高性能计算导论第二章PPT
合集下载
高性能计算导论课件-高性能计算导论-PPT文档资料

• 作业2:
– 任意选择一个演讲题目,谈谈你对该研究领域的理解 – 长度不限、鼓励原创观点
• 作业提交
– 9月10日,最后一节课上提交打印版
In+Lab@SYSU
3
智能规划
中山大学计算机软件所教授,博士生导师 吉林大学珠海学院计算机科学与技术系主任 中国计算机学会理事 中国计算机教育专业委员会秘书长 姜云飞 教授 中国计算机学会人工智能专业委员会自动推 理学组组长
高性能计算导论
超级计算系 数据科学与计算机学院 中山大学 2019年夏季学期
In+Lab@SYSU
1
课程时间表
In+Lab@SYSU
2
课程作业
• 作业1:
– – – – 写一个高性能计算的综述 定义、起源、分支、应用、最新研究方向等 请做好引用及提供参考文献 A4纸张、单栏、小4号宋体、4页以上
In+Lab@SYSU
4
机器学习辅助的进化计算方法
• • • • • • 詹志辉
副教授
2019年广东省自然科学杰出青年基金获得者 2019年中国高被引学者(计算机科学)入选者 2019年珠江科技新星人才计划项目入选者 2019年中国计算机学会(CCF)优秀博士论文奖 2019年广东省优秀博士学位论文奖 已发表学术论文40多篇,其中IEEE Transactions 等 SCI期刊论文13篇,ESI前1%高被引论文3篇,其中一 篇入选ESI 前0.1% Hot Paper.
李全忠
讲师
In+Lab@SYSU
7
数据密集型视觉计算
• 视觉计算、智能学习、大规模数据处理 • 教育部新世纪优秀人才支持计划入选者,广东省自然科 学杰出青年基金获得者,主持中山大学智能媒体计算实 验室 • 迄今共发表或录用论文70余篇(Proceeding of the IEEE论文1篇,IEEE TPAMI论文4 篇,IEEE TIP论文4 篇,IEEE TCSVT论文4篇,国际会议论文ICCV、CVPR 、NIPS、ACM Multimedia 20余篇) • 香港理工大学,访问教授 • 美国加州大学洛杉矶分校(UCLA),博士后研究员
高性能计算导论:并行计算性能评价

任务并行算法
如流水线技术、分治算法等,通过将任务划分为多个子任 务,分配给不同的处理单元并行执行,从而实现任务的快 速完成。
消息传递并行算法
如MPI(Message Passing Interface)算法,通过进程 间通信来协调不同处理单元上的任务执行,适用于分布式 内存系统。
算法优化策略与方法探讨
结果分析和改进建议
结果分析
对实验结果进行深入分析,找出性能 瓶颈和影响性能的关键因素。
改进建议
根据分析结果提出针对性的改进建议,如优 化算法、改进系统结构、提高硬件性能等。 同时,也可以对实验方法和流程进行反思和 改进,以提高评估的准确性和有效性。
05 案例分析:并行计算性能 评价实践
案例背景和目标设定
加速比
并行算法相对于串行算法 的执行速度提升倍数。
效率
用于衡量并行系统中处理 器利用率的指标,通常表 示为加速比与处理器数量 的比值。
可扩展性与规模性指标
1 2
等效性
在增加处理器数量时,保持问题规模和计算复杂 度不变的情况下,系统性能的提升能力。
弱可扩展性
在增加处理器数量的同时,增加问题规模,保持 每个处理器的负载不变,系统性能的提升能力。
功耗与能效比指标
功耗
01
并行计算系统在运行过程中的总功率消耗。
能效比
02
用于衡量并行计算系统每消耗一单位能量所能完成的计算量或
任务量的指标。
节能技术
03
采用低功耗处理器、动态电压频率调整、节能算法等技术降低
并行计算系统的功耗。
03 并行算法设计与优化策略
典型并行算法介绍及原理剖析
数据并行算法
如数组运算、矩阵乘法等,通过将数据划分为多个部分, 在多个处理单元上并行执行相同的操作来提高性能。
如流水线技术、分治算法等,通过将任务划分为多个子任 务,分配给不同的处理单元并行执行,从而实现任务的快 速完成。
消息传递并行算法
如MPI(Message Passing Interface)算法,通过进程 间通信来协调不同处理单元上的任务执行,适用于分布式 内存系统。
算法优化策略与方法探讨
结果分析和改进建议
结果分析
对实验结果进行深入分析,找出性能 瓶颈和影响性能的关键因素。
改进建议
根据分析结果提出针对性的改进建议,如优 化算法、改进系统结构、提高硬件性能等。 同时,也可以对实验方法和流程进行反思和 改进,以提高评估的准确性和有效性。
05 案例分析:并行计算性能 评价实践
案例背景和目标设定
加速比
并行算法相对于串行算法 的执行速度提升倍数。
效率
用于衡量并行系统中处理 器利用率的指标,通常表 示为加速比与处理器数量 的比值。
可扩展性与规模性指标
1 2
等效性
在增加处理器数量时,保持问题规模和计算复杂 度不变的情况下,系统性能的提升能力。
弱可扩展性
在增加处理器数量的同时,增加问题规模,保持 每个处理器的负载不变,系统性能的提升能力。
功耗与能效比指标
功耗
01
并行计算系统在运行过程中的总功率消耗。
能效比
02
用于衡量并行计算系统每消耗一单位能量所能完成的计算量或
任务量的指标。
节能技术
03
采用低功耗处理器、动态电压频率调整、节能算法等技术降低
并行计算系统的功耗。
03 并行算法设计与优化策略
典型并行算法介绍及原理剖析
数据并行算法
如数组运算、矩阵乘法等,通过将数据划分为多个部分, 在多个处理单元上并行执行相同的操作来提高性能。
高性能计算(HPC)ppt课件
• 2、了解我们能为用户做什么
a) 机群硬件系统搭建 b) 机群软件系统安装
4
如何做好HPC的销售工作
•Linpack 理论峰值计算 什么是Linpack?
是国际上主流测试HPC浮点运算能力的工具,影响其数值要素为:硬件、 软件及执行参数。 硬件:CPU、内存、网络 软件主要指:MPI 、数学库(函数库) 执行参数指:矩阵规模(计算一元N次方程矩阵,采用高斯消元法(就是 我们说的代入法),通常有100、1000、N即自定义三种。)
如何做好HPC的销售工作之应用 篇
•4、流体力学/分子动力学
主要应用软件:CFD(Ansys、Fluent)工程计算 软件
了解用户研究方向:流体材料、空气动力、 化学反应
了解关键词:并行效果高,动态负载均衡
CPU选型:advanced
内存选型:1、根据CPU
2、需要大内存
10
如何做好HPC的销售工作之应用 篇
了解关键词:并行效果低
CPU选型:advanced
内存选型:1、根据CPU
2、需要大内存
硬盘选型:I/O量大,SAS
网络选型:千兆网
12
如何做好HPC的销售工作之应用 篇
•6、理论化学计算
主要应用软件: NAMD+CHARMM;GROMACS;AMBER
了解用户研究方向:理论化学研究;材料计 算;分子
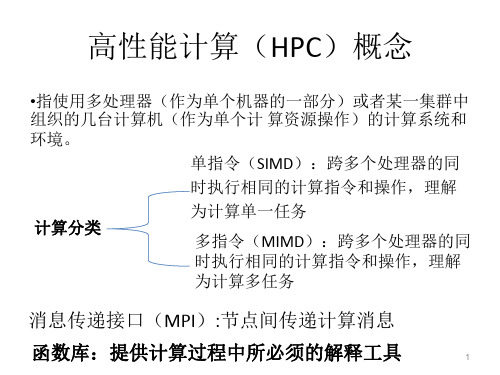
高性能计算(HPC)概念
•指使用多处理器(作为单个机器的一部分)或者某一集群中 组织的几台计算机(作为单个计 算资源操作)的计算系统和
环境。
单指令(SIMD):跨多个处理器的同
时执行相同的计算指令和操作,理解
计算分类
为计算单一任务
多指令(MIMD):跨多个处理器的同 时执行相同的计算指令和操作,理解 为计算多任务
a) 机群硬件系统搭建 b) 机群软件系统安装
4
如何做好HPC的销售工作
•Linpack 理论峰值计算 什么是Linpack?
是国际上主流测试HPC浮点运算能力的工具,影响其数值要素为:硬件、 软件及执行参数。 硬件:CPU、内存、网络 软件主要指:MPI 、数学库(函数库) 执行参数指:矩阵规模(计算一元N次方程矩阵,采用高斯消元法(就是 我们说的代入法),通常有100、1000、N即自定义三种。)
如何做好HPC的销售工作之应用 篇
•4、流体力学/分子动力学
主要应用软件:CFD(Ansys、Fluent)工程计算 软件
了解用户研究方向:流体材料、空气动力、 化学反应
了解关键词:并行效果高,动态负载均衡
CPU选型:advanced
内存选型:1、根据CPU
2、需要大内存
10
如何做好HPC的销售工作之应用 篇
了解关键词:并行效果低
CPU选型:advanced
内存选型:1、根据CPU
2、需要大内存
硬盘选型:I/O量大,SAS
网络选型:千兆网
12
如何做好HPC的销售工作之应用 篇
•6、理论化学计算
主要应用软件: NAMD+CHARMM;GROMACS;AMBER
了解用户研究方向:理论化学研究;材料计 算;分子
高性能计算(HPC)概念
•指使用多处理器(作为单个机器的一部分)或者某一集群中 组织的几台计算机(作为单个计 算资源操作)的计算系统和
环境。
单指令(SIMD):跨多个处理器的同
时执行相同的计算指令和操作,理解
计算分类
为计算单一任务
多指令(MIMD):跨多个处理器的同 时执行相同的计算指令和操作,理解 为计算多任务
高性能科学计算理论和方法全册配套课件

运行得快!!!
串行问题的处理方法
将串行程序改写为并行程序
编写一个翻译程序来自动地将串行程序 翻译成并行程序
非常困难 鲜有突破
更多的问题
尽管我们可以编写一些程序,让这些程序辨识 串行程序的常见结构,并自动将这些结构转换 成并行程序的结构,但转化后的并行程序在实 际运行时可能很低效
一个串行程序的高效并行实现可能不是通过发 掘其中每一个步骤的高效并行实现来获得,相 反,最好的并行化实现可能是通过一步步回溯 ,然后发现一个全新的算法来获得的
总线——指令和数据通过CPU和主存之间 的互连结构进行传输。这种互连结构通 常是总线,总线中包括一组并行的线以 及控制这些线的硬件。
例如,假如有8个核,n=24,24次调用 Compute_next_value获得如下的值:
1,4,3, 9,2,8, 5,1,1, 5,2,7, 2,5,0, 4,1,8, 6,5,1, 2,3,9
例子(续)
当各个核都计算 完各自的 my_sum值后, 将自己的结果值 发送给一个指定 为“master”的 核(主核), master核将收 到的部分和累加 而得到全局总和
求和例子的第二部分——任务 并行
总共有两个任务:一个任务由master核执行,负责接收从其他核传来的 部分和,并累加部分和; 另一个任务由其他核执行, 负责将自己计算得 到的部分和传递给master核。
第一章的课堂练习
练习1. 为求全局总和例子中的 my_first_i和my_last_i推导一个公式 。需要注意的是:在循环中,应该 给各个核分配数目大致相同的计算 元素。
练习2
尝试写出树形结构求全局总和的伪代码。假设核的数 目是2的幂(1、2、4、8等)。提示:使用变量divisor 来决定一个核应该是发送部分和还是接收部分和, divisor的初始值为2,并且每次迭代后增倍。使用变量 core_difference来决定哪个核与当前核合作,它的初 始值为1,并且每次迭代后增倍。例如,在第一次迭代 中0 % divisor = 0,1 % divisor = 1,所以0号核负责 接收和,1号核负责发送。在第一次迭代中0 + core_difference = 1,1-core_difference = 0,所以0 号核与1号核在第一次迭代中合作。
串行问题的处理方法
将串行程序改写为并行程序
编写一个翻译程序来自动地将串行程序 翻译成并行程序
非常困难 鲜有突破
更多的问题
尽管我们可以编写一些程序,让这些程序辨识 串行程序的常见结构,并自动将这些结构转换 成并行程序的结构,但转化后的并行程序在实 际运行时可能很低效
一个串行程序的高效并行实现可能不是通过发 掘其中每一个步骤的高效并行实现来获得,相 反,最好的并行化实现可能是通过一步步回溯 ,然后发现一个全新的算法来获得的
总线——指令和数据通过CPU和主存之间 的互连结构进行传输。这种互连结构通 常是总线,总线中包括一组并行的线以 及控制这些线的硬件。
例如,假如有8个核,n=24,24次调用 Compute_next_value获得如下的值:
1,4,3, 9,2,8, 5,1,1, 5,2,7, 2,5,0, 4,1,8, 6,5,1, 2,3,9
例子(续)
当各个核都计算 完各自的 my_sum值后, 将自己的结果值 发送给一个指定 为“master”的 核(主核), master核将收 到的部分和累加 而得到全局总和
求和例子的第二部分——任务 并行
总共有两个任务:一个任务由master核执行,负责接收从其他核传来的 部分和,并累加部分和; 另一个任务由其他核执行, 负责将自己计算得 到的部分和传递给master核。
第一章的课堂练习
练习1. 为求全局总和例子中的 my_first_i和my_last_i推导一个公式 。需要注意的是:在循环中,应该 给各个核分配数目大致相同的计算 元素。
练习2
尝试写出树形结构求全局总和的伪代码。假设核的数 目是2的幂(1、2、4、8等)。提示:使用变量divisor 来决定一个核应该是发送部分和还是接收部分和, divisor的初始值为2,并且每次迭代后增倍。使用变量 core_difference来决定哪个核与当前核合作,它的初 始值为1,并且每次迭代后增倍。例如,在第一次迭代 中0 % divisor = 0,1 % divisor = 1,所以0号核负责 接收和,1号核负责发送。在第一次迭代中0 + core_difference = 1,1-core_difference = 0,所以0 号核与1号核在第一次迭代中合作。
超性能计算(mpi) ppt课件详解

贵族计算机
• 近年来,集群式系统由于具有以下优点而得到了快速发展
低成本、高性能、短周期,大规模并行,分布式共享内存 平民的超级计算机
• 向量机 (芯片级的并行计算机) • MPP(Massively Parallel Processors)
研制难度逐 渐降底
(主板级的并行计算机)
• Cluster
高性能计算程序设计
课程内容
• 并行计算机与并行算法的基础知识
• MPI程序设计
• OpenMP程序设计
目的:
了解和掌握基本的高性能程序设计编程技术。
参考资料
• • • 《高性能计算并行编程技术—MPI并行程序设计》
都志辉
清华大学出版社
《并行算法实践》 阵国良等 高等教育出版社 《并行计算---结构、算法、编程》 阵国良等 高等教育出版社
4、MPI的语言绑定
MPI不是一门语言,而是一个库,必须和特定的语 言绑定才能进行 MPI_I:C、FORTRAN77 MPI_II:C++、FORTRAN90
5、目前MPI的主要实现
• MPICH: 美国的Argonne国家实验室 /mpi/mpich • CHIMP:
计算系统共有15台曙光W580双路服务器,CPU整体峰值 性能达到3.312万亿次/秒。每台计算节点配臵2颗 IntelXEON E5-2630 2.3G 6C CPU六核CPU,24G DDR3 内存。 GPGPU计算系统共有7台曙光W580I,GPU双精度浮点 峰值达到9.17万亿次/秒。每台GPGPU计算节点配臵2块 Nvidia K20 GPGPU卡。 系统配备1台管理/IO/登陆节点,存储裸容量为2.3TB, 部署曙光Gridview 2.6集群管理系统,用户可通过IP地址 实现Web访问。 系统配臵机房环境管理节点1台,部署曙光IMMS机房环 境管理系统。用户可通过IP地址实现Web访问。 系统配臵1套线速互联的56Gb FDR Infiniband网络。 系统共用9个服务器机柜、1个空调机柜、4个航空电源箱 供电,系统峰值功耗约为28kW。
• 近年来,集群式系统由于具有以下优点而得到了快速发展
低成本、高性能、短周期,大规模并行,分布式共享内存 平民的超级计算机
• 向量机 (芯片级的并行计算机) • MPP(Massively Parallel Processors)
研制难度逐 渐降底
(主板级的并行计算机)
• Cluster
高性能计算程序设计
课程内容
• 并行计算机与并行算法的基础知识
• MPI程序设计
• OpenMP程序设计
目的:
了解和掌握基本的高性能程序设计编程技术。
参考资料
• • • 《高性能计算并行编程技术—MPI并行程序设计》
都志辉
清华大学出版社
《并行算法实践》 阵国良等 高等教育出版社 《并行计算---结构、算法、编程》 阵国良等 高等教育出版社
4、MPI的语言绑定
MPI不是一门语言,而是一个库,必须和特定的语 言绑定才能进行 MPI_I:C、FORTRAN77 MPI_II:C++、FORTRAN90
5、目前MPI的主要实现
• MPICH: 美国的Argonne国家实验室 /mpi/mpich • CHIMP:
计算系统共有15台曙光W580双路服务器,CPU整体峰值 性能达到3.312万亿次/秒。每台计算节点配臵2颗 IntelXEON E5-2630 2.3G 6C CPU六核CPU,24G DDR3 内存。 GPGPU计算系统共有7台曙光W580I,GPU双精度浮点 峰值达到9.17万亿次/秒。每台GPGPU计算节点配臵2块 Nvidia K20 GPGPU卡。 系统配备1台管理/IO/登陆节点,存储裸容量为2.3TB, 部署曙光Gridview 2.6集群管理系统,用户可通过IP地址 实现Web访问。 系统配臵机房环境管理节点1台,部署曙光IMMS机房环 境管理系统。用户可通过IP地址实现Web访问。 系统配臵1套线速互联的56Gb FDR Infiniband网络。 系统共用9个服务器机柜、1个空调机柜、4个航空电源箱 供电,系统峰值功耗约为28kW。
《高能计算介绍》PPT课件

2021/3/8
18
编译并行程序:
1. openmp paralleled fortran program efc -O2 -tpp2 -fpp -openmp yourprog.f -o yourprog.out
2 .mpi paralleled fortran program efc -O2 -tpp2 yourprog.f -o yourprog.out lmpi
`output1'
prog<input2>output1 \> the same using input file
named `input2'
prog<input2>output1& \> the same `in background'
control-c
\> if cursor does not return: kill task
高性能计算介绍
2021/3/8
1
什么是高性能计算?(HPC) 1.高速运算 2.大内存 3.海量存储
2021/3/8
2
常见的高性能计算的实现 1. 多CPU共享内存结构(SGI Altix 3000) 2. 集群(cluster)结构(联想计算集群) 操作系统
Unix, Linux, Windows 并行开发软件
MPI, OpenMP
2021/3/8
3
SGI Altix 3700体系结构
一 系统模块
1.C brick: 32个1.3GHz/3M Intel Itanium2 cpu 2. M brick: 32G内存 3. R brick:路由 4. IX brick:输入/输出 5. D brick: 硬盘扩展(连接1T盘阵)
“高性能计算课件PPT教程”
应用案例
探索并行计算软件在科学计 算中的各种应用案例。
数据并行和任务并行的区别
数据并行
探索数据并行的基本原理和应用 场景。
任务并行
介绍任务并行
了解主流的并行计算框架以及将 它们应用到数据并行和任务并行 设计中。
集群计算系统的管理和操作
集群管理技术 系统安装和配置
高性能计算在云计算和大数据场景下的应 用
1
云计算与高性能计算
了解高性能计算在云计算环境下的实现
Map Reduce框架
2
和优化策略。
探索MapReduce框架在大数据处理中的
应用。
3
Hadoop 架构与优化
介绍Hadoop架构和优化技巧,提高大数
机器学习与大数据处理
4
据的处理效率。
探索机器学习在大数据处理中的应用, 如基于Spark的机器学习算法。
2
掌握编译器的原理和使用技巧,提高程
序执行效率。
3
并行化原理
了解多级并行的原理及其在高性能计算 中的应用。
调度器优化
介绍调度器的原理和使用方法,提高系 统的并行计算效率。
并行计算软件设计原则
设计原则
学习并行计算软件设计的基 本原则,如任务分解、通信、 同步等。
主流框架
介绍几种主流的并行计算框 架,如MPI和OpenMP。
并行程序调试
探究并行程序调试的技巧和方法, 如GDB和DDE。
GPU加速计算和异构计算体系 结构
1 CUDA编程模型
学习CUDA并行计算编程模 型和程序设计方法。
2 OpenCL
介绍OpenCL编程模型和异构 计算在高性能计算中的应用 场景。
3 异构计算的挑战
高性能并行计算PPT文档39页
61、奢侈是舒适的,否则就不是奢侈 。——CocoCha nel 62、少而好学,如日出之阳;壮而好学 ,如日 中之光 ;志而 好学, 如炳烛 之光。 ——刘 向 63、三军可夺帅也,匹夫不可夺志也。 ——孔 丘 64、人生就是学校。在那里,与其说好 的教师 是幸福 ,不如 说好的 教师是 不幸。 ——海 贝尔 65、接受挑战,就可以享受胜利的喜悦 。——杰纳勒 尔·乔治·S·巴顿
谢谢!
高性能并行计算
1、纪律是管理关系的形式。——阿法 纳西耶 夫 2、改革如果不讲纪律,就难以成功。
3、道德行为训练,不是通过语言影响 ,而是 让儿童 练习良 好道德 行为, 克服懒 惰、轻 率、不 守纪律 、颓废 等不良 行为。 4、学校没有纪律便如磨房里没有水。 ——夸 美纽斯
5、教导儿童服从真理、服从集体,养 成儿童 自觉的 纪律性 ,这是 儿童道 德教
高性能计算机讲义 (2)精品课件
1.4 计算和计算机科学的应用(5)
➢ 生物学
✓ 解码蜜蜂通信:使用数码录像机记录蜜蜂之间的通信,研 究人员发现一些蜜蜂使用声音编码来传达关于食物位置的 信息,这种编码能阻止其它的蜜蜂种类拦截此信息。使用 数码录像机需要存储和读取巨大的数据量(上万亿位),使 用网络系统,便于广布在各地区的科学家们访问和分析记 录蜜蜂行为的数以万帧计的录像,以便帮助解释特定种群 适应环境的进化,保证种群继续繁荣。
国家高性能计算中心(合肥)
2021/5/9
3
1、计算与计算机科学(2)
1.2 计算和计算机科学的特点、地位与作用
▪ 特点
➢ 知识强度高(涉及面广)、应用面广(无处不在的学科)、有益于其它所 有研究领域和无政治色彩的中性学科。
▪ 地位与作用
➢ 科学发现和人类社会文明进步的第三支柱。 ➢ 具有促进其它学科发展的基础作用:21世纪科学上最重要的和经济上
✓ 传染病传播动态建模:根据遭受的苦难以及所产生的社会与经济 后果,传染病对人类和动物的影响是巨大的。借助数学和计算机 科学研究传染病的空间和时间传播机制和特征,帮助我们预测、 制定和评估控制策略,并通过模拟程序提供虚拟场景,帮助人们 面对流行疾病时,应采取的紧急措施和最有效的隔离决策等。
✓ 强风暴预测:强风暴每年给国家带来的经济损失和人员伤亡是巨 大的,由于不准确和缺乏时间性,约有3/4的龙卷风警报被证明 是无效的。美国俄克拉荷马州立大学研究人员使用匹兹堡的超级 计算机模拟过去所发生的大型龙卷风,首次模拟了整个暴风雨, 真实地再现了完整的龙卷风发展过程。
✓ 社会行为科学:当社会和行为科学家面临巨大的数据需要 理解和保护这些数据时,社会科学家和计算科学家加强合 作是最有利的;社会科学家可帮助计算科学家理解在社会 生态系统中怎样运用计算机科学;行为科学家也能帮助计 算机科学家开发良好的人机交互模型;心理学家和语言学 家同计算机科学家合作,能联合开发易于理解、使用和语 言翻译的计算机程序,等等。
➢ 生物学
✓ 解码蜜蜂通信:使用数码录像机记录蜜蜂之间的通信,研 究人员发现一些蜜蜂使用声音编码来传达关于食物位置的 信息,这种编码能阻止其它的蜜蜂种类拦截此信息。使用 数码录像机需要存储和读取巨大的数据量(上万亿位),使 用网络系统,便于广布在各地区的科学家们访问和分析记 录蜜蜂行为的数以万帧计的录像,以便帮助解释特定种群 适应环境的进化,保证种群继续繁荣。
国家高性能计算中心(合肥)
2021/5/9
3
1、计算与计算机科学(2)
1.2 计算和计算机科学的特点、地位与作用
▪ 特点
➢ 知识强度高(涉及面广)、应用面广(无处不在的学科)、有益于其它所 有研究领域和无政治色彩的中性学科。
▪ 地位与作用
➢ 科学发现和人类社会文明进步的第三支柱。 ➢ 具有促进其它学科发展的基础作用:21世纪科学上最重要的和经济上
✓ 传染病传播动态建模:根据遭受的苦难以及所产生的社会与经济 后果,传染病对人类和动物的影响是巨大的。借助数学和计算机 科学研究传染病的空间和时间传播机制和特征,帮助我们预测、 制定和评估控制策略,并通过模拟程序提供虚拟场景,帮助人们 面对流行疾病时,应采取的紧急措施和最有效的隔离决策等。
✓ 强风暴预测:强风暴每年给国家带来的经济损失和人员伤亡是巨 大的,由于不准确和缺乏时间性,约有3/4的龙卷风警报被证明 是无效的。美国俄克拉荷马州立大学研究人员使用匹兹堡的超级 计算机模拟过去所发生的大型龙卷风,首次模拟了整个暴风雨, 真实地再现了完整的龙卷风发展过程。
✓ 社会行为科学:当社会和行为科学家面临巨大的数据需要 理解和保护这些数据时,社会科学家和计算科学家加强合 作是最有利的;社会科学家可帮助计算科学家理解在社会 生态系统中怎样运用计算机科学;行为科学家也能帮助计 算机科学家开发良好的人机交互模型;心理学家和语言学 家同计算机科学家合作,能联合开发易于理解、使用和语 言翻译的计算机程序,等等。
云计算与高性能计算42页PPT
40、人类法律,事物有规律,这是不 容忽视 的。— —爱献 生
谢谢!
36、自己的鞋子,自己知道紧在哪里。——西班牙
37、我们唯一不会改正的缺点是软弱。——拉罗什福科
xiexie! 38、我这个人走得很慢,但是我从不后退。——亚伯拉罕·林肯
云计算与高性能计算
36、如果我们国家的法律中只有某种 神灵, 而不是 殚精竭 虑将神 灵揉进 宪法, 总体上 来说, 法律就 会更好 。—— 马克·吐 温 37、纲纪废弃之日,便是暴政兴起之 时。— —威·皮 物特
38、若是没有公众舆论的支持,法律 是丝毫 没有力 量的。 ——菲 力普斯 39、一个判例造出另一个判例,它们 迅速累 聚,进 而变成 法律。 ——朱 尼厄斯
39、勿问成功的秘诀为何,且尽全力做你应该做的事吧。——美华纳
40、学而不思则罔,思而不学则殆。——孔子
谢谢!
36、自己的鞋子,自己知道紧在哪里。——西班牙
37、我们唯一不会改正的缺点是软弱。——拉罗什福科
xiexie! 38、我这个人走得很慢,但是我从不后退。——亚伯拉罕·林肯
云计算与高性能计算
36、如果我们国家的法律中只有某种 神灵, 而不是 殚精竭 虑将神 灵揉进 宪法, 总体上 来说, 法律就 会更好 。—— 马克·吐 温 37、纲纪废弃之日,便是暴政兴起之 时。— —威·皮 物特
38、若是没有公众舆论的支持,法律 是丝毫 没有力 量的。 ——菲 力普斯 39、一个判例造出另一个判例,它们 迅速累 聚,进 而变成 法律。 ——朱 尼厄斯
39、勿问成功的秘诀为何,且尽全力做你应该做的事吧。——美华纳
40、学而不思则罔,思而不学则殆。——孔子
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
42
流水线例子(4)——另一个方案
43
流水线例子(5)——另一个方案
在时间5后,流水循环每 1纳秒产生一个结果,而 不再是每7纳秒一次。所 以,执行for循环的总时 间从7000纳秒降低到 1006纳秒,提高了近7 倍。
44
思考题2
当讨论浮点数加法时,我们简单地假设每个功 能单元都花费相同的时间。如果每个取命令与 存命令都耗费2纳秒,其余的每个操作耗费1纳 秒。 a. 在上述假设下,每个浮点数加法要耗费多少
缓存的分层(level)
最小 & 最快 L1
L2
L3 最大 & 最慢
20
Cache命中(hit)
fetch x L1
x sum
L2
y z total
L3
A[ ] radius r1 center
21
Cache缺失(miss)
fetபைடு நூலகம்h x
x
主存
L1 y sum
L2
r1 z total
L3
A[ ] radius center
x
26
例子
假设主存有16行,分别用0~15 标记,Cache有4行,用0~3标 记。
在全相联映射中,主存中的0号 行能够映射到Cache中的0、1、 2、3任意一行。
在直接映射Cache中,可以根据 主存中高速缓存行的标记值除以 4求余,获得在Cache中的索引 。因此主存中0、4、8号行会映 射到Cache的0号行,主存中的1 、5、9号行映射到Cache的1号 行,以此类推。
第二章 并行硬件和并行软件
1
背景知识
2
串行硬件和软件
程序
输入
输出
一次只执行单个任务
3
“经典”的冯·诺依曼结构
4
主存(Main memory)
主存中有许多区域,每个区域都可以存 储指令和数据。
每个区域都有一个地址,可以通过这个 地址来访问相应的区域及区域中存储的 数据和指令。
5
中央处理单元(CPU)
terminating a thread
Is called joining(合并)
15
对冯·诺依曼模型的改进
16
缓存 (Cache)
CPU Cache 是一组相比于主存,CPU能 更快速地访问的内存区域。
CPU Cache位于与CPU同一块的芯片或者 位于其他芯片上,但比普通的内存芯片 能更快地访问。
write/store
CPU
9
冯·诺依曼瓶颈
主存和CPU之间的分离称为冯·诺 依曼瓶颈。这是因为互连结构限 定了指令和数据访问的速率。程 序运行所需要的大部分数据和指 令被有效地与CPU隔离开。
10
一个操作系统“进程”
进程是运行着的程序的一个实例。 一个进程包括如下实体:
可执行的机器语言程序. 一块内存空间. 操作系统分配给进程的资源描述符. 安全信息. 进程状态信息.
adder #1
z[2] z[0]
z[3] z[1]
adder #2
50
多发射(2)
静态多发射——如果功能单元是在编译时 调度的,则称该多发射系统使用静态多 发射
动态多发射——如果是在运行时间调度的 ,则称该多发射系统使用动态多发射。 一个支持动态多发射的处理器称为超标 量(superscalar)。
中央处理单元分为控制单 元和算术逻辑单元( Arithmetic Logic Unit, ALU)。
控制单元负责决定应该执 行程序中的哪些指令。
ALU负责执行指令。
add 2+2
6
关键术语
寄存器——CPU中的数据和程序执行时的 状态信息存储在特殊的快速存储介质中
程序计数器——控制单元中一个特殊的寄 存器,用来存放下一条指令的地址。
11
多任务
大多数现代操作系统都是多任务的。 这 意味着操作系统提供对同时运行多个程 序的支持。
这对于单核系统也是可行的,因为每个 进程只运行一小段时间(几毫秒),亦 即一个时间片。在一个程序执行了一个 时间片的时间后,操作系统就切换执行 其他程序
12
多任务
在一个多任务操作系统中,如果一个进 程需要等待某个资源,例如需要从外部 的存储器读数据,它会阻塞。这意味着 ,该进程会停止运行,操作系统可以运 行其他进程。例如:航班预定系统在一 个用户因为等待座位图而阻塞时,可为 另一个用户提供可用的航线查询。
直接映射(directed mapped) Cache——每个高 速缓存行在Cache中有唯一的位置。
n路组相联(n-way set associated)——每个高速 缓存行都能放置到Cache中n个不同区域位置中 的一个。
25
n路组相联
当内存中的行(多于一行)能被映射到 Cache中的多个不同位置(全相联和n路 组相联)时,需要决定替换或者驱逐 Cache中的哪一行。
13
线程
线程包含在进程中。
线程为程序员提供了一种机制,将程序 划分为多个大致独立的任务,当某个任 务阻塞时能执行其他任务。
此外,在大多数系统中,线程间的切换 比进程间的切换更快。
14
一个进程和两个线程
the “master” thread(主线程)
starting a thread
Is called forking(派生)
表2-2
33
思考题
在表2-2中,虚拟地址由12位字节偏移量 和20位的虚拟页号组成。如果一个程序 运行的系统上拥有这样的页大小和虚拟 地址空间,这个程序有多少页?
34
转译后备缓冲区( TLB )
尽管多个程序可以同时使用主存了,但 使用页表会增加程序总体的运行时间。
为了解决这个问题,处理器有一种专门 用于地址转换的缓存,叫做转译后备缓 冲区(Translation Lookaside Buffer, TLB)。
w=y;
Z 应该是 正数
如果系统预测错误,需要回退机制, 然后执行w=y.
53
硬件多线程
指令级并行是很难利用的,因为程序中有许多部分之 间存在依赖关系。
硬件多线程(hardware multithreading)为系统提供了一 种机制,使得当前执行的任务被阻塞时,系统能够继 续其他有用的工作。 例如,如果当前任务需要等待数据从内存中读出, 那么它可以通过执行其他线程而不是继续当前线程 来发掘并行性.
优点: 不需要线程间的立即切换. 缺点: 处理器还是可能在短阻塞时空闲,线
程间的切换也还是会导致延迟.
56
硬件多线程(4)
同步多线程(Simultaneous Multithreading,SMT)——是细粒度多线 程的变种。
27
虚拟内存(1)
如果运行一个大型的程序,或者程序需 要访问大型数据集,那么所有的指令或 者数据可能在主存中放不下。
利用虚拟存储器(或虚拟内存),使得 主存可以作为辅存的缓存。
28
虚拟内存(2)
虚拟内存通过在主存中存放当前执行程 序所需要用到的部分,来利用时间和空 间局部性.
29
虚拟内存(3)
22
与缓存有关的问题
当CPU向Cache中写数据时,Cache中的 值与主存中的值就会不同或者不一致 (inconsistent)。
有两种方法来解决这个不一致性问题: 写直达(write-through) 和写回(writeback)
23
与缓存有关的问题
在写直达(write-through) Cache中,当 CPU向Cache写数据时,高速缓存行会立 即写入主存中。
如果每次操作花费1纳秒,那 么加法操作需要花费7纳秒
for循环需要花费7000纳秒.
41
流水线例子(3)——另一个方案
将浮点数加法器划分成7个独立的硬件或 者功能单元。
第一个单元取两个操作数,第二个比较 指数,以此类推。
假设一个功能单元的输出是下面一个功 能单元的输入,那么加法功能单元的输 出是规格化结果功能单元的输入。
54
硬件多线程(2)
细粒度(fine-grained)——在细粒度多线 程中,处理器在每条指令执行完后切换 线程,从而跳过被阻塞的线程。
优点: 能够避免因为阻塞而导致机器时间的 浪费.
缺点: 执行很长一段指令的线程在执行每条 指令的时候都需要等待.
55
硬件多线程(3)
粗粒度(coarse grained)——只切换那些 需要等待较长时间才能完成操作(如从 主存中加载)而被阻塞的线程。
51
预测(speculation)
为了能够利用多发射,系统必须找出能 够同时执行的指令。其中一种最重要的 技术是预测(speculation)。
在预测技术中,编译器或者处 理器对一条指令进行猜测,然 后在猜测的基础上执行代码。
52
预测(2)
z=x+y; i f ( z > 0)
w=x; else
总线——指令和数据通过CPU和主存之间 的互连结构进行传输。这种互连结构通 常是总线,总线中包括一组并行的线以 及控制这些线的硬件。
7
memory
当数据或指令从主存传送到CPU 时,我们称数据或指令从内存中 取出或者读出。
fetch/read
CPU
8
memory
当数据或指令从CPU传送到主存 中时,我们称数据或指令写入或 者存入内存中。
35
转译后备缓冲区(2)
TLB在快速存储介质中缓存了一些页表的 条目(通常为16~512条)。
页面失效——假如想要访问的页不在内存 中,即页表中该页没有合法的物理地址 ,该页只存储在磁盘上,那么这次访问 称为页面失效(page fault)。
36
指令级并行(ILP)
流水线例子(4)——另一个方案
43
流水线例子(5)——另一个方案
在时间5后,流水循环每 1纳秒产生一个结果,而 不再是每7纳秒一次。所 以,执行for循环的总时 间从7000纳秒降低到 1006纳秒,提高了近7 倍。
44
思考题2
当讨论浮点数加法时,我们简单地假设每个功 能单元都花费相同的时间。如果每个取命令与 存命令都耗费2纳秒,其余的每个操作耗费1纳 秒。 a. 在上述假设下,每个浮点数加法要耗费多少
缓存的分层(level)
最小 & 最快 L1
L2
L3 最大 & 最慢
20
Cache命中(hit)
fetch x L1
x sum
L2
y z total
L3
A[ ] radius r1 center
21
Cache缺失(miss)
fetபைடு நூலகம்h x
x
主存
L1 y sum
L2
r1 z total
L3
A[ ] radius center
x
26
例子
假设主存有16行,分别用0~15 标记,Cache有4行,用0~3标 记。
在全相联映射中,主存中的0号 行能够映射到Cache中的0、1、 2、3任意一行。
在直接映射Cache中,可以根据 主存中高速缓存行的标记值除以 4求余,获得在Cache中的索引 。因此主存中0、4、8号行会映 射到Cache的0号行,主存中的1 、5、9号行映射到Cache的1号 行,以此类推。
第二章 并行硬件和并行软件
1
背景知识
2
串行硬件和软件
程序
输入
输出
一次只执行单个任务
3
“经典”的冯·诺依曼结构
4
主存(Main memory)
主存中有许多区域,每个区域都可以存 储指令和数据。
每个区域都有一个地址,可以通过这个 地址来访问相应的区域及区域中存储的 数据和指令。
5
中央处理单元(CPU)
terminating a thread
Is called joining(合并)
15
对冯·诺依曼模型的改进
16
缓存 (Cache)
CPU Cache 是一组相比于主存,CPU能 更快速地访问的内存区域。
CPU Cache位于与CPU同一块的芯片或者 位于其他芯片上,但比普通的内存芯片 能更快地访问。
write/store
CPU
9
冯·诺依曼瓶颈
主存和CPU之间的分离称为冯·诺 依曼瓶颈。这是因为互连结构限 定了指令和数据访问的速率。程 序运行所需要的大部分数据和指 令被有效地与CPU隔离开。
10
一个操作系统“进程”
进程是运行着的程序的一个实例。 一个进程包括如下实体:
可执行的机器语言程序. 一块内存空间. 操作系统分配给进程的资源描述符. 安全信息. 进程状态信息.
adder #1
z[2] z[0]
z[3] z[1]
adder #2
50
多发射(2)
静态多发射——如果功能单元是在编译时 调度的,则称该多发射系统使用静态多 发射
动态多发射——如果是在运行时间调度的 ,则称该多发射系统使用动态多发射。 一个支持动态多发射的处理器称为超标 量(superscalar)。
中央处理单元分为控制单 元和算术逻辑单元( Arithmetic Logic Unit, ALU)。
控制单元负责决定应该执 行程序中的哪些指令。
ALU负责执行指令。
add 2+2
6
关键术语
寄存器——CPU中的数据和程序执行时的 状态信息存储在特殊的快速存储介质中
程序计数器——控制单元中一个特殊的寄 存器,用来存放下一条指令的地址。
11
多任务
大多数现代操作系统都是多任务的。 这 意味着操作系统提供对同时运行多个程 序的支持。
这对于单核系统也是可行的,因为每个 进程只运行一小段时间(几毫秒),亦 即一个时间片。在一个程序执行了一个 时间片的时间后,操作系统就切换执行 其他程序
12
多任务
在一个多任务操作系统中,如果一个进 程需要等待某个资源,例如需要从外部 的存储器读数据,它会阻塞。这意味着 ,该进程会停止运行,操作系统可以运 行其他进程。例如:航班预定系统在一 个用户因为等待座位图而阻塞时,可为 另一个用户提供可用的航线查询。
直接映射(directed mapped) Cache——每个高 速缓存行在Cache中有唯一的位置。
n路组相联(n-way set associated)——每个高速 缓存行都能放置到Cache中n个不同区域位置中 的一个。
25
n路组相联
当内存中的行(多于一行)能被映射到 Cache中的多个不同位置(全相联和n路 组相联)时,需要决定替换或者驱逐 Cache中的哪一行。
13
线程
线程包含在进程中。
线程为程序员提供了一种机制,将程序 划分为多个大致独立的任务,当某个任 务阻塞时能执行其他任务。
此外,在大多数系统中,线程间的切换 比进程间的切换更快。
14
一个进程和两个线程
the “master” thread(主线程)
starting a thread
Is called forking(派生)
表2-2
33
思考题
在表2-2中,虚拟地址由12位字节偏移量 和20位的虚拟页号组成。如果一个程序 运行的系统上拥有这样的页大小和虚拟 地址空间,这个程序有多少页?
34
转译后备缓冲区( TLB )
尽管多个程序可以同时使用主存了,但 使用页表会增加程序总体的运行时间。
为了解决这个问题,处理器有一种专门 用于地址转换的缓存,叫做转译后备缓 冲区(Translation Lookaside Buffer, TLB)。
w=y;
Z 应该是 正数
如果系统预测错误,需要回退机制, 然后执行w=y.
53
硬件多线程
指令级并行是很难利用的,因为程序中有许多部分之 间存在依赖关系。
硬件多线程(hardware multithreading)为系统提供了一 种机制,使得当前执行的任务被阻塞时,系统能够继 续其他有用的工作。 例如,如果当前任务需要等待数据从内存中读出, 那么它可以通过执行其他线程而不是继续当前线程 来发掘并行性.
优点: 不需要线程间的立即切换. 缺点: 处理器还是可能在短阻塞时空闲,线
程间的切换也还是会导致延迟.
56
硬件多线程(4)
同步多线程(Simultaneous Multithreading,SMT)——是细粒度多线 程的变种。
27
虚拟内存(1)
如果运行一个大型的程序,或者程序需 要访问大型数据集,那么所有的指令或 者数据可能在主存中放不下。
利用虚拟存储器(或虚拟内存),使得 主存可以作为辅存的缓存。
28
虚拟内存(2)
虚拟内存通过在主存中存放当前执行程 序所需要用到的部分,来利用时间和空 间局部性.
29
虚拟内存(3)
22
与缓存有关的问题
当CPU向Cache中写数据时,Cache中的 值与主存中的值就会不同或者不一致 (inconsistent)。
有两种方法来解决这个不一致性问题: 写直达(write-through) 和写回(writeback)
23
与缓存有关的问题
在写直达(write-through) Cache中,当 CPU向Cache写数据时,高速缓存行会立 即写入主存中。
如果每次操作花费1纳秒,那 么加法操作需要花费7纳秒
for循环需要花费7000纳秒.
41
流水线例子(3)——另一个方案
将浮点数加法器划分成7个独立的硬件或 者功能单元。
第一个单元取两个操作数,第二个比较 指数,以此类推。
假设一个功能单元的输出是下面一个功 能单元的输入,那么加法功能单元的输 出是规格化结果功能单元的输入。
54
硬件多线程(2)
细粒度(fine-grained)——在细粒度多线 程中,处理器在每条指令执行完后切换 线程,从而跳过被阻塞的线程。
优点: 能够避免因为阻塞而导致机器时间的 浪费.
缺点: 执行很长一段指令的线程在执行每条 指令的时候都需要等待.
55
硬件多线程(3)
粗粒度(coarse grained)——只切换那些 需要等待较长时间才能完成操作(如从 主存中加载)而被阻塞的线程。
51
预测(speculation)
为了能够利用多发射,系统必须找出能 够同时执行的指令。其中一种最重要的 技术是预测(speculation)。
在预测技术中,编译器或者处 理器对一条指令进行猜测,然 后在猜测的基础上执行代码。
52
预测(2)
z=x+y; i f ( z > 0)
w=x; else
总线——指令和数据通过CPU和主存之间 的互连结构进行传输。这种互连结构通 常是总线,总线中包括一组并行的线以 及控制这些线的硬件。
7
memory
当数据或指令从主存传送到CPU 时,我们称数据或指令从内存中 取出或者读出。
fetch/read
CPU
8
memory
当数据或指令从CPU传送到主存 中时,我们称数据或指令写入或 者存入内存中。
35
转译后备缓冲区(2)
TLB在快速存储介质中缓存了一些页表的 条目(通常为16~512条)。
页面失效——假如想要访问的页不在内存 中,即页表中该页没有合法的物理地址 ,该页只存储在磁盘上,那么这次访问 称为页面失效(page fault)。
36
指令级并行(ILP)