基于SPSS软件的CPI回归分析
SPSS回归分析过程详解

线性回归的假设检验
01
线性回归的假设检验主要包括拟合优度检验和参数显著性 检验。
02
拟合优度检验用于检验模型是否能够很好地拟合数据,常 用的方法有R方、调整R方等。
1 2
完整性
确保数据集中的所有变量都有值,避免缺失数据 对分析结果的影响。
准确性
核实数据是否准确无误,避免误差和异常值对回 归分析的干扰。
3
异常值处理
识别并处理异常值,可以使用标准化得分等方法。
模型选择与适用性
明确研究目的
根据研究目的选择合适的回归模型,如线性回 归、逻辑回归等。
考虑自变量和因变量的关系
数据来源
某地区不同年龄段人群的身高 和体重数据
模型选择
多项式回归模型,考虑X和Y之 间的非线性关系
结果解释
根据分析结果,得出年龄与体 重之间的非线性关系,并给出 相应的预测和建议。
05 多元回归分析
多元回归模型
线性回归模型
多元回归分析中最常用的模型,其中因变量与多个自变量之间存 在线性关系。
非线性回归模型
常见的非线性回归模型
对数回归、幂回归、多项式回归、逻辑回归等
非线性回归的假设检验
线性回归的假设检验
H0:b1=0,H1:b1≠0
非线性回归的假设检验
H0:f(X)=Y,H1:f(X)≠Y
检验方法
残差图、残差的正态性检验、异方差性检验等
非线性回归的评估指标
判定系数R²
(完整word版)SPSS线性回归分析案例

回归分析实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析【研究目的】居民消费在社会经济的持续发展中有着重要的作用。
影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。
【模型设定】我们研究的对象是各地区居民消费的差异。
由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。
模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。
从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。
1、实验数据表1:2010年中国各地区城市居民人均年消费支出和可支配收入数据来源:《中国统计年鉴》2010年2、实验过程作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX表2模型汇总b模型R R方调整R方标准估计的误差1 .965a.932 .930 877.29128a.预测变量:(常量),可支配收入X(元)。
b.因变量:消费性支出Y(元)表3相关性表4系数a3、结果分析表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128表3是相关分析结果。
消费性支出Y与可支配收入X相关系数为0.965,相关性很高。
表4是回归分析中的系数:常数项b=704.824,可支配收入X 的回归系数a=0.668。
a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。
spss研究影响居民消费因素的进行多元分析的详细步骤

spss研究影响居民消费因素的进行多元分析的详细步骤
进行多元线性回归分析的步骤如下:
1. 收集数据:收集到与居民消费相关的各种变量的数据,包括但不限于收入、教育程度、性别、婚姻状况、职业、地区等。
2. 数据处理:将数据导入SPSS软件,并进行数据清洗,包括剔除异常值、空值填充、变量标准化等。
3. 变量选择:参考文献、问题分析或实验结果等,选择影响居民消费的主要变量。
4. 模型建立:将选择的主要变量建立在多元线性回归模型之中。
5. 模型检验:使用F检验和t检验等,检验所建立的模型是否显著。
6. 模型诊断:检查模型诊断常见问题的方法包括:
a. 正态分布性的检验:检验残差是否符合正态分布,可使用K-S正态性检验进行检验。
b. 线性性的检验:检验自变量与因变量之间是否有线性关系,可绘制散点图、残差图等进行分析。
c. 异方差性的检验:检测残差方差是否对自变量的不同值有依赖性,可使用对数化、变量转换等方法解决。
d. 多重共线性的检验:检测自变量之间是否存在强相关关系,可使用VIF值进行检验。
7. 结果解释:通过模型运算和分析,应对变量之间的关系进行解释,说明影响居民消费的主要因素。
8. 结论汇报:对分析结果进行总结和汇报,通过图表等形式进行可视化展示,展示变量之间的关系和模型准确性,以及对应解释。
用SPSS作回归分析

xi xi
y i
2n
n 5
∑ 140 1300 2528 21040
x xi 140 14
n 10
y yi 1300 130
n 10
ˆ0 y 1 x 130 514 60
位于有16000名 学生校园附近的
=
yˆ
60
516
140(千元)
yˆi 60 5xi
饭店的销售收入
y
变量间所具有的密切关联而又不能用函数关系精确表达的关系称相关关系。
具有相关关系的两 个变量可以是不同 类型的变量。本章 中所指的相关关系 是两个数值型变量 间的相关关系。
相关关系分析不强 调两变量间的先后 顺序,即不区分自 变量与因变量。
1400
1200 月 支 1000 出 ( 元 800 )
600
ˆ1
yi
ˆ0 ˆ0
ˆ1xi
2
0
yi
ˆ0 ˆ1xi ˆ1
20Βιβλιοθήκη 2yi ˆ0 ˆ1xi 0
2 yi ˆ0 ˆ1xi xi 0
n
i1
yi
nˆ0
ˆ1
n i 1
xi
n
n
n
i1
xi yi
ˆ0
i 1
xi
ˆ1
i 1
xi 2
ˆ1
xi yi
xi
y x y 月支出(元)
月收入(元)
家庭序号 月支出(元)
1148
8882
21
710
489
4558
22
937
1208
9053
23
1030
1065
8094
24
基于SPSS的全国城镇居民消费水平差异分析

基于SPSS的全国城镇居民消费水平差异分析全国城镇居民消费水平差异分析是一个重要的经济研究课题,它可以帮助我们了解不同地区、不同人群的消费行为和消费能力,为政府制定相关经济政策提供科学依据。
本文将基于SPSS软件对全国城镇居民消费水平的差异进行分析和解读。
我们需要获取全国城镇居民的消费水平数据。
可以通过调查问卷、面访等方式获取样本数据,并对数据进行清洗和整理。
在SPSS中,可以使用数据编辑模块完成数据清洗和整理工作。
在数据清洗和整理完成后,我们可以进行描述性统计分析。
通过描述性统计分析,可以计算出各个指标的均值、标准差、最大值和最小值等统计量,从而了解数据的基本情况。
在SPSS中,可以使用统计分析模块中的描述统计功能进行计算。
接下来,我们可以进行多样本t检验分析。
多样本t检验可以比较不同地区、不同人群的消费水平是否存在显著差异。
在SPSS中,可以使用统计分析模块中的t检验功能进行多样本t检验分析。
在进行多样本t检验前,需要先设置组别变量和待比较的指标变量。
组别变量应该包含不同地区、不同人群的分类信息,指标变量则是我们需要比较的消费水平指标。
通过多样本t检验分析的结果,我们可以判断不同地区、不同人群之间的消费水平是否存在显著差异,并可以比较差异的大小和方向。
我们还可以进行相关分析或回归分析。
通过相关分析,可以计算出各个指标之间的相关系数,从而了解不同指标之间的关系。
在SPSS中,可以使用统计分析模块中的相关功能进行相关分析。
通过回归分析,我们可以建立消费水平和其他相关因素之间的数学模型,并判断这些因素对消费水平的影响程度。
在SPSS中,可以使用统计分析模块中的线性回归功能进行回归分析。
通过相关分析和回归分析的结果,我们可以了解不同指标之间的相关关系,并揭示消费水平的影响因素。
我们可以进行差异分析结果的解读。
根据上述分析结果,我们可以比较不同地区、不同人群之间的消费水平差异,并解释差异产生的原因。
通过解读分析结果,我们可以为政府制定相关经济政策提供科学依据,促进消费水平的均衡和提高。
如何使用统计软件SPSS进行回归分析

如何使用统计软件SPSS进行回归分析一、本文概述在当今的数据分析领域,回归分析已成为了一种重要的统计方法,广泛应用于社会科学、商业、医学等多个领域。
SPSS作为一款功能强大的统计软件,为用户提供了进行回归分析的便捷工具。
本文将详细介绍如何使用SPSS进行回归分析,包括回归分析的基本原理、SPSS 中回归分析的操作步骤、结果解读以及常见问题的解决方法。
通过本文的学习,读者将能够熟练掌握SPSS进行回归分析的方法和技巧,提高数据分析的能力,更好地应用回归分析解决实际问题。
二、SPSS软件基础SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)是一款广泛应用于社会科学领域的数据分析软件,具有强大的数据处理、统计分析、图表制作等功能。
对于回归分析,SPSS 提供了多种方法,如线性回归、曲线估计、逻辑回归等,可以满足用户的不同需求。
在使用SPSS进行回归分析之前,用户需要对其基本操作有一定的了解。
打开SPSS软件后,用户需要熟悉其界面布局,包括菜单栏、工具栏、数据视图和变量视图等。
在数据视图中,用户可以输入或导入需要分析的数据,而在变量视图中,用户可以定义和编辑变量的属性,如变量名、变量类型、测量级别等。
在SPSS中进行回归分析的基本步骤如下:用户需要选择“分析”菜单中的“回归”选项,然后选择适当的回归类型,如线性回归。
接下来,用户需要指定自变量和因变量,可以选择一个或多个自变量,并将它们添加到回归模型中。
在指定变量后,用户还可以设置其他选项,如选择回归模型的类型、设置显著性水平等。
完成这些设置后,用户可以点击“确定”按钮开始回归分析。
SPSS将自动计算回归模型的系数、标准误、显著性水平等统计量,并生成相应的输出表格和图表。
用户可以根据这些结果来评估回归模型的拟合优度、预测能力以及各自变量的贡献程度。
除了基本的回归分析功能外,SPSS还提供了许多高级选项和工具,如模型诊断、变量筛选、多重共线性检测等,以帮助用户更深入地理解和分析回归模型。
spss多元回归分析报告案例
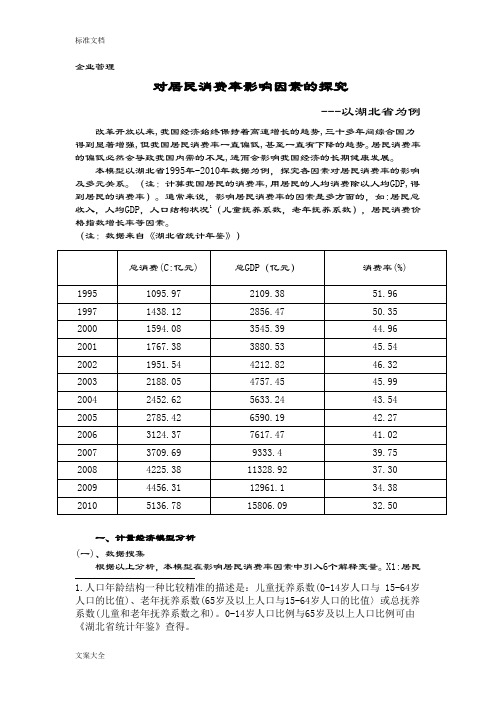
企业管理对居民消费率影响因素的探究---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。
居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。
本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。
(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。
通常来说,影响居民消费率的因素是多方面的,如:居民总收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。
(注:数据来自《湖北省统计年鉴》)总消费(C:亿元) 总GDP(亿元)消费率(%)1995 1095.97 2109.38 51.96 1997 1438.12 2856.47 50.35 2000 1594.08 3545.39 44.96 2001 1767.38 3880.53 45.54 2002 1951.54 4212.82 46.32 2003 2188.05 4757.45 45.99 2004 2452.62 5633.24 43.54 2005 2785.42 6590.19 42.27 2006 3124.37 7617.47 41.02 2007 3709.69 9333.4 39.75 2008 4225.38 11328.92 37.30 2009 4456.31 12961.1 34.38 2010 5136.78 15806.09 32.50一、计量经济模型分析(一)、数据搜集根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。
X1:居民1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。
用SPSS做回归分析

用SPSS做回归分析回归分析是一种统计方法,用于研究两个或多个变量之间的关系,并预测一个或多个因变量如何随着一个或多个自变量的变化而变化。
SPSS(统计软件包的统计产品与服务)是一种流行的统计分析软件,广泛应用于研究、教育和业务领域。
要进行回归分析,首先需要确定研究中的因变量和自变量。
因变量是被研究者感兴趣的目标变量,而自变量是可能影响因变量的变量。
例如,在研究投资回报率时,投资回报率可能是因变量,而投资额、行业类型和利率可能是自变量。
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,并导入数据:首先打开SPSS软件,然后点击“打开文件”按钮导入数据文件。
确保数据文件包含因变量和自变量的值。
2.选择回归分析方法:在SPSS中,有多种类型的回归分析可供选择。
最常见的是简单线性回归和多元回归。
简单线性回归适用于只有一个自变量的情况,而多元回归适用于有多个自变量的情况。
3.设置因变量和自变量:SPSS中的回归分析工具要求用户指定因变量和自变量。
选择适当的变量,并将其移动到正确的框中。
4.运行回归分析:点击“运行”按钮开始进行回归分析。
SPSS将计算适当的统计结果,包括回归方程、相关系数、误差项等。
这些结果可以帮助解释自变量如何影响因变量。
5.解释结果:在完成回归分析后,需要解释得到的统计结果。
回归方程表示因变量与自变量之间的关系。
相关系数表示自变量和因变量之间的相关性。
误差项表示回归方程无法解释的变异。
6.进行模型诊断:完成回归分析后,还应进行模型诊断。
模型诊断包括检查模型的假设、残差的正态性、残差的方差齐性等。
SPSS提供了多种图形和统计工具,可用于评估回归模型的质量。
回归分析是一种强大的统计分析方法,可用于解释变量之间的关系,并预测因变量的值。
SPSS作为一种广泛使用的统计软件,可用于执行回归分析,并提供了丰富的功能和工具,可帮助研究者更好地理解和解释数据。
通过了解回归分析的步骤和SPSS的基本操作,可以更好地利用这种方法来分析数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于SPSS软件的多元线性回归模型分析1.研究背景通胀压力日益上升,食品价格飞速上涨,百姓菜篮子越拎越沉,这已成为当下中国最为棘手的问题。
可谓是市场价格的变动牵动着百姓的心。
2009年以来,尤其是自去年4、5月份以来,鲜菜、鸡蛋等食品价格上涨不但影响到居民的正常生活,而且影响到社会经济全局的健康发展,成为人们关注的热点问题。
据阿左旗(中国内蒙古)城调队50户城镇居民家庭抽样调查显示,2010年一季度,城镇居民人均可支配收入为4884.42元,增长11.48%,人均食品支出1573.84元,增长4.48%,扣除食品价格指数实际增长2.07%。
说明由于物价的上涨,使居民食品支出增幅比上年有所下降,可支配收入的增长不能够弥补因食品价格增长多支出的部分。
针对于目前大众所最关心的物价问题,我小组将我们的研究对象定于消费价格指数CPI,探讨它与国名生产总值GDP、汇率、就业人数、工资和固定投资之间的关系。
2.问题定义模型中定基消费者价格指数是因变量Y;国内生产总值GDP定基值(单位:亿元)为自变量X1;汇率定基值为自变量X2;就业人数定基值(单位:万人)为X3;工资定基值(单位:元)为X4;固定投资定基值(单位:亿元)为X5;B为系数;ε为误差项,定基年为1985年。
由此建立模型,表达式如下所示:Y=B0+B1X1+B2X2+B3X3+B4X4+B5X5+ε3.检验是否满足线性回归的假设条件利用多元线性回归方法标定模型参数并进行分析时,首先必须保证变量等满足线性回归的假设条件:1)自变量与因变量间存在线性关系;2)自变量之间无共线性,相互独立;3)残差独立、等方差,且符合正态分布;首先分析每个自变量与因变量的相关性和线性关系,利用SPSS得到以下图表:由于只有24组数据,数据较少,线性关系表达的不是很清晰,但是从上图中可以看出自变量汇率定基值、国名生产总值GDP定基值、就业人数定基值、工资定基值和固定投资定基值与价格定基指数的线性关系,可以利用X2建立线性方程。
另外,控制X2不变,利用偏相关系数来观察国名生产总值GDP定基值、就业人数定基值、工资定基值和固定投资定基值与价格定基指数的相关性,各自变量的偏相关系数如下:其次,仅满足自变量与因变量的线性关系是不够的,需要保证自变量之间在共线性较小或不存在:由图表可以看出,各变量的容差都较小。
最后,就是检验残差是否满足方差齐性和正态性的要求。
从图(1)的散点图(以回归预测值为Y值,以标准化残差为X轴)看出,它的大部分都落在(-3,3)范围内,且残差直方图中正态拟合曲线与标准P-P拟合图较好,所以该模型满足这个要求。
图(1)综上所述,模型符合线性回归的假设条件。
4. 回归与分析利用SPSS 对模型进行回归,下面我们主要针对表(1)、表(2)、表(3)对模型结果进行分析。
回归分析基本情况表:模型R R 方 调整 R 方 标准 估计的误差 1 .943a .889 .88432.1335 2 .958b .918 .910 28.2881 3 .985c .971 .966 17.2546 4 .985d .971 .968 16.8388 5 .990e .979 .976 14.5162 6.995f.990.98810.2760从上表一可以看出,六个模型的R 方都比较大,说明他们中的自变量都能较好的解释因变量,自变量引起的变动占总变动的百分比高。
观察点在回归直线附近越密集。
然而,直观上判定系数随解释变量个数的增加而增大,易造成错觉:要模型拟合得越好,就应增加解释变量。
然而增加解释变量会降低自由度,减少可用的样本数。
并且有时增加解释变量是不必要的。
这就导致了解释变量个数不同模型之间对比困难。
判定系数只涉及平方和,没有考虑自由度。
为了消除这种影响,这就需要引进自由度校正所计算的平方和,也即表格一中的校正R 方。
同样结果令人满意。
(表中第五列为估计的标准误差,说明了因变量还有好多不能被回归方程所解释。
它只有相对意义,没有绝对意义,与所带单位有关。
)这说明模型假设合理。
拟合较好。
表二中给出了逐步回归过程中每一步被剔除的变量,并给出了各种值,以判断下一步进入回归方程的变量的依据。
下面以模型1为例进行分析。
第一列说明被排除在回归方程外的变量,也即首先考虑就业人数定基指数。
第2列说明所有自变量进行回归分析时的b值,一般认为该值越大,该变量对因变量的贡献越大。
模型1中最大的b=0.366,故第二个进入回归方程的为汇率定基指数。
第3列是针对每一个变量前面的系数是否为零的假设和t检验值,第四列给出了这个检验结果。
上述中的显著性水平只有0.013<0.05,满足要求,其他都不满足。
故应接受就业人口变量前,系数为0的假设,即剔除变量就业人数(因为其的显著性水平最高)。
下面分析剔除就业人数这个变量之后的模型及其参数值。
如表3(模型6)所示:汇率定基指数.831 .059 .602 13.962 .000GDP定基指数.226 .063 2.180 3.616 .002工资定基指数-.236 .082 -1.703 -2.874 .0096 (常量) 54.957 11.181 4.915 .000汇率定基指数.510 .082 .370 6.222 .000GDP定基指数.431 .063 4.149 6.844 .000工资定基指数-.333 .062 -2.398 -5.375 .000 固定投资定基指数-.061 .013 -1.158 -4.573 .000a. 因变量: 价格定基指数模型中CPI(定基消费者价格指数,基础年1985年)是因变量Y;国内生产总值GDP(单位:亿元)为自变量X1;汇率为自变量X2;就业人数(单位:万人)为X3;工资(单位:元)为X4;固定投资(单位:亿元)为X5;B为系数;ε为误差项。
建立模型表达式如下所示:由表3可得:模型6中五个变量显著性水平均为0,故应拒绝他们前面系数为0的假设。
则B0=54.957,B1=0.431,B2=0.510,B3=0,B4=−0.333,B5=−0.061。
ε~N(0,0.91)则最终模型为:Y=54.957+0.431X1+0.510X2−0.333X4−0.061X5+ε注:ε~N(0,0.91)5.模型建议汇率升高导致消费价格指数增大,揭示了一个现象:即汇率(美元兑人民币)增高,即人民币贬值,导致人民币的购买率越低,物价越贵,消费价格指数也就越高,当达到一定程度时,就出现通货膨胀;相反,会使人民币升值,物价降低。
所以,一定程度上应适当提高人民币价值,或者使其保持稳定,对模型进行线性回归时,如果有更多的数据,回归的结果将会更好。
附表1986 107.0 114.0 117.6 102.8 106.4 122.71987 116.4 133.7 126.7 105.8 125.2 149.11988 140.5 166.8 126.7 108.9 145.0 186.91989 163.4 188.5 128.2 110.9 136.8 173.41990 165.5 207.1 162.9 128.1 180.8 177.61991 173.7 241.6 181.2 129.9 197.7 220.01992 177.2 298.6 187.8 131.4 229.1 317.71993 203.3 391.9 196.2 133.1 284.8 514.01994 252.3 534.6 293.5 134.7 383.5 670.11995 295.4 674.3 284.3 136.2 464.8 787.21996 320.0 789.4 283.1 138.1 524.7 901.01997 328.9 875.9 282.3 139.6 546.7 980.71998 326.3 936.1 281.9 140.3 632.0 1116.91999 321.7 994.6 281.9 143.2 705.2 1173.92000 323.0 1100.4 281.9 144.5 791.8 1294.32001 325.3 1216.2 281.8 146.4 918.5 1463.32002 322.7 1334.7 281.8 147.9 1049.7 1710.42003 326.5 1506.5 281.8 149.2 1186.4 2184.92004 339.3 1773.3 281.8 150.8 1354.0 2771.22005 345.4 2032.1 278.9 152.0 1551.8 3490.62006 350.6 2350.5 271.4 153.2 1774.6 4325.22007 367.4 2853.9 258.9 154.4 2106.8 5399.7为了让数据形式保持统一,使回归效果更好,我们对各变量进行了变形,同样都取85年为定基年,分别求取各自的定基值,上数据即变形得到的新数据,原始数据如下:原始数据价格指数国内生产总值(亿元)X1汇率X2就业人数(万人)X3工资(元)X4固定投资(亿元)X51985 134.35 9016.04 2.94 49873.00 1183.00 2543.20 1986 143.75 10275.18 3.45 51282.00 1259.70 3120.60 1987 156.40 12058.62 3.72 52783.00 1481.10 3791.70 1988 188.74 15042.82 3.72 54334.00 1716.20 4753.80 1989 219.49 16992.32 3.77 55329.00 1618.50 4410.40 1990 222.33 18667.82 4.78 63909.00 2140.00 4517.001992 238.10 26923.48 5.51 65554.00 2711.00 8080.10 1993 273.10 35333.92 5.76 66373.00 3371.00 13072.30 1994 339.00 48197.86 8.62 67199.00 4538.00 17042.10 1995 396.90 60793.73 8.35 67947.00 5500.00 20019.30 1996 429.90 71176.59 8.31 68850.00 6210.00 22913.50 1997 441.90 78973.03 8.29 69600.00 6470.00 24941.10 1998 438.40 84402.28 8.28 69957.00 7479.00 28406.20 1999 432.20 89677.05 8.28 71394.00 8346.00 29854.70 2000 434.00 99214.55 8.28 72085.00 9371.00 32917.70 2001 437.00 109655.17 8.28 73025.00 10870.00 37213.50 2002 433.50 120332.69 8.28 73740.00 12422.00 43499.90 2003 438.70 135822.76 8.28 74432.00 14040.00 55566.60 2004 455.80 159878.34 8.28 75200.00 16024.00 70477.43 2005 464.00 183217.40 8.19 75825.00 18364.00 88773.61 2006 471.00 211923.50 7.97 76400.00 21001.00 109998.16 2007 493.60 257305.60 7.60 76990.00 24932.00 137323.94 2008 522.70 300670.00 6.95 77480.00 29229.00 172828.406.软件及方法。