多重共线性与虚拟变量
多重共线性

解决方法
解决方法
(1)排除引起共线性的变量 找出引起多重共线性的解释变量,将它排除出去,以逐步回归法得到最广泛的应用。 (2)差分法 时间序列数据、线性模型:将原模型变换为差分模型。 (3)减小参数估计量的方差:岭回归法(Ridge Regression)。 (4)简单相关系数检验法
谢谢观看
简介
简介
对线性回归模型 基本假设之一是自变量,之间不存在严格的线性关系。如不然,则会对回归参数估计带来严重影响。为了说 明这一点,首先来计算线性回归模型参数的 LS估计的均方误差。为此。重写线性回归模型的矩阵形式为 其中服从多元正态分布,设计矩阵 X是的,且秩为 p。这时,参数的 LS估计为,而回归系数的 LS估计为。 注意到由此获得的 LS估计是无偏的,于是估计的均方误差为 其中是的特征根。显然,如果至少有一个特征根非常接近于零,则就很大,也就不再是的一个好的估计。由 线性代数的理论知道,若矩阵的某个特质根接近零,就意味着矩阵 X的列向量之间存在近似线性关系。 如果存在一组不全为零的数,使得 则称线性回归模型存在完全共线性;如果还存在随机误差 v,满足,使得 则称线性回归模型存在非完全共线性。 如果线性回归模型存在完全共线性,则回归系数的 LS估计不存在,因此,在线性回归分析中所谈的共线性 主要是非完全共线性,也称为复共线性。判断复共线性及其严重程度的方法主要有特征分析法(analysis of eigenvalue),条件数法 (conditional numbers)和方差扩大因子法(variance inflation factor)。
产生原因
产生原因
主要有3个方面: (1)经济变量相关的共同趋势 (2)滞后变量的引入 (3)样本资料的限制
影响
影响
多重共线性PPT课件

协方差同理。
方差膨胀因子(variance-inflating factor, VIF)
1 VIF 1 r223
所以 var b2
2
x22i VIF
2-21
8.5 多重共线性的诊断
在任一给定的情况下,特别是在涉及多于两 个解释变量的模型中,我们怎么知道有没有 共线性?
2-22
1.多重共线性是一个程度问题而不是有无问 题。有意义的区分不在于有无之间,而在于 程度大小。
因为 数。
b2 b3 是一个方程,却有两个未知
对给定的alpha和lamda值,有无穷多个解。
2-15
出现“高度”但“不完全”多重共线性 时的估计问题
仍以上述三变量回归模型为例。 假定 X3i X 2i vi ,其中 vi x2i 0
回归系数估计:
b2
yi x2i 2 x22i vi2
yi x2i
第8章 多重共线性:解释变量
相关会有什么后果?
McGraw-Hill/Irwin
Copyright © 2006 The McGraw-Hill Companies, Inc. All rights reserved.
问题
多重共线性的性质是什么? 多重共线性是否是一个严重的问题? 多重共线性的理论后果是什么? 多重共线性的实际后果是什么? 实践中如何诊断多重共线性? 消除多重共线性的补救措施有哪些?
但在应用计量经济学中,我们的宗旨就是区 分每个变量的单独影响。
2-13
把 X3i yi
X 2i 代入回归方程: b2 x2i b3 x2i ei b2 b3 x2i ei
x2i ei
利用OLS公式得:
b2 b3
x2i yi x22i
计量经济学07计量多重共线性

Y/C1 △ Y
0.6072 0.6028 0.5996 0.5613 0.5339 0.5697
588 587 1088 1628 1441
0.5552 1651 0.5067 2920
0.5684 1762 0.5762 1854 0.5339 2960 0.5083 4584 0.4624 8637 0.4284 12610 0.4581 12294 0.5041 9093
横截面数据:生产函数中,资本投入与劳动力投入往 往出现高度相关情况,大企业二者都大,小企业都小。
(2)滞后变量的引入
在经济计量模型中,往往需要引入滞后经济变量来 反映真实的经济关系。例如消费变动的影响因素不仅有 本期可支配收入,还应考虑以往各期的可支配收入;固 定资产存量变动的影响因素不仅有本期投资,还应考虑 以往若干期的投资。同一变量的前后期之值很可能有较 强的线性相关性,模型中引入了滞后变量,多重共线性 就难以避免。
第七章 多重共线性
(Multicollinearity)
一、多重共线性的概念 二、实际经济问题中的多重共线性 三、多重共线性的后果 四、多重共线性的检验 五、克服多重共线性的方法 六、案例
一、多重共线性的概念
对于模型
Yi= 0+ 1X1i+ 2X2i+ + kXki+ i
i=1,2,…,n 其基本假设之一是解释变量是互相独立的。
求出X1与X2的简单相关系数r,若|r|接近1,则说明两变量 存在较强的多重共线性。
(2) 对多个解释变量的模型,采用综合统计检验法
若 在OLS法下:R2与F值较大,但t检验值较小,说明各 解释变量对Y的联合线性作用显著,但各解释变量间存在共 线性而使得它们对Y的独立作用不能分辨,故t检验不显著。
多重共线性检验方法

多重共线性检验方法多重共线性是多元回归分析中常见的问题,指的是自变量之间存在高度相关性,导致回归系数估计不准确甚至失真。
在实际应用中,多重共线性可能会对模型的解释能力和预测能力造成严重影响,因此需要采取相应的检验方法来识别和应对多重共线性问题。
一、多重共线性的影响。
多重共线性会导致回归系数估计不准确,增大回归系数的标准误,降低统计推断的准确性。
此外,多重共线性还会使得模型的解释能力下降,使得模型对自变量的解释变得模糊不清,降低模型的预测能力。
因此,识别和解决多重共线性问题对于保证模型的准确性和稳定性至关重要。
二、多重共线性的检验方法。
1. 方差膨胀因子(VIF)。
方差膨胀因子是一种常用的多重共线性检验方法,它通过计算每个自变量的方差膨胀因子来判断自变量之间是否存在多重共线性。
通常情况下,方差膨胀因子大于10时,就表明存在严重的多重共线性问题。
2. 特征值检验。
特征值检验是通过计算自变量矩阵的特征值来判断自变量之间是否存在多重共线性。
当特征值接近0或者为0时,就表明存在多重共线性问题。
3. 条件数(Condition Number)。
条件数是通过计算自变量矩阵的条件数来判断自变量之间是否存在多重共线性。
通常情况下,条件数大于30就表明存在多重共线性问题。
4. 相关系数和散点图。
通过计算自变量之间的相关系数和绘制散点图来初步判断自变量之间是否存在多重共线性。
当自变量之间存在高度相关性时,就可能存在多重共线性问题。
三、处理多重共线性的方法。
1. 剔除相关性较强的自变量。
当自变量之间存在高度相关性时,可以考虑剔除其中一个或者几个相关性较强的自变量,以减轻多重共线性的影响。
2. 主成分回归分析。
主成分回归分析是一种处理多重共线性的方法,它通过将自变量进行主成分变换,从而降低自变量之间的相关性,减轻多重共线性的影响。
3. 岭回归和套索回归。
岭回归和套索回归是一种通过对回归系数进行惩罚来减轻多重共线性影响的方法,通过引入惩罚项,可以有效地缩小回归系数的估计值,减轻多重共线性的影响。
多重共线性与虚拟变量

多重共线性以下是美国1971-1986年间的年数据。
其中,y为售出新客车的数量(千辆);x1为新车,消费者价格指数,1967=100;x2为所有物品所有居民的消费者价格指数,1967=100;x3为个人可支配收入(PDI,10亿美元);x4为利率;x5为城市就业劳动力(千人)。
考虑下面的客车需求函数:Lny=b0+b1lnx1+b2lnx2+b3lnx3+b4lnx4+b5lnx5+u(1)用OLS法估计样本回归方程。
(2)如果模型存在多重共线性,试估计各辅助回归方程,并找出哪些变量是高度共线性的。
(3)如果存在严重的共线性,你会剔除哪一个变量,为什么?(4)在剔除一个或多个解释变量后,最终的客车需求函数是什么?这个模型在哪些方面好于包括所有解释变量的原始模型?(5)你认为还有哪些变量可以更好地解释美国的汽车需求?美国人个可支配收入与储蓄模型(EP129.wf1)问题描述:研究1970~1995年间美国个人可支配收入与个人储蓄的关系。
在1982年,美国遭受到和平时期最严重的经济衰退,当年的城市失业率高达9.7%,是自1948年以来失业率最高的一年。
这种事件会扰乱收入和储蓄之间的关系,现考察这种情况是否会发生。
美国个人可支配收入与个人储蓄数据思考:实际上是对模型稳定性的检验,除了用CHOW 检验,也可用虚拟变量模型进行判断。
1.构造虚拟变量{110 1982 1982D =年以后年及以前2.建立虚拟变量模型在命令窗口输入LS saving c d1 income income*d1,执行后会发现income*d1的系数不显著,可以将其剔除,再次进行LS saving c d1 income ,则发现d1的系数是显著的,因此1982年的事件对美国个人可支配收入与个人储蓄的关系有显著的影响,原模型不具有稳定性。
也可以做分段线性回归,在命令窗口输入LS saving c income (income -2374.3)*d1,执行后也会发现(income -2374.3)*d1的系数显著不为零,可以得到同样的结论。
计量经济学名词解释与简答

1、完全共线性:对于多元线性回归模型,其基本假设之一是解释变量1x ,2x ,…,k x 是相互独立的,如果存在02211=+++ki k i i x c x c x c ,i=1,2,…,n ,其中c 不全为0,即某一个解释变量可以用其他解释变量的线性组合表示,则称为完全共线性。
2、虚假序列相关:由于随机干扰项的序列相关往往是在模型设定中遗漏了重要的解释变量或对模型的函数形式设定有误时而导致的序列相关。
3、残差项:是指对每个样本点,样本观测值与模型估计值之间的差值。
4、多重共线性:在经典回归模型中总是假设解释变量之间是相互独立的。
如果某两个或多个解释变量之间出现了相关性,则称为多重共线性。
5、无偏性:是指参数估计量的均值(期望)等于模型的参数值。
6、工具变量:是在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量的变量。
7、结构分析:经济学中所说的结构分析是指对经济现象中变量之间关系的研究。
8、虚假回归(伪回归):如果两列时间序列数据表现出一致的变化趋势(非平稳),即它们之间没有任何经济关系,但进行回归也会表现出较高的可决系数。
9、异方差性:即相对于不同的样本点,也就是相对于不同的解释变量观测值,随机干扰项具有不同的方差。
10、计量经济学:它是经济学的一个分支学科,以揭示经济活动中客观存在的数量关系为内容的分支学科。
11、计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。
12、截面数据:是一批发生在同一时间截面上的数据。
13、回归分析:是研究一个变量关于另一个(些)变量的依赖关系的计算方法和理论,其目的在于通过后者的已知和设定值,去估计和(或)预测前者的(总体)均值。
14、随机误差项:观察值围绕它的期望值的离差就是随机误差项。
15、最佳线性无偏估计量(高斯-马尔可夫定理):普通最小二乘估计量具有线性性、无偏性和有效性等优良性质,是最佳线性无偏估计量,这就是著名的高斯-马尔可夫定理。
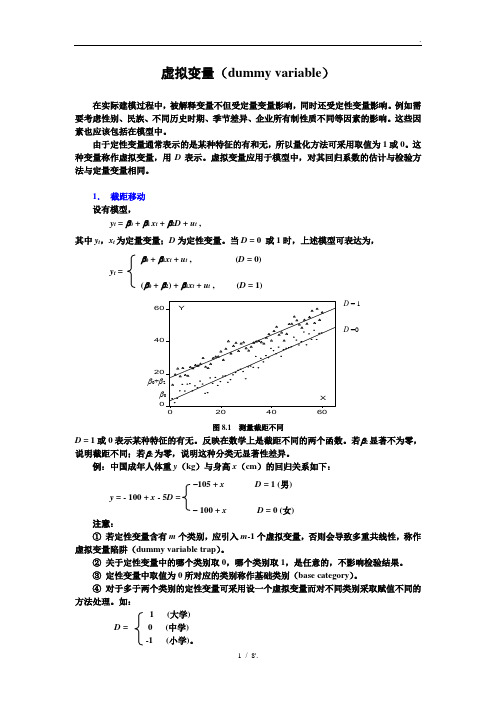
虚拟变量(dummy variable)
1(1978 - 1984)
中国进出口贸易总额数据(1950-1984)(单位:百亿元人民币)
年
trade
T
D
T*D
年
trade
T
D
T*D
1950
0.415
1
0
0
1968
1.085
19
0
0
1951
0.595
2
0
0
1969
1.069
20
0
0
1952
0.646
3
0
0
1970
1.129
21
0
0
1953
1(第2季度)
D2=
0(其他季度)
1(第3季度)
D3=
0(其他季度)
1(第4季度)
D4=
0(其他季度)
1(1998:1~2002:4)
DT=
0(1990:1~1997:4)
得估计结果如下:
GDPt= 1.1573+0.0668t+0.0775D2+0.2098D3+0.2349D4+1.8338DT-0.0654DTt
(50.8)(64.6) (3.7)(9.9) (11.0)(19.9) (-28.0)
R2=0.99, DW=0.9,s.e.=0.05, F=1198.4,T=52,t0.05 (52-7)= 2.01
对于1990:1~1997:4
GDPt= 1.1573+0.0668t+0.0775D2+0.2098D3+0.2349D4
首先看天津市粮食市场小麦批发价格的变化情况(图1)。1995年初,天津市粮食市场的小麦批发价格首先放开。在经历5个月的上扬之后,进入平稳波动期。从1996年8月份开始小麦批发价格一路走低。至2002年12月份,小麦批发价格降至是1160元/吨。
计量经济学名词解释

名词解释:1、计量经济学:是以经济理论和经济数据的事实为依据,运用数学、统计学的方法,借助计算机为辅助工具,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
2、虚拟变量数据:是人为构造的,用来表征政策等定性事实的数据。
3.回归平方和:用ESS 表示,是被解释变量的样本估计值与其平均值的离差平方和。
4、拟和优度检验:指检验模型对样本观测值的拟合程度,用2R 表示,该值越接 近1,模型对样本观测值拟合得越好。
5、偏回归系数:在多元线性回归模型中,回归系数j β(j=1,2,……,k )表示的是当控制其他解释变量不变的条件下,第j 个解释变量的单位变动对被解释变量平均值的影响,这样的回归系数称为偏回归系数。
6. 多重可决系数:“回归平方和”与“总离差平方和”的比值,用2R 表示。
7、修正的可决系数:用自由度修正多重可决系数2R 中的残差平方和与回归平方和。
8、回归方程的显著性检验(F 检验):对模型中被解释变量与所有解释变量之间的线性关系在总体上是否显著做出推断。
9、回归参数的显著性检验(t 检验):当其他解释变量不变时,某个回归系数对应的解释变量是否对被解释变量有显著影响做出推断。
10、正规方程组:指采用OLS 法估计线性回归模型时,对残差平方和关于各参数求偏导,并令偏导数为零后得到的一组方程,其矩阵形式为X X X Y β''= 。
11、多重共线性: 解释变量之间精确的线性关系和解释变量之间近似的线性关系。
12、完全的多重共线性: 解释变量的数据矩阵中,至少有一个列向量可以用其余的列向量线性表示。
13、辅助回归: 多元线性回归模型,分别以每个解释变量为被解释变量,做对其他解释变量的回归。
14、方差扩大因子VIF j: 1除以(1-多重可决系数的平方),决定了方差和协方差增大的速度。
15、逐步回归法: 将变量逐个的引入模型,每引入一个解释变量后,都要进行F 检验,并对已经选入的解释变量逐个进行t 检验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多重共线性
以下是美国1971-1986年间的年数据。
其中,y为售出新客车的数量(千辆);x1为新车,消费者价格指数,1967=100;x2为所有物品所有居民的消费者价格指数,1967=100;x3为个人可支配收入(PDI,10亿美元);x4为利率;x5为城市就业劳动力(千人)。
考虑下面的客车需求函数:
Lny=b0+b1lnx1+b2lnx2+b3lnx3+b4lnx4+b5lnx5+u
(1)用OLS法估计样本回归方程。
(2)如果模型存在多重共线性,试估计各辅助回归方程,并找出哪些变量是高度共线性的。
(3)如果存在严重的共线性,你会剔除哪一个变量,为什么?
(4)在剔除一个或多个解释变量后,最终的客车需求函数是什么?这个模型在哪些方面好于包括所有解释变量的原始模型?
(5)你认为还有哪些变量可以更好地解释美国的汽车需求?
美国人个可支配收入与储蓄模型(EP129.wf1)
问题描述:研究1970~1995年间美国个人可支配收入与个人储蓄的关系。
在1982年,美国遭受到和平时期最严重的经济衰退,当年的城市失业率高达9.7%,是自1948年以来失业率最高的一年。
这种事件会扰乱收入和储蓄之间的关系,现考察这种情况是否会发生。
美国个人可支配收入与个人储蓄数据
思考:实际上是对模型稳定性的检验,除了用CHOW 检验,也可用虚拟变量模型进行判断。
1.构造虚拟变量
{
110 1982 1982D =
年以后
年及以前
2.建立虚拟变量模型
在命令窗口输入LS saving c d1 income income*d1,执行后会发现income*d1的系数不显著,可以将其剔除,再次进行LS saving c d1 income ,则发现d1的系数是显著的,因此1982年的事件对美国个人可支配收入与个人储蓄的关系有显著的影响,原模型不具有稳定性。
也可以做分段线性回归,在命令窗口输入LS saving c income (income -2374.3)*d1,执行后也会发现(income -2374.3)*d1的系数显著不为零,可以得到同样的结论。
实验:虚拟变量模型
下表给出1965-1970年美国制造业利润和销售额的季度数据。
1965-1970年美国制造业利润和销售额的季度数据
假定利润不仅与销售额有关,而且和季度因素有关。
要求:
①如果认为季度影响使利润平均值发生变异,应当如何引入虚拟变量?
②如果认为季度影响使利润对销售额的变化率发生变异,应当如何引入虚拟变量?
③如果认为上述两种情况都存在,又应当如何引入虚拟变量?
④对上述三种情况分别估计利润模型,进行对比分析。