Tracking website data-collection and privacy practices with the iWatch web crawler
船运货物跟踪网址大全

船运货物跟踪网址大全"K" Line (Hong Kong) Ltd.川崎(香港)有限公司/GctApp/search?id=trackerAPL Co. Pte Ltd美国总统轮船私人有限公司/GctApp/search?id=trackerCheng Lie Navigation (HK) Co., Ltd.正利航业(香港)有限公司/GctApp/search?id=trackerChina Shipping Container Lines (Hong Kong) Co., Limited.中海集装箱运输(香港)有限公司:6060/cargo_track.jspCMA CGM & ANL (HK) Shipping Agencies Ltd./eBusiness/Tracking/Default.aspxCosco (H.K.) Cargo Service Co., Ltd中远(香港)货运服务有限公司/ebusiness/ ... =init&locale=enCosco Container Line/ebusiness/ ... =init&locale=enCosco Container Line Agencies Ltd.中远货柜代理有限公司/ebusiness/ ... =init&locale=enCSAV/rastreo/rastreo.nsf/YourTrace?OpenForm Delmas Hong Kong Ltd.香港达贸轮船有限公司/html/Clubdelmas/tracking/tracking_GB.asp Evergreen Marine (Hong Kong) Ltd./servlet/TDB1_CargoTracking.do Hamburg Sud Hong Kong Ltd汉堡南美香港有限公司/WWW/EN ... and_Trace/index.jsp Hanjin Shipping Co., Ltd.韩进海运/eservice/cn/cargo/front.doHapag-Lloyd (China) Ltd.http://www.hlcl.de/inet/Dispatch ... cing&language=I Hatsu Marine Limitedhttp://www.hlcl.de/inet/Dispatch ... cing&language=I Hyundai Merchant Marine (Hong Kong) Ltd.现代商船(香港)有限公司/hmm/ebiz/track_trace/main_new.jsp IRISL/transporte ... mCargoTracking.aspx Italia Marittima Hong Kong Limited意大利海运香港有限公司http://www.italiamarittima.it/TDB1_LTCargoTrack.asp KMTC Linehttp://www.kmtc.co.kr/kmtc/eng/e ... king/track_list.jsp Maersk (China) Shipping Co., Ltd.马士基?中国?有限公司/appman ... acking3_trackSimple Maersk Hong Kong Ltd.马士基香港有限公司/appman ... acking3_trackSimple Mediterranean Shipping Co., (Hong Kong) Ltd.地中海航运(香港)有限公司http://www.mscgva.ch/php/msctracking.phpModern Shipping Ltd.http://www.kmtc.co.kr/web1/cargotrace/cargotrace_blnumber.jsp MOL (Asia) Ltd.商船叁井(亚洲)有限公司https:///Regusers/Web_CT_Pks.SearchCrt_CT Norasia Container Lines Ltd.北欧亚航运/NYK Line (HK) Ltd.日本邮船(香港)有限公司/servlet/c ... nsContainerSearchPg OOCL (HK) Ltd.东方海外货柜航运(香港)有限公司/eng/ourservices/eservices/trackandtrace/RCL - Regional Container Lines (HK) Ltd.宏海箱运(香港)有限公司/CrgTrack_00.aspSafmarine Hong Kong/Senator Lines/seservice/cargo/front.doSinokor Merchant Marine (China) Co., Ltd长锦商船 (中国) 船务有限公司http://www.sinokor.co.kr/default_e.aspUniglory/servlet/TDB1_CargoTracking.do Wan Hai Lines (HK) Ltd.万海航运(香港)股份有限公司/index_whl. ... lwww/cargoTrack.jsp Yang Ming Line (HK) Ltd.阳明海运(香港)有限公司/track_trace/track_trace_cargo_tracking.asp Zim Integrated Shipping Agencies (HK) Ltd.以星航运代理有限公司http://www.zim.co.il/Tracing.aspx?id=166&l=4。
我的职业是电商英文作文

我的职业是电商英文作文I work in the field of e-commerce. It's an exciting and fast-paced industry that constantly keeps me on my toes. Every day is different, and there's always something new to learn and explore.In this line of work, customer satisfaction is key.It's all about providing a seamless online shopping experience for our customers. From browsing our website to making a purchase, we strive to make the process as smooth as possible. We focus on user-friendly interfaces, clear product descriptions, and efficient customer service to ensure that our customers are happy with their purchases.One of the challenges I face in e-commerce is staying ahead of the competition. With so many online retailers out there, it's important to constantly innovate and find unique ways to attract customers. This could be through offering exclusive deals, providing personalized recommendations, or even partnering with influencers topromote our products. It's a constant battle to stay relevant and stand out in the crowded e-commerce space.Another aspect of my job is analyzing data and metrics. E-commerce is heavily data-driven, and we use analytics to gain insights into customer behavior, sales trends, and marketing strategies. This helps us make informed decisions and optimize our online store for better performance. From tracking conversion rates to monitoring website traffic, data analysis plays a crucial role in the success of our e-commerce business.In e-commerce, adaptability is key. The industry is constantly evolving, and it's important to keep up with the latest trends and technologies. From mobile shopping to social media advertising, there are always new avenues to explore and leverage. As an e-commerce professional, I need to be adaptable and open to change in order to stay ahead of the game.Overall, working in e-commerce is both challenging and rewarding. It requires a combination of creativity,analytical skills, and a deep understanding of customer needs. Despite the fast-paced nature of the industry, it's a field that offers endless opportunities for growth and innovation. I'm proud to be a part of the e-commerce world and excited to see what the future holds for this ever-evolving industry.。
介绍部门工作英文作文

介绍部门工作英文作文英文:My department is responsible for managing the company's marketing strategy and executing various marketing campaigns. As the head of the department, I work closely with my team to ensure that we are meeting our goals and delivering results.One of our main focuses is on digital marketing, including social media, email marketing, and search engine optimization. We also work on traditional marketing efforts such as print ads and events.To give you an example of our work, we recently launched a social media campaign for a new product release. We created engaging content and targeted specific demographics to increase brand awareness and drive sales. The campaign was a success, and we saw a significant increase in website traffic and sales.In addition to our marketing efforts, we also gather and analyze data to make informed decisions about our strategy. This includes tracking website analytics, monitoring social media engagement, and conducting customer surveys.Overall, our department plays a crucial role in the success of the company. We work hard to stay up-to-date with the latest marketing trends and technologies to ensure that we are delivering the best results possible.中文:我所在的部门负责管理公司的营销策略并执行各种营销活动。
世界各国EMS追踪查询网址

世界各国EMS追踪查询网址注意:先在寄出国查,出境后,就需要到寄达国网站查了。
/中国EMS邮局网址查询/中国邮政EMS查询网/香港邮政 EMS 网 (HongKONG)/台湾(Taiwan) 邮政 EMS 查询网http://www.post.japanpost.jp/english/tracking/index.html日本(Japan) 邮政EMS查询网http://service.epost.go.kr/iservice/ems/ems_eng.jsp韩国(Korea) EMS查询网(Korea)http://track.thailandpost.co.th/泰国 EMS查询网(Thailand).sg/新加坡(SINGAPORE) EMS邮政查询网.au/澳大利亚EMS查询网(Austeralia)/Cultures/en-NZ/OnlineTools/TrackAndTrace/Trac k+and+Trace.htm新西兰邮政EMS查询网(New Zealand)/文捷 EMS邮政查询网.vn/越南(VIETNAM) 邮政EMS查询网.kh/Postweb/on-line_tracking.htm柬埔寨(Cambodia) 邮政EMS查询网http://ems.posindonesia.co.id/印度尼西亚(Indonesia) 邮政EMS查询网.my/posekspres/mainframe.asp?addr=first1.asp 马来西亚(Malaysia) 邮政 EMS 查询网/印度(INDIA) 邮政EMS查询网/美国USA 邮局 EMS 邮政查询网(U.S.A)/加拿大邮政EMS查询网(Canada)/英国United Kingdom 邮局邮政 EMS 查询网(U.K)/fr/法国邮政 EMS 邮局查询网(France)http://www.poste.it/online/dovequando/paccocelere1.shtml意大利邮政EMS查询网(ITALY)http://www.gdsk.de/eng/index.html德国 EMS邮政查询网(GERMANY)http://www2.ctt.pt/fewcm/wcmservlet/ctt/index.html葡萄牙Portugal 邮政 EMS 邮局查询网http://www.correos.es/dinamic/plantillas/home1.asp西班牙(Spain) 邮政EMS查询网http://www.postdanmark.dk/tracktrace/indexUK.jsp丹麦( Denmark ) 邮政邮局 EMS 查询网http://www.poste.ch/瑞士( Switzerland ) 邮政EMS查询网http://www.posten.no/Portal/挪威( Norway ) 邮政EMS查询网http://www.posti.fi/芬兰( Finland ) 邮政EMS查询网http://etracker.emstaxipost.be/index.asp?lang=fr比利时( Belgium ) 邮政邮局 EMS查询网http://www.ept.lu/?lm1=75769FAD20A1卢森堡 ( Luxemburg ) 邮政EMS查询网http://www.post.at/奥地利( Austria )邮政EMS查询网/文捷快递Wenjie 邮政 EMS查询网http://www.anpost.ie/AnPost爱尔兰( Ireland ) 邮政EMS查询网/阿联酋( U.A.E ) 邮政速递EMS查询网/卡塔尔( Qatar ) 邮政快递 EMS查询网.pk/巴基斯坦( Pakistan ) 邮局邮政 EMS 查询网http://www.postur.is/english/index.html冰岛( Ice Land ) 邮政EMS查询网t.ru/俄罗斯( Russia ) 邮政EMS查询网/postunit.nsf/def2/index以色列( Israel ) 邮政EMS查询网.ua/form.shtml乌克兰( Ukraine ) 邮政EMS查询网http://www.sepomex.gob.mx/Sepomex/Servicios/RastreoEMS/墨西哥( Mexico ) 邮政EMS查询网/加纳( Ghana ) 邮政EMS查询网http://www.posta.sk/斯洛伐克( Slovakia ) 邮政EMS查询网.pe/秘鲁 ( Peru ) 邮政EMS查询网.br/servicos/rastreamento/internacional/defaul t.cfm?Idioma=E巴西 ( Brazil ) 邮政 EMS 查询网/乌干达 ( Uganda ) 邮政速递 EMS查询网.pk/乌克兰( Ukraine ) 邮政EMS查询网http://www.pocztex.pl/波兰( Poland ) 邮政EMS查询网http://www.belpost.by/白俄罗斯( Belarus ) 邮政EMS查询网。
如何跟踪物流信息英语作文

如何跟踪物流信息英语作文Tracking Logistics InformationIn the modern age of e-commerce, tracking logistics information has become a necessity for both buyers and sellers. In this article, we will discuss the various methods of tracking logistics information.The most common method of tracking logistics information is through online portals. Most couriers and shipping companies have online portals where customers can enter their tracking numbers and check the status of their shipments. These portals are generally user-friendly and offer real-time tracking updates. Customers can also sign up for email or text notifications for updates on their shipments.Another method of tracking logistics information is through mobile apps. Many courier and shipping companies have mobile apps that allow customers to track their shipments and receive real-time updates on the go. These apps also offer other features, such as the ability to schedule pickup and delivery times, and access to customer support.Some shipping companies also offer tracking services through social media platforms such as Twitter. Customers can follow the shipping company's Twitter account and receive updates on their shipments via private messages or public tweets. This method is particularly useful for customers who prefer to receive updates on their shipments through social media.In some cases, it may also be possible to track logistics information through the seller's website. Some e-commerce companies have integrated shipping tracking features on their platform, allowing customers to track their shipments without having to leave the website.In conclusion, tracking logistics information is essential for modern-day e-commerce. Customers have access to a variety of tracking methods, including online portals, mobile apps, social media platforms, and seller websites. With these methods, customers can stay updated on the status of their shipments and plan accordingly.。
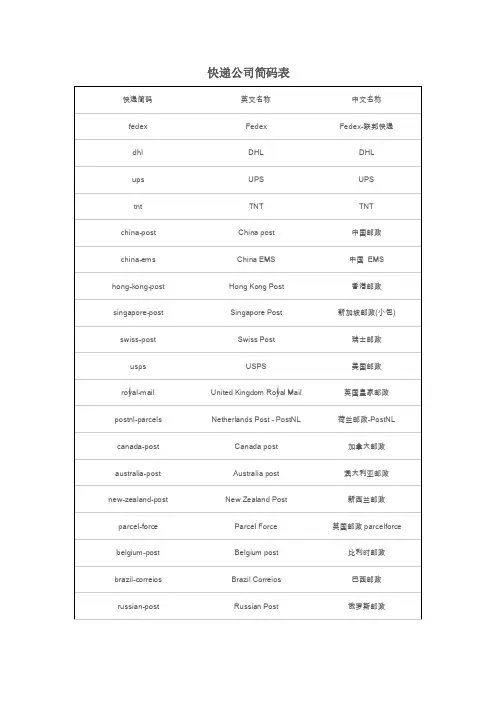
Trackingmore物流轨迹查询接口快递公司编码
colissimo
French Post - Colissimo
法国邮政-Colissim o
chronopost
France EMS - Chronopost
法国 EMS-Chronopost
gabon-post
Gabon post
加蓬邮政
gam bia-post
Gambia post
冈比亚邮政
georgian-post
antilles-post correo-argentino
armenia-post aruba-post
ascension-post australia-em s austria-post azerbaijan-post
Sweden Posten French Post -La Poste
Poste Italiane Åland Post Afghan Post Albania post Algeria post Andorra Post
cuba-post cyprus-post czech-post denm ark-post djibouti-post dom inica-post inposdom east-timor-post correos-del-ecuador egypt-post el-salvador-post
Central African Republic post Chad post
belize-post
Belize post
benin-post
Benin post
berm uda-post
Bermuda post
bhutan-post
Bhutan post
correos-bolivia
保护互联网上的隐私英语作文120词
标题:Safeguarding Privacy in the DigitalWorldIn the digital era, protecting one's privacy on the internet is paramount. With the proliferation of social media, online shopping, and other digital platforms, our personal information is constantly being collected and shared. Hence, it's crucial to be vigilant and proactive in safeguarding our digital footprint.Using strong passwords and regularly updating them is essential. Avoiding the use of personal details in passwords and enabling two-factor authentication adds an extra layer of security. Furthermore, being mindful of what we share online is crucial. Sharing excessive personal information, such as home addresses or phone numbers, can make us vulnerable to privacy breaches.Moreover, using privacy-enhancing tools like virtual private networks (VPNs) and secure browsers can further enhance our privacy. VPNs encrypt our internet traffic, hiding our IP addresses and making it difficult for third parties to track us. Secure browsers, on the other hand, prevent websites from tracking our browsing habits.Additionally, being mindful of the apps and websites we use is also essential. Reading the privacy policies and understanding what data is being collected is crucial. If an app or website seems too intrusive with its data collection practices, it's best to avoid using them.In conclusion, protecting our privacy in the digital world requires vigilance and proactive measures. By being mindful of what we share, using strong passwords, and employing privacy-enhancing tools, we can enjoy thebenefits of the internet while keeping our personal information safe.**保护数字世界中的隐私**在数字时代,保护互联网上的隐私至关重要。
各船司货物跟踪查询网址
1. 澳大利亚航运(ANL)货物跟踪网址:/ANL/Tracking/Default.aspx 船公司名称(英):ANL船公司名称(中):澳大利亚航运船公司标志:2. 美总轮船(APL)货物跟踪网址:/tracking/船公司名称(英):APL船公司名称(中):美总轮船船公司标志:3. 中通海运(CCL)货物跟踪网址:/index.asp船公司名称(英):CCL船公司名称(中):中通海运船公司标志:4. 天敬海运(CK line)货物跟踪网址:http://www.ckline.co.kr/english/eservice/construction.asp 船公司名称(英):CK line船公司名称(中):天敬海运船公司标志:5. 达飞轮船(CMA CGM)货物跟踪网址:/eBusiness/Tracking/Default.aspx 船公司名称(英):CMA CGM船公司名称(中):达飞轮船船公司标志:6. 正利航业(CNC)货物跟踪网址:船公司名称(英):CNC船公司名称(中):正利航业船公司标志:7. 中远集运(COSCON)货物跟踪网址:/ebusiness/service/cargoTracking.do?action=init船公司名称(英):COSCON船公司名称(中):中远集运船公司标志:8. 北欧亚(CSAV NORASIA)货物跟踪网址:/index_en.htm船公司名称(英):CSAV NORASIA船公司名称(中):北欧亚船公司标志:9. 中海集运(CSCL)货物跟踪网址:http://222.66.158.204/cargo_track/cargo_track.jsp 船公司名称(英):CSCL船公司名称(中):中海集运船公司标志:10. 达贸航运(Delmas)货物跟踪网址:船公司名称(英):Delmas船公司名称(中):达贸航运船公司标志:11. 长荣海运(EMC,Evergreen)货物跟踪网址:/船公司名称(英):EMC,Evergreen船公司名称(中):长荣海运船公司标志:12. 阿联酋航运(ESL,Emirates)货物跟踪网址:/船公司名称(英):ESL,Emirates船公司名称(中):阿联酋航运船公司标志:13. 远东船务(FESCO)货物跟踪网址:http://www.fesco.ru/en/tracking/船公司名称(英):FESCO船公司名称(中):远东船务船公司标志:14. 金星轮船(Gold Star)货物跟踪网址:/cargo_tracing.html 船公司名称(英):Gold Star船公司名称(中):金星轮船船公司标志:15. 大新华(Grand)货物跟踪网址:/船公司名称(英):Grand船公司名称(中):大新华船公司标志:16. 海文船务(HaiWin)货物跟踪网址:/cn/sailing.aspx船公司名称(英):HaiWin船公司名称(中):海文船务船公司标志:17. 汉堡南美(Hamburg Sud)货物跟踪网址:/WWW/EN/E-Business/Track_and_Trace/index.jsp 船公司名称(英):Hamburg Sud船公司名称(中):汉堡南美船公司标志:18. 海华轮船(HASCO)货物跟踪网址:/船公司名称(英):HASCO船公司名称(中):海华轮船船公司标志:19. 兴亚海运(Heung-A)货物跟踪网址:http://www.heung-a.co.kr/chinese/cargo_web/cargotrace.cfm 船公司名称(英):Heung-A船公司名称(中):兴亚海运船公司标志:20. 韩进海运(HJ,HanJin)货物跟踪网址:/eservice/alps/cn/cargo/Cargo.do船公司名称(英):HJ,HanJin船公司名称(中):韩进海运船公司标志:21. 赫伯罗特(H-L,Hapag-Lloyd)货物跟踪网址:/en/home.html船公司名称(英):H-L,Hapag-Lloyd船公司名称(中):赫伯罗特船公司标志:22. 现代商船(HMM,Hyundai)货物跟踪网址:/cms/business/china/trackTrace/trackTrace/index.jsp 船公司名称(英):HMM,Hyundai船公司名称(中):现代商船船公司标志:23. 伊朗国航(IRISL,IRIS Lines)货物跟踪网址:/CLS/CargoTracking/CargoTracking/FindContainer.aspx 船公司名称(英):IRISL,IRIS Lines船公司名称(中):伊朗国航船公司标志:24. 神原汽船(Kambara Kisen)货物跟踪网址:http://www.kambara-kisen.co.jp/mychart/cargotrack/search.php 船公司名称(英):Kambara Kisen船公司名称(中):神原汽船船公司标志:25. 川崎汽船(K-L,KLine)货物跟踪网址:http://206.103.2.35/GctApp/search船公司名称(英):K-L,KLine船公司名称(中):川崎汽船船公司标志:26. 高丽海运(KMTC)货物跟踪网址:http://www.kmtc.co.kr/船公司名称(英):KMTC船公司名称(中):高丽海运船公司标志:27. 协和海运(KYOWA)货物跟踪网址:http://www.kyowa-line.co.jp/en/index.html船公司名称(英):KYOWA船公司名称(中):协和海运船公司标志:28. 马士基航运(Maersk)货物跟踪网址:/appmanager/船公司名称(英):Maersk船公司名称(中):马士基航运船公司标志:29. 玛丽亚娜(MARIANA)货物跟踪网址:船公司名称(英):MARIANA船公司名称(中):玛丽亚娜船公司标志:30. 南美邮船(MARUBA)货物跟踪网址:.ar/main.asp?region 船公司名称(英):MARUBA船公司名称(中):南美邮船船公司标志:31. 美森轮船(Matson)货物跟踪网址:船公司名称(英):Matson船公司名称(中):美森轮船船公司标志:32. 马士基所属近洋航线(MCC)货物跟踪网址:.sg/船公司名称(英):MCC船公司名称(中):马士基所属近洋航线船公司标志:33. 民生轮船(Minsheng)货物跟踪网址:/船公司名称(英):Minsheng船公司名称(中):民生轮船船公司标志:34. 马来西亚航运(MISC)货物跟踪网址:.my/船公司名称(英):MISC船公司名称(中):马来西亚航运船公司标志:35. 商船三井(MOL)货物跟踪网址:http://www.mol.co.jp/船公司名称(英):MOL船公司名称(中):商船三井船公司标志:36. 地中海航运(MSC)货物跟踪网址:http://www.mscgva.ch/tracking/index.html船公司名称(英):MSC船公司名称(中):地中海航运船公司标志:37. 南星海运(NAMSUNG)货物跟踪网址:http://www.namsung.co.kr/eng/eservice/sw_search.ns.tsp 船公司名称(英):NAMSUNG船公司名称(中):南星海运船公司标志:38. 尼罗河航运(NDS,NileDutch)货物跟踪网址:/schedules.php船公司名称(英):NDS,NileDutch船公司名称(中):尼罗河航运船公司标志:39. 日本邮船(NYK)货物跟踪网址:船公司名称(英):NYK船公司名称(中):日本邮船船公司标志:40. 新安通(ONTO)货物跟踪网址:/newEbiz1/EbizPortalFG/portal/html/index.html 船公司名称(英):ONTO船公司名称(中):新安通船公司标志:41. 东方海外(OOCL)货物跟踪网址:/schi/ourservices/eservices/trackandtrace/船公司名称(英):OOCL船公司名称(中):东方海外船公司标志:42. 奥林汽船(Orient)货物跟踪网址:http://www.orientferry.co.jp/cn.html船公司名称(英):Orient船公司名称(中):奥林汽船船公司标志:43. 太平船务(PIL)货物跟踪网址:船公司名称(英):PIL船公司名称(中):太平船务船公司标志:44. 宏海箱运(RCL)货物跟踪网址:/船公司名称(英):RCL船公司名称(中):宏海箱运船公司标志:45. 南非海运(SAF,Safmarine)货物跟踪网址:/wps/portal/Safmarine/Home?WCM_GLOBAL_CON TEXT=/wps/wcm/connect/Safmarine-Chinese/Safmarine/Home船公司名称(英):SAF,Safmarine船公司名称(中):南非海运船公司标志:46. 萨姆达拉(Samudera)货物跟踪网址:/船公司名称(英):Samudera船公司名称(中):萨姆达拉船公司标志:47. 印度国航(SCI)货物跟踪网址:/newsite/default.asp 船公司名称(英):SCI船公司名称(中):印度国航船公司标志:48. 德胜航运(Senator)货物跟踪网址:/Senator.html船公司名称(英):Senator船公司名称(中):德胜航运船公司标志:49. 长锦商船(Sinokor)货物跟踪网址:http://www.sinokor.co.kr/船公司名称(英):Sinokor船公司名称(中):长锦商船船公司标志:50. 中外运(Sinotrans)货物跟踪网址:船公司名称(英):Sinotrans船公司名称(中):中外运船公司标志:51. 新海丰(SITC)货物跟踪网址:/hangyun/searchcargo.asp船公司名称(英):SITC船公司名称(中):新海丰船公司标志:52. 速达海运(Speeda)货物跟踪网址:.sg/船公司名称(英):Speeda船公司名称(中):速达海运船公司标志:53. 泛洋轮船(STX,STX-Pan Ocean)货物跟踪网址:/HP2401/track.do 船公司名称(英):STX,STX-Pan Ocean船公司名称(中):泛洋轮船船公司标志:54. 德翔航运(TSL,TS Lines)货物跟踪网址:/船公司名称(英):TSL,TS Lines船公司名称(中):德翔航运船公司标志:55. 阿拉伯航运(UASC)货物跟踪网址:/aspx/OnlineShipping.aspx船公司名称(英):UASC船公司名称(中):阿拉伯航运船公司标志:56. 澳门永发(WFL)货物跟踪网址:/company/Company_Browse.aspx?id=1船公司名称(英):WFL船公司名称(中):澳门永发船公司标志:57. 万海航运(WHL,WanHai)货物跟踪网址:/index_whl.jsp?file_num=15040&web=whlwww&i_url=wh lwww/cargoTrack.jsp船公司名称(英):WHL,WanHai船公司名称(中):万海航运船公司标志:58. 威兰德船务(Winland)货物跟踪网址:船公司名称(英):Winland船公司名称(中):威兰德船务船公司标志:59. 阳明海运(YML,Yangming)货物跟踪网址:/simplified_version/track_trace/track_trace_cargo_tracking .asp船公司名称(英):YML,Yangming船公司名称(中):阳明海运船公司标志:60. 以星航运(ZIM)货物跟踪网址:http://www.zim.co.il/Tracing.aspx?id=166&l=4船公司名称(英):ZIM船公司名称(中):以星航运船公司标志:61. CSAV (南美轮船)货物跟踪网址:/index_en.htm船公司名称(英):南美轮船船公司名称(中):CSAV。
世界各国邮政查询网站大全1
国旗国家名称国家名称(英文)邮政名称(中文)中华人民共和国china 中国邮政巴林 Bahrain 巴林邮政韩国 Korea 韩国邮政黎巴嫩 Lebanon 黎巴嫩邮政尼泊尔 Nepal 尼泊尔邮政泰国 Thailand 泰国邮政邮政巴基斯坦Pakistan巴基斯坦邮政阿拉伯联合酋长国The United Arab Emirates阿联酋邮政不丹Bhutan 不丹邮政阿曼 Oman 阿曼 邮政阿塞拜疆 Azerbaijan 阿塞拜疆 邮政朝鲜 Korea 朝鲜 邮政菲律宾the Philippines菲律宾邮政柬埔寨 Cambodia 柬埔寨 邮政卡塔尔Qatar 卡塔尔邮政吉尔吉斯斯坦 Kyrghyzstan 吉尔吉斯斯坦 邮政马尔代夫 Maldives 马尔代夫 邮政马来西亚 Malaysia 马来西亚 邮政蒙古 Mongolia 蒙古 邮政沙特阿拉伯Saudi Arabia沙特阿拉伯 邮政郑州纵横国际速递有限公司 郑州国际快递优惠价格请世界各国邮政小包查塞浦路斯 Cyprus塞浦路斯 邮政文莱 Brunei文莱 邮政老挝Laos老挝邮政日本 Japan日本 邮政土库曼斯坦Turkmenistan土库曼斯坦邮政土耳其 turkey土耳其 邮政哈萨克斯坦邮政哈萨克斯坦 Kazakhstan巴勒斯坦国The State of Palestine巴勒斯坦邮政塔吉克斯坦Tadzhikistan塔吉克斯坦邮政格鲁吉亚Georgia格鲁吉亚邮政科威特Kuwait科威特邮政叙利亚邮政叙利亚 Syria印度 India印度 邮政印度尼西亚Indonesia印度尼西亚邮政亚美尼亚Armenia亚美尼亚邮政阿富汗邮政阿富汗Afghanistan乌兹别克斯坦邮政乌兹别克斯坦Uzbekistan斯里兰卡Sri Lanka斯里兰卡邮政伊拉克Iraq伊拉克邮政越南 Vietnam越南 邮政伊朗Iran伊朗邮政也门Yemen也门邮政约旦 Jordan约旦 邮政缅甸Burma缅甸邮政锡金Sikkim锡金邮政孟加拉国Bangladesh孟加拉邮政新加坡 Singapore新加坡邮政以色列 Israel以色列 邮政欧 洲国旗国家名称邮政名称(中文)阿尔巴尼亚 Albania阿尔巴尼亚 邮政爱尔兰Ireland爱尔兰邮政爱沙尼亚 Estonia爱沙尼亚 邮政安道尔 Andorra安道尔 邮政摩纳哥 Monaco摩纳哥 邮政卢森堡Luxembourg卢森堡邮政西班牙Spain西班牙邮政瑞典 Sweden瑞典 邮政马其顿Macedonia马其顿邮政意大利 Italy意大利 邮政圣马力诺 San Marino圣马力诺邮政匈牙利Hungary匈牙利邮政南斯拉夫Yugoslavia南斯拉夫邮政希腊 Greece希腊 邮政瑞士Switzerland瑞士邮政摩尔多瓦 Moldova摩尔多瓦 邮政立陶宛 Lithuania立陶宛 邮政拉脱维亚 Latvia拉脱维亚 邮政梵蒂冈 Vatican梵蒂冈 邮政法国 France法国 邮政冰岛 Iceland冰岛 邮政波兰 Poland波兰 邮政英国 Britain英国 邮政列支敦士登Liechtenstein 列支敦士登邮政斯洛伐克Slovakia斯洛伐克邮政荷兰Netherlands荷兰邮政乌克兰 Ukraine乌克兰 邮政葡萄牙Portugal葡萄牙邮政马耳他Malta马耳他邮政俄罗斯 Russia俄罗斯 邮政比利时Belgium比利时邮政克罗地亚 Croatia克罗地亚 邮政芬兰 Finland芬兰 邮政保加利亚 Bulgaria保加利亚邮政 德国 Germany德国 邮政捷克Chech捷克 邮政罗马尼亚 Roumania罗马尼亚 邮政挪威 Norway挪威 邮政斯洛文尼亚 Slovenia斯洛文尼亚 邮政奥地利 Austria奥地利 邮政白俄罗斯 White Russia白俄罗斯 邮政丹麦Denmark丹麦邮政波斯尼亚和黑塞哥维那 Bosnia and Herzegovina波斯尼亚和黑塞哥维那 邮政非 洲国旗国家名称邮政名称(中文)阿尔及利亚 Algeria 阿尔及利亚 邮政布基纳法索 burkina faso布基纳法索 邮政马达加斯加Madagascar 马达加斯加邮政埃及 Egypt埃及 邮政布隆迪Burundi布隆迪邮政赤道几内亚 Equatorial Guinea 赤道几内亚邮政多哥Togo多哥邮政安哥拉 Angola安哥拉 邮政埃塞俄比亚 Ethiopia埃塞俄比亚邮政尼日利亚Nigeria尼日利亚邮政南非 South Africa南非 邮政塞内加尔Senegal塞内加尔邮政佛得角Cape Verde佛得角邮政圣多美和普林西比Sao Tome and Principe圣多美和普林西比邮政斯威士兰Swaziland斯威士兰邮政尼日尔the Niger尼日尔邮政毛里求斯 Mauritius 毛里求斯 邮政几内亚比绍 Guinea-Bissau几内亚比绍 邮政厄立特里亚 Eritrea厄立特里亚 邮政坦桑尼亚Tanzania坦桑尼亚邮政苏丹 sultan苏丹 邮政几内亚Guinea几内亚邮政科特迪瓦 Ivory Coast科特迪瓦 邮政乍得Chad乍得邮政科摩罗Comorin科摩罗邮政塞拉利昂sierra leone塞拉利昂邮政中非 Central Africa中非 邮政赞比亚Zambia赞比亚邮政乌干达 Uganda乌干达 邮政毛里塔尼亚Mauritania 毛里塔尼亚邮政利比亚Libya利比亚邮政喀麦隆 Cameroon喀麦隆 邮政吉布提 Djibouti吉布提 邮政利比里亚Liberia利比里亚邮政津巴布韦Zimbabwe 津巴布韦邮政刚果 Congo刚果 邮政马里 Mali马里 邮政莱索托 Lesotho莱索托 邮政加蓬Gabon加蓬邮政刚果(民) Congo刚果(民) 邮政摩洛哥Morocco摩洛哥邮政冈比亚 Gambia 冈比亚 邮政加纳 Ghana加纳 邮政肯尼亚 Kenya 肯尼亚 邮政马拉维 Malawi马拉维 邮政纳米比亚 Namibia纳米比亚 邮政塞舌尔 Seychelles塞舌尔 邮政博茨瓦纳 Botswana 博茨瓦纳 邮政莫桑比克Mozambique莫桑比克邮政贝宁Benin贝宁邮政卢旺达 Rwanda卢旺达 邮政索马里Somalia索马里邮政突尼斯 Tunisia突尼斯 邮政南 美 洲国旗国家名称邮政名称(中文)阿根廷 Argentina阿根廷 邮政巴拉圭Paraguay巴拉圭邮政巴西 Brazil巴西 邮政玻利维亚Bolivia 玻利维亚邮政委内瑞拉Venezuela委内瑞拉邮政智利Chile智利邮政乌拉圭 Uruguay乌拉圭 邮政苏里南 Surinam苏里南 邮政秘鲁 Peru秘鲁 邮政哥伦比亚Colombia哥伦比亚邮政厄瓜多尔Ecuador 厄瓜多尔邮政圭亚那 Guyana圭亚那 邮政北 美 洲国旗国家名称邮政名称(中文)巴哈马 Bahamas巴哈马 邮政巴拿马Panama巴拿马邮政尼加拉瓜 Nicaragua尼加拉瓜 邮政巴巴多斯Barbados 巴巴多斯邮政牙买加Jamaica牙买加邮政海地Haiti海地邮政墨西哥Mexico墨西哥邮政危地马拉Guatemala危地马拉邮政古巴Cuba古巴邮政洪都拉斯Honduras洪都拉斯邮政格林纳达Grenada格林纳达邮政哥斯达黎加 Costa Rica 哥斯达黎加 邮政多米尼加共和国 Dominican Republic多米尼加共和国邮政圣基茨和尼维斯The Federation Of Saint圣基茨和尼维斯邮政美国 America美国 邮政圣文森特和格林纳丁斯圣文森特和格林纳丁斯 邮政Saint Vincentand The Grenadines特立尼达和多巴哥Trinidad and Tobago特立尼达和多巴哥邮政安提瓜和巴布达 Antigua and Barbuda安提瓜和巴布达 邮政多米尼克国 The Commonwealth of Dominica多米尼克国 邮政伯利兹 Belize伯利兹 邮政萨尔瓦多 Salvador萨尔瓦多 邮政加拿大 Canada加拿大 邮政圣卢西亚 Saint Lucia圣卢西亚 邮政大洋洲国旗国家名称邮政名称(中文)澳大利亚Australia澳大利亚邮政瑙鲁共和国The Republic of Nauru瑙鲁邮政瓦努阿图共和国The Republic of Vanuatu瓦努阿图邮政马绍尔群岛共和国he Republic of Marshall Island马绍尔群岛邮政汤加王国The kingdom of tonga汤加王国邮政新西兰New Zealand新西兰邮政图瓦卢Tuvalu图瓦卢邮政基里巴斯共和国The Republic of kiritabi基里巴斯邮政所罗门群岛Solomon Islands所罗门群岛邮政斐济共和国The Republic of Fiji斐济邮政萨摩亚Samoa萨摩亚邮政巴布亚新几内亚独立国Papua New Guinea 巴布亚新几内亚独立国邮政帕劳共和国The Republic of Palau帕劳邮政邮政名称(英文)LOGO查询链接EMS/qcgzOutQueryAct ion.do?reqCode=gotoSearch.bh/en/modules.php?name=Content&pa=showpage&pKORER POST http://service.epost.go.kr/trace.RetrieveEmsTraceEngTibco.postalLIBAN POST.lb/TrackTrac e/tabid/59/Default.aspx.np/index.aspxThailand Post http://track.thailandpost.co.th/track internet/Default.aspx?lang=en Pakistan Post .pk/Emirates Post /frame.do?page=%2Fgpaen%2Fgpatracktrace%2FTrack BHUTAN POST.bt/index.ph p?id=124/http://www.azems.az/en/index_en.htm http://www.koreapost.go.kr .ph/.kh//qpost/ttchmail /tracktrace.htm/.my/v1/?c=/v1/Track Trace/MainTrack.htm http://www.mongolpost.mn/.sa/English/Saudipos t/Pages/default.aspx价格请来电垂询:0371-******** QQ120139418小包查询网站大全.cy/mcw/dps/dps.nsf /index_en/index_en?opendocument.bn/JAPAN POST http://tracking.post.japanpost.jp/ser vice/jsp/refi/DP311-00100.jsp.tm/PPT .tr/en/interaktif/k ayitliposta.phpKAZ POST http://portal.kazpost.kz/wps/portalhttp://www.georgianpost.ge/index.php?lang=eng&page=1/SYRIA POST /.in/Index.htmlhttp://ems.posindonesia.co.id/haypost http://www.haypost.am/view-lang-eng-page-79.htmlAfghan Post .af/p://www.wasim.Post ofUzbekistanhttp://www.pochta.uz/index.php/enSri Lanka Post .lk/http://ems.vnpost.vn/services/search_ENG.aspxhttp://www.post.ir/HomePage.aspx?TabID=1&Site=PostPortal&Lang=en-UShttp://www.post.ye/.jo/.bd/Singapore Post /ra/ra_article _status.aspIsrael Post http://www.israelpost.co.il/itemtrace .nsf/mainsearch?openform&L=EN邮政名称(英文)LOGO 查询链接http://www.postashqiptare.al/kreu.php?gj=enhttp://track.anpost.ie/track/tracklist.htmleesti Post http://teavitus.post.ee/ar_status.aspLuxembourg Post http://www.trackandtrace.lu/homepage. htmhttp://www.correos.es/dinamic/plantil las/home1.asphttp://www.posten.se/tracktrace/Track Consignments_do.jsp?lang=GBMacedonia Post .mk/ips/ips.htm Italy Post http://www.poste.it/online/http://www.aasfn.sm/english/english.htmmagyar Post http://www.posta.hu/Greece Post http://www.elta.gr/Swiss Post http://www.poste.ch/en/post-startseite.htmMoldova Post http://www.posta.md/en.html 洲Lithuania Post http://trace.post.lt/tandtCritImbed.j sp?refresh=1276154675419Latvia Post http://www2.pasts.lv/en/http://www.vaticanstate.va/EN/Services/Philatelic_and_Numismatic_Office/http://www.chronopost.fr/transport-express/livraison-colishttp://www.postur.is/english/desktopdefault.aspxhttp://sledzenie.poczta-polska.pl/royal mail ostoffice.co.uhttp://www.post.li/http://tandt.posta.sk/enTNT https://securepostplaza.tntpost.nl/tr acktrace/.ua/eng/Base eng.htmlhttp://www2.ctt.pt/feapl_2/app/open/o bjectSearch/ctt_feapl_132col-/Tr ackAndTrace.asphttp://www.russianpost.ru/rp/servise/ ru/home/postuslug/trackingpohttp://www.post.be/http://www.correos.go.cr/sce_php/edit tracking.phphttp://www.posti.fi/english/eservices /itemtracking/index.htmlhttp://www.bgpost.bg/English/Index.as pxDHL https://www.dhl.de/oservices/t_u_t/en/index.htmlhttp://www. http://www.cpost.cz/en/nastroje/sledovani-zasilky.phphttp://www.posta-romana.ro/track_tracehttp://www.posten.no/en/http://www.posta.si/?localeid=en-ENhttp://www.post.at/en/http://www.belpost.by http://www.postdanmark.dk/contentfull.dk?lang=en那 邮政http://www.posta.ba/track/2/0/36.html邮政名称(英文)LOGO查询链接http://www.mpt.bf/quotidien/actualites/index.php /ar/index.asphttp://www.poste.bi/poste.tg/index_html.html.ng/http://sms.postoffice.co.za/tracking/Parcel.aspxposte.sn/邮政http://www.sptc.co.sz/http://www.mauritiuspost.mu/洲http://www.posta.co.tz//web/fr/http://www.ugapost.co.ug/http://www.mauripost.mr/http://ips-webtracking.zimpost.co.zw/trackit//onp/.ma/http://www.gampost.gm/http://www.posta.co.ke/http://www.botspost.co.bw/http://www.correios.co.mz/http://www.e-suivi.poste.tn/fr/index.html邮政名称(英文)LOGO 查询链接.ar/.py/.br/servicos/rastreamento/rastreamento.cfm/.ve/https://www.correos.cl/.uy/index.asp?codPag=tyt/surpost2/index.php美 洲.pe/.ec/ipswebtracking/tracking.htm邮政名称(英文)LOGO查询链接/http://www.correos.gob.ni/.bb/default.php.jm/http://www.sepomex.gob.mx/.gt/elcorreo/index.php/http://www.correos.go.cr/政邮政/shipping/trackandconfirm.htm斯 邮政邮政/美 洲巴布达 邮政http://www.canadapost.ca/cpo/mc/default.jsf?LOCALE=en邮政名称(英文)LOGO查询链接Australia Post .au/track/New Zealand Post /Cultures/en-NZ/OnlineTools/Tracking/Fiji Post .fj/国邮政洋洲/link/track/www.deutschepost.de/dpag?xmlFile=828。
英文邮件模板
邮件模板售前1.客人问产品材料,颜色,规格等。
Dear Friend,Thanks for your interesting of our products, the information which you need is as follow.根据客人的问题作答,例如材料,颜色,规格等,有实物图的也可以附上给客人参考(please see the attached real picture for reference)。
Any needed,please contact me freely./ If any question,please tell us with no hesitation,we will try our best to service for you./More information, you can visit our store website, or you can contact me freely, we will reply you asap, our contact methods(联系方式)Best regards!2.客人问备货期,运输方式及时间。
Dear,Thanks for your email/question, usually we will send the product to you within (备货期) after you order it,we will send the product to you by (快递方式),and the shipping time is around (运输时间).You can also tell us the accurate time you need the product, then we can arrange the shipping for you or to see whether we can reach your time.(客人如果要的比较紧急,可以先问具体时间,看是否备货期和运输时间来得及)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Tracking Website Data-Collection and Privacy Practices with the iWatch Web CrawlerCarlos JensenSchool of EECS Oregon State University Corvallis, OR 97331, USA +1-541-737-2555 cjensen@Chandan SarkarSchool of EECSOregon State UniversityCorvallis, OR 97331, USAsarkar@Christian JensenDepartment of EconomicsSouthern Methodist Uni.Dallas, TX 75275, USAchristia@Colin PottsCollege of ComputingGeorgia Institute of Tech.Atlanta, GA 30332, USApotts@ABSTRACTIn this paper we introduce the iWatch web crawler, a tool designed to catalogue and analyze online data practices and the use of privacy related indicators and technologies. Our goal in developing iWatch was to make possible a new type of analysis of trends, the impact of legislation on practices, and geographic and social differences online. In this paper we present preliminary findings from two sets of data collected 15 months apart and analyzed with this tool. Our combined samples included more than 240,000 pages from over 24,000 domains and 47 different countries. In addition to providing useful and needed data on the state of online data practices, we show that iWatch is a promising approach to the study of the web ecosystem.Categories and Subject DescriptorsH.5.4 [Hypertext/Hypermedia], Architecture, User issuesK.4.1 [Public Policy issues]. Privacy, Transborder data flow. General TermsManagement, Measurement, Documentation, Human Factors, Standardization, Legal Aspects, Verification.KeywordsPrivacy, Demographics, Data-collection practices, Web-crawling, Cookies, Webbugs, P3P, Legislative impact.1.INTRODUCTIONThe Web is a complex place in terms of technologies and practices, especially when considering how these affect privacy and security. These are important concerns for consumers who have to decide who to trust with their data, for legislators who have to develop meaningful and effective regulation, as well as for system administrators and developers, who stand to loose significant time and money on flawed models and designs, or potentially face a user backlash and/or fines.Part of what makes this such a challenging problem is that technology and business practices are constantly evolving. Keeping up with changes and trends can sometime seem like a full-time job. Another challenge is that the web is a global system, crossing and blurring many of the traditional lines of jurisdictions.A company can be registered in one country, be hosted in a number of other countries, and do business with consumers from anywhere in the world. This picture can get even more complicated when we start talking about multi-national companies, and potential business-to-business (b2b) partners. This issue of jurisdiction has been, and will continue to be for the foreseeable future, a serious challenge to e-commerce and e-business. Determining compliance should therefore be a major concern for designers, developers, and administrators of such systems.For legislators and policy makers it is therefore important to understand the impact of policy decisions in order to craft rules and legislation which will be effective and meaningful, and enforce such rules once adopted. Given that legislation often lags behind technological adoption and development, it is important to monitor when safeguards are needed, and when they are no longer meaningful or necessary. It is equally important to monitor developments following the introduction of new legislation as well, to ensure that these are having the intended and desired effects, something which is not always the case [22].For consumers it is important to understand the risks out there - including the prevalence of undesirable or dubious security and privacy practices - in order to make better decisions about whom to trust. This is especially important as a mechanism for ensuring market forces take effect. If consumers are unaware of companies using undesirable practices, they cannot express their preferences by taking their business elsewhere. Such knowledge can help spur the adoption of effective and necessary safeguards and detection mechanisms, and can help end-users press legislators for regulation of practices.For researchers, it is important to know what problems, technologies and practices are worth addressing, or which remedies are having effect. When designing monitoring, notification, blocking, or any other type of technologies, it is important to know where best to invest time and effort, especially given the limited resources in many academic settings. Such an overview could help researchers make the necessary justifications for their decisions.In order to meet the information needs of such diverse stakeholders we need access to a reliable set of data about current data practices and technology use. Because this data may influence public policy, consumer perception, as well as business practices, it is essential that the data be publicly available, and collected in a transparent and unbiased fashion. A technique for doing this is to instrument a web crawler, specifically designed toCopyright is held by the author/owner. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee.Symposium On Usable Privacy and Security (SOUPS) 2007, July 18-20, 2007, Pittsburgh, PA, USA.go out and index web-pages based on publicly visible and machine identifiable data-collection practices and policies. This data could then be made available to the public, and/or scrutinized, and used as a common benchmark or reference set. This basic approach has been used in the past [10], though not on the scale of what we demonstrate in this paper.Our proposal for filling this function is a web crawler named iWatch. The name is derived from the famous question “Q uis custodiet ipsos custodes?” or "Who watches the watchers/guards?" originally posed by Plato in The Republic [31] and popularized in Latin in Juvenal’s Satires [24]. In this case, iWatch monitors those who normally monitor us; websites.iWatch is meant to serve as a source of basic statistics on the stateof privacy, security, and data-collection practices on the web. Because we have no access to information on what websites are doing behind the scenes we have to limit our analysis to the information and technologies which are publicly visible, and what we can automatically detect and analyze. Though this naturally limits the accuracy and scope of our analysis, it still allows us to examine and detect some fairly interesting practices and situations.perspective of the outside observer (no knowledge of internal website workings). We will look at several interesting practices, and ways of examining the data. This paper is also meant to serve as a point for reflection and discussion about which practices to observe, and how the raw data from a system such as iWatch, which is still a work in progress, can and should be evolved and made available to a wider audience.The structure of the rest of this paper will be as follows: We will first discuss a selection of related work, followed by a descriptionof the terminology, conventions and definitions used in this paper. We then discuss the workings and implementation decisions madein our web-crawler, and present two sets of data, from 2005, and 2006, and explore the changes which have taken place in this period, as well as the impact of geography and regulation. We wrap up with a discussion of these results and future plans.2.RELATED WORKPrivacy and security have long been recognized as important areas of concern, both offline and online. As such, this is one of the areas where online activity already has a long history of legislation. These laws have taken different forms across the globe. In Europe, comprehensive or omnibus laws for data protection have been enacted, while the US has largely implemented sector specific laws. These two approaches are fundamentally different, both approaches having advantages and disadvantages, which are often hotly debated [26, 33].Regardless of approach, the goal of these privacy laws is to protect the Personally Identifiable Information (PII) of the individual, as well as regulate how information may be collected, for what purpose, and how it must be protected. Examples of such laws include the US Health Insurance Portability and Accountability Act of 1996 (HIPAA) [36], the US Children’s Online Privacy Protection Act of 1998 (COPPA) [34], the US Gramm-Leach-Bliley Financial Services Modernization Act of 1999 (GLBA) [35], and the European Union Directive on the protection of personal data (95/46/EC) [17]. Given that studies have shown that users fail to read sites’ privacy policies [22, 27], the kinds of minimum protections these laws put in place are particularly important. Previous research has shown that legislation can have mixed effects on policies, especially their readability and usability [3, 22].Despite legislative efforts, privacy concerns have been shown to be major obstacles to the adoption and success of e-commerce [1, 23]. Numerous surveys indicate that people consider privacy to be important [6, 7, 11, 15]. Privacy concerns are the most cited reasons for avoiding the use of e-commerce systems, an aversion that industry groups estimate costs e-commerce companies USD 25 billion per year in lost revenue opportunities [23]. Surveys have also found that people are more concerned about their privacy online than offline [21], even though most cases of identity theft occur offline [20]. It is not surprising that industry groups invest significant resources to build consumer confidence and engage in voluntary efforts such as publishing privacy policies and seeking different forms of certification.Such self-regulation attempts through programs such as seal programs such as TRUSTe (), BBBOnLine (Better Business Bureaus Online Seal, ), MultiCheck and WebTrust (offered by American Institute of CPAs ) allow licensees who abide by posted privacy policies and/or allow compliance monitoring to display the granting organization’s seal of approval on their web site. Such programs have been found to significantly increase consumer trust [21, 28, 29], though some questions remain over whether what they imply matches user expectations, and questions remain about the ease with which sites may misrepresent their certification status [29]. In other words, there is some indication that users are being misled, intentionally or unintentionally, by some of these efforts [27].We also know from surveys that though users think it is important for sites to present privacy policies, they are less than impressed with their quality and accuracy [12]. Surveys show that users find privacy policies to be boring, hard to read and understand, hard to find, and that they don’t answer the kinds of questions they are interested in. The same survey also found that most people do not believe the claims and guarantees made in privacy policies [12, 20]. While most surveys report that a sizable portion of users claim to read such policies or notices regularly [12], there is evidence to suggest these reports are greatly exaggerated [21].To overcome some of the problems associated with privacy policies and reduce the burden on users, machine-readable policy specification languages, such as P3P [8, 9] and EPAL [5], have been proposed. These policies can be read by automated agents (such as Privacybird [9], Privacy Fox [4], or the Microsoft IE 6 and 7, or Netscape 7 browsers themselves), only alerting users if the policy is likely to cause concern. The theory is that by filtering out the noise and drawing users’ attention to only those policy elements which require attention, users are more likely to be engaged.The most popular and widely used of these technologies without question is P3P. The Platform for Privacy Preferences (P3P) was created by the W3C to make it easier for web site visitors to obtain information about sites’ privacy policies [8, 9]. P3P specifies a standard XML format for machine-readable privacy policies that can be parsed by a user-agent program. These tools have shown some indications of success [16], though there is little data on their effects during long-term or large-scale use. P3P policies have also been used as data to direct users’ web-searches[10] in a system sharing many methodological similarities to our iWatch.A number of other tools independent of P3P have also been developed over the years, including filtering and privacy protecting proxy servers, popup-blockers, cookie blockers and analysis tools, anti-phishing tools, etc. Given that many of these functions have subsequently been absorbed by the latest generation of web-browsers, their numbers and user base is unknown today.Regardless of the underlying technology, HCI researchers have been examining the issue of how to improve the usability and usefulness of such systems, an early shortcoming of many. Classic papers and studies include [37, 38]. This research showed that a secure system would fail unless these security measures were made usable. In recent years we have seen excellent papers on why phishing attacks work [14, 13], and how our tools and warning tend to go unheeded, regardless of the information presented [39]. While excellent results, it is obvious more work still needs to be done in this area as there are far more studies of why things fail than how to succeed.Our approach of harvesting and examining large amounts of data via the use of a web-crawler has been employed by other security and privacy researchers. Recently, this approach has produced interesting results in the identification of malware and spyware disseminating websites [30, 32]. In these studies, researchers were able to scan and classify a large enough sample to convincingly argue about the state of the Internet as a whole.3.DefinitionsBefore diving into the meat of our study, it is important to define certain terms in order to avoid misunderstandings or ambiguity. Our definitions should most often match generally accepted definitions, but may in some cases have a rather more narrow definition, chosen for practical considerations.In this paper, domain, web server, and website are terms which are used interchangeably. While in the real-world, a given domain can host many distinct sites, we differentiate between sites based solely on domain-names. A distinct domain-name in our study identifies a distinct domain. Our classification of domains was very simplistic. We did not attempt to identify synonymous domain names ( is not recognized as a synonym for ), or sub-domains ( is not identified as a sub-domain of ). The first is a hard problem and requires either a set of records from domain registrars, or a lot of hand-tuning. The second, though technically simple to implement, would cause problems with hosting services and smaller or related web-sites, which may lack unique second-level domain names.We will also use the terms 1st party and 3rd party frequently. In this context a 1st party typically refers to the domain or website which served the page, and a 3rd party is any other domain/website which either receives information about the transaction, or supplies information or resources used by the requested page. Examples are 3rd party cookies, webbugs, and banner ads.In this paper we will talk about technologies such as P3P policies, webbugs, cookies, popups, and banners. P3P stands for the Platform for Privacy Preferences, and is a standard for specifying privacy policies in a machine-readable XML format [8]. There are two types of P3P policies, the compact policy (CP) and the full policy. The P3P compact policy is a keyword abbreviated P3P policy, offering less detail and nuance, but often used by browsers to filter cookies. P3P and P3P policy will be terms that are used interchangeably in this paper.The P3P protocol specifies 3 ways of publishing a P3P policy; in the HTTP header (can either be a compact policy, or a link to a full policy), in the HTML document as a link tag, or in a well-known location on the server. Because of some quirks of the way web servers implement the serving of P3P policies (see discussion in methodology), our current version of iWatch only finds policies posted in the HTTP header or the body of the document, it does not search the known locations. In order to fetch these remaining policies without bringing the crawler to a halt we delegate this task to a standalone program.Privacy Seals are, in this paper, a combination of different certificates or trustmarks issued by TRUSTe and BBBOnline (BBBPrivacy and BBBReliability seals). These seals certify that the site discloses or follows a minimum set of privacy protection and security practices. While different seals or certificates are enforced by different agencies, have different meanings, and offer different enforcement mechanisms and guarantees, they are all meant to calm potential users concerns. Given the relatively low usage numbers, the different seal programs are grouped together for most of our analysis.Webbugs, also known as web-beacons or pixel tag, are a collection of techniques aimed to tag and collect information from web and email users without their knowledge. In a web page, webbugs are typically used to track users navigating a given site, and have become quite ubiquitous. Webbugs technically can be implemented through a number of different techniques, but are most commonly associated with a 1x1 pixel transparent gif, invisible to the user. Webbugs are often used to augment the tracking available with cookies, and are most troubling when set by third parties, usually without user knowledge or consent. In iWatch we group a number of tracking techniques under the label of webbugs, but only when these are set and used by 3rd parties. We do not classify banner ads or 3rd party cookies as webbugs, but rather track these separately.Much has been written about cookies, and so a discussion of how they work and their potential threats to user privacy is omitted here. We will just mention that in this work we do track the three main categories of cookies separately, session cookies, defined as cookies set by the first party and expiring with the browsing session, 1st party cookies, set by the 1st party and set to persist, and 3rd party cookies, which are set for any domain other than the 1st party.Unsolicited popups, or just popups for short, refers to the much hated technique of opening new browser windows, typically for the purpose of advertising. Affiliated techniques include the pop-under (popups which try to hide themselves). They present a potential danger to end-users as they often serve up content for third parties, enabling these to track users much like webbugs. Popups have stopped being as big a focus in recent years as blocking tools and techniques have become ubiquitous and effective.Web banners, or banners for short, do not present a privacy risk in and of themselves, unless served by a third party. In this case, they serve much the same function as a webbug, though at least remaining visible to the user. Banners in our study are identified by their size (these are the standardized sizes set by the InternetAdvertising Bureau (/standards/adunits.asp)), and the fact they are served by a 3rd party.Some practices and technologies are ambiguous or difficult to detect reliably. This is especially true for automatic pop-ups, which at times are difficult to disambiguate from user-activated pop-ups, or webbugs from images or tricks used to layout web-pages. While we have done our best to unambiguously define and detect interesting practices, there is still room for improvement. Webbugs and unsolicited popups are still difficult to detect unambiguously, and some amounts of false-positives are still detected.4.METHODOLOGYiWatch is a web-crawler, or spider [19], implemented in Java, and built from the ground up to search for and index data-handling practices. Similar to most crawlers, which search for and index key words, or all words within the body of a document, iWatch is designed to look for certain HTTP tokens, or HTML constructs and patterns, which may identify certain data-handling or collection techniques of interest.Like any web-crawler, iWatch starts with a seed-list, or given set of URL’s which to visit initially. iWatch downloads these pages in parallel using multiple threads, and searches the resulting download stream for web-links and a set of filters. This process is partially done using Java’s built in classes and their data-handling functions (such as finding links in a HTML document), and a set of full-text searches using regular expressions.Links found are added to a database of pages to potentially crawl. Given that most websites are complex in structure, iWatch seeks to analyze a number of pages within each domain in order to get a more complete picture of the site. At the same time, iWatch seeks to minimize the impact on the servers studied by limiting the number of pages requested from any domain. This also ensures that iWatch does not get stuck analyzing big sites, ensuring we get a minimum breadth of coverage. When a thread is idle, or is done analyzing its current page, it consults the database of links found, selecting the next eligible link and repeating the process. Because the initial seed-list used has a tremendous effect on the overall crawling pattern it is important to choose carefully. Given the limited resources of a university/research setting, the crawler will only be able to visit a very limited number of pages and domains when compared to dedicated operations such as Google and MSN. The seed-list must therefore be selected so that the sample taken is a) as representative as possible, b) as relevant as possible, and c) leads down a path of diversity of sites.These criteria are not always achievable. A fully representative sample would require a random sampling, which is not possible with a web-crawler, which by its nature investigates clusters of websites by following the links between these. Instead, we have chosen to construct our seed-list based on the data’s potential value or impact. In other words, we ensure that the most popular sites, the sites most likely to impact the privacy of the most users, are at the heart of the crawl. In addition, to avoid an overwhelming US and English language bias, the sample must be balanced to include different countries and classes of websites. For our experiments, the crawler was seeded with a combination of the top 50 websites for that month (as determined by the Comscore MediaMetrix (/metrix)), and a hand-picked set of popular European and Asian sites. This is far from a perfect selection of sites, but gives us an interesting and relevant sample to study.Given a functioning web-crawler, one then needs a set of search criteria to index the pages. Table 1 gives an abbreviated list of the main bits of information we currently collect using iWatch. Many of these are composed by multiple regular expressions of mechanisms. For instance, cookies are identified by one of three filters, depending on whether they are session cookies, 1st party cookies, or 3rd party cookies. For each of these, different information is collected. iWatch collects information on 21 data-practices plus assorted site-characteristics such as geographic location based on IP address matching.Our indices were derived from the filters used in the privacy-protecting proxy server called Privoxy (). Privoxy is an open-source proxy server designed to act as a filter between a browser and the web. In order to do this, Privoxy filters incoming and outgoing HTTP communication using a set of regular expressions identifying potentially dangerous or undesirable practices from an end-user perspective. These filters were manually tuned to remove some false-positives (especially in the area of webbugs) and give us more information to process. Table 1: Main iWatch index termsBased on early experiments, we learned that in order to correctly identify P3P and privacy seal use, we needed to adopt a strategy other than filters. While filters effectively identify the use of compact and embedded P3P policy references, finding and downloading full P3P policies requires additional steps, which are prone to errors. As pointed out in [10], some servers will at times refuse to serve some full P3P policies from the default location (http://server/w3c/p3p.xml), skewing results. In order to ensure more correct results, we wrote a custom application that revisited each of the domains in our samples 3 times trying to get a full p3p policy. These repeated queries made a significant difference in our results, giving us an additional 117 policies for our 2006 sample, and 211 additional policies in the 2005 sample when compared with a single visit strategy. Responses were analyzed to check that what was returned was an xml document and not a html document, and that redirects were followed correctly. In the current version of the crawler, the P3P policies are not analyzed. Our early attempts at determining seal usage directly from the pages we crawled also proved to be an ineffective strategy. Seals Index Terms DescriptionCookiesIdentifies the use of different types of cookies (session, 1stparty and 3rd party), and their characteristicsUnsolicitedpopupsIdentifies the use of unsolicited popup windows WebbugsIdentifies the use of third part resources potentially used totrack users from site to siteBannersIdentifes the use of different types of banners and ads,potentially used to track users from site to siteP3P policiesIdentifies the use of both full and compact P3P privacy policiesin HTTP headerPrivacy SealsIdentifies the use of Privacy seals (TRUSTe, BBBOnline, andWebTrust) in a domain’s pages (link and graphic) Data-sharingnetworksA collection of the techniques used to track users across sites(3rd party cookies, webbugs, banners), and who the data isshared withLink structureBasic information on page’s link structure and relationshipsbetween sitesGeographicinformationMaps a domain/server’s IP address to a country using theGeoLite database created by MaxMind(/)are typically confined to a disclaimer or privacy policy page, therefore our ability to detect seal use through filters depends on a) the crawler having reached a policy page for the site, and b) that the seal is presented using a standard format. Of these, the first hurdle proved to be the most significant and eventually insurmountable obstacle to this strategy. To overcome these limitations we gained access to lists of certified sites directly from the certifying agencies (in this case TRUSTe and BBBOnline). These lists (/about/member_list.php, and /consumer/pribrowse.asp) were then cross-referenced with our sample sites. We were unable to obtain lists for other seal providers, though this is something which we will seek to work on in the future.To demonstrate the effectiveness and value of this approach to the study of online privacy, online regulation, and online data collection practices, we performed two experiments, one in May of 2005, and the second in August 2006, where we collected information on web-sites’ privacy and data-collection practices. Each of these crawls was performed over a period of 10-14 days, with our crawler running on a single dedicated server. In this paper we will use these two samples to examine the changes that have taken place online over the last year.Before concluding this section we wish to say a few things about the statistical testing using our two sample databases. Given the large size of our two samples, finding statistical significance is relatively simple even for relatively small changes in behavior. The reader is therefore advised that it is important to make a distinction between statistically significant and meaningful changes when considering this data. We therefore, uncharacteristically within the field of computer science, choose to set our threshold for statistical significance at the p<0.001 level throughout this paper, unless otherwise noted.5.RESULTS5.1Sampling ResultsAcross both samples, a total of 240,340 web pages were crawled, from a total of 24,990 unique domains. There was an overlap of 1,223 domains between the two samples, or 4.7% of the total sample domains, for a total of 26,213 non-unique domains across both samples. Given that these samples were taken 15 months apart, and the speed with which websites evolve, we decided touse the non-unique total in our calculations, and treat the two samples as statistically independent. This means that on averagewe analyzed 9.17 pages per domain, a relatively solid basis fordrawing conclusions about any given domain. Table 2 summarizes the basic characteristics of the two samples.Overall, our two samples reached 81 countries or territories, 69 inthe first sample and 60 in the second, despite the crawler beingprimarily seeded with US web-sites (Figure 1 shows an overviewof our geographic reach). Many of these countries were represented by extremely small number of domains and pages inour data-sets, which forced us to filter some of the data to avoiddrawing conclusions on overly thin data. We decided to excludefrom analysis any country which was not represented by morethan 10 domains across both samples, unless they were part of the European Economic Area (EEA).Table 2: Data sample summary statisticsSample 1 Sample 2 TotalCollection May 2005 August 2006Web-pages 119,237121,103240,340 Domains(unique)15,792 10,42126,213(24,990) Web-Pages/Domain(unique)7.55 11.629.17(9.62)Total Countries 69 60 81 Filtered Countries 43 43 47 Domains/Country 367.26 242.35 557.72The EEA is composed of the 25 European Union (EU) members,plus Iceland, Liechtenstein and Norway. All domains belongingto any EEA country were included in our sample because all EEA countries are signatories to the EU privacy directive [17], and therefore have similar privacy legislation in place. For the purpose of this analysis, the EEA countries will be viewed as ablock. Of the 28 EEA countries, we found 27 in our sample (Lichtenstein being absent, see table 3 for list of all countries included in study). EEA countries make up 9.66% of our total sample.Figure 1: Geographic distribution of sampleCountries marked in red are included in the study. Countries marked in green were reached, but excluded from the study due to small sample size. Map courtesy of Applying the above filtering rules, we lose 56 domains and 26countries from Sample 1, and 34 domains and 17 countries insample 2. Overall, 34 countries were filtered from the combineddata-set, leaving 47 (43 in each of the samples). On average, the。