play框架手册-13.使用缓存
Play框架教程

P l a y f r a m e w o r k框架 1一、P l a y框架介绍 1二、初学者入门 6安装 Play Framework 6 接下来创建一个新的应用程序7来看看 Play 框架是怎么工作的 ? 9增加一个新的页面10结论11三、P l a y F r a m e w o r k框架路由(R o u te)11三、P l a y F r a m e w o r k框架的控制器(C o n tr o ll er)14四、P l a y F r a m e w o r k框架的模板27五、P l a y框架中的A j ax32六、P l a y框架使用缓存33七、P l a y!1.1框架中的S ca l a模块37Controllers composition using traits 39How to define and access Models 39 Main differences 39Running queries against Scala Models from Scala classes 40Running queries against Java Models from Scala classes 41 Unit Testing 42八、使用P l a y发送邮件42九、Play framework的问题47十、P l a y F r a m e w o r k平台的性能比较49十一、P l a y F r a m e w o r k平台所用到的j a r 包一览52 十二、P l a y F r a m e w o r d生成的w a r 包里有什么内容52P l a y f r a m e w o r k框架一、P l a y框架介绍Play框架概述Play框架是臃肿的企业级Java之外的另一个选择,它关注的是开发的效率和提供REST式的架构风格, Play是“敏捷软件开发”的绝佳伴侣。
Ionic框架中的本地存储和缓存技巧

Ionic框架中的本地存储和缓存技巧Ionic框架作为一款面向移动端的开发框架,为开发者提供了丰富的工具和功能,其中本地存储和缓存技巧是构建稳定和高性能应用的重要组成部分。
本文将探讨Ionic框架中的本地存储和缓存技巧,帮助开发者更好地应用于实际项目中。
在移动应用开发中,由于网络环境的不稳定性和延迟,本地存储和缓存技巧是提升用户体验和应用性能的关键。
Ionic框架提供了多种本地存储和缓存方案,开发者可以根据实际需求选择合适的方案。
一种常用的本地存储技术是使用Ionic的Storage模块。
这个模块提供了一种简单和可靠的键值对存储方案,可以在应用中轻松存储和检索数据。
通过使用Storage模块,开发者可以将用户的个人设置、应用的状态和其他需要持久保存的数据保存在本地,确保用户下次打开应用时能继续使用之前的设置。
除了Storage模块,Ionic还提供了一个名为IonicCache的插件,用于缓存请求的数据。
在移动应用中,经常需要从远程服务器获取数据,然后在应用中使用。
使用IonicCache可以将服务器返回的数据保存在本地,下次需要使用时可以直接从缓存中获取,避免了频繁的网络请求,提高了应用的响应速度和性能。
在实际项目中,开发者可以结合Storage和IonicCache来实现更多的本地存储和缓存需求。
例如,可以将用户的登录信息通过Storage模块保存在本地,实现自动登录功能。
当用户再次打开应用时,可以首先检查本地是否存在登录信息,如果存在则直接跳过登录界面,提升用户体验。
另外,开发者还可以使用IonicCache缓存用户最近喜欢的音乐列表或商品信息,减少对服务器的请求,提高应用的加载速度。
除了Storage和IonicCache,Ionic框架还支持使用SQLite数据库进行本地存储。
SQLite是一种轻量级的关系型数据库,适用于嵌入式设备和移动应用。
使用SQLite数据库可以实现更复杂的数据查询和管理,对于一些需要使用复杂查询的场景非常有用。
轻量级的高性能Web框架:Play

Play是一款开源、轻量、无状态、Web友好的架构,使用Java语言编写并遵循MVC模式,集成了当今Web开发所需的组件和API。
此外Play可以给应用程序提供可预测的和最小的资源消耗(CPU,内存,线程),可构建高扩展的应用程序。
目前Play的最新版本是2.1,在该版本中需关注的几点是:移植到Scala 2.1上、Migration to scala.concurrent.Future库,可在Scala中管理异步代码、改进Iteratee API、在项目中可构建更多的模块化代码、为Java API提供更好的线程模型、新增Scala JSON API、Filter API和CSRF保护机制等。
除了上述所描述的这些特征外,最受开发者喜爱的又有哪些呢?不妨来看下:•快速迭代:修改代码、刷新页面立即就能看到•Java和Scala:JVM性能、类型安全、库、IDE/工具支持、活跃的社区•反应:非阻塞I0机制使数据/基于网络的实时数据获取更容易•灵活:支持可插、自定义配置和可定制。
既然Play拥有这么多功能,下面就提供一些示例给大家。
1.创建按照安装说明,创建一个叫play-tutorial的App,使用play new命令:2.运行Appcd到play-tutorial的根目录下,使用play run命令启动服务器,然后在浏览器中输入:http://localhost:9000这时,你可以在IDE里加载和查看play-tutorial源码。
Java培训:3.Hello WroldPlay遵循MVC模式,所以先在app/controllers下创建一个控制器:HelloWorld下面要做的是在浏览器上显示这个controller/action,你可以把这个添加到conf下的routes 文件下。
在浏览器中输入:http://localhost:9000/hello。
play框架plugin简单说明及例子

play1.2.4版本:继承类play.PlayPlugin,我们可以实现插件的功能。
play框架本身基于此类提供了一些已经实现的plugin,比如:ConfigurablePluginDisablingPlugin, CorePlugin, DBPlugin, Evolutions, JobsPlugin, JPAPlugin, MessagesPlugin, TempFilePlugin, ValidationPlugin, WS这其中有我们非常熟悉的JobsPlugin,实现一些定时JOB,onApplicationStart() 和onApplicationStop() 在服务启动停止时实现一些我们自己的业务。
onApplicationStart() 和onApplicationStop() 都是PlayPlugin类的方法,当然还有很多其它方法,你只需要继承类并重写这些方法就可以实现自己需要的插件。
打开play-1.2.4.jar包,在根目录下,我们可以看到文件play.plugins,这里面列出了所有play 已经实现的插件,该文件中列出的插件类在play启动时加载。
打开看看内容:0:play.CorePlugin100:play.data.parsing.TempFilePlugin200:play.data.validation.ValidationPlugin300:play.db.DBPlugin400:play.db.jpa.JPAPlugin450:play.db.Evolutions500:play.i18n.MessagesPlugin600:play.libs.WS700:play.jobs.JobsPlugin100000:play.plugins.ConfigurablePluginDisablingPlugin每个插件类一行,第一列的数字为编号。
所以,我们要实现自己的插件并应用,必须也新加一个play.plugins文件(名称必须为play.plugins,在play jar中写死了,否则无法加载),存放在app目录下。
如何使用前端框架技术实现页面缓存与离线访问

如何使用前端框架技术实现页面缓存与离线访问使用前端框架技术实现页面缓存和离线访问是提高网页性能和用户体验的重要步骤。
本文将介绍页面缓存和离线访问的概念,并详细讨论如何利用前端框架技术来实现这些功能。
页面缓存是将网页的内容保存在本地存储中,以便在未来访问相同网页时能够直接加载缓存的内容,而无需再次从服务器请求数据。
这可以大大减少页面加载时间和服务器负载,提高用户的访问速度和体验。
一种常见的实现页面缓存的方式是使用Service Worker。
Service Worker是一个独立于网页的JavaScript线程,它可以拦截和处理网络请求,并且可以将请求的数据缓存到本地。
通过在Service Worker中使用缓存API,可以将网页的内容缓存在用户设备上,实现页面缓存和离线访问的功能。
在使用前端框架时,可以通过以下步骤实现页面缓存和离线访问:1. 注册Service Worker:首先,在前端框架的入口文件中注册Service Worker。
通过navigator.serviceWorker.register()方法,将Service Worker脚本注册到浏览器中。
2. 缓存静态资源:在Service Worker脚本中,可以通过监听install事件来缓存网页的静态资源文件,如HTML、CSS、JavaScript和图像等。
在监听到install事件后,可以使用缓存API将这些静态资源文件缓存到本地。
3. 拦截网络请求:通过监听fetch事件,可以拦截并处理浏览器发起的网络请求。
在Service Worker中,可以通过缓存API查询本地缓存是否存在该请求的数据,如果存在,则直接从缓存中返回数据;如果不存在,则通过网络请求获取数据,并将其缓存到本地供以后使用。
4. 更新缓存:当静态资源发生更新时,需要更新缓存在本地的数据。
可以通过监听activate事件,在Service Worker激活后,清除旧版本的缓存,并将新版本的静态资源缓存到本地。
play框架手册-01.Play框架最主要的概念
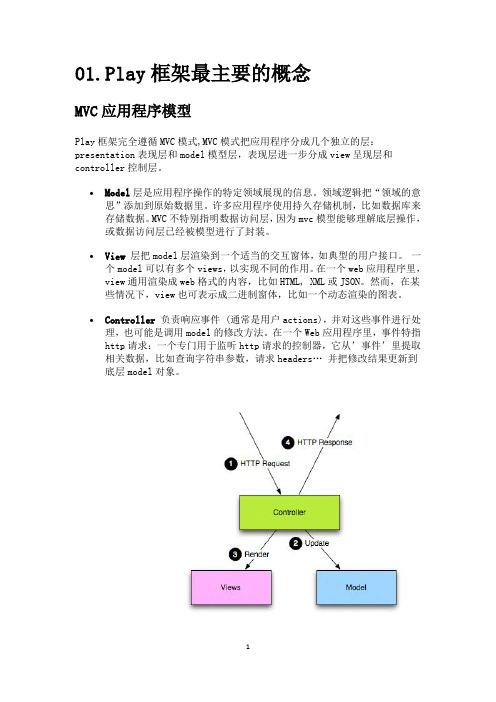
01.Play框架最主要的概念MVC应用程序模型Play框架完全遵循MVC模式,MVC模式把应用程序分成几个独立的层:presentation表现层和model模型层,表现层进一步分成view呈现层和controller控制层。
∙Model层是应用程序操作的特定领域展现的信息。
领域逻辑把“领域的意思”添加到原始数据里。
许多应用程序使用持久存储机制,比如数据库来存储数据。
MVC不特别指明数据访问层,因为mvc模型能够理解底层操作,或数据访问层已经被模型进行了封装。
∙View层把model层渲染到一个适当的交互窗体,如典型的用户接口。
一个model可以有多个views,以实现不同的作用。
在一个web应用程序里,view通用渲染成web格式的内容,比如HTML, XML或JSON。
然而,在某些情况下,view也可表示成二进制窗体,比如一个动态渲染的图表。
∙Controller负责响应事件 (通常是用户actions),并对这些事件进行处理,也可能是调用model的修改方法。
在一个Web应用程序里,事件特指http请求:一个专门用于监听http请求的控制器,它从’事件’里提取相关数据,比如查询字符串参数,请求headers… 并把修改结果更新到底层model对象。
在Play应用程序里,这三个层被分别定义到app目录下的三个java包里。
app/controllers控制器就是一个java类,其中的每个public/static方法都是一个Action。
一个action就是一个java入口点,当接收到一个http请求时,这个action就会被调用。
控制器类里的java代码并不真正的面向对象的。
Action方法从http 请求中提取相关的数据,读取或更新model对象,并向http请求者返回一个封装好的response结果。
app/models领域模型对象层(以下简称model)是一系列完全使用java面向对象语言特征的java类,它包含了数据结构和数据操作。
【翻译】Play框架入门教程一:建立项目

【翻译】Play框架入门教程一:建立项目简介在这个教程中你会学到用Play框架从头到尾的开发一个真切的Web程序。
在这个程序中,我们将用法在一个真切项目中需要的全部技术,来介绍Play框架开发Web程序的实战技巧。
这个教程分为几个自立的部分。
每个部分将介绍更多复杂的特性,并且提供真切项目的需求,包括数据验证、错误处理、权限框架、自动测试框架、Web界面接口、国际化等内容。
项目我们打算创建一个blog项目。
这不是一个有想象力的打算,但是这个项目能让我们学习到目前Web程序大多数的功能性需求。
为了更好玩点,我们要处理不同角色的用户(itor,admin)。
这个项目的名字称为yabe。
这个教程的源代码在Play安装名目下的samples-and-tests/yabe/名目。
先决条件首先,确保计算机安装了Java,Play框架需要Java 5或以上版本。
还有我们要用法行,最好用法类Unix操作系统。
固然假如你用法Windows操作系统,Play框架也会工作得很好。
要有Java和Web开发技术(比如:HTML, CSS and JavaScript)的学问,然而不必深化了解JEE的学问。
Play框架是一个全栈式 Java框架,提供和封装了你所需要的全部Java API,你不必知道怎样配置JPA实体或者部署JEE组件。
固然还需要文本编辑器。
假如你习惯用诸如Eclipse和NetBeans等Java IDE开发Play框架的Web程序是十分好的。
然而用法一些诸如Ttmate、Emacs或VI简便的文本编辑器来开发Play框架的Web程序也是十分开心的。
安装Play 框架安装十分容易,下载最近的版本然后到任何路径。
假如用法Windows,应避开在安装路径中有空格。
比如c:\play ,而不能是c:\Documents And Settings\user\play。
最好是把Play主名目加入到工作路径path,这样只需要在指令行输入play就可以用法Play框架的功能了。
Django缓存Cache使用详解

Django缓存Cache使⽤详解缓存(Cache)对于创建⼀个⾼性能的⽹站和提升⽤户体验来说是⾮常重要的,然⽽对我们这种只⽤得起拼多多的码农⽽⾔最重要的是学会如何使⽤缓存。
今天我们就来看看缓存Cache应⽤场景及⼯作原理吧,并详细介绍如何在Django中设置Cache并使⽤它们。
什么是缓存Cache缓存是⼀类可以更快的读取数据的介质统称,也指其它可以加快数据读取的存储⽅式。
⼀般⽤来存储临时数据,常⽤介质的是读取速度很快的内存。
⼀般来说从数据库多次把所需要的数据提取出来,要⽐从内存或者硬盘等⼀次读出来付出的成本⼤很多。
对于中⼤型⽹站⽽⾔,使⽤缓存减少对数据库的访问次数是提升⽹站性能的关键之⼀。
为什么要使⽤缓存Cache在Django中,当⽤户请求到达视图后,视图会先从数据库提取数据放到模板中进⾏动态渲染,渲染后的结果就是⽤户看到的⽹页。
如果⽤户每次请求都从数据库提取数据并渲染,将极⼤降低性能,不仅服务器压⼒⼤,⽽且客户端也⽆法即时获得响应。
如果能将渲染后的结果放到速度更快的缓存中,每次有请求过来,先检查缓存中是否有对应的资源,如果有,直接从缓存中取出来返回响应,节省取数据和渲染的时间,不仅能⼤⼤提⾼系统性能,还能提⾼⽤户体验。
我们来看⼀个实际的博客例⼦。
每次当我们访问⾸页时,下⾯视图都会从数据库中提取⽂章列表,并渲染的模板⾥去。
⼤多数情况下,我们的博客不会更新得那么频繁,所以⽂章列表是不变的。
这样⽤户在⼀定时间内多次访问⾸页时都从数据库重新读取同样的数据是⼀种很⼤的浪费。
from django.shortcuts import renderdef index(request):# 读取数据库等并渲染到⽹页article_list = Article.objects.all()return render(request, 'index.html', {'article_list': article_list})使⽤缓存Cache就可以帮我们解决这个问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
13.使用cache
为了创建高效的系统,有里会需要缓存数据。
play有一个cache库,在分布式环境中使用Memcached。
如果没有配置Memcached,play将使用标准的缓存来存储数据到JVM heap堆中。
在JVM应用程序里缓存数据打破了play创造的“什么都不共享”的原则:你不能在多个服务器上运行同一应用程序,否则不能保证应用行为的一致性。
每个应用实例将拥有不同的数据备份。
清晰理解缓存约定非常重要:当把数据放入缓存时,就不能保证数据永久存在。
事实上不能这样做,缓存非常快,只在内存里存在(并没有进行持久化)。
因此使用缓存最好的用途就是数据不需要进行修改的情况
public static void allProducts() {
List<Product> products = Cache.get("products", List.class);
if(products == null) {
products = Product.findAll();
Cache.set("products", products, "30mn");
}
render(products);
}
The cache API
缓存API由play.cache.Cache类提供,这个类包含了许多用于从缓存设置、替换、获取数据的方法。
参考Memcached文档以了解每个方法的用法。
示例:
public static void showProduct(String id) {
Product product = Cache.get("product_" + id, Product.class);
if(product == null) {
product = Product.findById(id);
Cache.set("product_" + id, product, "30mn");
}
render(product);
}
public static void addProduct(String name, int price) {
Product product = new Product(name, price);
product.save();
showProduct(product.id);
}
public static void editProduct(String id, String name, int price) {
Product product = Product.findById(id);
= name;
product.price = price;
Cache.set("product_" + id, product, "30mn");
showProduct(id);
}
public static void deleteProduct(String id) {
Product product = Product.findById(id);
product.delete();
Cache.delete("product_" + id);
allProducts();
}
有一些方法是以safe前缀开头的方法,比如safeDelete, safeSet。
而标准方法是非阻塞式的,比如:
Cache.delete("product_" + id);
delete方法将立即返回,不会一直等到缓存对象是否真的删除。
因此,如果发生错误时,比如IO错误,那么要删除的对象仍旧存在。
在继续之前如果需要确定是否真的把对象删除了,就可以使用safeDelete方法:
Cache.safeDelete("product_" + id);
这个方法是阻塞式的,并且会返回一个boolean值来确定是否真的把对象删除了。
因此,从缓存中删除对象的完整模式应该是这样的:
if(!Cache.safeDelete("product_" + id)) {
throw new Exception("Oops, the product has not been removed from the cache");
}
...
注意:这些方法会导致调用中断,安全方法会慢慢的顺着执行下去,一般情况下,只要确实需要的时候才使用这些方法。
同时要注意,当expiration == "0s" (0秒)时,真正的中止时间可能与缓存执行的时间不同。
不要把Session当成缓存!
如果使用框架带来的内存式的session来作缓存,你就会发现play只允许很小的字符串数据可以存入HTTP Session,这里不应该是缓存应用程序数据的地方!
如果你已经习惯了这样做:
httpServletRequest.getSession().put("userProducts", products);
...
// 之后进行请求
products =
(List<Product>)httpServletRequest.getSession().get("userProducts");
在Play里可以用其他方式实现相同效果:
Cache.set(session.getId(), products);
...
//接下来的请求为:
List<Product> products = Cache.get(session.getId(), List.class)
在这里,我们使用唯一的UUID来为每个用户在缓存里保存唯一信息。
请记住,这和session对象不同,缓存并不绑定任何特定的用户!
配置mcached
如果需要允许真正的Memcached实现,就需在memcached configuration定义守护地址memcached.host configuration。