实验四 类模型的建立
实验数学模型建立与转换

实验数学模型建立与转换文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-实验四 数学模型建立与转换一、实验目的1.学会用MATLAB 建立控制系统的数学模型。
2.学会用MATLAB 对控制系统的不同形式的数学模型之间的转换和连接。
二、实验内容1.建立控制系统的数学模型用MATLAB 建立下述零极点形式的传递函数类型的数学模型:>> z=-3;p=[-1;-1];k=1;sys=zpk(z,p,k)Zero/pole/gain:(s+3)-------(s+1)^22.不同形式及不同类型间的数学模型的相互转换1)用MATLAB 将下列分子、分母多项式形式的传递函数模型转换为零极点形式的传递函数模型:>> num=[12 24 0 20];den=[2 4 6 2 2];G=tf(num,den);[z,p,k]=zpkdata(G,'v');sys=zpk(z,p,k)Zero/pole/gain:6 (s+2.312) (s^2 - 0.3118s + 0.7209)-------------------------------------------------(s^2 + 0.08663s + 0.413) (s^2 + 1.913s + 2.421)2)用MATLAB 将下列零极点形式的传递函数模型转换为分子、分母多项式形式的传递函数模型:>> z=[0;-6;-5]; p=[-1;-2;-3-4*j;-3+4*j];22642202412)(23423++++++=s s s s s s s G )43)(43)(2)(1()5)(6()(j s j s s s s s s s G -+++++++=k=1;[num,den]=zp2tf(z,p,k);G=tf(num,den)Transfer function:s^3 + 11 s^2 + 30 s--------------------------------s^4 + 9 s^3 + 45 s^2 + 87 s + 503. 用MATLAB 命令求如下图所示控制系统的闭环传递函数>> G1=tf(1,[500 0]);G2=tf([1 2],[1 4]);G3=tf([1 1],[1 2]);G4=G1*G2;GP=G4/(1+G3*G4);GP1=minreal(GP)Transfer function:0.002 s + 0.004---------------------s^2 + 4.002 s + 0.0023.已知系统的状态空间表达式,写出其SS 模型,并求其传递函数矩阵(传递函数模型),若状态空间表达式为⎩⎨⎧+=+=DuCx y Bu Ax x ,则传递函数矩阵表达式为: D B A sI C s G +-=-1)()(。
化学反应动力学模型建立与模拟方法教程

化学反应动力学模型建立与模拟方法教程为了深入了解化学反应过程并预测其动力学行为,建立适当的模型是至关重要的。
化学反应动力学模型的建立能够提供相关参数和反应速率方程,从而使研究者能够更好地理解反应机理和优化反应条件。
本文将介绍化学反应动力学模型建立与模拟的基本步骤和方法。
第一步是数据收集。
在建立反应动力学模型之前,需要收集实验数据。
实验数据应包含反应物浓度、反应温度和反应速率等信息。
这些数据可通过实验室实验或文献调研获得。
数据收集是建立可靠模型的基础,因此务必确保数据的准确性和全面性。
第二步是选择适当的模型。
根据反应的特性和目的,可以选择不同类型的动力学模型。
常见的模型包括一级反应、二级反应、阻滞动力学和微分动力学等。
选取合适的模型需要考虑反应机理和反应条件等因素。
第三步是参数估计。
参数估计是建立反应动力学模型过程中的关键步骤。
参数包括反应速率常数、活化能和反应级数等。
参数估计可以通过不同的统计方法、优化算法和曲线拟合等进行。
最常用的方法是最小二乘法,通过最小化实验数据和模型预测值之间的平方误差来估计参数。
第四步是模型验证。
模型验证是确认所建立模型的可靠性和准确性的重要环节。
通过将模型的预测结果与实验数据进行比较,可以评估模型的精确度和适用性。
如果模型表现良好,即能够准确预测实验数据,则可以认为该模型是可靠的。
除了建立动力学模型,还可以利用模型进行反应模拟。
反应模拟可以预测不同反应条件下的反应动力学行为。
通过改变反应物浓度、温度和反应时间等参数,可以预测反应速率和产物生成量的变化趋势。
反应模拟能够帮助研究者优化反应条件,提高反应效率和选择合适的反应条件。
在进行反应模拟之前,需要对模型进行合理的参数选择。
参数选择可以基于实验数据或文献中已有的参数值。
同时,也可以通过灵敏度分析来评估参数对模型预测结果的影响程度。
灵敏度分析可以帮助确定关键参数,进一步优化模型。
反应模拟的过程中,可以使用不同的数值方法求解动力学方程。
理论模型的解析与建立

理论模型的解析与建立引言在科学研究中,理论模型是构建科学理论的基础。
通过对现有实验结果的解析和观察中发现的规律,我们可以建立起一个理论模型,从而推导出关于现象的准确预测。
本文将探讨理论模型的解析过程以及建立的方法,为读者提供一些关于理论模型的基本认识和应用。
理论模型的解析理论模型的解析是对现有实验结果和观察到的现象进行分析和归纳,以找到其中的规律和规则。
通过解析的过程,我们可以理解到底什么因素影响了现象的发生和变化,从而揭示其中的机理。
下面是一般的理论模型解析过程的步骤:步骤一:数据收集首先,我们需要收集相关的实验数据和观察结果。
这些数据可以来自于实验室测量、野外观察和文献调研等途径。
数据的收集应该尽可能全面、准确和可靠,以保证后续的解析工作能够有实际依据。
步骤二:数据分析在获得数据后,我们需要对其进行分析。
数据分析的方法有很多种,可以利用统计学方法、数据挖掘技术、机器学习算法等进行。
通过数据分析,我们可以找到数据中的规律和趋势,发现可能的关联性和因果关系。
步骤三:规律总结和归纳在数据分析的基础上,我们可以总结出一些数据中的规律和趋势。
通过对规律的总结和归纳,我们可以得到一些初步的理论模型。
这些模型可以是描述现象的数学公式、图表,也可以是基于统计学方法和机器学习算法得到的模型。
步骤四:验证和修正建立初步的理论模型后,我们需要对其进行验证和修正。
验证可以通过实验和观察来进行,验证的结果将反馈给模型,从而修正模型的不足之处。
通过多次验证和修正,我们可以改进理论模型,使其更加准确和完善。
步骤五:建立最终的理论模型最后,通过不断的验证和修正,我们可以建立起一个较为完善的理论模型。
这个模型可以用来预测和解释现象,为进一步的科学研究和实践提供指导。
理论模型的建立理论模型的建立是在解析的基础上,通过利用现有的知识和规律,对模型进行构建和验证的过程。
下面是理论模型建立的步骤:步骤一:理论分析在建立理论模型之前,我们需要对现有的知识进行理论分析。
实验四 虚拟变量模型
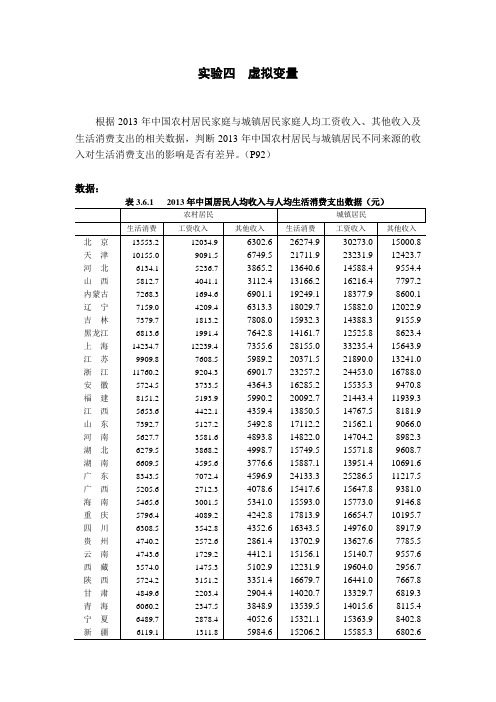
实验四虚拟变量根据2013年中国农村居民家庭与城镇居民家庭人均工资收入、其他收入及生活消费支出的相关数据,判断2013年中国农村居民与城镇居民不同来源的收入对生活消费支出的影响是否有差异。
(P92)数据:1、 可以通过在收入的系数中引入虚拟变量来考察,设⎩⎨⎧=城镇居民,农村居民,01i D则全体居民的消费模型可建立如下:i i i i i X D X Y μβββ++/+=210其中,Y 、X 分别表示居民家庭人均年消费支出与年可支配收入,虚拟变量D 以与X 相乘的方式引入模型,从而可用来考察边际消费倾向的差异。
2、2013年我国农村与城镇居民人均消费函数可写成:农村居民:i i i i X X Y 122110μααα+++=(1,...,2,1n i =) 城镇居民:i i i i X X Y 222110μβββ+++=(1,...,2,1n i =) 将1n 和2n 次观察值合并,估计以下回归模型:i i i i i i i i X D X X D X D Y μδβδβδβ++++++=)()(2222i1111003、操作(1)录入数据打开EViews6,点击“File ”→“New ”→“Workfile ”在命令行输入:DATA Y X1 X2 D1将数据复制粘贴到Group 中的表格中,农村居民的D1为1,城镇居民的D1为0:(2)在命令栏输入命令:GENR D1X1=D1*X1GENR D1X2=D1*X2(3)利用混合样本估计模型,在命令栏输入命令:LE Y C D1 X1 D1X1 X2 D1X2估计结果如图:引入虚拟变量的模型为:2i 2110059.06017.01896.04865.0895.1573145.2599X D X X D X D Y i i i i i i -+++-=∧(3.8199)(-1.6856)(10.2724) (2.3977) (7.0190) (-0.0383) 可以看出,2013年中国农村居民的平均消费支出要比城镇居民少1573.90 元。
最新四种线性代数模型资料

线性代数是高等学校理工科和经济类学科相关专业的一门重要基础课,它不仅是其他数学课程的基础,也是物理、力学、电路等专业课程的基础。
作为处理离散问题工具的线性代数,也是从事科学研究和工程设计的科研人员必备的数学工具之一。
实验一 生物遗传模型1.工程背景设一农业研究所植物园中某植物的基因型为AA 、Aa 和aa 。
常染色体遗传的规律是:后代是从每个亲体的基因对中个继承一个基因,形成自己的基因对。
如果考虑的遗传特征是由两个基因A 、a 控制的,那末就有三种基因对,记为AA 、Aa 和aa 。
研究所计划采用Aa(AA)型的植物与每一种基因型植物相结合的方案培育植物后代。
问经过若干年后,这种植物的任意一代的三种基因型分布如何?2.问题分析分析双亲体结合形成后代的基因型概率,如表6-4所示。
表6-4基因型概率矩阵 后代 基因对 父体—母体的基因对AA —AAAA —Aa AA —aa Aa —Aa Aa —aa aa —aa AA 1 1/2 0 1/4 0 0 Aa 0 1/2 1 1/2 1/2 0 aa1/41/213.模型建立与求解设,,n n n a b c 分别表示第n 代植物中基因型AA 、Aa 、aa 型的植物占植物总数的百分率。
则第n 代植物的基因型分布为()n n n n a x b c ⎛⎫ ⎪= ⎪ ⎪⎝⎭,0(0)00a x b c ⎛⎫ ⎪= ⎪ ⎪⎝⎭表示植物型的初始分布。
依据上述基因型概率矩阵,有1112n n n a a b --=+,1112n n n b b c --=+,0n c =,1n n n a b c ++=,表示为矩阵形式11111/2001/21000n n n n n n a a b b c c ---⎛⎫⎛⎫⎛⎫⎪ ⎪⎪= ⎪ ⎪⎪ ⎪ ⎪⎪⎝⎭⎝⎭⎝⎭记11/2001/21000M ⎛⎫ ⎪= ⎪ ⎪⎝⎭,则()(1)2(2)3(3)(0)n n n n n x MxM x M x M x ---=====。
数学建模第四讲:实验建模

ABCD
微积分法
利用微积分的基本定理和性质,解决连续系统的 建模和求解问题。
ቤተ መጻሕፍቲ ባይዱ
优化方法
利用优化理论和方法,求解最优化问题,如线性 规划、非线性规划等。
模型验证与评估
数据对比
将模型的输出结果与实际数据进行对比,检 验模型的准确性和可靠性。
灵敏度分析
分析模型参数变化对输出结果的影响,了解 模型对参数的敏感性。
间接测量法
利用已知的物理公式或数学模型,通过测量 其他参数来推算所需数据。
实验法
通过实验设计获取数据,需注意实验条件和 操作规范。
数据预处理与清洗
数据清洗
去除异常值、缺失值和重复值。
数据转换
将数据转换为适合分析的格式或类型。
数据归一化
将数据缩放到特定范围,如[0,1]或[1,1]。
数据插值
对缺失数据进行估计填充。
案例二:交通流量预测模型
总结词
基于历史交通流量数据,建立数学模型预测未来交通流量。
详细描述
通过分析历史交通流量数据,利用线性回归、神经网络等算法,建立交通流量预测模型,为交通规划 和管理提供决策依据。
案例三:股票价格预测模型
总结词
基于历史股票价格和相关经济指标,建 立数学模型预测未来股票价格走势。
真实性原则
建立的模型应真实反映实际系统的内在机制和规 律,不能随意简化或忽略重要因素。
可行性原则
确保所选的数学模型在现有技术和资源条件下能 够求解,避免过于复杂或难以实现的模型。
模型求解的方法与技巧
代数法
通过代数运算和方程求解,适用于线性方程和非 线性方程的求解。
数值分析法
通过数值计算和迭代方法,求解离散系统的数值 解,如差分方程、微分方程的数值解。
高中生物实验模型构建教案

高中生物实验模型构建教案
一、实验目的:
本实验旨在通过模型构建的方法,让学生了解生物结构与功能的关系,培养其观察和分析
生物现象的能力。
二、实验材料:
1. 纸板或卡纸
2. 剪刀
3. 胶水
4. 颜色笔
三、实验步骤:
1. 准备纸板或卡纸,根据教师提供的生物结构示意图,分别按照比例将各个结构绘制在纸
板或卡纸上。
2. 利用剪刀将绘制好的生物结构剪下,并按照示意图的要求进行组合,使用胶水进行粘贴。
3. 使用颜色笔对模型进行涂色,使其更具生动感。
4. 完成模型后,学生需在实验报告中描述所构建的模型代表的生物结构及其功能,并分析
其关系。
四、实验要点:
1. 学生在构建模型时应注意结构的比例和组合方式。
2. 在实验报告中要清晰地描述所构建的模型代表的生物结构及其功能。
3. 学生可以借助课本或参考其他资料来更深入地了解所构建模型代表的生物结构。
五、实验评价:
通过本实验,能够培养学生观察和分析生物现象的能力,同时增强他们对生物结构与功能
关系的理解,促进其对生物学的兴趣和学习。
逢考必记高中化学解题模型

逢考必记高中化学解题模型
高中化学解题模型包括实验操作类规范语言表述、方程或方程组法等。
实验操作类规范语言表述包括以下几种:
1. 萃取分液操作:关闭分液漏斗活塞,将混合液倒入分液漏斗中,塞上塞子,用右手心顶住塞子,左手握住活塞部分,将分液漏斗倒置,充分振荡、静置、分层,在漏斗下面放一个小烧杯,先打开上口塞子再打开分液漏斗活塞,使下层液体从下口沿烧杯壁流下,上层液体从上口倒出。
2. 浓H2SO4稀释操作:将浓H2SO4沿烧杯壁缓缓注入水中,并用玻璃棒不断搅拌。
3. 粗盐的提纯:实验室提纯粗盐的实验操作依次为取样、溶解、沉淀、过滤、蒸发、结晶、过滤。
方程或方程组法则是根据质量守恒和比例关系,依据题设条件设立未知数,列方程或方程组求解,是化学计算中最常用的方法。
如果需要更多高中化学解题模型的内容,建议查阅教辅练习资料或咨询专业化学教师。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四类模型的建立
1、实验类型
设计性实验
2、实验目的
(1)理解类的基本概念。
(2)掌握在Rational Rose 中绘制类的操作方法。
(3)掌握在Rational Rose 中绘制类的关联、依赖、泛化关系。
3、实验内容与要求
实验分成两部分:第 1 部通过完成的用例图,初步了解系统的业务功能,对需求进一步分析,从中识别出系统的概念类,对系统进行分析阶段的静态建模;第2 部分要求在第1 部分系统分析的基础上,精化、完善分析阶段的类图,使之成为计算机系统可实现的模型。
运用课堂所学的有关如何抽象出类的知识,完成如下任务:
(1)寻找和抽象出图书管理功能中的类。
(2)识别类间的关系。
(3)精化、完善类图,使之成为计算机系统可实现的模型。
4、实验步骤
4.1 分析阶段的静态建模
1.分析:分析阶段类的识别仅限于业务领域的概念类(或称实体类),根据课堂教授的方法——名词短语策略和不同类别的概念,将图书管理业务领域的实体类识别如下:馆藏书目、馆藏资源品种、图书品种、碟片品种、资源项、借书记录、预定记录、逾期记录、罚款细则、图书管理员、读者。
2.绘制类的步骤:
(1)打开图书管理系统.mdl。
(2)打开Rose 中的Logical View(逻辑视图),鼠标右键单击Logical View 根节点后,选择“New——Package”项,在逻辑视图下建一个名为“Class Diagram”(类图)的包,用于存放图书管理系统的静态模型。
(3)鼠标右键单击新建的“Class Diagram”包,在“Class Diagram”包下建立一张名为“Entity”的业务领域实体类图。
鼠标双击“Entity”类图,在绘图窗口打开这张新建类图。
(4)添加以下如图所示的类
(5)添加类的关联关系:在左边的类图工具栏选取“Unidirectional Association”图标,在右边图的“馆藏书目”类与“馆藏资源品种”类之间添加一个关联,如
下图。
(6)设置关联属性:选中新添加的关联,单击鼠标右键,选择“Open Specification”项,打开该关联的设置对话框。
在name框中为该关联命名:记载;此时可以看到关联的一方Role A 是“馆藏资源品种”类,另一方Role B 是“馆藏书目”类。
点击“Role A Detail”选项,为关联类“馆藏资源品种”定义关联的多重性,在Multiplic 框中选择1..n 即可;同理,点击“Role B Detail”选项,为关联类“馆藏书目”定义关联的多重性,在Multiplic 框中选择1 即可,这表示1个“馆藏书目”中可以记载多个“馆藏资源品种”。
定义完毕的关联,如下图所示。
(7)去掉关联的箭头:在分析阶段,关联的箭头指向暂可以不做考虑,这种具体的指向关系,可以放到设计阶段再进行,故这里要去掉指向“馆藏资源品种”箭头。
选中关联,点击鼠标右键,出现快捷菜单,再次选择“Open Specification”菜单项,再次打开关联的设置对话框,选中Role A Detail 选项,将图中“Navigable”前的“√”去掉,点击OK 即可去掉指向“馆藏资源品种”的箭头。
重复以上
步骤,将其余类之间的关联一一画出、定义,最终下图所示。
(8)定义聚集关联:“馆藏资源品种”与“资源项”是整体——部分的聚集关联,一个馆藏资源品种是由若干资源项组成,为了将这种特殊的关联用UML 表示出来,可以选中二者间的关联直线,点击鼠标右键,再次选择“Open Specification”菜单项,打开关联的设置对话框,此时我们可以看到“馆藏资源品种”对应的是Role B(即角色B)。
点击“Role B Detail”选项,将图中“Aggregate”前打“√”,点击OK 即可在“馆藏资源品种”端添加聚合。
(9)添加类的泛化关系:“馆藏资源品种”是“图书品种”和“碟片品种”的父类,故二者之间是类的泛化关系,为了将它们的泛化关系用UML 语言表示出来,要在主界面左边的类图工具栏中选取“Generalization”图标,在右边图的“馆藏资源品种”类与“图书品种”类之间添加一个泛化关联;同样,在右边图的“馆
藏资源品种”类与“碟片品种”类之间添加一个泛化关联。
(10)至此,图书管理系统分析阶段的静态建模结束,点击主菜单“File——Save”完成对“图书管理系统.mdl”模型文件的保存。
4.2 设计阶段的静态建模
1.分析:设计阶段类的静态建模包括两方面:第1 方面是将分析阶段识别的领域实体类进一步细化,将分析阶段识别的汉语的类名、属性名和方法名转变为英文的类名、属性名和方法名,这样便于后续正向工程代码框架的生成,同时要将分析阶段未识别出来的属性、方法补充进去;第2方面,要根据软件体系结构的分层模式,为静态模型添加边界类和控制类,绘制一张反映边界类、控制类、实体类三者关系的总体图。
2.绘制的步骤:
(1)打开图书管理系统.mdl。
(2)打开Rose 中的Logical View(逻辑视图)节点下“Class Diagram”包中的“Entity”实体类图,鼠标右键单击“借书记录”类,选择“Open Specification”菜单项,打开类设置对话框,更改类名“借书记录”为“Loan”,点击“Attributes”选项,将name 框中的属性名“借书日期”更改为“lendDate”;在Type 框中定义属性类型为“Date”型;在“Export Control 框中定义属性的可见性(即作用域)为“Private”私有属性。
点击OK 按钮即可完成该属性的定义;以此类推完成属性“还书日期”的详细设计,同时设计阶段增加一个“LoanID”属性,String 类型,用于标识一个借书记录;增加一个“dueDate”属性(截止期限日期),Date
类型,用于逾期的处理。
如下图所示:
(3)设计类的方法:鼠标右键单击“Loan”类,在出现的快捷菜单中,选择“Open Specification”菜单项,打开类设置对话框,点击“Operations”选项,鼠标双击“设置借书日期”方法,打开设置该方法的对话框,将name 框中的方法名“设置借书日期”更改为“setlendDate”;在Return 框中定义方法的返回类型为“void”型;在“Export Control 框中定义方法的可见性(即作用域)为“Public”公有方法。
(4)定义类方法的参数:在“Detail”选项界面的“Arguments”的空白处单击鼠标右键出现快捷菜单,选择“Insert”菜单项,添加一个参数,参数名为“ADate”,在Type 框中设置参数类型为“Date”型。
以此类推,重复步骤,完成方法“设置还书日期(setreturnDate)”(参数为ADate:Date 型,返回类型为void),“取得借书日期(getlendDate)”、“取得还书日期(getreturnDate)”(无参数,返回值为Date 型)三个方法的更改设计。
另外对应于新增加的属性“dueDate”,添加类的两个新方法:“getdueDate”(参数、返回值与方法getlendDate 相同)和“setdueDate”(参数、返回值与方法setlendDate 相同)。
(5)至此,借书记录类“Loan”的详细设计完成,以此类推,在分析阶段的基础上,完成其他类属性和方法的详细设计。
(6)设计阶段需要添加边界类、控制类,在添加之前,需要建立一个实体类子包“BO”,用于存放上述设计的实体类。
首先在主界面的导航窗口中,鼠标右击”ClassDiagram”包,选择“New——Package”菜单项,在“Class Diagram”下建立一个名为“BO”的实体子包。
在导航窗口中,按住鼠标左键不放,将已建好的实体类拖入到“BO”子包下,类似于Windows 资源管理器的移动文件操作,
移动完成后,将如下所示。
(7)设计边界类:与第(6)步相似,在导航窗口“Class Diagram”包下建立边界类子包“UI”,子包下添加一个界面类“MainWindow”。
(8)以此类推,完成其他边界类的添加(LendWindow、ReturnWindow、QueryWindow、ReservationWindow、MaintainReaderWindow 和MaintainResourceWindow)。
由于边界类一般情况下不需要设置属性,方法也是在设计完顺序图后Rose 自动添加,为此,在这里只要为“MainWindow”主界面类添加一个方法main(参数args 属于String[]型,返回类型为void)即可。
(9)设计控制类:参照设计边界类的步骤,为控制类在“Class Diagram”
包下建立一个“CO”子包,并在“CO”子包下添加控制类(LendLogic、ReturnLogic、QueryLogic、ReservationLogic、MaintainReaderLogic 和MaintainResourceLogic)。
控制类和边界类相类似,一般情况下,不需要设置属性,方法也是在设计完顺序图后Rose 自动添加,因此,控制类添加完成后,如图所示。
(10)至此,实体类、边界类和控制类均已添加完毕。
(11)首先按住鼠标左键不放,将导航窗口Use Case View 节点下的参与者“图书管理员”和“读者”拖到类图Overall 的绘图窗口中,然后用同样的方法,将“UI”子包下的边界类拖到类图Overall 的绘图窗口中,以此类推,再将“CO”子包中的控制类拖到类图Overall 的绘图窗口中。