LL(1)文法分析程序
LL(1)语法分析程序实验报告

LL1实验报告1.设计原理所谓LL(1)分析法,就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前看一个输入符号,便可确定当前所应当选择的规则。
实现LL(1)分析的程序又称为LL(1)分析程序或LL1(1)分析器。
我们知道一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。
当文法满足条件后,再分别构造文法每个非终结符的FIRST和FOLLOW 集合,然后根据FIRST和FOLLOW集合构造LL(1)分析表,最后利用分析表,根据LL(1)语法分析构造一个分析器。
LL(1)的语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出的语法分析栈,本程序也是采用了同样的方法进行语法分析,该程序是采用了C++语言来编写,其逻辑结构图如下:LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a做哪种过程的。
对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:(1)若X = a =‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看预测分析表M。
若M[A,a]中存放着关于X的一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式的右部符号串按反序一一弹出STACK栈(若右部符号为ε,则不推什么东西进STACK栈)。
若M[A,a]中存放着“出错标志”,则调用出错诊断程序ERROR。
事实上,LL(1)的分析是根据文法构造的,它反映了相应文法所定义的语言的固定特征,因此在LL(1)分析器中,实际上是以LL(1)分析表代替相应方法来进行分析的。
2.分析LL ( 1) 分析表是一个二维表,它的表列符号是当前符号,包括文法所有的终结和自定义。
的句子结束符号#,它的表行符号是可能在文法符号栈SYN中出现的所有符号,包括所有的非终结符,所有出现在产生式右侧且不在首位置的终结符,自定义的句子结束符号#表项。
编译原理笔记10 自上而下分析-预测分析程序与LL(1)文法
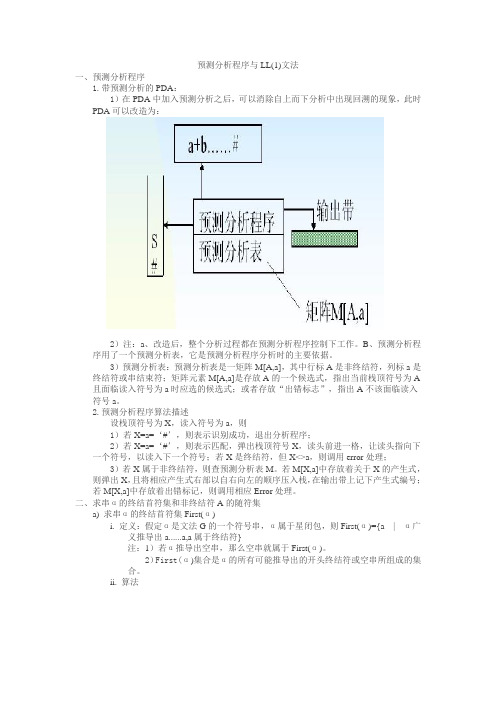
预测分析程序与LL(1)文法一、预测分析程序1.带预测分析的PDA:1)在PDA中加入预测分析之后,可以消除自上而下分析中出现回溯的现象,此时PDA可以改造为:2)注:a、改造后,整个分析过程都在预测分析程序控制下工作。
B、预测分析程序用了一个预测分析表,它是预测分析程序分析时的主要依据。
3)预测分析表:预测分析表是一矩阵M[A,a],其中行标A是非终结符,列标a是终结符或串结束符;矩阵元素M[A,a]是存放A的一个候选式,指出当前栈顶符号为A 且面临读入符号为a时应选的候选式;或者存放“出错标志”,指出A不该面临读入符号a。
2.预测分析程序算法描述设栈顶符号为X,读入符号为a,则1)若X=a=‘#’,则表示识别成功,退出分析程序;2)若X=a=‘#’,则表示匹配,弹出栈顶符号X,读头前进一格,让读头指向下一个符号,以读入下一个符号;若X是终结符,但X<>a,则调用error处理;3)若X属于非终结符,则查预测分析表M。
若M[X,a]中存放着关于X的产生式,则弹出X,且将相应产生式右部以自右向左的顺序压入栈,在输出带上记下产生式编号;若M[X,a]中存放着出错标记,则调用相应Error处理。
二、求串α的终结首符集和非终结符A的随符集a) 求串α的终结首符集First(α)i. 定义:假定α是文法G的一个符号串,α属于星闭包,则First(α)={a | α广义推导出a......a,a属于终结符}注:1)若α推导出空串,那么空串就属于First(α)。
2)First(α)集合是α的所有可能推导出的开头终结符或空串所组成的集合。
ii. 算法具体步骤:b) 求非终结符A的随符集Follow(A)i. 定义:假定S是文法G的开始符号,对于G的任何非终结符A,定义:ii. 算法1. 对文法开始符号S,将‘#’加入到Follow(S)中;2. 若B->αAβ是文法G的一个产生式,则将First(β)-空串加入到Folow(A)中;3. 若B->αA是文法G的一个产生式,或B->αAβ是文法G的一个产生式,且β推导出空串,则将Follow(B)加入到Follow(A)中;注:这里的文法必须消除左递归且提取了左因子后的文法。
【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集

【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
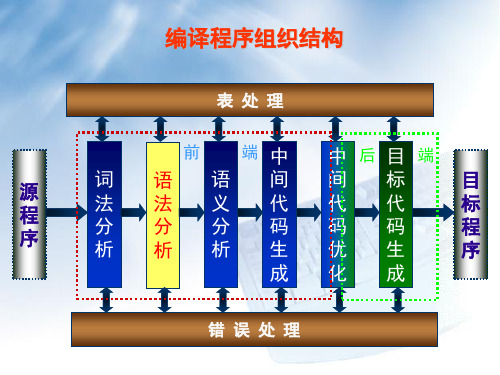
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
编译原理实验LL1分析

实验三语法分析---LL(1)分析器
一
(
1.用程序的方法实现语法分析的LL(1)方法。
}
void put_setence()
{
char ch;
int i=0;
while((ch=cin.get()) != '#') {
analyz_sentence[i] = ch;
i++;
}
analyz_sentence[i] = '#';
}
void init_stack()
{
stack[0] = '#';
return i;
}
return -1;
}
void reve()
{
strcpy(s, tp);
int i,j;
char t;
i=0;
while (s[i] != '\0')
++i;
--i;
if (s[i] == '\n')
--i;
j=0;
while (j<i)
{
t = s[j];
s[j] = s[i];
cout << "=>";
if (top == 'u')
pop();
}
void pop()
{
编译原理(3)语法_4(自顶向下语法分析:LL(1)分析法)

课本例题3.8 第二步:计算非终结符的FOLLOW集合
G[E]: E→TE' E'→ + TE' | ε T→FT' T'→*FT' | ε F→(E) | i ③由E→TE' 知FOLLOW(E) ⊂ FOLLOW(E' ), 即FOLLOW(E' ) = {),#}; 由E→TE ' 且E ' → ε知FOLLOW(E)FOLLOW(T),即 FOLLOW(T) = {+,),#};
特别是当Y1~Yk均含有ε产生式时,应把ε也加到FIRST(X)中。
课本例题3.8 第一步:计算非终结符的FIRST集合 例3.8 试构造表达式文法G[E]的LL(1)分析表,其中: G[E]: E→TE' E'→ + TE' | ε T→FT' T'→*FT' | ε F→(E) | i
[解答] 首先构造FIRST集,步骤如下: ① FIRST(E') = {+, ε}; FIRST(T') = {*, ε}; FIRST(F) = {(, i}; ② T→F… 和E→T…知:FIRST(F) ⊂ FIRST(T) ⊂ FIRST(E) 即有FIRST(F) = FIRST(T) = FIRST(E) = {(,i}。
编译原理中LL(1)文法的源代码汇总

一. 实验目的1.掌握LL(1分析法的基本原理2.掌握LL(1分析表的构造方法3.掌握LL(1驱动程序的构造方法二. 实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
例:对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E(8)F->i输出的格式如下:(1LL(1)分析程序,编制人:姓名,学号,班级(2输入一以#结束的符号串(包括+—*/()i#:在此位置输入符号串(3输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG(4输入符号串为非法符号串(或者为合法符号串备注:(1在“所用产生式”一列中如果对应有推导则写出所用产生式;如果为匹配终结符则写明匹配的终结符;如分析异常出错则写为“分析出错”;若成功结束则写为“分析成功”。
(2 在此位置输入符号串为用户自行输入的符号串。
(3上述描述的输出过程只是其中一部分的。
注意:1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符i,结束符#;2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照;4.可采用的其它的文法。
三. 实验过程LL(1分析法的实验源程序代码如下:#include#include#include#includechar A[20];/*分析栈*/char B[20];/*剩余串*/char v1[20]={'i','+','*','(','','#'};/*终结符 */char v2[20]={'E','G','T','S','F'};/*非终结符 */int j=0,b=0,top=0,l;/*L为输入串长度 */typedef struct type/*产生式类型定义 */{char origin;/*大写字符 */char array[5];/*产生式右边字符 */int length;/*字符个数 */}type;type e,t,g,g1,s,s1,f,f1;/*结构体变量 */ type C[10][10];/*预测分析表 */void print(/*输出分析栈 */{int a;/*指针*/for(a=0;a<=top+1;a++printf("%c",A[a];printf("\t\t";}/*print*/void print1(/*输出剩余串*/{int j;for(j=0;j 输出对齐符 */printf(" ";for(j=b;j<=l;j++printf("%c",B[j];printf("\t\t\t";}/*print1*/void main({int m,n,k=0,flag=0,finish=0;char ch,x;type cha;/*用来接受C[m][n]*/ /*把文法产生式赋值结构体*/ e.origin='E';strcpy(e.array,"TG";e.length=2;t.origin='T';strcpy(t.array,"FS";t.length=2;g.origin='G';strcpy(g.array,"+TG";g.length=3;g1.origin='G';g1.array[0]='^';g1.length=1;s.origin='S';strcpy(s.array,"*FS";s.length=3;s1.origin='S';s1.array[0]='^';s1.length=1;f.origin='F';strcpy(f.array,"(E";f.length=3;f1.origin='F';f1.array[0]='i';f1.length=1;for(m=0;m<=4;m++/*初始化分析表*/for(n=0;n<=5;n++C[m][n].origin='N';/*全部赋为空*//*填充分析表*/C[0][0]=e;C[0][3]=e;C[1][1]=g;C[1][4]=g1;C[1][5]=g1;C[2][0]=t;C[2][3]=t;C[3][1]=s1;C[3][2]=s;C[3][4]=C[3][5]=s1;C[4][0]=f1;C[4][3]=f;printf("提示:本程序只能对由'i','+','*','(',''构成的以'#'结束的字符串进行分析,\n"; printf("请输入要分析的字符串:";do/*读入分析串*/{scanf("%c",&ch;if ((ch!='i' &&(ch!='+' &&(ch!='*'&&(ch!='('&&(ch!=''&&(ch!='#'{printf("输入串中有非法字符\n";exit(1;}B[j]=ch;j++;}while(ch!='#';l=j;/*分析串长度*/ch=B[0];/*当前分析字符*/A[top]='#'; A[++top]='E';/*'#','E'进栈*/printf("步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 \n"; do{x=A[top--];/*x为当前栈顶字符*/printf("%d",k++;printf("\t\t";for(j=0;j<=5;j++/*判断是否为终结符*/if(x==v1[j]{flag=1;break;}if(flag==1/*如果是终结符*/{if(x=='#'{finish=1;/*结束标记*/printf("acc!\n";/*接受 */getchar(;getchar(;exit(1;}/*if*/if(x==ch{print(;print1(;printf("%c匹配\n",ch;ch=B[++b];/*下一个输入字符*/flag=0;/*恢复标记*/}/*if*/else/*出错处理*/{print(;print1(;printf("%c出错\n",ch;/*输出出错终结符*/ exit(1;}/*else*/}/*if*/else/*非终结符处理*/{for(j=0;j<=4;j++if(x==v2[j]{m=j;/*行号*/break;}for(j=0;j<=5;j++if(ch==v1[j]{n=j;/*列号*/break;}cha=C[m][n];if(cha.origin!='N'/*判断是否为空*/{print(;print1(;printf("%c->",cha.origin;/*输出产生式*/for(j=0;jprintf("%c",cha.array[j];printf("\n";for(j=(cha.length-1;j>=0;j--/*产生式逆序入栈*/ A[++top]=cha.array[j];if(A[top]=='^'/*为空则不进栈*/top--;}/*if*/else/*出错处理*/{print(;print1(;printf("%c出错\n",x;/*输出出错非终结符*/exit(1;}/*else*/}/*else*/}while(finish==0;}/*main*/程序的运行结果如下:四. 实验心得经过这个实验的练习,通过对程序的分析,让我进一步了解LL(1)算法的思想以及它的进一步程序实现,让我对它的了解从简单的理论上升到程序实现的级别,有理论上升到实际,让我更清楚它的用途。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LL(1)文法自动生成语法分析程序的设计任意输入LL(1)文法,自动构造LL(1)分析表并生成相应的语法分析程序,实现LL(1)分析过程;能对输入串进行语法分析,判断其是否符合文法。
进行调试的文法如下:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i算法思想示例如下:1、输入LL(1)文法G[E]2、输入终结字符串input3、获取终结符集tset和非终结符nset4、构造first集和follow集5、根据构造方法构造分析表Mset6、查表、分析程序如下#include<iostream>#include<string.h>using namespace std;struct formula //M表{char ch1;char ch2;char production[10];//存放产生式};struct FirstSet{char ch;char firstset[10];int top;};struct FollowSet{char ch;char followset[10];int top;};char pp[20];bool analyse(char t,char n);//把t n的产生式反向入栈void startwork();void instore();char store[20]; //堆栈int top,aa;char *proc;char input[20];int stop=0;int len;char X;void output();char instr[20][20]; //记录产生式int itop=-1; //记录产生式的条数char nset[20]; //非终结符集合char tset[20]; //终结符集合int ntop=0; //非终结符个数int ttop=-1; //终结符个数bool isterminal(char c);void makenset();void maketset();struct formula Mset[20][20]; //分析表void makefirstset();void makefollowset();void addsinglefollow(char a,char b); void addmultifollow(char a,char b); void addfollow(char a,char b);bool ifcanend(char c);bool haveempty(char n);void addmultifirst(char a,char b);void makeM();//构造M表bool have(char n,char a);struct FirstSet ftset[20];struct FollowSet fwset[20];void addempty(char A,char b);int fttop=0;int fwtop=0;void changeempty();void addM32(int a,char b);void addM33(char);void maketset(){for(int i=0;i<=itop;i++){for(int b=2;b<strlen(instr[i]);b++){if(instr[i][b]!=':'&&instr[i][b]!='|'&&isterminal(instr[i][b])){ for(int x=0;x<=ttop+1;x++){if(instr[i][b]==tset[x]) break;if(x==ttop+1){ttop++;tset[ttop]=instr[i][b];break;}}}}}//最终确定了终结符个数ttop;}bool isterminal(char c){for(int i=0;i<=ntop;i++){if(c==nset[i]) return false;}return true;}void makenset(){nset[0]=instr[0][0];for(int a=1;a<=itop;a++){if(isterminal(instr[a][0])){ntop++;nset[ntop]=instr[a][0];}}//最终确定了非终结符个数}void calculate(){makenset();maketset();changeempty();fttop=ntop;fwtop=ntop;for(int i=0;i<=ntop;i++)ftset[i].ch=nset[i];ftset[i].top=-1;fwset[i].ch=nset[i];fwset[i].top=-1;}makefirstset();makefollowset();makeM();}void addmultifirst(char a,char b){//int mr,mk;for(int i=0;i<=ntop;i++){if(ftset[i].ch==b) {mr=i;}if(ftset[i].ch==a) {mk=i;}}for(int i=0;i<=ftset[mr].top;i++){for(int j=0;j<=ftset[mk].top+1;j++){if(ftset[mr].firstset[i]==ftset[mk].firstset[j]) break;if(j==ftset[mk].top+1){ftset[mk].top++;ftset[mk].firstset[ftset[mk].top]=ftset[mr].firstset[i];break;}}}bool haveempty(char n){for(int i=0;i<=itop;i++){if(instr[i][0]==n&&instr[i][2]=='@')return true;}return false;}void makefirstset(){for(int i=0;i<=itop;i++){if(isterminal(instr[i][2])){for(int j=0;j<=fttop;j++){if(ftset[j].ch==instr[i][0]){ftset[j].top++;ftset[j].firstset[ftset[j].top]=instr[i][2];break;}}}}for(int i=itop;i>=0;i--){for(int j=2;j<strlen(instr[i]);j++){if(isterminal(instr[i][j]))break;if(j==2){addmultifirst(instr[i][0],instr[i][j]);}else{if(haveempty(instr[i][j-1])){addmultifirst(instr[i][0],instr[i][j]);}}}}}void makefollowset(){int i;int mk,mr;fwset[0].top=0;fwset[0].followset[0]='#';for(i=0;i<=itop;i++){for(int j=3;j<strlen(instr[i]);j++){if(!isterminal(instr[i][j-1])&&isterminal(instr[i][j])&&instr[i][2]!='@'){addsinglefollow(instr[i][j-1],instr[i][j]);}if(!isterminal(instr[i][j-1])&&!isterminal(instr[i][j])){addmultifollow(instr[i][j-1],instr[i][j]);}}}for(i=0;i<=itop;i++){for(int j=3;j<=strlen(instr[i]);j++){if(j==strlen(instr[i])&&!isterminal(instr[i][j-1])){addfollow(instr[i][0],instr[i][j-1]);break;}if(!isterminal(instr[i][j-1])&&!isterminal(instr[i][j])){ if(ifcanend(instr[i][j])){addfollow(instr[i][0],instr[i][j-1]);}}}}}bool ifcanend(char a){int mark;for(int i=0;i<=itop;i++){for(int j=0;j<=2;j++){if(instr[i][0]==a&&instr[i][2]=='@') return true;}}return false;}void addsinglefollow(char a,char b){//把字符b添加到非终结符a的follow集中for(int i=0;i<=fwtop;i++){if(fwset[i].ch==a){for(int j=0;j<=fwset[i].top+1;j++){if(fwset[i].followset[j]==b)break;if(j==fwset[i].top||fwset[i].top==-1){fwset[i].top++;fwset[i].followset[fwset[i].top]=b;}}}}}void addmultifollow(char a,char b){int mark1,mark2;for(int i=0;i<=ntop;i++){if(fwset[i].ch==a){mark1=i;continue;}if(ftset[i].ch==b){mark2=i;}}int m2=ftset[mark2].top;for(int i=0;i<=m2;i++){for(int j=0;j<=fwset[mark1].top+1;j++){if(fwset[mark1].followset[j]==ftset[mark2].firstset[i]||ftset[mark2].firstset[i]=='@') break;if(j==fwset[mark1].top||fwset[mark1].top==-1){fwset[mark1].top++;fwset[mark1].followset[fwset[mark1].top]=ftset[mark2].firstset[i];}}}}void addfollow(char a,char b){int mark1,mark2;for(int i=0;i<=ntop;i++){if(fwset[i].ch==a){mark1=i;continue;}if(fwset[i].ch==b){mark2=i;}}int m1=fwset[mark1].top;for(int i=0;i<=m1;i++){for(int j=0;j<=fwset[mark2].top+1;j++){if(fwset[mark1].followset[i]==fwset[mark2].followset[j]||fwset[mark1].followset[i]=='@') break;if(j==fwset[mark2].top||fwset[mark2].top==-1){fwset[mark2].top++;fwset[mark2].followset[fwset[mark2].top]=fwset[mark1].followset[i];}}}}void changeempty(){char temp;for(int i=0;i<ttop;i++){if(tset[i]=='@'){temp=tset[i+1];tset[i+1]=tset[i];tset[i]=temp;}}}void makeM(){for(int i=0;i<ttop;i++){for(int j=0;j<=fttop;j++){for(int k=0;k<=ftset[j].top;k++){if(tset[i]==ftset[j].firstset[k]){addM32(i,ftset[j].ch);continue;}if(ftset[j].firstset[k]=='@')addM33(ftset[j].ch);}}}}void addM32(int a,char b){//a为第a个终结符的索引,b为非终结符A int dicisionA;for(int i=0;i<=ntop;i++){if(nset[i]==b)dicisionA=i;}for(int i=0;i<=itop;i++){if(instr[i][0]==nset[dicisionA]&&have(instr[i][2],tset[a])){strcpy_s(Mset[dicisionA][a].production,instr[i]);break;}}}bool have(char n,char a){//判断非终结符n能否推出终结符a if(isterminal(n)){if(n==a){return true;}}for(int i=0;i<=fttop;i++){if(ftset[i].ch==n){for(int j=0;j<=ftset[i].top;j++){if(ftset[i].firstset[j]==a)return true;}}}return false;}void addM33(char a){//A为非终结符A,n为A的位置for(int i=0;i<=fwtop;i++){if(fwset[i].ch==a){for(int j=0;j<=fwset[i].top;j++){//获取A的终结符b addempty(a,fwset[i].followset[j]);}}}}void addempty(char A,char b){int markA,markb;char XX[4];for(int i=0;i<=ntop;i++){if(nset[i]==A){markA=i;break;}}for(int j=0;j<=ttop;j++){if(tset[j]==b||j==ttop){markb=j;break;}}XX[0]=A;XX[1]=':';XX[2]='@';strcpy_s(Mset[markA][markb].production,XX); }void instore(){top--;for(int b=0;b<strlen(proc);b++){top++;store[top]=proc[b];}store[top+1]='\0';cout<<store<<"\t\t\t";output();cout<<endl;}bool analyse(char n,char t){ //分析表M,输入终结符t和非终结符n for(int i=0;i<20;i++){pp[i]='\0';}proc="";int indexn,indext;for(int i=0;i<=ntop;i++){if(nset[i]==n){indexn=i;break;}}for(int i=0;i<=ttop;i++){if(tset[i]==t){indext=i;break;}}if(strlen(Mset[indexn][indext].production)!=0){//将产生式反向付给proc;if(Mset[indexn][indext].production[2]=='@'){proc="";return true;}int x=strlen(Mset[indexn][indext].production);//反向导入for(int i=x-1,j=0;i>=2;i--,j++){pp[j]=Mset[indexn][indext].production[i];}proc=pp;return true;}return false;}void output(){for(int i=stop;i<=len;i++){cout<<input[i];}}void startwork(){aa=input[stop];X=store[top];if(isterminal(X)&&X!='#') {if(X==aa){stop++;top--;startwork();}else {cout<<"该字符串不符合该文法"<<endl;}}else {if(X=='#'){if(X==aa){cout<<"分析成功"<<endl;return;}else{abort();}}else {if(X==aa){top--;stop++;startwork();}else {if(analyse(X,aa)){instore();startwork();}else{cout<<"该字符串不符合该文法"<<endl;return;} }}}}void main(){strcpy_s(instr[0],"E:Te");strcpy_s(instr[1],"e:+Te");strcpy_s(instr[2],"e:@");strcpy_s(instr[3],"T:Ft");strcpy_s(instr[4],"t:*Ft");strcpy_s(instr[5],"t:@");strcpy_s(instr[6],"F:(E)");strcpy_s(instr[7],"F:i");//以上8句系ll(1)文法。