的选择 内对照 外对照 人群对照 多种对照
职业人群
暴露史比较明确,有关暴露与疾病的历史记
流行病学 第四章 队列研究

南京医科大学公共卫生学院流行病与卫生统计学系 电邮:sujing@
流行病学病因研究的一般过程
描述疾病频 度和分布
描述性研究
三间分布 常规资料 临床信息
形成
检验
→ 假设 → 假设
→ 因果 推断
逻辑推理
(Mill’s 准则)
队列研究 病例对照研究
实验研究
结合各方面因
素进行综合分
二、基本原理
选定一组研究人群,根据过去或目前的暴露情 况进行分组 有无暴露因素:暴露组和非暴露组 暴露因素的水平:低、中、高剂量组
随访观察各组的观察结局(发病或死亡) 比较各组发病率或死亡率的差异,从而判定暴
露因素与发病有无因果关联及关联大小
©by Jing Su
暴
露
组
研
究
对
象
对
照
组
发病 未发病 发病 未发病
研究现场: 江苏省海门市(HCC高发区)
研究人群: 35个镇的1008个村的25-64岁居民 海门市防疫站工作人员入户调查
©by Jing Su
四、确定样本量
决定因素: 1、一般人群(非暴露组的)所研究疾病的发病
或死亡率(P0),P0越接近0.5,样本越小 2、暴露组与对照组人群发病率之差d= P1- P0, 暴露组疾病的发病或死亡率(P1),或相对危 险度(RR)估算P1,d越大,样本越小
注意事项: 一般对照组样本数≥暴露组的样本数 估计失访对数据分析的影响,一般按估计样
本量增加10%作为实际样本量
©by Jing Su
例:乙肝病毒感染与原发性肝细胞癌的队列研究
假设HCC发病率P0=0.003/人年(全国水平)
假设HBV感染者的发病率为未感染者的2.5倍,即
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
×
front
×
2.2 循环队列出队2
×
×
front
2.2 循环队列出队3
下一个front计算公式: front=(front+1)% max
2.3 循环队列长度1
2.3 循环队列长度2
2.3 循环队列长度3
循环队列长度? 队列长度:(rear-front+max)% max
练习:
10
(1)顺序队列的空间分配及初始化 顺序队列的空间分配和顺序栈基本相同,不同的是其初 始化操作。假设通过SeqStack s和SeqQueue q分别定义了 一个顺序栈s和一个顺序队列q,则顺序栈的初始化操作是设 置其栈顶指针s.top=-1,而顺序队列的初始化操作需要同时 设置其队头指针q.front=-1和队尾指针q.rear=-1。
6
4-1-2 队列的基本运算
(1)入队操作: InQueue(q,x) 初始条件:队q存在且未满。 操作结果:输入一个元素x到队尾,长度加1。 (2)出队操作: OutQueue(q,x) 初始条件: 队q存在,且非空。 操作结果:删除队首元素,长度减1。 (3)读队头元素:ReadFront(q,x) 初始条件: 队q存在且非空。 操作结果: 读队头元素,队列不变。
队长操作
int QueueLen(SeqQueue *q) { return(q->rear-q->front); }
从图4-2中可以看到,随着入队、出队操作的进行,整个 队列会整体向上移动,这样就出现了图4-2(d)中的现象— —队尾指针虽然已经移到了最上面,而队列却未真满,这种 “假溢出”现象使得队列的空间没有得到有效利用。解决的方 法是:可以将当前队列中的所有数据整体往下移动,让剩余的 空单元留在队尾,这样新的数据元素就可以继续进队了。
16
出队操作
int OutQueue(SeqQueue *q, datatype *x) { if (IsEmpty(q)) { printf("队空!"); return 0; } // 队已空,不能出队,返回0 else { q->front=q->front+1; // 先移动队头指针 *x=q->data[q->front]; // 队头元素送x,参数x将其返回 return 1; } // 出队成功,返回1 }
21
2.循环队列1
假溢出的问题:用循环队列来解决
将存储数据元素的一维数组看成是头尾相接的循 环结构即:
循环队列
2.1 循环队列入队1
rear C
×
2.1 循环队列入队2
×
F
rear
2.1 循环队列入队3
下一个rear计算公式: rear=(rear+1)% max
2.2 循环队列出队1
} CycleSeqQueue;
40
创建队列操作
void InitSeqQueue(CycleSeqQueue *q) { q=malloc(sizeof(CycleSeqQueue)); q->front=q->rear=-1; // 初始化队头、队尾 q->flag=FALSE; }
41
入队操作
队空:front=rear
冲突解决!!
2.4 循环队列队满队空7
循环队列解决冲突的三种方法 以牺牲一个存储空间为代价,当判断到(下一个 rear==front)时,即认为队满。 设置一个布尔变量flag。当flag==flase时为空,当
flag==true时为满。
使用一个计数器记录队列中元素的个数。如num,当 num==0时队空,当num==MaxSize时队满。
17
队满操作
int IsEmpty(SeqQueue *q) { if(q->rear-q->front== MAXLEN-1) return 1; else return 0; }
队空操作
Int IsFull(CycleSeqQueue *q) { if(q->rear-q->front==0) return 1; else return 0; }
8
4-2
队列的存储实现及运算实现
4-2-1 顺序队列
1.顺序队列
顺序队列是用内存中一组连续的存储单元顺序存放队
列中各元素。所以可以用一维数组Q[MAXLEN]作为队列的顺
序存储空间,其中MAXLEN为队列的容量,队列元素从Q[0] 单元开始存放,直到Q[MAXLEN–1]单元。因为队头和队尾都
是活动的,因此,除了队列的数据以外,一般还设有队首
5
2. 队列的特性
(1)队列的主要特性是“先进先出”。 (2)队列是限制在两端进行插入和删除操作的线性表。 能够插入元素的一端称为 队尾(Rear),允许删除元素的一端称为 队首 (Front)。
3. 应用实例
(1)如车站排队买票或自动取款机排队取款。 (2)在计算机处理文件打印时,为了解决高速的CPU与低速的打印机之间的 矛盾,对于多个请求打印文件,操作系统把它们当作可以被延迟的任务,提出 打印任务的先后顺序,就是它们实际打印的先后顺序。即按照“先进先出”的 原则形成打印队列。
7
(4)显示队列中元素ShowQueue (q) 初始条件: 队列q存在,且非空。 操作结果: 显示队列中所有元素。 (5)判队空操作:QEmpty(q) 初始条件: 队q存在。 操作结果: 若队空则返回为1,否则返回为0。 (6)判队满操作:QFull(q) 初始条件: 队q存在。 操作结果: 若队满则返回为1,否则返回为0。 (7)求队列长度Qlen(q) 初始条件: 队列q存在。 操作结果: 返回队列的长度。
12
13
(5)判队空 由图4-2可见,队头指针q.front始终指向队头元素的前 面一个位置,队尾指针q.rear始终指向队尾元素。由于队头 指针q.front和队尾指针q.rear的初值均为-1,每进队一个元 素时q.rear++,每出队一个元素时q.front++,因此当 q.front和q.rear相等(即队头指针和队尾指针指向同一个单 元)时,队列为空。 (6)判队满: 当顺序队列中的元素个数n==MAXLEN时,队列的数组 Q中没有空余单元可供进队元素存放,可以认为队列已满。 设队列长度MAXLEN=10,则顺序队列的操作示意图如 图4-2所示。
(front)和队尾(rear)两个指针。
9
顺序队可以用C++语言定义: #define MAXLEN 10 // 队列的最大容量 typedef struct { datatype Q[MAXLEN]; // datatype 可根据用户需要定义 int front; // 定义队头指针 int rear; // 定义队尾指针 }SeqQueue; // 定义顺序队列类型 基于以上类型定义,顺序队列的基本操作如下:
int n; } CycleSeqQueue;
// 定义队头、队尾指针
// 循环顺序队列的类型名
// 用于记录循环顺序队列中元素的个数
45
当采用第(3)种方法时,循环顺序队列与顺序队列的基
11
(2)入队或进队 在队列不满的情况下,队尾指针加1,新元素即可进队: q.rear++; // 先将队尾指针加1 q.Q[q.rear]=x; // 元素x进队 (3)出队 在队列非空的情况下允许出队,出队时队头指针加1,队头 元素即可出队: q.front++; // 先将队头指针加1 x=q.Q[q.front] ; // 队头元素送x,x对出队元素作进一 步处理 (4)顺序队列中的元素个数:n=(q.rear)(q.front),如图 4-2中所示的四种情况,队列中的元素个数均可用队尾指针 q.rear和队头指针q.front相减得到。
int InQueue(CycleSeqQueue *q, datatype x) { if (IsFull(q)) { printf("队满!"); return 0; } // 队已满,不能入队,返回0 else { q->rear=(q->rear+1)%MAXLEN; // 先移动队尾指针 q-> data[q->rear]=x; // 元素x入队 if(q->rear==q->front) q->flag==TRUE; return 1; // 入队成功,返回1 }
2.5 循环队列基本操作
当采用第(2)种方法时,循环顺序队列的结构体类型应定 义如下: typedef struct { datatype data[MAXLEN]; int front, rear; // 定义存储数据元素的数组 // 定义队头、队尾指针 // 循环顺序队列的类型名
bool flag;
3
第 4 章 目录
4-1 队列的定义和基本运算 4-2 队列的存储及运算的实现 4-3 队列的应用举例 小 结 验证实验4 队列子系统 自主设计实验4循环队列的实现和运算 单元练习4
4
4-1
队列的定义和基本运算
4-1-1 队列(Queue)的定义
1.队列的定义
设有n个元素的队列Q=(a1,a2,a3,…,an),则称a1 为队首元素, an 为队尾元素。队列中的元素按, a1 , a2 , a3,…,an–1 ,an的次序进队,按a 1,a2,a3,…,an–1 , an次序出队,即队列的操作是按照“先进先出” 的原则进行 的。
43
思考:???
IsEmpty(CycleSeqQueue *q) IsFull(CycleSeqQueue *q)
当采用第(3)种方法时,循环顺序队列的结构体类型应定