SPSS统计描述分析
SPSS统计分析数据特征的描述统计分析

SPSS统计分析数据特征的描述统计分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,用于对数据进行描述统计分析。
描述统计分析旨在帮助研究人员对数据进行简单的整理、描述和总结,以便更好地理解数据的特征和趋势。
下面将说明几种常用的描述统计分析方法。
1.频数统计频数统计是指对数据中各个变量的不同取值进行计数。
通过统计每个取值出现的次数,可以了解数据的分布情况和变量的特点。
SPSS提供了多种方式来进行频数统计,包括直方图、饼图等。
通过这些图表,可以清晰地看到变量的取值分布。
2.中心趋势测量中心趋势测量是描述数据集合中心位置的统计方法,常用的测量指标包括平均数、中位数和众数。
平均数是所有数据的算术平均值,中位数是将数据按大小排列后处于中间位置的数值,众数是出现次数最多的数值。
SPSS提供了计算这些测量指标的功能,以便更好地了解数据的中心位置。
3.离散程度测量离散程度测量是描述数据变异程度的方法,常用的度量指标包括标准差、方差和极差。
标准差是数据与平均数之间的平均偏差,方差是标准差的平方,表示数据的离散程度,极差是最大值与最小值之间的差异。
通过这些指标,可以判断数据的离散程度,以及是否存在异常值等问题。
4.偏度和峰度测量偏度和峰度是描述数据分布形态的指标。
偏度测量的是数据分布的偏斜程度,正偏斜表示分布右侧的极端值较多,负偏斜表示分布左侧的极端值较多。
峰度测量的是数据分布的尖峰程度,正峰度表示尖峰较高且尾巴较短,负峰度表示尖峰较低且尾巴较长。
通过偏度和峰度的测量,可以判断数据的分布形态是否符合正态分布。
5.相关分析相关分析旨在研究两个或多个变量之间的关系。
相关系数是用来衡量变量之间线性相关程度的指标,取值范围从-1到+1、接近-1的相关系数表示负相关,接近+1的相关系数表示正相关,接近0的相关系数表示无相关。
通过相关分析,可以了解不同变量之间的关系,以及它们对研究问题的影响程度。
SPSS数据分析—描述性统计分析

SPSS数据分析—描述性统计分析描述性统计分析是一种针对数据本身的分析方法,通过使用统计学指标来描述数据的特征。
这种分析方法看似简单,但实际上却是许多高级分析的基础工作。
很多高级分析方法都对数据有一定的假设和适用条件,这些可以通过描述性统计分析来判断。
我们也会发现,许多分析方法的结果中都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三个方面:集中趋势、离散趋势和数据分布情况。
描述集中趋势的指标包括均值、众数和中位数,其中均值包括截尾均值、几何均值和调和均值等。
描述离散趋势的指标包括频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数和变异系数等。
需要注意的是,连续型变量和离散型变量的指标有所不同。
由于许多统计分析都有一个正态分布的假设,因此我们经常关注数据的分布特征。
常用峰度系数和偏度系数来描述数据偏离正态分布的程度。
也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值。
SPSS用于描述性统计分析的过程大部分都在分析-描述统计菜单中,另有一个在比较均值-均值菜单。
虽然这几个过程用途不同,但基本上都可以输出常用的指标结果。
分析-描述统计-频率过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值。
此外,该过程最主要的作用是输出频数表。
分析-描述统计-描述过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
分析-描述统计-探索过程是在原有数据进行描述性统计的基础上,更进一步的描述数据。
与前两种过程相比,它能提供更详细的结果。
分析-描述统计-比率过程主要用于对两个连续变量间的比率进行描述分析。
输出的结果比较简单,只是指标的汇总表格。
分析-描述统计-交叉表过程主要用于分类变量的描述性统计。
它可以完成频数分布和构成比的分析,也经常被用来做列联表的推断分析。
SPSS-03描述性统计分析

这三组数据的均值都是15.5,即他们的集中
趋势相同,但偏离中心的离散趋势却大不相 同:B最集中,A较的分散,C最分散。
①全距(range):又称极差,定义是range=maxmin,不常使用,只适合于度量型变量的计算。
②方差(variance)和标准差(std. deviation ):
如果勾选“描述性”:则输出均值、中位数、众数、
标准差、方差、最小值、最大值、峰度、偏度…… 如果勾选“M-估计量”:通常用来判断异常值,若 此统计量离均值较远,说明数据中有异常值
如果勾选“界外值”:则输出最大的5个值和最小
的5个值 如果勾选百分位数:输出第5%、10%、25%、50%、 75%、90%、95%分位数 这里勾选“描述性”,单击【继续】返回,单击 【绘制】,勾选“茎叶图”和箱图,即保持默认选 项,【继续】后返回,最后点击【确定】 结果显示,案例共有1963个,有效率是100%,缺 失率是0%;表格列出了均值、中位数、方差等统 计量,统计量偏度为1.371表示数据右偏,峰度大 于0,表现出“尖峰拖尾”的特性。
3.2 度量型变量的描述性统计分析
度量型变量的性质很好,最适合做统计分 析,与前两种变量相比,针对度量型变量的 统计方法要丰富的多。 首先来学习度量型数据描述性统计分析时 常用的几个统计量。
度量型变量的特点可以归纳为:
变量的取值可以是有限或无限个,可以是离
散取值,也可以是连续取值;变量的大小不 仅表示顺序,而且取值的差表示两个变量的 距离;不同的差距是可以比较的。
如果n是偶数,中位数为按从小到大的顺序,取中间
那两个数的平均数。 ③众数(mode): 是指变量值中出现频数最多的那个取值,三种类型 的变量都可以计算众数,众数可能不止一个,也可 能没有。 例如,调查10个学生的成绩,分别是: 69,72,84,75,84,75,74,89,90,75 众数是75
SPSS统计分析—描述性统计分析

SPSS统计分析—描述性统计分析描述性统计分析(Descriptive statistics analysis)简介描述性统计分析是统计学的一个领域,主要目的是通过对样本数据进行总结、整理和分析,揭示数据中的模式、趋势和关联。
它可以通过计算和展示各种统计指标来帮助我们更好地理解和解释数据。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,可以用于进行各种描述性统计分析。
本文将介绍一些常用的描述性统计分析方法和在SPSS中的应用。
1.数据摘要数据摘要是描述性统计分析的基础,主要目的是对数据进行概括性的总结。
常用的数据摘要方法包括计数、频数、百分比、均值、中位数、标准差等。
在SPSS中,可以使用“Frequencies”命令对数据进行频数分析。
该命令可以列出每个变量的频数、百分比以及累积百分比。
此外,使用“Descriptives”命令可以计算各个变量的均值、中位数、标准差等统计量。
2.绘制图表图表可以帮助我们更好地理解和展示数据的特征和分布。
常用的图表包括直方图、饼图、箱线图等。
在SPSS中,可以使用“Graphs”菜单下的不同选项来绘制各种图表。
例如,使用“Bar Chart”选项可以绘制柱状图,使用“Pie Chart”选项可以绘制饼图,使用“Boxplot”选项可以绘制箱线图。
3.相关分析相关分析可以帮助我们研究数据之间的关联关系。
它可以通过计算相关系数来评估两个变量之间的线性关系。
在SPSS中,可以使用“Correlations”命令进行相关分析。
该命令可以计算出各个变量之间的相关系数,并提供了相关系数矩阵和散点图来展示结果。
4.因素分析因素分析是一种常用的数据降维方法,可以帮助我们理解并提取潜在的数据结构和变量之间的关系。
在SPSS中,可以使用“Factor Analysis”命令进行因素分析。
该命令可以根据指定的变量,自动提取主成分或因子,并计算出因子载荷矩阵和因子得分。
SPSS数据分析—描述性统计分析

描述性统计分析是针对数据本身而言,用统计学指标描述其特征的分析方法,这种描述看似简单,实际上却是很多高级分析的基础工作,很多高级分析方法对于数据都有一定的假设和适用条件,这些都可以通过描述性统计分析加以判断,我们也会发现,很多分析方法的结果中,或多或少都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三大内容:1.集中趋势2.离散趋势3.数据分布情况描述集中趋势的指标有均值、众数、中位数,其中均值包括截尾均值、几何均值、调和均值等。
描述离散趋势的指标有频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数、变异系数等。
注意:连续型变量和离散型变量的指标有所不同。
由于很多统计分析都有一个正态分布的假设,因此我们经常也会关注数据的分布特征,常用峰度系数和偏度系数来描述数据偏离正态分布的程度,也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值SPSS用于描述性统计分析的过程大部分都在分析—描述统计菜单中,另有一个在比较均值—均值菜单,虽然这几个过程用途不同,但是基本上都可以输出常用的指标结果。
一、分析—描述统计—频率此过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值,此外,该过程最主要的作用是输出频数表,结果举例如下:二、分析—描述统计—描述看起来似乎这个过程才是正统的描述统计分析过程,实际上该过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
三、分析—描述统计—探索探索性分析是对原有数据进行描述性统计的基础上,更进一步的描述数据,和前两种过程相比,它能提供更详细的结果。
四、分析—描述统计—比率该过程主要用于对两个连续变量间的比率进行描述分析输出的结果比较简单,只是指标的汇总表格,在此略去五、分析—描述统计—交叉表分类变量的描述性统计比较简单,主要就是看频数分布和构成比,基本用交叉表一个过程就可以完成,该过程虽然放在描述统计中,但是由于功能丰富,也经常被用来做列联表的推断分析。
在报告中使用SPSS进行描述性统计分析

在报告中使用SPSS进行描述性统计分析引言:描述性统计分析是统计学的基础分析方法之一,它可以通过数值和图表来描述数据的基本特征。
随着科学技术的发展,SPSS(Statistical Product and Service Solutions)软件成为了描述性统计分析的重要工具之一。
本文将探讨在报告中如何使用SPSS进行描述性统计分析,并列出以下六个标题进行详细论述。
一、数据收集与准备数据收集是进行描述性统计分析的首要步骤。
在报告中,我们需要明确数据的来源与采集方法,并进行相关数据的准备和清洗。
使用SPSS软件时,可以利用其提供的数据导入和数据清洗功能,例如删除重复数据、填补缺失值等。
二、数据的中心趋势测度中心趋势测度是描述数据分布的重要指标,主要包括均值、中位数和众数。
在报告中,我们可以通过SPSS软件计算得到这些指标,并通过文字描述和图表展示来展示数据的中心位置,帮助读者更好地理解数据的分布特征。
三、数据的离散程度测度离散程度测度反映了数据的离散程度,常用的指标包括标准差、方差和四分位数间距。
在报告中,我们可以使用SPSS软件计算得到这些指标,并通过文字描述和图表展示来揭示数据的离散程度,帮助读者了解数据的变异情况。
四、数据的分布形态测度分布形态是描述数据分布曲线的特征,常用的指标包括偏度和峰度。
在报告中,我们可以通过SPSS软件计算得到这些指标,并通过文字描述和图表展示来展示数据的分布形态,帮助读者理解数据是否服从特定的分布规律。
五、数据间的关系分析数据间的关系分析能够帮助我们了解变量之间的相关性。
在报告中,我们可以利用SPSS软件进行相关性分析,计算得到相关系数,并通过文字描述和图表展示来展示变量之间的关系。
此外,我们还可以使用SPSS软件进行回归分析和方差分析,探索更深入的变量之间的关系。
六、结果的可视化展示在报告中,除了通过文字描述,更加直观有效的方式是通过图表展示结果。
SPSS软件提供了多种图表类型供我们选择,包括柱状图、折线图、散点图等。
spss第四章,描述性统计分析。。
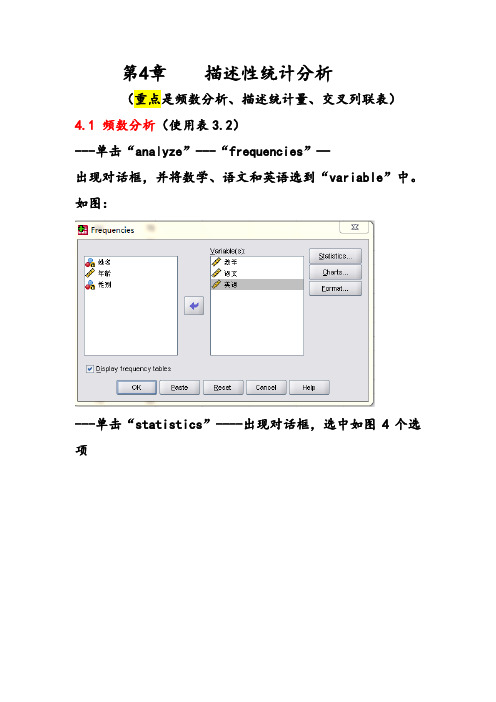
第4章描述性统计分析(重点是频数分析、描述统计量、交叉列联表)4.1 频数分析(使用表3.2)---单击“analyze”---“frequencies”—出现对话框,并将数学、语文和英语选到“variable”中。
如图:---单击“statistics”----出现对话框,选中如图4个选项-----单击“continue”回到前一对话框----单击“OK”结果如表4.1-----如图,重新选择语文---单击“charts”---得到一个对话框,如图选中2个选项----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.24.2 基本描述统计量(使用表3.2)---单击“analyze”---“descriptive statistics”—“Descriptives”---得到对话框,并将数据进行如图选入:-----单击“options”—得到对话框,并选中如图6个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.34.3 探索性分析(使用表3.2)---单击“analyze”---“descriptive statistics”—“Explore”---得到对话框,并将数据进行如图选入:----单击“Plots”—得到对话框,并选中如图4个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.6(与书有不同)4.4交叉列联表分析(使用表化环0708)(1)T ransform(修改)----Recode into Different variable----选定身高------点击“向右箭头”------在“name”下写个名字:eg:T1-------change-------(此处T1和T2是已经做好的分组)点击-----old and new values对其分组---例:Range LOWEST through values :160 new values :1Rang :160 through :170 2Range HIGHEST through values :170 3 点击continue-----回到前一个对话框点击------OK同样的方法做好T2---------点击“analyze(分析)”-----“Descriptive Statistics(描述性统计)”------“Crosstabs(交叉列联表)”选中行列------点击“Exat….“则弹出“exct tests(精确检测)对话框”点“Statistics…”则弹出“Crosstabs:statistics(交叉表统计)对话框”-------点击“Chi—square(卡方检验)”----“continue”点“Cells…”则弹出“Crosstabs:Cells display(交叉表统计)对话框”-------选择“Counts”中的“Observed”和“Expected”为期望频数,-------选择“Percentages”中的“Row”“Column”“Total”选项,分别计算“频数”“列频数”“总频数”-------选择“Residuals”中的“Standardized”分别计算单元格的非标准化残差、标准化残差、调整后的残差----“continue”回到前一页点----“OK”4.5比率分析(课本71页)不需要掌握英语未写完作业:1-10,11-25,26-30。
第讲SPSS描述性统计分析

第讲 SPSS 描述性统计分析1. 简介SPSS(Statistical Package for the Social Sciences)是一款功能强大的统计分析软件,在社会科学、医学和商业等领域中广泛应用。
本文将介绍 SPSS 中的描述性统计分析方法,帮助用户更好地理解和解读数据。
2. 描述性统计分析概述描述性统计分析是对数据进行和组织的过程。
它可以帮助人们更好地理解数据的特性和分布情况。
SPSS 中的描述性统计分析主要包括以下内容:2.1 中心趋势中心趋势是指数据在数轴上的中心位置。
SPSS 中常用的中心趋势指标包括:平均数、中位数和众数。
平均数是指所有数据的总和除以数据的个数。
它能够反映数据的总体水平,但会受到极端值的影响。
中位数是指数据按大小排序后位于中间位置的数值。
它能够反映数据的分布情况,不会受到极端值的影响。
众数是指出现次数最多的数值。
它能够反映数据的典型值,但在数据分布不均匀时可能不够准确。
2.2 离散程度离散程度是指数据相对于中心趋势的差异程度。
SPSS 中常用的离散程度指标包括:标准差、方差和极差。
标准差是指数据与平均数的差异程度的平均值。
它能够反映数据的分散程度,越大表示数据越分散。
方差是指数据与平均数的差异程度的平方的平均值。
它可以用来比较不同数据集的分散程度。
极差是指数据最大值和最小值之间的差异。
它不能反映数据的分布情况,但可以用来描述数据范围。
2.3 数据分布数据分布是指数据在数轴上的分布情况。
SPSS 中常用的数据分布指标包括:偏度、峰度和频数分布表。
偏度是指数据分布的不对称程度。
正偏态分布表示数据分布向左偏,负偏态分布表示数据分布向右偏。
峰度是指数据分布的峰度程度。
正态分布峰度值为 0,大于 0 表示峰度更高,小于 0 表示峰度更低,称为尖峰态和扁平态。
频数分布表是指数据中每个值出现的次数。
它可以用来了解数据的分布情况,如是否存在异常值或集中现象。
3. SPSS 描述性统计分析操作步骤SPSS 中的描述性统计分析可以通过以下步骤进行:Step 1:导入数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4、分布栏(Distribution)(复选项):峰度( Kurtosis)、偏度(Skewness)。
5、单击“图表”(Charts)按钮,打开“频率:
图表”(Frequencies:Charts)对话框,如图3-3
所示。
在该对话框中,用户可以选择频数分析的图表类型。 该对话框中各选项的具体意义如下: 1、图表类型(Chart Type)(单选项):无(None )(系统默认选项)、条形图(Bar charts)、饼形 图(Pie charts)、直方图(Histograms)。 如果选择输出“直方图”,可以选择是否在输出的直 方图中添加正态分布曲线。如果需要输出正态分布曲 线,则可勾选“带正态曲线”(With normal curve )复选框。
个分组变量的水平创建一个箱锁图,在每个箱锁图内用不 同的颜色区分不同因变量所对应的箱形单元,方便用户进 行比较。
“无(None)”:选择此项,不创建箱图。 “描述性(Descriptive)栏(复选项)”:选择该组内的选 项,可以生成茎叶图和(或)直方图。
“茎叶图(Stem-and-leaf,系统默认)”:茎叶图主要由3 个部分组成,即频率(Frequency)、茎(Stem)和叶(
“频率:图表”(Frequencies:Charts)对话框
在该对话框中,用户可以设置频率分布表的输出格式。对话框 中各选项的意义如下: 1、排序方式(Order by)栏:单选项组,用户可以选择频数 分布表中数值及其对应频率的排列顺序。
按值的升序排序(Ascending values):系统默认选项,频数 分布表中将按照数值从小到大排列。
IBM-SPSS
第3章 统计描述分析
描述性统计分析是进行其他统计分析的基础 和前提。在描述性分析中,通过各种统计图表及数 字特征量可以对样本来自的总体特征有比较准确的 把握,从而选择正确的统计推断方法。
主要内容
1:频数分布分析(Frequencies)
2:描述性统计分析(Descriptives)
“伸展与级别Levene检验(Spread vs level with Levene
Test)栏(单选项组)”:对所有的展布-水平图进行方差齐
性检验和数据转换,同时输出回归直线的斜率及方差齐性的 Levene检验,但如果没有指定分组变量,则此选项无效。
探索性分析的选项对话框
在该对话框中,可选择缺失值的处理方式,SPSS提供了3 种处理方式: “按列表排除个案(Exclude cases listwise,系统默认) ”:选择此项,对所有的分析过程剔除分组变量和因变量 中所有带有缺失值的观测量数据; “按对排除个案(Exclude cases pairwise)”:同时剔除 带缺失值的观测量及与缺失值有成对关系的观测量。在当 前分析过程中用到的变量数据中剔除带有缺失值的观测量 数据,在其他分析过程中可能包含缺失值; “报告值(Report values)”:选择此项,将分组变量的 缺失值单独分为一组,在输出频数表的同时输出缺失值。
实例讲解
例3.1:从某单位职工体检资料中获得101名正 常成年女子的血清总胆固醇 (mmol/L)的测量 结果;见“胆固醇.sav” 。
第二节
spss 描述性统计分析
一、基本概念 描述性统计分析主要用以计算描述集中趋势和
离散趋势的各种统计量,此外还有一个重要功能是
对变量做标准化变换,即Z变换。
Mean):用户还可输入数值指定均值的置信区间
的置信度,系统默认的置信度为95%。
“M-估计量(M-estimators)”:选择此项,将计 算并生成稳健估计量。M估计在计算时对所有观测 量赋予权重,随观测量距分布中心的远近而变化, 通过给远离中心值的数据赋予较小的权重来减小异 常值的影响。 “界外值(Outliers)”:选择此项,将输出分析 数据中的5个最大值和5个最小值作为异常嫌疑值。 “百分位数(Percentiles)”:选择此项,将计算 并显示指定的百分位数,包括5%、10%、25%、 50%、75%、90%和95%等。
Leaf),在图中按从左到右的顺序依次排列,在图的底端,
注明了茎的宽(Stem Width)和每一叶所代表的观测量数( Each Leaf)。图3-13为本例分析结果之一。本例茎宽10, 每片叶子代表一例。
“直方图(Histogram)”:直接绘制直方图 “带检验的正态图(Normality plots with test,复选框)”: 选择此项,将进行正态性检验,并生成正态Q-Q概率图和无 趋势正态Q-Q概率图。
2、图表值(Chart Values)(单选项组):可选 择图形中分类值的表现形式。 频率(Frequencies):如果图表类型是直方图, 则直方图的纵轴为频数;如果图表类型是饼形图, 则饼形图中每块表示属于该组观测值的频数。 百分比(Percentage):如果图表类型是直方图, 则直方图的纵轴为百分比;如果图表类型是饼形图 ,则饼形图中每块表示该组的观测量数占总数的百 分比。
模块解读
描述性统计分析对话框
描述性统计分析选项对话框
实例讲解
例3.2:分析不同性别演员获得奥斯卡的年龄差 异性;见“演员.sav” .
第三节
SPSS探索性分析
一、基本概念 探索分析是在对数据的基本特征统计量有初步
了解的基础上,对数据进行的更为深入详细的描述
性观察分析。它在一般描述性统计指标的基础上, 增加了有关数据其他特征的文字与图形描述,显得 更加细致与全面,有助于用户思考对数据进行进一 步分析的方案。
实例讲解
例3.3:分析中国南北城市的温度差异;见“南北 差异温度.sav” .
THE
END
1、百分位值(Percentile Values)栏为复选项,在此栏中可 选择多项。 四分位数(Quartile) 割点(Cut points):选择此项,在后面的文本框中输入数值 ,假设为N(N为在2 100之间的整数),则计算并显示N分 位数。 百分位数(Percentile(s)):选择此项,在后面的文本框中输 入数值,可以有选择地显示百分位数。在文本框中可以输入0 到100之间的数,输入后,单击“添加”(Add)按钮,将对 应的百分位数添加到方框内的列表框中,利用“更改”( Change)按钮和“删除”(Remove)按钮,可以对列表框 中的选项进行修改和删除。
3:探索性分析(Explore)
第一节
SPSS频数分布分析
一、基本概念
频数分布分析主要通过频数分布表、条图和直 方图,以及集中趋势和离散趋势的各种统计量,描 述数据的分布特征。
模块解读
“频率”(Frequencies)主对话框
统计量”(Frequencies:Statistics)对话框
按值的降序排序(Descending values):频数分布表中将按 照数值从大到小排列。 按计数的升序排序(Ascending counts):频数分布表中将按 照计数从小到大排列。
按计数的降序排序(Descending counts):频数分布表中将 按照计数从大到小排列。
2、多个变量(Multiple Variables)栏:单选项组 ,当“频率(Frequencies)”主对话框的“变量 ”(Variable(s))列表框中有多个变量时,利用“ 多个变量”栏可以设置表格的显示方式。
统计图对话框
“箱图(Boxplots)栏(单选项组)”:箱图,又称箱锁图 。
“按因子水平分组(Factor levels together,系统默认)” :选择此项,将为每个因变量创建一个箱锁图,在每个箱 锁图内根据分组变量的不同水平的取值创建箱形单元。
“不分组(Dependents together)”:选择此项,将为每
比较变量(Compare variables):系统默认选项 ,SPSS将所有变量的描述统计的结果显示在同一 张表格中,方便用户进行比较分析。
按变量组织输出(Organize output by variable) :SPSS将对应每个变量分别输出单独的描述统计 表格。
“频率:格式”(Frequencies:Format)对话框
模块解读
探索性分析主对话框
统计量对话框
ቤተ መጻሕፍቲ ባይዱ
“描述性(Descriptives)”:选择此项,将生成
描述性统计表格。表中显示样本数据的描述统计量
,包括平均值、中位数、5%调整平均数、标准误
、方差、标准差、最大值、最小值、组距、四分位
数、峰度、偏度及峰度和偏度的标准误。
“均值的置信区间”(Confidence Interval for
二、探索性分析有以下几个目的: 1.对数据进行初步检查,判断有无离群点和极端值。
2.对前提条件假设,如正态分布和方差齐性进行检查
,不满足正态分布和方差齐性时,提示数据转换方法
,最后决定使用参数方法或非参数方法。
3.了解组间差异的特征。
探索分析是在对数据的基本特征统计量有 初步了解的基础上,对数据进行的更为深入详 细的描述性观察分析。它在一般描述性统计指 标的基础上,增加了有关数据其他特征的文字 与图形描述,显得更加细致与全面,有助于用 户思考对数据进行进一步分析的方案。
2、离散(Dispersion)栏(复选项): 标准差(Std Deviation) 最小值(Minimum) 方差(Variance) 最大值(Maximum)