华盛顿大学公开课 Introduction to Data Science 039_publication_bias
合集下载
华盛顿大学公开课 Introduction to Data Science 1 - 4 - Dimensions (10-24)

technique, and applying it and running it
is a fairly small fraction.
What you'll be spending much more time on
is the preparation of the data, the
manipulation of the data, the cleaning of
very, very large data sets.
Okay.
However, some of the methods, some of the
models you'll build are, are the same in
both cases.
So database experts, database programmers
new mathematics to squeeze as much
information as you can out of the 20 you
already have.
But that's not always the problem
anymore, right?
So as we shift from a data-poor regime to
business intelligence is that, the BI
engineers are not typically expected to
consume their own data products, and
perform their own analysis, and make, and
is a fairly small fraction.
What you'll be spending much more time on
is the preparation of the data, the
manipulation of the data, the cleaning of
very, very large data sets.
Okay.
However, some of the methods, some of the
models you'll build are, are the same in
both cases.
So database experts, database programmers
new mathematics to squeeze as much
information as you can out of the 20 you
already have.
But that's not always the problem
anymore, right?
So as we shift from a data-poor regime to
business intelligence is that, the BI
engineers are not typically expected to
consume their own data products, and
perform their own analysis, and make, and
华盛顿大学公开课 Introduction to Data Science 1 - 8 - Big Data (14-36)

Okay?
So, the, probably the main thing to
recognize is this notion of the three V's
of Big Data which are volume, velocity,
and variety.
And we talked a little bit about this in
if you sort of make a plot of number of
bytes on the Y-axis versus number of data
sources.
Maybe columns of data in single table or
columns of data across multiple tables or
hemisphere, or whole eastern pacific, or
there could be models, of a particular
bay.
Or inlet or estuary connected to a river
or connected to the open ocean or a much
a large[UNKNOWN] telescope.
but the number of different types of
instruments you can, use to acquire data
is large and ever-growing, right?
So you have these glider systems that
So, the, probably the main thing to
recognize is this notion of the three V's
of Big Data which are volume, velocity,
and variety.
And we talked a little bit about this in
if you sort of make a plot of number of
bytes on the Y-axis versus number of data
sources.
Maybe columns of data in single table or
columns of data across multiple tables or
hemisphere, or whole eastern pacific, or
there could be models, of a particular
bay.
Or inlet or estuary connected to a river
or connected to the open ocean or a much
a large[UNKNOWN] telescope.
but the number of different types of
instruments you can, use to acquire data
is large and ever-growing, right?
So you have these glider systems that
华盛顿大学公开课Introduction to Data Science 003_this_course_1
Bill Howe, UW 2
4/28/13
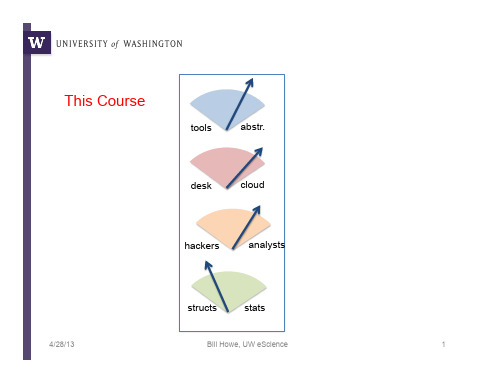
tools
abstr.
What are the abstractions of data science?
“Data Jujitsu” “Data Wrangling” “Data Munging”
Translation: “We have no idea what this is all about”
4/28/13
Bill Howe, UW
4
Data Access Hitting a Wall
Current practice based on data download (FTP/GREP) Will not scale to the datasets of tomorrow
• • • • • You can GREP 1 MB in a second You can GREP 1 GB in a minute You can GREP 1 TB in 2 days You can GREP 1 PB in 3 years. Oh!, and 1PB ~5,000 disks
desk
cloud
• • • •
You can FTP 1 MB in 1 sec You can FTP 1 GB / min (~1$) … 2 days and 1K$ … 3 years and 1M$
• At some point you need indices to limit search parallel data search and analysis • This is where databases can help
abstr.
Pre-2004: commercial RDBMS, some open source 2004 Dean et al. MapReduce 2008 Hadoop 0.17 release 2008 Olston et al. Pig: Relational Algebra on Hadoop 2008 DryadLINQ: Relational Algebra in a Hadoop-like system 2009 Thusoo et al. HIVE: SQL on Hadoop 2009 Hbase: Indexing for Hadoop 2010 Dietrich et al. Schemas and Indexing for Hadoop 2012 Transactions in HBase (plus VoltDB, other NewSQL systems) But also some permanent contributions: – Fault tolerance – Schema-on-Read – User-defined functions that don’t suck
4/28/13
tools
abstr.
What are the abstractions of data science?
“Data Jujitsu” “Data Wrangling” “Data Munging”
Translation: “We have no idea what this is all about”
4/28/13
Bill Howe, UW
4
Data Access Hitting a Wall
Current practice based on data download (FTP/GREP) Will not scale to the datasets of tomorrow
• • • • • You can GREP 1 MB in a second You can GREP 1 GB in a minute You can GREP 1 TB in 2 days You can GREP 1 PB in 3 years. Oh!, and 1PB ~5,000 disks
desk
cloud
• • • •
You can FTP 1 MB in 1 sec You can FTP 1 GB / min (~1$) … 2 days and 1K$ … 3 years and 1M$
• At some point you need indices to limit search parallel data search and analysis • This is where databases can help
abstr.
Pre-2004: commercial RDBMS, some open source 2004 Dean et al. MapReduce 2008 Hadoop 0.17 release 2008 Olston et al. Pig: Relational Algebra on Hadoop 2008 DryadLINQ: Relational Algebra in a Hadoop-like system 2009 Thusoo et al. HIVE: SQL on Hadoop 2009 Hbase: Indexing for Hadoop 2010 Dietrich et al. Schemas and Indexing for Hadoop 2012 Transactions in HBase (plus VoltDB, other NewSQL systems) But also some permanent contributions: – Fault tolerance – Schema-on-Read – User-defined functions that don’t suck
华盛顿大学公开课 Introduction to Data Science 6 - 12 - 12 k Nearest Neighbors (11-43)

derive estimates of important statistics.
Okay.
And we put some of that together and
talked about random forests, which is an
ensemble method for decision trees that
to a pure machine learning, pure
statistical you know background.
the category is quite common, and so
defining nearest neighbor is sometimes
possible, but it's not, it's, it's not
says you work with especially when you're
coming from kind of a, you know maybe
data processing background.
Data science sort of scenario, as opposed
represent another.
You know, maybe survived or not survived
in the Titanic example.
and when you have a new point that you
want to classify,ቤተ መጻሕፍቲ ባይዱjust drop it into the
challenge of decision trees is that they
Okay.
And we put some of that together and
talked about random forests, which is an
ensemble method for decision trees that
to a pure machine learning, pure
statistical you know background.
the category is quite common, and so
defining nearest neighbor is sometimes
possible, but it's not, it's, it's not
says you work with especially when you're
coming from kind of a, you know maybe
data processing background.
Data science sort of scenario, as opposed
represent another.
You know, maybe survived or not survived
in the Titanic example.
and when you have a new point that you
want to classify,ቤተ መጻሕፍቲ ባይዱjust drop it into the
challenge of decision trees is that they
华盛顿大学公开课 Introduction to Data Science 1 - 3 - Context (9-30)

to.
So another perspective on this that you
should be familiar with is this Venn
diagram that made the rounds several
years ago by Drew Conway.
And what he, his point was that Data
This, you know, DJ has an applied math
background so he's maybe coming from that
perspective.
So Mike Driscoll also talks about the
three skills of data geeks which are
dangerous but you don't know how to
ground your analysis in.
Proper theorem.
And you know, some of my colleagues like
to joke, the computer scientists don't
[MUSIC].
Welcome back.
So I want to talk about in this segment
what this term data science actually
means actually means.
So, you know, you'll see these quotes
blend of Red-Bull-fueled hacking and
So another perspective on this that you
should be familiar with is this Venn
diagram that made the rounds several
years ago by Drew Conway.
And what he, his point was that Data
This, you know, DJ has an applied math
background so he's maybe coming from that
perspective.
So Mike Driscoll also talks about the
three skills of data geeks which are
dangerous but you don't know how to
ground your analysis in.
Proper theorem.
And you know, some of my colleagues like
to joke, the computer scientists don't
[MUSIC].
Welcome back.
So I want to talk about in this segment
what this term data science actually
means actually means.
So, you know, you'll see these quotes
blend of Red-Bull-fueled hacking and
华盛顿大学公开课Introduction to Data Science 006_big_data

4/28/13 Bill Howe, UW 7
Big Data Now
“…the necessity of grappling with Big Data, and the desirability of unlocking the information hidden within it, is now a key theme in all the sciences – arguably the key scientific theme of our times.”
AUVs gliders cruises, CTDs flow cytometry satellites
ADCP
# of data sources
4/28/13 Bill Howe, UW 3
Big Data
“Big Data is any data that is expensive to manage and hard to extract value from.”
– the size of the data
• Velocity
– the latency of data processing relative to the growing demand for interactivity
• Variety
– the diversity of sources, formats, quality, structures
telescopes n-body sims
# of bytes
spectra
Ocean Sciences
models stations
OOI (~50TB/year; sims, RSN) IOOS (~50TB/year; sims, satellite, gliders, AUVs, vessels, more) CMOP (~10TB/year; sims, stations, gliders, AUVs, vessels, more)
Big Data Now
“…the necessity of grappling with Big Data, and the desirability of unlocking the information hidden within it, is now a key theme in all the sciences – arguably the key scientific theme of our times.”
AUVs gliders cruises, CTDs flow cytometry satellites
ADCP
# of data sources
4/28/13 Bill Howe, UW 3
Big Data
“Big Data is any data that is expensive to manage and hard to extract value from.”
– the size of the data
• Velocity
– the latency of data processing relative to the growing demand for interactivity
• Variety
– the diversity of sources, formats, quality, structures
telescopes n-body sims
# of bytes
spectra
Ocean Sciences
models stations
OOI (~50TB/year; sims, RSN) IOOS (~50TB/year; sims, satellite, gliders, AUVs, vessels, more) CMOP (~10TB/year; sims, stations, gliders, AUVs, vessels, more)
华盛顿大学公开课 Introduction to Data Science 2 - 5 - Relational Algebra Details- Project, Cross

probably maybe should have put a slide in
here just about join in general first.
Well, generating all possible pairs and
applyபைடு நூலகம்ng the function is, is always a, a
reasonable way to do this.
Okay.
Alright, so these kinds of operations are
And so, the question here is which one is
more efficient?
Well, removing duplicates is expensive.
So, just leaving them in place is, is
more efficient.
called distinct.
Okay.
Now, let's see an example of this.
All right.
So, fine.
So, as an example here is project social
security number and names.
We only want two columns out of all the
applications.
And that's this notion of cross product.
And so a cross product here is, for every
tuple in r one.
here just about join in general first.
Well, generating all possible pairs and
applyபைடு நூலகம்ng the function is, is always a, a
reasonable way to do this.
Okay.
Alright, so these kinds of operations are
And so, the question here is which one is
more efficient?
Well, removing duplicates is expensive.
So, just leaving them in place is, is
more efficient.
called distinct.
Okay.
Now, let's see an example of this.
All right.
So, fine.
So, as an example here is project social
security number and names.
We only want two columns out of all the
applications.
And that's this notion of cross product.
And so a cross product here is, for every
tuple in r one.
华盛顿大学公开课 Introduction to Data Science 2 - 1 - From Data Models to Databases (10-35)

So, you have here sort of an embedded
table within a spreadsheet and so on.
So, you need to sort of, the idea is to
think about what data model is being
What constraints there are the over the
structure and so on and this gives you an
idea of the data model.
Alright, what does it, so what is a
database?
that they're not they persist, even when
the power goes out.
The data is safe, even when the power is
not on, okay, so non volatile storage,
right?
And so, a lot of the work in data base is
It's essentially get the next in bytes,
move to another position within the file
and then you can open and close the file,
and that's about that's not all the
more of the logical way we store, the
table within a spreadsheet and so on.
So, you need to sort of, the idea is to
think about what data model is being
What constraints there are the over the
structure and so on and this gives you an
idea of the data model.
Alright, what does it, so what is a
database?
that they're not they persist, even when
the power goes out.
The data is safe, even when the power is
not on, okay, so non volatile storage,
right?
And so, a lot of the work in data base is
It's essentially get the next in bytes,
move to another position within the file
and then you can open and close the file,
and that's about that's not all the
more of the logical way we store, the
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Publication bias: What are the challenges and can they be overcome? Ridha Joober, Norbert Schmitz, Lawrence Annable, and Patricia Boksa 5/29/13 Bill Howe, Data Science, Autumn 2012 J Psychiatry Neurosci. 2012 May; 37(3): 149–152. doi: 10.1503/jpn.120065
5/29/13
Bill Howe, UW
2
5/29/13
Bill Howe, UW
3
5/29/13
Bill Howe, UW
4
Jonah Lehrer, 2010, The New Yorker The Truth Wears off
John Davis, University of Illinois “Davis has a forthcoming analysis demonstrating that the efficacy of antidepressants has gone down as much as threefold in recent decades.” Anders Pape Møller, 1991 “female barn swallows were far more likely to mate with male birds that had long, symmetrical feathers” “Between 1992 and 1997, the average effect size shrank by eighty per cent.” Jonathan Schooler, 1990 “subjects shown a face and asked to describe it were much less likely to recognize the face when shown it later than those who had simply looked at it.” The effect became increasingly difficult to measure. Joseph Rhine, 1930s, coiner of the term extrasensory perception Tested individuals with card-guessing experiments. A few students achieved multiple low-probability streaks. But there was a “decline effect” – their performance became worse over time.
/reporting/2010/12/13/101213fa_fact_lehrer 5/29/13 Bill Howe, Data Science, Autumn 2012ation Bias
“In the last few years, several meta-analyses have reappraised the efficacy and safety of antidepressants and concluded that the therapeutic value of these drugs may have been significantly overestimated.” “Although publication bias has been documented in the literature for decades and its origins and consequences debated extensively, there is evidence suggesting that this bias is increasing.” “A case in point is the field of biomedical research in autism spectrum disorder (ASD), which suggests that in some areas negative results are completely absent” (emphasis mine) “… a highly significant correlation (R2= 0.13, p < 0.001) between impact factor and overestimation of effect sizes has been reported.”
5/29/13
Bill Howe, UW
1
P-value
• If the test is two-sided:
– P-value = 2 * P( X > |observed value| )
• If the test is one-sided:
– HA is µ > µ0 – P-value = P( X > observed value ) – HA is µ < µ0 – P-value = P( X < observed value )
6
Publication Bias (2)
“decline effect”
5/29/13
Bill Howe, UW
7
“decline effect” = publication bias!
5/29/13
Bill Howe, UW
8
How different is different?
• How do we know the difference in two treatments is not just due to chance? • We don’t. But we can calculate the odds that it is. • This is the p-value • In repeated experiments at this sample size, how often would you see a result at least this extreme assuming the null hypothesis?
5/29/13
Bill Howe, UW
2
5/29/13
Bill Howe, UW
3
5/29/13
Bill Howe, UW
4
Jonah Lehrer, 2010, The New Yorker The Truth Wears off
John Davis, University of Illinois “Davis has a forthcoming analysis demonstrating that the efficacy of antidepressants has gone down as much as threefold in recent decades.” Anders Pape Møller, 1991 “female barn swallows were far more likely to mate with male birds that had long, symmetrical feathers” “Between 1992 and 1997, the average effect size shrank by eighty per cent.” Jonathan Schooler, 1990 “subjects shown a face and asked to describe it were much less likely to recognize the face when shown it later than those who had simply looked at it.” The effect became increasingly difficult to measure. Joseph Rhine, 1930s, coiner of the term extrasensory perception Tested individuals with card-guessing experiments. A few students achieved multiple low-probability streaks. But there was a “decline effect” – their performance became worse over time.
/reporting/2010/12/13/101213fa_fact_lehrer 5/29/13 Bill Howe, Data Science, Autumn 2012ation Bias
“In the last few years, several meta-analyses have reappraised the efficacy and safety of antidepressants and concluded that the therapeutic value of these drugs may have been significantly overestimated.” “Although publication bias has been documented in the literature for decades and its origins and consequences debated extensively, there is evidence suggesting that this bias is increasing.” “A case in point is the field of biomedical research in autism spectrum disorder (ASD), which suggests that in some areas negative results are completely absent” (emphasis mine) “… a highly significant correlation (R2= 0.13, p < 0.001) between impact factor and overestimation of effect sizes has been reported.”
5/29/13
Bill Howe, UW
1
P-value
• If the test is two-sided:
– P-value = 2 * P( X > |observed value| )
• If the test is one-sided:
– HA is µ > µ0 – P-value = P( X > observed value ) – HA is µ < µ0 – P-value = P( X < observed value )
6
Publication Bias (2)
“decline effect”
5/29/13
Bill Howe, UW
7
“decline effect” = publication bias!
5/29/13
Bill Howe, UW
8
How different is different?
• How do we know the difference in two treatments is not just due to chance? • We don’t. But we can calculate the odds that it is. • This is the p-value • In repeated experiments at this sample size, how often would you see a result at least this extreme assuming the null hypothesis?