多重共线性的检验与处理
多重共线性与自相关的检验与解决

5word 格式支持编辑,如有帮助欢迎下载支持。
2 算出来再进行回归即得到以下结果:
Model Summaryb
Model
Std. Error of the
R
R Square
Adjusted R Square
Estimate
Durbin-Watson
1
.993a
.987
.985
.29640
1.862
Model
1
Regression
Residual
综上所述,该模型不存在多重共线性但存在自相关,运用广义差分法解决自相 关后,模型的拟合程度有显著提升,得到优化的模型将更有利于帮助我们分析经济 问题。
实训 总结 分析
这次试验完成得比上次轻松了许多,因为使用软件的频率增加使得用起来更得 心应手。这次的问题是检验和解决模型的多重共线性和自相关,因为多重共线性比 自相关的影响程度更大,且对整个模型的变量个数都有影响,所以先检验和解决多 重共线性再检验和解决自相关。
首先对原始数据进行用普通最小二乘法进行大致的拟合,并选择 Linear Regression-Statistics-Collinearity diagnostics,即用膨胀因子法对原模型进行多重共 线性检验,结果如下:
Model Summary
Model 1
R .982a
R Square .965
Coefficient Correlationsa
Model
第三产业增长率
第一产业增长率
第二产业增长率
1
Correlations
第三产业增长率
1.000
多元回归分析中的多重共线性及其解决方法

多元回归分析中的多重共线性及其解决方法在多元回归分析中,多重共线性是一个常见的问题,特别是在自变量之间存在高度相关性的情况下。
多重共线性指的是自变量之间存在线性相关性,这会造成回归模型的稳定性和可靠性下降,使得解释变量的效果难以准确估计。
本文将介绍多重共线性的原因及其解决方法。
一、多重共线性的原因多重共线性常常发生在自变量之间存在高度相关性的情况下,其主要原因有以下几点:1. 样本数据的问题:样本数据中可能存在过多的冗余信息,或者样本数据的分布不均匀,导致变量之间的相关性增加。
2. 选择自变量的问题:在构建回归模型时,选择了过多具有相似解释作用的自变量,这会增加自变量之间的相关性。
3. 数据采集的问题:数据采集过程中可能存在误差或者不完整数据,导致变量之间的相关性增加。
二、多重共线性的影响多重共线性会对多元回归模型的解释变量产生不良影响,主要表现在以下几个方面:1. 回归系数的不稳定性:多重共线性使得回归系数的估计不稳定,难以准确反映各个自变量对因变量的影响。
2. 系数估计值的无效性:多重共线性会导致回归系数估计偏离其真实值,使得对因变量的解释变得不可靠。
3. 预测的不准确性:多重共线性使得模型的解释能力下降,导致对未知数据的预测不准确。
三、多重共线性的解决方法针对多重共线性问题,我们可以采取以下几种方法来解决:1. 剔除相关变量:通过计算自变量之间的相关系数,发现高度相关的变量,选择其中一个作为代表,将其他相关变量剔除。
2. 主成分分析:主成分分析是一种降维技术,可以通过线性变换将原始自变量转化为一组互不相关的主成分,从而降低多重共线性造成的影响。
3. 岭回归:岭回归是一种改良的最小二乘法估计方法,通过在回归模型中加入一个惩罚项,使得回归系数的估计更加稳定。
4. 方差膨胀因子(VIF):VIF可以用来检测自变量之间的相关性程度,若某个自变量的VIF值大于10,则表明该自变量存在较高的共线性,需要进行处理。
多重共线性实验报告
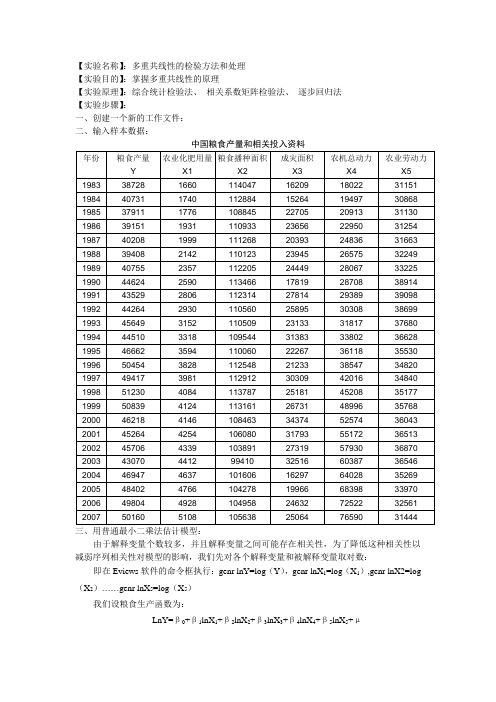
【实验名称】:多重共线性的检验方法和处理【实验目的】:掌握多重共线性的原理【实验原理】:综合统计检验法、相关系数矩阵检验法、逐步回归法【实验步骤】:一、创建一个新的工作文件:二、输入样本数据:三、用普通最小二乘法估计模型:由于解释变量个数较多,并且解释变量之间可能存在相关性,为了降低这种相关性以减弱序列相关性对模型的影响,我们先对各个解释变量和被解释变量取对数:即在Eviews软件的命令框执行:genr lnY=log(Y),genr lnX1=log(X1),genr lnX2=log (X2)……genr lnX5=log(X5)我们设粮食生产函数为:LnY=β0+β1lnX1+β2lnX2+β3lnX3+β4lnX4+β5lnX5+μ用运普通最小二乘法估计:下表给出了采用Eviews软件对表一的数据进行回归分析的统计结果:Dependent Variable: LNYMethod: Least SquaresDate: 12/19/13 Time: 10:05Sample: 1983 2007C -4.173174 1.923624 -2.169434 0.0429LNX1 0.381145 0.050242 7.586182 0.0000 LNX2 1.222289 0.135179 9.042030 0.0000 LNX3 -0.081110 0.015304 -5.300024 0.0000 LNX4 -0.047229 0.044767 -1.054980 0.3047R-squared 0.981597 Mean dependent var 10.70905 Adjusted R-squared 0.976753 S.D. dependent var 0.093396 S.E. of regression 0.014240 Akaike info criterion -5.459968 Sum squared resid 0.003853 Schwarz criterion -5.167438 Log likelihood 74.24960 F-statistic 202.6826 Durbin-Watson stat 1.791427 Prob(F-statistic) 0.000000根据上表估计出的参数,可以得到如下普通最小二乘法估计模型:lnY=‐4.17+0.381lnX1+1.222lnX2‐0.081lnX3‐0.047lnX4‐0.101lnX5四、模型检验:1、数学检验:由于R2为0.9816接近于一,且F=202.68>F0.05(5,9)=2.74,故认为粮食产量和上述解释变量之间的总体线性关系显著;但是就X4,X5来说,其t检验的参数较小,尚不能通过t检验,因此怀疑模型中存在多重共线性。
多重共线性检验方法

多重共线性检验方法多重共线性是指自变量之间存在高度相关性,导致回归模型估计的不稳定性和不准确性。
在实际的数据分析中,多重共线性经常会对回归分析结果产生严重影响,因此需要采用适当的方法来检验和解决多重共线性问题。
本文将介绍几种常用的多重共线性检验方法,帮助读者更好地理解和处理多重共线性问题。
1. 方差膨胀因子(VIF)。
方差膨胀因子是一种常用的多重共线性检验方法,它通过计算自变量的方差膨胀因子来判断自变量之间是否存在多重共线性。
方差膨胀因子的计算公式为,VIF = 1 / (1 R^2),其中R^2是自变量对其他自变量的线性相关性的度量,VIF越大表示自变量之间的共线性越严重。
一般来说,如果自变量的VIF大于10,就可以认为存在严重的多重共线性问题。
2. 特征值和条件指数。
特征值和条件指数是另一种常用的多重共线性检验方法,它们是通过对自变量之间的相关矩阵进行特征值分解得到的。
特征值表示了自变量之间的共线性程度,而条件指数则可以用来判断自变量之间的共线性是否严重。
一般来说,特征值大于1或条件指数大于30就表示存在严重的多重共线性问题。
3. Tolerance(容忍度)。
容忍度是一种用来判断自变量之间共线性的指标,它是方差膨胀因子的倒数。
一般来说,如果自变量的容忍度小于0.1,就可以认为存在严重的多重共线性问题。
4. 相关系数和散点图。
除了上述的定量方法,我们还可以通过观察自变量之间的相关系数和绘制散点图来判断是否存在多重共线性。
如果自变量之间的相关系数接近1或-1,或者在散点图中存在明显的线性关系,就可能存在多重共线性问题。
5. 多重共线性的解决方法。
一旦发现存在多重共线性问题,我们可以采取一些方法来解决。
例如,可以通过删除相关性较强的自变量、合并相关性较强的自变量、使用主成分分析等方法来减轻多重共线性的影响。
此外,还可以使用岭回归、套索回归等方法来处理多重共线性问题。
总之,多重共线性是回归分析中常见的问题,需要及时进行检验和处理。
多重共线性的四种检验方法

多重共线性的四种检验方法1. 协方差矩阵检验协方差矩阵检验是通过计算变量之间的协方差来检测变量之间是否存在多重共线性的一种方法。
当变量之间的协方差较大时,可以推断出变量之间存在多重共线性的可能。
另外,协方差矩阵检验还可以用来检测变量之间的相关性,以及变量之间的线性关系。
2. 因子分析检验因子分析检验是一种检验多重共线性的方法,它检验变量之间是否存在共同的共线性因子。
它通过对变量之间的相关性进行分析,以及对变量的因子负载度进行检验,来确定变量之间是否存在多重共线性。
因子分析检验可以帮助研究者识别变量之间的共同共线性因子,从而更好地理解数据的结构。
3. 相关系数检验相关系数检验是一种检验多重共线性的方法,它可以检测自变量之间的相关性。
它通过计算自变量之间的相关系数来检验,如果相关系数的绝对值较大,则可以认为存在多重共线性。
此外,相关系数检验还可以检测自变量与因变量之间的相关性,如果自变量与因变量之间的相关系数较大,则可以认为存在多重共线性。
方差分析检验:方差分析检验是一种检验多重共线性的有效方法,它可以用来检测自变量之间的关系。
它的思想是,如果自变量之间存在多重共线性,那么它们的方差应该会受到影响,而且这种影响会反映在回归系数上。
因此,方差分析检验的基本思想是,如果自变量之间存在多重共线性,那么它们的方差应该会受到影响,而且这种影响会反映在回归系数上。
为了检验这一点,可以使用方差分析检验,它可以用来检测自变量之间是否存在多重共线性。
5. 回归分析检验回归分析检验是一种用于检测多重共线性的方法,它可以用来确定变量之间是否存在多重共线性。
回归分析检验是通过比较模型的R-平方值和调整后的R-平方值来确定多重共线性存在的程度。
如果调整后的R-平方值明显低于R-平方值,则表明多重共线性存在。
另外,可以通过观察模型的拟合度来检测多重共线性。
如果拟合度较低,则可能存在多重共线性。
多重共线性检验方法

多重共线性检验方法多重共线性是多元回归分析中常见的问题,指的是自变量之间存在高度相关性,导致回归系数估计不准确甚至失真。
在实际应用中,多重共线性可能会对模型的解释能力和预测能力造成严重影响,因此需要采取相应的检验方法来识别和应对多重共线性问题。
一、多重共线性的影响。
多重共线性会导致回归系数估计不准确,增大回归系数的标准误,降低统计推断的准确性。
此外,多重共线性还会使得模型的解释能力下降,使得模型对自变量的解释变得模糊不清,降低模型的预测能力。
因此,识别和解决多重共线性问题对于保证模型的准确性和稳定性至关重要。
二、多重共线性的检验方法。
1. 方差膨胀因子(VIF)。
方差膨胀因子是一种常用的多重共线性检验方法,它通过计算每个自变量的方差膨胀因子来判断自变量之间是否存在多重共线性。
通常情况下,方差膨胀因子大于10时,就表明存在严重的多重共线性问题。
2. 特征值检验。
特征值检验是通过计算自变量矩阵的特征值来判断自变量之间是否存在多重共线性。
当特征值接近0或者为0时,就表明存在多重共线性问题。
3. 条件数(Condition Number)。
条件数是通过计算自变量矩阵的条件数来判断自变量之间是否存在多重共线性。
通常情况下,条件数大于30就表明存在多重共线性问题。
4. 相关系数和散点图。
通过计算自变量之间的相关系数和绘制散点图来初步判断自变量之间是否存在多重共线性。
当自变量之间存在高度相关性时,就可能存在多重共线性问题。
三、处理多重共线性的方法。
1. 剔除相关性较强的自变量。
当自变量之间存在高度相关性时,可以考虑剔除其中一个或者几个相关性较强的自变量,以减轻多重共线性的影响。
2. 主成分回归分析。
主成分回归分析是一种处理多重共线性的方法,它通过将自变量进行主成分变换,从而降低自变量之间的相关性,减轻多重共线性的影响。
3. 岭回归和套索回归。
岭回归和套索回归是一种通过对回归系数进行惩罚来减轻多重共线性影响的方法,通过引入惩罚项,可以有效地缩小回归系数的估计值,减轻多重共线性的影响。
关于多重共线性模型的检验和处理的方法

计量经济学实验报告题目:关于多重共线性模型的检验和处理方法姓名:张飞飞学号:2008163050专业:工商管理指导教师:崔海燕实验时间: 2010-12-22二○一○年十二月二十五日关于多重共线性模型的检验和处理的方法一、实验目的:掌握多重共线性模型检验和处理的方法二、实验原理:判定系数检验法、逐步回归法、解释变量、相关系数检验三、实验步骤:1.创建一个新的工作文件:打开Eviews软件,点击File下的New File,创建一个新的工作文件,选择Annual,在Start Date栏中输入1983,在End date栏中输入2000,点击OK,点击保存,完成创建新的工作文件。
2.输入数据:点击Quick下的Empty Group,导入中国粮食生产函数模型的具体数据,命名被解释变量为Y,解释变量为X1、X2、X3、X4、X5,其中:Y表示粮食产量;X1表示农业化肥施用量;X2表示粮食播种面积;X3表示成灾面积;X4表示农业机械总动力;X5表示农业劳动力.点击Name保存数据,命名为Group01。
3.采用普通最小二乘法估计模型参数:点击Quick下的Estimate Equation,输入方程y c x1 x2 x3 x4 x5.点击OK,生成EQ1. 如下表所示:从结果可以看出:R-squared的值为0.982798,拟合优度比较高(一般为0.9以上),F-statistic 的值为137.1164,也比较大,说明模型上存在多重共线性,但无法看出变量之间的关系。
4.进行多重共线性检验:主要运用综合统计检验和采用解释变量之间的相关系数进行检验。
由综合统计检验法(步骤3),可以看出存在多重共线性,继而进行解释变量之间的相关下系数检验。
点击Quick下的Groupstatistics,选择Correlations,打开Series List界面,输入X1 X2 X3 X3 X4 X5,点击OK,生成Group02,结果如下图:从结果可以看出:X1和X4之间的相关系数为0.960278,最接近1,说明X1和X4之间存在高度相关性。
什么是多重共线性如何进行多重共线性的检验

什么是多重共线性如何进行多重共线性的检验多重共线性是指在统计模型中,独立变量之间存在高度相关性或者线性依赖关系,从而给模型的解释和结果带来不确定性。
在回归分析中,多重共线性可能导致系数估计不准确、标准误差过大、模型的解释变得复杂等问题。
因此,对于多重共线性的检验和处理是非常重要的。
一、多重共线性的检验多重共线性的检验可以通过以下几种方式进行:1. 相关系数矩阵:可以通过计算独立变量之间的相关系数,判断它们之间的关系强度。
当相关系数超过0.8或-0.8时,可以视为存在高度相关性,即可能存在多重共线性问题。
2. 方差扩大因子(VIF):VIF是用来检验自变量之间是否存在共线性的指标。
计算每一个自变量的VIF值,当VIF值大于10或者更高时,可以视为存在多重共线性。
3. 条件数(Condition index):条件数也是一种用来检验多重共线性的指标。
它度量了回归矩阵的奇异性或者相对不稳定性。
当条件数超过30时,可以视为存在多重共线性。
4. 特征值(Eigenvalues):通过计算特征值,可以判断回归矩阵的奇异性。
如果存在特征值接近于零的情况,可能存在多重共线性。
以上是常用的多重共线性检验方法,可以根据实际情况选择合适的方法进行检验。
二、多重共线性的处理在检测到存在多重共线性问题后,可以采取以下几种方式进行处理:1. 去除相关性强的变量:在存在高度相关变量的情况下,可以选择去除其中一个或多个相关性较强的变量。
2. 聚合相关变量:将相关性强的变量进行加权平均,得到一个新的变量来替代原来的变量。
3. 主成分分析(PCA):主成分分析是一种降维技术,可以将相关性强的多个变量合并成为一个或多个无关的主成分。
4. 岭回归(Ridge Regression):岭回归是一种缓解多重共线性的方法,通过加入一个正则化项,来使得共线性变量的系数估计更加稳定。
5. Lasso回归(Lasso Regression):Lasso回归也是一种缓解多重共线性的方法,通过对系数进行稀疏化,来选择重要的变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验名称:多重共线性的检验与处理
实验时间:2011.12.10
实验要求:
主要是学习多重共线性的检验与处理,主要是研究解释变量与其余解释变量之间有严重多重共线性的模型,分析变量之间的相关系数。
通过具体案例建立模型,然后估计参数,求出相关的数据。
再对模型进行检验,看数据之间是否存在多重共线性。
最后利用所求出的模型来进行修正。
实验内容:
实例:我国钢材供应量分析
通过分析我国改革开放以来(1978-1997)钢材供应量的历史资料,可以建立一个单一方程模型。
根据理论及对现实情况的认识,影响我国钢材供应量 Y(万吨)的主要因素有:原油产量X1(万吨),生铁产量X2(万吨),原煤产量X3(万吨),电力产量X4(亿千瓦小时),固定资产投资X5(亿元),国内生产总值
X6(亿元),铁路运输量X7(万吨)。
(一)建立我国钢材供应量的计量经济模型:
(二)估计模型参数,结果为:
Dependent Variable: Y
Method: Least Squares
Date: 11/02/09 Time: 16:09
Sample: 1978 1997
Included observations: 20
Variable Coefficient Std. Error t-Statistic Prob.
C 139.2362 718.2493 0.193855 0.8495
X1 -0.051954 0.090753 -0.572483 0.5776
X2 0.127532 0.132466 0.962751 0.3547
X3 -24.29427 97.48792 -0.249203 0.8074
X4 0.863283 0.186798 4.621475 0.0006
X5 0.330914 0.105592 3.133889 0.0086
X6 -0.070015 0.025490 -2.746755 0.0177
X7 0.002305 0.019087 0.120780 0.9059
R-squared 0.999222 Mean dependent var 5153.350
Adjusted R-squared 0.998768 S.D. dependent var 2511.950
S.E. of regression 88.17626 Akaike info criterion 12.08573
Sum squared resid 93300.63 Schwarz criterion 12.48402
Log likelihood -112.8573 F-statistic 2201.081
Durbin-Watson stat 1.703427 Prob(F-statistic) 0.000000
由此可见,该模型可绝系数很高,F检验值2201.081,明显显著。
但当,系数的t检验不显著,而且系数的符号与预期的相反,这表明很可能存在严重的多重共线性。
(三)计算各解释变量的相关系数,选择数据,得相关系数矩阵(表3.1)。
表3.1 相关系数矩阵
X2 X3 X4 X5 X6 X7
X2 1.000000 0.964400 0.994921 0.969686 0.972530 0.931689
X3 0.964400 1.000000 0.974809 0.894963 0.913344 0.982943
X4 0.994921 0.974809 1.000000 0.959613 0.969105 0.945444
X5 0.969686 0.894963 0.959613 1.000000 0.996169 0.827643
X6 0.972530 0.913344 0.969105 0.996169 1.000000 0.846079
X7 0.931689 0.982943 0.945444 0.827643 0.846079 1.000000
由相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实确实存在严重多重共线性。
(四)修正多重共线性
采用逐步回归的办法,去检验和解决多重共线性问题。
分别做Y对的一元回归,结果如表3.2所示
表3.2 一元回归结果
变量
参数估计
量 1.181784 0.926212 926.7178 0.884047 0.572451 0.108665 0.106826
t统计
量 10.10629 57.82017 15.87243 62.49381 15.47892 16.54535 11.45524
0.850171 0.994645 0.933317 0.995412 0.930123 0.938303 0.879375
0.841847 0.994347 0.929612 0.995157 0.926241 0.934875 0.872673
其中,加入的方程最大,以为基础,顺次加入其他变量逐步回归,结果如表3.3所示。
表3.3 加入新变量的回归结果(一)
变量 X1 X2 X3 X4 X5 X6 X7
X4、X1 -0.074944
(-1.359593) 0.932329
(24.46548)
0.995375
X4、X2 0.429201
(3.895858) 0.476623
(4.534407) 0.997291
X4、X3 -125.0949
(-1.960538) 0.996689
(16.91041) 0.995818
X4X5 0.808630
(16.81022) 0.052646
(1.633786) 0.995568
X4、X6 0.858914
(14.63712)
0.003283
(0.441961) 0.994931
X4、X7 0.927639
21.44406
-0.005928
(-1.065860) 0.995194
经比较,新加入的方程 =0.997291,改进最大,而且各参数的t检验显著,选择保留 ,再加入其他新变量逐步回归,结果如表3.4所示:
表3.4 加入新变量的回归结果(二)
X1 X2 X3 X4 X5 X6 X7
X4、X2、X1 -0.052631
-1.255622 0.409652
3.742505 0.529087
4.745215 0.997380
X4、X2、X3 0.386819
3.559933 -81.25478
-1.604227 0.590021
4.800056 0.997521
在、基础上加入后的方程增大,但参数的t检验不显著,甚至的符号也变得不合理。
加入后的方程增大,但参数的t检验不显著,甚至的符号也变得不合理。
加入后的方程下降,而且参数的t检验不显著。
加入后的方程下降,而且参数的t检验不显著,甚至的符号也变得不合理。
加入后的方程下降,而且参数的t检验不显著,甚至的符号也变得不合理。
这说明、、、、引起严重多重共线性,应予剔除。
最后修正严重多重共线性影响的回归结果为:
t=(-3.179263) ( 3.895858) ( 4.534407)
F=3498.403 DW=0.864859
这说明,在其他因素不变的情况下,当生铁产量每增长1万吨,电力产量每增长1亿千瓦小时,钢材供应量将分别增长万吨和万吨。