深入分析Linux内核源码
linux coredump里面的code 解析

linux coredump里面的code 解析摘要:1.Linux coredump 背景介绍2.Linux coredump 文件结构解析3.Linux coredump 中的code 段解析4.Linux coredump 中code 段的实际应用案例5.总结正文:Linux coredump 是Linux 系统中的一种重要调试工具,可以帮助开发者分析程序崩溃的原因。
在coredump 文件中,包含了程序崩溃时的一些关键信息,如进程状态、内存信息等。
其中,code 段是coredump 中非常重要的一个部分,它包含了程序的执行代码。
Linux coredump 文件结构解析Linux coredump 文件主要包括以下几个部分:- magic:魔数,用于标识coredump 文件类型,固定为0x8130。
- version:版本信息,表示coredump 文件格式版本,当前为2。
- header:coredump 文件头,包含文件类型、进程ID、时间戳等信息。
- body:coredump 文件主体,包含进程的内存映像,包括code 段、data 段、bss 段等。
Linux coredump 中的code 段解析code 段是coredump 中存储程序执行代码的部分,通常以ELF (Executable and Linkable Format)格式存储。
ELF 是一种可执行文件格式,支持多种处理器架构。
code 段包含了程序的指令和数据,以及符号表等信息。
在ELF 文件中,code 段分为两种:text 段和data 段。
text 段包含了程序的执行代码,而data 段包含了程序的数据。
这两个段通过动态链接器(dynamic linker)链接在一起,形成一个完整的可执行文件。
Linux coredump 中code 段的实际应用案例假设我们有一个程序崩溃了,产生了coredump 文件。
Linux操作系统源代码详细分析

linux源代码分析:Linux操作系统源代码详细分析疯狂代码 / ĵ:http://Linux/Article28378.html内容介绍: Linux 拥有现代操作系统所有功能如真正抢先式多任务处理、支持多用户内存保护虚拟内存支持SMP、UP符合POSIX标准联网、图形用户接口和桌面环境具有快速性、稳定性等特点本书通过分析Linux内核源代码充分揭示了Linux作为操作系统内核是如何完成保证系统正常运行、协调多个并发进程、管理内存等工作现实中能让人自由获取系统源代码并不多通过本书学习将大大有助于读者编写自己新 第部分 Linux 内核源代码 arch/i386/kernel/entry.S 2 arch/i386/kernel/init_task.c 8 arch/i386/kernel/irq.c 8arch/i386/kernel/irq.h 19 arch/i386/kernel/process.c 22 arch/i386/kernel/signal.c 30arch/i386/kernel/smp.c 38 arch/i386/kernel/time.c 58 arch/i386/kernel/traps.c 65arch/i386/lib/delay.c 73 arch/i386/mm/fault.c 74 arch/i386/mm/init.c 76 fs/binfmt-elf.c 82fs/binfmt_java.c 96 fs/exec.c 98 /asm-generic/smplock.h 107 /asm-i386/atomic.h 108 /asm-i386/current.h 109 /asm-i386/dma.h 109 /asm-i386/elf.h 113 /asm-i386/hardirq.h 114 /asm-i386/page.h 114 /asm-i386/pgtable.h 115 /asm-i386/ptrace.h 122 /asm-i386/semaphore.h 123 /asm-i386/shmparam.h 124 /asm-i386/sigcontext.h 125 /asm-i386/siginfo.h 125 /asm-i386/signal.h 127/asm-i386/smp.h 130 /asm-i386/softirq.h 132 /asm-i386/spinlock.h 133 /asm-i386/system.h 137/asm-i386/uaccess.h 139 //binfmts.h 146 //capability.h 147 /linux/elf.h 150 /linux/elfcore.h 156/linux/errupt.h 157 /linux/kernel.h 158 /linux/kernel_stat.h 159 /linux/limits.h 160 /linux/mm.h 160/linux/module.h 164 /linux/msg.h 168 /linux/personality.h 169 /linux/reboot.h 169 /linux/resource.h 170 /linux/sched.h 171 /linux/sem.h 179 /linux/shm.h 180 /linux/signal.h 181 /linux/slab.h 184/linux/smp.h 184 /linux/smp_lock.h 185 /linux/swap.h 185 /linux/swapctl.h 187 /linux/sysctl.h 188/linux/tasks.h 194 /linux/time.h 194 /linux/timer.h 195 /linux/times.h 196 /linux/tqueue.h 196/linux/wait.h 198 init/.c 198 init/version.c 212 ipc/msg.c 213 ipc/sem.c 218 ipc/shm.c 227 ipc/util.c 236 kernel/capability.c 237 kernel/dma.c 240 kernel/exec_do.c 241 kernel/exit.c 242 kernel/fork.c 248 kernel/info.c 255 kernel/itimer.c 255 kernel/kmod.c 257 kernel/module.c 259 kernel/panic.c 270 kernel/prk.c 271 kernel/sched.c 275 kernel/signal.c 295 kernel/softirq.c 307 kernel/sys.c 307kernel/sysctl.c 318 kernel/time.c 330 mm/memory.c 335 mm/mlock.c 345 mm/mmap.c 348mm/mprotect.c 358 mm/mremap.c 361 mm/page_alloc.c 363 mm/page_io.c 368 mm/slab.c 372mm/swap.c 394 mm/swap_state.c 395 mm/swapfile.c 398 mm/vmalloc.c 406 mm/vmscan.c 409第 2部分 Linux 内核源代码分析 第1章 Linux 介绍 让用户很详细地了解大多数现有操作系统实际工作方式是不可能大多数操作系统源代码都是严格保密除了些研究用及为操作系统教学而设计系统外尽管研究和教学目都很好但是这类系统很少能够通过对正式操作系统小部分实现来体现操作系统实际功能对于操作系统些特殊问题这种折衷系统所能够表现就更是少得可怜了 在以实际使用为目标操作系统中让任何人都可以自由获取系统源代码无论目是要了解、学习还是改进这样现实系统并不多本书主题就是这些少数操作系统中个:Linux Linux工作方式类似于Uinx它是免费源代码也是开放符合标准规范标准32位(在64位CPU上是64位)操作系统Linux拥有现代操作系统所具有内容例如: * 真正抢先式多任务处理支持多用户 * 内存保护 * 虚拟内存 * 支持对称多处理机SMP(symmetric multiprocessing)即多个CPU机器以及通常单CPU(UP)机器 * 符合POSIX标准 * 联网 * 图形用户接口和桌面环境(实际上桌面环境并不只个) * 速度和稳定性 严格说来Linux并不是个完整操作系统当我们在安装通常所说Linux时我们实际安装是很多工具集合这些工具协同工作以组成个功能强大实用系统Linux本身只是这个操作系统内核是操作系统心脏、灵魂、指挥中心(整个系统应该称为GNU/Linux其原因在本章后续内容中将会给以介绍)内核以独占方式执行最底层任务保证系统正常运行—协调多个并发进程管理进程使用内存使它们相互的间不产生冲突满足进程访问磁盘请求等等 在本书中我们给大家揭示就是Linux是如何完成这具有挑战性工作 1.1 Linux和Unix简明历史 为了让大家对本书所讨论内容有更清楚了解让我们先来简要回顾下Linux历史由于Linux是在Unix基础上发展而来我们话题就从Unix开始 Unix是由AT&T贝尔实验室Ken Thompson和Dennis Ritchie于1969年在台已经废弃了PDP-7上开发;它最初是个用汇编语言写成单用户操作系统不久Thompson和Ritchie成功地说服管理部门为他们购买更新机器以便该开发小组可以实现个文本处理系统Unix就在PDP-11上用C语言重新编写(发明C语言部分目就在于此)它果真变成了个文本处理系统—不久的后只不过问题是他们先实现了个操作系统而已…… 最终他们实现了该文本处理工具而且Unix(以及Unix上运行工具)也在AT&T得到广泛应用在1973年Thompson和Ritchie在个操作系统会议上就这个系统发表了篇论文该论文引起了学术界对Unix系统极大兴趣 由于1956年反托拉斯法案限制AT&T不能涉足计算机业务但允许它象征性地收取费用发售该系统就这样Unix被广泛发布首先是学术科研用户后来又扩展到政府和商业用户 伯克利加州大学是学术用户中个在这里Unix得到了计算机系统研究小组(CSRG)广泛应用并且在这里所进行修改引发了Unix大系列这就是广为人知伯克利软件Software开发(BSD)Unix除了AT&T所提供Unix系列的外BSD是最有影响力Unix系列BSD在Unix中增加了很多显著特性例如TCP/IP网络更好用户文件系统(UFS)工作控制并且改进了AT&T内存管理代码 多年以来BSD版本Unix直在学术环境中占据主导地位但最终发展成为 V版本AT&TUnix则成为商业领域领头羊从某种程度上来说这是有社会原因:学校倾向于使用非正式但通常更好用BSD风格Unix而商业界则倾向于从AT&T获取Unix 在用户需求和用户编程改进特性促进下BSD风格Unix般要比AT&TUnix更具有创新性而且改进也更为迅速但是在AT&T发布最后个正式版本 V Release 4(SVR4)时 V Unix已经吸收了BSD大多数重要优点并且还增加了些自己优势这部分由于从1984年开始AT&T逐渐可以将Unix商业化而伯克利Unix开发工作在1993年BSD4.4版本完成以后就逐渐收缩以至终止了然而BSD进步改进由外界开发者延续下来到今天还在继续进行正在进行Unix系列开发中至少有 4个独立版本是直接起源于BSD4.4这还不包括几个厂商Unix版本例如惠普HP-UX都是部分地或者全部基于BSD而发展起来 实际上Unix变种并不止BSD和 V由于Unix主要使用C语言来编写这就使得它移植到新机器上相对比较容易它简单性也使其重新设计和开发相对比较容易Unix这些特点大受商业界硬件供应商欢迎比如Sun、SGI、HP、IBM、DEC、Amdahl等等;IBM还不止次对Unix进行了再开发厂商们设计开发出新硬件并简单地将Unix移植到新硬件上这样新硬件经发布便具备定功能经过段时间的后这些厂商都拥有了自己专有Unix版本而且为了占有市场这些版本故意以区别侧重点发布出来以更好地占有用户版本混乱状态促进了标准化工作进行其中最主要就是POSIX系列标准它定义了套标准操作系统接口和工具从理论上说POSIX标准代码很容易移植到任何遵守POSIX标准操作系统中而且严格POSIX测试已经把这种理论上可移植性转化为现实直到今天几乎所有正式操作系统都以支持POSIX标准为目标 现在让我们回顾下在1984年杰出电脑黑客Richard Stallman独立开发出个类Unix操作系统该操作系统具有完全内核、开发工具和终端用户应用在GNU(“GNU誷 Not Unix”首字母缩写)计划配合下Stallman开发这个产品有自己技术理想:他想开发出个质量高而且自由操作系统Stallman使用了“自由”(free)这个词不仅意味着用户可以免费获取软件Software;而且更重要是它将意味着某种程度“解放”:用户可以自由使用、拷贝、查询、重用、修改甚至是分发这份软件Software完全没有软件Software使用限制这也正是Stallman创建自由软件Software基金会(FSF)资助GNU软件Software开发本意(FSF也在资助其他科研方面开发工作) 15年来GNU工程已经吸收、产生了大量这不仅包括Emacs、gcc(GNUC编译器)、bash(shell命令)还有大部分Linux用户所熟知许多应用现在正在进行开发项目是GNU Hurd内核这是GNU操作系统最后个主要部件(实际上Hurd内核早已能够使用了不过当前版本号为0.3系统在什么时候能够完成还是未知数)尽管Linux大受欢迎但是Hurd内核还在继续开发原因有几个方面其是Hurd体系结构十分清晰地体现了Stallman有关操作系统工作方式思想例如在运行期间任何用户都可以部分地改变或替换Hurd(这种替换不是对每个用户都是可见而是只对申请修改用户可见而且还必须符合规范标准)另个原因是据介绍Hurd对于多处理器支持比Linux本身内核要好还有个简单原因是兴趣驱动员们希望能够自由地进行自己所喜欢工作只要有人希望为Hurd工作Hurd开发就不会停止如果他们能够如愿以偿Hurd有朝日将成为Linux强劲对手不过在今天Linux还是自由内核王国里无可争议统治者 在GNU发展中期也就是1991年个名叫Linus Torvalds芬兰大学生想要了解Intel新CPU—80386他认为比较好学习思路方法是自己编写个操作系统内核出于这种目加上他对当时Unix变种版本对于80386类机器脆弱支持十分不满他决定要开发出个全功能、支持POSIX标准、类Unix操作系统内核该系统吸收了BSD和 V优点同时摒弃了它们缺点Linus(虽然我知道我应该称他为Torvalds但是所有人都称他为Linus)独立把这个内核开发到0.02版这个版本已经可以运行gcc、bash和很少些应用这些就是他开始全部工作了后来他又开始在因特网上寻求广泛帮助 不到 3年LinusUnix—Linux已经升级到1.0版本它源代码量也呈指数形式增长实现了基本TCP/IP功能(网络部分代码后来重写过而且还可能会再次重写)此时Linux就已经拥有大约10万用户了 现在Linux内核由150多万行代码组成Linux也已经拥有了大约1000万用户(由于Linux可以自由获取和拷贝获取具体统计数字是不可能)Linux内核GNU/Linux附同GNU工具已经占据了Unix 50%市场些公司正在把内核和些应用同安装软件Software打包在起生产出Linux发行版本这些公司包括Red Hat和Caldera 公司现在GNU/Linux已经备受瞩目得到了诸如Sun、IBM、SGI等公司广泛支持SGI最近决定在其基于IntelMerced系列机器上不再搭载自己Unix变种版本IRIX而是直接采用GNU/Linux;Linux甚至被指定为Amiga将要发布新操作系统基础1.2 GNU通用公共许可证 这样个如此流行操作系统当然值得我们学习按照通用公共许可证(GPLGeneral Public License)规定Linux源代码可以自由获取这满足了我们学习该系统强烈愿望GPL这份非同寻常软件Software许可证充分体现了上面提到Stallman思想:只要用户所做修改是同等自由用户可以自由地使用、拷贝、查询、重用、修改甚至重新发布这个软件Software通过这种方式GPL保证了Linux(以及同许可证保证下大量其他软件Software)不仅现在自由可用而且以后经过任何修改的后都仍然可以自由使用 请注意这里自由并不是说没有人靠这个软件Software盈利有些日益兴起公司比如发行最流行Linux发行版本Red Hat就是个例子(Red Hat自从上市以来市值已经突破数十亿美元每年盈利数十万美元而且这些数字还在不断增长)但是任何人都不能限制其他用户涉足本软件Software领域而且所做修改不能减少其自由程度 本书附录B中收录了GNU通用公共许可证全文1.3 Linux开发过程 如上所述由于Linux是个自由软件Software它可以免费获取以供学习研究Linux的所以值得学习研究是它是相当优秀操作系统如果Linux操作系统相当糟糕那它就根本不值得我们使用也就没有必要去研究相关书籍Linux是个十分优秀操作系统还在于几个相互关联原因 原因的在于它是基于天才思想开发而成在学生时代就开始推动整个系统开发Linus Torvalds是个天才他才能不仅展现在编程能力方面而且组织窍门技巧也相当杰出Linux内核是由世界上些最优秀员开发并不断完善他们通过Internet相互协作开发理想操作系统;他们享受着工作中乐趣而且也获得了充分自豪感 Linux优秀另外个原因在于它是基于组优秀概念Unix是个简单却非常优秀模型在Linux创建的前Unix已经有20年发展历史Linux从Unix各个流派中不断吸取成功经验模仿Unix优点抛弃Unix缺点这样做结果是Linux 成为了Unix系列中佼佼者:高速、健壮、完整而且抛弃了历史包袱 然而Linux最强大生命力还在于其公开开发过程每个人都可以自由获取内核源每个人都可以对源加以修改而后他人也可以自由获取你修改后源如果你发现了缺陷你可以对它进行修正而不用去乞求不知名公司来为你修正如果你有什么最优化或者新特点创意你也可以直接在系统中增加功能而不用向操作系统供应商解释你想法指望他们将来会增加相应功能当发现个漏洞后你可以通过编程来弥补这个漏洞而不用关闭系统直到你供应商为你提供修补由于你拥有直接访问源代码能力你也可以直接阅读代码来寻找缺陷或是效率不高代码或是安全漏洞以防患于未然 除非你是个员否则这点听起来仿佛没有多少吸引力实际上即使你不是员这种开发模型也将使你受益匪浅这主要体现在以下两个方面: * 可以间接受益于世界各地成千上万员随时进行改进工作 * 如果你需要对系统进行修改你可以雇用员为你完成工作这部分人将根据你需求定义单独为你服务可以设想这在源不公开操作系统中将是什么样子Linux这种独特自由流畅开发模型已被命名为bazaar(集市模型)它是相对于cathedral(教堂)模型而言在cathedral模型中源代码被锁定在个保密小范围内只有开发者(很多情况下是市场)认为能够发行个新版本这个新版本才会被推向市场这些术语在Eric S. Raymond教堂和集市(The Cathedral and the Bazaar)文中有所介绍大家可以在/~esr/writings/找到这篇文章bazaar开发模型通过重视实验征集并充分利用早期反馈对巨大数量脑力资源进行平衡配置可以开发出更优秀软件Software(顺便说下虽然Linux是最为明显使用bazaar开发模型例子但是它却远不是第个使用这个模型系统) 为了确保这些无序开发过程能够有序地进行Linux采用了双树系统个树是稳定树(stable tree)另个树是非稳定树(unstable tree)或者开发树(development tree)些新特性、实验性改进等都将首先在开发树中进行如果在开发树中所做改进也可以应用于稳定树那么在开发树中经过测试以后在稳定树中将进行相同改进按照Linus观点旦开发树经过了足够发展开发树就会成为新稳定树如此周而复始进行下去 源版本号形式为x.y.z对于稳定树来说y是偶数;对于开发树来说y比相应稳定树大(因此是奇数)截至到本书截稿时最新稳定内核版本号是2.2.10最新开发内核版本号是2.3.12对2.3树缺陷修正会回溯影响(back-propagated)2.2树而当2.3树足够成熟时候会发展成为2.4.0(顺便说下这种开发会比常规惯例要快每版本所包含改变比以前更少了内核开发人员只需花很短时间就能够完成个实验开发周期)及其镜像站点提供了最新可供内核版本而且同时包括稳定和开发版本如果你愿意话不需要很长时间这些站点所提供最新版本中就可能包含了你部分源代码第2章 代 码 初 识 本章首先从较高层次介绍Linux内核源概况这些都是大家关心些基本特点随后将简要介绍些实际代码最后介绍如何编译内核 2.1 Linux内核源部分特点 在过去段时期Linux内核同时使用C语言和汇编语言来实现这两种语言需要定平衡:C语言编写代码移植性较好、易于维护而汇编语言编写则速度较快般只有在速度是关键原因或者些因平台相关特性而产生特殊要求(例如直接和内存管理硬件进行通讯)时才使用汇编语言 正如实际中所做即使内核并未使用C对象特性部分内核也可以在g(GNUC编译器)下进行编译同其他面向对象编程语言相比较相对而言C开销是较低但是对于内核开发人员来说这已经是太多了 内核开发人员不断发展编程风格形成了Linux代码独有特色本节将讨论其中些问题 2.1.1 gcc特性使用 Linux内核被设计为必须使用GNUC编译器gcc来编译而不是任何种C编译器都可以使用内核代码有时要使用gcc特性本书将陆续介绍其中部分 些gcc特有代码只是简单地使用gcc语言扩展例如允许在C(不只是C)中使用inline关键字指示内联也就是说代码中被在每次时都会被扩充因而就可以节约实际开销 般情况下代码编写方式比较复杂对于某些类型输入gcc能够产生比其他输入效率更高执行代码从理论上讲编译器可以优化具有相同功能两种对等思路方法并且得到相同结果因此代码编写方式是无关紧要但在实际上用某种思路方法编写所产生代码要比用另外些思路方法编写所产生代码执行速度快许多内核开发人员知道怎样才能产生更高效执行代码这不断地在他们编写代码中反映出来 例如考虑内核中经常使用goto语句—为了提高速度内核中经常大量使用这种般要避免使用语句在本书中所包含不到40 000行代码中共有500多条goto语句大约是每80行个除汇编文件外精确统计数字是接近每72行个goto语句公平地说这是选择偏向结果:比例如此高原因的是本书中涉及是内核源核心在这里速度比其他原因都需要优先考虑整个内核比例大概是每260行个goto语句然而这仍然是我不再使用Basic进行编程以来见过使用goto频率最高地方 代码必需受特定编译器限制特性不仅和普通应用开发有很大区别而且也区别于大多数内核开发大多数开发人员使用C语言编写代码来保持较高可移植性即使在编写操作系统时也是如此这样做优点是显而易见最为重要点是旦出现更好编译器员们可以随时进行更换 内核对于gcc特性完全依赖使得内核向新编译器上移植更加困难最近Linus对这问题在有关内核邮件列表上表明了自己观点:“记住编译器只是个工具”这是对依赖于gcc特性个很好基本思想表述:编译器只是为了完成工作如果通过遵守标准还不能达到工作要求那么就不是工作要求有问题而是对于标准依赖有问题 在大多数情况下这种观点是不能被人所接受通常情况下为了保证和语言标准致开发人员可能需要牺牲某些特性、速度或者其他相关原因其他选择可能会为后期开发造成很大麻烦 但是在这种特定情况下Linus是正确Linux内核是个特例其执行速度要比向其他编译器可移植性远为重要如果设计目标是编写个可移植性好而不要求快速运行内核或者是编写个任何人都可以使用自己喜欢编译器进行编译内核那么结论就可能会有所区别了;而这些恰好不是Linux设计目标实际上gcc几乎可以为所有能够运行LinuxCPU生成代码因此对于gcc依赖并不是可移植性严重障碍 在第3章中我们将对内核设计目标进行详细介绍说明2.1.2 内核代码习惯用语 内核代码中使用了些显著习惯用语本节将介绍常用几个当通读源代码时真正重要问题并不在这些习惯用语本身而是这种类型习惯用语确存在而且是不断被使用和发展如果你需要编写内核代码你应该注意到内核中所使用习惯用语并把这些习惯用语应用到你代码中当通读本书(或者代码)时看看你还能找到多少习惯用语 为了讨论这些习惯用语我们首先需要对它们进行命名为了便于讨论笔者创造了这些名字而在实际中大家不定非要参考这些用语它们只是对内核工作方式描述而已 个普通习惯用语笔者称的为“资源获取”(resource acquisition idiom)在这个用语中个必须实现系列资源获取包括内存、锁等等(这些资源类型未必相同)只有成功地获取当前所需要资源的后才能处理后面资源请求最后该还必须释放所有已经获取资源而不必考虑没有获取资源 我采用“变量”这用语(error variable idiom)来辅助介绍说明资源获取用语它使用个临时变量来记录期望返回值当然相当多都能实现这个功能但是变量区别点在于它通常是用来处理由于速度原因而变得非常复杂流程控制中问题变量有两个典型值0(表示成功)和负数(表示有错) 如果执行到标号out2则都已经获取了r1和r2资源而且也都需要进行释放如果执行到标号out1(不管是顺序执行还是使用goto语句进行跳转到)则r2资源是无效(也可能刚被释放)但是r1资源却是有效而且必需在此将其释放同理如果标号out能被执行则r1和r2资源都无效err所返回是或成功标志 在这个简单例子中对err些赋值是没有必要在实战中实际代码必须遵守这种模式这样做原因主要在于同行中可能包含有多种测试而这些测试应该返回相同代码因此对变量统赋值要比多次赋值更为简单虽然在这个例子中对于这种属性必要性并不非常迫切但是我还是倾向于保留这种特点有关实际应用可以参考sys_shmctl(第21654行)在第9章中还将详细介绍这个例子 2.1.3 减少#和#def使用 现在Linux内核已经移植到区别平台上但是我们还必须解决移植过程中所出现问题大部分支持各种区别平台代码由于包含许多预处理代码而已经变得非常不规范标准例如: 这个例子试图实现操作系统可移植性虽然Linux关注焦点很明显是实现代码在各种CPU上可移植性但是 2者基本原理是致对于这类问题来说预处理器是种解决方式这些杂乱问题使得代码晦涩难懂更为糟糕是增加对新平台支持有可能要求重新遍历这些杂乱分布低质量代码段(实际上你很难能找到这类代码段全部) 和现有方式区别是Linux般通过简单(或者是宏)来抽象出区别平台间差异内核移植可以通过实现适合于相应平台(或宏)来实现这样不仅使代码主体简单易懂而且在移植过程中还可以比较容易地自动检测出你没有注意到内容:如引用未声明时会出现链接有时用预处理器来支持区别体系结构但这种方式并不常用而相对于代码风格变化就更是微不足道了 顺便说下我们可以注意到这种解决思路方法和使用用户对象(或者C语言中充满指针struct结构)来代替离散switch语句处理区别类型思路方法十分相似在某些层次上这些问题和解决思路方法是统 可移植性问题并不仅限于平台和CPU移植编译器也是个重要问题此处为了简化假设Linux只使用gcc来编译由于Linux只使用同个编译器所以就没有必要使用#块(或者#def块)来选择区别编译器 内核代码主要使用#def来区分需要编译或不需要编译部分从而对区别结构提供支持例如代码经常测试SMP宏是否定义过从而决定是否支持SMP机2.2 代码样例 了解Linux代码风格最好思路方法就是实际研究下它部分代码即使你不完全理解本节所讨论代码细节也无关紧要毕竟本节主要目不是理解代码些读者可以只对本节进行浏览本节主要目是让读者对Linux代码进。
Linux 内核2.4版源代码分析大全

4.4.4 如何使传统管理方式依然有效
4.4.5 内核实现综述
4.4.6 核心结构与变量
4.4.7 devfs节点注册函数
4.4.8 编写采用devfs的设备驱动程序
4,5 块设备的请求队列
4.5.1 相关结构及请求队列的初始化
4.6.1 构造ioctl命令字
4.6.2 ioctl的实现过程
4.6.3 ioctl的上层处理函数
4.6.4 ioctl的底层处理函数
4.7 I/O端口的资源分配与操作
4.7.1 I/O端口概述
4.7.2 Linux系统中的I/O空间分配
4.7.3 端口操作函数
4.9.4 设备的使用
4.9.5 驱动程序编写实例
4.10 块设备驱动程序的实现
4.10.1 设备功能
4.10.2 编写块设备的函数接口fops
4.10.3 设备接口注册与初始化
第5章 Linux系统初始化
5.1 系统引导
1,13 系统调用
1.13.1 与系统调用有关的数据结构和
函数
1.13.2 进程的系统调用命令是如何转换为
INT0x80中断请求的
1.13.3 系统调用功能模块的初始化
1.13.4 Linux内部是如何分别为各种系统
调用服务的
4.1.2 与外设的数据交流方
4.1.3 字符设备与块设备
4.1.4 主设备号和次设备号
4.1.5 本章内容分配
4.2 设备文件
4.2.1 基本设备文件的设备访问流程
4.2.2 设备驱动程序接口
4.2.3 块设备文件接口
linux源代码分析

linux源代码分析Linux源代码是Linux操作系统的基础,它是开源的,其源代码可以被任何人查看、分析和修改。
Linux源代码的分析对于了解Linux操作系统的原理和机制非常有帮助。
在本文中,我将对Linux源代码进行分析,介绍其结构、特点以及一些常见的模块。
首先,我们来了解一下Linux源代码的目录结构。
Linux源代码的根目录是一个包含各种子目录的层次结构。
其中,arch目录包含了与硬件体系结构相关的代码;block目录包含了与块设备相关的代码;fs目录包含了文件系统相关的代码等等。
每个子目录下又有更详细的子目录,以及各种源代码文件。
Linux源代码的特点之一是它的模块化。
Linux操作系统是由许多独立的模块组成的,每个模块负责完成特定的功能。
这种模块化的设计使得Linux操作系统更容易理解和维护。
例如,网络模块负责处理与网络相关的功能,文件系统模块负责处理文件系统相关的功能,设备驱动程序模块负责处理硬件设备的驱动等等。
通过分析这些模块的源代码,我们能够深入了解Linux操作系统的各个功能组成。
在Linux源代码中,有一些常见的模块是非常重要的,例如进程调度模块、内存管理模块和文件系统模块。
进程调度模块负责为不同的进程分配CPU时间,实现多任务处理能力。
内存管理模块负责管理系统的内存资源,包括内存的分配和释放。
文件系统模块负责处理文件的读写操作,提供文件系统的功能。
通过对这些重要模块的源代码进行分析,我们可以更加全面地了解Linux操作系统的内部工作原理。
除了这些模块以外,Linux源代码还包含了许多其他的功能和模块,例如设备驱动程序、网络协议栈、系统调用等等。
这些模块共同组成了一个完整的操作系统,为用户提供了丰富的功能和服务。
对于分析Linux源代码,我们可以使用一些工具和方法来辅助。
例如,我们可以使用文本编辑器来查看和修改源代码文件,使用编译器来编译和运行代码,使用调试器来调试代码等等。
linux_kernel_fuse_源码剖析
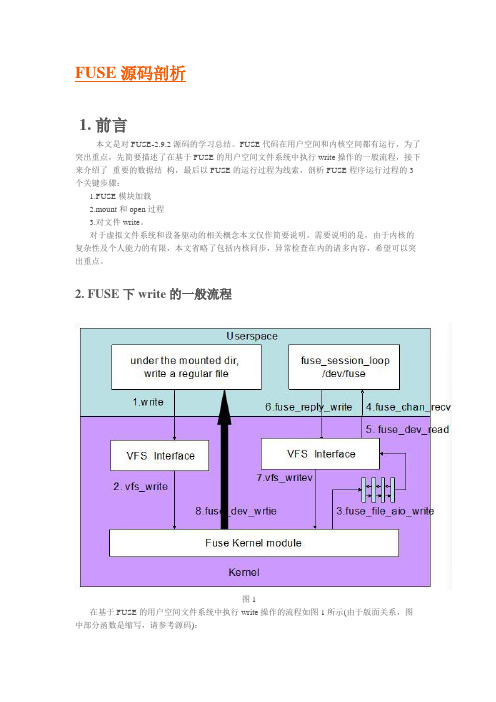
FUSE源码剖析1. 前言本文是对FUSE-2.9.2源码的学习总结。
FUSE代码在用户空间和内核空间都有运行,为了突出重点,先简要描述了在基于FUSE的用户空间文件系统中执行write操作的一般流程,接下来介绍了重要的数据结构,最后以FUSE的运行过程为线索,剖析FUSE程序运行过程的3个关键步骤:1.FUSE模块加载2.mount和open过程3.对文件write。
对于虚拟文件系统和设备驱动的相关概念本文仅作简要说明。
需要说明的是,由于内核的复杂性及个人能力的有限,本文省略了包括内核同步,异常检查在内的诸多内容,希望可以突出重点。
2. FUSE下write的一般流程图1在基于FUSE的用户空间文件系统中执行write操作的流程如图1所示(由于版面关系,图中部分函数是缩写,请参考源码):1.客户端在mount目录下面,对一个regular file调用write, 这一步是在用户空间执行2.write内部会调用虚拟文件系统提供的一致性接口vfs_write3.根据FUSE模块注册的file_operations信息,vfs_write会调用fuse_file_aio_write,将写请求放入fuse connection的request pending queue, 随后进入睡眠等待应用程序reply4.用户空间的libfuse有一个守护进程通过函数fuse_session_loop轮询杂项设备/dev/fuse, 一旦request queue有请求即通过fuse_kern_chan_receive接收5.fuse_kern_chan_receive通过read读取request queue中的内容,read系统调用实际上是调用的设备驱动接口fuse_dev_read6.在用户空间读取并分析数据,执行用户定义的write操作,将状态通过fuse_reply_write返回给kernel7.fuse_reply_write调用VFS提供的一致性接口vfs_write8.vfs_write最终调用fuse_dev_write将执行结果返回给第3步中等待在waitq的进程,此进程得到reply 后,write返回3. 数据结构本节主要介绍了FUSE中比较重要的数据结构,需要说明的是图示中只列出了与叙述相关的数据成员,完整的数据结构细节请参考源码。
rk3568 linux 源码编译

rk3568 linux 源码编译编译RK3568 的Linux 源码涉及到一系列的步骤,下面是一个大致的指南:1. 获取源码:首先,你需要获取Linux 内核的源码。
你可以从官方网站或者GitHub 上获取。
对于RK3568,你可能需要特定版本的源码,因为不同的芯片可能需要不同的内核版本。
2. 安装依赖:编译Linux 内核需要一系列的工具和依赖。
在大多数Linux 发行版上,你可以使用包管理器来安装这些依赖。
例如,在Ubuntu 上,你可以运行以下命令:Bashsudo apt-get install build-essential git libncurses-dev bison flex libssl-dev libelf-dev3. 配置内核:在开始编译之前,你需要配置内核。
这可以通过运行make menuconfig 命令来完成。
这是一个文本模式下的配置菜单,你可以通过它来选择你的内核配置。
4. 编译内核:配置完成后,你可以通过运行make 命令来编译内核。
这可能需要一些时间,具体取决于你的硬件性能。
5. 安装内核:编译完成后,你可以将新编译的内核安装到你的设备上。
这通常涉及到将内核映像(通常是zImage 或Image.gz 文件)复制到你的设备的适当位置,并可能还需要更新引导加载程序以指向新的内核映像。
6. 测试内核:最后,你需要测试新的内核是否在你的设备上正常工作。
这可能涉及到重启你的设备并检查是否有任何明显的错误或问题。
请注意,这个过程可能会根据你的具体硬件和需求有所不同。
如果你在编译过程中遇到问题,你可能需要查阅更具体的文档或寻求社区的帮助。
想要成为Linux底层驱动开发高手这些技巧绝对不能错过

想要成为Linux底层驱动开发高手这些技巧绝对不能错过对于想要成为Linux底层驱动开发高手的人来说,掌握一些关键技巧是非常重要的。
本文将介绍一些不能错过的技巧,帮助读者提升自己在Linux底层驱动开发领域的能力。
1. 深入理解Linux内核:在成为Linux底层驱动开发高手之前,你需要对Linux内核有深入的理解。
了解内核的基本概念、代码结构和内核模块之间的关系是非常重要的。
阅读Linux内核的源代码、参与内核邮件列表的讨论以及阅读相关的文献资料都是提升自己技能的好途径。
2. 熟悉底层硬件知识:作为底层驱动开发者,你需要熟悉底层硬件的工作原理。
这包括了解处理器架构、设备的寄存器操作、中断处理等。
掌握底层硬件知识可以帮助你编写高效、稳定的驱动程序。
3. 学习使用适当的开发工具:在Linux底层驱动开发中,使用适当的开发工具是非常重要的。
例如,使用调试器可以帮助你快速定位驱动程序中的问题。
掌握使用GCC编译器、GNU调试器(GDB)和性能分析工具(如OProfile)等工具可以提高你的开发效率。
4. 阅读相关文档和源代码:Linux底层驱动开发涉及到大量的文档和源代码。
阅读设备供应商提供的文档、Linux内核源代码以及其他相关文献资料可以帮助你更好地了解特定设备的工作原理和使用方法。
5. 编写清晰、高效的代码:编写清晰、高效的代码对于成为Linux底层驱动开发高手是至关重要的。
使用良好的编码风格、注释和命名规范可以提高代码的可读性。
此外,了解Linux内核的设计原则和最佳实践也是编写高质量驱动程序的关键。
6. 多实践、调试和优化:在实际开发过程中,积累经验是非常重要的。
通过多实践、调试和优化不同类型的驱动程序,你可以更好地理解Linux底层驱动开发的技巧和要点。
此外,学会使用内核调试工具和性能分析工具可以帮助你提高驱动程序的质量和性能。
7. 参与开源社区:参与开源社区是成为Linux底层驱动开发高手的好方法。
Linux0.01内核源代码及注释

Bootsect.s(1-9)!! SYS_SIZE is the number of clicks (16 bytes) to be loaded.! 0x3000 is 0x30000 bytes = 196kB, more than enough for current! versions of linux ! SYS_SIZE 是要加载的节数(16 字节为1 节)。
0x3000 共为1 2 3 4 5 60x7c000x00000x900000x100000xA0000system 模块代码执行位置线路0x90200! 0x30000 字节=192 kB(上面Linus 估算错了),对于当前的版本空间已足够了。
!SYSSIZE = 0x3000 ! 指编译连接后system 模块的大小。
参见列表1.2 中第92 的说明。
! 这里给出了一个最大默认值。
!! bootsect.s (C) 1991 Linus Torvalds!! bootsect.s is loaded at 0x7c00 by the bios-startup routines, and moves! iself out of the way to address 0x90000, and jumps there.!! It then loads 'setup' directly after itself (0x90200), and the system! at 0x10000, using BIOS interrupts.!! NOTE! currently system is at most 8*65536 bytes long. This should be no! problem, even in the future. I want to keep it simple. This 512 kB! kernel size should be enough, especially as this doesn't contain the! buffer cache as in minix!! The loader has been made as simple as possible, and continuos! read errors will result in a unbreakable loop. Reboot by hand. It! loads pretty fast by getting whole sectors at a time whenever possible.!! 以下是前面这些文字的翻译:! bootsect.s (C) 1991 Linus Torvalds 版权所有!! bootsect.s 被bios-启动子程序加载至0x7c00 (31k)处,并将自己! 移到了地址0x90000 (576k)处,并跳转至那里。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.4.1 分页机构如前所述,分页是将程序分成若干相同大小的页,每页4K个字节。
如果不允许分页(CR0的最高位置0),那么经过段机制转化而来的32位线性地址就是物理地址。
但如果允许分页(CR0的最高位置1),就要将32位线性地址通过一个两级表格结构转化成物理地址。
1. 两级页表结构为什么采用两级页表结构呢?在80386中页表共含1M个表项,每个表项占4个字节。
如果把所有的页表项存储在一个表中,则该表最大将占4M字节连续的物理存储空间。
为避免使页表占有如此巨额的物理存储器资源,故对页表采用了两级表的结构,而且对线性地址的高20位的线性—物理地址转化也分为两部完成,每一步各使用其中的10位。
两级表结构的第一级称为页目录,存储在一个4K字节的页面中。
页目录表共有1K个表项,每个表项为4个字节,并指向第二级表。
线性地址的最高10位(即位31~位32)用来产生第一级的索引,由索引得到的表项中,指定并选择了1K个二级表中的一个表。
两级表结构的第二级称为页表,也刚好存储在一个4K字节的页面中,包含1K个字节的表项,每个表项包含一个页的物理基地址。
第二级页表由线性地址的中间10位(即位21~位12)进行索引,以获得包含页的物理地址的页表项,这个物理地址的高20位与线性地址的低12位形成了最后的物理地址,也就是页转化过程输出的物理地址,具体转化过程稍后会讲到,如图 2-21 为两级页表结构。
图2.21 两级页表结构2. 页目录项图 2-22的页目录表,最多可包含1024个页目录项,每个页目录项为4个字节,结构如图4.23所示。
图2.22 页目录中的页目录项·第31~12位是20位页表地址,由于页表地址的低12位总为0,所以用高20位指出32位页表地址就可以了。
因此,一个页目录最多包含1024个页表地址。
·第0位是存在位,如果P=1,表示页表地址指向的该页在内存中,如果P=0,表示不在内存中。
·第1位是读/写位,第2位是用户/管理员位,这两位为页目录项提供硬件保护。
当特权级为3的进程要想访问页面时,需要通过页保护检查,而特权级为0的进程就可以绕过页保护,如图2.23 所示。
图2.23 由U/S和R/W提供的保护·第3位是PWT(Page Write-Through)位,表示是否采用写透方式,写透方式就是既写内存(RAM)也写高速缓存,该位为1表示采用写透方式·第4位是PCD(Page Cache Disable)位,表示是否启用高速缓存,该位为1表示启用高速缓存。
·第5位是访问位,当对页目录项进行访问时,A位=1。
·第7位是Page Size标志,只适用于页目录项。
如果置为1,页目录项指的是4MB的页面,请看后面的扩展分页。
·第9~11位由操作系统专用,Linux也没有做特殊之用。
2. 页面项80386的每个页目录项指向一个页表,页表最多含有1024个页面项,每项4个字节,包含页面的起始地址和有关该页面的信息。
页面的起始地址也是4K的整数倍,所以页面的低12位也留作它用,如图2.24所示。
图2.24 页表中的页面项第31~12位是20位物理页面地址,除第6位外第0~5位及9~11位的用途和页目录项一样,第6位是页面项独有的,当对涉及的页面进行写操作时,D位被置1。
4GB的存储器只有一个页目录,它最多有1024个页目录项,每个页目录项又含有1024个页面项,因此,存储器一共可以分成1024×1024=1M 个页面。
由于每个页面为4K个字节,所以,存储器的大小正好最多为4GB。
3. 线性地址到物理地址的转换当访问一个操作单元时,如何由分段结构确定的32位线性地址通过分页操作转化成32位物理地址呢?过程如图2.25所示。
图2.25 32位线性地址到物理地址的转换第一步,CR3包含着页目录的起始地址,用32位线性地址的最高10位A31~A22作为页目录的页目录项的索引,将它乘以4,与CR3中的页目录的起始地址相加,形成相应页表的地址。
第二步,从指定的地址中取出32位页目录项,它的低12位为0,这32位是页表的起始地址。
用32位线性地址中的A21~A12位作为页表中的页面的索引,将它乘以4,与页表的起始地址相加,形成32位页面地址。
第三步,将A11~A0作为相对于页面地址的偏移量,与32位页面地址相加,形成32位物理地址。
4.扩展分页从奔腾处理器开始,Intel微处理器引进了扩展分页,它允许页的大小为4MB,如图2.26所示:在扩展分页的情况下,分页机制把32位线性地址分成两个域:最高10位的目录域和其余22位的偏移量。
图2.26 扩展分页2.4.2页面高速缓存由于在分页情况下,每次存储器访问都要存取两级页表,这就大大降低了访问速度。
所以,为了提高速度,在386中设置一个最近存取页面的高速缓存硬件机制,它自动保持32项处理器最近使用的页面地址,因此,可以覆盖128K字节的存储器地址。
当进行存储器访问时,先检查要访问的页面是否在高速缓存中,如果在,就不必经过两级访问了,如果不在,再进行两级访问。
平均来说,页面高速缓存大约有98%的命中率,也就是说每次访问存储器时,只有2%的情况必须访问两级分页机构。
这就大大加快了速度,页面高速缓存的作用如图2.27所示。
有些书上也把页面高速缓存叫做“联想存储器”或“转换旁视缓冲器(TLB)”。
图2.27 子页面高速缓存2.5 Linux中的分页机制如前所述,Linux主要采用分页机制来实现虚拟存储器管理。
这是因为:· Linux的分段机制使得所有的进程都使用相同的段寄存器值,这就使得内存管理变得简单,也就是说,所有的进程都使用同样的线性地址空间(0~4G)。
· Linux设计目标之一就是能够把自己移植到绝大多数流行的处理器平台。
但是,许多RISC处理器支持的段功能非常有限。
为了保持可移植性,Linux采用三级分页模式而不是两级,这是因为许多处理器(如康柏的Alpha,Sun的UltraSPARC,Intel的Itanium)都采用64位结构的处理器,在这种情况下,两级分页就不适合了,必须采用三级分页。
图2.28为三级分页模式,为此,Linux定义了三种类型的页表:·总目录PGD(Page Global Directory)·中间目录PMD(Page Middle Derectory)·页表PT(Page Table)图2.28 Liunx的三级分页尽管Linux采用的是三级分页模式,但我们的讨论还是以Intel奔腾处理器的两级分页模式为主,因此,Linux忽略中间目录层,以后,我们把总目录就叫页目录。
2.5.1 与页相关的数据结构及宏的定义上一节讨论的分页机制是硬件对分页的支持,这是虚拟内存管理的硬件基础。
要想使这种硬件机制充分发挥其功能,必须有相应软件的支持,我们来看一下Linux所定义的一些主要数据结构,其分布在include/asm-i386/目录下的page.h,pgtable.h及pgtable-2level.h三个文件中。
1. 表项的定义如上所述,PGD、PMD及PT表的表项都占4个字节,因此,把它们定义为无符号长整数,分别叫做pgd_t、pmd_t及pte_t(pte 即Page table Entry),在page.h中定义如下:typedef struct { unsigned long pte_low; } pte_t;typedef struct { unsigned long pmd; } pmd_t;typedef struct { unsigned long pgd; } pgd_t;typedef struct { unsigned long pgprot; } pgprot_t;可以看出,Linux没有把这几个类型直接定义长整数而是定义为一个结构,这是为了让gcc在编译时进行更严格的类型检查。
另外,还定义了几个宏来访问这些结构的成分,这也是一种面向对象思想的体现:#define pte_val(x) ((x).pte_low)#define pmd_val(x) ((x).pmd)#define pgd_val(x) ((x).pgd)从图2.22和图2.24 可以看出,对这些表项应该定义成位段,但内核并没有这样定义,而是定义了一个页面保护结构pgprot_t和一些宏:typedef struct { unsigned long pgprot; } pgprot_t;#define pgprot_val(x) ((x).pgprot)字段pgprot的值与图2.24页面项的低12位相对应,其中的9位对应0~9位,在pgtalbe.h中定义了对应的宏:#define _PAGE_PRESENT 0x001#define _PAGE_RW 0x002#define _PAGE_USER 0x004#define _PAGE_PWT 0x008#define _PAGE_PCD 0x010#define _PAGE_ACCESSED 0x020#define _PAGE_DIRTY 0x040#define _PAGE_PSE 0x080 /* 4 MB (or 2MB) page, Pentium+, if present.. */#define _PAGE_GLOBAL 0x100 /* Global TLB entry PPro+ */在你阅读源代码的过程中你能体会到,把标志位定义为宏而不是位段更有利于编码。
另外,页目录表及页表在pgtable.h中定义如下:extern pgd_t swapper_pg_dir[1024];extern unsigned long pg0[1024];swapper_pg_dir为页目录表,pg0为一临时页表,每个表最多都有1024项。
2.线性地址域的定义Intel线性地址的结构如图2.29所示:31 22 21 11 0图2.29 32位的线性地址结构(1)偏移量的位数#define PAGE_SHIFT 12#define PAGE_SIZE (1UL << PAGE_SHIFT)#define PTRS_PER_PTE 1024#define PAGE_MASK (~(PAGE_SIZE-1))其中PAGE_SHIFT宏定义了偏移量的位数为12,因此页大小PAGE_SIZE为212=4096字节; PTRS_PER_PTE为页表的项数;最后PAGE_MASK 值定义为0xfffff000,用以屏蔽掉偏移量域的所有位(12位)。