查找与及其应用实验报告
计算机信息检索实验报告(6个)

实验一网上中文搜索引擎及其使用一、实验心得在电脑已经成为生活必备品的现在,日常搜索是一件很平常的事情。
俗话说,天天百度知识丰富。
当然,我国国内主要的搜索引擎除了百度,还有谷歌、雅虎、搜狗、网易、新浪。
一般来说,百度和谷歌是最多人用的。
不同的搜索引擎,不同的搜索方法,得到搜索结果的速度和准确度也不一样。
所以我觉得学习计算机信息检索的主要目的就是更好地提高自己搜索的速度和准确度。
在这次实验当中,我们主要学习和掌握以下搜索技巧的运用。
「“”」的基本用法、「+」或「空格」的基本用法、「+」的基本用法、「-」的基本用法、「OR」的基本用法、「site」的基本用法、「inurl」的基本用法、「intitle」的基本用法、「filetype」的基本用法。
比起以前直接把整个问题打上去然后从网页中寻找满意的答案,灵活使用这些搜索技巧可以更快地找到准确率高的答案。
这些技巧在现实生活中具有高度的可操作性和便捷性。
二、实验结果(一)请使用Google或百度搜索引擎完成以下知识测验:(请将检索结果复制到题干之后,并把所有有关的网页都下载到你的作业文件夹中,以作为本作业评分的依据。
)1.谁根据小仲马的《茶花女》改编了同名歌剧( B )/b/7602599.htmlA.奥斯汀 B.威尔第 C.福楼拜2."生存还是死亡,这是一个问题。
"出自莎士比亚的哪部作品?( A )/question/25934693.htmlA.《哈姆雷特》 B.《李尔王》 C.《麦克白》3."侦探福尔摩斯"第一次出现是在下列哪部作品中: ( A )/question/1306083005651.htmlA.《血字的研究》B.《东方快车谋杀案》C.《尼罗河上的惨案》D.《难逃一生》4.李清照词中名句"寻寻觅觅,冷冷清清,凄凄惨惨戚戚"的词牌名是: ( D ) /wenda/thread?tid=7c29ad4f072df739&hl=cnA.醉花阴B.一剪梅C.如梦令D.声声慢(二)请在网上寻找如下列图片。
信息检索课程实验报告

一、实验背景随着信息技术的飞速发展,信息检索已成为信息时代的重要技能。
为了提高我们的信息素养,培养我们在海量信息中快速、准确地找到所需信息的能力,我们开展了信息检索课程实验。
本实验旨在让我们熟悉信息检索的基本流程,掌握各种检索工具的使用方法,并学会运用检索策略进行信息获取。
二、实验目的1. 熟悉信息检索的基本概念和流程。
2. 掌握搜索引擎和数据库的使用方法。
3. 学会运用检索策略提高检索效率。
4. 培养信息素养,提高信息获取能力。
三、实验内容1. 信息检索基本概念(1)信息检索:指根据信息用户的需求,利用一定的检索工具或联机网络,从大量的文献中迅速准确地查找、筛选、整理和利用所需信息的过程。
(2)检索工具:包括搜索引擎、数据库、图书馆等。
(3)检索策略:指在检索过程中,针对特定需求,选择合适的检索词、检索式和检索途径,以达到快速、准确地获取所需信息的目的。
2. 搜索引擎的使用(1)以百度为例,介绍搜索引擎的基本操作。
(2)演示如何利用关键词进行精确检索、组合检索和高级检索。
(3)讲解如何使用搜索技巧,如排除法、使用引号等。
3. 数据库的使用(1)以CNKI为例,介绍学术数据库的基本操作。
(2)演示如何利用数据库的高级检索功能,如主题检索、作者检索、机构检索等。
(3)讲解如何筛选和整理检索结果,提高信息获取效率。
4. 检索策略的应用(1)针对特定课题,分析检索需求,确定检索策略。
(2)运用关键词、布尔逻辑运算符、位置运算符等构建检索式。
(3)根据检索结果,调整检索策略,提高检索效果。
四、实验步骤1. 熟悉实验内容,了解信息检索的基本概念和流程。
2. 登录百度搜索引擎,进行关键词检索、组合检索和高级检索实验。
3. 登录CNKI学术数据库,进行主题检索、作者检索、机构检索等实验。
4. 根据实验需求,构建检索式,进行检索实验。
5. 分析检索结果,调整检索策略,提高检索效果。
6. 撰写实验报告,总结实验心得。
实验四 搜索 实验报告

实验四搜索实验报告一、实验目的本次实验的主要目的是深入了解和掌握不同的搜索算法和技术,通过实际操作和分析,提高对搜索问题的解决能力,以及对搜索效率和效果的评估能力。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
实验中所需的数据集和相关库函数均从网络上获取和下载。
三、实验原理1、线性搜索线性搜索是一种最简单的搜索算法,它从数据的开头开始,依次比较每个元素,直到找到目标元素或者遍历完整个数据集合。
2、二分搜索二分搜索则是基于有序数组的一种搜索算法。
它每次将数组从中间分割,比较目标值与中间元素的大小,然后在可能包含目标值的那一半数组中继续进行搜索。
3、广度优先搜索广度优先搜索是一种图搜索算法。
它从起始节点开始,逐层地访问相邻节点,先访问距离起始节点近的节点,再访问距离远的节点。
4、深度优先搜索深度优先搜索也是一种图搜索算法,但它沿着一条路径尽可能深地访问节点,直到无法继续,然后回溯并尝试其他路径。
四、实验内容及步骤1、线性搜索实验编写线性搜索函数,接受一个列表和目标值作为参数。
生成一个包含随机数的列表。
调用线性搜索函数,查找特定的目标值,并记录搜索所用的时间。
2、二分搜索实验先对列表进行排序。
编写二分搜索函数。
同样生成随机数列表,查找目标值并记录时间。
3、广度优先搜索实验构建一个简单的图结构。
编写广度优先搜索函数。
设定起始节点和目标节点,进行搜索并记录时间。
与广度优先搜索类似,构建图结构。
编写深度优先搜索函数。
进行搜索并记录时间。
五、实验结果与分析1、线性搜索结果在不同规模的列表中,线性搜索的时间消耗随着列表长度的增加而线性增加。
对于较小规模的列表,线性搜索的效率尚可,但对于大规模列表,其搜索时间明显较长。
2、二分搜索结果二分搜索在有序列表中的搜索效率极高,其时间消耗增长速度远低于线性搜索。
即使对于大规模的有序列表,二分搜索也能在较短的时间内找到目标值。
3、广度优先搜索结果广度优先搜索能够有效地遍历图结构,并找到最短路径(如果存在)。
查找排序实验报告

查找排序实验报告一、实验目的本次实验的主要目的是深入理解和比较不同的查找和排序算法在性能和效率方面的差异。
通过实际编程实现和测试,掌握常见查找排序算法的原理和应用场景,为今后在实际编程中能够选择合适的算法解决问题提供实践经验。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
计算机配置为:处理器_____,内存_____,操作系统_____。
三、实验内容1、查找算法顺序查找二分查找2、排序算法冒泡排序插入排序选择排序快速排序四、算法原理1、顺序查找顺序查找是一种最简单的查找算法。
它从数组的一端开始,依次比较每个元素,直到找到目标元素或者遍历完整个数组。
其时间复杂度为 O(n),在最坏情况下需要遍历整个数组。
2、二分查找二分查找适用于已排序的数组。
它通过不断将数组中间的元素与目标元素进行比较,将查找范围缩小为原来的一半,直到找到目标元素或者确定目标元素不存在。
其时间复杂度为 O(log n),效率较高。
3、冒泡排序冒泡排序通过反复比较相邻的两个元素并交换它们的位置,将最大的元素逐步“浮”到数组的末尾。
每次遍历都能确定一个最大的元素,经过 n-1 次遍历完成排序。
其时间复杂度为 O(n^2)。
4、插入排序插入排序将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的合适位置。
其时间复杂度在最坏情况下为 O(n^2),但在接近有序的情况下性能较好。
5、选择排序选择排序每次从待排序数组中选择最小的元素,与当前位置的元素交换。
经过 n-1 次选择完成排序。
其时间复杂度为 O(n^2)。
6、快速排序快速排序采用分治的思想,选择一个基准元素,将数组分为小于基准和大于基准两部分,然后对这两部分分别递归排序。
其平均时间复杂度为 O(n log n),在大多数情况下性能优异。
五、实验步骤1、算法实现使用Python 语言实现上述六种查找排序算法,并分别封装成函数,以便后续调用和测试。
文献检索的实验报告

一、实验目的1. 掌握文献检索的基本方法与技巧。
2. 培养查找相关文献的能力,提高学术研究水平。
3. 了解学术资源数据库的特点与使用方法。
二、实验时间2023年10月25日三、实验地点图书馆电子阅览室四、实验内容1. 确定检索主题:以“人工智能在医疗领域的应用”为检索主题。
2. 选择检索工具:使用中国知网(CNKI)进行文献检索。
3. 确定检索策略:采用关键词检索、主题词检索和分类检索相结合的方式。
五、实验步骤1. 打开中国知网(CNKI)官方网站,点击“高级检索”。
2. 在检索框中输入关键词“人工智能”、“医疗领域”。
3. 选择检索范围:全文、标题、关键词等。
4. 设置检索时间范围:2010年至今。
5. 选择文献类型:期刊、学位论文、会议论文等。
6. 点击“检索”按钮,查看检索结果。
六、实验结果与分析1. 检索结果:共检索到相关文献123篇,其中期刊论文89篇,学位论文20篇,会议论文14篇。
2. 文献分析:(1)人工智能在医疗领域的应用研究主要集中在以下几个方面:a. 辅助诊断:利用人工智能技术对医学影像进行分析,提高诊断准确率。
b. 辅助治疗:根据患者的病情,制定个性化的治疗方案。
c. 医疗资源优化:通过人工智能技术,实现医疗资源的合理配置。
(2)研究方法:a. 数据挖掘:通过对大量医疗数据的挖掘,发现疾病规律。
b. 深度学习:利用深度学习技术,实现对医学图像的自动识别。
c. 自然语言处理:通过自然语言处理技术,实现医疗文本的自动分析。
(3)研究现状:a. 人工智能在医疗领域的应用已取得一定成果,但仍存在一些问题,如数据质量、算法精度等。
b. 未来发展趋势:随着技术的不断发展,人工智能在医疗领域的应用将更加广泛。
七、实验结论1. 通过本次实验,掌握了文献检索的基本方法与技巧。
2. 提高了查找相关文献的能力,为学术研究提供了有力支持。
3. 了解了学术资源数据库的特点与使用方法,为今后的学术研究奠定了基础。
文件检索实验报告

文件检索实验报告一、引言文件检索是一种通过关键词或查询语句来查找和检索目标文件的方法。
它在信息检索领域有着广泛的应用,包括大规模文本搜索、网络搜索引擎等。
本实验旨在通过设计和实现一个简单的文件检索系统,来探讨文件检索的原理和实现方法。
二、文件检索系统设计2.1 系统架构文件检索系统主要包括以下三个组件:1.文本预处理器:负责对待检索的文件进行预处理,包括文本分词、去除停用词等。
2.索引构建器:将预处理后的文本构建成倒排索引,以便后续的查询操作。
3.查询处理器:接收用户的查询请求,根据倒排索引进行检索,并返回与查询相关的文件列表。
2.2 文件预处理文件预处理是文件检索的第一步,目的是将待检索的文件转化为可以建立索引的形式。
常见的预处理步骤包括:1.分词:将文本切分成一个个单词或词组,常用的方法有基于规则的切分和基于统计的切分。
2.去除停用词:将一些常见且无实际检索意义的词汇去除,例如“的”、“是”等。
3.大小写转换:将文本中的英文字母统一转换为小写,以方便后续的索引构建和查询处理。
2.3 索引构建索引构建是文件检索的核心步骤,其目的是根据预处理后的文本构建倒排索引。
倒排索引是一种将单词映射到包含该单词的文件列表的数据结构。
索引构建的过程主要包括以下几个步骤:1.单词统计:对预处理后的文本进行单词的统计,得到每个单词在不同文档中的出现次数。
2.倒排列表生成:根据单词的统计信息,生成每个单词对应的倒排列表,记录该单词在哪些文档中出现。
3.索引存储:将生成的倒排列表存储到磁盘上,以便后续的查询操作。
2.4 查询处理查询处理是文件检索的关键步骤,通过用户的查询请求,在倒排索引中查找与查询相关的文档列表,并按照相关性进行排序。
查询处理的过程主要包括以下几个步骤:1.查询解析:将用户的查询请求解析为一组关键词,例如对查询语句进行分词。
2.查询扩展:根据倒排索引,将查询中的关键词进行扩展,找到与之相关的同义词或相关词。
计算机信息检索实验报告(6个)

实验一网上中文搜索引擎及其使用一、实验心得在电脑已经成为生活必备品的现在,日常搜索是一件很平常的事情。
俗话说,天天百度知识丰富。
当然,我国国内主要的搜索引擎除了百度,还有谷歌、雅虎、搜狗、网易、新浪。
一般来说,百度和谷歌是最多人用的。
不同的搜索引擎,不同的搜索方法,得到搜索结果的速度和准确度也不一样。
所以我觉得学习计算机信息检索的主要目的就是更好地提高自己搜索的速度和准确度。
在这次实验当中,我们主要学习和掌握以下搜索技巧的运用。
「“”」的基本用法、「+」或「空格」的基本用法、「+」的基本用法、「-」的基本用法、「OR」的基本用法、「site」的基本用法、「inurl」的基本用法、「intitle」的基本用法、「filetype」的基本用法。
比起以前直接把整个问题打上去然后从网页中寻找满意的答案,灵活使用这些搜索技巧可以更快地找到准确率高的答案。
这些技巧在现实生活中具有高度的可操作性和便捷性。
二、实验结果(一)请使用Google或百度搜索引擎完成以下知识测验:(请将检索结果复制到题干之后,并把所有有关的网页都下载到你的作业文件夹中,以作为本作业评分的依据。
)1.谁根据小仲马的《茶花女》改编了同名歌剧( B )/b/7602599.html A.奥斯汀B.威尔第C.福楼拜2."生存还是死亡,这是一个问题。
"出自莎士比亚的哪部作品?( A )/question/25934693.html A.《哈姆雷特》 B.《李尔王》 C.《麦克白》 3."侦探福尔摩斯"第一次出现是在下列哪部作品中: ( A ) /question/1306083005651.html A.《血字的研究》 B.《东方快车谋杀案》 C.《尼罗河上的惨案》D.《难逃一生》4.李清照词中名句"寻寻觅觅,冷冷清清,凄凄惨惨戚戚"的词牌名是: ( D ) /wenda/thread?tid=7c29ad4f072df739&hl=cn A.醉花阴 B.一剪梅 C.如梦令 D.声声慢(二)请在网上寻找如下列图片。
文献检索与利用作业(一)
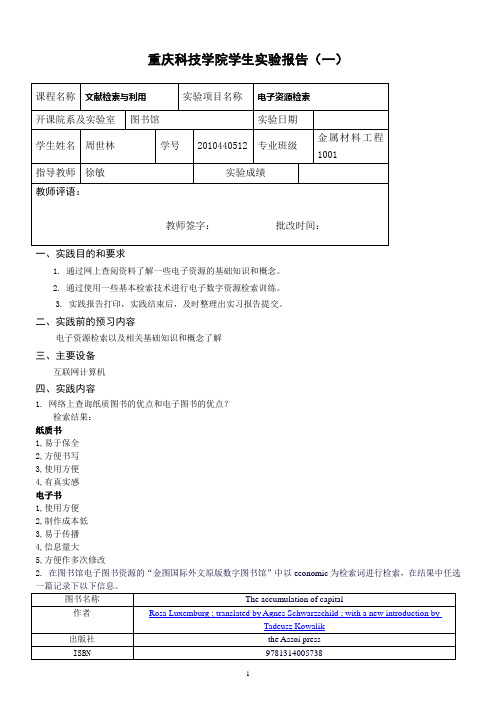
重庆科技学院学生实验报告(一)一、实践目的和要求1. 通过网上查阅资料了解一些电子资源的基础知识和概念。
2. 通过使用一些基本检索技术进行电子数字资源检索训练。
3. 实践报告打印,实践结束后,及时整理出实习报告提交。
二、实践前的预习内容电子资源检索以及相关基础知识和概念了解三、主要设备互联网计算机四、实践内容1. 网络上查询纸质图书的优点和电子图书的优点?检索结果:纸质书1,易于保全2,方便书写3,使用方便4,有真实感电子书1,使用方便2,制作成本低3,易于传播4,信息量大5,方便作多次修改2.在图书馆电子图书资源的“金图国际外文原版数字图书馆”中以economic为检索词进行检索,在结果中任选一篇记录下以下信息。
3. 在图书馆电子图书资源的“时代圣典数字图书馆”中检索作者为“王燕”,书名含“四级”的电子图书信息。
4.在图书馆电子图书资源的“超星数字图书馆”中检索作者姓“赵”,书名含“冶金”的2009年出版的电子图检索结果:( 4 )条书信息,记录下检索结果数量并任选一个记录以下信息。
★此项要填>>6.在图书馆电子图书资源的“书生之家数字图书馆”中利用分类检索来查找“冶金与金属-> 炼钢-> 炼钢炉”下的电子图书数量并任选一个记录以下信息。
★此项要填>> 检索结果:( 1 )条56348. 在图书馆电子图书资源的“九羽数字图书馆”中,高级搜索以ISBN号为7-80153-961-3来检索并记录。
9.在图书馆电子图书资源的“博图外文电子图书”中,高级检索书名含“economy”,出版社为“State University of New Y ork Press”的任意一条结果并记录结果中的书名、作者和ISBN信息。
图书名称:A Comparative Political Economy of Tunisia and Morocco : On the Outside of Europe Looking in作者:White, Gregory.ISBN:0791450279/079145027910. 图书馆的CNKI中国学术期刊全文数据库中的中国期刊全文数据库中寻找题名为“国内铜硫浮选分离研究现状”的文章并下载打开记录其结论段落三点内容任意其一。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
{printf("%d ",R[i].key);i++; //从表头往后找}if (i>=n)return -1;else{printf("%d",R[i].key);return i;}}int main(){SeqList R;int n=10,i;KeyType k=5;int a[]={3,6,2,10,1,8,5,7,4,9};for (i=0;i<n;i++) //建立顺序表R[i].key=a[i];printf("关键字序列:");for (i=0;i<n;i++)printf("%d ",R[i].key);printf("\n");printf("查找%d所比较的关键字:\n\t",k);if ((i=SeqSearch(R,n,k))!=-1)printf("\n元素%d的位置是%d\n",k,i);elseprintf("\n元素%d不在表中\n",k);printf("\n");}代码片段2:#include <stdio.h>#define MAXL 100//定义表中最多记录个数typedef int KeyType;typedef char InfoType[10];typedef struct{KeyType key;//KeyType为关键字的数据类型InfoType data;//其他数据} NodeType;typedef NodeType SeqList[MAXL];//顺序表类型int BinSearch(SeqList R,int n,KeyType k)//二分查找算法{int low=0,high=n-1,mid,count=0;while (low<=high){mid=(low+high)/2;printf("第%d次比较:在[%d,%d]中比较元素R[%d]:%d\n",++count,low,high,mid,R[mid].key);if (R[mid].key==k)//查找成功返回return mid;if (R[mid].key>k)//继续在R[low..mid-1]中查找high=mid-1;elselow=mid+1;//继续在R[mid+1..high]中查找}return -1;}int main(){SeqList R;KeyType k=9;int a[]={1,2,3,4,5,6,7,8,9,10},i,n=10;for (i=0;i<n;i++)//建立顺序表R[i].key=a[i];printf("关键字序列:");for (i=0;i<n;i++)printf("%d ",R[i].key);printf("\n");printf("查找%d的比较过程如下:\n",k);if ((i=BinSearch(R,n,k))!=-1)printf("元素%d的位置是%d\n",k,i);elseprintf("元素%d不在表中\n",k);return 0;}代码片段3:#include <stdio.h>#include <malloc.h>#define MaxSize 100typedef int KeyType;//定义关键字类型typedef char InfoType;typedef struct node //记录类型{KeyType key; //关键字项InfoType data; //其他数据域struct node *lchild, *rchild;//左右孩子指针} BSTNode;int path[MaxSize];//全局变量,用于存放路径void DispBST(BSTNode *b);//函数说明int InsertBST(BSTNode *&p, KeyType k);BSTNode *CreatBST(KeyType A[], int n);void DispBST(BSTNode *bt);int JudgeBST(BSTNode *bt);int SearchBST(BSTNode *bt, KeyType k);void Delete1(BSTNode *p, BSTNode *&r);void Delete(BSTNode *&p);int DeleteBST(BSTNode *&bt, KeyType k);int InsertBST(BSTNode *&p, KeyType k)//在以*p为根节点的BST中插入一个关键字为k的节点{if (p == NULL)//原树为空, 新插入的记录为根节点{p = (BSTNode *)malloc(sizeof(BSTNode));p->key = k; p->lchild = p->rchild = NULL;return 1;}else if (k == p->key)return 0;else if (k<p->key)return InsertBST(p->lchild, k);//插入到*p的左子树中elsereturn InsertBST(p->rchild, k); //插入到*p的右子树中}BSTNode *CreatBST(KeyType A[], int n)//由数组A中的关键字建立一棵二叉排序树{BSTNode *bt = NULL; //初始时bt为空树int i = 0;while (i<n)if (InsertBST(bt, A[i]) == 1)//将A[i]插入二叉排序树T中{printf(" 第%d步,插入%d:", i + 1, A[i]);DispBST(bt); printf("\n");i++;}return bt; //返回建立的二叉排序树的根指针}void DispBST(BSTNode *bt)//以括号表示法输出二叉排序树bt{if (bt != NULL){printf("%d", bt->key);if (bt->lchild != NULL || bt->rchild != NULL){printf("(");DispBST(bt->lchild);if (bt->rchild != NULL) printf(",");DispBST(bt->rchild);printf(")");}}}KeyType predt = -32767; //predt为全局变量,保存当前节点中序前趋的值,初值为-∞int JudgeBST(BSTNode *bt)//判断bt是否为BST{int b1, b2;if (bt == NULL) //空二叉树是排序二叉树return 1;else{b1 = JudgeBST(bt->lchild); //返回对左子树的判断,不是返回0,否则返回1if (b1 == 0 || predt >= bt->key) //当左子树不是二叉排序树,或中序前趋(全局变量)大于当前根结点时return 0; //返回“不是二叉排序树”predt = bt->key; //记录当前根为右子树的中序前趋b2 = JudgeBST(bt->rchild); //对右子树进行判断return b2;}}int SearchBST(BSTNode *bt, KeyType k)//以递归方式输出从根节点到查找到的节点的路径{if (bt == NULL)return 0;else if (k == bt->key){printf("%3d", bt->key);return 1;}else if (k<bt->key)SearchBST(bt->lchild, k); //在左子树中递归查找elseSearchBST(bt->rchild, k); //在右子树中递归查找printf("%3d", bt->key);}void Delete1(BSTNode *p, BSTNode *&r)//当被删*p节点有左右子树时的删除过程{BSTNode *q;if (r->rchild != NULL)Delete1(p, r->rchild);//递归找最右下节点else//找到了最右下节点*r{p->key = r->key;//将*r的关键字值赋给*pq = r;r = r->lchild;//将*r的双亲节点的右孩子节点改为*r的左孩子节点free(q);//释放原*r的空间}}void Delete(BSTNode *&p)//从二叉排序树中删除*p节点{BSTNode *q;if (p->rchild == NULL)//*p节点没有右子树的情况{q = p; p = p->lchild; free(q);}else if (p->lchild == NULL)//*p节点没有左子树的情况{q = p; p = p->rchild; free(q);}else Delete1(p, p->lchild);//*p节点既有左子树又有右子树的情况}int DeleteBST(BSTNode *&bt, KeyType k)//在bt中删除关键字为k的节点{if (bt == NULL) return 0;//空树删除失败else{if (k<bt->key)return DeleteBST(bt->lchild, k);//递归在左子树中删除关键字为k的节点else if (k>bt->key)return DeleteBST(bt->rchild, k);//递归在右子树中删除关键字为k的节点else//k=bt->key的情况{Delete(bt);//调用Delete(bt)函数删除*bt节点return 1;}}}int main(){BSTNode *bt;KeyType k = 6;int a[] = { 4, 9, 0, 1, 8, 6, 3, 5, 2, 7 }, n = 10;printf("创建一棵BST树:");printf("\n");bt = CreatBST(a, n);printf("BST:"); DispBST(bt); printf("\n");printf("bt%s\n", (JudgeBST(bt) ? "是一棵BST" : "不是一棵BST"));printf(" 查找%d关键字(递归,逆序):", k); SearchBST(bt, k);//SearchBST(bt, k, path, -1);printf("\n删除操作:\n");printf(" 原BST:"); DispBST(bt); printf("\n");printf(" 删除节点4:");DeleteBST(bt, 4);DispBST(bt); printf("\n");printf(" 删除节点5:");实验结果:1.2.3:总结体会:通过本次实验学会了顺序查找和二分查找的区别,认清了两种方法的不同之处,相比之下,二分查找比顺序查找更能节约空间和时间,利用二分查找要优越与顺序查找,也更符合人们的思想,对排序的算法有了更深的认识,体会到了算法的优越。