oracle 11G 新特性
oracle11g新特性(精)

Oracle 11g 新特性Oracle 11g现在已经开始进行beta测试,预计在2007年底要正式推出。
和她以前其他产品一样,新一代的oracle又将增加很多激动人心的新特性。
下面介绍一些11g 的新特性。
1.数据库管理部分•数据库重演(Database Replay)这一特性可以捕捉整个数据的负载,并且传递到一个从备份或者standby数据库中创建的测试数据库上,然后重演负责以测试系统调优后的效果。
•SQL重演(SQL Replay)和前一特性类似。
但是只是捕捉SQL负载部分,而不是全部负载。
•计划管理(Plan Management)这一特性允许你将某一特定语句的查询计划固定下来,无论统计数据变化还是数据库版本变化都不会改变她的查询计划。
•自动诊断知识库(Automatic Diagnostic Repository ADR)当Oracle探测到重要错误时,会自动创纪一个事件(incident),并且捕捉到和这一事件相关的信息,同时自动进行数据库健康检查并通知DBA。
此外,这些信息还可以打包发送给Oracle支持团队。
•事件打包服务(Incident Packaging Service)如果你需要进一步测试或者保留相关信息,这一特性可以将与某一事件相关的信息打包。
并且你还可以将打包信息发给oracle支持团队。
•基于特性打补丁(Feature Based Patching)在打补丁包时,这一特性可以使你很容易区分出补丁包中的那些特性是你正在使用而必须打的。
企业管理器(EM)使你能订阅一个基于特性的补丁服务,因此企业管理器可以自动扫描那些你正在使用的特性有补丁可以打。
•自动SQL优化(Auto SQL Tuning)10g的自动优化建议器可以将优化建议写在SQL profile中。
而在11g中,你可以让oracle自动将能3倍于原有性能的profile应用到SQL语句上。
性能比较由维护窗口中一个新管理任务来完成。
【2019年整理】Oracle11gR2数据库新特性

Oracle 11g 新特性
• • • • • • • 自动内存管理 ADDM for RAC 数据卫士( Dataguard )技术革新 闪回技术
• 闪回存档
RAC和ASM
• •
• •
RAC One Node ASM
Database Vault Audit Vault
primary / standby 均支持RAC 查询结果在transaction级别一致
对广大physical standby用户立 即可以带来好处 DR + 实时查询—业界独一无二 的技术–无闲置资源 支持所有的数据类型,但缺乏 logical standby的灵活性 支持多达30个Active Standby数 据库(11gR2)
RAC数据库的ADDM
确定集群性能问题 定位问题
• • • • • 全局资源,如 IO和锁 高负载SQL和热数据块 内存内部争用 网络延时 实例间相应时间偏差
在EM中运行ADDM
数据卫士(Data Guard)技术革新
Active Data Guard
physical standby在redo apply同 时,支持只读查询
自动内存管理
Oracle11g数据库已经实现了自动内 存管理,一定程度上简化了数据 库管理员对于内存管理的工作。 自动内存管理是通过两个初始化参 数进行配置的: MEMORY_MAX_TARGET MEMORY_TARGET
• 动态的参数 • 根据负载自动进行调整 • 多平台支持
Linux Windows Solaris HPUX AIX
压缩对系统响应时间和吞吐 量的影响可以忽略不计 需要Oracle 11g高级压缩选件
Oracle数据库11g新特性:安全性

Oracle数据库11g新特性:安全性默认口令2006 年,OTN 发布了我撰写的一系列题为“安全保护项目:一种分阶段的数据库基础架构保护方法”的文章。
在这些文章中,我讨论了如何应对常见的安全挑战(如用户使用默认口令)以及如何扫描您的数据库以查找这些用户。
对我而言很不幸的是,您可能已经忘记了我文章中的那一部分。
Oracle 数据库11g 现在提供一种快速识别使用默认口令的用户的方法。
该方法实施起来极为简单,只需检查单个数据字典视图:D BA_USERS_WITH_DEFPWD.(注意,DBA_ 是一个标准前缀,它不仅包含使用默认口令的DBA 用户。
)您可以执行以下命令来识别这些用户:输出如下:由于SCOTT 使用了默认口令TIGER,因此您会看到他出现在上面的清单中。
使用下面的语句进行更改:现在,如果您查看该视图:您就不会在该清单中看到SCOTT 了。
就这么简单!区分大小写的口令在版本11g 之前的Oracle 数据库中,用户口令是不区分大小写的。
例如:这种安排为支付卡行业(PCI)数据安全标准之类的标准带来了问题,这些标准要求口令区分大小写。
该问题得到了解决,在Oracle 数据库11g 中,口令也可以区分大小写。
通过DBCA 创建数据库时,系统会提示您是否希望升级到“新的安全标准”,其中之一就是区分大小写的口令。
如果您接受该标准,口令在创建时的大小写状态将被记录下来。
假如您接受了新标准,相应的操作结果如下:注意对“tiger”和“TIGER”的不同处理方式。
现在,您的某些应用程序可能无法立刻传递大小写正确的口令。
典型示例是用户输入表单:很多表单在接受口令时不会进行大小写转换。
然而,在Oracle 数据库11g中,这种登录方式可能会失败,除非用户以区分大小写格式输入口令,或者开发人员对应用程序进行了修改,使其能够进行大小写转换(这一点不可能迅速实现)。
不过,如果您希望的话,仍然可以通过更改系统参数SEC_CASE_SENSITIVE_LOGON 恢复到不区分大小写的状态,如以下示例所示。
Oracle 11g 新特性ADR

Oracle 11g 新特性 ADRADR 主目录既然所有的焦点都集中于数据库的诊断能力, 那么 Oracle 数据库是不是应该存储以结 构化方式组织的所有跟踪文件、日志文件等等?在 Oracle 数据库 11g 中确实如此。
自动 诊断信息库 (ADR) 文件位于一个指定为诊断目标(或 ADR 基目录)的常用目录下的目录 中。
该目录由初始化参数 (diagnostic_dest) 设置。
默认情况下, 它设置为 $ORACLE_BASE, 但是您可以将其显式设置为某些独占目录。
(但是不建议这样做。
) 该目录下有一个 diag 子 目录,您将在这个子目录中发现存储诊断文件的子目录。
ADR 存储所有组件(ASM、CRS、监听器等)的日志和跟踪文件,包括数据库本身的 日志和跟踪文件。
这使您可以方便地在一个位置查找特定的日志。
在 ADR 基目录中,可以有多个 ADR 主目录,每个组件和实例一个。
例如,如果服 务器有两个 Oracle 实例,则有两个 ADR 主目录。
下面是数据库实例的 ADR 主目录的 目录结构。
目录名称 <在 DIAGNOSTIC_DEST 参数中提到的目录> →diag →rdbms →<数据库名称> →<实例名称> →alert →cdump →hm →incident →<所有事件目录存在这里> →incpkg说明XML 格式的警报日志存储在这里。
核心转储存储在这里, 相当于早期版本中的 core_dump_dest。
运行情况监视对多个组件运行检查,它在这里存储某些文件。
所有事件转储都存储在这里。
每个事件存储在一个不同的目录中,这些目录都存储在这里。
当您打包事件时(在本文中可以了解打包),某些支持文件存储在这里。
→metadata →trace 有关问题、事件、程序包等的元数据存储在这里。
用户跟踪文件和背景跟踪文件存储在这里,并附带警报日志的 文本版本。
ORACLE-技术文档-ORACLE11G新特性-SPA使用指南-V121120

ORACLE-技术文档-ORACLE11G新特性-SPA使用指南-V121120ORACLE-技术文档-11G新特性-SPA使用指南-(v120726)版本说明目录版本说明 (2)1. 概述 (4)2. SPA 过程 (4)2.1. 简述 (4)2.2. 工作流程 (4)2.3.捕捉有代表性的SQL工作负载 (5)2.3.1. 创建SQL调整集(STS) (5)2.3.2. 生产库加载SQL调整集 (5)2.3.3. 传送SQL调整集 (6)2.3.4. 将STS导入测试系统 (7)2.4. 创建SPA任务 (8)2.4.1. 在测试库创建一个SPA任务 (8)2.5. 分析更改前SQL工作负载 (8)2.6. 分析升级后的sql工作负载 (9)2.7. 比较SQL性能 (9)2.7.1. 为了比较升级前和升级后SQL性能,需要第三次执行EXECUTE_ANALYSIS_TASK过程. (9)2.7.2. 生成SPA报表 (10)2.7.3. 分析性能报表 (12)3. 参考文档 (12)1.概述ORACLE11G 的新特性SPA,可对给定SQL结果集进行性能分析,特别适合在有大的动作(比如升级\迁移等)做前后的性能比较。
分析结果以永久对象存在数据库内部,可供以后查询和修改。
2.SPA 过程2.1.简述SQL工作负载不仅包括SQL语句,还包括环境信息(绑定变量和执行频率)。
2.2.工作流程2.3.捕捉有代表性的SQL工作负载2.3.1.创建SQL调整集(STS)SQL> exec dbms_sqltune.create_sqlset(sqlset_name=>'sql_test',description =>'11g spa test'); PL/SQL procedure successfully completed.2.3.2.生产库加载SQL调整集2.3.2.1. 从当前的缓存加载SQL语句作为调整集.SQL> DECLARE2 mycur DBMS_SQLTUNE.SQLSET_CURSOR;3 BEGIN4 OPEN mycur FOR5 SELECT VALUE(P)6 FROM table(7 DBMS_SQLTUNE.SELECT_CURSOR_CACHE(8 'parsing_schema_name <> ''SYS'' AND elapsed_time > 500000',9 NULL, NULL, NULL, NULL, 1, NULL,10 'ALL')) P;1112 DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name => 'sql_test',13 populate_cursor => mycur);1415 END;/ 16PL/SQL procedure successfully completed.2.3.2.2. 从AWR报告提取SQL语句作为调整集SQL> EXEC DBMS_SQLTUNE.CREATE_SQLSET('my_workload');SQL>SQL>SQL>SQL> DECLARE2 cur DBMS_SQLTUNE.SQLSET_CURSOR;3 BEGIN4 OPEN cur FOR5 SELECT VALUE(P)6 FROM table(7 DBMS_SQLTUNE.SELECT_WORKLOAD_REPOSITORY(24,27,8 'parsing_schema_name <> ''SYS''',9 NULL, NULL,NULL,NULL,10 1,11 NULL,12 'ALL')) P;1314 DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name =>'my_workload',15 populate_cursor => cur,16 load_option => 'MERGE',17 update_option => 'ACCUMULATE');18 END;19 /2.3.3.传送SQL调整集在能进行传送之前,需要在生产库创建一个中转表作为下个环节的导出源.2.3.3.1. 创建中转表SQL> EXEC DBMS_SQLTUNE.CREATE_STGTAB_SQLSET(table_name=>'STGTAB_SQLSET');此表不能创建在SYS模式下.2.3.3.2. 将SQL调整结果集导入到中转表EXECDBMS_SQLTUNE.PACK_STGTAB_SQLSET(sqlset_name=>'sql_test' ,staging_table_name=>'STGTAB_SQLSET');从中转表选择数据,验证是否有数据SQL> select count(*) from STGTAB_SQLSET;72说明已经存在数据了.2.3.4.将STS导入测试系统2.3.4.1. 先使用数据泵将中转表数据导出和导入[oracle@ora11g ~]$ expdp system DUMPFILE=STGTAB_SQLSET.dmp DIRECTORY=REPLAY_DIR TABLES=STGTAB_SQLSETExport: Release 11.2.0.1.0 - Production on Tue Jul 24 00:45:382012Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.Password:UDE-28002: operation generated ORACLE error 28002ORA-28002: the password will expire within 7 daysConnected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - ProductionWith the Partitioning, OLAP, Data Mining and Real Application Testing optionsStarting "SYSTEM"."SYS_EXPORT_TABLE_01": system/******** DUMPFILE=STGTAB_SQLSET.dmp DIRECTORY=REPLAY_DIR TABLES=STGTAB_SQLSETEstimate in progress using BLOCKS method...Processing object type TABLE_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 576 KBProcessing object type TABLE_EXPORT/TABLE/TABLEProcessing object type TABLE_EXPORT/TABLE/PRE_TABLE_ACTION. . exported "SYSTEM"."STGTAB_SQLSET" 100.7 KB 72 rows Master table "SYSTEM"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded*************************************************************** ***************Dump file set for SYSTEM.SYS_EXPORT_TABLE_01 is:/home/oracle/replay_dir/STGTAB_SQLSET.dmpJob "SYSTEM"."SYS_EXPORT_TABLE_01" successfully completed at 00:47:362.3.4.2. 将此表导入到测试系统的system用户下[oracle@11g replay_dir]$ impdp systemDUMPFILE=STGTAB_SQLSET.dmp DIRECTORY=REPLAY_DIR Import: Release 11.2.0.1.0 - Production on Tue Jul 24 01:20:51 2012Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.Password:UDI-28002: operation generated ORACLE error 28002ORA-28002: the password will expire within 7 daysConnected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - ProductionWith the Partitioning, OLAP, Data Mining and Real Application Testing optionsMaster table "SYSTEM"."SYS_IMPORT_FULL_01" successfully loaded/unloadedStarting "SYSTEM"."SYS_IMPORT_FULL_01": system/******** DUMPFILE=STGTAB_SQLSET.dmp DIRECTORY=REPLAY_DIR Processing object type TABLE_EXPORT/TABLE/TABLEProcessing object type TABLE_EXPORT/TABLE/PRE_TABLE_ACTIONProcessing object type TABLE_EXPORT/TABLE/TABLE_DATA . . imported "SYSTEM"."STGTAB_SQLSET" 100.7 KB 72 rows Job "SYSTEM"."SYS_IMPORT_FULL_01" successfully completed at 01:23:202.3.4.3. 在测试库解压中转表的数据到STSSQL> EXEC DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET(sqlset_name=>'sql_t est',replace=>true ,staging_table_name=>'STGTAB_ SQLSET');PL/SQL procedure successfully completed.2.4.创建SPA任务2.4.1.在测试库创建一个SPA任务SQL> variable sts_task VARCHAR2(64);SQL>exec :sts_task:=DBMS_SQLPA.CREATE_ANALYSIS_TASK(sqlset_na me=>'sql_test',task_name=>'spa_task1');/PL/SQL procedure successfully completed2.5.分析更改前SQL工作负载现实环境中,通常源库和测试库的版本至少差一个版本,比如源库可能是10.2版本,而测试库版本是11G,如果源库的版本是10G,需要在测试库将参数:optimizer_features_enable 设置为10.2.0,将此参数设置为此10.2.0后,生成的性能数据就是升级前的数据了.本案例由于是为了演示整个SPA的过程,源库和测试库的版本都是11G的,所以上述参数环节就不用设置了.直接进行性能抓取即可.SQL>execDBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name=>'spa_task 1',execution_type=>'testexecute',execution_name=>'before_change');PL/SQL procedure successfully completed.一定注意黄色部分,test 和execute 之前不是下划线,而是空格.2.6.分析升级后的sql工作负载如果是由于版本升级做的SPA,在此处需要将optimizer_features_enable 设置为11.2.0,本次案例由于不是这个目的,所以此参数不用处理.SQL>execDBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name=>'spa_task 1',execution_type=>'testexecute',execution_name=>'after_change');PL/SQL procedure successfully completed.2.7.比较SQL性能2.7.1.为了比较升级前和升级后SQL性能,需要第三次执行EXECUTE_ANALYSIS_TASK过程.SQL> exec DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(task_name=>'spa_task 1',execution_type=>'compare performance');PL/SQL procedure successfully completed.2.7.2.生成SPA报表SQL> variable report1 clob;SQL>exec :report1 := DBMS_SQLPA.REPORT_ANALYSIS_TASK(task_name=>'spa_task1' ,type=>'text',level=>'typical',section=>'summary');PL/SQL procedure successfully completed.SQL> SQL> set long 100000 longchunksize 100000 linesize 120SQL> print :report1REPORT1------------------------------------------------------------------------------------------------------------------------General Information---------------------------------------------------------------------------------------------Task Information: Workload Information:--------------------------------------------- ---------------------------------------------Task Name : spa_task1 SQL Tuning Set Name : sql_testTask Owner : SYSTEM SQL Tuning Set Owner : SYSTEMDescription : Total SQL Statement Count : 10Execution Information:---------------------------------------------------------------------------------------------REPORT1------------------------------------------------------------------------------------------------------------------------Execution Name : EXEC_89 Started : 07/24/2012 02:56:05 Execution Type : COMPARE PERFORMANCE Last Updated : 07/24/2012 02:56:06 Description : Global Time Limit : UNLIMITED Scope : COMPREHENSIVE Per-SQL Time Limit : UNUSEDStatus : COMPLETED Number of Errors : 2Number of Unsupported SQL : 3Analysis Information:---------------------------------------------------------------------------------------------Before Change Execution: After Change Execution:--------------------------------------------- ---------------------------------------------REPORT1------------------------------------------------------------------------------------------------------------------------ Execution Name : before_change Execution Name : after_change Execution Type : TEST EXECUTE Execution Type : TEST EXECUTEScope : COMPREHENSIVE Scope : COMPREHENSIVE Status : COMPLETED Status : COMPLETED Started : 07/24/2012 02:24:25 Started : 07/24/2012 02:33:36 Last Updated : 07/24/2012 02:25:04 Last Updated : 07/24/2012 02:33:38 Global Time Limit : UNLIMITED Global Time Limit : UNLIMITEDPer-SQL Time Limit : UNUSED Per-SQL Time Limit : UNUSED Number of Errors : 2 Number of Errors : 2---------------------------------------------REPORT1------------------------------------------------------------------------------------------------------------------------ Comparison Metric: ELAPSED_TIME------------------Workload Impact Threshold: 1%--------------------------SQL Impact Threshold: 1%----------------------Report Summary---------------------------------------------------------------------------------------------Projected Workload Change Impact:REPORT1-------------------------------------------------------------------------------------------------------------------------------------------------------------------Overall Impact : 6.44%Improvement Impact : 6.44%Regression Impact : 0%SQL Statement Count-------------------------------------------SQL Category SQL Count Plan Change CountOverall 10 0Improved 2 0Unchanged 3 0REPORT1------------------------------------------------------------------------------------------------------------------------with Errors 2 0Unsupported 3 0Top 5 SQL Sorted by Absolute Value of Change Impact on the Workload--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| | | Impact on | Execution | Metric | Metric | Impact | Plan || object_id | sql_id | Workload | Frequency | Before | After | on SQL | Change |-----------------------------------------------------------------------------------------| 28 | a4vxhbv8nxt57 | 4.25% | 1 | 55276 | 49395 | 10.64% | n | | 31 | c99yw1xkb4f1u | 2.19% | 1 | 19309 | 16283 | 15.67% | n | REPORT1------------------------------------------------------------------------------------------------------------------------| 29 | a50nw0ap6kv2c | .85% | 1 | 60288 | 59112 | 1.95% | n | | 26 | 767pug2dbpqpc | .05% | 3 | 1075 | 1052 | 2.14% | n | | 24 | 02suhrf4z78n3 | .03% | 2 | 145 | 127 | 12.41% | n | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------2.7.3.分析性能报表如上报表的黄色部分为报表的主要部分,报表最后给出了分析汇总.3.参考文档ORACLE 的官方文档Oracle? Database PL/SQL Packages and Types Reference11g Release 2 (11.2)Part Number E16760-05和Oracle? Database Real Application Testing User's Guide11g Release 2 (11.2)Part Number E16540-03。
Oracle 11g 分区新特性

前不久,曾经接手一个性能调优案例:这是一个报表系统,其基础数据主要存储于三张表中。
表的大小已经很大了,最大一张接近100G。
在生成报表时需要长时间才能返回结果,一些online查询甚至经常timeout。
表中存储的是2万多个公司的数据,报表的生成也是以公司为单位的,因此,这一调优方案的思路比较明确:将表按公司分区。
但是,这中间却存在一些麻烦:每个公司的数据并不是均衡的。
其中近200家公司属于VIP用户,他们的数据量最大,每个公司差不多是十几万到几十万的数据量,其总量占了全部数据的30%左右;而其它非VIP用户的数据基本上每个都在1万以内。
而我们的主要目标就是要优先保证VIP用户获取到最佳的性能(由于其数据量,当前最大的性能问题恰恰就出在这些VIP用户上)。
因此,我们提出了2中分区方案:基于Company Id的Hash分区;基于Company Id的List分区;但是,这两种方案各有优缺点:对于Hash分区,分区的大小更加均衡,因而性能也更加均衡。
但是,可能出现一些无法控制的极端现象:Hash分区仅仅是对Company Id使用Hash函数进行分组,它能做到每个分区分配基本相当数量的Company Id,但是每个Company Id对应的数据量并不考虑在内,因此可能出现某些分区集中的都是VIP数据或者都是非VIP数据,造成分区过大或过小;另外一个缺点就是我们很难直接干预某个公司的性能。
例如,可能有某个非VIP用户成为了VIP用户,其数据量激增,它又正好处于一个大的分区上,这时,我们很难将其从这个分区剥离出来,除非它所在分区正好出在一个即将分裂的分区上。
对于List分区,VIP用户的性能能够得到保证。
我们可以将每个VIP用户单独存储在一个分区上,但是,不可能将非VIP用户单独存储开(不仅增加维护难度,且增加整个表的大小),只能将非VIP用户存储在几个分区上。
但是这样还是造成DDL语句非常复杂,并且非VIP的分区很大(每个都在10G左右,而VIP分区最大才200M)。
Oracle 数据库11g新特性概述

Oracle 数据库 11g 新特性概述
Martin.yang@
Oracle数据库进化史
Oracle exadata
Oracle 数据库 11g
数据库一体机
数据屏蔽
TDE 表空间加密 Oracle Audit Vault Oracle Database Vault 透明数据加密 (TDE)
• 表压缩技术
• 象在数据仓库应用中一样, 现在可以用在OLTP应用中
• 查询结果集缓存
• 查询或函数结果集的高速缓存, 可用于大量读操作的数据
• 新一代RAC Cache Fusion技术
• 更高的伸缩性
Oracle SecureFiles
Consolidated Secure Management of Data 许多应用同时使用文件和关系型数据 • 例: 文档管理系统, 医药, CAD, 图象管理
• • •
DataGuard创新
• DataGuard增强
• 支持只读物理备份 • APPLY性能提高
• 支持XML类型
• 支持透明数据加密
• 备份数据库快照
• 除作为HA和DR外, 充分利用备份数据库 资源 • 测试! • 保证无数据丢失
DataGuard从根本上改变了冗余架构的价值
Flashback创新
Oracle 数据库 10g
实时列屏蔽(VPD) 安全配置扫描
客户端身份传播 细粒度审计 Oracle 数据库 9i Oracle Label Security 代理身份验证 企业用户安全性 Oracle 8i 虚拟专用数据库 (VPD)
数据库加密 API 强身份验证 自带网络加密 Oracle 7 数据库审计 政府客户
Oracle 11G新特性--ASM 增强 说明
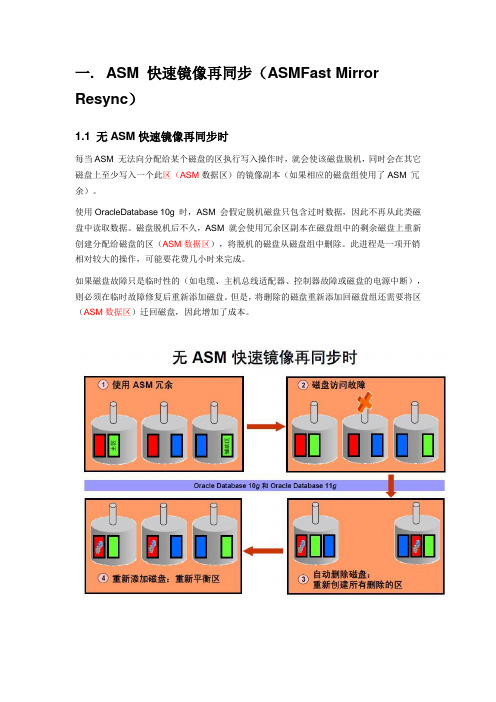
一. ASM 快速镜像再同步(ASMFast Mirror Resync)1.1 无ASM快速镜像再同步时每当ASM 无法向分配给某个磁盘的区执行写入操作时,就会使该磁盘脱机,同时会在其它磁盘上至少写入一个此区(ASM 数据区)的镜像副本(如果相应的磁盘组使用了ASM 冗余)。
使用OracleDatabase 10g 时,ASM 会假定脱机磁盘只包含过时数据,因此不再从此类磁盘中读取数据。
磁盘脱机后不久,ASM 就会使用冗余区副本在磁盘组中的剩余磁盘上重新创建分配给磁盘的区(ASM 数据区),将脱机的磁盘从磁盘组中删除。
此进程是一项开销相对较大的操作,可能要花费几小时来完成。
如果磁盘故障只是临时性的(如电缆、主机总线适配器、控制器故障或磁盘的电源中断),则必须在临时故障修复后重新添加磁盘。
但是,将删除的磁盘重新添加回磁盘组还需要将区(ASM 数据区)迁回磁盘,因此增加了成本。
1.2 ASM 快速镜像再同步1.2.1 概述ASM 快速镜像再同步会显著减少重新同步临时故障磁盘所需的时间。
如果某个磁盘因临时故障而脱机,ASM 将跟踪在中断期间发生修改的区。
临时故障被修复后,ASM 可以快速地仅重新同步在中断期间受到影响的ASM 磁盘区。
此功能假定受到影响的ASM磁盘内容未发生损坏或修改。
某个ASM 磁盘路径出现故障时,如果您已设置了相应磁盘组的DISK_REPAIR_TIME 属性,则ASM 磁盘会脱机,但不会被删除。
此属性的设置确定了ASM 可容忍的磁盘中断持续时间;如果中断在此时间范围内,则修复完成后仍可重新同步。
注:跟踪机制对每个已修改的区使用一个位,这样可确保跟踪机制非常高效。
1.2.2 设置ASM 快速镜像再同步请按磁盘组设置此功能。
可以在创建磁盘组后使用ALTER DISKGROUP 命令完成此操作。
使用一个类似以下命令的命令启用ASM 快速镜像再同步:ALTER DISKGROUPSET ATTRIBUTE 'DISK_REPAIR_TIME'='2D4H30M'在修复了磁盘后,运行SQL 语句ALTER DISKGROUP ONLINE DISK。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
官网的说明链接如下:/cd/E11882_01/server.112/e22487/toc.htm一. 11.2.0.1新特性This chapter containsdescriptions of all of the features that are new to Oracle11g Database,Release 2. This chapter contains the following sections:(1) ApplicationDevelopment(2) Availability(3) BusinessIntelligence and Data W arehousing(4) Clustering(5) DatabaseOverall(6) Diagnosability(7) Performance(8) Security(9) ServerManageability(10) UnstructuredData Management1.1 Application DevelopmentThe followingsections describe the new application development features for Oracle Database11g Release 2 (11.2).1.1.1 OracleApplication ExpressThe following sections describe OracleApplication Express features.(1)ApplicationDate Format(2)Custom Themes(3)Declarative BLOB Support(4)DocumentedJavaScript Libraries(5) EnhancedReport Printing(6) FormsConversion(7)ImprovedSecurity(8) InteractiveReporting Region(9) Runtime-OnlyInstallation1.1.2 OtherGeneral Development FeaturesThe followingsections describe new features in the areas of OCI, Pro*C, JDBC, and otherdevelopment APIs.(1)Support W ITHHOLD Option for CURSOR DECLARATION in Pro*C(2)Pro*C Supportfor 8-Byte Native Numeric Host Variable for INSERT and FETC H(3) Pro*COBOLSupport for 8-Byte Native Numeric Host Variable for INSERT and FETCH(4) JDBCSupport for Time Zone Patching(5) JDBCSupport for SecureFile Zero-Copy LOB I/O and LOB Prefetching(6) OCISupport for 8-Byte Integer Bind/Define1.2 AvailabilityThe focus ofthis Availability section is aimed towards providing capabilities that keep theOracle database available for continuous data access, despite unplannedfailures and scheduled maintenance activities. These various capabilities formthe basis of Or acle Maximum Availability Architecture (MAA), which is theOracle blueprint for implementing a highly available infrastructure usingintegrated Oracle technologies.1.2.1 Backupand RecoveryThe followingsections describe new features in this release that provide improvements in thearea of backup and recovery.(1) AutomaticBlock RepairAutomatic blockrepair allows corrupt blocks on the primary database or physical standbydatabase to be automatically repaired, as s oon as they are detected, bytransferring good blocks from the other destination. In addition, RECOVERBLOCK is enhanced to restore blocks from a physical standby database. Thephysical standby database must be in real-time query mode.--当在主库或者物理standby库上检测到坏块时,会自动对这些坏块进行修复。
This featurereduces time when production data cannot be accessed, due to block corruption,by automatically repairing the corruptions as soon as they are detected inreal-time using good blocks from a physical standby database. This reducesb lock recovery time by using up-to-date good blocks from a real-time,synchronized physical standby database as opposed to disk or tape backups orflashback logs.(2) Backupto Amazon Simple Storage Service (S3) Using OSB Cloud ComputingOracle nowoffers backup to Amazon S3, an internet-based storage service, with the OracleSecure Backup (OSB) Cloud Module. This is part of the Oracle Cloud Computingoffering.This featureprovides easy-to-manage, low cost database backup to W eb services storage,reducing or eliminating the cost and time to manage an in-house backupinfrastructure.--使用OSB 可以将DB 备份到amazon S3 存储上。
(3) DUPLICATEW ithout Connection to Target DatabaseDUPLICATE canbe performed without connecting to a target database. This requires connectingto a catalog and auxiliary database.The benefit isimproved availability of a DUPLICATE operation by not requiringconnection to a target database. This is particularly usefulfor DUPLICATE to a destination database where connection to thetarget database may not b e available at all times.--duplicate 可以在连接到catalog 和 auxiliary 库上进行工作,而不需要在连到target db上。
(4) EnhancedTablespace Point-In-Time Recovery (TSPITR)Tablespace point-in-time recovery (TSPITR)is enhanced as follows:--TSPITR 得到如下的增强:1) You now have the ability torecover a dropped tablespace.2) TSPITR can be repeated multipletimes for the same tablespace. Previously, once a tablespace had been recoveredto an earlier point-in-time, it could not be recovered to another earlierpoint-in-time.3) DBMS_TTS.TRANSPORT_SET_CHECK isautomatically run to ensure that TSPITR is successful.4) AUXNAME is no longer usedfor recovery set data files.This feature improves usability withTSPITR.(5) NewDUPLICATE OptionsThe following are new options forthe DUPLICATE command:--Duplicate 增加选项:1)NOREDONOREDO indicatesthat archive logs are not applied. Because targetless DUPLICATE does notconnect to the target database, it cannot check if the database isrunningin NOARCHIVELOG mode. It can also be used during regular duplicationto force adatabase currently in ARCHIVELOG mode to be recoveredwithout applying archive logs (for example, because it was in NOARCHIVELOG modeat the point-in-time it is being duplicated).--noredo指定archive logs 不被应用。