数字语音处理实验报告分析解析
语音信号处理实验报告.docx
在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10。
5.基音周期估计
①自互相关函数法
②短时平均幅度差法
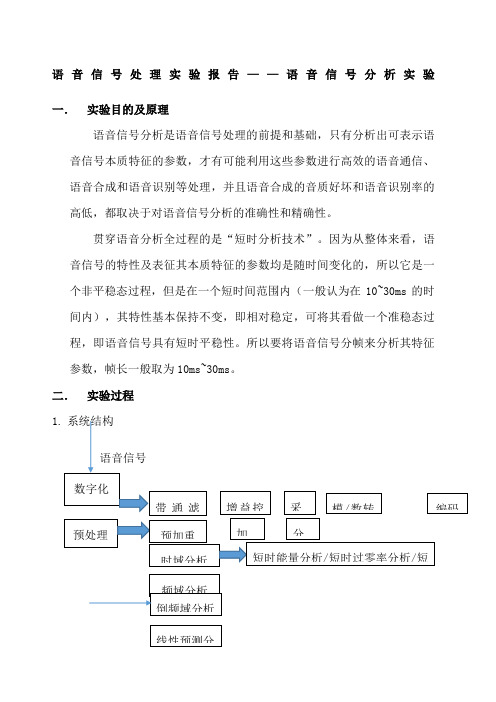
二.实验过程
1. 系统结构
2.仿真结果
(1)时域分析
男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)
某一帧的自相关函数
3.频域分析
①一帧信号的倒谱分析和FFT及LPC分析
②男声和女声的倒谱分析
③浊音和清音的倒谱分析
④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
2.频域分析
这里对信号进行快速傅里叶变换(FFT),可以发现,当窗口函数不同,傅里叶变换的结果也不相同。根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄。汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗。
三.实验结果分析
1.时域分析
实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。这里窗长合适,En能够反应语音信号幅度变化。同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
语音信号处理实验报告实验二

语音信号处理实验报告实验二一、实验目的本次语音信号处理实验的目的是深入了解语音信号的特性,掌握语音信号处理的基本方法和技术,并通过实际操作和数据分析来验证和巩固所学的理论知识。
具体而言,本次实验旨在:1、熟悉语音信号的采集和预处理过程,包括录音设备的使用、音频格式的转换以及噪声去除等操作。
2、掌握语音信号的时域和频域分析方法,能够使用相关工具和算法计算语音信号的短时能量、短时过零率、频谱等特征参数。
3、研究语音信号的编码和解码技术,了解不同编码算法对语音质量和数据压缩率的影响。
4、通过实验,培养我们的动手能力、问题解决能力和团队协作精神,提高我们对语音信号处理领域的兴趣和探索欲望。
二、实验原理(一)语音信号的采集和预处理语音信号的采集通常使用麦克风等设备将声音转换为电信号,然后通过模数转换器(ADC)将模拟信号转换为数字信号。
在采集过程中,可能会引入噪声和干扰,因此需要进行预处理,如滤波、降噪等操作,以提高信号的质量。
(二)语音信号的时域分析时域分析是对语音信号在时间轴上的特征进行分析。
常用的时域参数包括短时能量、短时过零率等。
短时能量反映了语音信号在短时间内的能量分布情况,短时过零率则表示信号在单位时间内穿过零电平的次数,可用于区分清音和浊音。
(三)语音信号的频域分析频域分析是将语音信号从时域转换到频域进行分析。
通过快速傅里叶变换(FFT)可以得到语音信号的频谱,从而了解信号的频率成分和分布情况。
(四)语音信号的编码和解码语音编码的目的是在保证一定语音质量的前提下,尽可能降低编码比特率,以减少存储空间和传输带宽的需求。
常见的编码算法有脉冲编码调制(PCM)、自适应差分脉冲编码调制(ADPCM)等。
三、实验设备和软件1、计算机一台2、音频采集设备(如麦克风)3、音频处理软件(如 Audacity、Matlab 等)四、实验步骤(一)语音信号的采集使用麦克风和音频采集软件录制一段语音,保存为常见的音频格式(如 WAV)。
数字音频实训总结报告

一、引言随着信息技术的飞速发展,数字音频技术在我国得到了广泛应用。
为了提高自身在数字音频领域的实践能力,我参加了为期一个月的数字音频实训。
通过这次实训,我对数字音频的基本原理、操作技能以及实际应用有了更加深入的了解。
以下是我对本次实训的总结报告。
二、实训目的1. 掌握数字音频的基本原理和操作技能;2. 熟悉数字音频编辑软件的使用;3. 了解数字音频在实际应用中的价值;4. 培养团队合作精神和创新能力。
三、实训内容1. 数字音频基本原理(1)数字音频的基本概念:数字音频是指将模拟信号转换为数字信号,再通过数字信号处理技术进行编辑、存储和传输的音频信号。
(2)数字音频的采样、量化、编码:采样是将连续的模拟信号转换为离散的数字信号;量化是将采样得到的数字信号按照一定的精度进行表示;编码是将量化后的数字信号转换为二进制数据。
(3)数字音频的格式:常见的数字音频格式有MP3、WAV、AAC等。
2. 数字音频编辑软件的使用(1)Audacity:一款开源、免费的数字音频编辑软件,功能强大,操作简单。
(2)Adobe Audition:一款专业的数字音频编辑软件,界面美观,功能丰富。
3. 数字音频实际应用(1)音乐制作:数字音频技术在音乐制作领域有着广泛的应用,如音频剪辑、混音、母带处理等。
(2)影视后期制作:数字音频技术可以用于影视后期制作中的音效制作、配音、音轨剪辑等。
(3)广播、播客:数字音频技术在广播、播客等领域有着重要的应用,如音频剪辑、音频处理、音频合成等。
四、实训过程及成果1. 实训过程(1)理论学习:通过查阅资料、观看视频等方式,对数字音频的基本原理、操作技能和实际应用进行深入学习。
(2)软件操作:在指导下,学习并熟练掌握Audacity和Adobe Audition两款数字音频编辑软件的使用。
(3)实践操作:通过实际操作,完成音频剪辑、混音、母带处理等任务。
2. 实训成果(1)掌握了数字音频的基本原理和操作技能。
数字语音处理课程实验报告

数字语音处理课程报告语音信号的采集与分析摘要语音信号的采集与分析技术是一门涉及面很广的交叉科学,它的应用和发展与语音学、声音测量学、电子测量技术以及数字信号处理等学科紧密联系。
其中语音采集和分析仪器的小型化、智能化、数字化以及多功能化的发展越来越快,分析速度较以往也有了大幅度的高。
本文简要介绍了语音信号采集与分析的发展史以及语音信号的特征、采集与分析方法,并通过PC机录制自己的一段声音,运用Matlab进行仿真分析,最后加入噪声进行滤波处理,比较滤波前后的变化。
关键词:语音信号,采集与分析,时域,频域0 引言通过语音传递信息是人类最重要、最有效、最常用和最方便的交换信息的形式。
语言是人类持有的功能.声音是人类常用的工具,是相互传递信息的最主要的手段。
因此,语音信号是人们构成思想疏通和感情交流的最主要的途径。
并且,由于语言和语音与人的智力活动密切相关,与社会文化和进步紧密相连,所以它具有最大的信息容量和最高的智能水平。
现在,人类已开始进入了信息化时代,用现代手段研究语音信号,使人们能更加有效地产生、传输、存储、获取和应用语音信息,这对于促进社会的发展具有十分重要的意义。
让计算机能听懂人类的语言,是人类自计算机诞生以来梦寐以求的想法。
随着计算机越来越向便携化方向发展,随着计算环境的日趋复杂化,人们越来越迫切要求摆脱键盘的束缚而代之以语音输人这样便于使用的、自然的、人性化的输人方式。
作为高科技应用领域的研究热点,语音信号采集与分析从理论的研究到产品的开发已经走过了几十个春秋并且取得了长足的进步。
它正在直接与办公、交通、金融、公安、商业、旅游等行业的语音咨询与管理.工业生产部门的语声控制,电话、电信系统的自动拨号、辅助控制与查询以及医疗卫生和福利事业的生活支援系统等各种实际应用领域相接轨,并且有望成为下一代操作系统和应用程序的用户界面。
可见,语音信号采集与分析的研究将是一项极具市场价值和挑战性的工作。
我们今天进行这一领域的研究与开拓就是要让语音信号处理技术走人人们的日常生活当中,并不断朝更高目标而努力。
语音处理实验报告

实验一语音信号的端点检测一、实验目的1、掌握短时能量的求解方法2、掌握短时平均过零率的求解方法3、掌握利用短时平均过零率和短时能量等特征,对输入的语音信号进行端点检测。
二、仪器设备实验仪器设备及软件HP计算机,MATLAB三、实验原理端点检测是语音信号处理过程中非常重要的一步,它的准确性直接影响到语音信号处理的速度和结果。
本次实验利用短时过零率和短时能量相结合的语音端点检测算法利用短时过零率来检测清音,用短时能量来检测浊音,两者相配合便实现了信号信噪比较大情况下的端点检测。
算法对于输入信号的检测过程可分为短时能量检测和短时过零率检测两个部分。
算法以短时能量检测为主,短时过零率检测为辅。
根据语音的统计特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。
在本算法中,短时能量检测可以较好地区分出浊音和静音。
对于清音,由于其能量较小,在短时能量检测中会因为低于能量门限而被误判为静音;短时过零率则可以从语音中区分出静音和清音。
将两种检测结合起来,就可以检测出语音段(清音和浊音)及静音段1、短时能量计算定义n 时刻某语言信号的短时平均能量为:En ∑∑--=+∞∞--=-=n N n m m n w m x m n w m x En )1(22)]()([)]()([式中N 为窗长,可见短时平均能量为一帧样点值的平方和。
特殊地,当窗函数为矩形窗时,有∑--==n N n m m x En )1(2)(2、短时过零率过零就是指信号通过零值。
过零率就是每秒内信号值通过零值的次数。
对于离散时间序列,过零则是指序列取样值改变符号,过零率则是每个样本的改变符号的次数。
对于语音信号,则是指在一帧语音中语音信号波形穿过横轴(零电平)的次数。
可以用相邻两个取样改变符号的次数来计算。
用过零率检测清音,用短时能量检测浊音,两者配合。
首先为短时能量和过零率分别确定两个门限,一个是较低的门限数值较小,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。
实验一 数字音频处理实验

实验一数字音频处理实验一、实验目的:1、探讨采样频率对数据量的影响,对音质的影响以及带来的其他问题。
2、学习并掌握基本的音频处理手段。
3、熟悉和掌握WAV标准音频文件和MP3压缩音频文件的编辑方法。
二、实验要求:独立进行实验,完成实验报告。
三、实验内容:1、理论内容:在多媒体产品中,声音是必不可少的对象,其主要表现形式是语音、自然声和音乐。
要处理声音,首先要把声音数字化,这个过程叫做音频采样。
有了数字化声音后,接着对其进行处理。
处理方式主要有:剪辑、合成、制作特殊效果、增加混响、调整时间长度、改善频响特性等。
音质的好坏与采样频率成正比,当然,也与数据量成正比。
换言之,采样频率越高,音质越好,数据量也越大。
2、实验内容:(1)获取声音:准备好以WAV和MP3两种格式保存的文件,WAV格式无压缩,音质好,能够忠实地还原自然声;MP3格式是压缩格式,在压缩比不大的情况下,音质也非常好。
(2)录制声音:在录制之前,把麦克风连接到声卡上,如果使用的是带麦克风的头带耳机,检查连接线是否接好。
A、使用“录音机”录制练习:如果录制小于1min的声音,可使用Windows自带的“录音机”软件录制。
操作步骤:a、启动录音机软件。
b、单击录音按钮,开始录音。
此时,进程滑块向右移动,到右端终点位置停止,时间正好1min。
c、单击播放按钮,聆听效果。
如果不满意,选择“文件/新建”菜单,清除录音,重新进行步骤b。
d、转换采样频率。
选择“文件/属性”菜单,显示“声音的属性”画面。
“声音的属性”画面自上而下显示了声音文件的版权、长度、数据大小、音频格式。
其中的音频格式就是当前文件的采样频率。
画面显示“PCM 44100 Hz,16位,立体声”,对于语音来说,采样频率过高了,数据量过大,造成存储空间的浪费。
单击开始转换按钮,显示“选择声音”画面。
在“选择声音”画面的“属性”选择框中,选择适合语音的采样频率“22050Hz,8位,单声道22KB/s”,单击“确定”按钮。
数字信号处理语音处理课程设计实验报告
实验报告(1)语音采样和观察clear,clc;[y,fs]=audioread('E:\大学课程\大三上\数字信号处理\201400121184吴蔓.mp3'); %语音信号的采集,把采样值放在y中subplot(3,1,1)plot(y);title('时域波形');sound(y,fs); %语音信号的播放n=length(y) %计算语音信号的长度Y=fft(y) ; %快速傅里叶变换subplot(3,1,2)plot(abs(Y)); %绘出频域波形title('幅频特性');subplot(3,1,3)plot(angle(Y));title('相频特性');plot(angle(Y1)); title('延时后相频特性');0.511.522.533.544.5x 105-0.500.5延时后时域波形0.511.522.533.544.5x 10505001000延时后幅频特性0.511.522.533.544.5x 105-505延时后相频特性我延时了和原信号一样长的点数,可以看出来延时后的信号要后播放一小段时间并且幅频相频差别不大。
(3)混响: clear,clc;[y,fs]=audioread('E:\大学课程\大三上\数字信号处理\201400121184吴蔓.mp3'); %语音信号的采集一,加一撇表示转置。
如右图二,语音信号真的大多数是在3.4khz以内的,由下面三图对比可以发现,实际人的声音只在一段频率范围内,并且主要集中在3400hz以内。
但录制的语音还有一些少许的幅度很低的高频信号达到了100khz,那都是人耳听不见的声音。
也可以看出声音占得频谱很宽,并且是在数字域的pi也就是模拟域的FS以内,audioread函数读取Mp3格式的采样率大约是44100hz。
也可以看出采样时大致满足奈奎斯特定理,fs约等于2fh.(5)多重回声(回声数量有限):clear,clc;[y,fs]=audioread('E:\大学课程\大三上\数字信号处理\201400121184吴蔓.mp3') ; %语音信号的采集,从命令行窗口的输出可以看出%采样后的信号矩阵是多行一列的,下面n=length(y0)语句计算出来有220032个采样数据,有的数据为0,大多数数据是复数y0= y (:,1);%冒号代表“所有的”,这里指的是把y的所有行的第一列给y0,实际上y0和y 一样的,这句指令用来取单声道信号N=3; %三重回声y1=filter(1,[1,zeros(1,80000/(N+1)),0.5],y');%这里的y'指的是y的转置矩阵,故是一行多列的,y'作为filter函数的输入矩阵%[1,zeros(1,30000),0.5]是分母矩阵,1是分子,就相当于这是个无限长的信号,求其差分方程,y1是输出矩阵,这里filter函数相当于是个IIR滤波器,系统函数%相当于H(Z)=1/(1-0.5Z.^(-30001)).sound(10*y1,fs); %回放三重回声信号,这里乘以10以加强信号,便于听取,因为如果衰减系数太大则回声难以听见n=length(y0) ;Y0=fft(y0) ;Y=fft(y1) ;figure(1);subplot(2,1,1)plot(y);title('原音时域波形');axis([0 225000 -0.4 0.6]);subplot(2,1,2)plot(y1);title('多重回声时域波形');。
数字语音信号处理实验报告
语音信号处理实验报告专业班级电子信息1203学生姓名钟英爽指导教师覃爱娜完成日期2015年4月28日电子信息工程系信息科学与工程学院实验一语音波形文件的分析和读取一、实验学时:2 学时二、实验的任务、性质与目的:本实验是选修《语音信号处理》课的电子信息类专业学生的基础实验。
通过实验(1)掌握语音信号的基本特性理论:随机性,时变特性,短时平稳性,相关性等;(2)掌握语音信号的录入方式和*.WAV音波文件的存储结构;(3)使学生初步掌握语音信号处理的一般实验方法。
三、实验原理和步骤:WAV 文件格式简介WAV 文件是多媒体中使用了声波文件的格式之一,它是以RIFF格式为标准。
每个WAV 文件的头四个字节就是“RIFF”。
WAV 文件由文件头和数据体两大部分组成,其中文件头又分为RIFF/WAV 文件标识段和声音数据格式说明段两部分。
常见的WAV 声音文件有两种,分别对应于单声道(11.025KHz 采样率、8Bit 的采样值)和双声道(44.1KHz 采样率、16Bit 的采样值)。
采样率是指声音信号在“模拟→数字”转换过程中,单位时间内采样的次数;采样值是指每一次采样周期内声音模拟信号的积分值。
对于单声道声音文件,采样数据为8 位的短整数(short int 00H-FFH);而对于双声道立体声声音文件,每次采样数据为一个16 位的整数(int),高八位和低八位分别代表左右两个声道。
WAV 文件数据块包含以脉冲编码调制(PCM)格式表示的样本。
在单声道WAV 文件中,道0 代表左声道,声道1 代表右声道;在多声道WAV 文件中,样本是交替出现的。
WAV 文件的格式表1 wav文件格式说明表(1)选取WINDOWS 下MEDIA 中的任一WAV 文件,采用播放器进行播放,观察其播放波形,定性描述其特征;(2)录入并存储本人姓名语音文件(姓名.wav),根据WAV 文件的储格式,利用MATLAB 或C 语言,分析并读取文件头和数据信息;(3)将文件的通道数、采样频率、样本位数和第一个数据读取并示出来。
语音信号处理实验报告
一、实验目的1. 理解语音信号处理的基本原理和流程。
2. 掌握语音信号的采集、预处理、特征提取和识别等关键技术。
3. 提高实际操作能力,运用所学知识解决实际问题。
二、实验原理语音信号处理是指对语音信号进行采集、预处理、特征提取、识别和合成等操作,使其能够应用于语音识别、语音合成、语音增强、语音编码等领域。
实验主要包括以下步骤:1. 语音信号的采集:使用麦克风等设备采集语音信号,并将其转换为数字信号。
2. 语音信号的预处理:对采集到的语音信号进行降噪、去噪、归一化等操作,提高信号质量。
3. 语音信号的特征提取:提取语音信号中的关键特征,如频率、幅度、倒谱等,为后续处理提供依据。
4. 语音信号的识别:根据提取的特征,使用语音识别算法对语音信号进行识别。
5. 语音信号的合成:根据识别结果,合成相应的语音信号。
三、实验步骤1. 语音信号的采集使用麦克风采集一段语音信号,并将其保存为.wav文件。
2. 语音信号的预处理使用MATLAB软件对采集到的语音信号进行预处理,包括:(1)降噪:使用谱减法、噪声抑制等算法对语音信号进行降噪。
(2)去噪:去除语音信号中的杂音、干扰等。
(3)归一化:将语音信号的幅度归一化到相同的水平。
3. 语音信号的特征提取使用MATLAB软件对预处理后的语音信号进行特征提取,包括:(1)频率分析:计算语音信号的频谱,提取频率特征。
(2)幅度分析:计算语音信号的幅度,提取幅度特征。
(3)倒谱分析:计算语音信号的倒谱,提取倒谱特征。
4. 语音信号的识别使用MATLAB软件中的语音识别工具箱,对提取的特征进行识别,识别结果如下:(1)将语音信号分为浊音和清音。
(2)识别语音信号的音素和音节。
5. 语音信号的合成根据识别结果,使用MATLAB软件中的语音合成工具箱,合成相应的语音信号。
四、实验结果与分析1. 语音信号的采集采集到的语音信号如图1所示。
图1 语音信号的波形图2. 语音信号的预处理预处理后的语音信号如图2所示。
语音信号处理实验报告
实验报告一、 实验目的、要求(1)掌握语音信号采集的方法(2)掌握一种语音信号基音周期提取方法(3)掌握短时过零率计算方法(4)了解Matlab 的编程方法二、 实验原理基本概念:(a )短时过零率:短时内, 信号跨越横轴的情况, 对于连续信号, 观察语音时域波形通过横轴的情况;对于离散信号, 相邻的采样值具有不同的代数符号, 也就是样点改变符号的次数。
对于语音信号, 是宽带非平稳信号, 应考察其短时平均过零率。
其中sgn[.]为符号函数⎪⎩⎪⎨⎧<=>=0 x(n)-1sgn(x(n))0 x(n)1sgn(x(n))短时平均过零的作用1.区分清/浊音:浊音平均过零率低, 集中在低频端;清音平均过零率高, 集中在高频端。
2.从背景噪声中找出是否有语音, 以及语音的起点。
(b )基音周期基音是发浊音时声带震动所引起的周期性, 而基音周期是指声带震动频率的倒数。
基音周期是语音信号的重要的参数之一, 它描述语音激励源的一个重要特征, 基音周期信息在多个领域有着广泛的应用, 如语音识别、说话人识别、语音分析与综合以及低码率语音编码, 发音系统疾病诊断、听觉残障者的语音指导等。
因为汉语是一种有调语言, 基音的变化模式称为声调, 它携带着非常重要的具有辨意作用的信息, 有区别意义的功能, 所以, 基音的提取和估计对汉语更是一个十分重要的问题。
由于人的声道的易变性及其声道持征的因人而异, 而基音周期的范围又很宽, 而同—个人在不同情态下发音的基音周期也不同, 加之基音周期还受到单词∑--=-=10)]1(sgn[)](sgn[21N m n n n m x m x Z发音音调的影响, 因而基音周期的精确检测实际上是一件比较困难的事情。
基音提取的主要困难反映在: ①声门激励信号并不是一个完全周期的序列, 在语音的头、尾部并不具有声带振动那样的周期性, 有些清音和浊音的过渡帧是很难准确地判断是周期性还是非周期性的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数字语音处理实验报告题目语音端点检测作者学院专业班级学号指导教师目录摘要: (2)前言: (2)1、实现原理 (3)1.1基本公式: (3)1.2 理论基础: (3)1.3 基本思路: (4)2、 matlab实现 (4)2.1 程序流程图: (4)2.2 程序分析 (5)2.2.1 流程图的说明 (5)2.2.2 起点和终点的判断 (5)2.2.3 enframe函数的说明 (5)2.2.4 过零率的计算 (7)2.2.5能量的计算 (8)2.3 运行结果 (9)总结 (10)参考文献 (11)附录:完整源程序 (12)摘要:短时能量分析和过零率分析作为语音信号时域分析中最基本的方法,应用相当广泛,特别是在语音信号端点检测方面。
由于在语音信号端点检测方面这两种方法通常是独立使用的,在端点检测的时候很容易漏掉重要的信息。
本文将这两种方法结合起来,利用MATLAB 工具对其进行了分析。
实验结果表明,检测的效果好于分别使用其中一种方法的情况。
关键词:端点检测,短时能量过零率门限前言:近年来,在语音信号处理领域,关于语音信号中端点检测及判定的研究越来越重要。
作为语音识别的前提工作,有效的端点检测方法不仅可以减少数据的存储量和处理时间,而且可以排除无声段的噪声干扰,使语音识别更为准确。
目前的语音信号端点检测算法比较多,有短时能量,短时过零率分析,自相关法等等,其中以短时能量和短时过零率用的最多。
大多文献和教材都是把它们分别进行介绍,由于它们各有其优缺点,分别使用作为语音端点检测的手段难免会漏掉很多有用的信息,因此,笔者将这两种方法结合起来进行分析,在判断清浊音及静音方面可以起到互补的作用,从语音信号的短时能量和过零率分析的特点出发,加以门限值来分析将两种方法相结合应用的效果,最后通过Matlab 进行了仿真。
1、实现原理1.1基本公式:短时能量公式:设第n帧语音信号Xn(m)的短时能量用En表示,其计算公式为:式中,N为信号帧长。
短时过零率公式:其中,sgn[]是符号函数,即:1.2 理论基础:语音信号一般可分为无声段、清音段和浊音段。
无声段是背景噪声段, 平均能量最低; 浊音段为声带振动发出对应的语音信号段, 平均能量最高; 清音段是空气在口腔中的摩擦、冲击或爆破而发出的语音信号段, 平均能量居于前两者之间。
清音段和无声段的波形特点有明显的不同, 无声段信号变化较为缓慢, 而清音段信号在幅度上变化剧烈, 穿越零电平次数也多。
经验表明, 通常清音段过零率最大。
端点检测就是首先判断“有声”还是“无声”, 如果有声,则还要判断是“清音”还是“浊音”。
为正确地实现端点检测, 一般综合利用短时能量和过零率两个特征,采用“双门限检测法”。
1.3 基本思路:根据信号设置三个阈值:能量阈值,TL,TH;过零率阈值ZCR,当某帧信号大于TL 或者大于ZCR时,认为信号的开始、起点,当大于TH时,则认为正式的语音信号,如果保持一段时间,则确认这信号即所需信号。
2、 matlab实现2.1 程序流程图:2.2 程序分析2.2.1 流程图的说明amp2,amp1为能量的两个阈值,前者为小的,后者为大的,zcr2为过零率的阈值小值,当>amp2 or >zcr2,count开始加1,在此期间如果有不满足该条件的话,count立即为0,回到0状态。
如果>amp1 时,count加1,然后进入2状态。
在2状态里边,当>amp2 or >zcr2,count也1,如果不满足条件,则Silence+1,如果Silence即在2状态期间处于静音状态满足结束时的静音条件,则判断所有计数的信号即count的值是否满足最小的语音信号长度值,如果满足,则找到结束点,否则认为是噪声,重新开始。
如果Silence即在2状态期间处于静音状态不足结束时的静音条件,则count继续加1。
2.2.2 起点和终点的判断即判断X1,X2。
根据程序x1=max(n-count-1,1);n为找到>amp1时,此时的贞的序列值。
而count为在这之前的>amp2 or >zcr2,的贞的个数。
一般突发信号从无慢慢到有,如果N=6,COUNT=2,则起点从第三帧开始。
很好理解。
对于X2,有count = count-silence/2;x2 = x1 + count - 1;总count值为>amp2 or >zcr2开始,到判断超过最小静音为止。
而当进入silence加的时候,已经为静音阶段了。
当silence=6时,便结束了,然后X2的计算方法,基本了解,但silence/2感觉可以不要也行,后边的-1也感觉可以不要。
2.2.3 enframe函数的说明前边算能量,过零率都是基于帧来计算的,而enframe函数是用来把信号进行分帧的。
其代码如下:function f=enframe(x,win,inc)nx=length(x(:)); % x(:)的作用是把x给弄成一个向量,x为一行,则变成一列, % 如果为矩阵,则按每一列的顺序排成一列。
% 得出的nx为序列的数据个数。
nwin=length(win);if (nwin == 1)len = win; % 如果win中就一个数,则len就=该数,此例中为256个点。
elselen = nwin; % 如果有多个数,则len=个数。
endif (nargin < 3) % nargin返回的是函数输入的个数,% 如果中间有变量,返回的是负值。
inc = len; % 也就是说,如果函数enframe的输入只有两个的话,% 系统就自动赋incendnf = fix((nx-len+inc)/inc); % 这个比较关键,nf为分帧的组数,% 结合下边的可以分析这里各参数的意义,% len为帧长,inc为未覆盖的数据,% nx为整个数据量。
假设数据为1:30,% len为10,未覆盖为5,则nf=5,5组,% 第一组为1,2,……10,% 第二组为6,7,……15,依次列推,% 便可知其缘由,即(nx-len )/inc + 1;f=zeros(nf,len); % 构成以组数为行,帧长为列的矩阵。
indf= inc*(0:(nf-1)).'; % indf为一列nf个数据,即0到nf-1的inc倍, % 即分好了每幀起点。
inds = (1:len); % 构成了长度为len的一行。
f(:) = x(indf(:,ones(1,len))+inds(ones(nf,1),:));% 上一条语句为整个算法的核心部分了,indf(:,ones(1,len))把indf的% 第一列扩展了nf*len的矩阵。
同理inds(ones(nf,1),:)把inds第一行扩 % 展为nf*len的矩阵,相加得到% [ 1 2 3 …… len% inc+1 inc+2 inc+3 …… inc+len% 2*inc+1………………2*inc+len% 。
…………………………………]% 然后就按照这个矩阵从x中把数据给选出来,达到分帧的目的。
if (nwin > 1) % nwin大于1的情况这里就没有讨论了。
w = win(:)';f = f .* w(ones(nf,1),:);end2.2.4 过零率的计算其语句如下:tmp1 = enframe(x(1:end-1), FrameLen,inc);tmp2 = enframe(x(2:end) , FrameLen,inc);signs = (tmp1.*tmp2)<0; % 对于tmp1.*tmp2算出来的矩阵,% 矩阵中<0的数都为1,其他为0,后边也是一样的。
diffs = (tmp1 - tmp2)>0.02;zcr = sum(signs.*diffs,2);假设数据量为1,2……21,帧长为10,inc为5,则tmp1为[1 2 3 4 5 6 7 8 9 106 7 8 9 10 11 12 13 14 1511 12 13 14 15 16 17 18 19 20]tmp2为[2 3 4 5 6 7 8 9 10 117 8 9 10 11 12 13 14 15 1612 13 14 15 16 17 18 19 20 21]在这里注意一个问题:即数组的乘法与矩阵的乘法是不一样的。
数组乘法:A.*A,矩阵乘法:A*A’。
前者有‘.’号,算出来的结果是在矩阵A中每一个数据平方,而后者成为另一个数组,行与列相乘然后相加作为一个值。
在这里tmp1.*tmp2为数组相乘,第一个数乘以第二个数,第二个数乘以第三个数,依次,从而判断两者的符号,<0的为1。
然后进行相减,第一个减第二个数,第二个减第三个数……,>0.02,为什么>0.02了?首先得到的signs是真正的过零率,但得限制能量,因为对于噪音的话,也会在0点附近上下摆动,但噪声能量显然是没有语音大的,根据实际情况,所以选择>0.02,2.2.5能量的计算语句为:amp = sum((abs(enframe( x, FrameLen, inc))).^2, 2);通过对enframe 函数的分析,就比较容易了,enframe 对x 分帧后,绝对值然后平方,最后是sum (x ,2)2代表是各列相加最后得到的是一列数据,即各帧的平方和。
从中可以看出矩阵处理数据的方便性,一个矩阵就把各帧的结果给弄出来了。
2.3 运行结果123456789x 104-101S p e e ch1002003004005006007008009001000100E n e r gy1002003004005006007008009001000510Z CR总结参考文献[1] 杨行峻,迟惠生.语音信号数字处理[M]. 北京:电子工业出版杜,2003[2] 王华朋,杨洪臣.声纹识别特征MFCC的提取方法研究[J],中国人民公安大学学报,2008[3] 林波, 吕明.基于DTW改进算法的孤立词识别系统的仿真与分析[J].信息技术,2006年第4期.[4] 丁美玉,高西全.数字信号处理[M].西安电子科技大学出版社,2004.68-71[5] 李潇,王大堃.基于MATLAB 的孤立字语音识别试验平台[J].四川理工学院学报(自然科学版),第19 卷第3 期,1673-1549(2006)03-0097-04.[6] 黄文梅,杨勇,熊桂林,成晓明.系统仿真分析与设计——Matlab语音工程应用[M].国防科技大学出版社.[7] 李宏松,苏健民,黄英来,于慧伶.基于声音信号的特征提取方法的研究[J].信息技术, 2006[8] 方绍武,戴蓓倩.VQ话者模型中失真测度的鲁棒性研究[J]. 数据采集与处理. 第1卷,第2期.2000年[9] D.G.Childers. Speech Processing and Synthesis Toolboxes[M].北京:清华大学出版社,2004.[10] Cooley J W, Tukey J W. An algorithm for the machine computation of complex Fourierseries [J]. Mathematical Computations, 1965,19:297-301.[11] 何强,何英.MATLAB扩展编程[M].第一版,北京:清华大学出版社.[12] Oppenbeim AV,Schafer RW.Digital signal Processing[M].Prentice Hall,Inc,1975.附录:完整源程序% 语音信号的端点检测matlab实现:[x,fs,nbits]=wavread('ni.wav');%首先打开语音文件x = x / max(abs(x));%幅度归一化到[-1,1]%参数设置FrameLen = 256; %帧长inc = 90; %未重叠部分amp1 = 10; %短时能量阈值amp2 = 2;zcr1 = 10; %过零率阈值zcr2 = 5;minsilence = 6; %用无声的长度来判断语音是否结束minlen = 15; %判断是语音的最小长度status = 0; %记录语音段的状态count = 0; %语音序列的长度silence = 0; %无声的长度%计算过零率tmp1 = enframe(x(1:end-1), FrameLen,inc);tmp2 = enframe(x(2:end) , FrameLen,inc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 - tmp2)>0.02;zcr = sum(signs.*diffs,2);%计算短时能量amp = sum((abs(enframe( x, FrameLen, inc))).^2, 2);%调整能量门限amp1 = min(amp1, max(amp)/4);amp2 = min(amp2, max(amp)/8);%min函数是求最小值的,没必要说了。