Excel函数应用教程:统计函数
excel里countif用法

在Excel中,countif函数是一个非常常用的统计函数,用来统计符合指定条件的单元格个数。
它的语法非常简单,但是有着非常广泛的应用场景。
本文将详细介绍countif函数的用法及其在实际工作中的应用。
一、countif函数的语法在使用countif函数时,需要按照以下语法进行书写:=countif(range, criteria)其中,range表示要统计的数据范围,可以是一个单独的单元格,也可以是一个区域;criteria表示要进行统计的条件,可以是一个具体的数值,也可以是一个逻辑表达式。
二、countif函数的基本用法1. 统计特定数值的个数在实际工作中,我们常常需要统计某个数值在一列数据中出现的次数。
此时,可以使用countif函数来实现。
我们有一列成绩数据,想要统计成绩大于等于60分的学生人数,可以使用如下公式:=countif(A2:A10, ">=60")2. 统计满足特定条件的数据个数除了统计特定数值的个数,countif函数还可以用来统计满足特定条件的数据个数。
我们有一列销售数据,想要统计销售额大于5000的销售人员的数量,可以使用如下公式:=countif(B2:B10, ">5000")三、countif函数的高级用法1. 组合条件的统计在实际工作中,有时候我们需要统计满足多个条件的数据个数。
此时,可以使用countif函数的高级用法。
我们有一列学生成绩数据,想要统计数学成绩大于80且英语成绩大于60的学生人数,可以使用如下公式:=countif((A2:A10, "数学成绩">80)*(B2:B10, "英语成绩">60))2. 使用通配符进行统计countif函数还支持使用通配符进行统计。
通配符“*”表示匹配任意多个字符,“?”表示匹配单个字符。
我们有一列员工名单,想要统计姓“张”的员工数量,可以使用如下公式:=countif(C2:C10, "张*")四、countif函数的实际应用1. 数据分析在数据分析中,countif函数经常被用来统计满足特定条件的数据个数,从而进行数据筛选和分析。
excel里的countif函数

导语在日常工作中,Excel是一款非常常用的工具软件,它可以帮助我们进行数据处理、分析和统计。
在实际操作中,我们经常会用到countif函数,它可以帮助我们快速统计符合某一条件的数据数量。
本文将从简单到复杂,由浅入深地探讨Excel中的countif函数,帮助读者更深入地理解和运用这一函数。
一、countif函数的基本用法在Excel中,countif函数的基本用法是统计某一范围内满足指定条件的单元格数量。
其语法为:=countif(范围,条件)。
其中,“范围”表示要进行统计的单元格范围,“条件”表示要进行统计的条件。
如果我们要统计一个区域内大于80的成绩数量,可以使用=countif(A1:A10,">80")。
二、countif函数的扩展用法除了基本用法,countif函数还有许多扩展用法,可以帮助我们更灵活地进行数据统计。
我们可以结合通配符(*和?)进行模糊匹配,或者结合其他函数(如sumif、averageif等)进行复杂的数据分析。
三、countif函数在实际工作中的应用在实际工作中,countif函数可以发挥很大的作用。
我们可以用它来统计某一销售区域的订单数量,或者统计某一时间段内的任务完成情况。
在数据分析和报表制作中,countif函数也是一个非常有用的工具,可以帮助我们快速准确地获取需要的统计信息。
四、对countif函数的个人理解对我而言,countif函数是Excel中非常实用的一个函数,它可以帮助我快速进行数据统计和分析。
在日常工作中,我经常会用到这个函数,比如在制作销售报表时,统计不同产品的销售数量;或者在项目管理中,统计各个阶段任务的完成情况等。
通过不断的实践和探索,我对countif函数的灵活运用越来越得心应手,相信在将来的工作中,它一定会成为我数据处理的得力助手。
总结在本文中,我们从countif函数的基本用法开始,逐步展开了对它的深入探讨。
Excel函数应用教程

Excel函数应用教程:统计函数来源:CFAN 发布时间:2009-07-21 [评论Error! Invalid Template Key.条][an error occurred while processing this directive]41.MAX用途:返回数据集中的最大数值。
语法:MAX(number1,number2,...)参数:Number1,number2,...是需要找出最大数值的1至30个数值。
实例:如果A1=71、A2=83、A3=76、A4=49、A5=92、A6=88、A7=96,则公式“=MAX(A1:A7)”返回96。
42.MAXA用途:返回数据集中的最大数值。
它与MAX的区别在于文本值和逻辑值(如TRUE 和FALSE)作为数字参与计算。
语法:MAXA(value1,value2,...)参数:value1,value2,...为需要从中查找最大数值的1到30个参数。
实例:如果A1:A5包含0、0.2、0.5、0.4和TRUE,则:MAXA(A1:A5)返回1。
43.MEDIAN用途:返回给定数值集合的中位数(它是在一组数据中居于中间的数。
换句话说,在这组数据中,有一半的数据比它大,有一半的数据比它小)。
语法:MEDIAN(number1,number2,...)参数:Number1,number2,...是需要找出中位数的1到30个数字参数。
实例:MEDIAN(11,12,13,14,15)返回13;MEDIAN(1,2,3,4,5,6)返回3.5,即3与4的平均值。
44.MIN用途:返回给定参数表中的最小值。
语法:MIN(number1,number2,...)。
参数:Number1,number2,...是要从中找出最小值的1到30个数字参数。
实例:如果A1=71、A2=83、A3=76、A4=49、A5=92、A6=88、A7=96,则公式“=MIN(A1:A7)”返回49;而=MIN(A1:A5,0,-8)返回-8。
Excel函数公式:排名统计公式大全!!!

Excel函数公式:排名统计公式大全一、单列排名统计方法:1、选定目标单元格。
2、在目标单元格中输入公式:=RANK(C3,$C$3:$C$11)。
3、Ctrl Enter填充。
二、逆序排名方法:1、选定目标单元格。
2、在目标单元格中输入公式:=RANK(C3,$C$3:$C$11,1)。
3、Ctrl Enter填充。
三、多列统一排名方法:1、选定目标单元格,多个不连续的单元格可以借助Ctrl进行选取。
2、在目标单元格中输入公式:=RANK(C3,($C$3:$C$11,$F$3:$F$11,$I$3:$I$11))。
3、Ctrl Enter填充。
四、多工作表统一排名。
方法:1、选定目标单元格,多个不连续的单元格可以借助Ctrl进行选取。
2、在目标单元格中输入公式:=RANK(C3,'1:3'!C$3:C$11)。
3、Ctrl Enter填充。
五、忽略缺考下的排名方法:1、选定目标单元格。
2、在目标单元格中输入公式:=IF(C3='缺考','',RANK(C3,$C$3:$C$11))3、Ctrl Enter填充。
六、考虑缺考成绩下的排名方法:1、选定目标单元格。
2、在目标单元格中输入公式:=IF(C3='缺考',COUNT($C$3:$C$11) 1,RANK(C3,$C$3:$C$11))3、Ctrl Enter填充。
七、中国式排名首先解释一下“中国式排名”:并列排名不占名次。
方法:1、选定目标单元格。
2、在目标单元格中输入公式:=SUMPRODUCT((C$3:C$11>=C3)*(1/COUNTIF(C$3:C$11,C$3:C $11)))。
3、Ctrl Enter填充。
八、分组排名方法:1、选定目标单元格。
2、在目标单元格中输入公式:=SUMPRODUCT((C$3:C$11=C3)*(D$3:D$11>=D3))。
Excel函数应用之统计函数

Excel函数应用之统计函数Excel的统计工作表函数用于对数据区域进行统计分析。
例如,统计工作表函数能够用来统计样本的方差、数据区间的频率散布等。
是不是感觉仿佛是很专业范围的东西?是的,统计工作表函数中提供了很多属于统计学范围的函数,但也有些函数其实在你我的日常生活中是很经常使用的,比如求班级平均成绩,排名等。
在本文中,要紧介绍一些常见的统计函数,而属于统计学范围的函数不在此赘述,详细的利用方式能够参考Excel帮忙及相关的书籍。
在介绍统计函数之前,请大伙儿先看一下附表中的函数名称。
是不是发觉有些函数是很类似的,只是在名称中多了一个字母A?比如,A VERAGE与A VERAGEA;COUNT与COUNTA。
大体上,名称中带A的函数在统计时不仅统计数字,而且文本和逻辑值(如TRUE 和FALSE)也将计算在内。
在下文中笔者将要紧介绍不带A的几种常见函数的用法。
一、用于求平均值的统计函数A VERAGE、TRIMMEAN一、求参数的算术平均值函数A VERAGE语法形式为A VERAGE(number1,number2, ...)其中Number1, number2, ...为要计算平均值的1~30个参数。
这些参数能够是数字,或是涉及数字的名称、数组或引用。
若是数组或单元格引用参数中有文字、逻辑值或空单元格,那么忽略其值。
可是,若是单元格包括零值那么计算在内。
二、求数据集的内部平均值TRIMMEAN函数TRIMMEAN先从数据集的头部和尾部除去必然百分比的数据点,然后再求平均值。
当希望在分析中剔除一部份数据的计算时,能够利用此函数。
比如,咱们在计算选手平均分数中经常使用去掉一个最高分,去掉一个最低分,XX号选手的最后得分,就能够够利用该函数来计算。
语法形式为TRIMMEAN(array,percent)其中Array为需要进行挑选并求平均值的数组或数据区域。
Percent为计算时所要除去的数据点的比例,例如,若是percent = ,在20个数据点的集合中,就要除去4个数据点(20 x ,头部除去2个,尾部除去2个。
如何使用Excel函数统计各分数段的人数(五种方法)
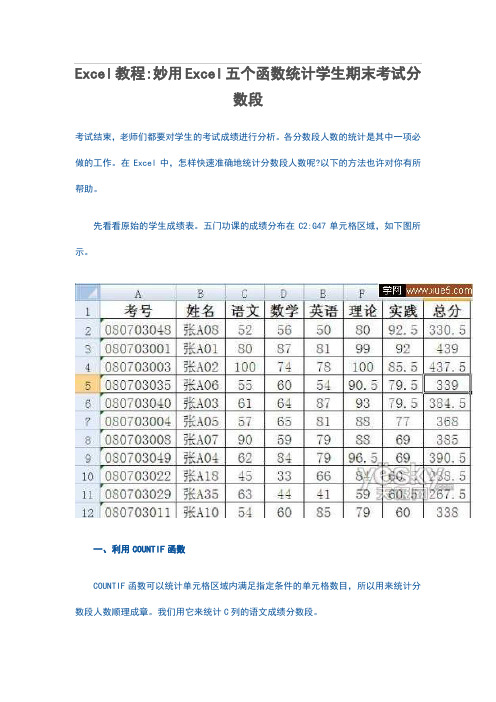
Excel教程:妙用Excel五个函数统计学生期末考试分数段考试结束,老师们都要对学生的考试成绩进行分析。
各分数段人数的统计是其中一项必做的工作。
在Excel中,怎样快速准确地统计分数段人数呢?以下的方法也许对你有所帮助。
先看看原始的学生成绩表。
五门功课的成绩分布在C2:G47单元格区域,如下图所示。
一、利用COUNTIF函数COUNTIF函数可以统计单元格区域内满足指定条件的单元格数目,所以用来统计分数段人数顺理成章。
我们用它来统计C列的语文成绩分数段。
如图2所示,我们需要在N2单元格统计语文分数在90分以上的学生数。
那么只需要在N2单元格输入公式“=COUNTIF(C2:C47,">=90")”就可以了。
其含义就是统计C2:C47单元格区域中满足大于等于90的单元格数目。
所以,要统计80分至89分这一段的学生数,那么就需要输入公式“=COUNTIF(C2:C47,">=80")-COUNTIF(C2:C47,">=90")”。
很明显,大于等于80分的人数减去大于等于90分的人数正是我们想要的人数。
其他分数段可以依此类推。
二、利用FREQUENCY函数这是一个专门用于统计单元格区域中数据的频率分布的函数,用它来统计分数段自然名正言顺。
以D列的数学成绩的统计为例。
我们先在M8:M12设置好分数段,再在L8:L12单元格区域设置好各分数段的分隔数(即为该分数段的上限数字),如图3所示。
选中N8:N12单元格,在编辑栏输入公式“=FREQUENCY($D$2:$D$47,$L$8:$L$12)”,然后按下“Ctrl+Shift+Enter”组合键确认,即可在公式的两端添加数组公式的标志“{}”,同时可以看到各分数段的人数已经统计完成了。
需要注意的是公式输入完成后必须按“Ctrl+Shift+Enter”组合键确认以产生数组公式,而且数组公式的标志“{}”也不可以手工输入。
excel用函数统计非空值数量的教程

excel用函数统计非空值数量的教程
Excel中的非空值数量具体该如何用函数统计呢?下面是由店铺分享的excel用函数统计非空值数量的教程,以供大家阅读和学习。
excel用函数统计非空值数量的教程:
函数统计非空值步骤1:下面是一名员工的出勤表,我们要统计他截至15号为止一共出勤几天。
函数统计非空值步骤2:通过上述的函数介绍我们看出要统计非空单元格只能用COUNTA及COUNTIF函数。
函数统计非空值步骤3:首先介绍COUNT函数的方法。
在C2单元格输入"=COUNTA(B2:B16)",然后C2单元格就得出这该名员工截至15号一共出勤10天。
函数统计非空值步骤4:COUNTIF是用于统计符合选定条件的单元格的数量,所以要统计非空单元格,我们首先需要知道非空在EXCEL中如何表示。
“><”“<>”这两个都是用于表示非空单元格的。
函数统计非空值步骤5:在C2单元格中输入“=COUNTIF(B2:B16,"<>")”,C3单元格输入“=COUNTIF(B2:B16,"><")”,两个公式得出的结果是一样的。
EXCEL控的COUNTIF函数应用助力职场数据统计

EXCEL控的COUNTIF函数应用助力职场数据统计在现代职场中,数据统计扮演着至关重要的角色。
数据的准确收集和分析,对于决策制定、进程优化以及业务增长都起着至关重要的作用。
然而,针对大规模的数据集进行统计分析是一项复杂而繁琐的任务。
幸运的是,Excel这一强大的办公软件提供了丰富的函数和工具,其中包括COUNTIF函数,它可以极大地简化职场数据统计的过程。
一、COUNTIF函数的基本用法COUNTIF函数是Excel中最常用的函数之一,它的作用是统计满足指定条件的单元格的个数。
基本语法如下:COUNTIF(range, criteria)其中,range代表要统计的数据范围,criteria代表要匹配的条件。
例如,在一个包含员工销售额的表格中,要统计销售额超过10000的员工人数,可以使用以下公式:=COUNTIF(B2:B10, ">10000")这将统计B2到B10单元格中值大于10000的个数。
二、COUNTIF函数的高级用法除了上述的基本用法,COUNTIF函数还提供了一系列高级的用法,进一步扩展了其在职场数据统计中的应用。
1. 多条件统计COUNTIF函数能够通过使用逻辑运算符(如AND、OR)来实现多条件的统计。
例如,统计销售额在10000到20000之间,并且工作年限在3年以上的员工人数,可以使用以下公式:=COUNTIF((B2:B10, ">10000") * (C2:C10, ">=3"))其中,*代表AND逻辑运算符,统计满足两个条件的结果。
2. 文本条件统计COUNTIF函数同样适用于文本条件的统计。
例如,在一个包含员工评级的表格中,要统计评级为"A"或"B"的员工人数,可以使用以下公式:=COUNTIF(D2:D10, "A") + COUNTIF(D2:D10, "B")这将统计D2到D10单元格中评级为"A"或"B"的个数,并使用加法运算符将两个结果相加。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.AVEDEV用途:返回一组数据与其平均值的绝对偏差的平均值,该函数可以评测数据(例如学生的某科考试成绩)的离散度。
语法:AVEDEV(number1,number2,...)参数:Number1、number2、...是用来计算绝对偏差平均值的一组参数,其个数可以在1~30个之间。
实例:如果A1=79、A2=62、A3=45、A4=90、A5=25,则公式“=AVEDEV(A1:A5)”返回20.16。
2.AVERAGE用途:计算所有参数的算术平均值。
语法:AVERAGE(number1,number2,...)。
参数:Number1、number2、...是要计算平均值的1~30个参数。
实例:如果A1:A5区域命名为分数,其中的数值分别为100、70、92、47和82,则公式“=AVERAGE(分数)”返回78.2。
3.AVERAGEA用途:计算参数清单中数值的平均值。
它与AVERAGE函数的区别在于不仅数字,而且文本和逻辑值(如TRUE和FALSE)也参与计算。
语法:AVERAGEA(value1,value2,...)参数:value1、value2、...为需要计算平均值的1至30个单元格、单元格区域或数值。
实例:如果A1=76、A2=85、A3=TRUE,则公式“=AVERAGEA(A1:A3)”返回54(即76+85+1/3=54)。
4.BETADIST用途:返回Beta分布累积函数的函数值。
Beta分布累积函数通常用于研究样本集合中某些事物的发生和变化情况。
例如,人们一天中看电视的时间比率。
语法:BETADIST(x,alpha,beta,A,B)参数:X用来进行函数计算的值,须居于可选性上下界(A和B)之间。
Alpha分布的参数。
Beta分布的参数。
A是数值x所属区间的可选下界,B是数值x所属区间的可选上界。
实例:公式“=BETADIST(2,8,10,1,3)”返回0.685470581。
5.BETAINV用途:返回beta分布累积函数的逆函数值。
即,如果probability=BETADIST(x,...),则BETAINV(probability,...)=x。
beta分布累积函数可用于项目设计,在给出期望的完成时间和变化参数后,模拟可能的完成时间。
语法:BETAINV(probability,alpha,beta,A,B)参数:Probability为Beta分布的概率值,Alpha分布的参数,Beta分布的参数,A数值x所属区间的可选下界,B数值x所属区间的可选上界。
实例:公式“=BETAINV(0.685470581,8,10,1,3)”返回2。
6.BINOMDIST用途:返回一元二项式分布的概率值。
BINOMDIST函数适用于固定次数的独立实验,实验的结果只包含成功或失败二种情况,且成功的概率在实验期间固定不变。
例如,它可以计算掷10次硬币时正面朝上6次的概率。
语法:BINOMDIST(number_s,trials,probability_s,cumulative)参数:Number_s为实验成功的次数,Trials为独立实验的次数,Probability_s为一次实验中成功的概率,Cumulative是一个逻辑值,用于确定函数的形式。
如果cumulative 为TRUE,则BINOMDIST函数返回累积分布函数,即至多number_s次成功的概率;如果为FALSE,返回概率密度函数,即number_s次成功的概率。
实例:抛硬币的结果不是正面就是反面,第一次抛硬币为正面的概率是0.5。
则掷硬币10次中6次的计算公式为“=BINOMDIST(6,10,0.5,FALSE)”,计算的结果等于0.2050787.CHIDIST用途:返回c2分布的单尾概率。
c2分布与c2检验相关。
使用c2检验可以比较观察值和期望值。
例如,某项遗传学实验假设下一代植物将呈现出某一组颜色。
使用此函数比较观测结果和期望值,可以确定初始假设是否有效。
语法:CHIDIST(x,degrees_freedom)参数:X是用来计算c2分布单尾概率的数值,Degrees_freedom是自由度。
实例:公式“=CHIDIST(1,2)”的计算结果等于0.606530663。
8.CHIINV用途:返回c2分布单尾概率的逆函数。
如果probability=CHIDIST(x,?),则CHIINV(probability,?)=x。
使用此函数比较观测结果和期望值,可以确定初始假设是否有效。
语法:CHIINV(probability,degrees_freedom)参数:Probability为c2分布的单尾概率,Degrees_freedom为自由度。
实例:公式“=CHIINV(0.5,2)”返回1.386293564。
9.CHITEST用途:返回相关性检验值,即返回c2分布的统计值和相应的自由度,可使用c2检验确定假设值是否被实验所证实。
语法:CHITEST(actual_range,expected_range)参数:Actual_range是包含观察值的数据区域,Expected_range是包含行列汇总的乘积与总计值之比的数据区域。
实例:如果A1=1、A2=2、A3=3、B1=4、B2=5、B3=6,则公式“=CHITEST(A1:A3,B1:B3)”返回0.062349477。
10.CONFIDENCE用途:返回总体平均值的置信区间,它是样本平均值任意一侧的区域。
例如,某班学生参加考试,依照给定的置信度,可以确定该次考试的最低和最高分数。
语法:CONFIDENCE(alpha,standard_dev,size)。
参数:Alpha是用于计算置信度(它等于100*(1-alpha)%,如果alpha为0.05,则置信度为95%)的显著水平参数,Standard_dev是数据区域的总体标准偏差,Size为样本容量。
实例:假设样本取自46名学生的考试成绩,他们的平均分为60,总体标准偏差为5分,则平均分在下列区域内的置信度为95%。
公式“=CONFIDENCE(0.05,5,46)”返回1.44,即考试成绩为60±1.44分。
11.CORREL用途:返回单元格区域array1和array2之间的相关系数。
它可以确定两个不同事物之间的关系,例如检测学生的物理与数学学习成绩之间是否关联。
语法:CORREL(array1,array2)参数:Array1第一组数值单元格区域。
Array2第二组数值单元格区域。
实例:如果A1=90、A2=86、A3=65、A4=54、A5=36、B1=89、B2=83、B3=60、B4=50、B5=32,则公式“=CORREL(A1:A5,B1:B5)”返回0.998876229,可以看出A、B 两列数据具有很高的相关性。
12.COUNT用途:返回数字参数的个数。
它可以统计数组或单元格区域中含有数字的单元格个数。
语法:COUNT(value1,value2,...)。
参数:value1,value2,...是包含或引用各种类型数据的参数(1~30个),其中只有数字类型的数据才能被统计。
实例:如果A1=90、A2=人数、A3=〞〞、A4=54、A5=36,则公式“=COUNT(A1:A5)”返回3。
13.COUNTA用途:返回参数组中非空值的数目。
利用函数COUNTA可以计算数组或单元格区域中数据项的个数。
语法:COUNTA(value1,value2,...)说明:value1,value2,...所要计数的值,参数个数为1~30个。
在这种情况下的参数可以是任何类型,它们包括空格但不包括空白单元格。
如果参数是数组或单元格引用,则数组或引用中的空白单元格将被忽略。
如果不需要统计逻辑值、文字或错误值,则应该使用COUNT函数。
实例:如果A1=6.28、A2=3.74,其余单元格为空,则公式“=COUNTA(A1:A7)”的计算结果等于2。
14.COUNTBLANK用途:计算某个单元格区域中空白单元格的数目。
语法:COUNTBLANK(range)参数:Range为需要计算其中空白单元格数目的区域。
实例:如果A1=88、A2=55、A3=""、A4=72、A5="",则公式“=COUNTBLANK(A1:A5)”返回2。
15.COUNTIF用途:计算区域中满足给定条件的单元格的个数。
语法:COUNTIF(range,criteria)参数:Range为需要计算其中满足条件的单元格数目的单元格区域。
Criteria为确定哪些单元格将被计算在内的条件,其形式可以为数字、表达式或文本。
16.COVAR用途:返回协方差,即每对数据点的偏差乘积的平均数。
利用协方差可以研究两个数据集合之间的关系。
语法:COVAR(array1,array2)参数:Array1是第一个所含数据为整数的单元格区域,Array2是第二个所含数据为整数的单元格区域。
实例:如果A1=3、A2=2、A3=1、B1=3600、B2=1500、B3=800,则公式“=COVAR(A1:A3,B1:B3)”返回933.3333333。
17.CRITBINOM用途:返回使累积二项式分布大于等于临界值的最小值,其结果可以用于质量检验。
例如决定最多允许出现多少个有缺陷的部件,才可以保证当整个产品在离开装配线时检验合格。
语法:CRITBINOM(trials,probability_s,alpha)参数:Trials是伯努利实验的次数,Probability_s是一次试验中成功的概率,Alpha 是临界值。
实例:公式“=CRITBINOM(10,0.9,0.75)”返回10。
18.DEVSQ用途:返回数据点与各自样本平均值的偏差的平方和。
语法:DEVSQ(number1,number2,...)参数:Number1、number2、...是用于计算偏差平方和的1到30个参数。
它们可以是用逗号分隔的数值,也可以是数组引用。
实例:如果A1=90、A2=86、A3=65、A4=54、A5=36,则公式“=DEVSQ(A1:A5)”返回2020.8。
19.EXPONDIST用途:返回指数分布。
该函数可以建立事件之间的时间间隔模型,如估计银行的自动取款机支付一次现金所花费的时间,从而确定此过程最长持续一分钟的发生概率。
语法:EXPONDIST(x,lambda,cumulative)。
参数:X函数的数值,Lambda参数值,Cumulative为确定指数函数形式的逻辑值。
如果cumulative为TRUE,EXPONDIST返回累积分布函数;如果cumulative为FALSE,则返回概率密度函数。