多重共线性和虚拟变量的使用
虚拟变量实验报告感想

通过本次虚拟变量实验,我对虚拟变量有了更加深入的理解和认识,感受到了其在计量经济学中的重要作用。
以下是我对本次实验的一些感想。
一、虚拟变量的重要性虚拟变量在计量经济学中具有举足轻重的地位。
它可以将定性变量转化为定量变量,使模型更加全面地反映经济现象。
在现实生活中,许多因素都是定性因素,如性别、民族、地区等,这些因素无法直接用数值表示,但它们对经济现象的影响却是客观存在的。
虚拟变量恰好能够将这些定性因素纳入模型,使模型更加准确、全面地反映经济现象。
二、虚拟变量的设定在本次实验中,我们学习了如何设定虚拟变量。
首先,要明确虚拟变量的含义和作用,然后根据研究目的和实际数据情况,确定虚拟变量的个数。
需要注意的是,当定性变量含有m个类别时,应引入m-1个虚拟变量,以避免多重共线性问题。
此外,虚拟变量的取值应遵循互斥和完备的原则,即每个样本只能属于一个类别。
三、虚拟变量的估计与检验在本次实验中,我们运用Eviews软件对虚拟变量模型进行了估计和检验。
通过观察模型的回归结果,我们可以了解虚拟变量对因变量的影响程度。
此外,我们还可以通过t检验、F检验等方法对虚拟变量的显著性进行检验。
在检验过程中,要注意控制其他变量的影响,以确保检验结果的可靠性。
四、虚拟变量的应用虚拟变量在实际应用中非常广泛。
以下是一些常见的应用场景:1. 时间序列分析:在时间序列分析中,虚拟变量可以用来表示季节性、节假日等因素对经济现象的影响。
2. 州际差异分析:在分析不同地区经济现象时,可以引入地区虚拟变量,以反映地区间的差异。
3. 政策效应分析:在分析政策对经济现象的影响时,可以引入政策虚拟变量,以观察政策实施前后经济现象的变化。
4. 模型设定:在构建计量经济模型时,可以引入虚拟变量来表示定性因素,使模型更加全面。
五、实验收获通过本次虚拟变量实验,我收获颇丰。
首先,我掌握了虚拟变量的基本原理和操作方法,为今后的研究奠定了基础。
其次,我学会了如何设定虚拟变量、估计模型和检验结果,提高了自己的实践能力。
如何处理逻辑回归模型中的多重共线性

逻辑回归模型是一种常用的数据分析方法,它被广泛应用于分类问题的解决。
然而,在使用逻辑回归模型时,研究者常常面临一个问题,那就是多重共线性。
多重共线性是指自变量之间存在高度相关性的情况,这会导致模型的不稳定性和系数估计的不准确性。
因此,如何处理逻辑回归模型中的多重共线性成为了一个重要的问题。
首先,我们需要了解多重共线性对逻辑回归模型的影响。
多重共线性会导致模型的系数估计不准确,使得模型的解释能力下降。
此外,多重共线性还会增加模型的方差,使得模型的预测能力变差。
因此,处理逻辑回归模型中的多重共线性是至关重要的。
一种常用的处理多重共线性的方法是使用正则化技术。
正则化技术通过在目标函数中引入正则化项,对模型进行惩罚,从而减小模型的系数估计值。
常见的正则化方法包括L1正则化和L2正则化。
L1正则化通过在目标函数中加入自变量的绝对值之和,使得一些系数变为零,从而实现特征选择的作用。
L2正则化通过在目标函数中加入自变量的平方和,惩罚系数的绝对值,从而减小系数的估计值。
这两种方法可以有效地处理多重共线性问题,提高模型的稳定性和预测能力。
除了正则化技术,还可以使用主成分分析(PCA)等降维方法来处理多重共线性。
主成分分析是一种常用的数据降维技术,它通过线性变换将原始变量转换为一组新的主成分变量,从而减小变量之间的相关性。
通过主成分分析,我们可以将高度相关的自变量转换为一组新的无关的主成分变量,从而减小多重共线性的影响。
然后,我们可以使用这些主成分变量来构建逻辑回归模型,从而提高模型的稳定性和预测能力。
此外,还可以使用岭回归、套索回归等方法来处理多重共线性。
岭回归通过在目标函数中加入系数的平方和,减小系数的估计值,从而降低模型的方差。
套索回归通过在目标函数中加入系数的绝对值之和,实现特征选择的作用,从而减小模型的复杂度。
这些方法可以有效地处理多重共线性问题,提高模型的稳定性和预测能力。
综上所述,处理逻辑回归模型中的多重共线性是一个重要的问题。
计量经济学名词解释与简答

1、完全共线性:对于多元线性回归模型,其基本假设之一是解释变量1x ,2x ,…,k x 是相互独立的,如果存在02211=+++ki k i i x c x c x c ,i=1,2,…,n ,其中c 不全为0,即某一个解释变量可以用其他解释变量的线性组合表示,则称为完全共线性。
2、虚假序列相关:由于随机干扰项的序列相关往往是在模型设定中遗漏了重要的解释变量或对模型的函数形式设定有误时而导致的序列相关。
3、残差项:是指对每个样本点,样本观测值与模型估计值之间的差值。
4、多重共线性:在经典回归模型中总是假设解释变量之间是相互独立的。
如果某两个或多个解释变量之间出现了相关性,则称为多重共线性。
5、无偏性:是指参数估计量的均值(期望)等于模型的参数值。
6、工具变量:是在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量的变量。
7、结构分析:经济学中所说的结构分析是指对经济现象中变量之间关系的研究。
8、虚假回归(伪回归):如果两列时间序列数据表现出一致的变化趋势(非平稳),即它们之间没有任何经济关系,但进行回归也会表现出较高的可决系数。
9、异方差性:即相对于不同的样本点,也就是相对于不同的解释变量观测值,随机干扰项具有不同的方差。
10、计量经济学:它是经济学的一个分支学科,以揭示经济活动中客观存在的数量关系为内容的分支学科。
11、计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。
12、截面数据:是一批发生在同一时间截面上的数据。
13、回归分析:是研究一个变量关于另一个(些)变量的依赖关系的计算方法和理论,其目的在于通过后者的已知和设定值,去估计和(或)预测前者的(总体)均值。
14、随机误差项:观察值围绕它的期望值的离差就是随机误差项。
15、最佳线性无偏估计量(高斯-马尔可夫定理):普通最小二乘估计量具有线性性、无偏性和有效性等优良性质,是最佳线性无偏估计量,这就是著名的高斯-马尔可夫定理。
虚拟变量回归

数据收集
收集不同市场细分群体的基本信息和 产品需求数据,如年龄、性别、收入、 消费习惯等。
变量设置
将市场细分变量转换为虚拟变量,并 引入到回归模型中。
结果分析
分析虚拟变量的系数和显著性,解释 其对产品需求的影响,为市场定位提 供依据。
案例三:教育程度与收入水平的关系研究
目的
研究教育程度对收入水平的影响,以及 不同教育程度对收入水平的差异。
虚拟变量可能依赖于某些自变量,需 要谨慎处理以避免多重共线性问题。
REPORT
CATALOG
DATE
ANALYSIS
SUMMAR Y
03
虚拟变量回归的模型构 建
线性回归模型
线性回归模型是最常用的回归分析方法之一,用 于探索自变量与因变量之间的线性关系。
在线性回归模型中,虚拟变量可以作为自变量引 入,以解释和预测因变量的变化。
变量设置
将教育程度转换为虚拟变量,并引入 到回归模型中。
数据收集
收集受访者的教育程度和收入水平数 据。
结果分析
分析虚拟变量的系数和显著性,解释 其对收入水平的影响,为职业规划和 教育投资提供参考。
案例四:健康状况与生活习惯的关系研究
目的
数据收集
研究生活习惯对健康状况的影响,以及不 同生活习惯对健康状况的差异。
虚拟变量回归的应用场景
1 2
社会科学研究
在社会科学研究中,经常需要研究分类变量对连 续变量的影响。例如,研究不同教育程度或不同 职业对收入的影响。
生物统计学
在生物统计学中,虚拟变量回归可用于研究基因 型、物种或地理区域等因素对连续变量的影响。
3
市场分析
在市场分析中,虚拟变量回归可用于研究不同产 品类别、品牌或市场细分对销售或其他连续变量 的影响。
计量经济学第三章-回归模型的扩展

第二节 自相关性
一Байду номын сангаас自相关性的概念及其产生原因:
1.定义:随机误差项的各期值之间存在相关性 COV(t, s)0, ts
例:投资函数、生产函数
2.产生原因: 1)模型遗漏了自相关的解释变量; 2)模型函数形式的设定误差; 3)经济惯性; 4)随机因素影响; (注:自相关性更易产生于时序数据)
原理:辅助回归检验 命令:View\ResidualTest \SerialCorrelation LM
Test
四、自相关性的修正方法
1.利用广义差分变换消除自相关性:
步骤: 实质:GLS估计
2.的估计方法:
1)近似估计; 2)迭代估计;
3.Eviews软件的实现:
1)检验自相关性的阶数; 2)在LS命令中增加AR项;
二、异方差的影响
1.OLS估计不再是最佳估计量; 2.T检验可靠性降低; 3.增大预测误差; 三、异方差的检验 ★1.图形分析: (1)观察Y、X相关图:SCAT Y X (2)残差分析:观察回归方程的残差图
在方程窗口直接点击Residual按钮; 或:点击View\Actual,Fitted,Residual\Table
1. 调整季节波动
y a bx 1D1 2D2 3D3
2. 检验模型结构的稳定性(P141)
y a bx D XD
3. 混合回归
例8.教材P132
第五节 滞后变量模型
一、滞后效应与滞后变量的作用 1、产生滞后效应的原因:
1)心理因素:消费习惯、消费心理(如价格、利率) 2)技术原因:农民收入、农产品价格、天气条件 3)制度原因:
多重共线性与虚拟变量

多重共线性以下是美国1971-1986年间的年数据。
其中,y为售出新客车的数量(千辆);x1为新车,消费者价格指数,1967=100;x2为所有物品所有居民的消费者价格指数,1967=100;x3为个人可支配收入(PDI,10亿美元);x4为利率;x5为城市就业劳动力(千人)。
考虑下面的客车需求函数:Lny=b0+b1lnx1+b2lnx2+b3lnx3+b4lnx4+b5lnx5+u(1)用OLS法估计样本回归方程。
(2)如果模型存在多重共线性,试估计各辅助回归方程,并找出哪些变量是高度共线性的。
(3)如果存在严重的共线性,你会剔除哪一个变量,为什么?(4)在剔除一个或多个解释变量后,最终的客车需求函数是什么?这个模型在哪些方面好于包括所有解释变量的原始模型?(5)你认为还有哪些变量可以更好地解释美国的汽车需求?美国人个可支配收入与储蓄模型(EP129.wf1)问题描述:研究1970~1995年间美国个人可支配收入与个人储蓄的关系。
在1982年,美国遭受到和平时期最严重的经济衰退,当年的城市失业率高达9.7%,是自1948年以来失业率最高的一年。
这种事件会扰乱收入和储蓄之间的关系,现考察这种情况是否会发生。
美国个人可支配收入与个人储蓄数据思考:实际上是对模型稳定性的检验,除了用CHOW 检验,也可用虚拟变量模型进行判断。
1.构造虚拟变量{110 1982 1982D =年以后年及以前2.建立虚拟变量模型在命令窗口输入LS saving c d1 income income*d1,执行后会发现income*d1的系数不显著,可以将其剔除,再次进行LS saving c d1 income ,则发现d1的系数是显著的,因此1982年的事件对美国个人可支配收入与个人储蓄的关系有显著的影响,原模型不具有稳定性。
也可以做分段线性回归,在命令窗口输入LS saving c income (income -2374.3)*d1,执行后也会发现(income -2374.3)*d1的系数显著不为零,可以得到同样的结论。
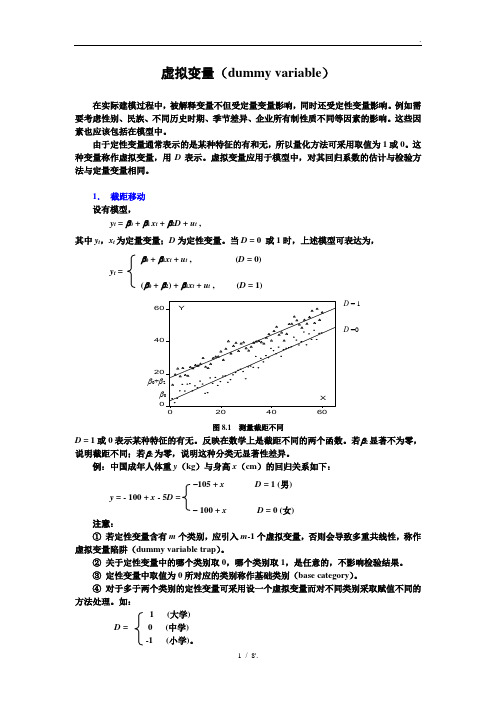
虚拟变量(dummy variable)
0
0
1
2000:4
2.7280
20
0
0
0
数据来源:《中国统计年鉴》1998-2001
2.斜率变化
以上只考虑定性变量影响截距,未考虑影响斜率,即回归系数的变化。当需要考虑时,可建立如下模型:
yt=0+1xt+2D+3xtD+ut,
其中xt为定量变量;D为定性变量。当D= 0或1时,上述模型可表达为,
若不采用虚拟变量,得回归结果如下,
GDP = 1.5427 + 0.0405 T
(11.0) (3.5) R2= 0.3991, DW = 2.6,s.e.=0.3
定义
1(1季度)1(2季度)1(3季度)
D1=D2=D3=
0(2, 3,4季度)0(1,3, 4季度)0(1,2, 4季度)
第4季度为基础类别。
15
0
0
1982
7.713
384
16
0
0
1983
8.601
34
1
34
1966
1.271
17
0
0
1984
12.010
35
1
35
1967
1.122
18
0
0
以时间T=time为解释变量,进出口贸易总额用trade表示,估计结果如下:
trade= 0.37 + 0.066time- 33.96D+ 1.20timeD
虚拟变量(dummy variable)
在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。这些因素也应该包括在模型中。
虚拟变量(dummy variable)
1(1978 - 1984)
中国进出口贸易总额数据(1950-1984)(单位:百亿元人民币)
年
trade
T
D
T*D
年
trade
T
D
T*D
1950
0.415
1
0
0
1968
1.085
19
0
0
1951
0.595
2
0
0
1969
1.069
20
0
0
1952
0.646
3
0
0
1970
1.129
21
0
0
1953
1(第2季度)
D2=
0(其他季度)
1(第3季度)
D3=
0(其他季度)
1(第4季度)
D4=
0(其他季度)
1(1998:1~2002:4)
DT=
0(1990:1~1997:4)
得估计结果如下:
GDPt= 1.1573+0.0668t+0.0775D2+0.2098D3+0.2349D4+1.8338DT-0.0654DTt
(50.8)(64.6) (3.7)(9.9) (11.0)(19.9) (-28.0)
R2=0.99, DW=0.9,s.e.=0.05, F=1198.4,T=52,t0.05 (52-7)= 2.01
对于1990:1~1997:4
GDPt= 1.1573+0.0668t+0.0775D2+0.2098D3+0.2349D4
首先看天津市粮食市场小麦批发价格的变化情况(图1)。1995年初,天津市粮食市场的小麦批发价格首先放开。在经历5个月的上扬之后,进入平稳波动期。从1996年8月份开始小麦批发价格一路走低。至2002年12月份,小麦批发价格降至是1160元/吨。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2 2 2 y x x x x y x y x x y x x 0 i 1i 2i 1i 2i i 2i i 2i 2i i 2i 2i ˆ 1 x1i 2 x2i 2 ( x1i x2i )2 2 ( x 2 2 i ) 2 2 ( x 2 2 i ) 2 0
本章要点
• • • • • • • • 多重共线性的含义 多重共线性产生的原因 多重共线性的后果 判断多重共线性的方法及其修正方法 虚拟变量的设置原则 虚拟变量模型的应用 邹氏检验的做法及缺陷 虚拟变量法检验结构稳定性的优点
多重共线性的概念
• 多重共线性(multicollinearity)一词最早由 挪威经济学家弗瑞希(R.Frisch)于1934年提出。 • 其原义是指回归模型中的一些或全部解释变量中 存在的一种完全(perfect)或准确(exact)的线性 关系。而现在所说的多重共线性,除指上述提到 的完全多重共线性(perfect multicollinearity ), 也包括近似多重共线性(near multicollinearity)。
ˆ 也是无法确定的,即不能求得参数数估计值的方差,有
2 2 x v 2i ˆ) var( 1 2 2 2 2 2 2 2 2 2 x1i x2i ( x1i x2i ) ( x 2 i ) ( x 2 i )
检验多重共线性问题是否严重
• 若回归模型的 R 2 值高(如 R 2 >0.8),或F检验值 显著,但单个解释变量系数估计值却不显著;或 从金融理论知某个解释变量对因变量有重要影响, 但其估计值却不显著,则可以认为存在严重的多 重共线性问题。 • 若两个解释变量之间的相关系数高,比如说大于 0.8,则可以认为存在严重的多重共线性。
• 为对上述两概念加以区别,我们以一组解释变量 X1、X2、...Xn 为例 • 如果存在一组不完全为零的常数 1、 2、 ... n 满足1X1+ 2X2+...+ nXn=0 ,即任一变量都可以由其它变 量的线性组合推出,则这组变量满足完全多重共线性。 若变量组 X1、X2、...Xn , 满足如下关系式 1X1+ 2X2+...+ nXn+u=0 ,其中u表示随机误差项,即 某一变量不仅取决于其它变量的线性组合,也取决于随机 误差项,此时变量组之间存在非严格但近似的线性关系, 解释变量之间高度相关,也即变量组存在近似多重共线性 关系。
多重共线性产生的原因
• 多重共线性问题在金融数据中是普遍存在的,不仅存在于 时间序列数据中,也存在于横截面数据中。具体而言,多 重共线性产生的原因主要有以下几点: (1)数据收集及计算方法。 (2)模型或从中取样的总体受到限制。 (3)模型设定偏误。 • 此外,在观测值个数较少,以至于小于解释变量个数时, 也会产生多重共线性;时间序列数据中,若同时使用解释 变量的当期值和滞后值,由于当期值和滞后值之间往往高 度相关,也容易产生多重共线性。
多重共线性的后果
• 多重共线性不会改变最小二乘估计的无偏性,但在解释变 量之间存在严重的多重共线性而被忽略时,会对模型的估 计、检验与预测产生严重的不良后果。以某一离差形式 (即 xt Xt X )表示的二元线性回归模型 为例 yi 1 x1i 2 x2i vi
• 若存在完全多重共线性,假设存在关系 x1i x2i 常数 0 。则 1的估计值
多重共线性的检验
• 如前所述,多重共线性普遍存在于金融、经济数据中,因 此对多重共线性的检验并不是要确定其是否存在,而是要 确定多重共线性的程度。 • 由于多重共线性是对被假定为非随机变量的解释变量的情 况而言的,所以它是一种样本而非总体特征,这决定了我 们只能以某些经验法则(rules of thumb)来检验模型的 多重共线性。 • 对多重共线性的检验主要包括以下内容: (1)检验多重共线性问题是否严重 (2)多重共线性的存在范围,即确定多重共线性 是由哪些主要变量引起的。 (3)多重共线性的表现形式,即找出与主要变量 有共线性的解释变量。
v 2 x2i 2
ˆ 的方差也是无限大的。因此,当存在完 • 同理, 2 全多重共线性时,我们将不能求得参数估计值, 参数估计值的方差无限大。 • 当存在近似多重共线性时,尽管可以求得参数估 计值,但它们是不稳定的,同时参数估计值的方 差将变大,变大的程度取决于多重共线性的严重 程度。
•
Ri 2 /(k 1) Fi= (1 Ri 2 ) /(n k)
2
服从自由度为k-1与n-k的F分布
• 其中 Ri (i=1,2,…k)为第i个解释变量 Xi 关于其 余解释变量的辅助回归的拟和优度,k为解释变 量的个数,n代表样本容量。
检验多重共线性的表现形式
• 当确定多重共线性是由哪些主要变量引起后,若要找出与 主要变量有共线性的解释变量,即确定多重共线性的表现 Xj 偏相关系数 形式,可采用偏相关系数法。解释变量 X与 i 即是在其它的解释变量固定的情况下它们之间的相关系数。 • 偏相关系数法构造的检验统计量定义如下: ij ,服从自由度为n-k-1的t分布
判断多重共线性的存在范围
• 要确定多重共线性是由哪些主要变量引起的,可 以采用辅助回归法(auxiliary regression method)。所谓辅助回归是指某一解释变量对其 余解释变量的回归,区别于因变量对所有解释变 量回归的主回归(main regression)。 • 辅助回归法构造的检验统计量定义如下:
在实际金融数据中,完全多重共线性只是一种极端情况, 各种解释变量之间存在的往往是近似多重共线性,因此 通常所说多重共线性造成的后果是指近似多重共线性造 成的后果,具体而言,它将造成如下的后果: (1)回归方程参数估计值将变得不精确,因为 较大的方差 将会导致置信区间变宽。 (2)由于参数估计值的标准差变大,t值将缩小,使得t检验 有可能得出错误的结论 。 (3)将无法区分单个变量对被解释变量的影响作用。