首先可绘制矩阵散点图
人力资源回归预测法

人力资源回归预测法人力资源管理对于企业的发展起着至关重要的作用。
为了合理规划和调配人力资源,预测人力资源需求是一项必不可少的工作。
而人力资源回归预测法是一种常用的预测方法,可以通过对历史数据的分析,利用回归模型来预测未来的人力资源需求。
人力资源回归预测法基于统计学原理,通过对过去的数据进行分析和建模,来预测未来的人力资源需求。
这种方法的核心思想是,人力资源需求与一系列相关因素之间存在着一定的线性关系,通过建立回归模型,可以利用这些相关因素的变化来预测人力资源的需求量。
在进行人力资源回归预测之前,首先需要确定一些相关的自变量。
这些自变量可以包括企业的规模、行业的发展状况、经济的增长率、劳动力市场的供求情况等。
通过对这些自变量的收集和整理,可以建立起一个完整的数据集。
接下来,需要对数据进行处理和分析。
首先,可以通过绘制散点图来观察变量之间的关系,判断是否存在线性关系。
如果存在线性关系,可以进一步计算相关系数,来评估变量之间的相关程度。
然后,可以利用多元线性回归模型来建立预测模型,通过最小二乘法来估计模型的参数。
在建立好回归模型之后,可以利用该模型来进行人力资源需求的预测。
根据预测的目标,可以设置不同的自变量的取值,来预测不同时间段的需求量。
同时,也可以通过模型的拟合优度来评估模型的准确性和可靠性。
人力资源回归预测法的优点在于可以利用历史数据来进行预测,具有一定的科学性和可靠性。
同时,该方法也可以帮助企业进行人力资源的合理规划和调配,减少人力资源的浪费和闲置。
然而,该方法也存在一些局限性,如对于外部环境的变化较为敏感,需要不断更新和调整模型。
人力资源回归预测法是一种常用的预测方法,可以通过对历史数据的分析和建模,来预测未来的人力资源需求。
通过合理利用该方法,企业可以更好地规划和调配人力资源,提高企业的竞争力和效益。
但同时也需要注意该方法的局限性,及时更新和调整模型,以适应外部环境的变化。
excel怎么做直角坐标系散点图

Excel如何绘制直角坐标系散点图
Excel是一款强大的办公软件,除了表格处理和数据计算外,还具备绘制图表的功能。
直角坐标系散点图是一种常见的数据可视化方式,在Excel中制作起来也非常简单。
下面将介绍如何在Excel中绘制直角坐标系散点图。
步骤一:准备数据
首先,打开Excel并准备要绘制散点图所需的数据。
通常情况下,数据应该包含两列:一列用于X轴数据,一列用于Y轴数据。
确保数据以合适的格式组织,这样绘制起来会更加方便。
步骤二:选择数据
在Excel中选中包含数据的范围。
可以同时选中X轴和Y轴的数据,也可以先选中其中一列,再按住Ctrl键选中另一列。
步骤三:插入散点图
在Excel的菜单栏中选择“插入”选项卡,然后选择“散点图”功能。
在弹出的菜单中,选择合适的散点图类型,通常选择标准散点图即可。
步骤四:调整图表样式
一般来说,Excel会自动绘制散点图,但有时需要对图表进行一些调整以使其更清晰易读。
可以修改标题、坐标轴标签、数据点的形状和颜色等,以及添加图例来帮助解读数据。
步骤五:保存和分享
完成散点图的制作后,记得保存Excel文件。
可以将图表导出为图片或PDF格式,也可以直接在Excel中将文件分享给其他人。
通过以上步骤,你可以在Excel中轻松制作直角坐标系散点图,将数据直观地呈现出来,帮助你更好地分析和理解数据。
希望这个简单的教程对你有所帮助!。
(完整版)Stata学习笔记和国贸理论总结

Stata学习笔记一、认识数据(一)向stata中导入txt、csv格式的数据1.这两种数据可以用文本文档打开,新建记事本,然后将相应文档拖入记事本即可打开数据,复制2.按下stata中的edit按钮,右键选择paste special3.*.xls/*.xlsx数据仅能用Excel打开,不可用记事本打开,打开后会出现乱码,也不要保存,否则就恢复不了。
逗号分隔的数据常为csv数据。
(二)网页数据网页上的表格只要能选中的,都能复制到excel中;网页数据的下载可以通过百度“国家数据”进行搜索、下载二、Do-file 和log文件打开stata后,第一步就要do-file,记录步骤和历史记录,方便日后查看。
Stata处理中保留的三种文件:原始数据(*.dta),记录处理步骤(*.do),以及处理的历史记录(*.smcl)。
三、导入StataStata不识别带有中文的变量,如果导入的数据第一行有中文就没法导入。
但是对于列来说不会出现这个问题,不分析即可(Stata不分析字符串,红色文本显示;被分析的数据,黑色显示);第一行是英文变量名,选择“Treat first row as variable names”在导入新数据的时候,需要清空原有数据,clear命令。
导入空格分隔数据:复制——Stata中选择edit按钮或输入相应命令——右键选择paste special——并选择,确定;导入Excel中数据,复制粘贴即可;逗号分隔数据,选择paste special后点击comma,然后确定。
Stata数据格式为*.dta,导入后统一使用此格式。
四、基本操作(几个命令)(一)use auto,clear 。
在清空原有数据的同时,导入新的auto数据。
(二)browse 。
浏览数据。
(三)describe 和list。
查看数据,describe 和list 使用list命令能使我们根据自己的需要选择数据(例如其与in/if语句的结合使用)。
SPSS实验7-曲线估计

SPSS作业7:曲线估计为研究居民家庭教育支出和消费性支出之间的关系,收集到1990年到2002年全国人均消费性支出和教育支出的数据。
首先绘制教育支出和消费性支出的散点图,如下所示:(一)教育支出的相关因素分析曲线估计的基本操作:(1)选择菜单Analyz e-Regression―Curve Estimation;(2)选择被解释变量到Dependent框中,再选择菜单Graph s―Scatter;分别作简单散点图,矩阵散点图,结果如下:Graph教育支出和年人均消费性支出的散点图分析:观察散点图发现两变量之间呈非线性关系,其中,教育支出为被解释变量,消费性支出为解释变量,分析结果如下:教育支出的曲线估计结果MODEL: MOD_2.Dependent variable.. X5 Method.. QUADRATIListwise Deletion of Missing DataMultiple R .99353R Square .98710Adjusted R Square .98452Standard Error 45.70690Analysis of Variance:DF Sum of Squares Mean SquareRegression 2 1598766.0 799383.00Residuals 10 20891.2 2089.12F = 382.64096 Signif F = .0000-------------------- Variables in the Equation -------------------- Variable B SE B Beta T Sig TX2 -.147527 .025041 -1.134958 -5.892 .0002 X2**2 2.46018091E-05 2.2722E-06 2.085797 10.827 .0000 (Constant) 252.697890 57.792248 4.373 .0014Dependent variable.. X5 Method.. CUBICListwise Deletion of Missing DataMultiple R .99711R Square .99422Adjusted R Square .99230Standard Error 32.23848Analysis of Variance:DF Sum of Squares Mean SquareRegression 3 1610303.3 536767.78Residuals 9 9353.9 1039.32F = 516.46087 Signif F = .0000-------------------- Variables in the Equation -------------------- Variable B SE B Beta T Sig T X2 .075378 .069194 .579897 1.089 .3043 X2**2 -1.98768467E-05 1.3446E-05 -1.685204 -1.478 .1734 X2**3 2.59626300E-09 7.7924E-10 2.112252 . . (Constant) -41.313805 97.204131 -.425 .6808Dependent variable.. X5 Method.. COMPOUNDListwise Deletion of Missing DataMultiple R .99737R Square .99476Adjusted R Square .99428Standard Error .09002Analysis of Variance:DF Sum of Squares Mean SquareRegression 1 16.905289 16.905289Residuals 11 .089131 .008103F = 2086.35111 Signif F = .0000-------------------- Variables in the Equation -------------------- Variable B SE B Beta T Sig T X2 1.000420 9.1977E-06 2.711154 108768.23 .0000 (Constant) 20.955019 1.226139 17.090 .0000Dependent variable.. X5 Method.. POWERListwise Deletion of Missing DataMultiple R .97687R Square .95428Adjusted R Square .95012Standard Error .26578Analysis of Variance:DF Sum of Squares Mean SquareRegression 1 16.217387 16.217387Residuals 11 .777033 .070639F = 229.58009 Signif F = .0000-------------------- Variables in the Equation --------------------Variable B SE B Beta T Sig TX2 1.845988 .121832 .976871 15.152 .0000(Constant) 3.5781705054E-05 3.7164E-05 .963 .3563分析:由表可知:三次曲线和二次曲线的拟合优度都比较高,可参见下图。
高维数据可视化的主要方法

高维数据可视化的主要方法随着科技的发展和数据的爆炸式增长,我们面临的数据越来越高维。
高维数据的特点是维度多、样本稀疏,给数据分析和可视化带来了巨大的挑战。
为了更好地理解和分析高维数据,研究人员提出了许多高维数据可视化的方法。
本文将介绍几种主要的高维数据可视化方法。
1. 散点矩阵图散点矩阵图是一种常用的高维数据可视化方法。
它通过绘制数据集中每两个维度之间的散点图,可以直观地展示出各个维度之间的关系。
每个散点代表一个样本,不同的颜色可以表示不同的类别。
散点矩阵图可以帮助我们找出高维数据中存在的规律和异常值。
2. 平行坐标图平行坐标图是一种常用的高维数据可视化方法,它可以显示多个维度之间的关系。
在平行坐标图中,每个维度表示为垂直于坐标轴的一条直线,每个样本则表示为连接各个维度的折线。
通过观察这些折线的形状和走势,我们可以发现高维数据中的模式和异常。
3. t-SNEt-SNE是一种降维算法,可以将高维数据映射到二维或三维空间中进行可视化。
t-SNE通过计算样本之间的相似度,然后在低维空间中保持相似度关系,将高维数据映射到低维空间。
这样一来,我们可以通过观察降维后的数据点在二维或三维空间中的分布情况,来了解高维数据中的结构和聚类情况。
4. 主成分分析(PCA)主成分分析是一种常用的降维方法,可以将高维数据映射到低维空间中。
主成分分析通过线性变换将原始数据的维度降低,同时保留最大方差的特征。
这样一来,我们可以用较低维度的数据来表示高维数据,方便可视化和分析。
5. 矩阵散点图矩阵散点图是一种可视化高维数据的方法,适用于数据之间存在复杂关系的情况。
在矩阵散点图中,每个维度都用一个坐标轴表示,每个样本则表示为一个散点。
通过绘制不同维度之间的散点图,我们可以观察到高维数据的内在结构和规律。
6. 树状图树状图是一种将高维数据可视化为树状结构的方法。
在树状图中,每个节点代表一个维度,树的根节点代表整个数据集。
通过观察树状图的结构和分支情况,我们可以发现高维数据中的聚类和相似性。
智慧树知到《SPSS应用》章节测试答案

智慧树知到《SPSS应用》章节测试答案绪论1、学习《SPSS应用》可以有效提高你的统计思维能力。
A:对B:错正确答案:对第一章1、SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。
A.哈佛大学B.斯坦福大学C.波士顿大学D.剑桥大学正确答案:斯坦福大学2、()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。
A.savB.txtC.mp4D.flv正确答案:sav3、Spss输出结果保存时的文件扩展名是()。
A.savB.spvC.mp4D.flv正确答案:spv4、数据编辑窗口的主要功能有()。
A.定义SPSS数据的结构B.录入编辑和管理待分析的数据C.结果输出D.A和B正确答案:A和B5、数据编辑窗口中的一行称为一个()。
A.变量B.个案C.属性D.元组正确答案:个案第二章1、SPSS中无效的变量名有()。
A.@a1B.abc1#C.homeD.cd_1正确答案:@a1,home2、SPSS软件的编辑窗口能打开的文件类型有()。
A..stB..docC..xlsD..mat正确答案:*.xls3、变量的起名规则一般:变量名的字符个数不多于()。
A.6B.7C.8D.9正确答案:84、SPSS默认的字符型变量的对齐方式是()。
A.右对齐B.中间对齐C.左对齐D.以上说法都不对正确答案:中间对齐5、SPSS的主要变量类型不包括()。
A.数值型B.字符型C.日期型正确答案:英镑型第三章1、关于利用Sort by对数据排序的描述错误的有()。
A.排序变量可以是多个B.排序变量最多一个C.排序变量为多个时先按第一个排序,取值相同的再按第二个排,以此类推D.观测个体所有变量的值都变到新位置正确答案:B2、在横向合并数据文件时,两个数据文件都必须事先按关键变量值()。
A.升序排序B.降序排序C.不排序D.可升可降正确答案:A3、通过()可以达到将数据编辑窗口中的计数数据还原为原始数据的目的。
采用散点图气泡图三种方案轻松制作波士顿矩阵
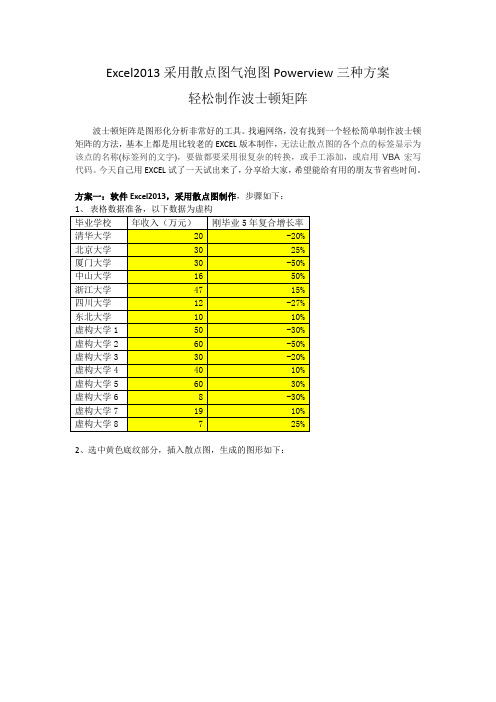
Excel2013采用散点图气泡图Powerview三种方案轻松制作波士顿矩阵波士顿矩阵是图形化分析非常好的工具。
找遍网络,没有找到一个轻松简单制作波士顿矩阵的方法,基本上都是用比较老的EXCEL版本制作,无法让散点图的各个点的标签显示为该点的名称(标签列的文字),要做都要采用很复杂的转换,或手工添加,或启用VBA宏写代码。
今天自己用EXCEL试了一天试出来了,分享给大家,希望能给有用的朋友节省些时间。
方案一:软件Excel2013,采用散点图制作,步骤如下:2、选中黄色底纹部分,插入散点图,生成的图形如下:把表中图拉伸放大,方便大家查看,如下:把图表标题改成波士顿矩阵,生成的图形如下:-60%-40%-20%0%20%40%60%010203040506070图表标题-60%-40%-20%0%20%40%60%010203040506070波士顿矩阵4、右键选中图上小点点,再点左键,调出菜单,选生成数据标签,过程图和生成的图形如下:-20%25%-50%50%15%-27%10%-30%-50%-20%10%30%-30%10%25%-60%-40%-20%0%20%40%60%010203040506070波士顿矩阵5、右键选中图上小点点,再点左键,调出菜单,选设置数据标签格式,过程图和生成的图形如下:6、右键选中单元格中的值前的勾,在新跳出的数据标签区域栏选中毕业大学那列,再点确定,然后把Y值前的勾去掉,过程图和生成的图形如下:7、右键点图中网络线,在右上角新出来设置主要网格线格式的菜单中,选无线条去掉横的网格线,然后用同样的方法去掉竖的网格线,过程图和生成的图形如下:8、右键点图中横坐标,在右上角新出来设置坐标轴格式的菜单中,把纵坐标交叉由自动调成坐标轴值为35,过程图和生成的图形如下:9、右键点图中横坐标、纵坐标,和方框进行美化和处理,过程图和生成的图形如下:10、好了,大功告成,如下:方案二:软件Excel2013,采用气泡图制作,步骤如下:1、选中下表格所有部分,插入气泡图,生成的图形一步步如下,由于气泡图的过程与散点图非常类似,除了多了一个气泡大小(我是用年收入体现气泡大小差异)外,中间过程我不毕业学校年收入(万元)刚毕业5年复合增长率清华大学20 -20%北京大学30 25%厦门大学30 -50%中山大学16 50%浙江大学47 15% 四川大学12 -27% 东北大学10 10% 虚构大学1 50 -30% 虚构大学2 60 -50% 虚构大学3 30 -20% 虚构大学4 40 10% 虚构大学5 60 30% 虚构大学6 8 -30% 虚构大学7 19 10% 虚构大学8 7 25%好了,是不是超级简单。
矩阵的散布图解原理和应用

矩阵的散布图解原理和应用1. 引言散布图(Scatter plot)是一种常用的数据可视化工具,用于展示两个变量之间的关系。
矩阵的散布图是指将多个变量两两组合,生成多个散布图的图表。
本文将介绍矩阵的散布图的原理和应用。
2. 矩阵的散布图的原理矩阵的散布图的原理基于散布图的原理,即通过绘制变量之间的点来显示它们之间的关系。
对于矩阵的散布图,我们需要选择两个或多个变量,并将它们两两组合。
对于每个组合,我们绘制一个散布图来显示它们之间的关系。
3. 矩阵的散布图的应用矩阵的散布图在数据分析中有广泛的应用。
下面列举了一些常见的应用场景:•探索变量之间的相互关系:通过生成矩阵的散布图,我们可以快速了解多个变量之间的关系,从而帮助我们发现变量之间的模式和趋势。
•识别异常值和离群点:矩阵的散布图可以帮助我们发现变量之间的异常值和离群点。
通过观察散布图中的点分布情况,我们可以发现那些与其他变量不一致的数据点。
•比较不同变量的分布:通过生成矩阵的散布图,我们可以直观地比较不同变量的分布情况。
例如,我们可以将人口数量和GDP进行组合,从而探索人口数量和GDP之间的关系。
4. 生成矩阵的散布图的步骤以下是生成矩阵的散布图的基本步骤:•选择要比较的变量:首先,我们需要选择要比较的变量。
这些变量可以是连续变量或分类变量。
•组合变量:根据选择的变量,我们需要将它们两两组合。
如果我们选择了n个变量,将会生成n * (n-1)个散布图。
•绘制散布图:对于每个变量组合,我们绘制一个散布图来显示它们之间的关系。
散布图可以使用散点图的形式,其中横轴和纵轴分别表示两个变量的值。
•分析结果:根据生成的矩阵的散布图,我们可以分析变量之间的关系。
我们可以观察点的分布情况,找出异常值和离群点,并比较不同变量的分布情况。
5. 矩阵的散布图的示例下面是一个示例,展示了如何生成矩阵的散布图:变量1 变量2 变量3变量1 散布图散布图变量2 散布图变量3在这个示例中,我们选择了3个变量进行比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
t
r n2 1 r
2
27
2. Spearman等级相关系数
• 用来度量两定序变量间的线性相关关系,计 算时并不直接采用原始数据 ( xi , yi ) ,而是利 用数据的秩,用两变量的秩 (U i ,Vi )代替( xi , yi ) 代入Pearson简单相关系数计算公式中,于 是其中的 xi 和 y i 的取值范围被限制在1和n 之间,且可被简化为:
实验七
相关分析
1
SPSS的相关分析
7.1 相关分析和回归分析概述 7.2 相关分析
7.3 偏相关分析
2
7.1 相关分析和回归分析概述
• 客观事物之间的关系大致可归纳为两大类:
函数关系(确定性关系) :指两事物之间的一种一一对应的关
系,如商品的销售额和销售量之间的关系。 统计关系(非确定性关系):指两事物之间的一种非一一对应的 关系,例如家庭收入和支出、子女身高和父母身高之间的关系等 。统计关系又分为相关关系和回归关系两种。
• 第二,对样本来自的两总体是否存在显著的线 24 性关系进行推断。
对不同类型的变量应采用不同的相关系数来度量
双变量关系强度测量的主要指标
定类 定类 定序 定距 定序 定距
卡方类测量 卡方类测量 Eta 系数
Spearman 相关系数 同序 -异序 对测量 Spearman 相关系数 Pearson 相关系数
23
7.2.2 相关系数
利用相关系数进行变量间线性关系的分析 通常需要完成以下两个步骤: • 第一,计算样本相关系数r;
相关系数r的取值在-1~+1之间 r>0,正的线性相关关系;r<0负的线性相关关系 r=1,完全正相关;r=-1,完全负相关;r=0,不相关 |r|>0.8,较强的线性关系; |r|<0.3,线性关系较弱
• 标注个案Label Cases by:观测量标签变量
10
11
2、矩阵散点图
• 在矩阵散点图中,将图形分成多个方格,在 每个方格中单独绘制某两个变量的数据。 • 在散点图窗口中选择矩阵散点图,单击定义 Define,在出现的窗口中,依次选择投入高 级职称人数、课题总数、论文数和获奖数进 入矩阵变量Matrix框中,选择是否为直辖市
19
20
相关回归分析(高校科研研究).sav
5、堆积散ቤተ መጻሕፍቲ ባይዱ图-简单点图
• 选中简单点, 单击定义 Define按钮, 打开窗口
21
22
• 对于其它图形的SPSS绘制 ,可阅读参考书,杜强、 贾丽艳,《SPSS统计分析 从入门到精通》,人民邮 电出版社,2011年 • 书中的第19章,统计图形.
15
相关回归分析(高校科研研究).sav
16
17
4、三维散点图
三维散点图在三维坐标系中绘制三个变 量的数据。 在散点图窗口中选择三维散点图,单击 Define ,在出现的窗口中,分别选择论文 数、投入人年数和获奖数为 Y 轴变量、 X 轴变量、Z轴变量。
18
相关回归分析(高校科研研究).sav
• 相关分析和回归分析都是分析客观事物之间统计
关系的数量分析方法。
3
相关分析与回归分析的区别
相关关系 变量y与变量x处于平等地位 变量y与x均为随机变量 回归关系 变量y处于被解释的特殊地位 变量y为随机变量,x可为随 机变量,也可为非随机变量
目的是刻画变量间的相关程 度
可解释x对Y的影响大小,还 可以对y进行预测与控制
i 1 i 1
• 在小样本下,在零假设成立时, Spearman等级相关 系数服从Spearman分布;在大样本下, Spearman等 级相关系数的检验统计量为Z统计量,定义为:
进入设置标记Set Markers框中。
12
相关回归分析(高校科研研究).sav
13
14
3、重叠散点图
在重叠散点图中,在一个坐标系中绘制 多个不同的变量对。 在散点图窗口中选择重叠散点图,单击 定义Define,在出现的窗口中,选择变量 投入人年数--论文数对和投入高级职称的 人年数--专著数对进入Y-X Pairs框中。
4
7.2 相关分析
• 7.2.1 散点图 • 7.2.2 相关系数 • 7.2.3 基本操作 • 7.2.4 应用举例
5
•
相关分析通过图形和数值两种方式,有 效地揭示事物之间相关关系的强弱程度和形 式。
• 7.2.1 散点图
•
它将数据以点的的形式画在直角坐标系 上,通过观察散点图能够直观的发现变量间
的相关关系及他们的强弱程度和方向。
6
散点图的绘制
• 单击图形旧对话框散点/点状,打开窗口
7
• 简单分布(Simple Scatter),只能在图上显 示一对相关变量 • 矩阵分布(Matrix Scatter),在矩阵中显示 多个相关变量 • 重叠分布(Overlay Scatter),在图上显示多 对相关变量 • 3-D分布(3-D Scatter),显示三个相关变量 • 简单点,堆积散点图
8
相关回归分析(高校科研研究).sav
1、简单散点图
选中简单分布,单 击定义Define按钮, 打开窗口
9
• Y轴Y Axis:选择Y轴要绘制的变量
• X轴X Axis:选择X轴要绘制的变量
• 设置标记 Set Markers by:选择分组变量
,SPSS根据该变量的值将观测量分成几组
,每组采用不同的符号标注
25
更多指标-交叉列联表
适用于两分类 变量的分析
适用于两顺序 变量的分析
适用于一分类 变量一定距变 量的分析
26
1. Pearson简单相关系数
• 适用于两个变量都是数值型的数据
r
( x x )( y y ) ( x x ) g ( y y )
i i 2 i i
2
• Pearson简单相关系数的检验统计量为:
r 1
n(n 1)
2
6 D
2 i
,其中 D (Ui Vi )
i 1 2 i i 1
n
n
2
28
• 如果两变量的正相关性较强,它们秩的变化具有同步 n n 2 性,于是 Di (U i Vi )2 的值较小,r趋向于1;
i 1 i 1
• 如果两变量的正相关性较弱,它们秩的变化不具有同 n n 2 步性,于是 Di (U i Vi )2 的值较大,r趋向于0;