酶切回文识别序列
实验六-酶切

五、利用限制性内切酶克隆
克隆PCR产物的方法之一,是在PCR产物两端设
计一定的限制酶切位点,经酶切后克隆至用相同 酶切的载体中。但实验证明,大多数限制酶对裸 露的酶切位点不能切断。必须在酶切位点旁边加 上一个至几个保护碱基,才能使所定的限制酶对 其识别位点进行有效切断。 酶切位点(内切酶的识别序列)要加在引物的 5‘端 具体为:5'-保护碱基+酶切位点+引物序列-3'
四、使用限制酶注意事项
当微量的污染物进入限制性内切酶贮存液中时,会影响其进
一步使用,因此在吸取限制性内切酶时,每次都要用新的吸 管头。如果采用两种限制性内切酶,必须要注意分别提供各 自的最适盐浓度。 若两者可用同一缓冲液,则可同时水解。 若需要不同的盐浓度,则低盐浓度的限制性内切酶必须首先 使用,随后调节盐浓度,再用高盐浓度的限制性内切酶水解。 也可在第一个酶切反应完成后,用等体积酚/氯仿抽提,加0.1 倍体积3mol/L NaAc和2倍体积无水乙醇,混匀后臵-70℃低温 冰箱30分钟,离心、干燥并重新溶于缓冲液后进行第二个酶 切反应。
割双链。但这几个核苷酸对则是任意的。
第二类内切酶
酶识别的专一核苷酸顺序最常见的是4个或6个核苷酸
识别顺序是一个回文对称顺序,即有一个中心对称轴
同尾酶;切割不同的DNA片段但产生相同的粘性末端的 一类限制性内切酶。
这一类的限制酶来源各异,识别的靶序列也不相同,但产生相
同的粘性末端。 由同尾酶产生的DNA片段,是能够通过其粘性末端之间的互补 作用彼此连接起来的。当把同尾酶切割的DNA片断与原来的限 制性内切酶切割的DNA片段连接后,原来的酶切位点将不存在, 不能被原来的限制性内切酶所识别。
识别序列为非回纹对称结构限制核酸酶的正确切割位点

(. 国农 业 大学农 业 生物 技术 国家 实验 室 , 京 10 9 ;. 国农 业大 学动 物科 学技 术学 院 , 京 10 9) 1中 北 00 42 中 北 0 0 4
摘
要 : 制 性 内切 核 酸 酶 的 切 割 识 别 序 列 分 为 回 纹 对 称 和 非 回 纹 对 称 结 构 两 类 , 于 DNA 是 互 补 双 链 ,所 以 对 限 由
t o s r ndsOfD N A w e e oti ntc 、T her f e t e r r o w ta r n de i al e or h t ue ec gnii s que e ar zng e nc s e not onl y one n hi .I t s exp i er—
中 图 分 类 号 : 5 . Q5 6 4 文献 标 识码 : A 文 章 编 号 : 2 3 9 7 ( 0 2) 4 0 2 0 5 — 7 2 2 0 0 — 4 0—0 3
The Tr e R e o ni i e e e o h e t i to u c g z ng S qu nc f t e R s r c i n Enz m e W h s y o e R e o ni i e c g z ng S que e i o nc s N npa i dr m i ln o c
he i c lx om p e e ar t a l m nt y s r nds .So t e o he r c gni i e zng s que e lndr nc s ofpa i om e e ym e i w o standsofD N A e e i nt— nz n t r w r de i
酶切位点识别序列
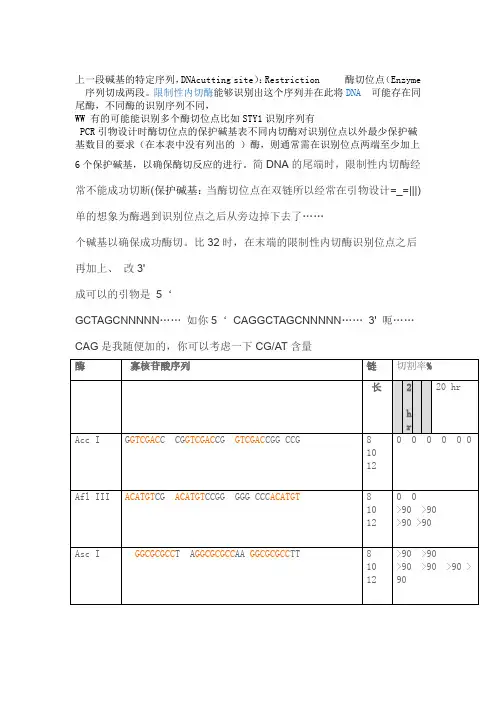
上一段碱基的特定序列,DNAcutting site):Restriction 酶切位点(Enzyme 序列切成两段。
限制性内切酶能够识别出这个序列并在此将DNA可能存在同尾酶,不同酶的识别序列不同,
WW 有的可能能识别多个酶切位点比如STY1识别序列有
PCR引物设计时酶切位点的保护碱基表不同内切酶对识别位点以外最少保护碱
基数目的要求(在本表中没有列出的)酶,则通常需在识别位点两端至少加上
6个保护碱基,以确保酶切反应的进行。
简DNA的尾端时,限制性内切酶经常不能成功切断(保护碱基:当酶切位点在双链所以经常在引物设计=_=|||)单的想象为酶遇到识别位点之后从旁边掉下去了……
个碱基以确保成功酶切。
比32时,在末端的限制性内切酶识别位点之后
再加上、改3'
成可以的引物是5‘
GCTAGCNNNNN……如你5‘CAGGCTAGCNNNNN……3' 呃……CAG是我随便加的,你可以考虑一下CG/AT含量
注释
1.如果要加在序列的5'端,就在酶切位点识别碱基序列(红色)的5'端加上相应的碱基(黑色),如果要在序列的3'端加上保护碱基,就在酶切位点识别碱基序列(红色)的3'端加上相应的碱基(黑色)。
2.切割率:正确识别并切割的效率。
加保护碱基时最好选用切割率高时加的相应碱基。
3.。
限制酶bamhi识别序列

限制酶bamhi识别序列
BamHI是一种限制酶,它识别的DNA序列为5'-G|GATCC-3',其
中竖线表示酶切位点。
这意味着BamHI在G和A之间切割DNA链。
这个识别序列是对称的,也就是说,它在DNA的两条链上都有相同
的序列。
这种对称性使得BamHI能够在DNA双螺旋结构中切割两条链,形成突出的粘性末端。
从生物学角度来看,BamHI限制酶的识别序列在分子生物学和
基因工程领域被广泛应用。
科研人员可以利用BamHI酶切割特定的DNA序列,从而在DNA分子中创建特定的切口,为后续的DNA连接、插入或分析提供方便。
在实验室中,科研人员通常会在特定的实验条件下使用BamHI 酶,以确保其能够准确地识别和切割DNA序列。
此外,他们还会根
据实验需要选择合适的缓冲液、温度和反应时间等因素,以最大限
度地发挥BamHI酶的作用。
另外,从应用角度来看,了解BamHI限制酶的识别序列有助于
科研人员在实验设计和数据分析中更好地利用这一工具。
他们可以
根据BamHI的识别序列来设计引物或探针,进行特定基因的扩增或
检测。
同时,对BamHI的识别序列有深入的了解,也有助于科研人
员在实验过程中更好地控制酶切反应的准确性和效率。
综上所述,了解BamHI限制酶的识别序列对于分子生物学和基
因工程领域的研究具有重要意义,它不仅为科研人员提供了一种重
要的DNA操作工具,同时也为实验设计和数据分析提供了有力支持。
基因工程名词解释

名词解释【基因工程】:在体外对不同生物的遗传物质(基因)进行剪切、重组、连接,然后插入到载体分子中(细菌质粒、病毒或噬菌体DNA),转入微生物,植物或动物细胞内进行无性繁殖,并表达出基因产物。
【限制性核酸内切酶】:是一类能够识别双链DNA分子中的某种特定核苷酸序列(4-8bp),并由此处切割DNA双链结构的核酸内切酶。
【识别序列】:限制性核酸内切酶在双链DNA上能够识别的特殊核苷酸序列被称为识别序列。
【酶切位点】:DNA在限制性核酸内切酶的作用下,使多聚核苷酸链上磷酸二酯键点开的位置被称为切割位点。
【粘性末端】:是指含有几个核苷酸单链的末端,可通过这种末端的碱基互补,使不同的 DNA片段发生退火。
【平末端】:限制酶在它识别序列的中心轴线处切开时产生的平齐的末端。
【同裂酶】:一些来源不同的但能识别位点的序列相同的限制性内切酶。
【同尾酶】:一些来源不同且识别序列不同,但能产生相同粘性末端的限制性内切酶。
【DNA的甲基化程度】:DNA被甲基化酶甲基化,识别序列中的核苷酸一旦被甲基化,就会影响内切酶的切割效率。
【位点偏爱】:对不同位置的同一个识别序列表现出不同的切割效率的现象【内切酶的star活性】:某种限制性核酸内切酶在特定条件下,可在不是原来的识别序列处切割DNA,这种现象称为star活性。
【末端转移酶】:一种能将脱氧核苷酸三磷酸(dNTP)加到某DNA片段上3’-OH基上的酶。
【DNA连接酶】:借助ATP或NAD水解提供的能量催化DNA双链,DNA片段紧靠在一起的3’-OH末端与5’-PO4末端之间形成磷酸二酯键,使两末端连接【DNA聚合酶】:以DNA为复制模板,使DNA由5'端点开始复制到3'端的酶。
【反转录酶】:与DNA聚合酶作用方式相似:5’→3’聚合,模版是mRNA,合成DNA【碱性磷酸酶】:能够催化核酸分子脱掉5’磷酸基团,从而使DNA(或RNA)片段的5’-P 末端转换成5’-OH末端。
限制酶识别序列

二轮小专题限制酶识别序列一.回文诗:静思伊久阻归期,久阻归期忆别离;忆别离时闻漏转,时闻漏转静思伊。
赏花归去马如飞,去马如飞酒力微。
酒力微醒时已暮,醒时已暮赏花归。
二.DNA回文序列限制性内切酶Ⅱ类酶有EcoR I、BamH I、Hind Ⅱ、Hind Ⅲ等。
其分子量小于105道尔顿;反应只需Mg2+;最重要的是在所识别的特定碱基顺序上有特异性的切点,因而DNA分子经过Ⅱ类酶作用后,可产生特异性的酶解片断,这些片断可用凝胶电泳法进行分离、鉴别。
限制性内切酶识别DNA序列中的回文序列。
有些酶的切割位点在回文的一侧(如EcoR I、BamH I、Hind等),因而可形成粘性末端,另一些Ⅱ类酶如Alu I、BsuR I、Bal I、Hal Ⅲ、HPa I、Sma I等,切割位点在回文序列中间,形成平整末端。
Alu I的切割位点如下:5'-A G^C T-3'3'-T C^G A-5'酶类型识别序列ApaI Type II restriction enzyme 5'GGGCC^C 3' BamHI Type II restriction enzyme 5' G^GATCC 3' BglII Type II restriction enzyme 5' A^GATCT 3' EcoRI Type II restriction enzyme 5' G^AATTC 3' HindIII Type II restriction enzyme 5' A^AGCTT 3' KpnI Type II restriction enzyme 5' GGTAC^C 3' NcoI Type II restriction enzyme 5' C^CATGG 3' NdeI Type II restriction enzyme 5' CA^TATG 3' NheI Type II restriction enzyme 5' G^CTAGC 3' NotI Type II restriction enzyme 5' GC^GGCCGC 3' SacI Type II restriction enzyme 5' GAGCT^C 3' SalI Type II restriction enzyme 5' G^TCGAC 3' SphI Type II restriction enzyme 5' GCATG^C 3' XbaI Type II restriction enzyme 5' T^CTAGA 3' XhoI Type II restriction enzyme 5' C^TCGAG 3'。
酶切位点识别序列
酶切位点(Restriction Enzyme cutting site):DNA上一段碱基的特定序列,能够识别出这个序列并在此将序列切成两段。
可能存在同尾酶,不同酶的识别序列不同,
有的可能能识别多个酶切位点比如STY1识别序列有WW
PCR引物设计时酶切位点的保护碱基表
不同内切酶对识别位点以外最少保护碱基数目的要求(在本表中没有列出的酶,则通常需在识别位点两端至少加上6个保护碱基,以确保酶切反应的进行。
)
保护碱基:当酶切位点在双链DNA的尾端时,限制性内切酶经常不能成功切断(简单的想象为酶遇到识别位点之后从旁边掉下去了…… =_=|||)所以经常在引物设计时,在末端的限制性内切酶识别位点之后再加上2、3个碱基以确保成功酶切。
比如你的引物是5‘ GCTAGCNNNNN……3’ 可以改成5‘ CAGGCTAGCNNNNN……3’ 呃……CAG是我随便加的,你可以考虑一下CG/AT含量
注释
1.如果要加在序列的5’端,就在酶切位点识别碱基序列(红色)的5’端加上相应的
碱基(黑色),如果要在序列的3’端加上保护碱基,就在酶切位点识别碱基序列(红色)的3’端加上相应的碱基(黑色)。
2.切割率:正确识别并切割的效率。
3.加保护碱基时最好选用切割率高时加的相应碱基。
酶切位点识别序列
酶切位点识别序列 Document serial number【KKGB-LBS98YT-BS8CB-BSUT-BST108】
酶切位点(Restriction Enzyme cutting site):DNA上一段碱基的特定序列,能够识别出这个序列并在此将序列切成两段。
可能存在同尾酶,不同酶的识别序列不同,
有的可能能识别多个酶切位点比如STY1识别序列有WW
PCR引物设计时酶切位点的保护碱基表
不同内切酶对识别位点以外最少保护碱基数目的要求(在本表中没有列出的
注释
1.如果要加在序列的5’端,就在酶切位点识别碱基序列(红色)的5’端加上相应的
碱基(黑色),如果要在序列的3’端加上保护碱基,就在酶切位点识别碱基序列(红色)的3’端加上相应的碱基(黑色)。
2.切割率:正确识别并切割的效率。
3.加保护碱基时最好选用切割率高时加的相应碱基。
dna回文序列
dna回文序列dna回文序列解释如下:如果一个(单链)核苷酸的序列和它的反向互补链的序列一样,那么这个核苷酸序列就是回文序列。
回文序列结构不仅在DNA中存在,在RNA中也常因碱基的互补而常出现类似的结构,有利于稳定RNA的结构和行使功能[1] 。
回文序列也经常出现在组成蛋白质的肽序列中,但它们在蛋白质功能中的作用尚不清楚。
短的回文结构可能是一种特别的信号,如限制性内切酶的识别序列。
较长的回文结构容易转化成发夹结构,可能有助于DNA与特异性DNA结合蛋白结合。
特征有对称中心。
例如,DNA序列ACCTAGGT之所以是回文序列,是因为它的互补序列是TGGATCCA,而反向互补序列是ACCTAGGT,和其原来序列一致。
功能1)是限制性内切酶的识别位点;2)具有调节基因的表达作用,如色氨酸操纵子的前的弱化子;3)转录终止时的识别结构;4)基因工程的"手术刀"。
例子限制性酶切位点回文序列在分子生物学中起着重要的作用。
许多限制性内切酶能识别特定的回文序列并切割它们。
比如,限制性内切酶EcoR1识别以下回文序列:5'- G A A T T C -3'3'- C T T A A G -5'甲基化位点回文序列也可能有甲基化位点。
这些是甲基可以附着在回文序列上的位点。
T细胞受体中的回文核苷酸T细胞受体(TCR)基因的多样性是通过从其生殖系编码的V、D和J段重新排列后的插入核苷酸而产生的。
在V-D和D-J连接处的核苷酸插入是随机的,但其中的一些小的子集插入是例外,一到三个碱基对反向重复生殖系DNA的序列。
这些短的互补的回文序列称为P 核苷酸。
酶切位点识别序列
酶切位点识别序列 Last revised by LE LE in 2021
酶切位点(Restriction Enzyme cutting site):DNA上一段碱基的特定序列,能够识别出这个序列并在此将序列切成两段。
可能存在同尾酶,不同酶的识别序列不同,
有的可能能识别多个酶切位点比如STY1识别序列有WW
PCR引物设计时酶切位点的保护碱基表
不同内切酶对识别位点以外最少保护碱基数目的要求(在本表中没有列出的
注释
1.如果要加在序列的5’端,就在酶切位点识别碱基序列(红色)的5’端加上相应的
碱基(黑色),如果要在序列的3’端加上保护碱基,就在酶切位点识别碱基序列(红色)的3’端加上相应的碱基(黑色)。
2.切割率:正确识别并切割的效率。
3.加保护碱基时最好选用切割率高时加的相应碱基。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DdeI
Hinf I
Sau96 I
□□▼N□□
ScrF I
Fnu4H I
□□N▼□□
HpyCH4 III
Hpy188 I
□□N□▼□
Fmu I
□□N□□▼
▼□□A/T□□
PspG I
□▼□A/T□□
Tfi I
ApeK I
Tse I
Ava II
□□▼A/T□□
BstN I
□□A/T▼□□
□□A/T□▼□
Nru I
Fsp I
Msc I
Psi I
Dra I
T□□□▼□A
T□□□□▼A
五核苷回文识别序列
AA□TT
AC□GT
AG□CT
AT□AT
CA□TG
CC□GG
CG□CG
CT□AG
GA□TC
GC□GC
GG□CC
GT□AC
TA□TA
TC□GA
TG□CA
TT□AA
▼□□N□□
BssK I
StyD4 I
Mae III
Sma I
MspA1 I
C□□□▼□G
Sac II
Pvu I
BsiE I
BsiE I
C□□□□▼G
Pst I
G▼□□□□C
EcoR I
ApoI
NgoM IV
BsrF I
BssH II
Nhe I
BamH I
BstY I
Kas I
Ban I
PspOM I
Acc65 I
Ban I
Sal I
ApaL I
G□▼□□□C
Bbe I
Hae II
Apa I
Ban II
Bme1580 I
Bsp1286 I
Kpn I
Bme1580 I
Bsp1286 I
BsiHKA I
T▼□□□□A
BspH I
BspE I
BsaW I
Xba I
Bcl I
Eae I
BsrG I
Tat I
T□▼□□□A
BstB I
T□□▼□□A
SnaB I
BsaA I
BsaW I
Mlu I
Afl III
Spe I
Bgl II
BstY I
Tat I
A□▼□□□T
Acl I
Cla I
BspD I
Ase I
A□□▼□□T
Ssp I
Afe I
Stu I
Sca I
BfrB I
A□□□▼□T
A□□□□▼T
Nsp I
Hae II
Nsi I
C▼□□□□G
Mfe I
Nco I
Sty I
Btg I
Xma I
Ava I
BsoB I
Btg I
Avr II
Sty I
Eag I
Eae I
BsiW I
Sfc I
PaeR7 I
Tli I
Xho I
Ava I
BsoB I
Sml I
Sfc I
Afl II
Sml I
C□▼□□□G
Nde I
C□□▼□□G
Pml I
BsaA I
Pvu II
MspA1 I
HinP1 I
Csp6 I
Taq I
Mse I
□□▼□□
Alu I
CviJ I
Bst U I
Dpn I
Hae III
Pho I
CviJ I
Rsa I
HpyCH4 V
□□□▼□
Hha I
□□□□▼
Tai I
Nla III
A▼□□□□T
ApoI
Hind III
Pci I
Afl III
Age I
BsrF I
□□A/T□□▼
Hpy99 I
▼□□G/C□□
Tsp45 I
□▼□G/C□□
□□▼G/C□□
Nci I
□□G/C▼□□
□□G/C□▼□
AspCN I
□□G/C□□▼
四和六核苷回文识别序列
AATT
ACGT
AGCT
ATAT
CATG
CCGG
CGCG
CTAG
GATC
GCGC
GGCC
GTAC
TATA
TCGA
TGCATTAAຫໍສະໝຸດ ▼□□□□Tsp509 I
Fat I
BfuC I
Dpn II
Mbo I
Sau3AI
□▼□□□
HpyCH4 IV
CviA II
Msp I
Hpa II
Bfa I
BsaH I
Nar I
BsaH I
Acc I
Acc I
G□□▼□□C
Zra I
Ecl136 II
EcoR V
Nae I
Sfo I
BstZ17 I
Hinc II
Hpa I
Hinc II
G□□□▼□C
G□□□□▼C
Aat II
Sac I
Ban II
BsiHKA I
Bsp1286 I
Sph I
Nsp I
Bmt I