9西安电子科技大学《编译原理》
电子科大-编译原理实验报告(得分80分)

电子科技大学实验报告学生姓名:爸爸学号:2222222222222 指导教师:陈昆实验地点:科研楼A-506 实验时间:2017-04-28一、实验项目名称:词法分析器的设计与实现二、实验学时:4学时三、实验原理1.编译程序要求对高级语言编写的源程序进行分析和合成,生成目标程序。
词法分析是对源程序进行的首次分析,实现词法分析的程序为词法分析程序或词法分析器,也称扫描器。
2.词法分析的功能是:从左到右逐个地扫描源程序字符串,按照词法规则,识别出单词符号作为输出,对识别过程中发现的词法错误,输出相关的错误信息。
3.识别出来的单词会采用某种中间表现形式,通常一个单词用一个二元式来表示:(单词类别,单词的属性)。
4.状态转换图简称转化图,是有限有向图,是设计词法分析器的有效工具。
四、实验目的通过该实验,让同学们自己独立自主的设计词法分析器,使得同学们可以更好的掌握词法分析程序设计的原理及相应的程序设计方法,对编译这门课程也可以有更加深刻理解,同时还可以锻炼编程能力。
五、实验内容实现求n!的极小语言的词法分析程序,返回二元式作为输出。
六、实验器材(设备、元器件)1.操作系统:Windows XP2.开发工具:VS2013七、实验步骤(1)在VS2013中创建工程;(2)编写输入输出,初始化,错误处理等函数;(3)建立相应的单词符号与种别对照表,根据状态转换图编写相应的处理函数;(4)运行代码进行调试;(5)编写测试需要的输入文件:.pas文件;(6)生成.dyd文件。
八、实验数据及结果分析编码完成后将测试程序放入debug文件夹中,测试程序如下图:代码运行成功后在debug文件夹中会产生对应的exe,在cmd中运行后,会在debug文件夹中生成后缀为dyd和err的文件,打开dyd如下图所示:因为没有错误,所以对应的test1.err的文件为空可以对源程序进行词法分析,如果有错给出出错信息和所在行数,如果无错则生成二元式文件。
电子科技大学编译原理--A2答案--网络教育

《计算机编译原理》试卷A2参考答案一、单项选择题(每小题1分,共25分)1、构造编译程序应掌握___D___。
A、源程序B、目标语言C、编译方法D、以上三项都是2、变量应当___C___。
A、持有左值B、持有右值C、既持有左值又持有右值D、既不持有左值也不持有右值3、编译程序绝大多数时间花在___D___上。
A、出错处理B、词法分析C、目标代码生成D、管理表格4、___D___不可能是目标代码。
A、汇编指令代码B、可重定位指令代码C、绝对指令代码D、中间代码5、使用___A___可以定义一个程序的意义。
A、语义规则B、词法规则C、产生规则D、词法规则6、词法分析器的输入是___B___。
A、单词符号串B、源程序C、语法单位D、目标程序7、中间代码生成时所遵循的是___C___。
A、语法规则B、词法规则C、语义规则D、等价变换规则8、编译程序是对___D___。
A、汇编程序的翻译B、高级语言程序的解释执行C、机器语言的执行D、高级语言的翻译9、文法G:S→xSx|y所识别的语言是___C___。
A、xyxB、(xyx)*C、x n yx n(n≥0)D、x*yx*10、文法G描述的语言L(G)是指___A___。
A、L(G)={α|S+ ⇒α ,α∈V T*}B、L(G)={α|S*⇒α,α∈V T*}C、L(G)={α|S*⇒α,α∈(V T∪V N*)}D、L(G)={α|S+ ⇒α,α∈(V T∪V N*)}11、有限状态自动机能识别___C___。
A、上下文无关文法B、上下文有关文法C、正规文法D、短语文法12、设G为算符优先文法,G的任意终结符对a、b有以下关系成立___C___。
A、若f(a)>g(b),则a>bB、若f(a)<g(b),则a<bC、A~B都不一定成立D、A~B一定成立13、如果文法G是无二义的,则它的任何句子α___A___。
A、最左推导和最右推导对应的语法树必定相同B、最左推导和最右推导对应的语法树可能不同C、最左推导和最右推导必定相同D、可能存在两个不同的最左推导,但它们对应的语法树相同14、由文法的开始符经0步或多步推导产生的文法符号序列是___C___。
电子科技大学编译原理--B答案--网络教育

《计算机编译原理》试卷B参考答案一、单项选择题(每小题1分,共25分)1、有文法G:E→E*T|TT→T+i|i句子1+2*8+6按该文法G归约,其值为___B___。
A、23B、42C、30D、172、规范归约指___B___。
A、最左推导的逆过程B、最右推导的逆过程C、规范推导D、最左归约的逆过程3、词法分析所依据的是___B___。
A、语义规则B、构词规则C、语法规则D、等价变换规则4、词法分析器的输出结果是___C___。
A、单词的种别编码B、单词在符号表中的位置C、单词的种别编码和自身值D、单词自身值5、正规式M1和M2等价是指___C___。
A、M1和M2的状态数相等B、M1和M2的有向弧条数相等C、M1和M2所识别的语言集相等D、M1和M2状态数和有向弧条数相等6、下面的状态转换图接受的字集为___D___。
A、以0开头的二进制数组成的集合B、以0结尾的二进制数组成的集合C、含奇数个0的二进制数组成的集合D、含偶数个0的二进制数组成的集合7、词法分析器作为独立的阶段使整个编译程序结构更加简洁、明确,因此,___B___。
A、词法分析器应作为独立的一遍B、词法分析器作为子程序较好C、词法分析器分解为多个过程,由语法分析器选择使用D、词法分析器并不作为一个独立的阶段8、若a为终结符,则A→α·aβ为___B___项目A、归约B、移进C、接受D、待约9、若项目集I k含有A→α·,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α·”动作的一定是___D___。
A、LALR文法B、LR(0)文法C、LR(1)文法D、SLR(1)文法10、就文法的描述能力来说,有___C___。
A、SLR(1)⊂LR(0)B、LR(1)⊂LR(0)C、SLR(1)⊂LR(1)D、无二义文法⊂LR(1)11、在LR(0)的ACTION子表中,如果某一行中存在标记“r j”的栏,则___A___。
西安电子科技大学编译原理 (10)

L →E ; L | ε E →TE' E'→ + T E' | - T E' | ε T →FT' T'→*F T'|/FT'|mod FT'|ε F →(E) | id | num
L →E ; L | ε E →TE' E'→ + T E' | - T E' | ε T →FT' T'→*F T'|/FT'|mod FT'|ε F →(E) | id | num
对文法的每个产生式A→α ② 对FIRST(α)的每个终结符a,加入α 到M[A,a]; ③ 若ε∈FIRST(α),则FOLLOW(A)每 个终结符b(包括#),加入α到M[A, b];
/ mod ( E;L TE' ε ε ) ; # ε
+
-
*
E'
T T' F
id
num
(E)
3.4 自上而下语法分析
...
E
T T F F id T FT
T
T FT
6
非终 结符 E E T T
输 入 符 号
id
E TE
+
E +TE
...
T FT T T FT
F
F id
栈
输
入
输
出
$E
id id + id$
id id + id$ id id + id$ id id + id$ id + id$ id + id$ id + id$ id + id$ F id
编译原理

习惯称法 汇编语言-机器指令:汇编(或交叉汇编) 程序设计语言-汇编语言或机器指令:编译(或解释) 高级语言之间:转换(或预编译) 逆向:反汇编、反编译
19
1.3 编译器与解释器
语言翻译的两种基本形态 先翻译后执行
源程序 编译器 目标程序 输出
边翻译边执行
源程序 输入数据
解释器
1.4 编译器的工作原理与基本组成
position = initial + rate 60
词法分析器
• 标识符position形成的记号是<id, 1> • id是标识符的总称 • 1代表position在符号表中的条目 • 符号表的条目用来存放标示符的 各种属性
• 赋值号=形成的记号是<assign> id, 1 = id, 2 + id, 3 60 •该记号只有一个实例,不需 要属性值来区分实例 •为了直观,记作<=> 符 号 表 • 标识符initial形成的记号是<id,2> 1 position ...
Java 处 理 过 程
计算机能够识别的语言
2
课程简介
翻译
汉语普通话
课程简介
高级程序设计语言
编译 (解释)
处 理 过 程
C 处 理 过 程
C++ 处 理 过 程
Java 处 理 过 程
My PL 处 理 过 程
计算机能够识别的语言
课程简介 介绍编 译器的 原理和 基本实 现方法
源程序 词法分析 语法分析 符 号 表 管 理 语义分析 中间代码生成 代码优化 目标代码生成 目标代码
17
1.1 从面向机器的语言到面向人类的语言
编译原理 答案

a a b b
X
Y
b
图2-2 习题2.3的NFA M
•
用子集法构造状态转换矩阵,如 表2-1所示。
表2-1 状态转换矩阵
I {x} {y} {x,y} Ia {x,y} — {x,y} Ib {y} {x,y} {x,y}
•
将转换矩阵中的所有子集重新命 名,形成表2-2所示的状态转换矩阵,即 得到 • M′=({0,1,2},{a,b},f,0,{1,2}), 其状态转换图如图2-3所示。
•
• G[A]:A→aA|bB|b • •
•
• • • • • • •
2.8 下列程序段以B表示循环体, A表示初始化,I表示增量,T表示测试: I=1; while (I<=n) { sun=sun+a[I]; I=I+1; } 请用正规表达式表示这个程序段 可能的执行序列。
•
【解答】 用正规表达式表示程 序段可能的执行序列为A(TBI)*。 • 2.9 将图 2-19 所示的非确定有 限自动机(NFA)变换成等价的确定有限自 动机(DFA)。
Ia {1,2} {1,2} {1,2}
Ib {1,2,Y} {1,2,Y} {1,2,Y} 重新命名
S 1 2 3
a 2 2 2
b 3 3 3
图2-18 图2-17确定化后的状态转换矩阵
•
比较图2-18与图2-15,重新命名 后的转换矩阵是完全一样的,也即正规 式 (a|b)*b 可以同样得到化简后的 DFA 如 图 2-16 所示。因此,两个自动机完全一 样,即两个正规文法等价。 (2) 对图2-16,令A对应状态1, B对应状态2,则相应的正规文法G[A]为 B→aA|bB|b G[A] 可 进 一 步 化 简 为 G[S] :
西安电子科技大学编译原理 (1)
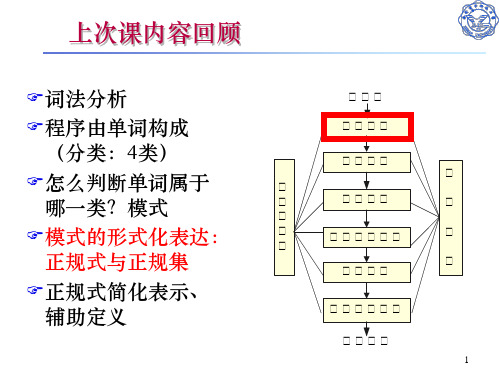
8
b
2.3 记号的识别-有限自动机
NFA如何识别记号? 对字符串,从初态开始,是否可以经过一系列状态转 移到达终态? 例如:字符串abb是否可以被上页的NFA所识别
S = {0, 1, 2, 3} Σ = {a, b} move = { move(0, a) = {0, 1}, move(0, b) = 0, move(1, b) = 2, move(2, b) = 3 } s0 = 0 F = {3}
digit1=[1-9]
num=digit1(digit)*(ε |.digit*digit1)
3
2.3 记号的识别-有限自动机
正规式(模式的描述)
有限状态自动机(识别记号)
id = letter(letter|num)*
69fed? F987y?
正规式:(((letter|digit)*num)*|digit*}num)*
辅助定义
letter=[a-z,A-Z] digit=[0-9]
id = letter(letter|digit)* literal=“(letter|digit)*”
integer=digit digit*
num=integer(ε| . integer)
0000.0000 ? 0000.0000?
18
2.3 记号的识别-有限自动机
DFA对NFA施加的两条限制: 限制1:没有ε状态转移 限制2:同一状态经过同一字符最多有一个状态转移 [例2.10] 正规式(a|b)*abb的DFA,识别输入序列abb和abab:
a a b 0 b a a 3 2 b 1 b
0 1 2 3
a 1 1 1 1
西电编译原理_第二章习题解答

最终的正规式: 1* | 1*(01|0)* = 1*(01|0)*
© 西安电子科技大学 · 软件学院
5
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路2:考虑包含 011 的串,然后构造没有011的串 ① 含有 子串 011 的最简单的串:
然后据上,考查每条从初态到终态的路径,综合正规式即可。
© 西安电子科技大学 · 软件学院 9
2.依据NFA/DFA,给出正规式
习题2.10 (2) 用正规式描述 DFA 所接受的语言;
0 b,c 2 b,c a b a a,c 1
该DFA从初态到终态有三条路径:0b2,0c2,0a1b2 用正规式表示为: b | c | a(a|c)*b, 而且是这三条路径均至少重复一次, 故最终的正规式为:(b|c|a(a|c)*b)+
© 西安电子科技大学 · 软件学院 13
其它
习题2.9 构造 10*1 的最小DFA 解: 活用 Thompson 算法 (1) 分解为三部分:1,0*,1; (2) 画出三者的状态转换图:
0 1 0 1 2 3 1 4
(3) 连接运算:子图首尾相连
0
1
0 1 1
1
4
这已经是最小的DFA
© 西安电子科技大学 · 软件学院
© 西安电子科技大学 · 软件学院
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化:
说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法: 自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
E.post=35+8+ E.post=35++ E.post=3 + 3 E.post=8
E .post=5 8 5
产生式 语法制导定义 L→E print(E.post); E→E1+E2 E.post:=E1.post ||E2.post||'+'; E→num E.post:=num.lexval;
输入记号流 ip
top
top
top
3 分 E ? 析 + 栈 5 E 8 E
驱动器 移进-归约 分析表
输出
11
例4.3 3+5*8的语法制导翻译。 4.1.4 LR分析翻译方案的设计(续1) 产生式 翻译方案 语法制导定义 L→E print(val[top]); print(E.val) E→E1+E2 val[top]:=val[top]+val[top+2]; E.val:=E1.val+E2.val; E→E1*E2 val[top]:=val[top]*val[top+2]; E.val:=E1.val*E2.val; E→n val[top]:=lexval; E.val:=n.lexval; 分析栈 语义栈 输入 语义动作 # # 3+5*8# shift #n #3 +5*8# E→n,val[top]:=lexval #E #3 +5*8# shift #E+ #3? 5*8# shift #E+n #3?5 *8# E→n,val[top]:=lexval #E+E #3?5 *8# shift #E+E* #3?5? 8# shift #E+E*n #3?5?8 # E→n,val[top]:=lexval #E+E*E #3?5?8 # E→E1*E2; val[top]:=val[top]*val[top+2]; #E+E #3?40 # E→E1+E2,val[top]:=val[top]+val[top+2]; #E #43 # acc 12
翻译方案 print(+); print(lexval);
9
4.1.3 语义规则的两种形式(续3) <4> 注释分析树上看继承属性与综合属性 继承属性是自上而下计算的 综合属性是自下而上计算的 提醒:除非特别提醒,本章讨论的语法制导翻译是综合属性。
10
4.1.4 LR分析翻译方案的设计
LR分析中的语法制导翻译实质上是对LR语法分析的扩充: <1> 扩充LR分析器的功能:当执行归约产生式的动作时,也执行产 生式对应的语义动作。由于是归约时执行语义动作,因此限制语义 动作仅能放在产生式右部的最右边; <2> 扩充分析栈:增加一个与分析栈并列的语义栈,用于存放分析 栈中文法符号所对应的属性值。 例如: E→E1+E2 val[top]:=val[top]+val[top+2]; 对于表达式: 5+3 当归约为左部E时, 同时也得到了值8。
1
4.1 语法制导翻译简介
4.1.1 语法与语义
<1> 语法与语义的关系 语法是指语言的结构、即语言的“样子”;语义是指附着于语 言结构上的实际含意 ,即语言的“意义”。 对于语法和语义: • 语义不能离开语法独立存在; • 语义远比语法复杂; • 同一语言结构可以包含多种含意,不同语言结构表示相同含意; • 语法与语义之间没有明确的界线。 例1:猫吃老鼠与老鼠吃猫 例2:程序设计语言中的分情况结构: 1.case condition is 2.switch (condition) { case1: stat1; case condition1:stat1; break; case2: stat2; case condition2:stat2; break; ... ... end case; } 2
-- 操作数进栈 -- 算符,弹出操作数 -- 计算,并将结果进栈
16
<4> 将后缀式推广到其他语句
4.2.1 后缀式(续2)
后缀式并不局限于二元运算的表达式,可以推广到任何语句, 只要遵守操作数在前,操作符紧跟其后的原则即可。 语句: if e then x else y 它的后缀式可以写为: e x y if-then-else (1) 上述表示中,e、x和y均需计算。 而实际上,根据条件e的取值,x和y不能都计算: e p1 jez x p2 jump p1: y p2: (2) 其中: p1和p2分别是标号; p1 jez表示e的结果为0(假)则转向p1; p2 jump表示无条件转向p2。 与 (1)比较,(2)中的if-then-else被分解,首先计算e,根据e的 结果是否为真,决定计算x还是计算y。
4.1.1 语法与语义(续1) <2> 语义分析的两个作用 检查是否结构正确的句子所表示的意思也合法; 执行规定的语义动作,如: 表达式求值 符号表填写 中间代码生成等 <3> 语义分析的方法 语法制导翻译
(2004年3月31日在此结束) 3
4.1.2 属性与语义规则
<1> 语法制导翻译的基本思想 通俗地讲: 以语法分析为基础,伴随语法分析的各个步骤,执行相应 的语义动作。 具体方法: 1.将文法符号所代表的语言结构的意思,用附着于该文法 符号的属性表示; 2.用语义规则规定产生式所代表的语言结构之间的关系( 即属性之间的关系),即用语义规则实现属性计算。 语义规则的执行: 在语法分析的适当时刻(如推导或归约)执行附着在对应 产生式上的语义规则,以实现 对语言结构语义的处理,如计算 、查填符号表、生成中间代码、发布出错信息等。
5
E→E1+E2 E.val:=E1.val+E2.val 4.1.2 属性与语义规则(续2) <3> 属性的定义** E→E1+E2 print(E.val) 定义4.1 对于产生式A→α,其中α是由文法符号X1X2...Xn组成的 序列,它的语义规则可以表示为(4.1)所示关于属性的函数: b := f(c1, c2, ..., ck) (4.1) 语义规则中的属性存在下述性质与关系。 (1) 若b是A的属性,c1, c2, ..., ck是α中文法符号的属性, 或者A的其它属性,则称b是A的综合属性。 (2) 若b是α中某文法符号Xi的属性,c1, c2, ..., ck是A的属 性,或者是α中其它文法符号的属性,则称b是Xi的继承属性。 (3) 称(4.1)中属性b依赖于属性c1, c2, ..., ck。 (4) 若语义规则的形式如下述(4.2),则可将其想像为产生式左部 文法符号A的一个虚拟属性。属性之间的依赖关系,在虚拟属性上 依然存在。 f(c1, c2, ..., ck) (4.2) ■ (4.1)中属性之间的依赖关系,实质上反映了属性计算的先后次 序,即所有属性ci被计算之后才能计算属性b。
6
4.1.3 语义规则的两种形式
<1> 语法制导定义 用抽象的属性和运算符号表示的语义规则;(公式,做什么) <2> 翻译方案 用具体属性和运算表示的语义规则。(程序段,如何做) • 语义规则也被习惯上称为语义动作。 • 忽略实现细节,二者作用等价。(设计与实现)
7
4.1.3 语义规则的两种形式(续1) 例4.1 将中缀形式的算术表达式转换为后缀表示的语法制导定义和 翻译方案。虚拟属性print(E.post)可想象为L.p:=print(E.post)。 产生式 语法制导定义 翻译方案1 L→E print(E.post) print_post(post); E→E1+E2 E.post:=E1.post post(k):='+'; k:=k+1; ||E2.post||'+'; E→num E.post:=num.lexval; post(k):=lexval; k:=k+1; L 产生式 翻译方案2 语法制导定义-算法 L→E 翻译方案-程序实现,多种方法 E→E1+E2 print(+);E 翻译方案中需要考虑的问题: E→num print(lexval); E + E 1.采用什么样的语法分析方法; 2.为属性分配存储空间; E + E 8 3.考虑计算次序。 翻译方案1,自下而上计算,LR分析。 3 5 (以3+5+8为例,归约时翻译) post:(3 5 + 8 +)
4
4.1.2 属性与语义规则(续1) <2> 属性的抽象表示 .attr 例如:E.val(值) E.type(类型) E.code(代码序列) E.place(存储空间) <3> 对文法的约定 本章关注的是语法分析的基础上的语义处理,忽略语法 分析。 为了简单,本章的文法一般为二义文法。默认解决二义 的方法是规定常规意义下的优先级和结合性。
<3> 后缀式计算 4.2.1 后缀式(续1) 算术表达式3+5+8的后缀式为35+8+。 算法4.1的计算: (# 35+8+# 进栈) (#3 5+8+# 进栈) (#35 +8+# 弹出3和5,计算3+5,结果进栈) (#8 8+# 进栈) (#88 +# 弹出8和8,计算8+8,结果进栈) (#16 # ) x := first_token; while not end_of_exp loop if x in operators then push x; else pop(operators); push(evaluate); end if; next(x); end loop;
8
4.1.3 语义规则的两种形式(续2) <3> 属性作为分析树的注释 将属性附着在分析树对应文法符号上,形成注释分析树。 例4.2 3+5+8的分析树和注释分析树: L