第七章 虚拟变量
第七章 虚拟变量和随机解释变量 (2)

第七章 虚拟变量和随机解释变量本章将讨论两种不同的模型:虚拟变量模型和随机解释变量模型,以及模型设定的其它问题。
第一节 虚拟变量模型在我们以前考虑的模型中,解释变量都是定量变量(如成本、价格、收入、产出等),但在经济研究中,因变量经常受到一些定性变量的影响(如性别、种族、季节、不同历史时期等),我们把这类定性变量称为虚拟变量。
习惯上用D表示虚拟变量,虚拟变量的取值通常为0和1。
0表示变量具备某种属性,1表示变量不具备某种属性。
一、包含一个虚拟变量的模型如果我们要研究的问题中解释变量只分为两类。
则需引入一个模拟变量。
例9.1建立模型研究中国妇女在工作中是否受到歧视。
令Y=年薪,X=工作年限⎩⎨⎧=,女性,男性101D 可以建立如下模型:i i i i u D B X B B Y +++=210 )1.9( 与一般的回归模型一样,假定0)(=i u E 男性就业者的平均年薪:i i i i X B B D X Y E 10)0,(+== )2.9(女性就业者的平均年薪:210)1,(B X B B D X Y E i i i i ++== )3.9(如果B 2=0则说明不存在性别歧视,如果02<B ,则说明存在性别歧视。
图9.1表明男女就业者的平均年薪对工龄的函数具有相同斜率B 1,即随着工龄的增长男女工资的增长幅度相同;截距不同,说明男女的初始年薪不同。
我们称这种虚拟变量只影响截距不影响斜率的模型为加法模型。
图9.1不同性别就业者的收入(加法模型,B 2<0)如果随着工龄增加,男性与女性的年薪差距也发生变化,则模型(9.1)就变为i i i i i u X D B X B B Y +++=210 )4.9(图9.2描绘了男性年薪增加较快的情况。
我们称虚拟变量只影响斜率而不影响截距的模型为乘法模型如(9.4)如果男性与女性的初始年薪和年薪增加速度都有差异,我们可以将加法模型和乘法模型结合起来,得到如下模型i i i i i i u D B X D B X B B Y ++++=3210 )5.9(模型(9.5)可以用来表示截距和斜率都发生变化的模型。
第7章 Dummy Variables 虚拟变量

Case 1: y = b0 + d0d + b1x + u
• 考虑一个简单工资方程:
wage = b0 + d0 female + b1 educ + u
• If female =0, then wage = b0 + b1educ + u • If female =1, then wage = (b0 + d0) + b1educ + u
• d0 = E(wage| female=1, educ) - E(wage| female=0, educ)
• d0 (an intercept shift): 给定教育年限educ,女性平 均工资比男性平均工资高d0元。
Example of d0 > 0
E(wage|female,educ) = b0 + d0 female + b1 educ
扩展:多个虚拟变量回归模型
• female(1 female; 0 male); married(1 married; 0 single) • marrfem( 1 female married; 0 others) • marrmale (1 male married; 0 others) • singlefem (1 female single; 0 others) • singlemale (1 male single; 0 others)
• A dummy variable 是一种只取1或0两个数值的变量. • Examples: (1) sex: 1: male 2: female
male (= 1 if male, 0 otherwise); female (= 1 if female, 0 otherwise) (2) region: 1. eastern; 2. central ; 3. western) eastern (=1 if eastern, 0 otherwise); central (=1 if central, 0 otherwise) western (=1 if western, 0 otherwise) • Dummy variables are also called: 二值变量(binary variables), 0-1变量(zero-one variables)
计量经济学虚拟变量实验报告
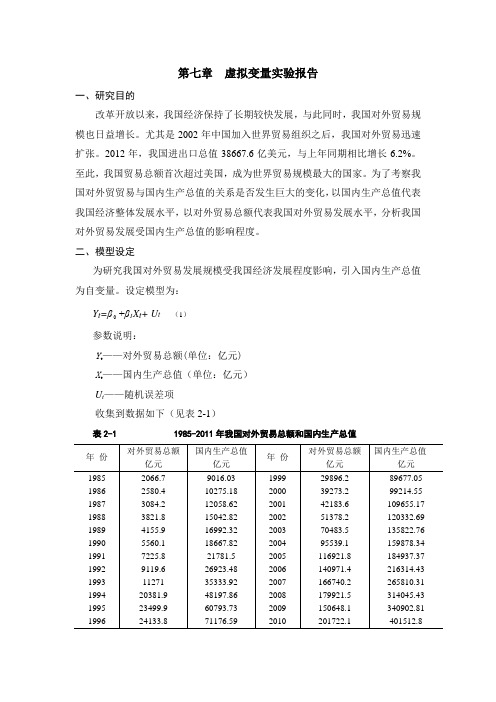
第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。
虚拟变量回归模型_OK

是一样的,但两者的平均薪金水平相差 a。
可以通过传统的回归检验,对 a的统计显著性进行检验,以
判断男女职工的平均薪金水平是否显著差异。
16
例7.1.4 居民家庭的教育费用支出除了受收入水平的影响之外,还与子女 的年龄结构密切相关。如果家庭中有适龄子女(6-21岁),教育费用支出就 多。因此,为了反映“子女年龄结构”这一定性因素,设置虚拟变量:
当tt*=1978年, Dt = 1
ˆyt = bˆ0 aˆxt + bˆ1 + aˆ xt
32
28
例如,进口消费品数量Y主要取决于国民收入 X的多少,中国在改革开放前后,Y对X的回归关 系明显不同。
这时,可以t*=1978年为转折期,以1978年的 国民收入Xt*为临界值,设如下虚拟变量:
1 Dt = 0
t t* t t*
则进口消费品的回归模型可建立如下:
yt = b0 + b1 xt + a xt xt Dt + ut
9
概念:
同时含有一般解释变量与虚拟变量的模型称为 虚 拟 变 量 模 型或 者 方差 分 析 ( analysis-of variance: ANOVA)模型。
一个以性别为虚拟变量考察企业职工薪金的模型:
Yt = b 0 + b1 Xt + b 2Dt + mt
其中:Yt为企业职工的薪金,Xt为工龄, Dt=1,若是男性,Dt=0,若是女性。
D4=
1 喜欢某种商品 0 不喜欢某种商品
5)表示天气变化的虚拟变量可取为
D5=
1 晴天 0 雨天
6
2.引入虚拟变量的作用 引入虚拟变量的作用,在于将定性因素或属性因素对因变量
计量经济学课件虚拟变量

通过引入虚拟变量,可以更准确地刻画经济现象的非线性特征,从而提高计量经济学模型 的精度和预测能力。
拓展应用领域
虚拟变量的引入使得计量经济学模型能够应用于更多的领域,如金融、环境、社会等,进 一步拓展了计量经济学的应用范围。
未来研究方向和趋势
深入研究虚拟变量的理论 和方法
未来研究将进一步深入探讨虚 拟变量的理论和方法,包括虚 拟变量的选择、设定和估计方 法等,以更准确地刻画经济现 象。
https://
未来研究将积极推动虚拟变量 在交叉学科领域的应用,如环 境经济学、金融经济学等,以 促进不同学科之间的交流和合 作。
WENKU DESIGN
WENKU DESIGN
2023-2026
END
THANKS
感谢观看
KEEP VIEW
WENKU DESIGN
WENKU DESIGN
WENKU
REPORTING
要点二
虚拟变量的设置原则
在设置虚拟变量时,需要遵循完备性 和互斥性的原则。完备性要求虚拟变 量的取值能够覆盖所有可能的情况, 而互斥性则要求不同虚拟变量之间不 能存在重叠或交叉的情况。
要点三
虚拟变量的回归系数 解释
在线性回归模型中,虚拟变量的回归 系数表示该定性因素对因变量的影响 程度。当虚拟变量取值为1时,其对 应的回归系数表示该水平与参照水平 相比对因变量的影响;当虚拟变量取 值为0时,则表示该水平对因变量没 有影响。
参数估计与假设检验
参数估计
采用最小二乘法等估计方法,对引入虚拟变量后的模型进行参数估计,得到各 解释变量的系数估计值。
假设检验
根据研究问题和假设,构建相应的原假设和备择假设,通过t检验、F检验等方 法对参数进行假设检验,判断虚拟变量对模型的影响是否显著。
第七章 虚拟变量

在E(i)=0 的初始假定下,高中以下、高中、大学 及其以上教育水平下个人保健支出的函数:
高中以下:
E (Yi | X i , D1 0, D2 0) 0 1 X i
• 高中:
E (Yi | X i , D1 1, D2 0) ( 0 2 ) 1 X i
可视为截距项的解释变 量,即α0= α0×1
所以引入4个虚拟变量出现了完全多重共线 性的问题! OLS法不能使用! 这就是虚拟变量陷阱问题!
如果只取六个观测值,其中春季与夏季取了 两次,秋、冬各取到一次观测值,则式中的:
1 1 1 ( X, D) 1 1 1 X 11 X k1 X 12 X k 2 X 13 X k 3 X 14 X k 4 X 15 X k 5 X 16 X k 6 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 1 0 0 1 0 0 0
1.定义
虚拟变量是一用以反映质的属性的一个人工 变量,取值为0或1,通常记为D(Dummy Variable),又可称之为哑变量或二进制变量。 对基础类型或肯定类型设 D=1 对比较类型或否定类型设 D=0 虚拟变量示例 注意:虚拟变量D只能取0或1两个值,即属性 之间不能运算!
(-6.11) (22.89) (4.33) (-2.55)
R 2 =0.9836
由3与4的t检验可知:参数显著地不等于0,强 烈示出两个时期的回归是相异的, 储蓄函数分别为:
1990年前: 1990年后:
ˆ 1649.7 0.4116X Y i i
ˆ 15452 0.8881X Y i i
1 D2 0
计量经济第七章虚拟变量模型
1.线性概率模型(LPM模型)
定义:以虚拟变量为因变量的线性回 归模型称为线性概率模型。 (linear probability model,LPM) 模型的基本形式为:
Yi 0 1 X1i +2 X 2i L k X ki ui ,
E Yi | X 0 1 X1i +2 X 2i L k X ki ,
第八章 虚拟变量模型
1
第一节 第二节 第三节
虚拟变量模型概述 二元概率模型 二元逻辑模型
2
第一节
虚拟变量模型概述
一、虚拟变量的含义 二、虚拟变量作为自变量 三、虚拟变量作为因变量
3
一、虚拟变量的含义
• 一个定性变量,它的可能值只有两个, 也就是说出现或不出现某种属性。一般 地,用1表示出现某种属性,用0表示没 有出现该属性。像这样取值只为0、1的 变量称为虚拟变量或哑变量。 • 并用符号 D表示,从而与常用符号 X区别 开。我们把赋值为0的一类称为基准类。
14
一、二元Probit模型
• 二元Probit模型的基本形式为:
1 Pi Zi 2
Zi
e
t 2 /2
dt
其中 Zi 0 1 X1i +L +k X ki ;是累积标 准正态分布函数,t 为服从标准正态分布 的随机变量。
Zi 1 P i 1 P i 0 1 X1i +L +k X ki .
i 1,2,L , n.
1,已婚 其中 Yi 为个人月支出, D1i = 0,未婚
7
• 未婚者的月期望支出为:
E Yi | D1i 0 E 0 1 g0 ui 0
第七章虚拟变量
如何刻画我国居民在不同时段的消费行为?
基本思路:采用乘法方式引入虚拟变量的手段。显然, 1979年是一个转折点,可考虑在这个转折点作为虚拟 变量设定的依据。若设X* =1979,当 t<X* 时可引 入虚拟变量。(为什么选择1979作为转折点?)
实质:加法方式引入虚拟变量改变的是截距;乘法方式 引入虚拟变量改变的是斜率。
一、加法类型 (1)一个两种属性定性解释变量而无定量变量的情形
例:按性别划分的教授薪金
(2)包含一个定量变量,一个定性变量模型
, 设有模型,yt = 0 + 1 xt + 2D + ut
其中yt,xt为定量变量;D为定性变量。当D = 0 或1时,上述模型可表达为,
令Y代表年薪, X代表教龄,建立模型:
Yi B0 B1Xi B2D2i B3D3i B4D4i ui
可以看出基准类是本科女教师,B0为刚参加工作的本 科女教师的工资;B1为参加工作时间对工资的影响;B2 是性别差异系数;B3和B4为学历差异系数,B3是硕士学 历与本科学历的收入差异,B4是博士学历与本科学历的 收入差异;通过上述分析,我们可以确定Bi的符号。
问题:如何刻画同时发展油菜籽生产和养蜂生产的交互 作用?
基本思想:在模型中引入相关的两个变量的乘积。
区别之处在于,上页定义中的交互效应是针对数量变量, 而现在是定性变量,又应当如何处理?
(3)分段回归分析
作用: 提高模型的描述精度。
虚拟变量也可以用来代表数量因素的不同阶段。分段线性 回归就是类似情形中常见的一种。
第七章 多元回归分析-虚拟变量
• • • • • • • • • • 模型 y = β0 + β1x1 + β2x2 + . . . βkxk + u 虚拟变量 表示两个类型的虚拟变量 表示多个类型的虚拟变量 虚拟变量之间的交叉项 虚拟变量和连续变量的交叉项 Chow检验 线性概率模型 项目评估和自选择偏差
多个数值的类型变量(续)
• 任何类型变量都可以变成一组虚拟变量 • 因为参照组由常数项表示了, 那么如果一共 有n 个类型,就应该由n – 1 虚拟变量 • 如果有太多的类型,通常应该对其进行分 组 • 例:前10 , 11 – 25, 等
虚拟变量之间的交叉项
• 求虚拟变量的交叉项就相当于对样本进行进一 步分组 • 例:有男性(male)的虚拟变量和hsgrad (仅仅中学毕业) 和 colgrad (大学毕业)的 虚拟变量 • 加入 male*hsgrad 和 male*colgrad, 共有五个 虚拟变量 –> 共有六种类型 • 参照组是女性中学辍学的人 • 此时hsgrad 代表女性仅仅中学毕业者, colgrad 表示女性大学毕业者 • 交叉项表示男性仅仅中学毕业者和男性大学毕 业者
事实上是经济过程检验
• 做模型回归时我们假设所有的样本观测值 都来自同一个总体,如果总体发生改变, 那么模型参数也将发生改变,因此检验总 体也就是经济过程是否发生改变是用计量 进行经济研究的主要步骤。或者是在进行 经济计量研究时必须考虑的一个重要步 骤。其具体方法是:
• 假设我们在1到n个时期研究经济的结构关系,得到如 下的回归模型: Y=b0+b1X1+b2X2+…+bkXk+e 在第q期(1<q < n)曾出台一个经济政策,为检验该 经济政策是否影响我们所研究的经济结构可作如下检 验: 1、用1到q个观测值对模型进行回归,得到回归残差的平 方和,记为ESS1;用q+1到n个观测值对模型进行回 归,得到回归残差平方和,记为ESS2,并令 ESSUR= ESS1+ ESS2。 2、用1到n个观测值对模型进行回归,得到回归残差平方 和,记为ESSR,这可用下面的F统计量检验在k时期出 台的经济政策是否导致经济结构变化: ( ESS R − ESSUR ) / k F ( k , n − 2k ) = ESSUR /(n − 2k )
虚拟变量
(-6.550) (8.758) (4.500)
R2 0.904
SE 83.675 D W 1.072
结果显示,各项指标明显改进,农民人均生活费支出 在1994年向上跳跃405.98元
§7.1 含有虚拟解释变量的线性回归模型
例2 Yt 集体单位职工人数
Xt 全民单位职工人数 集体单位职工人数 1955:254万 ;1956:554万 全民单位职工人数 1957:748万; 1958:2316万
§7.1 含有虚拟解释变量的线性回归模型
异常数据的影响——干扰我们对主要规律的认识。 如何对待异常数据——既要看到它偶然、变异的 一面,也要理解它异常中所包含的普遍性——偶然与 变异之可以发生的基础的一面。 简单地直接使用,它们的“变异性”会影响我们 对主要规律的认识;而简单地删除舍去又会丢失它们 所包含的“普遍性信息”。 虚拟变量可以方便、合理地解决这一问题。
Ln
1
p P
0
1LnX
U
§7.2 含有虚拟被解释变量的线性回归模型
Logit函数性质
Ln p 1 P
0
1LnX
1
P
1 aX 1
(X 0)
(a e0 )
1是随机事件 A 出现的机会比率关于解释变量 X 的弹性
§7.2 含有虚拟被解释变量的线性回归模型
(二)Logit模型应用示例
ATB=农户从事农业劳动的时间所占全部劳动时间的比重
D W 2.124
THE END
ቤተ መጻሕፍቲ ባይዱ
例7.4 政策效用评价
3
Y=SYL(失业率), X=ZWKQL(职位空缺率)
2.5
2.02 SYL1.5
SYL
1.01
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。
D取值为0的类型,是基础类型,是比较的基准。
不如前面说的性别变量,如果你研究是以男性为研究基准,则样本为男性,D取值为0,2、避免落入“虚拟变量陷阱”。
当一个定性变量含有m个相互排斥的类型时,应向模型引入m—1个虚拟变量。
比如“性别”含男性和女性两个类别,所以当性别作为解释变量时,应向模型引入一个虚拟变量。
取值方式是:D=1(男性)、D=0(女性)或D=0(男性)、D=1(女性)而当“学历”含有四个类别时,即大学、中学、小学、无学历。
当“学历”作为解释变量时,应向模型引入三个虚拟变量。
一种取值方式是:1 (大学)1(中学)1(小学)D1= 0 (非大学)D2 = 0(非中学)D3= 0(非小学)所谓的“虚拟变量陷阱”就是当一个定性变量含有m个类别时,模型引入m个虚拟变量,造成了虚拟变量之间产生完全多重共线性,无法估计回归参数。
在m-1个虚拟变量中,虚拟变量可以同时取值为0,但不能全部取值为1。
3、当定性变量含有m个类别时,不能把虚拟变量的值设为D=0(第一类)D=1(二类)D=2(三类)等等。
1、回归模型中可以只有虚拟变量作解释变量,也可以用定量变量和虚拟变量一起作解释变量。
另外,虚拟变量还可以作被解释变量。
第二节虚拟解释变量的回归虚拟变量的引入,可以影响模型的截距,也可以影响斜率,还可以同时影响截距和斜率。
因此,加入虚拟解释变量的途径有两种基本类型:一是加法类型,二是乘法类型。
不同的引入途径对计量经济模型有不同的影响。
一、加法类型:改变模型的截距所谓的加法类型引入虚拟变量,就是虚拟变量与其他解释变量在设定模型中是相加关系。
在所设定的计量经济模型中,根据所研究问题中定量变量的影响作用,按照虚拟变量的设置规则,直接在所设定的计量经济模型中加入适当的虚拟解释变量。
比如:Y=a0+a1D1+a2D2+βX+u 就是以加法形式引入的虚拟变量。
加法形式引入虚拟解释变量,其作用是改变了设定模型的截距水平。
定性因素所包含的属性类别m的多少,决定了引入虚拟解释变量个数的多少,同时也决定了所设模型的不同性质。
下面分三种主要情形对加法形式引入虚拟变量的情形进行讨论。
1、解释变量包含一个分为两种属性类型的定性变量的回归如Y=a0+a1D+βX+u D=0 (基础类型)D=1(其他类型)则基础类型:E(Y)=a0+βX 比较类型:E(Y)=(a0+a1)+βXa1就是截距的差异系数。
对a1的显著性检验,就是判别两条回归线的截距项是否存在显著性差异,或者说,检验定性因素对截距是否有显著影响。
注意:u应服从基本假定;这里一个定性变量有两种类型,只使用了一个虚拟变量。
比如:我们分析是否读大学对年工资的影响。
见资料。
另P2192、解释变量中包含一个两种属性以上的定性解释变量的回归Y=a0+a1D1+a2D2+βX+u 例如研究收入、学历(中学以下、中学、中学以上)对书报费支出的影响。
D1=1(中学)=0(其他)D2=1 (中学以上)=0 (其他)则基础类型:(中学以下)E(Y|D1=0、D2=0)=a0+βX比较类型(中学)E(Y|D1=1,D2=0)=(a0+a1)+βX(中学以上)E(Y|D1=0,D2=1)=(a0+a2)+βX这表明,三种不同的属性类型,其对应变量的影响都是不同的,原因在于三者的起点水平即截距不同。
同样,a2、a3表示的是截距差异系数,对他们的显著性检验,说明了不同的属性是否对戒惧6具有显著性影响。
注意:u应服从基本假定;一个定性变量有m种属性,使用了m-1个虚拟变量,D1、D2代表的是同一定性变量的两种不同属性。
两个差异截距系数a1、a2表示的都是与基础类型的差异;一个定性变量多种属性时,虚拟变量可以同时取0(基础类型),但不能同时取值为1,因为同一定性变量的各类型间是相互排斥,“非此即彼”的。
3、解释变量包含两个定性变量的回归模型Y=a0+a1D1+a2D2+βX+u 这里的D1、D2代表的是两个不同的定性变量。
例如研究卷烟需求与收入、性别、居住地区的关系。
D1=1(城镇居民)=0(其他)D2=1男性=0 女性基础类型:农村女性居民:E(Y|D1=0、D2=0)=a0+βX比较类型:农村男性居民:E(Y|D1=0、D2=1)=(a0+a2)+βX城镇女性居民:E(Y|D1=1、D2=0)=(a0+a1)+βX城镇男性居民:E(Y|D1=1、D2=1)=(a0+a1+a2)+βX这个结果表明,不同的定性变量以及他们各自不同的属性都对应变量产生不同的影响。
a1、a2的显著性检验,可验证这两个定性变量对截距是否有影响。
注意:u应服从基本假定‘两个定性变量和一个有三种属性类型的定性变量都用了两个虚拟变量,但其性质是不同的;K个定性变量可选用K个虚拟变量去表示,这不会出现“虚拟变量陷阱”;代表不同定性变量的虚拟变量,可以同时为0,也可以同时为1,因为不同的定性变量间没有非此即彼的关系。
二、乘法类型——引起模型中斜率系数的差异。
加法方式引入虚拟解释变量,暗含着一个基本的假定:定性解释变量对于应变量的影响作用,仅体现在回归模型的截距项,即仅影响平均水平,而不会影响不同属性模型的相对变化。
表现在图上,就是回归线的斜率不变,只会上下平移。
但在现实经济中,这种假定条件通常难以满足。
例如,居住地区(城市或乡村)不仅会使消费总体支出上升,而且消费的结构也会发生很大的变化。
乘法类型引入虚拟解释变量,是在所设定的计量经济模型中,将虚拟变量与其他解释变量相乘作为新的解释变量出现在模型中,以达到其调整设定模型斜率系数的目的。
例如:Y=a0+a1X1+a2X2D+u乘法形式引入虚拟解释变量的主要作用在于:1、关于两个回归模型的比较;2、因素间的交互影响分析;3、提高模型对现实经济现象的描述精度。
下面分别对上述作用进行讨论。
(一)回归模型的比较——结构变化检验比如我们比较我国改革开放前后的储蓄——收入关系的变化时,就存在着经济结构变化而导致设定模型斜率发生变化的问题。
这类问题可归结为两个回归模型的比较。
例如:Y=a0+a1D+β1X+β2(DX)+u 其中D=1(改革开放前)=0(改革开放后) Y储蓄总额 X收入总额基础类型:改革开放后E(Y|D=0)=a0+β1X比较类型改革前:E(Y|D=0)=(a0+a1)+(β1+β2)X对上式的估计等同于对两个储蓄函数进行估计。
在式中,a1被称为截距差异系数,β2为斜率差异系数,分别代表改革开放前后储蓄函数截距与斜率所存在的差异。
因此,当以乘法形式引入虚拟解释变量时,其作用在于区别改革开放前后储蓄关于收入的相对变化情况,即区别两个时期模型斜率系数的变化情况,而加法形式引入虚拟变量则是区别不同时期的储蓄起点。
显著性检验的意义,也在于说明引入的虚拟变量对斜率影响的显著性,也就是检验这两个回归的结构是否有差异。
优点:用一个回归替代了多个回归,简化了分析过程;合并回归增加了自由度,提高参数估计的精确性。
(二)交互效应分析我们前面的模型,不管引入多少个定性变量,都暗含着一种假定:两个定性变量是分别独立影响应变量的。
但在实际情况中,两个定性变量之间存在着交互影响,而且这种交互影响对应变量产生了作用。
比如,我们引入性别和学历两个定性变量解释对服装支出费用的影响,用上面的模型我们只能得出性别对服装支出的影响而与学历无关,以及学历对服装支出的影响而与性别无关,没有一个解释变量是表征女性本科比女性高中的支出有没有差异,也就是说,性别和学历这两个定性变量之间存在着交互影响,且对应变量产生作用。
因此,为了描述这种交互作用,把两个虚拟变量的乘积以加法形式引入模型。
例如上面所说的服装支出与收入、性别、学历的关系:Y=a0+a1D1+a2D2+a3(D1D2)+βX+U其中的D1D2描述的就是二者交互效应的虚拟变量。
假设D1=1 女性 =0 男性,D2=1 本科及本科以上,=0 其他。
则a1=女性服装年平均支出的截距差异系数;a2=高教育水平人群年平均服装支出的截距差异系数;a3=高教育水平女性服装支出的截距差异系数,又称为本科女性的交互效应系数。
可以通过对对交互效应虚拟变量系数的显著性检验,判断交互效应是否存在(三)分段线性回归有的社会经济现象的变动,会在解释变量达到某个临界值时发生突变,比如公司对销售人员的奖励政策就经常是这样设计的:按销售额提,当销售额在某一目标水平以上或以下,提奖励的方法不同。
当销售额X《X*时,与X》X*的线段更平缓。