序列提交软件sequin使用方法
最全的向NCBI递交序列说明
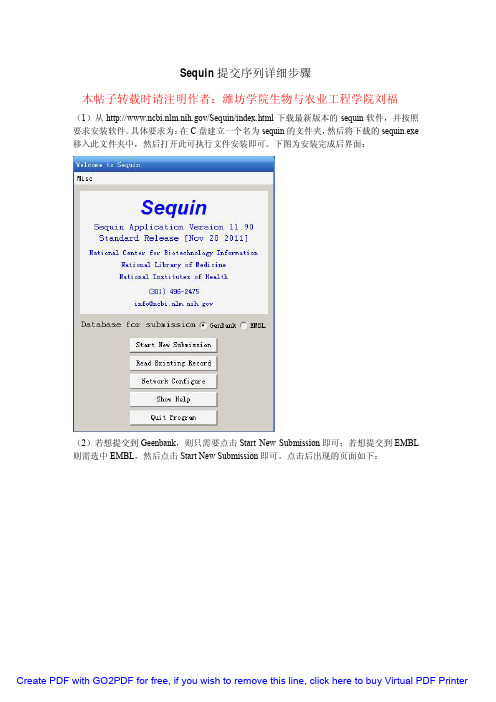
Sequin提交序列详细步骤本帖子转载时请注明作者:潍坊学院生物与农业工程学院刘福(1)从/Sequin/index.html下载最新版本的sequin软件,并按照要求安装软件。
具体要求为:在C盘建立一个名为sequin的文件夹,然后将下载的sequin.exe 移入此文件夹中,然后打开此可执行文件安装即可。
下图为安装完成后界面:(2)若想提交到Geenbank,则只需要点击Start New Submission即可;若想提交到EMBL 则需选中EMBL,然后点击Start New Submission即可。
点击后出现的页面如下:(3)第一个标签Submission:什么时候发表你的序列?可以选择①Immediately After Processing即Geenbank工作人员处理完毕你的序列后就将其发表到Geenbank内。
②Release Date即选择让Geenbank工作人员发表到Geenbank内的时间。
Tentative title for manuscript 这一项一般填写你将发表论文的暂定题目或已发表论文的题目。
(4)完成后点击Next Page,出现以下界面:此处填发见图内,需要解释的是Sfx是别命的意思,中国人一般不需要填写;M.I为中间名,中国人也不需要填;邮箱地址是负责最终提交序列者的,不一定是序列的作者的,如你导师是作者,你是负责给他提交者,则这里就填写你的邮箱,其他信息填写你导师的。
注:0086为中国国际代号,必须加上。
(5)完成后,点击Next Page,出现以下界面:为填写序列作者的界面,前一步填写的联系人被自动列为第一作者,然后往下继续填写其他作者,此处只显示三行,当你填写完第三个后,通过拖动滚动条后面将会还出现填写的表格,直到将所有作者填写完毕。
另外Consortium 为参与序列获取的机构名,当以此机构名义发表序列时可以填写,上面的作者也一并填写。
(6)完成后,点击Next Page。
向GenBank批量上传序列的方法

向GenBank批量上传序列的方法Qin1.利用DNAstar的editSeq制作待序列的FASTA文档:待上传序列删减至合适长度后,将待上传序列全部打开随后点击File - export as one,保存文件格式为:*.fas ,将待上传序列全部归至一个FASTA 文档。
注意序列命名:2.在GenBank的Submission Tools里,下载序列信息编辑软件Sequin。
:// /Sequin/〔下列图中点击Instructions下载软件〕注意打开安装文件后,程序会自动安装在安装包所在的文件夹。
3.打开Sequin,点击Start New Submission。
4.随后选择序列发布日期,输入论文题目。
假设之前保存有模板,可以点击下面的“Click here to import a template”导入。
模板导出在下文的第五点提到。
5.联系人、作者信息、机构或者学校信息建议导出模板,之后修改信息时可以直接导入模板而不需重新输入。
6.选择上传的序列类型。
7.导入之前准备好的FASTA文件:导入之后,输入序列ID〔序号ID相当于编号,可以自由命名,只要各个序列的ID不一致即可。
在这里以病人编号作为序列ID〕:导入序列成功后,显示各个序列信息如下:点击Sequencing Method,将测序方法输入:选择上传序列的用途:病毒类型:8.编辑每条序列的信息:点击Import Source T able可以导入模板,点击Export This Table 可以输出模板备用。
9.选择核酸类型,序列内容后,点击Open Record Viewer。
10.添加每条序列的信息,包括编码区重复区RNA结构等等。
双击相关信息可进行修改,点击Annotate添加相关信息。
11.检查信息是否有误〔也可以点击Search里的Validate检测是否有明显错误〕:有些错误是可以忽略的,如上传的序列为CDS序列,那么软件报错”序列无终止子”时可忽略。
最全的向NCBI递交序列说明
Sequin提交序列详细步骤本帖子转载时请注明作者:潍坊学院生物与农业工程学院刘福(1)从/Sequin/index.html下载最新版本的sequin软件,并按照要求安装软件。
具体要求为:在C盘建立一个名为sequin的文件夹,然后将下载的sequin.exe 移入此文件夹中,然后打开此可执行文件安装即可。
下图为安装完成后界面:(2)若想提交到Geenbank,则只需要点击Start New Submission即可;若想提交到EMBL 则需选中EMBL,然后点击Start New Submission即可。
点击后出现的页面如下:(3)第一个标签Submission:什么时候发表你的序列?可以选择①Immediately After Processing即Geenbank工作人员处理完毕你的序列后就将其发表到Geenbank内。
②Release Date即选择让Geenbank工作人员发表到Geenbank内的时间。
Tentative title for manuscript 这一项一般填写你将发表论文的暂定题目或已发表论文的题目。
(4)完成后点击Next Page,出现以下界面:此处填发见图内,需要解释的是Sfx是别命的意思,中国人一般不需要填写;M.I为中间名,中国人也不需要填;邮箱地址是负责最终提交序列者的,不一定是序列的作者的,如你导师是作者,你是负责给他提交者,则这里就填写你的邮箱,其他信息填写你导师的。
注:0086为中国国际代号,必须加上。
(5)完成后,点击Next Page,出现以下界面:为填写序列作者的界面,前一步填写的联系人被自动列为第一作者,然后往下继续填写其他作者,此处只显示三行,当你填写完第三个后,通过拖动滚动条后面将会还出现填写的表格,直到将所有作者填写完毕。
另外Consortium 为参与序列获取的机构名,当以此机构名义发表序列时可以填写,上面的作者也一并填写。
(6)完成后,点击Next Page。
sequin软件序列提交

这是选择 Uncultured sample项出现的 内容
选择导入核酸序列,这个就是本PPT第4页说 述格式。之后选择右上角的测序方法,选择 相应的方法(如一般测序就是sanger,高通量 有454,等)就OK了。点击NEXT
这里你可以根据自己需要自由选择。
无需选择,直接点击NEXT。
一般功能基因都是CDS,核糖体基 因rRNA, 或者ITS,视自己情况选择。
此处为 批量提 交
若每次只提交一个序列可以选择这个选项
此处导入序列
此处可以忽略
此处必须进行修订,双击 点击进行修订
出现错误基本是此处缺失序列的具体分类信息,点击lineage
添加完分类信息后点击此处
若无任何问题按上述地址发邮件
谢谢 祝各位提交顺利
Genebank序列提交
leolvcxm99 Leo924.student@
序列提交
• 序列提交目的是为了获得Genebank登录号, 一般的文章都需要并且非常重要。 • 序列提交首先要使用软件sequin进行编辑。 • 其次将编辑好的序列用邮件发送至 Genebank编辑邮箱,一星期左右就会得到 序列登录号。
Uncultured bacterium clone B1-14 ammonia monooxygenase subunit A (amoA) gene, partial cds. 此处信息根据你的基因类型可以参考BLAST里面信息写
序列另起一行顶格输入
Sequin序列编辑
选择所提交的数据库 开始提交
序列编辑
• 首先将确定分类的序列进行编辑,可以将 同类(同门)菌株放入同一个文件夹。 • 格式:建立一个*.TXT的文档,里面键入的 格式如图。
此处如果是纯培养菌株就写[strain=B1-14] >B1-14 [organism=Uncultured bacterium][clone=B1-14] [isolation_source=glaicer foreland soil][country=China] 此处一定要写,否则编 辑会专门发邮件向你要 这些信息。
sequence用法

SEQUENCE函数用法SEQUENCE函数是Excel2021新增函数中的一个,这个函数提供的转换能力令人惊讶!今天和大家一起来认识这个函数。
SEQUENCE函数的语法为:=SEQUENCE(rows,[columns],[start],[step])其中,rows:行数。
columns:可选的,列数。
start:可选的,序列的起始值,默认值是1。
step:可选的,序列的步长,默认值是1。
基本用法示例三个例子你就懂了在工作表中输入公式:=SEQUENCE(10),会得到一列十行的数组。
ps:如果你的版本不支持数组自动扩展,就需要先选中10个单元格,输入公式后三键结束。
在工工作表中输入公式:=SEQUENCE(5,3),会得到三列五行的数组。
调整两个参数的位置,公式=SEQUENCE(3,5)则会得到五列三行的数组。
注意,到序列填充的顺序是从左至右、由上至下。
如果想首先填充列,则使用TRANSPOSE函数进行转置:=TRANSPOSE(SEQUENCE(10,3))日期函数和SEQUENCE函数有点意思吧还可以使用SEQUENCE函数和日期函数进行组合,得到日、月、季度或年的序列。
例如,公式=SEQUENCE(10,,TODAY())可以生成10个日期序列。
ps:需要修改单元格格式为日期。
公式=DATE(2022,SEQUENCE(12),1)可以得到一年中每个月的第一天。
使用公式=DATE(2022,SEQUENCE(1,MONTH(TODAY())),1)可以得到当前日期之前的每个月的第一天,并且在一行显示。
值得一提的是,使用TODAY函数使公式具有了动态性,因此它会随着时间的推移而扩展。
当10月来临的时候,将会显示到10月!SEQUENCE函数在数据排列方面的应用以后再也不用烧脑了如下图所示,原数据都在一列中,我们可以使用SEQUENCE函数将其快速转换成行列排列的表。
使用公式=INDEX(A2:A16,SEQUENCE(5,3))得到的效果。
序列(sequence)的简易使用方法介绍

3. 修改序列 ALTER SEQUENCE
你或者是该SEQUENCE的owner,或者有ALTER ANY SEQUENCE 权限才能改动SEQUENCE. 可以alter除start至以外的所有SEQUENCE参数.如果想要改变start值,必须 DROP SEQUENCE 再 重新创建SEQUENCE .
START WITH 10000 --起始数值
INCREMENT BY 1 --每次增加1
NOCYCLE --一直累加不循环
CACHE 20 --缓存
ORDER ;
还有一些其他参数,比如:
NOMAXVALUE --无最大值
NOCACHE --不设置缓存
如果指定CACHE值,ORACLE就可以预先在内存里面放置一些sequence,这样存取的快些。cache里面的取完后,oracle自动再取一组到cache。使用cache或许会跳号, 比如数据库突然不正常down掉(shutdown abort),cache中的sequence就会丢失. 所以可以在create sequence的时候用nocache防止这种情况。
可以使用SEQUENCE的地方:
- 不包含子查询、snapshot、VIEW的 SELECT 语句
- INSERT语句的子查询中
- NSERT语句的VALUES中
- UPDATE 的 SET中
可以看如下例子:
INSERT INTO CUX_DEMO_TABLE VALUES
(CUX_DEMO_SEQUENCE.NEXTVAL, 123 , 'IBAD' , 'MARK' ,'Y');
2.使用序列
SEQUIN3中文使用说明书
SEQUIN3.0Sequin3.0是NCBI为了方便各国参与测序工作的分子生物学研究人员将序列输入到由Genbank,EMBL,DDBJ联合组成的国际协作核酸序列数据库(International Nucleotide Sequence Database Collaboration)而设计的一个客户端软件,使用户可以不需要上网就能够实现序列输入,格式的定制,和在序列数据库中的注册、修改、更新。
与其他的输入方法,如NCBI提供的另外一种在线序列注册工具Bankit相比,Sequin提供许多自动处理功能对序列进行格式定制,避免了手工输入的麻烦和格式不统一,并且,在大量相关数据输入时,Sequin可以方便的直接根据各个序列前的数据行读入各个序列的注释信息。
Sequin3.0是该程序的最新版本,与上一个版本2.9相比,3.0修改了程序的网络配置功能,解决了位于防火墙后的一些用户无法用该程序联网的问题。
另外对在2.9版本中发现的一些小的BUG也作了修正。
该程序具体的序列输入操作包括简单模式和复杂模式两种:一.简单模式:打开Sequin3.0可进入如下开始界面,然后选择了需要进行数据注入的数据库后就可以开始序列输入,对各个数据库序列输入的过程中信息填写都是一样的,只是最终生成的数据格式互不相同。
序列的具体输入过程是下面几个界面,按照要求填写即可:这一页是填写序列引用信息,包括文章(稿件)名,通讯作者联系方式,前三个作者列表,和作者所属机构。
这一页是选择所注入的序列的格式,程序会根据不通格式直接自动读入生成一些序列注释信息。
最后这页是输入序列,在上一页中选择不通格式,页面会有所不同,主要是表明序列的来源,包括来源物种的种属名,菌株号或克隆系列号等,对多序列还要进行注释,输入序列时是使用FASTA格式进行导入,即将各序列按照如下的FASTA格式加上序列头信息后保存成文本格式的文件再导入到Sequin中。
核酸:>ID [org=scientific name] [strain=name][clone=name] title蛋白:>ID [gene=symbol] [prot=name] title这样就完成了序列的简单输入,进入到以下的提交界面:这时可以利用程序提供的自动检查功能(Search菜单中的Validate命令)对输入的序列格式进行检查,之后向数据库提交可以通过三种方式:1.用File菜单中的Prepare submission将输入的序列及注册信息合成为提交文件,之后再用Email发给各个数据库的收件信箱Genbank: gb-sub@EMBL: datasub@DDBJ: ddbjsub@ddbj.nig.ac.jp2.用File菜单中Submit to NCBI来发送。
Excel中sequence函数的序列生成技巧
Excel中sequence函数的序列生成技巧Excel中sequence函数是一种强大的工具,能够方便地生成序列。
在Excel中,使用sequence函数可以快速生成指定的数值序列,并且可以按照一定的步长和规则进行调整。
本文将介绍一些使用sequence函数的技巧和示例,帮助读者更好地运用这一函数。
1. 生成基本序列通过sequence函数,可以轻松生成基本的数值序列。
该函数需要三个参数:序列的长度、起始值和步长。
例如,若想生成1到100的整数序列,可以使用如下公式:=SEQUENCE(100,1,1)这个公式的意思是生成一个长度为100的序列,起始值为1,步长为1。
通过填写不同的参数,我们可以生成不同的序列。
2. 递增/递减的序列sequence函数可以根据设置的步长生成递增或递减的序列。
例如,若想生成从1到100,步长为2的整数序列,可以使用如下公式:=SEQUENCE(50,1,2)这个公式的意思是生成一个长度为50的序列,起始值为1,步长为2。
通过修改步长,我们可以得到递增或递减的序列。
3. 生成日期序列sequence函数还可以生成日期序列。
在Excel中,日期被表示为序列号,起始日期为1900年1月1日。
例如,若想生成从2022年1月1日开始的连续7天的日期序列,可以使用如下公式:=SEQUENCE(7,1,DATE(2022,1,1),1)这个公式的意思是生成一个长度为7的日期序列,起始日期为2022年1月1日,步长为1天。
通过填写不同的参数,我们可以生成指定日期范围内的日期序列。
4. 生成自定义序列除了基本的数值和日期序列外,sequence函数还可以生成自定义的序列。
例如,若想生成一个由字符串组成的序列,可以使用如下公式:=SEQUENCE(5,1,"A",1)这个公式的意思是生成一个长度为5的序列,起始值为"A",步长为1。
通过修改起始值和步长,我们可以生成不同的自定义序列。
sequence函数
sequence函数sequence函数是一种数学工具,它可以用来生成不断增加或减少的序列。
序列由公式或算法定义,它们可以是固定长度或持续增长或减少的序列。
它们的功能是,给出一组数字或其它序列元素,根据指定的算法,通过每个元素的增加或减少,生成不断增加或减少的序列。
序列函数能够产生一系列特定的数字,允许用户更加细致地控制变量和参数,以及它们之间的关系。
它们也可以用来推算出其他变量的影响,从而了解更多信息。
它们还可以用来预测不断变化的趋势,也可以用来检测时间变化和空间变化。
使用sequence函数时,首先要定义序列的种类。
可以决定是生成持续增长的序列,还是持续减少的序列。
然后计算序列的首项,填入初始值,即序列的第一个元素,再给出每一项的公式,以及步长的数值,即每一项和前一项之间的差值。
这样,就可以通过既定的公式,逐项推算出序列的每一项。
sequence函数可用于不同的应用领域。
它可以用于线性代数,用来求解特定方程的根,也可以用于图像图形学,确定图像中每个像素点的坐标,甚至可以计算空间曲线的参数。
数学的一般运用,如计算面积、计算体积、计算某种函数的积分、求解不定积分等,均可以用sequence函数来实现。
随着计算机技术的发展,序列函数也推广到很多其他领域,可以应用于生物学、药学、心理学、物理学、机械工程、计算机科学和多媒体等领域。
例如在机器学习及人工智能方面,也可以用序列函数来建立相应的模型,从而更加准确地预测出实际数据的趋势。
总之,sequence函数不仅可以帮助用户生成不断增长或减少的序列,还可以用来更加精准地预测变化趋势,解决实际问题等。
它的价值就在于可以将复杂的数学问题简化,并有效地求解出精确的结果。
mysql的sequence用法
MySQL的sequence用法1.简介M y SQ L是一种流行的关系型数据库管理系统,广泛用于各种应用程序中。
在M yS QL中,se q ue nc e是一种非常有用的特性,可以轻松生成递增的序列值。
本文将详细介绍M yS QL中s eq u en ce的用法。
2.什么是s equence在数据库中,se qu en c e是一种生成递增序列值的对象。
它可以用于自动生成唯一的主键或其他需要递增值的列。
通常情况下,se q ue nc e是与表格关联的,每次向表格中插入一行数据时,s eq ue nc e会自动生成一个序列值。
3.创建seq uence在M yS QL中,可以通过以下语法创建se q ue nc e:C R EA TE SE QU EN CE seq u en ce_n am e;在创建s eq ue nc e时,可以定义其起始值、步长和最大值等属性。
例如,以下语法创建一个名为s eq ue nc e_na m e的se qu en ce,起始值为1,步长为1,最大值为100:C R EA TE SE QU EN CE seq u en ce_n am eS T AR TW IT H1I N CR EM EN TB Y1M A XV AL UE100;4.使用seq uence创建了s eq ue nc e后,可以通过以下方式获取s eq ue nc e的下一个值:N E XT VA LU EF OR se que n ce_n am e;通过这个语法,可以在插入数据时使用se q ue nc e的下一个值作为列的值。
例如,以下语句向名为ta bl e_nam e的表格中插入一行数据,其中i d列使用se qu en c e的下一个值:I N SE RT IN TO ta bl e_n a me(i d,na me)V A LU ES(N EX TV AL UEF O Rs eq ue nc e_na me,'Jo hn');5.修改seq uence在某些情况下,可能需要修改已创建的se q ue nc e的属性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 填写作者、联系方式等,可以将这一部分存为模板,以后修改时可以省去大量时间。
2. 选择序列准备方法”use the normal submission dialog”
3. 选择序列格式
Submission type:single sequence(单条序列)
Batch submission(批量提交,适用于相似的多条序列)
4. 载入DNA序列:
将DNA 序列保存为FASTA格式(注意序列不要有“—”,尤其是多条序列时,较短的序列末端可能会用“—”补齐,可以用记事本打开文件,删除)。
序列名称不要超过32个字符,可以用简单的编号。
5. 选择测序、拼接方法
6. 添加物种名称
7. 补充蛋白信息(如果序列是编码序列,则要提交蛋白序列信息)若为ITS序列见后
用MEGA或BioEdit将DNA序列翻译成蛋白序列,如果有含子,则先要找出含子并切除,否则不能翻译成功。
(确定含子位置方法:先从GenBank上下载一条该基因已经提交并注释好的序列,跟自己的序列比对一下,然后根据下载序列的注释确定自己序列的含子位置)
8. 注释
9. 添加分类地位
10. mRNA 添加“Name = 基因全称”CDS添加“product = 基因全称”
11. 更改序列标题(编号);Source 添加“strain = ”:
Modifiers > organism
12. 保存
若点击Done之后可以保存,则说明序列修改成功,可以提交了;若有错误则会提示,修改好之后再保存。
ITS序列
7. 以下信息无需填写
8.
9. 此时进入预览页面会有错误提示,可以忽略。
10. 添加miscRNA
11.。