实用数据结构LinkedList
linkedlist push offer

linkedlist push offer
在Java中,LinkedList类提供了两个方法来向列表末尾添加元素:
●push(E e):将元素e推入栈中,相当于在列表头部添加元素。
●offer(E e):将元素e添加到列表末尾,如果添加成功返回true,否则返回
false。
区别主要在于两者的目的和行为:
●push(E e):将LinkedList视为栈,在列表头部添加元素,主要用于模拟栈
的行为。
●offer(E e):将LinkedList视为队列,在列表末尾添加元素,主要用于模拟
队列的行为。
需要注意的是:
●push方法在容量已满的时候会抛出Exception异常,而offer方法不会。
●在大多数情况下,offer方法更常用,因为它更安全高效,并且避免了容量
已满时可能出现的异常。
此外,LinkedList还提供了一个add(E e)方法,它也可以将元素添加到列表末尾,与offer方法的主要区别是:
●add方法总是会将元素添加到列表末尾,不会考虑容量限制,如果容量已满,
会抛出Exception异常。
●offer方法只会在容量允许的情况下将元素添加到列表末尾,否则不会添加。
总结:
1.使用push方法将元素添加到列表头部,模拟栈的行为。
2.使用offer或add方法将元素添加到列表末尾,模拟队列的行为。
3.选择offer方法优先,因为它更安全高效,避免了容量已满时可能出现的异
常。
写出单链表存储结构的 c 语言描述

写出单链表存储结构的 c 语言描述一、单链表的概述单链表是一种常见的数据结构,它由若干个节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
单链表的特点是插入和删除操作效率高,但查找操作效率较低。
二、单链表的存储结构单链表的存储结构采用动态分配内存的方式,每个节点都是一个独立的内存区域,通过指针将它们连接在一起。
下面是单链表存储结构的 c 语言描述:```typedef struct Node{int data; // 数据域struct Node *next; // 指针域} ListNode, *LinkedList;```上面代码中,ListNode 表示节点类型,LinkedList 表示链表类型。
其中 data 是数据域,next 是指针域,用于存放下一个节点的地址。
三、单链表的基本操作1. 初始化操作初始化操作用于创建一个空链表。
```void InitList(LinkedList *L){*L = (ListNode*)malloc(sizeof(ListNode)); // 创建头结点(*L)->next = NULL; // 头结点指针域为空}```2. 插入操作插入操作用于在链表中插入新节点。
```int Insert(LinkedList L, int i, int x)int j = 0;ListNode *p = L;while (p && j < i - 1) // 找到第 i-1 个节点{p = p->next;j++;}if (!p || j > i - 1) // 判断 i 的范围是否合法{return 0;}ListNode *s = (ListNode*)malloc(sizeof(ListNode)); // 创建新节点s->data = x; // 赋值数据域s->next = p->next; // 新节点指向下一个节点p->next = s; // 前一个节点指向新节点 return 1;```3. 删除操作删除操作用于删除链表中的某个节点。
linkedlist用法

linkedlist用法Linkedlist用法Linkedlist是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和一个指向下一个节点的指针。
Linkedlist可以用于实现栈、队列、图等数据结构,也可以作为一种独立的数据结构使用。
1. 创建Linkedlist创建一个空的Linkedlist非常简单,只需要定义一个头指针即可。
头指针通常被定义为一个结构体类型的变量,其中包含指向第一个节点和最后一个节点的指针。
2. 插入节点在Linkedlist中插入新的节点有两种方式:在链表头部插入或在链表尾部插入。
对于单向链表来说,在链表中间插入新的节点比较困难。
2.1 在链表头部插入新的节点在链表头部插入新的节点是最简单、最快速的方式。
只需要将新的节点作为第一个节点,并将原来第一个节点作为新节点后面的那个节点即可。
2.2 在链表尾部插入新的节点在链表尾部插入新的节点需要遍历整个链表找到最后一个节点,并将其指向新的节点。
这个过程比较耗时,但是可以保证新加进来的元素总是排在最后面。
3. 删除节点删除Linkedlist中某个特定位置上的元素也有两种方式:删除头部元素或删除尾部元素。
对于单向链表来说,在链表中间删除节点比较困难。
3.1 删除头部元素删除头部元素非常简单,只需要将头指针指向第二个节点即可。
3.2 删除尾部元素删除尾部元素需要遍历整个链表找到倒数第二个节点,并将其指向NULL。
这个过程比较耗时,但是可以保证被删除的元素总是排在最后面。
4. 遍历Linkedlist遍历Linkedlist可以使用循环或递归的方式实现。
循环的方式比较简单,只需要从头指针开始一直遍历到最后一个节点即可。
递归的方式比较复杂,但是可以更加灵活地处理数据。
5. 反转Linkedlist反转Linkedlist也有两种方式:迭代和递归。
迭代的方式需要用三个指针分别表示当前节点、前一个节点和后一个节点,然后依次将当前节点指向前一个节点,并更新三个指针的位置。
数据结构程序填空题

数据结构程序填空题一、题目描述:编写一个程序,实现一个简单的链表数据结构,并完成以下操作:1. 初始化链表2. 在链表末尾插入节点3. 在链表指定位置插入节点4. 删除链表指定位置的节点5. 获取链表长度6. 打印链表中的所有节点二、解题思路:1. 定义链表节点结构体Node,包含一个数据域和一个指向下一个节点的指针域。
2. 定义链表结构体LinkedList,包含一个头节点指针和一个记录链表长度的变量。
3. 初始化链表时,将头节点指针置为空,链表长度置为0。
4. 在链表末尾插入节点时,先判断链表是否为空,若为空,则将新节点作为头节点;若不为空,则找到链表最后一个节点,将其指针指向新节点。
5. 在链表指定位置插入节点时,先判断插入位置的合法性,若位置超出链表长度范围,则插入失败;否则,找到插入位置的前一个节点,将新节点插入到其后面。
6. 删除链表指定位置的节点时,先判断删除位置的合法性,若位置超出链表长度范围,则删除失败;否则,找到删除位置的前一个节点,将其指针指向要删除节点的下一个节点,并释放要删除节点的内存空间。
7. 获取链表长度时,直接返回链表结构体中记录的长度变量。
8. 打印链表中的所有节点时,从头节点开始遍历链表,依次输出每个节点的数据域。
三、代码实现:```c#include <stdio.h>#include <stdlib.h>// 定义链表节点结构体typedef struct Node {int data; // 数据域struct Node* next; // 指针域} Node;// 定义链表结构体typedef struct LinkedList {Node* head; // 头节点指针int length; // 链表长度} LinkedList;// 初始化链表void initLinkedList(LinkedList* list) {list->head = NULL; // 头节点指针置为空list->length = 0; // 链表长度置为0}// 在链表末尾插入节点void insertAtEnd(LinkedList* list, int value) {Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点newNode->data = value; // 设置新节点的数据域newNode->next = NULL; // 设置新节点的指针域为NULL if (list->head == NULL) {list->head = newNode; // 若链表为空,将新节点作为头节点} else {Node* current = list->head;while (current->next != NULL) {current = current->next; // 找到链表最后一个节点}current->next = newNode; // 将最后一个节点的指针指向新节点}list->length++; // 链表长度加1}// 在链表指定位置插入节点void insertAtPosition(LinkedList* list, int value, int position) {if (position < 0 || position > list->length) {printf("插入位置不合法!\n");return;}Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点newNode->data = value; // 设置新节点的数据域if (position == 0) {newNode->next = list->head; // 若插入位置为0,将新节点作为头节点 list->head = newNode;} else {Node* current = list->head;for (int i = 0; i < position - 1; i++) {current = current->next; // 找到插入位置的前一个节点}newNode->next = current->next; // 将新节点的指针指向插入位置的节点 current->next = newNode; // 将插入位置的前一个节点的指针指向新节点}list->length++; // 链表长度加1}// 删除链表指定位置的节点void deleteAtPosition(LinkedList* list, int position) {if (position < 0 || position >= list->length) {printf("删除位置不合法!\n");return;}Node* temp;if (position == 0) {temp = list->head; // 记录要删除的节点list->head = list->head->next; // 将头节点指向下一个节点} else {Node* current = list->head;for (int i = 0; i < position - 1; i++) {current = current->next; // 找到删除位置的前一个节点}temp = current->next; // 记录要删除的节点current->next = current->next->next; // 将删除位置的前一个节点的指针指向删除位置的后一个节点}free(temp); // 释放要删除节点的内存空间list->length--; // 链表长度减1}// 获取链表长度int getLength(LinkedList* list) {return list->length;}// 打印链表中的所有节点void printLinkedList(LinkedList* list) { Node* current = list->head;while (current != NULL) {printf("%d ", current->data);current = current->next; // 遍历链表 }printf("\n");}int main() {LinkedList list;initLinkedList(&list);insertAtEnd(&list, 1);insertAtEnd(&list, 2);insertAtEnd(&list, 3);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 2 3insertAtPosition(&list, 4, 1);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 4 2 3deleteAtPosition(&list, 2);printf("链表中的节点:");printLinkedList(&list); // 链表中的节点:1 4 3int length = getLength(&list);printf("链表的长度:%d\n", length); // 链表的长度:3 return 0;}```四、测试结果:运行以上代码,输出结果为:```链表中的节点:1 2 3链表中的节点:1 4 2 3链表中的节点:1 4 3链表的长度:3```五、总结:通过以上程序的实现,我们成功地完成了一个简单的链表数据结构,并实现了初始化链表、在链表末尾插入节点、在链表指定位置插入节点、删除链表指定位置的节点、获取链表长度以及打印链表中的所有节点等操作。
Java核心数据结构(List、Map、Set)原理与使用技巧
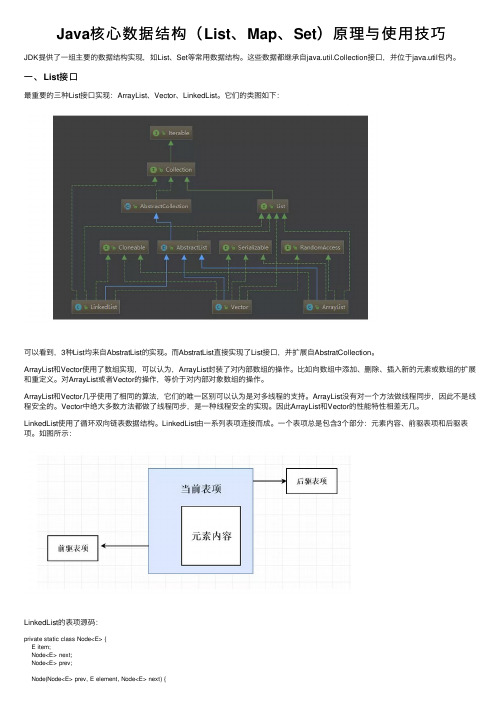
Java核⼼数据结构(List、Map、Set)原理与使⽤技巧JDK提供了⼀组主要的数据结构实现,如List、Set等常⽤数据结构。
这些数据都继承⾃java.util.Collection接⼝,并位于java.util包内。
⼀、List接⼝最重要的三种List接⼝实现:ArrayList、Vector、LinkedList。
它们的类图如下:可以看到,3种List均来⾃AbstratList的实现。
⽽AbstratList直接实现了List接⼝,并扩展⾃AbstratCollection。
ArrayList和Vector使⽤了数组实现,可以认为,ArrayList封装了对内部数组的操作。
⽐如向数组中添加、删除、插⼊新的元素或数组的扩展和重定义。
对ArrayList或者Vector的操作,等价于对内部对象数组的操作。
ArrayList和Vector⼏乎使⽤了相同的算法,它们的唯⼀区别可以认为是对多线程的⽀持。
ArrayList没有对⼀个⽅法做线程同步,因此不是线程安全的。
Vector中绝⼤多数⽅法都做了线程同步,是⼀种线程安全的实现。
因此ArrayList和Vector的性能特性相差⽆⼏。
LinkedList使⽤了循环双向链表数据结构。
LinkedList由⼀系列表项连接⽽成。
⼀个表项总是包含3个部分:元素内容、前驱表项和后驱表项。
如图所⽰:LinkedList的表项源码:private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}⽆论LinkedList是否为空,链表都有⼀个header表项,它既是链表的开始,也表⽰链表的结尾。
数据结构—链表

数据结构—链表链表⽬录⼀、概述1.链表是什么链表数⼀种线性数据结构。
它是动态地进⾏储存分配的⼀种结构。
什么是线性结构,什么是⾮线性结构?线性结构是⼀个有序数据元素的集合。
常⽤的线性结构有:线性表,栈,队列,双队列,数组,串。
⾮线性结构,是⼀个结点元素可能有多个直接前趋和多个直接后继。
常见的⾮线性结构有:⼆维数组,多维数组,⼴义表,树(⼆叉树等)。
2.链表的基本结构链表由⼀系列节点组成的集合,节点(Node)由数据域(date)和指针域(next)组成。
date负责储存数据,next储存其直接后续的地址3.链表的分类单链表(特点:连接⽅向都是单向的,对链表的访问要通过顺序读取从头部开始)双链表循环链表单向循环链表双向循环链表4.链表和数组的⽐较数组:优点:查询快(地址是连续的)缺点:1.增删慢,消耗CPU内存链表就是⼀种可以⽤多少空间就申请多少空间,并且提⾼增删速度的线性数据结构,但是它地址不是连续的查询慢。
⼆、单链表[1. 认识单链表](#1. 认识单链表)1. 认识单链表(1)头结点:第0 个节点(虚拟出来的)称为头结点(head),它没有数据,存放着第⼀个节点的⾸地址(2)⾸节点:第⼀个节点称为⾸节点,它存放着第⼀个有效的数据(3)中间节点:⾸节点和接下来的每⼀个节点都是同⼀种结构类型:由数据域(date)和指针域(next)组成数据域(date)存放着实际的数据,如学号(id)、姓名(name)、性别(sex)、年龄(age)、成绩(score)等指针域(next)存放着下⼀个节点的⾸地址(4)尾节点:最后⼀个节点称为尾节点,它存放着最后⼀个有效的数据(5)头指针:指向头结点的指针(6)尾指针:指向尾节点的指针(7)单链表节点的定义public static class Node {//Object类对象可以接收⼀切数据类型解决了数据统⼀问题public Object date; //每个节点的数据Node next; //每个节点指向下⼀结点的连接public Node(Object date) {this.date = date;}}2.引⼈头结点的作⽤1. 概念头结点:虚拟出来的⼀个节点,不保存数据。
linkedlist扩容机制原理

linkedlist扩容机制原理linkedlist扩容机制原理简介在计算机科学中,链表是一种常见的数据结构,用于存储和组织数据。
当链表的容量不足以存储所有数据时,需要进行扩容,即增加链表的大小。
本文将深入探讨linkedlist扩容机制的原理,从浅入深解释相关原理。
linkedlist基本概念•Linkedlist是由一系列节点组成的集合,每个节点包含一个数据元素和指向下一个节点的指针。
•Linkedlist的头部指针指向链表的第一个节点,而尾部指针指向链表的最后一个节点。
•Linkedlist可以动态地增加或删除节点,适用于频繁的插入和删除操作。
链表扩容的原因链表扩容是由于链表的容量不足以存储当前的数据量。
当链表的容量达到了某个上限时,就需要进行扩容操作,以便增加链表的存储空间。
链表扩容通常涉及以下几个方面的原理。
链表的分配策略链表的扩容涉及到如何分配新的存储空间。
通常有两种常见的分配策略:1.静态扩容:静态扩容是通过一次性分配一段固定大小的内存空间来实现的。
当链表需要扩容时,会分配一段较大的内存空间,然后将原有的数据复制到新的内存空间中。
静态扩容可以提高链表的效率,但是当链表的容量不足时,可能会产生较大的内存浪费。
2.动态扩容:动态扩容是通过按需分配内存来实现的。
当链表的容量不足时,会分配一小段新的内存空间,然后将原有的数据复制到新的内存空间中。
动态扩容可以减少内存浪费,但是在复制数据时可能会导致一定的性能损耗。
扩容触发条件链表扩容的触发条件通常有以下几种:1.当链表插入新节点时,如果当前链表的容量已满,则需要进行扩容操作。
插入新节点后,链表的容量达到上限,触发扩容。
2.当链表删除节点时,如果链表的容量过大(超过一定阈值),可以选择进行缩容操作。
删除节点后,链表的容量低于一定比例,触发缩容。
扩容算法链表的扩容操作通常涉及以下几个步骤:1.计算新的链表容量:根据当前链表容量和扩容因子计算出新的链表容量。
2.1ArrayList线程不安全,LinkedList线程不安全,Vector线程安全

2.1ArrayList线程不安全,LinkedList线程不安全,Vector线程安全⼀、ArrayList 线程不安全1.数据结构(数组 transient Object[] elemetData;)ArrayList的底层数据结构就是⼀个数组,数组元素的类型为Object类型,对ArrayList的所有操作底层都是基于数组的。
2.扩容(1.5倍,在add时初始化默认为10)ArrayList的扩容主要发⽣在向ArrayList集合中添加元素的时候private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 判断元素数组是否为空数组minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); // 取较⼤值}ensureExplicitCapacity(minCapacity);}private void ensureExplicitCapacity(int minCapacity) {// 结构性修改加1modCount++;if (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {int oldCapacity = elementData.length; // 旧容量int newCapacity = oldCapacity + (oldCapacity >> 1); // 新容量为旧容量的1.5倍if (newCapacity - minCapacity < 0) // 新容量⼩于参数指定容量,修改新容量newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0) // 新容量⼤于最⼤容量newCapacity = hugeCapacity(minCapacity); // 指定新容量// 拷贝扩容elementData = Arrays.copyOf(elementData, newCapacity);}2.线程不安全添加操作:在object[size]上存放元素,然后size++原因:两个线程,A将数据存放在0的位置,A暂停,B存放数据,由于A未将size++,所以B也将数据存放在0上,然后A和B都同时运⾏,size=2,但是只有位置0上有数据,所以说线程不安全解决办法:使⽤synchronized关键字;或⽤Collections类中的静态⽅法synchronizedList();对ArrayList进⾏调⽤即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
a1 a2 … a1 a2 …
ai-1 ai ai-1 e
… aianFra bibliotek… an
3
表的长度增加
插入算法时间复杂度分析: 插入算法时间复杂度分析: 考虑移动元素的平均情况
插入位置 1 2 … n n+1 需要移动的结点次数 n n-1 … 1
平均次数: 平均次数 (1+2+…+n-1+n)/(n+1) =n/2
24
List接口和LinkedList类
第二步: 第二步:具体实现
public class FirstLevelTitleDB { 2、获取第一条、以及最末条新闻标题 public static void main(String[] args) { FirstLevelTitle car = new FirstLevelTitle(1, "汽车 "管理员 new Date()); 汽车", 管理员 管理员", 汽车 3、删除第一条、以及最末条新闻标题 FirstLevelTitle medical = new FirstLevelTitle(2, "医学 "管理员 医学", 管理员 管理员",new Date()); 医学 LinkedList newsTitleList = new LinkedList(); newsTitleList.addFirst(car); newsTitleList.addLast(medical); FirstLevelTitle first = (FirstLevelTitle) newsTitleList.getFirst(); System.out.println("头条的新闻标题为 + first.getTitleName()); 头条的新闻标题为:" 头条的新闻标题为 FirstLevelTitle last = (FirstLevelTitle) newsTitleList.getLast(); System.out.println("排在最后的新闻标题为 + last.getTitleName()); 排在最后的新闻标题为:" 排在最后的新闻标题为 newsTitleList.removeFirst(); newsTitleList.removeLast();
第一步, 第一步,确定存储方式
1、LinkedList类是List接口的一个具体实现类 2、LinkedList 类用于创建链表数据结构 3、插入或者删除元素时,它提供更好的性能
23
List接口和ArrayList类
第二步: 第二步:确定存储对象
1、创建类型:新闻标题 public class FirstLevelTitle { private int id; //ID 2、包含属性: ID、名称、创建者、创建时间 private String titleName; //名称 名称 private String creater; //创建者 创建者 private Date createTime; //创建时间 创建时间
=
+ 指针(指示后继元素存储位置 指示后继元素存储位置) 指示后继元素存储位置 结点
(表示数据元素 或 数据元素的映象) 数据元素的映象
以“结点的序列 结点的序列”表示线性表 结点的序列 称作链表 链表
12
链表
单向链表
head节点 data next data next data next=null
25
1、添加第一条、以及最末条新闻标题
1
2
3
} }
练习
创建一个类Stack,代表堆栈(其特点为:后进先出), 创建一个类Stack,代表堆栈(其特点为:后进先出), Stack 添加方法add(Object obj)、以及delete( ),添加main 添加方法add(Object obj)、以及delete( ),添加main 方法进行验证,要求: 方法进行验证,要求:
21
List接口和LinkedList类
开发一套小型的新闻管理系统,要求如下: 开发一套小型的新闻管理系统,要求如下:
可以添加头条新闻标题 可以删除末条新闻标题
元素个数不确定 存储方式如何选择? 存储方式如何选择?
使用集合类
需要在列表的头或尾添加、 需要在列表的头或尾添加、删除元素
22
List接口和LinkedList类
13
链表
插入
head节点 data next data next data next=null
data
next
删除
head节点 data next data next data next=null
14
线性表的操作:插入在单链表中的实 现: 有序对 <ai-1, ai> 改变为 <ai-1, e> 和<e, ai>
ai-1 e
15
ai
线性表的操作:删除在单链表中的实现:
有序对< 有序对<ai-1, ai> 和 <ai, ai+1> 改变为 <ai-1, ai+1> ai-1 ai ai+1
16
链表
循环链表
head节点 data next data next data next
17
链表
双向循环链表
head节点 previous data next
创建一个类CatTest,添加main方法, 创建一个类CatTest,添加main方法,实现 CatTest main方法
创建一个ArrayList,向其中添加几个Cat对象 遍历该集合,并且对每个Cat对象调用show()方法
8
参考代码
class Cat{ private String name; public Cat(String name){ = name; } public void show(){ System.out.println(name); } } public class CatTest { public static void main(String[] args){ //创建一个 创建一个ArrayList,向其中添加几个Cat对象; ,向其中添加几个 对象; 创建一个 对象 ArrayList list = new ArrayList(); list.add(new Cat("mimi")); list.add(new Cat("qiqi")); list.add(new Cat("ding")); //遍历该集合,并且对每个Cat对象调用 遍历该集合,并且对每个 对象调用show()方法。 方法。 遍历该集合 对象调用 方法 for(int i= 0;i<list.size();i++){ Cat c = (Cat)list.get(i); c.show(); }
回顾
数组 Arrays类 Arrays类 Arrays.sort() Arrays.binarySearch() Arrays.fill() Arrays.asList() ArrayList类 ArrayList类 结构特点 常用方法:size(), isEmpty(),contains(),indexOf(),toArray(), get(),set(),add(),addAll(),remove(),clear()
public FirstLevelTitle(int id, String titleName, String creater,Date createTime) { this.id = id; this.titleName = titleName; this.creater = creater; this.createTime = createTime; } public String getTitleName() { return titleName; } public void setTitleName(String titleName) { this.titleName = titleName; } }
1
顺序表便于查找操作,而插入和 删除元素时要大量移动元素。
首先分析: 首先分析
插入元素时, 线性表的逻辑结构发生什么变化 逻辑结构发生什么变化 逻辑结构发生什么变化?
2
(a1, …, ai-1, ai, …, an) 改变为 (a1, …, ai-1, e, ai, …, an)
<ai-1, ai> <ai-1, e>, <e, ai>
previous
data
next
previous
data
next
18
LinkedList类
19
LinkedList类
LinkedList实现了List接口,允许null元素。 LinkedList实现了List接口,允许null元素。此外 实现了List接口 null元素 LinkedList提供额外的get,remove,insert方法在 提供额外的get LinkedList提供额外的get,remove,insert方法在 LinkedList的首部或尾部 这些操作使LinkedList 的首部或尾部。 LinkedList可 LinkedList的首部或尾部。这些操作使LinkedList可 被用作堆栈(stack),队列(queue) ),队列 被用作堆栈(stack),队列(queue)或双向队列 deque)。 (deque)。 注意LinkedList没有同步方法。 LinkedList没有同步方法 注意LinkedList没有同步方法。如果多个线程同时访 问一个List 则必须自己实现访问同步。 List, 问一个List,则必须自己实现访问同步。一种解决方 法是在创建List时构造一个同步的List List时构造一个同步的List: 法是在创建List时构造一个同步的List: List list = Collections.synchronizedList(new LinkedList(...));